

국내 ChatGPT '쉘'의 비밀이 이제 밝혀졌습니다


"iFlytek이 ChatGPT를 커버합니다!" "Baidu Wenxin은 한 단어로 Stable Diffusion을 은폐했습니다!" "SenseTime의 대형 모델은 실제로 표절되었습니다!"...
외부에서 국내 생산에 대해 의문을 제기한 것이 한두 번이 아닙니다. 대형 모델.
이 현상에 대한 업계 관계자의 설명은 고품질의 중국 데이터 세트가 실제로 부족하다는 것입니다. 모델을 훈련할 때 구매한 외국어 주석 데이터 세트를 사용하여 "대외 원조 역할"을 할 수 있습니다. 훈련에 사용된 데이터 세트가 충돌하면 유사한 결과가 생성되어 자체 사고로 이어집니다.
기존 대형 모델을 사용하여 학습 데이터 생성을 지원하는 방법 중 토큰을 재사용하면 과적합이 발생하기 쉽습니다. 희소 대형 모델만 학습하는 것은 장기적인 솔루션이 아닙니다.
업계에서는 점차 합의가 형성되고 있습니다.
AGI로 가는 길은 데이터 양과 데이터 품질 모두에 대해 계속해서 매우 높은 요구 사항을 제시할 것입니다.
현재 상황으로 인해 지난 2개월 동안 많은 국내 팀이 연속적으로 오픈 소스 중국어 데이터 세트를 보유했습니다. 프로그래밍과 의료.
고품질 데이터 세트를 사용할 수 있지만 거의 없습니다.
대형 모델의 새로운 혁신은 고품질의 풍부한 데이터 세트에 크게 의존합니다.
OpenAI의 "신경 언어 모델을 위한 스케일링 법칙"에 따르면 대형 모델이 제안하는 스케일링 법칙(스케일링 법칙)학습 데이터의 양을 독립적으로 늘리면 사전 학습된 모델의 효과가 향상될 수 있음을 알 수 있습니다.
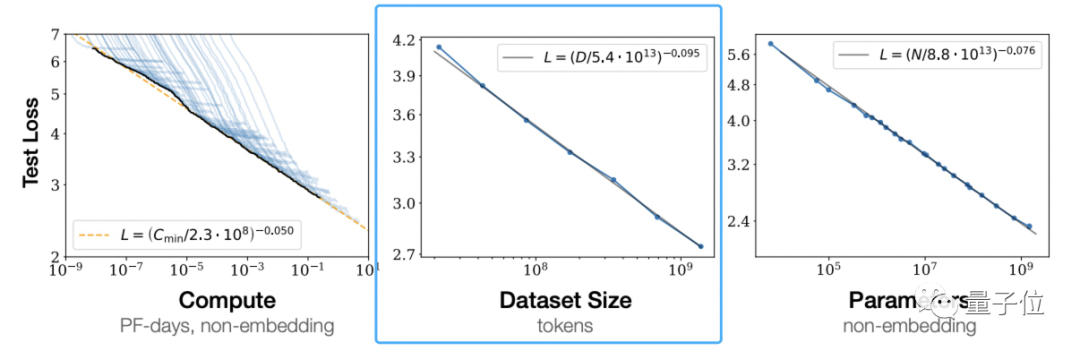
이것은 OpenAI의 의견이 아닙니다.
딥마인드 역시 친칠라 모델 논문에서 기존 대형 모델의 대부분이 훈련이 부족했다는 점을 지적하고, 최적의 훈련 공식도 제안해 업계에서 인정받은 표준이 됐다.
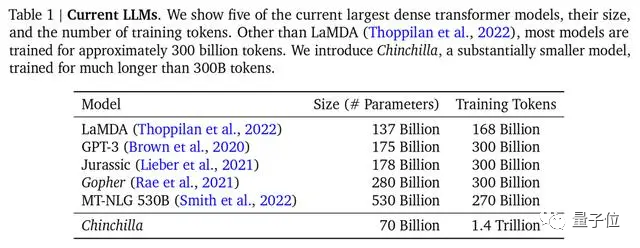
Δ주류 대형 모델인 Chinchilla는 매개변수가 가장 적지만 훈련은 가장 충분합니다
그러나 훈련에 사용되는 주류 데이터 세트는 주로 영어로 되어 있습니다. Common Crawl, BooksCorpus, WiKipedia, ROOT 등 가장 인기 있는 Common Crawl 중국어 데이터는 4.8%에 불과합니다.
중국 데이터셋의 상황은 어떤가요?
공개 데이터 세트는 없습니다. 이는 Lanzhou Technology의 창립자이자 CEO이자 현재 NLP 분야에서 가장 뛰어난 중국인 중 한 명인 Zhou Ming의 Qubits에 의해 확인되었습니다. 예를 들어 명명된 엔터티 데이터 세트 MSRA-NER, Weibo- NER 등 GitHub에서 찾을 수 있는 CMRC2018, CMRC2019, ExpMRC2022 등도 있지만 전체 숫자는 영어 데이터 세트에 비해 버킷에서 감소합니다.
그리고 그들 중 일부는 오래되었고 최신 NLP 연구 개념을 모를 수도 있습니다(새로운 개념과 관련된 연구는 arXiv에서 영어로만 나타납니다).
고품질의 중국 데이터 세트가 존재하지만 그 수가 적고 사용하기가 번거롭습니다. 이는 대규모 모델 연구를 수행하는 모든 팀이 직면해야 하는 심각한 상황입니다. 이전 칭화대학교 전자학과 포럼에서 칭화대학교 컴퓨터과학과 Tang Jie 교수는 1000억 모델 ChatGLM-130B의 사전 훈련을 위한 데이터를 준비할 때 청소 후 다음과 같은 상황에 직면했다고 공유했습니다. 중국 데이터를 보면 가용 용량이 2TB도 안 됐어요.
중국 세계의 고품질 데이터 세트 부족 문제를 해결하는 것이 시급합니다.
효과적인 솔루션 중 하나는 영어 데이터를 직접 사용하여 대형 모델을 학습시키는 것입니다.
인간 플레이어가 평가한 대규모 익명 경기장의 Chatbot Arena 목록에서 GPT-3.5는 영어 이외의 언어 순위에서 2위를 차지했습니다(첫 번째는 GPT-4입니다). GPT-3.5 학습 데이터의 96%가 영어로 되어 있다는 점을 알아야 합니다. 다른 언어를 제외하면 학습에 사용되는 중국어 데이터의 양은 "n/1000"으로 계산할 수 있을 정도로 적습니다.
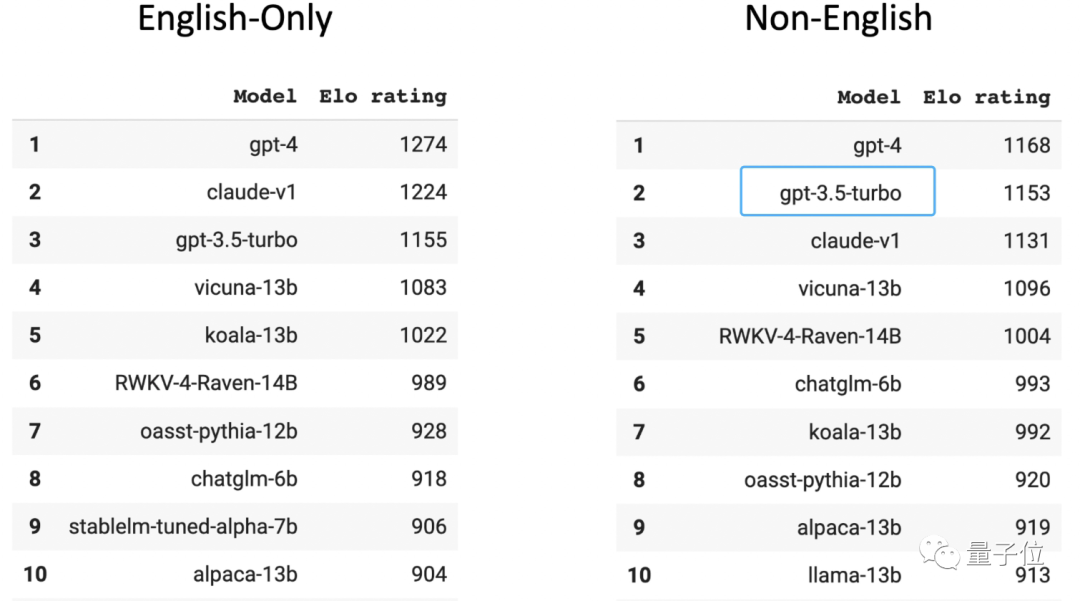
중국 3대 대학의 대규모 모델 관련 팀의 한 박사과정생은 이 방법을 채택하고 번거롭지 않다면 모델에 번역 소프트웨어를 연결해 변환할 수도 있다고 밝혔습니다. 모든 언어를 영어로 변환한 후 중국어로 변환하여 모델을 출력하여 사용자에게 반환합니다.
그러나 이렇게 먹힌 빅모델은 항상 영어로 생각하고 있습니다. 관용어 다시 쓰기, 구어체 이해, 기사 다시 쓰기 등 중국어 특성을 지닌 콘텐츠를 접할 때 제대로 처리되지 않아 번역 오류나 잠재적인 문화 문제가 발생하는 경우가 많습니다. 편차.
또 다른 해결책은 중국어 말뭉치를 수집, 정리 및 라벨링하고, 새로운 고품질 중국어 데이터 세트를 만들어 대형 모델에 공급하는 것입니다.
오픈 소스 데이터 세트가 장작을 모으고 있습니다
현재 상황을 인지한 많은 국내 대형 모델 팀은 두 번째 길을 택하기로 결정하고 개인 데이터베이스를 사용하여 데이터 세트를 만들기 시작했습니다.
Baidu에는 콘텐츠 생태 데이터가 있고, Tencent에는 공개 계정 데이터가 있고, Zhihu에는 Q&A 데이터가 있으며, Alibaba에는 전자상거래 및 물류 데이터가 있습니다.
다양하게 축적된 개인 데이터를 사용하면 특정 시나리오 및 분야에서 핵심 이점 장벽을 설정할 수 있습니다. 이러한 데이터의 엄격한 수집, 정렬, 필터링, 정리 및 라벨링은 훈련된 모델의 효과와 정확성을 보장할 수 있습니다.
그리고 프라이빗 데이터 이점이 그다지 명확하지 않은 대규모 모델 팀은 전체 네트워크에 걸쳐 데이터를 크롤링하기 시작했습니다(크롤러 데이터의 양이 매우 클 것으로 예상됩니다).
Pangu 대형 모델을 구축하기 위해 Huawei는 인터넷에서 80TB의 텍스트를 크롤링하여 최종적으로 이를 1TB 중국어 데이터 세트로 정리했습니다. Inspur Source 1.0 교육에 사용된 중국 데이터 세트는 5000GB에 달했습니다(GPT3 모델 교육 데이터와 비교). 570GB 세트), 최근 출시된 Tianhe Tianyuan 대형 모델은 Tianjin Supercomputing Center의 글로벌 웹 데이터 수집 및 구성과 다양한 오픈 소스 교육 데이터 및 전문 현장 데이터 세트가 포함된 결과이기도 합니다.
동시에 지난 2개월 동안 사람들이 중국 데이터 세트를 위해 장작을 모으는 현상이 있었습니다. -
많은 팀이 현재의 단점이나 불균형을 보완하기 위해 오픈 소스 중국 데이터 세트를 연속적으로 출시했습니다. 중국 오픈소스 데이터 세트.
그 중 일부는 다음과 같이 구성됩니다.
- CodeGPT: GPT 및 GPT에서 생성된 코드 관련 대화 데이터 세트를 뒷받침하는 기관은 Fudan University입니다.
- CBook-150k: 인문학, 교육, 과학 기술, 군사, 정치 등 다양한 분야를 망라하는 150,000권의 중국어 도서에 대한 다운로드 및 추출 방법을 포함한 중국어 코퍼스 도서 모음입니다. 그 뒤에 있는 조직은 푸단입니다. 대학교.
- RefGPT: 수동 주석으로 인한 값비싼 비용을 피하기 위해 우리는 사실 기반 대화를 자동으로 생성하고 데이터의 일부를 공개하는 방법을 제안합니다. 여기에는 50,000개의 중국 다단계 대화가 포함됩니다. Shanghai Jiao Tong University 및 홍콩 NLP 실무자는 폴리테크닉 대학과 같은 기관에 있습니다.
- COIG: 전체 이름은 "China Common Open Instruction Data Set"입니다. 이는 더 크고 다양한 명령어 튜닝 코퍼스이며, 그 뒤에 있는 공동 조직에는 Beijing Institute of Artificial가 포함되어 있습니다. 지능, 셰필드 대학교, 미시간 대학교, 다트머스 대학교, 절강 대학교, 베이항 대학교, 카네기 멜론 대학교.
- 멋진 중국 법률 자료: Shanghai Jiao Tong University에서 수집하고 정리한 중국 법률 데이터 자료입니다.
- Huatuo: 의학 지식 그래프와 GPT3.5 API를 통해 구축된 중국 의학 지시 데이터 세트를 바탕으로 LLaMA의 지시를 미세 조정하여 의료 분야에서 LLaMA의 질의 응답 효과를 향상시켰습니다. 해당 프로젝트의 오픈 소스 당사자는 Harbin Institute of Technology입니다.
- Baize: 소수의 "시드 질문"을 사용하여 ChatGPT가 자체적으로 채팅할 수 있게 하고 이를 자동으로 고품질의 다단계 대화 데이터 세트로 수집합니다. 캘리포니아 대학교 샌디에이고(UCSD) Sun Yat-sen 대학 및 MSRA 팀과 협력합니다. 이 방법을 사용하여 수집된 데이터 세트를 오픈 소스로 만듭니다.
고품질의 중국 데이터는 단지 내실에 숨겨져 있을 뿐입니다. 이제 모든 사람이 이 문제를 인식하고 있으므로 자연스럽게 다음과 같은 해당 솔루션이 나올 것입니다. 오픈 소스 데이터 .이 단계에서는 사전 훈련 데이터 외에도 인간 피드백 데이터도 필수적이라는 점에 주목할 가치가 있습니다. 기성품 예시가 눈앞에 있습니다. GPT-3과 비교했을 때 ChatGPT 오버레이의 중요한 이점은 RLHF한마디로 좋은 방향으로 발전하고 있는 거겠죠?
(인간 피드백 강화 학습) 을 사용하여 미세 조정을 위한 고품질 라벨 데이터를 생성한다는 것입니다. 인간의 의도에 맞춰 대형 모델을 만드는 것입니다.
인간 피드백을 제공하는 가장 직접적인 방법은 AI 도우미에게 "네 대답이 틀렸어"라고 말하거나, AI 도우미가 생성한 답변 바로 옆에 좋아요 또는 싫어요를 표시하는 것입니다.
위 내용은 국내 ChatGPT '쉘'의 비밀이 이제 밝혀졌습니다의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7489
7489
 15
1377
52
77
11
52
19
19
41
15
1377
52
77
11
52
19
19
41

 나는 Cursor AI와 함께 Vibe 코딩을 시도했는데 놀랍습니다!
Mar 20, 2025 pm 03:34 PM
나는 Cursor AI와 함께 Vibe 코딩을 시도했는데 놀랍습니다!
Mar 20, 2025 pm 03:34 PM
Vibe Coding은 끝없는 코드 라인 대신 자연 언어를 사용하여 애플리케이션을 생성함으로써 소프트웨어 개발의 세계를 재구성하고 있습니다. Andrej Karpathy와 같은 비전가들로부터 영감을 얻은이 혁신적인 접근 방식은 Dev가
 2025 년 2 월 2 일 Genai 출시 : GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
2025 년 2 월 2 일 Genai 출시 : GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
2025 년 2 월은 Generative AI의 또 다른 게임 변화 달이었으며, 가장 기대되는 모델 업그레이드와 획기적인 새로운 기능을 제공합니다. Xai 's Grok 3 및 Anthropic's Claude 3.7 Sonnet, Openai 's G에 이르기까지
 물체 감지에 Yolo V12를 사용하는 방법은 무엇입니까?
Mar 22, 2025 am 11:07 AM
물체 감지에 Yolo V12를 사용하는 방법은 무엇입니까?
Mar 22, 2025 am 11:07 AM
Yolo (한 번만 보이면)는 주요 실시간 객체 감지 프레임 워크였으며 각 반복은 이전 버전에서 개선되었습니다. 최신 버전 Yolo V12는 정확도를 크게 향상시키는 발전을 소개합니다.
 chatgpt 4 o를 사용할 수 있습니까?
Mar 28, 2025 pm 05:29 PM
chatgpt 4 o를 사용할 수 있습니까?
Mar 28, 2025 pm 05:29 PM
ChatGpt 4는 현재 이용 가능하고 널리 사용되며 ChatGpt 3.5와 같은 전임자와 비교하여 상황을 이해하고 일관된 응답을 생성하는 데 상당한 개선을 보여줍니다. 향후 개발에는보다 개인화 된 인터가 포함될 수 있습니다
 Google ' S Gencast : Gencast Mini 데모와의 일기 예보
Mar 16, 2025 pm 01:46 PM
Google ' S Gencast : Gencast Mini 데모와의 일기 예보
Mar 16, 2025 pm 01:46 PM
Google Deepmind 's Gencast : 일기 예보를위한 혁신적인 AI 일기 예보는 기초 관측에서 정교한 AI 구동 예측으로 이동하여 극적인 변화를 겪었습니다. Google Deepmind의 Gencast, 획기적인
 창의적인 프로젝트를위한 최고의 AI 아트 발전기 (무료 & amp; 유료)
Apr 02, 2025 pm 06:10 PM
창의적인 프로젝트를위한 최고의 AI 아트 발전기 (무료 & amp; 유료)
Apr 02, 2025 pm 06:10 PM
이 기사는 최고의 AI 아트 생성기를 검토하여 자신의 기능, 창의적인 프로젝트에 대한 적합성 및 가치에 대해 논의합니다. Midjourney를 전문가에게 최고의 가치로 강조하고 고품질의 사용자 정의 가능한 예술에 Dall-E 2를 추천합니다.
 chatgpt보다 어떤 AI가 더 낫습니까?
Mar 18, 2025 pm 06:05 PM
chatgpt보다 어떤 AI가 더 낫습니까?
Mar 18, 2025 pm 06:05 PM
이 기사에서는 AI 모델이 Lamda, Llama 및 Grok과 같은 Chatgpt를 능가하는 것에 대해 논의하여 정확성, 이해 및 산업 영향의 장점을 강조합니다. (159 자).
 O1 대 GPT-4O : OpenAI의 새로운 모델이 GPT-4O보다 낫습니까?
Mar 16, 2025 am 11:47 AM
O1 대 GPT-4O : OpenAI의 새로운 모델이 GPT-4O보다 낫습니까?
Mar 16, 2025 am 11:47 AM
OpenAi의 O1 : 12 일 선물 Spree는 아직 가장 강력한 모델로 시작합니다. 12 월의 도착은 세계의 일부 지역에서 전 세계적으로 속도가 저하 된 눈송이를 가져 오지만 Openai는 막 시작되었습니다. Sam Altman과 그의 팀은 12 일 선물을 시작하고 있습니다.
