
Redis는 키-값 쌍을 기반으로 하는 NoSQL 데이터베이스입니다. Redis의 Value는 String, hash, list, set, zset, Bitmaps, HyperLogLog 등 다양한 데이터 구조와 알고리즘으로 구성될 수 있습니다. Redis에는 키 만료, 게시 및 구독, 트랜잭션, Lua 스크립트, 센티널, 클러스터 등과 같은 많은 기능이 있습니다.
공식 성능 데이터에 따르면 Redis는 매우 빠른 속도로 명령을 실행할 수 있으며 QPS는 100,000 이상에 도달할 수 있습니다. 그래서 이번 글에서는 주로 Redis가 빠른 곳을 소개합니다.
1. 개발 언어
이제 우리는 모두 Java, Python 등 프로그래밍을 위해 고급 언어를 사용합니다. C언어는 아주 오래된 언어라고 생각할 수도 있지만, 사실은 유닉스 시스템이 C로 구현되어 있기 때문에 C언어는 운영체제와 매우 가까운 언어입니다. Redis는 C 언어로 개발되었기 때문에 실행 속도가 더 빨라집니다.
한 가지 더, 컴퓨터 운영체제를 더 잘 이해하는 데 도움이 되는 C 언어 학습에 집중해야 합니다. 고급 언어를 배운 후에는 하위 계층에 주의를 기울일 필요가 없다고 생각하지 마십시오. 빚진 것은 항상 갚아야 합니다. 여기 더 추천하기 어려운 책인 "컴퓨팅 시스템의 심층 이해"가 있습니다.
2. 순수 메모리 액세스
Redis는 모든 데이터를 저장하기 위해 메모리를 사용하므로 정상 작동 중에 데이터 이외의 동기화를 위해 디스크에서 데이터를 읽을 필요가 없으므로 IO 수가 0입니다. 메모리 응답 시간은 약 100나노초로, 이는 Redis의 빠른 속도를 위한 중요한 기반입니다. 먼저 CPU 속도를 살펴보겠습니다.
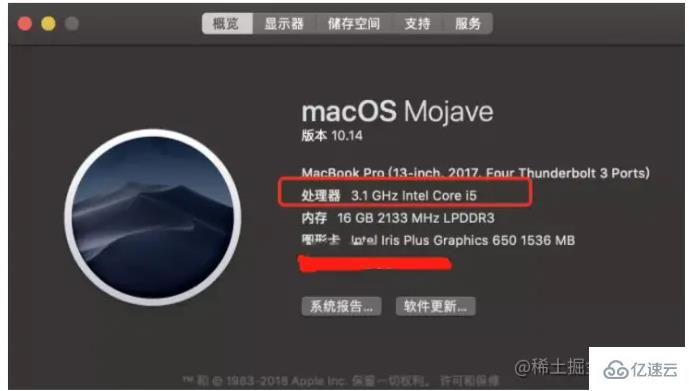
내 컴퓨터를 예로 들어보겠습니다. 주요 주파수는 3.1G이며 이는 초당 31억 개의 명령을 실행할 수 있음을 의미합니다. CPU의 세계관 처리 속도는 그에 비해 메모리는 100배, 디스크는 1,000,000배 느리다고 생각하시나요?
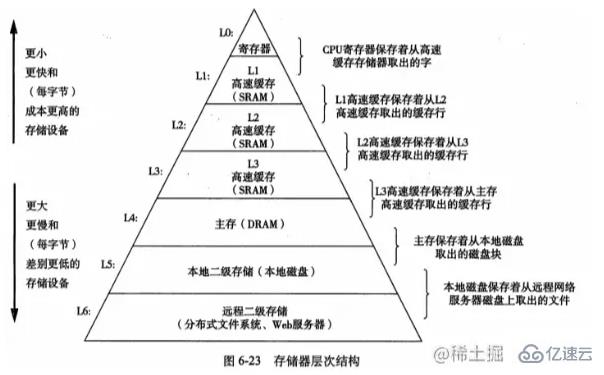
일반적인 메모리 계층 구조를 보여주는 "컴퓨터 시스템 심층 이해"에서 그림을 빌렸습니다. L0 계층에서는 CPU가 한 클럭 주기로 액세스할 수 있으며 SRAM 기반 캐시는 여러 액세스에서 갱신될 수 있습니다. CPU 클럭 사이클, 그리고 DRAM 기반 메인 메모리에서는 수십에서 수백 클럭 사이클에 액세스할 수 있습니다.
3. 단일 스레드
단일 스레드는 알고리즘 구현을 단순화할 수 있지만 동시 데이터 구조 구현은 어려울 뿐만 아니라 테스트하기에도 번거롭습니다. 서버 측 개발에서 잠금 및 스레드 전환은 일반적으로 성능을 저하시키며 단일 스레드를 사용하면 이로 인해 발생하는 소비를 피할 수 있습니다. 물론 단일 스레딩에도 단점이 있습니다. 이는 Redis의 악몽이기도 합니다. 바로 차단입니다. 명령 실행 시간이 너무 길면 다른 명령이 차단될 수 있으며 이는 Redis에 매우 치명적이므로 Redis는 빠른 실행 시나리오를 위한 데이터베이스입니다.
Redis 외에 Node.js도 싱글 쓰레드이고, Nginx도 싱글 쓰레드인데 둘 다 고성능 서버의 모델입니다.
4. 비차단 다중 채널 I/O 다중화 메커니즘
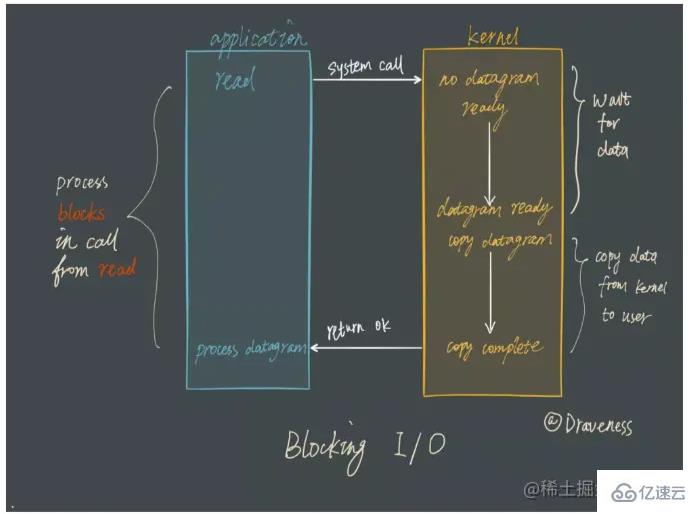
그 전에 전통적인 차단 I/O 작동 방식에 대해 이야기해 보겠습니다. 특정 파일 설명자(파일 설명자) FD에 대한 읽기 또는 쓰기를 사용할 때 읽기 및 쓰기 중 데이터가 수신되지 않으면 데이터가 수신될 때까지 스레드가 일시 중단됩니다.
차단 모델은 이해하기 쉽지만 여러 클라이언트 작업을 처리해야 하는 경우에는 사용되지 않습니다.
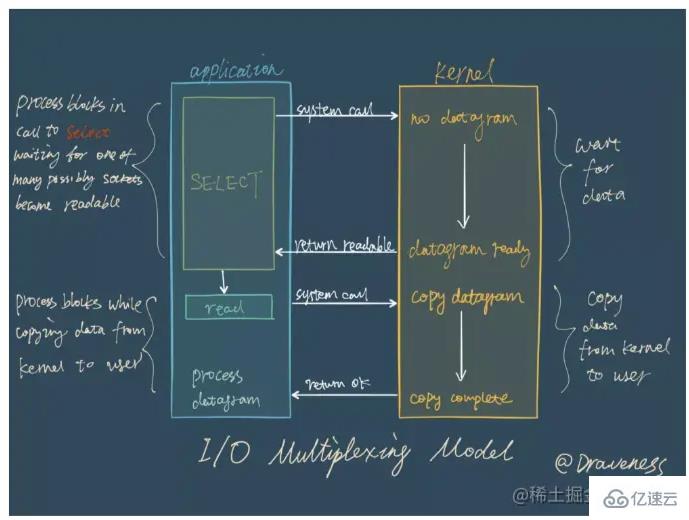
I/O 멀티플렉싱은 실제로 여러 연결 관리가 동일한 프로세스에 있을 수 있음을 의미합니다. 다중 채널은 네트워크 연결을 의미하며 다중화는 동일한 스레드입니다. 네트워크 서비스에서 I/O 다중화의 역할은 여러 연결 이벤트를 비즈니스 코드에 동시에 알리는 것입니다. 처리 방법은 비즈니스 코드에 따라 결정됩니다.
I/O 다중화 모델에서 가장 중요한 함수 호출은 I/O 다중화 함수입니다. 이 방법은 여러 파일 설명자(fd) 중 하나가 fd일 때 동시에 읽고 쓰는 것을 모니터링할 수 있습니다. 읽기/쓰기가 가능한 경우, 이 메소드는 읽기/쓰기 가능한 fd 수를 반환합니다.
Redis는 I/O 다중화 기술의 구현으로 epoll을 사용하며, Redis 자체 이벤트 처리 모델은 epoll의 읽기, 쓰기, 닫기 등을 이벤트로 변환하므로 네트워크 I/O에 낭비가 없습니다. 시간이 너무 많습니다 . 다중 FD 읽기 및 쓰기 모니터링을 실현하여 성능을 향상시킵니다.
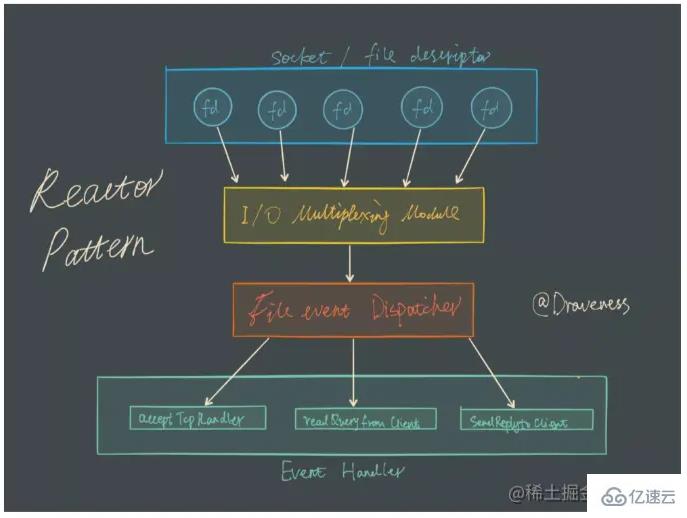
생생한 예를 들어보겠습니다. 예를 들어, TCP 서버는 20개의 클라이언트 소켓을 처리합니다.
계획: 순차 처리. 네트워크 카드로 인해 첫 번째 소켓의 데이터 읽기 속도가 느려지면 차단된 후 모든 것이 엉망이 됩니다.
계획 B: 각 소켓 요청을 처리하기 위한 복제 하위 프로세스를 만듭니다. 각 프로세스가 많은 시스템 리소스를 소비하고 프로세스 전환만으로도 운영 체제가 지치게 될 수 있다는 점은 말할 것도 없습니다.
C 방식(I/O 다중화 모델, epoll): 사용자 소켓에 해당하는 fd를 epoll에 등록합니다(실제로 서버와 운영 체제 간에 전달되는 것은 소켓의 fd가 아니라 fd_set의 데이터 구조입니다). 그런 다음 epoll은 읽기/쓰기가 필요한 소켓에 대해서만 활성 및 변경 소켓 fd만 처리해야 한다고 알려줍니다.
이렇게 하면 epoll이 호출될 때만 전체 프로세스가 차단되며, 고객 메시지 송수신은 차단되지 않습니다.
위 내용은 Redis가 왜 그렇게 빠른가요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



