

Mysql은 그룹별로 구분한 후 각 그룹의 상위 몇 개를 얻기 위해 sql을 작성하는 방법을 구현합니다.

데이터를 그룹화한 다음 각 그룹의 처음 10개 데이터를 가져와야 하는 시나리오에 직면했습니다. 처음에는 그룹별을 사용하려고 했지만 어떤 데이터가 순위가 매겨졌는지 아는 방법이 어려웠습니다. 그룹화 후 그룹에.
1. 테이블을 생성하고 관련 테스트 데이터를 삽입하세요
CREATE TABLE `score` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `subject` varchar(20) DEFAULT NULL COMMENT '科目', `student_id` int(11) DEFAULT NULL COMMENT '学生id', `student_name` varchar(20) NOT NULL COMMENT '学生姓名', `score` double DEFAULT NULL COMMENT '成绩', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=16 DEFAULT CHARSET=utf8;
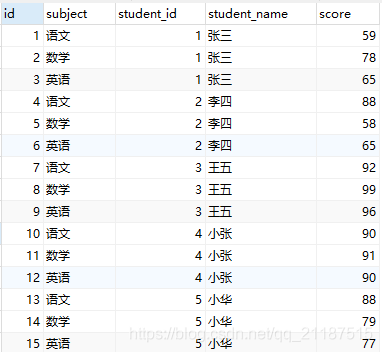
참고: 삽입된 데이터 sql은 맨 마지막에 있습니다. 다음 sql은 친구들이 직접 확인할 수 있습니다
2. 각 과목별 점수
이제 데이터가 확보되었으므로 sql을 다음과 같이 작성합니다.
###每科成绩前三名 SELECT * FROM score s1 WHERE ( SELECT count( * ) FROM score s2 WHERE s1.`subject` = s2.`subject` AND s1.score < s2.score ) < 3 ORDER BY SUBJECT, score DESC
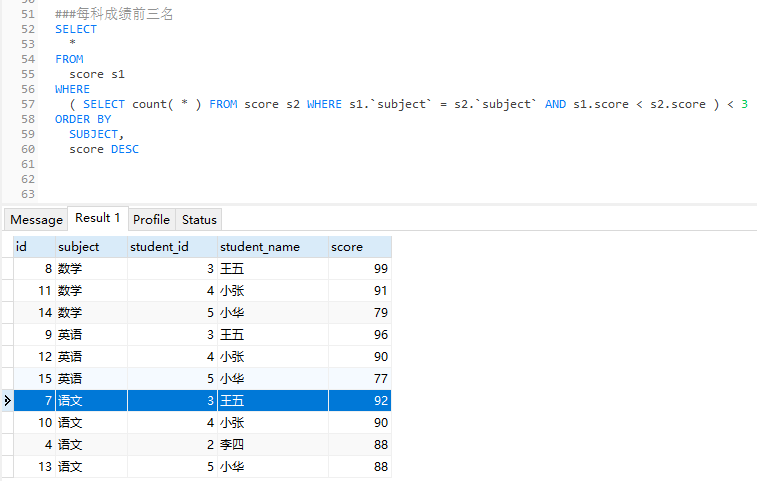
분석:
은 하위 쿼리를 사용하며 핵심 sql은 where 뒤의 조건입니다.
( SELECT count( * ) FROM score s2 WHERE s1.subject = s2.subject AND s1.score < s2.score ) < 3
의 의미 이것은 SQL입니다. . .
제 언어가 좀 설명하기 어려운 것 같아서 제가 익숙한 Java 코드를 사용하여 위의 SQL을 설명하겠습니다. 아마도 두 번 순회하는 for 루프이고 두 번째 for 루프에서는 학생입니다. 같은 과목의 기록이 s1보다 높은 수치입니다. 이 숫자가 3보다 작으면 s1이 상위 3위 안에 든다는 의미입니다.
public class StudentTest {
public static void main(String[] args) {
List<Student> list = new ArrayList<>();
//初始化和表结构一致的数据
initData(list);
//记录查询出来的结果
List<Student> result = new ArrayList<>();
for(Student s1 : list){
int num = 0;
//两次for循环遍历,相当于sql里面的子查询
for(Student s2:list){
//统计同一科目,且分数s2分数大于s1的数量,简单理解就是同一科目的学生记录,比s1的学生分数高的数量
if(s1.getSubject().equals(s2.getSubject())
&&s1.getScore()<s2.getScore()){
num++;
}
}
//比s1的学生分数高的数量,如果小于3的话,说明s1这个排名前三
// 举例:num=0时,说明同一科目,没有一个学生成绩高于s1学生, s1学生的这科成绩排名第一
// num =1,时,s1学生排名第二,num=3时:说明排名同一科目有三个学生成绩高过s1,s1排第四,所以只统计前三的学生,条件就是num<3
if(num < 3){
result.add(s1);
}
}
//输出各科成绩前三的记录
result.stream()
.sorted(Comparator.comparing(Student::getSubject))
.forEach(
s-> System.out.println(String.format("学生:%s,科目:%s,成绩:%s",s.getName(),s.getSubject(),s.getScore()))
);
}
public static void initData(List<Student> list) {
list.add(new Student(1,"语文","张三",59));
list.add(new Student(2,"数学","张三",78));
list.add(new Student(3,"英语","张三",65));
list.add(new Student(4,"语文","李四",88));
list.add(new Student(5,"数学","李四",58));
list.add(new Student(6,"英语","李四",65));
list.add(new Student(7,"语文","王五",92));
list.add(new Student(8,"数学","王五",99));
list.add(new Student(9,"英语","王五",96));
list.add(new Student(10,"语文","小张",90));
list.add(new Student(11,"数学","小张",91));
list.add(new Student(12,"英语","小张",90));
list.add(new Student(13,"语文","小华",88));
list.add(new Student(14,"数学","小华",79));
list.add(new Student(15,"英语","小华",77));
}
@Data
public static class Student {
private int id;
private String subject;
private String name;
private double score;
//想当于表结构
public Student(int id, String subject, String name, double score) {
this.id = id;
this.subject = subject;
this.name = name;
this.score = score;
}
}코드를 실행한 후 출력된 결과가 sql
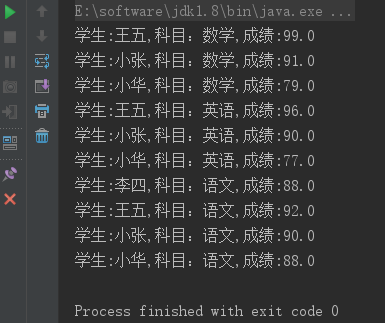 을 실행한 결과와 동일한 것을 확인할 수 있습니다.
을 실행한 결과와 동일한 것을 확인할 수 있습니다.
3. 과목별 점수가 90점 이상인 학생의 기록을 조회해 보세요
테이블과 데이터는 모두 있습니다. 그런데 이 유형의 SQL 질문도 요약합니다
예를 들어, 제목은 점수가 90점 이상인 모든 과목에 대해 위 테이블을 쿼리하는 것입니다. , SQL을 작성하는 방법은 무엇입니까?
1. 첫 번째 글쓰기 방법: 미래 지향적
각 과목의 점수가 90점보다 크면 가장 낮은 점수도 90점 이상이어야 합니다. SQL은 다음과 같습니다.
SELECT * FROM score WHERE student_id IN (SELECT student_id FROM score GROUP BY student_id HAVING min( score ) >= 90 )
2. 두 번째 글쓰기 방법: 거꾸로 생각하기
최고 점수가 90점 미만인 기록은 제외
SELECT * FROM score WHERE student_id NOT IN (SELECT student_id FROM score GROUP BY student_id HAVING max( score ) < 90 )
참고: 정방향 및 역방향 선택은 상황에 따라 다릅니다
기타 서술
기록 확인 과목별 평균 점수가 80점 이상인 학생의 비율
###查询学生各科平均分大于80分的记录
select * from score where student_id in(
select student_id from score GROUP BY student_id HAVING avg(score)>80
)Query one 과목별 학생의 낙제 점수 기록
###查询一个学生每科分数不及格的记录 SELECT * FROM score WHERE student_id IN ( SELECT student_id FROM score GROUP BY student_id HAVING max( score ) < 60 )
첨부: 테이블 구조에 SQL 삽입
CREATE TABLE `score` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `subject` varchar(20) DEFAULT NULL COMMENT '科目', `student_id` int(11) DEFAULT NULL COMMENT '学生id', `student_name` varchar(20) NOT NULL COMMENT '学生姓名', `score` double DEFAULT NULL COMMENT '成绩', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=16 DEFAULT CHARSET=utf8; INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (1, '语文', 1, '张三', 59); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (2, '数学', 1, '张三', 78); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (3, '英语', 1, '张三', 65); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (4, '语文', 2, '李四', 88); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (5, '数学', 2, '李四', 58); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (6, '英语', 2, '李四', 65); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (7, '语文', 3, '王五', 92); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (8, '数学', 3, '王五', 99); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (9, '英语', 3, '王五', 96); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (10, '语文', 4, '小张', 90); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (11, '数学', 4, '小张', 91); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (12, '英语', 4, '小张', 90); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (13, '语文', 5, '小华', 88); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (14, '数学', 5, '小华', 79); INSERT INTO `test`.`score`(`id`, `subject`, `student_id`, `student_name`, `score`) VALUES (15, '英语', 5, '小华', 77);
위 내용은 Mysql은 그룹별로 구분한 후 각 그룹의 상위 몇 개를 얻기 위해 sql을 작성하는 방법을 구현합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 LARAVEL 소개 예
Apr 18, 2025 pm 12:45 PM
LARAVEL 소개 예
Apr 18, 2025 pm 12:45 PM
Laravel은 웹 응용 프로그램을 쉽게 구축하기위한 PHP 프레임 워크입니다. 설치 : Composer를 사용하여 전 세계적으로 Laravel CLI를 설치하고 프로젝트 디렉토리에서 응용 프로그램을 작성하는 등 다양한 기능을 제공합니다. 라우팅 : Routes/Web.php에서 URL과 핸들러 간의 관계를 정의하십시오. 보기 : 리소스/뷰에서보기를 작성하여 응용 프로그램의 인터페이스를 렌더링합니다. 데이터베이스 통합 : MySQL과 같은 데이터베이스와 상자 외 통합을 제공하고 마이그레이션을 사용하여 테이블을 작성하고 수정합니다. 모델 및 컨트롤러 : 모델은 데이터베이스 엔티티를 나타내고 컨트롤러는 HTTP 요청을 처리합니다.
 MySQL 및 Phpmyadmin : 핵심 기능 및 기능
Apr 22, 2025 am 12:12 AM
MySQL 및 Phpmyadmin : 핵심 기능 및 기능
Apr 22, 2025 am 12:12 AM
MySQL 및 Phpmyadmin은 강력한 데이터베이스 관리 도구입니다. 1) MySQL은 데이터베이스 및 테이블을 작성하고 DML 및 SQL 쿼리를 실행하는 데 사용됩니다. 2) PHPMYADMIN은 데이터베이스 관리, 테이블 구조 관리, 데이터 운영 및 사용자 권한 관리에 직관적 인 인터페이스를 제공합니다.
 MySQL 대 기타 프로그래밍 언어 : 비교
Apr 19, 2025 am 12:22 AM
MySQL 대 기타 프로그래밍 언어 : 비교
Apr 19, 2025 am 12:22 AM
다른 프로그래밍 언어와 비교할 때 MySQL은 주로 데이터를 저장하고 관리하는 데 사용되는 반면 Python, Java 및 C와 같은 다른 언어는 논리적 처리 및 응용 프로그램 개발에 사용됩니다. MySQL은 데이터 관리 요구에 적합한 고성능, 확장 성 및 크로스 플랫폼 지원으로 유명하며 다른 언어는 데이터 분석, 엔터프라이즈 애플리케이션 및 시스템 프로그래밍과 같은 해당 분야에서 이점이 있습니다.
 데이터베이스 연결 문제 해결 : Minii/DB 라이브러리 사용 실질적인 사례
Apr 18, 2025 am 07:09 AM
데이터베이스 연결 문제 해결 : Minii/DB 라이브러리 사용 실질적인 사례
Apr 18, 2025 am 07:09 AM
작은 응용 프로그램을 개발할 때 까다로운 문제가 발생했습니다. 가벼운 데이터베이스 운영 라이브러리를 신속하게 통합해야합니다. 여러 라이브러리를 시도한 후에는 기능이 너무 많거나 호환되지 않는다는 것을 알았습니다. 결국, 나는 내 문제를 완벽하게 해결하는 YII2를 기반으로 단순화 된 버전 인 Minii/DB를 발견했습니다.
 Laravel 프레임 워크 설치 방법
Apr 18, 2025 pm 12:54 PM
Laravel 프레임 워크 설치 방법
Apr 18, 2025 pm 12:54 PM
기사 요약 :이 기사는 Laravel 프레임 워크를 쉽게 설치하는 방법에 대한 독자들을 안내하기위한 자세한 단계별 지침을 제공합니다. Laravel은 웹 애플리케이션의 개발 프로세스를 가속화하는 강력한 PHP 프레임 워크입니다. 이 자습서는 시스템 요구 사항에서 데이터베이스 구성 및 라우팅 설정에 이르기까지 설치 프로세스를 다룹니다. 이러한 단계를 수행함으로써 독자들은 라벨 프로젝트를위한 탄탄한 토대를 빠르고 효율적으로 놓을 수 있습니다.
 MySQL 모드 해결 문제 : theliamysqlmodeschecker 모듈 사용 경험
Apr 18, 2025 am 08:42 AM
MySQL 모드 해결 문제 : theliamysqlmodeschecker 모듈 사용 경험
Apr 18, 2025 am 08:42 AM
Thelia를 사용하여 전자 상거래 웹 사이트를 개발할 때 까다로운 문제가 발생했습니다. MySQL 모드가 제대로 설정되지 않아 일부 기능이 제대로 작동하지 않습니다. 약간의 탐색 후, 나는 theliamysqlmodeschecker라는 모듈을 발견했습니다.이 모듈은 Thelia가 요구하는 MySQL 패턴을 자동으로 수정하여 내 문제를 완전히 해결할 수 있습니다.
 MySQL : 구조화 된 데이터 및 관계형 데이터베이스
Apr 18, 2025 am 12:22 AM
MySQL : 구조화 된 데이터 및 관계형 데이터베이스
Apr 18, 2025 am 12:22 AM
MySQL은 테이블 구조 및 SQL 쿼리를 통해 구조화 된 데이터를 효율적으로 관리하고 외래 키를 통해 테이블 간 관계를 구현합니다. 1. 테이블을 만들 때 데이터 형식을 정의하고 입력하십시오. 2. 외래 키를 사용하여 테이블 간의 관계를 설정하십시오. 3. 인덱싱 및 쿼리 최적화를 통해 성능을 향상시킵니다. 4. 데이터 보안 및 성능 최적화를 보장하기 위해 데이터베이스를 정기적으로 백업 및 모니터링합니다.
 MySQL : 주요 기능 및 기능이 설명되었습니다
Apr 18, 2025 am 12:17 AM
MySQL : 주요 기능 및 기능이 설명되었습니다
Apr 18, 2025 am 12:17 AM
MySQL은 웹 개발에 널리 사용되는 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 주요 기능에는 다음이 포함됩니다. 1. 다른 시나리오에 적합한 InnoDB 및 MyISAM과 같은 여러 스토리지 엔진을 지원합니다. 2.로드 밸런싱 및 데이터 백업을 용이하게하기 위해 마스터 슬레이브 복제 기능을 제공합니다. 3. 쿼리 최적화 및 색인 사용을 통해 쿼리 효율성을 향상시킵니다.
