

MYSQL 함수 사용예 분석

MYSQL 함수
1: 집계 함수
집계 함수에는 주로 count, sum, min, max, avg, group_count()가 포함됩니다.
group_count() 함수에 중점을 둡니다. 먼저 group에서 지정한 열에 따라 그룹화합니다. , 구분 기호로 구분하여 동일한 그룹의 값을 연결하고 문자열 결과를 반환합니다.
형식: group_count([distinct] 필드 이름 [정렬 필드 asc/desc] [separator 'separator'])
지침:
1: 구별을 사용하여 중복 값을 제외합니다.
2: 결과 값을 정렬해야 하는 경우 order by 절을 사용할 수 있습니다.
3: 구분 기호는 문자열 값이며 기본값은 쉼표입니다.
2: 수학 함수
1:ABS(x)는 x의 절대값을 반환합니다.
2:CEIL(x)는 x보다 크거나 같은 가장 작은 정수를 반환합니다(반올림)
3:FLOOR(x) x 정수(내림)보다 작거나 같은 가장 큰 값을 반환합니다.
4:GREATEST(expr1,expr2...)는 목록의 최대값을 반환합니다.
5:LEAST(expr1,expr2....)는 최소값을 반환합니다. value of the list
6:MAX(x ) 필드 x
7:MIN(x) 필드의 최소값을 반환합니다. x
8:MOD(x,y) x를 y
로 나눈 나머지를 반환합니다. 9:PI()는 pi (3.141593)를 반환합니다
10 :POW(x,y) x를 y의 거듭제곱으로 반환합니다.
11:RAND() 0에서 1까지의 난수를 반환합니다.
12:ROUND(x) x에 가장 가까운 정수(반올림 후)
13:ROUND(x, y) 지정된 소수 자릿수를 반환합니다(반올림 후)
14: TRUNCATE(x,y) 소수점 이하 y 자리로 유지된 x 값을 반환합니다. , (ROUND와의 가장 큰 차이점은 반올림되지 않는다는 점입니다.)
2 :String 함수
3: 날짜 함수1:char_length(s) 문자열의 문자 수를 반환합니다. s
16:lcase(s) lower(s) 문자열을 소문자로 변환
2:character_length 문자열의 문자 수를 반환합니다. s
3:concat(s1,s2,s3) 문자열 s1, s2 등 문자열은 하나의 문자열로 병합됩니다
4:concat_ws(x,s1,s2..)는 concat(s1,s2,s3)과 동일합니다. 함수이지만 x는 각 문자열 사이에 추가되므로 x는 구분 기호가 될 수 있습니다
5 :field(s,s1,s2)는 문자열 목록에서 첫 번째 문자열 s의 위치를 반환합니다(s1,s2..)
6:length( )는 mysql에서 utf-8로 인코딩된 바이트 수를 반환합니다. 한자는 3바이트입니다.
7:ltrim(s) 문자열 s의 시작 부분에서 공백을 제거하고 왼쪽에서 공백을 제거합니다. rtrim() 문자열의 공백을 제거합니다. right Trim() 양쪽의 공백을 제거합니다
8:mid(s,n,len) 문자열 s의 위치 n에서 길이가 len인 하위 문자열을 가로채는 것은 하위 문자열(s,n,len)과 같습니다
9:position( s1,in,s) 문자열 s
10:replcae에서 s1의 시작 위치를 가져옵니다. (s,s1,s2) 문자열 s
11:reverse(s) 문자열 s
10에서 문자열 s2를 문자열 s1로 바꿉니다. 문자열 s
12의 순서를 반대로 바꿉니다. :right(s,n) 문자열 s n 문자의 끝을 반환합니다 (오른쪽에서 n 문자 가져옴)
13:strcmp(s1,s2) 문자열 s1과 s2를 비교하여 s1과 s2가 같으면 0을 반환하고 s1>이면 0을 반환합니다. ;s2 1을 반환하고, s1이 s2보다 작으면 -1을 반환합니다
14 :substr(s,start,length)는 문자열 s
15:ucase(s) upper(s)의 시작 위치에서 length 길이의 하위 문자열을 가로챕니다. 문자열을 대문자로 변환
4의 요구 사항에 따라 날짜 d를 표시합니다. 흐름 제어 함수9:date_format(d,f) 표현식 f
1: unix_timestamp() 1970-01-01 00:00:00을 현재로 반환 밀리초 값
2: unix_timestamp(date_string) 지정된 날짜를 밀리초 값으로 변환 timestamp
3:from_unixtime(bigint unixtime,string-format) 밀리초 값 타임스탬프를 지정된 형식으로 변환 date
4:curdate() 현재 날짜 반환
5: current_date() 현재 날짜를 반환합니다
6:current_timestamp() 현재 날짜와 시간을 반환합니다
7:datediff(d1,d2) d1>d2 날짜 사이의 일 수를 계산합니다. 예:datediff('2022-01-01', '2022-02-01')
8:currtime() 현재 시간을 반환합니다.
5: 윈도우 함수 mysql8.0의 새로운 윈도우 함수는 윈도우 함수라고도 하며, 집계가 아닌 윈도우 함수는 집계 함수에 상대적입니다. 데이터 집합을 계산한 후 단일 값(예: 그룹화)을 반환합니다. 비집계 함수는 한 번에 하나의 데이터 행만 처리합니다. 창 집계 함수는 필드 결과를 얻을 때 특정 값을 계산합니다. 행 수를 변경하지 않고 창 범위 내의 데이터를 집계 함수에 입력할 수 있습니다5.1 일련 번호 함수는 그룹화 정렬을 구현하고 일련 번호를 추가할 수 있습니다5:case 표현식을 반환하고, 조건이 1이면 result1을 반환합니다. 조건2, 결과2 그렇지 않으면 결과 end는 케이스 함수의 시작을 나타내고, 끝은 함수의 끝을 나타냅니다. 조건1이 true이면 결과1을 반환하고, 조건2가 성립하면 결과2가 반환됩니다. 그 중 하나가 성립되면 다음은 실행되지 않습니다.
1: if(expr,v1,v2) 표현식 expr이 true이면 결과 v1을 반환하고, 그렇지 않으면 결과 v2
2를 반환합니다. ifnull(v1,v2) v1의 값이 null이면 v1을 반환하고, 그렇지 않으면 v2
3을 반환합니다. :isnull(expression) 표현식이 null인지 확인
4:nullif(expr1,expr2) 두 문자열을 비교합니다. 문자열 expr1과 expr2가 같으면 null을 반환하고, 조건이 1이면 expr1
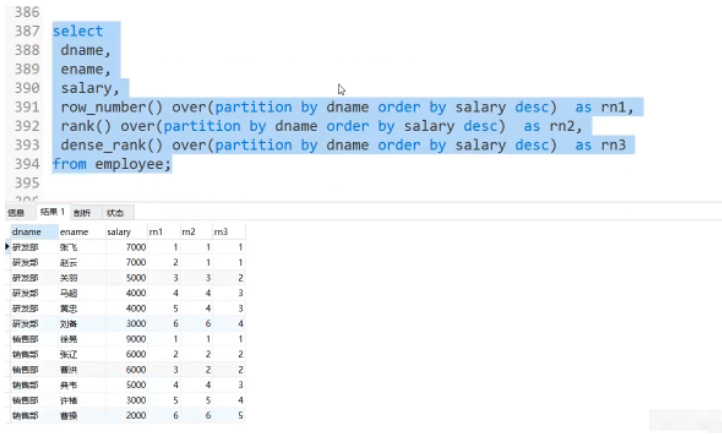
3: dark_rank()
1: row_number()
2: 순위()
Writing: select id,...,dense_rank() over(partition by dname order by Salary desc) as rn from Employees;참고: 전역을 나타내기 위해 partition by를 추가하지 마세요. 정렬🎜
5.2 분포 함수
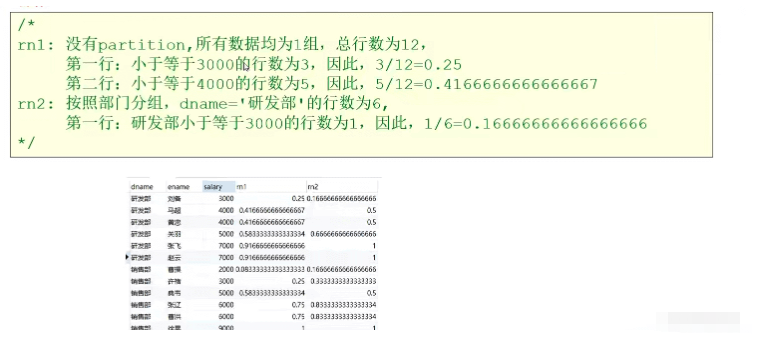
1: percent_rank()
用途:每行按照公式(rank-1)/(row-1)进行计算.其中rank为rank()函数产生的序号,row为当前窗口的记录总行数
2: cume_dist()
목적: 현재 순위 값보다 작거나 같은 그룹의 행 수/그룹의 전체 행 수
응용 시나리오: 비율 쿼리 현재 급여보다 작거나 같은 급여
쓰기: select dname, ename,salary,cume_dist() over(연봉순) as rn1,
cume_dist() over(dname별 order by 급여) as rn2 from Employee;
5.3 함수 전후
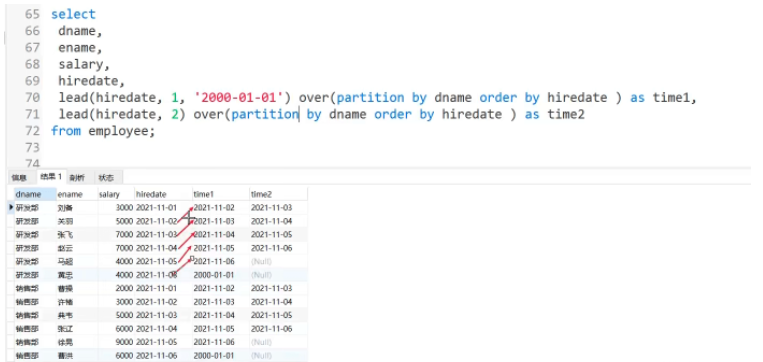
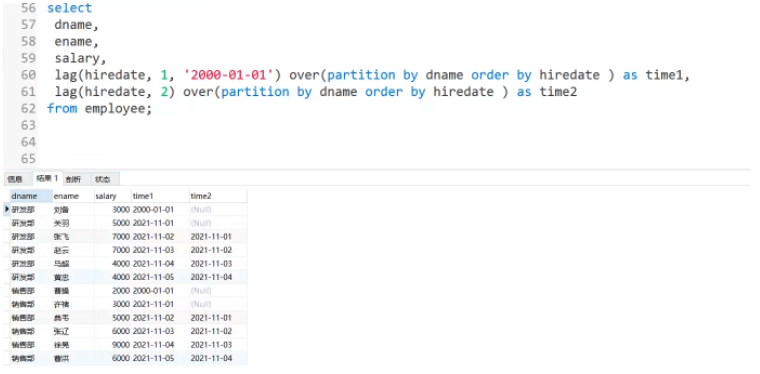
1: lag( expr,n)
2: Lead(expr,n)
목적: n 라인 앞에 위치한 expr 값을 반환합니다. (exor,n)) 또는 현재 줄의 (lead(expr,n)) 뒤의 n 줄
응용 시나리오: 상위 1명의 학생 점수와 현재 동급생의 점수 간의 차이를 쿼리합니다(현재 행은 이전 데이터 행의 특정 필드 값을 가짐)
5.4 머리 및 꼬리 함수
1 : first_value(expr)
2: last_value(expr)
목적: 값을 반환합니다. 첫 번째(first_value(expr)) 또는 마지막(last_value(expr)) expr
응용 시나리오: 지금은 날짜순으로 정렬 첫 번째와 마지막 직원의 급여 쿼리
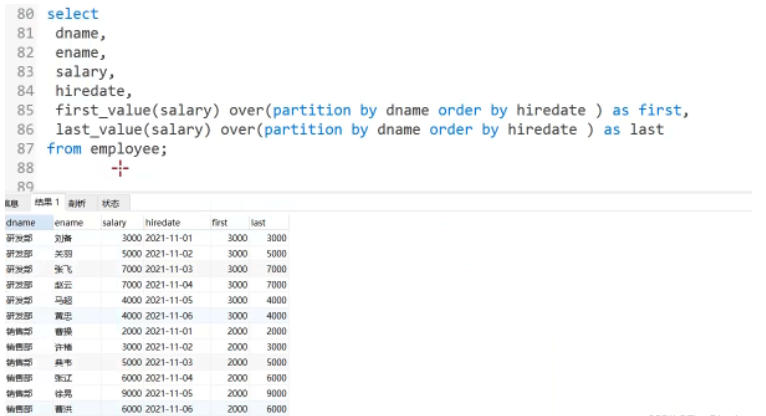
5.5 기타 기능
1: nth_value(expr,n)
2: ntile(n)
목적: 창에 n번째 expr을 반환합니다. expr의 값은 표현식 또는 열 이름일 수 있습니다.
응용 시나리오: 현재 급여를 기준으로 두 번째를 표시합니다. 또는 각 직원의 세 번째 급여
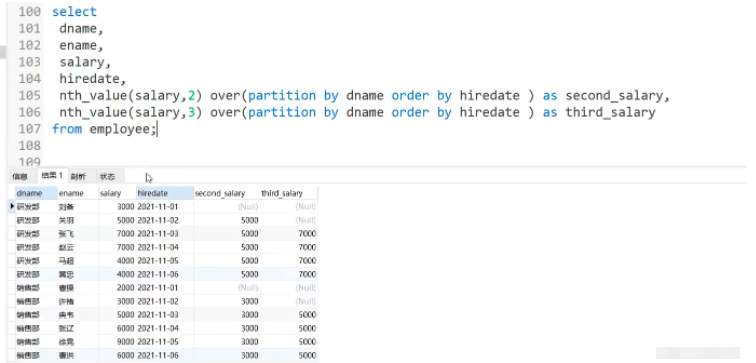
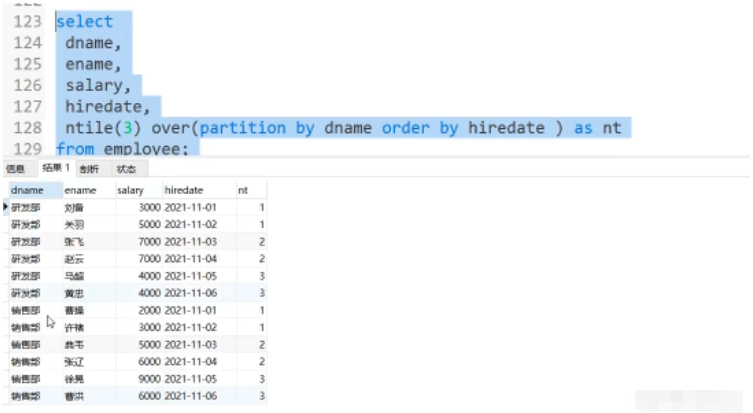
5.6 창 집계 함수
1: sum()
2: avg()
3: min()
4: max()
쓰기: select id,...,sum(salary) over(partition by dname order by Hiedate desc) as rn from Employee;
rn의 각 행의 데이터는 현재 행과 각 이전 행의 급여의 합입니다.
정렬문에 의한 순서가 없으면 기본적으로 그룹 내 모든 데이터가 합산됩니다
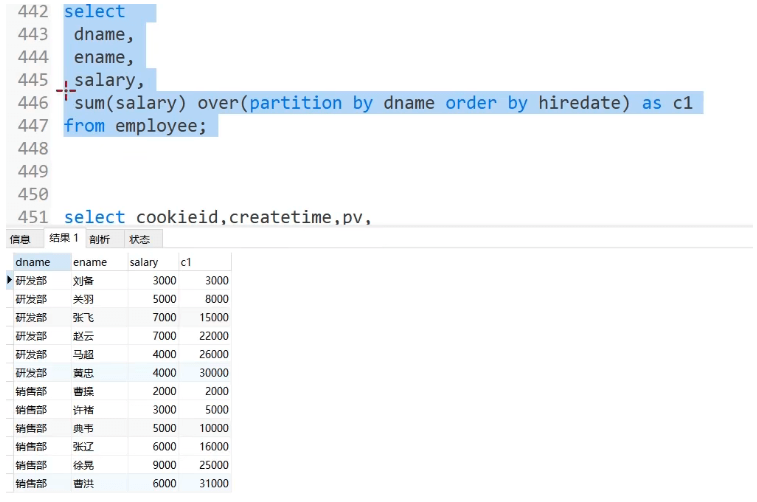
위 내용은 MYSQL 함수 사용예 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7557
7557
 15
1384
52
83
11
59
19
28
96
15
1384
52
83
11
59
19
28
96

 MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) 데이터베이스 및 테이블 작성 : CreateAbase 및 CreateTable 명령을 사용하십시오. 2) 기본 작업 : 삽입, 업데이트, 삭제 및 선택. 3) 고급 운영 : 가입, 하위 쿼리 및 거래 처리. 4) 디버깅 기술 : 확인, 데이터 유형 및 권한을 확인하십시오. 5) 최적화 제안 : 인덱스 사용, 선택을 피하고 거래를 사용하십시오.
 phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
다음 단계를 통해 phpmyadmin을 열 수 있습니다. 1. 웹 사이트 제어판에 로그인; 2. phpmyadmin 아이콘을 찾고 클릭하십시오. 3. MySQL 자격 증명을 입력하십시오. 4. "로그인"을 클릭하십시오.
 MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템으로, 주로 데이터를 신속하고 안정적으로 저장하고 검색하는 데 사용됩니다. 작업 원칙에는 클라이언트 요청, 쿼리 해상도, 쿼리 실행 및 반환 결과가 포함됩니다. 사용의 예로는 테이블 작성, 데이터 삽입 및 쿼리 및 조인 작업과 같은 고급 기능이 포함됩니다. 일반적인 오류에는 SQL 구문, 데이터 유형 및 권한이 포함되며 최적화 제안에는 인덱스 사용, 최적화 된 쿼리 및 테이블 분할이 포함됩니다.
 MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL은 성능, 신뢰성, 사용 편의성 및 커뮤니티 지원을 위해 선택됩니다. 1.MYSQL은 효율적인 데이터 저장 및 검색 기능을 제공하여 여러 데이터 유형 및 고급 쿼리 작업을 지원합니다. 2. 고객-서버 아키텍처 및 다중 스토리지 엔진을 채택하여 트랜잭션 및 쿼리 최적화를 지원합니다. 3. 사용하기 쉽고 다양한 운영 체제 및 프로그래밍 언어를 지원합니다. 4. 강력한 지역 사회 지원을 받고 풍부한 자원과 솔루션을 제공합니다.
 단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
Redis는 단일 스레드 아키텍처를 사용하여 고성능, 단순성 및 일관성을 제공합니다. 동시성을 향상시키기 위해 I/O 멀티플렉싱, 이벤트 루프, 비 블로킹 I/O 및 공유 메모리를 사용하지만 동시성 제한 제한, 단일 고장 지점 및 쓰기 집약적 인 워크로드에 부적합한 제한이 있습니다.
 MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL은 개발자에게 필수적인 기술입니다. 1.MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템이며 SQL은 데이터베이스를 관리하고 작동하는 데 사용되는 표준 언어입니다. 2.MYSQL은 효율적인 데이터 저장 및 검색 기능을 통해 여러 스토리지 엔진을 지원하며 SQL은 간단한 문을 통해 복잡한 데이터 작업을 완료합니다. 3. 사용의 예에는 기본 쿼리 및 조건 별 필터링 및 정렬과 같은 고급 쿼리가 포함됩니다. 4. 일반적인 오류에는 구문 오류 및 성능 문제가 포함되며 SQL 문을 확인하고 설명 명령을 사용하여 최적화 할 수 있습니다. 5. 성능 최적화 기술에는 인덱스 사용, 전체 테이블 스캔 피하기, 조인 작업 최적화 및 코드 가독성 향상이 포함됩니다.
 MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
데이터베이스 및 프로그래밍에서 MySQL의 위치는 매우 중요합니다. 다양한 응용 프로그램 시나리오에서 널리 사용되는 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) MySQL은 웹, 모바일 및 엔터프라이즈 레벨 시스템을 지원하는 효율적인 데이터 저장, 조직 및 검색 기능을 제공합니다. 2) 클라이언트 서버 아키텍처를 사용하고 여러 스토리지 엔진 및 인덱스 최적화를 지원합니다. 3) 기본 사용에는 테이블 작성 및 데이터 삽입이 포함되며 고급 사용에는 다중 테이블 조인 및 복잡한 쿼리가 포함됩니다. 4) SQL 구문 오류 및 성능 문제와 같은 자주 묻는 질문은 설명 명령 및 느린 쿼리 로그를 통해 디버깅 할 수 있습니다. 5) 성능 최적화 방법에는 인덱스의 합리적인 사용, 최적화 된 쿼리 및 캐시 사용이 포함됩니다. 모범 사례에는 거래 사용 및 준비된 체계가 포함됩니다
 SQL 데이터베이스를 구축하는 방법
Apr 09, 2025 pm 04:24 PM
SQL 데이터베이스를 구축하는 방법
Apr 09, 2025 pm 04:24 PM
SQL 데이터베이스 구축에는 10 단계가 필요합니다. DBMS 선택; DBMS 설치; 데이터베이스 생성; 테이블 만들기; 데이터 삽입; 데이터 검색; 데이터 업데이트; 데이터 삭제; 사용자 관리; 데이터베이스 백업.
