

MySQL에서 SELECT *를 사용하지 않는 것이 왜 권장되지 않습니까?

"SELECT *를 사용하지 마십시오"는 MySQL의 황금률이 되었습니다. 심지어 "Alibaba Java 개발 매뉴얼"에도 *를 사용할 수 없다고 명시되어 있습니다. 이 규칙에 권한을 부여하는 쿼리 필드 목록입니다. SELECT *”几乎已经成为了MySQL使用的一条金科玉律,就连《阿里Java开发手册》也明确表示不得使用*作为查询的字段列表,更是让这条规则拥有了权威的加持。

不过我在开发过程中直接使用SELECT *还是比较多的,原因有两个:
因为简单,开发效率非常高,而且如果后期频繁添加或修改字段,SQL语句也不需要改变;
我认为过早优化是个不好的习惯,除非在一开始就能确定你最终实际需要的字段是什么,并为之建立恰当的索引;否则,我选择遇到麻烦的时候再对SQL进行优化,当然前提是这个麻烦并不致命。
但是我们总得知道为什么不建议直接使用SELECT *,本文从4个方面给出理由。
1. 不必要的磁盘I/O
我们知道 MySQL 本质上是将用户记录存储在磁盘上,因此查询操作就是一种进行磁盘IO的行为(前提是要查询的记录没有缓存在内存中)。
查询的字段越多,说明要读取的内容也就越多,因此会增大磁盘 IO 开销。尤其是当某些字段是 TEXT、MEDIUMTEXT或者BLOB 等类型的时候,效果尤为明显。
那使用SELECT *会不会使MySQL占用更多的内存呢?
理论上不会,因为对于Server层而言,并非是在内存中存储完整的结果集之后一下子传给客户端,而是每从存储引擎获取到一行,就写到一个叫做net_buffer的内存空间中,这个内存的大小由系统变量net_buffer_length来控制,默认是16KB;当net_buffer写满之后再往本地网络栈的内存空间socket send buffer中写数据发送给客户端,发送成功(客户端读取完成)后清空net_buffer,然后继续读取下一行并写入。
也就是说,默认情况下,结果集占用的内存空间最大不过是net_buffer_length大小罢了,不会因为多几个字段就占用额外的内存空间。
2. 加重网络时延
承接上一点,虽然每次都是把socket send buffer中的数据发送给客户端,单次看来数据量不大,可架不住真的有人用*把TEXT、MEDIUMTEXT或者BLOB 类型的字段也查出来了,总数据量大了,这就直接导致网络传输的次数变多了。
如果MySQL和应用程序不在同一台机器,这种开销非常明显。即使MySQL服务器和客户端在同一台机器上,它们之间的通信仍然需要使用TCP协议,这也会增加额外的传输时间。
3. 无法使用覆盖索引
为了说明这个问题,我们需要建一个表
CREATE TABLE `user_innodb` ( `id` int NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `gender` tinyint(1) DEFAULT NULL, `phone` varchar(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `IDX_NAME_PHONE` (`name`,`phone`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
我们创建了一个存储引擎为InnoDB的表user_innodb,并设置id为主键,另外为name和phone创建了联合索引,最后向表中随机初始化了500W+条数据。
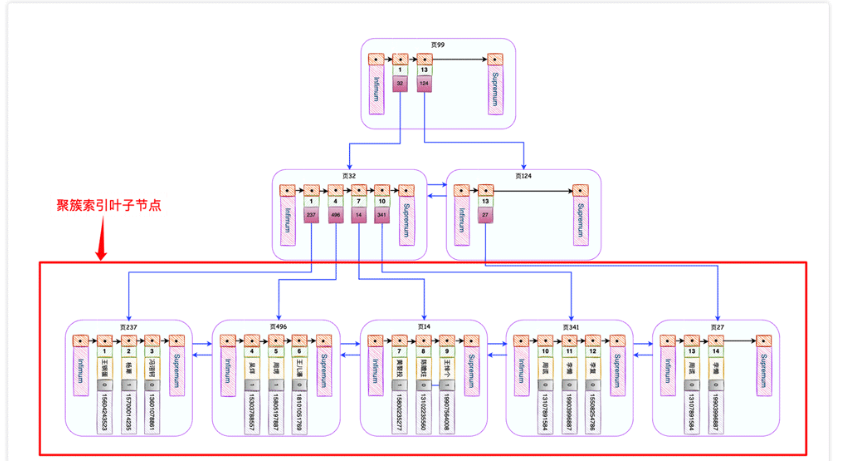
InnoDB会自动为主键id创建一棵名为主键索引(又叫做聚簇索引)的B+树,这个B+树的最重要的特点就是叶子节点包含了完整的用户记录,大概长这个样子。
如果我们执行这个语句
SELECT * FROM user_innodb WHERE name = '蝉沐风';
使用EXPLAIN查看一下语句的执行计划:

发现这个SQL语句会使用到IDX_NAME_PHONE索引,这是一个二级索引。二级索引的叶子节点长这个样子:
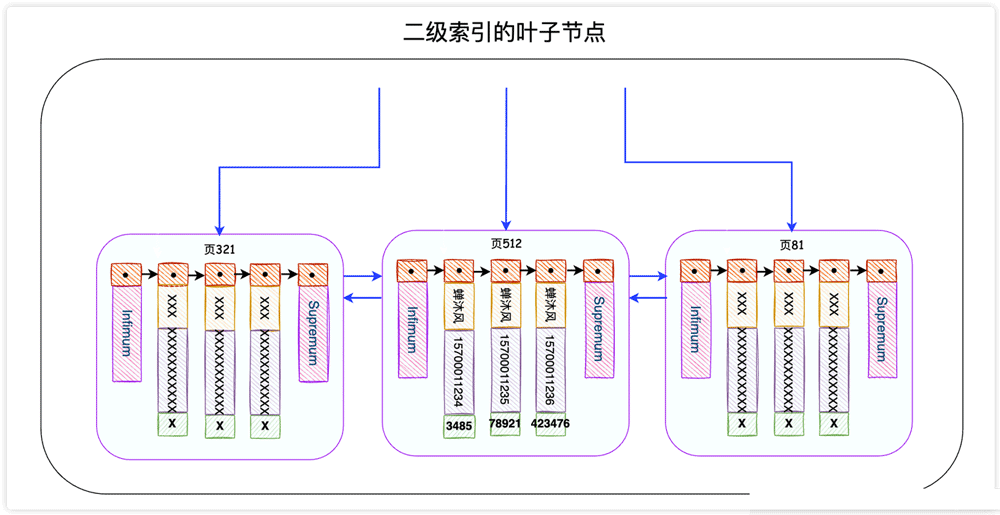
InnoDB存储引擎会根据搜索条件在该二级索引的叶子节点中找到name为蝉沐风的记录,但是二级索引中只记录了name、phone和主键id字段(谁让我们用的是SELECT *呢),因此InnoDB需要拿着主键id去主键索引中查找这一条完整的记录,这个过程叫做回表。
想一下,如果二级索引的叶子节点上有我们想要的所有数据,是不是就不需要回表了呢?是的,这就是覆盖索引。
举个例子,我们恰好只想搜索name、phone
🎜🎜 하지만 개발 과정에서 여전히 SELECT *를 직접 사용하는 이유는 두 가지입니다. 🎜- 🎜단순하기 때문에 개발 효율성이 높습니다. 매우 높으며 나중에 필드가 자주 추가되거나 수정되면 SQL 문을 변경할 필요가 없습니다. 🎜
- 🎜실제로 필요한 것이 무엇인지 판단할 수 없다면 성급한 최적화는 나쁜 습관이라고 생각합니다. 처음에는 필드가 무엇이며 이에 대한 적절한 인덱스를 생성합니다. 그렇지 않으면 문제가 치명적이지 않다면 물론 문제가 발생할 때 SQL을 최적화하기로 선택합니다. 🎜
SELECT *를 직접 사용하는 것이 권장되지 않는 이유를 알아야 합니다. 이 기사에서는 4가지 측면에서 이유를 설명합니다. 🎜1. 불필요한 디스크 I/O
🎜MySQL은 기본적으로 사용자 레코드를 디스크에 저장하므로 쿼리 작업은 디스크 IO를 수행하는 동작입니다(쿼리할 레코드가 캐시되지 않은 경우). 메모리). 🎜🎜쿼리하는 필드가 많을수록 읽어야 할 콘텐츠가 늘어나 디스크 IO 오버헤드가 늘어납니다. 특히 일부 필드가TEXT, MEDIUMTEXT 또는 BLOB 유형인 경우 그 효과는 특히 분명합니다. 🎜🎜SELECT *를 사용하면 MySQL이 더 많은 메모리를 차지하게 됩니까? 🎜🎜이론적으로는 그렇지 않습니다. 왜냐하면 서버 계층의 경우 전체 결과 세트가 메모리에 저장된 다음 한꺼번에 클라이언트에 전달되기 때문입니다. 대신 스토리지 엔진에서 행을 가져올 때마다 net_buffer라는 메모리 공간에서 이 메모리의 크기는 시스템 변수 net_buffer_length에 의해 제어됩니다. net_buffer일 때 기본값은 16KB입니다. 로컬 네트워크 스택 소켓 전송 버퍼의 메모리 공간에 기록된 데이터가 클라이언트로 전송됩니다. 전송이 성공한 후(클라이언트가 완료되었음을 읽음) >net_buffer가 지워지고 다음 줄을 읽고 씁니다. 🎜🎜즉, 기본적으로 결과 집합이 차지하는 최대 메모리 공간은 net_buffer_length 크기이며, 필드가 몇 개 더 있다고 해서 추가 메모리 공간을 차지하지는 않습니다. 🎜2. 네트워크 지연 증가
🎜앞에서 계속해서소켓 전송 버퍼의 데이터가 매번 클라이언트로 전송되지만 데이터의 양은 한 번에 크지는 않지만 실제로 누군가가 TEXT, MEDIUMTEXT 또는 BLOB</ 유형의 필드를 찾는 데 사용되었습니다. code>. 총 데이터 양이 엄청납니다. 이는 네트워크 전송 횟수의 증가로 직접 이어집니다. 🎜🎜MySQL과 애플리케이션이 동일한 시스템에 있지 않은 경우 이 오버헤드는 매우 분명합니다. MySQL 서버와 클라이언트가 동일한 시스템에 있더라도 이들 간의 통신은 여전히 TCP 프로토콜을 사용해야 하며 이로 인해 전송 시간이 추가됩니다. 🎜<h3 id="커버링-인덱스를-사용할-수-없습니다">3. 커버링 인덱스를 사용할 수 없습니다</h3>🎜이 문제를 설명하려면 테이블을 만들어야 합니다🎜<div class="code" style="position:relative; padding:0px; margin:0px;"><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'>SELECT id, name, phone FROM user_innodb WHERE name = "蝉沐风";</pre><div class="contentsignin">로그인 후 복사</div></div><div class="contentsignin">로그인 후 복사</div></div>🎜스토리지 엔진 InnoDB로 <code>user_innodb 테이블을 생성하고 설정했습니다. < code>id는 기본 키이고 name 및 phone에 대한 공동 인덱스가 생성됩니다. 마지막으로 500W 이상의 데이터가 테이블에 무작위로 초기화됩니다. . 🎜🎜InnoDB는 기본 키 id에 대해 기본 키 인덱스(클러스터형 인덱스라고도 함)라는 B+ 트리를 자동으로 생성합니다. 이 B+ 트리의 가장 중요한 특징은 리프 노드에 완전한 사용자 레코드가 포함된다는 것입니다. 아마도 이렇게 생겼을 것입니다. 🎜🎜🎜🎜 이 문을 실행하면🎜CREATE TABLE `t1` ( `id` int NOT NULL, `m` int DEFAULT NULL, `n` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT; CREATE TABLE `t2` ( `id` int NOT NULL, `m` int DEFAULT NULL, `n` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT;
EXPLAIN을 사용하여 문의 실행 계획을 볼 수 있습니다:🎜🎜🎜🎜이 SQL 문에서 보조 인덱스인 IDX_NAME_PHONE 인덱스를 사용하는 것으로 나타났습니다. 색인. 보조 인덱스의 리프 노드는 다음과 같습니다: 🎜🎜의 이유는 무엇입니까🎜🎜InnoDB 스토리지 엔진은 검색을 기반으로 보조 인덱스의 리프 노드에서 ChanMufeng이라는 name 레코드를 찾습니다. 그러나 보조 색인은 name, phone 및 기본 키 id 필드(SELECT *<를 사용하도록 요청한 필드)만 기록합니다. /code >), 따라서 InnoDB는 기본 키 인덱스에서 이 전체 레코드를 검색하기 위해 기본 키 <code>id를 사용해야 합니다. 이 프로세스를 테이블 반환이라고 합니다. 🎜🎜생각해 보세요. 보조 인덱스의 리프 노드에 우리가 원하는 데이터가 모두 포함되어 있다면 테이블을 반환해야 하지 않을까요? 예, 포함된 색인입니다. 🎜🎜예를 들어 이름, 전화 및 기본 키 필드만 검색하려고 합니다. 🎜SELECT id, name, phone FROM user_innodb WHERE name = "蝉沐风";
使用EXPLAIN查看一下语句的执行计划:

可以看到Extra一列显示Using index,表示我们的查询列表以及搜索条件中只包含属于某个索引的列,也就是使用了覆盖索引,能够直接摒弃回表操作,大幅度提高查询效率。
4. 可能拖慢JOIN连接查询
我们创建两张表t1,t2进行连接操作来说明接下来的问题,并向t1表中插入了100条数据,向t2中插入了1000条数据。
CREATE TABLE `t1` ( `id` int NOT NULL, `m` int DEFAULT NULL, `n` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT; CREATE TABLE `t2` ( `id` int NOT NULL, `m` int DEFAULT NULL, `n` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT;
如果我们执行下面这条语句
SELECT * FROM t1 STRAIGHT_JOIN t2 ON t1.m = t2.m;
这里我使用了STRAIGHT_JOIN强制令
t1表作为驱动表,t2表作为被驱动表
对于连接查询而言,驱动表只会被访问一遍,而被驱动表却要被访问好多遍,具体的访问次数取决于驱动表中符合查询记录的记录条数。现在,我们来讲一下两个表连接的本质,因为驱动表和被驱动表已经被强制确定
t1作为驱动表,针对驱动表的过滤条件,执行对t1表的查询。因为没有过滤条件,也就是获取t1表的所有数据;对上一步中获取到的结果集中的每一条记录,都分别到被驱动表中,根据连接过滤条件查找匹配记录
用伪代码表示的话整个过程是这样的:
// t1Res是针对驱动表t1过滤之后的结果集
for (t1Row : t1Res){
// t2是完整的被驱动表
for(t2Row : t2){
if (满足join条件 && 满足t2的过滤条件){
发送给客户端
}
}
}这种方法最简单,但同时性能也是最差,这种方式叫做嵌套循环连接(Nested-LoopJoin,NLJ)。怎么加快连接速度呢?
其中一个办法就是创建索引,最好是在被驱动表(t2)连接条件涉及到的字段上创建索引,毕竟被驱动表需要被查询好多次,而且对被驱动表的访问本质上就是个单表查询而已(因为t1结果集定了,每次连接t2的查询条件也就定死了)。
既然使用了索引,为了避免重蹈无法使用覆盖索引的覆辙,我们也应该尽量不要直接SELECT *,而是将真正用到的字段作为查询列,并为其建立适当的索引。
但是如果我们不使用索引,MySQL就真的按照嵌套循环查询的方式进行连接查询吗?当然不是,毕竟这种嵌套循环查询实在是太慢了!
在MySQL8.0之前,MySQL提供了基于块的嵌套循环连接(Block Nested-Loop Join,BLJ)方法,MySQL8.0又推出了hash join方法,这两种方法都是为了解决一个问题而提出的,那就是尽量减少被驱动表的访问次数。
这两种方法都用到了一个叫做join buffer的固定大小的内存区域,其中存储着若干条驱动表结果集中的记录(这两种方法的区别就是存储的形式不同而已),如此一来,把被驱动表的记录加载到内存的时候,一次性和join buffer中多条驱动表中的记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的I/O代价,大大减少了重复从磁盘上加载被驱动表的代价。使用join buffer的过程如下图所示:
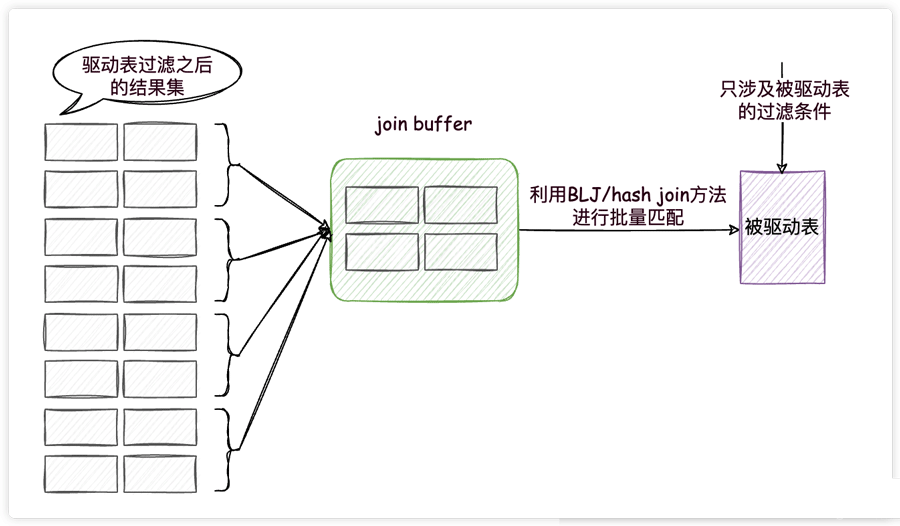
我们看一下上面的连接查询的执行计划,发现确实使用到了hash join(前提是没有为t2表的连接查询字段创建索引,否则就会使用索引,不会使用join buffer)。

最好的情况是join buffer足够大,能容纳驱动表结果集中的所有记录,这样只需要访问一次被驱动表就可以完成连接操作了。我们可以使用join_buffer_size这个系统变量进行配置,默认大小为256KB。如果还装不下,就得分批把驱动表的结果集放到join buffer中了,在内存中对比完成之后,清空join buffer再装入下一批结果集,直到连接完成为止。
重点来了!并不是驱动表记录的所有列都会被放到join buffer中,只有查询列表中的列和过滤条件中的列才会被放到join buffer中,所以再次提醒我们,最好不要把*作为查询列表,只需要把我们关心的列放到查询列表就好了,这样还可以在join buffer中放置更多的记录,减少分批的次数,也就自然减少了对被驱动表的访问次数
위 내용은 MySQL에서 SELECT *를 사용하지 않는 것이 왜 권장되지 않습니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7562
7562
 15
1384
52
84
11
60
19
28
99
15
1384
52
84
11
60
19
28
99

 MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) 데이터베이스 및 테이블 작성 : CreateAbase 및 CreateTable 명령을 사용하십시오. 2) 기본 작업 : 삽입, 업데이트, 삭제 및 선택. 3) 고급 운영 : 가입, 하위 쿼리 및 거래 처리. 4) 디버깅 기술 : 확인, 데이터 유형 및 권한을 확인하십시오. 5) 최적화 제안 : 인덱스 사용, 선택을 피하고 거래를 사용하십시오.
 phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
다음 단계를 통해 phpmyadmin을 열 수 있습니다. 1. 웹 사이트 제어판에 로그인; 2. phpmyadmin 아이콘을 찾고 클릭하십시오. 3. MySQL 자격 증명을 입력하십시오. 4. "로그인"을 클릭하십시오.
 MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템으로, 주로 데이터를 신속하고 안정적으로 저장하고 검색하는 데 사용됩니다. 작업 원칙에는 클라이언트 요청, 쿼리 해상도, 쿼리 실행 및 반환 결과가 포함됩니다. 사용의 예로는 테이블 작성, 데이터 삽입 및 쿼리 및 조인 작업과 같은 고급 기능이 포함됩니다. 일반적인 오류에는 SQL 구문, 데이터 유형 및 권한이 포함되며 최적화 제안에는 인덱스 사용, 최적화 된 쿼리 및 테이블 분할이 포함됩니다.
 MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL은 성능, 신뢰성, 사용 편의성 및 커뮤니티 지원을 위해 선택됩니다. 1.MYSQL은 효율적인 데이터 저장 및 검색 기능을 제공하여 여러 데이터 유형 및 고급 쿼리 작업을 지원합니다. 2. 고객-서버 아키텍처 및 다중 스토리지 엔진을 채택하여 트랜잭션 및 쿼리 최적화를 지원합니다. 3. 사용하기 쉽고 다양한 운영 체제 및 프로그래밍 언어를 지원합니다. 4. 강력한 지역 사회 지원을 받고 풍부한 자원과 솔루션을 제공합니다.
 단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
Redis는 단일 스레드 아키텍처를 사용하여 고성능, 단순성 및 일관성을 제공합니다. 동시성을 향상시키기 위해 I/O 멀티플렉싱, 이벤트 루프, 비 블로킹 I/O 및 공유 메모리를 사용하지만 동시성 제한 제한, 단일 고장 지점 및 쓰기 집약적 인 워크로드에 부적합한 제한이 있습니다.
 MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL은 개발자에게 필수적인 기술입니다. 1.MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템이며 SQL은 데이터베이스를 관리하고 작동하는 데 사용되는 표준 언어입니다. 2.MYSQL은 효율적인 데이터 저장 및 검색 기능을 통해 여러 스토리지 엔진을 지원하며 SQL은 간단한 문을 통해 복잡한 데이터 작업을 완료합니다. 3. 사용의 예에는 기본 쿼리 및 조건 별 필터링 및 정렬과 같은 고급 쿼리가 포함됩니다. 4. 일반적인 오류에는 구문 오류 및 성능 문제가 포함되며 SQL 문을 확인하고 설명 명령을 사용하여 최적화 할 수 있습니다. 5. 성능 최적화 기술에는 인덱스 사용, 전체 테이블 스캔 피하기, 조인 작업 최적화 및 코드 가독성 향상이 포함됩니다.
 MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
데이터베이스 및 프로그래밍에서 MySQL의 위치는 매우 중요합니다. 다양한 응용 프로그램 시나리오에서 널리 사용되는 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) MySQL은 웹, 모바일 및 엔터프라이즈 레벨 시스템을 지원하는 효율적인 데이터 저장, 조직 및 검색 기능을 제공합니다. 2) 클라이언트 서버 아키텍처를 사용하고 여러 스토리지 엔진 및 인덱스 최적화를 지원합니다. 3) 기본 사용에는 테이블 작성 및 데이터 삽입이 포함되며 고급 사용에는 다중 테이블 조인 및 복잡한 쿼리가 포함됩니다. 4) SQL 구문 오류 및 성능 문제와 같은 자주 묻는 질문은 설명 명령 및 느린 쿼리 로그를 통해 디버깅 할 수 있습니다. 5) 성능 최적화 방법에는 인덱스의 합리적인 사용, 최적화 된 쿼리 및 캐시 사용이 포함됩니다. 모범 사례에는 거래 사용 및 준비된 체계가 포함됩니다
 SQL 데이터베이스를 구축하는 방법
Apr 09, 2025 pm 04:24 PM
SQL 데이터베이스를 구축하는 방법
Apr 09, 2025 pm 04:24 PM
SQL 데이터베이스 구축에는 10 단계가 필요합니다. DBMS 선택; DBMS 설치; 데이터베이스 생성; 테이블 만들기; 데이터 삽입; 데이터 검색; 데이터 업데이트; 데이터 삭제; 사용자 관리; 데이터베이스 백업.
