
Redis 소개
Redis는 완전 오픈 소스이며 무료이며 BSD 프로토콜을 준수하며 고성능 키-값 데이터베이스입니다.
Redis는 다른 키-값 캐시 제품과 함께 다음 세 가지 특징을 가지고 있습니다.
Redis는 데이터를 지원합니다. Persistence는 메모리에 있는 데이터를 디스크에 저장하고 다시 로드하여 다시 시작할 때 사용할 수 있습니다.
Redis는 단순한 key-value 형태의 데이터뿐만 아니라 list, set, zset, hash 등의 데이터 구조에 대한 저장도 제공합니다.
Redis는 데이터 백업, 즉 마스터-슬레이브 모드를 지원합니다. 데이터 백업
Redis의 장점
매우 높은 성능– Redis의 읽기 속도는 110000회/초, 쓰기 속도는 81000회/초입니다.
풍부한 데이터 유형 - Redis는 이진 사례에 대한 문자열, 목록, 해시, 집합 및 순서 집합 데이터 유형 작업을 지원합니다.
원자성 - Redis의 모든 작업은 원자성입니다. 즉, 성공적으로 실행되거나 전혀 실행되지 않습니다. 개별 작업은 원자적입니다. 원자성을 보장하기 위해 MULTI 및 EXEC 명령어를 사용하여 여러 작업의 트랜잭션을 구현할 수 있습니다.
기타 기능 - Redis는 게시/구독 알림, 키 만료 및 기타 기능도 지원합니다.
Redis 데이터 유형
Redis는 5가지 데이터 유형을 지원합니다: 문자열(문자열), 해시(해시), 목록(목록), 집합(집합), zset(정렬된 집합: 정렬된 집합)
string
string은 Redis의 가장 기본적인 데이터 유형입니다. 키는 값에 해당합니다.
문자열은 바이너리 안전합니다. 즉, redis 문자열에는 모든 데이터가 포함될 수 있습니다. 예를 들어 jpg 이미지 또는 직렬화된 개체입니다.
Redis의 기본 데이터 유형 중 하나는 문자열 유형이며, 문자열 유형의 값 크기는 최대 512MB까지 가능합니다.
Understand: 문자열은 Java의 맵과 같고, 키는 값에 해당합니다
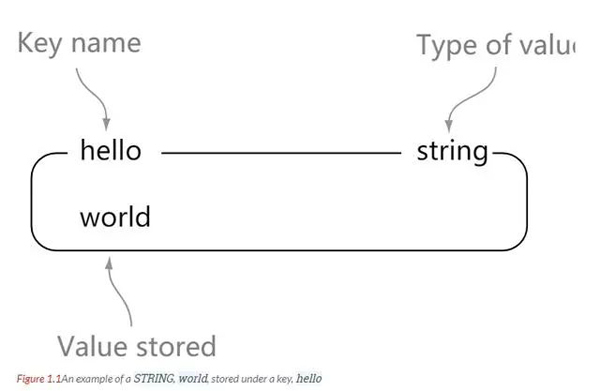
127.0.0.1:6379> set hello world OK 127.0.0.1:6379> get hello "world"
hash
Hash 컬렉션은 키-값 쌍으로 구성된 Redis 데이터 유형입니다. Redis 해시는 문자열 유형의 키와 값의 매핑 테이블입니다. 해시는 특히 개체를 저장하는 데 적합합니다.
이해: 해시를 키-값 세트로 생각할 수 있습니다. 여러 문자열에 해당하는 해시로 생각할 수도 있습니다.
과 문자열 의 차이점: 문자열은 키-값 쌍인 반면 해시는 여러 키-값 쌍입니다.
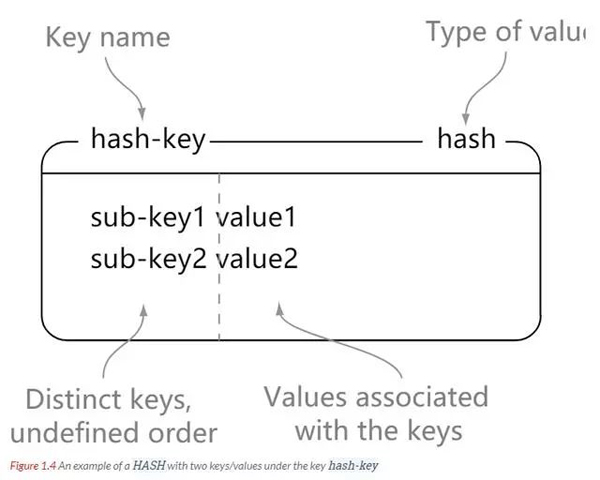
// hash-key 可以看成是一个键值对集合的名字,在这里分别为其添加了 sub-key1 : value1、 sub-key2 : value2、sub-key3 : value3 这三个键值对 127.0.0.1:6379> hset hash-key sub-key1 value1 (integer) 1 127.0.0.1:6379> hset hash-key sub-key2 value2 (integer) 1 127.0.0.1:6379> hset hash-key sub-key3 value3 (integer) 1 // 获取 hash-key 这个 hash 里面的所有键值对 127.0.0.1:6379> hgetall hash-key 1) "sub-key1" 2) "value1" 3) "sub-key2" 4) "value2" 5) "sub-key3" 6) "value3" // 删除 hash-key 这个 hash 里面的 sub-key2 键值对 127.0.0.1:6379> hdel hash-key sub-key2 (integer) 1 127.0.0.1:6379> hget hash-key sub-key2 (nil) 127.0.0.1:6379> hget hash-key sub-key1 "value1" 127.0.0.1:6379> hgetall hash-key 1) "sub-key1" 2) "value1" 3) "sub-key3" 4) "value3"
list
Redis 목록은 삽입 순서로 정렬된 간단한 문자열 목록입니다. 목록의 왼쪽이나 오른쪽에 요소를 추가할 수 있습니다.
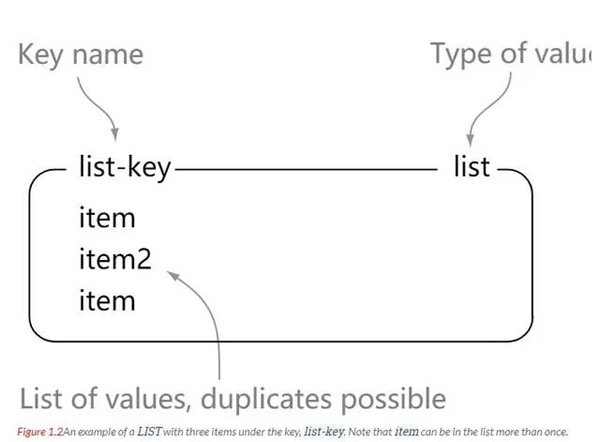
127.0.0.1:6379> rpush list-key v1 (integer) 1 127.0.0.1:6379> rpush list-key v2 (integer) 2 127.0.0.1:6379> rpush list-key v1 (integer) 3 127.0.0.1:6379> lrange list-key 0 -1 1) "v1" 2) "v2" 3) "v1" 127.0.0.1:6379> lindex list-key 1 "v2" 127.0.0.1:6379> lpop list (nil) 127.0.0.1:6379> lpop list-key "v1" 127.0.0.1:6379> lrange list-key 0 -1 1) "v2" 2) "v1"
목록은 간단한 문자열 모음이라는 것을 알 수 있는데, 이는 Java의 목록과 크게 다르지 않습니다. 여기서 목록은 문자열을 저장한다는 점입니다. 목록의 요소는 반복 가능합니다.
set
redis의 세트는 순서가 지정되지 않은 문자열 유형의 모음입니다. 세트는 해시 테이블의 데이터 구조를 사용하여 구현되므로 삽입, 삭제 및 검색 작업의 시간 복잡도는 O(1)
127.0.0.1:6379> sadd k1 v1 (integer) 1 127.0.0.1:6379> sadd k1 v2 (integer) 1 127.0.0.1:6379> sadd k1 v3 (integer) 1 127.0.0.1:6379> sadd k1 v1 (integer) 0 127.0.0.1:6379> smembers k1 1) "v3" 2) "v2" 3) "v1" 127.0.0.1:6379> 127.0.0.1:6379> sismember k1 k4 (integer) 0 127.0.0.1:6379> sismember k1 v1 (integer) 1 127.0.0.1:6379> srem k1 v2 (integer) 1 127.0.0.1:6379> srem k1 v2 (integer) 0 127.0.0.1:6379> smembers k1 1) "v3" 2) "v1"
redis의 세트는 Java의 세트와 다소 다릅니다.
redis의 집합은 여러 문자열 유형 값에 해당하는 키이며 문자열 유형의 모음이기도 합니다. 그러나 Redis의 목록과 달리 집합의 문자열 컬렉션 요소는 반복될 수 없지만 목록은 가능합니다.
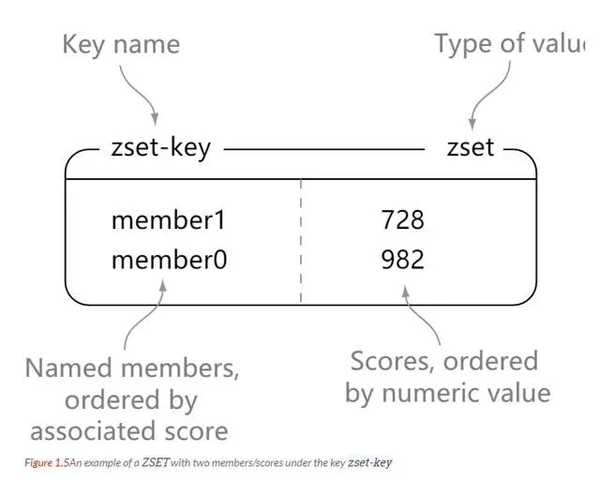
Zset
redis zset은 set과 마찬가지로 문자열 형식 요소의 모음이며 set에 포함된 요소는 반복될 수 없습니다.
차이점은 zset의 각 요소가 이중 유형 점수와 연관되어 있다는 것입니다. Redis는 점수를 사용하여 세트의 구성원을 작은 것부터 큰 것 순으로 정렬합니다.
zset의 요소는 고유하지만 점수가 반복될 수 있습니다.
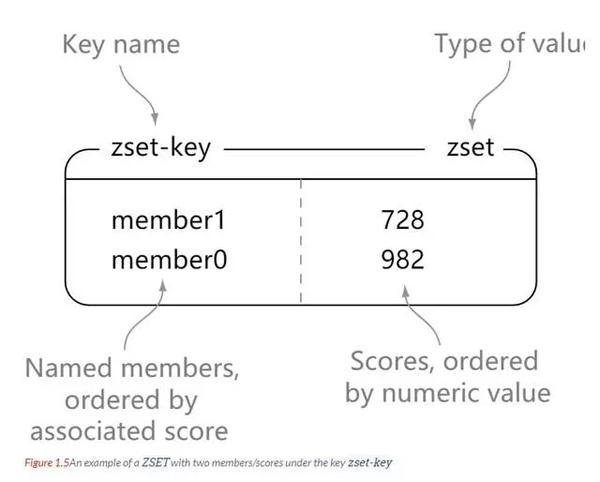
127.0.0.1:6379> zadd zset-key 728 member1 (integer) 1 127.0.0.1:6379> zadd zset-key 982 member0 (integer) 1 127.0.0.1:6379> zadd zset-key 982 member0 (integer) 0 127.0.0.1:6379> zrange zset-key 0 -1 withscores 1) "member1" 2) "728" 3) "member0" 4) "982" 127.0.0.1:6379> zrangebyscore zset-key 0 800 withscores 1) "member1" 2) "728" 127.0.0.1:6379> zrem zset-key member1 (integer) 1 127.0.0.1:6379> zrem zset-key member1 (integer) 0 127.0.0.1:6379> zrange zset-key 0 -1 withscores 1) "member0" 2) "982"
zset은 점수의 크기에 따라 정렬됩니다.
게시 및 구독
일반적으로 Redis는 메시지 게시 및 구독에 사용되지 않습니다.
소개
Redis 게시 및 구독(pub/sub)은 메시지 통신 모델입니다. 발신자(pub)는 메시지를 보내고 구독자(sub)는 메시지를 받습니다.
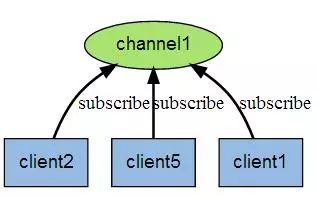
Redis 클라이언트는 원하는 수의 채널을 구독할 수 있습니다.
다음 그림은 채널1과 이 채널을 구독하는 세 클라이언트(클라이언트2, 클라이언트5, 클라이언트1) 간의 관계를 보여줍니다.
学Redis这篇就够了
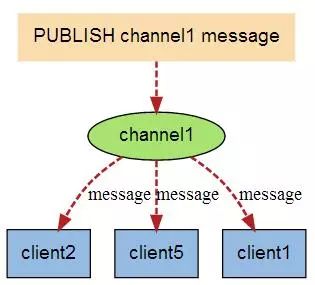
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
学Redis这篇就够了
实例
以下实例演示了发布订阅是如何工作的。在我们实例中我们创建了订阅频道名为 redisChat:
127.0.0.1:6379> SUBsCRIBE redisChat Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "redisChat"
现在,我们先重新开启个 redis 客户端,然后在同一个频道 redisChat 发布两次消息,订阅者就能接收到消息。
127.0.0.1:6379> PUBLISH redisChat "send message" (integer) 1 127.0.0.1:6379> PUBLISH redisChat "hello world" (integer) 1 # 订阅者的客户端显示如下 1) "message" 2) "redisChat" 3) "send message" 1) "message" 2) "redisChat" 3) "hello world"
事务
redis 事务一次可以执行多条命令,服务器在执行命令期间,不会去执行其他客户端的命令请求。
事务中的多条命令被一次性发送给服务器,而不是一条一条地发送,这种方式被称为流水线,它可以减少客户端与服务器之间的网络通信次数从而提升性能。
Redis 最简单的事务实现方式是使用 MULTI 和 EXEC 命令将事务操作包围起来。
批量操作在发送 EXEC 命令前被放入队列缓存。
在接收到 EXEC 命令后,进入事务执行。如果在事务中有命令执行失败,其他命令仍然会继续执行。也就是说 Redis 事务不保证原子性。
在事务执行过程中,其他客户端提交的命令请求不会插入到事务执行命令序列中。
一个事务从开始到执行会经历以下三个阶段:
开始事务。
命令入队。
执行事务。
实例
以下是一个事务的例子, 它先以 MULTI 开始一个事务, 然后将多个命令入队到事务中, 最后由 EXEC 命令触发事务, 一并执行事务中的所有命令:
redis 127.0.0.1:6379> MULTI OK redis 127.0.0.1:6379> SET book-name "Mastering C++ in 21 days" QUEUED redis 127.0.0.1:6379> GET book-name QUEUED redis 127.0.0.1:6379> SADD tag "C++" "Programming" "Mastering Series" QUEUED redis 127.0.0.1:6379> SMEMBERS tag QUEUED redis 127.0.0.1:6379> EXEC 1) OK 2) "Mastering C++ in 21 days" 3) (integer) 3 4) 1) "Mastering Series" 2) "C++" 3) "Programming"
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
这是官网上的说明 From redis docs on transactions:
It's important to note that even when a command fails, all the other commands in the queue are processed – Redis will not stop the processing of commands.
比如:
redis 127.0.0.1:7000> multi OK redis 127.0.0.1:7000> set a aaa QUEUED redis 127.0.0.1:7000> set b bbb QUEUED redis 127.0.0.1:7000> set c ccc QUEUED redis 127.0.0.1:7000> exec 1) OK 2) OK 3) OK
如果在 set b bbb 处失败,set a 已成功不会回滚,set c 还会继续执行。
Redis 事务命令
下表列出了 redis 事务的相关命令:
序号命令及描述:
1. DISCARD 取消事务,放弃执行事务块内的所有命令。
2. EXEC 执行所有事务块内的命令。
3. MULTI 标记一个事务块的开始。
4. UNWATCH 取消 WATCH 命令对所有 key 的监视。
5. WATCH key [key …]监视一个 (或多个) key ,如果在事务执行之前这个 (或这些) key 被其他命令所改动,那么事务将被打断。
持久化
Redis 是内存型数据库,为了保证数据在断电后不会丢失,需要将内存中的数据持久化到硬盘上。
RDB 持久化
将某个时间点的所有数据都存放到硬盘上。
可以将快照复制到其他服务器从而创建具有相同数据的服务器副本。
如果系统发生故障,将会丢失最后一次创建快照之后的数据。
如果数据量大,保存快照的时间会很长。
AOF 持久化
将写命令添加到 AOF 文件(append only file)末尾。
使用 AOF 持久化需要设置同步选项,从而确保写命令同步到磁盘文件上的时机。
这是因为对文件进行写入并不会马上将内容同步到磁盘上,而是先存储到缓冲区,然后由操作系统决定什么时候同步到磁盘。
选项同步频率always每个写命令都同步eyerysec每秒同步一次no让操作系统来决定何时同步
always 选项会严重减低服务器的性能
everysec 选项比较合适,可以保证系统崩溃时只会丢失一秒左右的数据,并且 Redis 每秒执行一次同步对服务器几乎没有任何影响。
no 选项并不能给服务器性能带来多大的提升,而且会增加系统崩溃时数据丢失的数量。
随着服务器写请求的增多,AOF 文件会越来越大。Redis提供了一项称作AOF重写的功能,能够消除AOF文件中的重复写入命令。
复制
slaveof 호스트 포트 명령을 사용하여 한 서버를 다른 서버의 슬레이브로 만듭니다.
슬레이브 서버는 마스터 서버를 하나만 가질 수 있으며 마스터-마스터 복제는 지원되지 않습니다.
연결 프로세스
마스터 서버는 스냅샷 파일, 즉 RDB 파일을 생성하여 슬레이브 서버로 전송하고, 전송 중에 실행된 쓰기 명령을 버퍼를 사용하여 기록합니다.
스냅샷 파일이 전송된 후 서버에서 버퍼에 저장된 쓰기 명령을 전송하기 시작합니다.
슬레이브 서버는 이전 데이터를 모두 삭제하고 마스터 서버가 보낸 스냅샷 파일을 로드한 후 슬레이브 서버가 마스터 서버의 쓰기 명령을 받아들이기 시작합니다.
마스터 서버는 쓰기 명령을 실행할 때마다 동일한 쓰기 명령을 슬레이브 서버로 보냅니다.
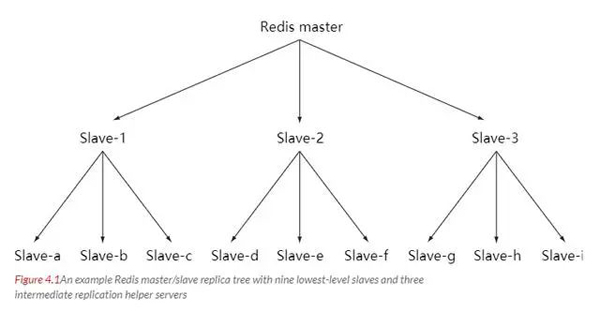
마스터-슬레이브 체인
부하가 계속 증가할 때 마스터 서버가 모든 슬레이브 서버를 신속하게 업데이트하지 못하거나 슬레이브 서버를 다시 연결하고 동기화하지 못하면 시스템에 과부하가 발생합니다.
이 문제를 해결하기 위해 중간 계층을 구축하여 메인 서버의 복제 작업량을 줄일 수 있습니다. 중간 계층 서버는 최상위 서버의 슬레이브 서버 역할과 하위 계층 서버의 마스터 서버 역할을 동시에 수행합니다.
Sentinel
Sentinel은 클러스터의 서버를 모니터링하고 마스터 서버가 오프라인 상태가 되면 슬레이브 서버에서 새 마스터 서버를 자동으로 선택할 수 있습니다.
샤딩
샤딩은 데이터를 여러 부분으로 나누는 방법으로, 특정 문제를 해결할 때 데이터를 여러 시스템에 저장할 수 있습니다.
4개의 Redis 인스턴스 R0, R1, R2, R3과 사용자 user:1, user:2, …을 나타내는 많은 키가 있다고 가정합니다. 지정된 키가 저장되는 인스턴스를 선택하는 다양한 방법이 있습니다.
가장 간단한 것은 범위 샤딩입니다. 예를 들어 0~1000의 사용자 ID는 인스턴스 R0에 저장되고, 1001~2000의 사용자 ID는 인스턴스 R1에 저장되는 식입니다. 그러나 이를 위해서는 매핑 범위 테이블을 유지 관리해야 하므로 유지 관리 비용이 많이 듭니다.
또 다른 하나는 해시 샤딩입니다. 저장해야 하는 인스턴스는 키에 대해 CRC32 해시 함수를 실행하고 이를 숫자로 변환한 다음 인스턴스 수를 모듈로로 계산하여 결정됩니다.
샤딩이 수행되는 위치에 따라 세 가지 샤딩 방법으로 나눌 수 있습니다.
클라이언트 측 샤딩: 클라이언트는 일관된 해싱과 같은 알고리즘을 사용하여 어떤 노드에 배포할지 결정합니다.
프록시 샤딩: 클라이언트의 요청을 프록시로 보내고 프록시는 이를 올바른 노드로 전달합니다.
서버 샤딩: Redis 클러스터.
위 내용은 Redis의 종합적인 지식 포인트는 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



