

MySQL의 B-트리 인덱스와 B+-트리 인덱스의 차이점은 무엇입니까?

트리를 인덱스 데이터 구조로 사용하면 데이터를 검색할 때마다 트리의 한 노드, 즉 페이지가 디스크에서 읽혀집니다. 그러나 이진 트리의 각 노드는 하나의 데이터만 저장합니다. , 저장 공간을 한 페이지도 채울 수 없다면 추가 저장 공간이 낭비되지 않을까요? 이러한 이진 균형 탐색 트리의 단점을 해결하기 위해서는 단일 노드에 더 많은 데이터를 저장할 수 있는 데이터 구조, 즉 다방향 탐색 트리를 찾아야 한다.
1. 다중 방향 검색 트리
1. 완전한 이진 트리 높이: O(log2N), 여기서 2는 로그, 트리의 각 수준에 있는 노드 수입니다. . 완전한 M-way 검색 트리 높이: O(logmN), 여기서 M은 로그, 트리의 각 레이어에 있는 노드 수입니다. O(log2N),其中2为对数,树每层的节点数;
2、完全M路搜索树的高度:O(logmN),其中M为对数,树每层的节点数;
M路搜索树适用于存储数据量过大无法一次性加载到内存的场景。通过增加每层节点的个数和在每个节点存放更多的数据来在一层中存放更多的数据,从而降低树的高度,在数据查找时减少磁盘访问次数。
因此,如果每个节点包含的关键字数量和每层的节点数量增加,则树的高度将减少。尽管每个节点的数据确定会更加耗时,但B树的关注点在于解决磁盘性能瓶颈,因此单个节点搜索数据的成本可以被忽略。
2. B树-多路平衡搜索树
B树是一种M路搜索树,B树主要用于解决M路搜索树的不平衡导致树的高度变高,跟二叉树退化为链表导致性能问题一样。B树通过对每层的节点进行控制、调整,如节点分离,节点合并,一层满时向上分裂父节点来增加新的层等操作来来保证该M路搜索树的平衡。
在B树中,每个节点都是一个磁盘块(页),而阶数或者说路数M则规定了节点中最多的子节点数量。每个非叶子节点存放了关键字和指向儿子树的指针,具体数量为:M阶的B树,每个非叶子节点存放了M-1个关键字和M个指向子树的指针。如图为5阶B树结构的示意图:

3. B树索引
首先创建一张user表:
create table user( id int, name varchar, primary key(id) ) ROW_FORMAT=COMPACT;
假如我们使用B树对表中的用户记录建立索引:
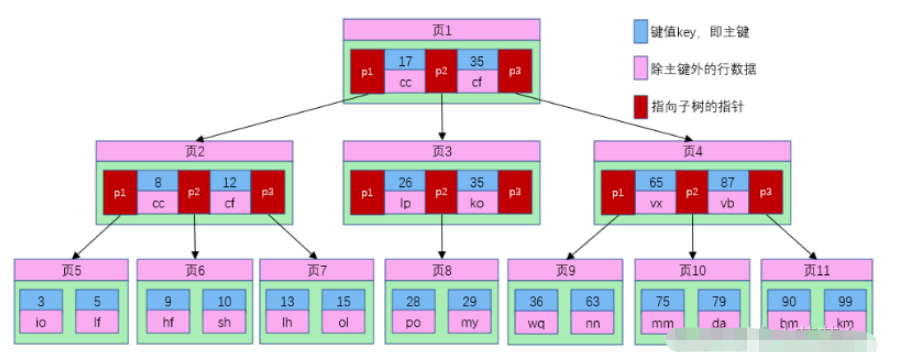
B树的每个节点占用一个磁盘块,磁盘块也就是页,从上图可以看出,B树相对于平衡二叉树,每个节点存储了更多的主键key和数据data,并且每个节点拥有了更多的子节点,子节点的个数一般称为阶,上述图中的B树为3阶B树,高度也会降低。假如我们要查找id=28的用户信息,那么查找流程如下:
1、根据根节点找到页1,读入内存。【磁盘I/O操作第1次】
2、比较键值28在区间(17,35),找到页1的指针p2;
3、根据p2指针找到页3,读入内存。【磁盘I/O操作第2次】
4、比较键值28在区间(26,35),找到页3的指针p2。
5、根据p2指针找到页8,读入内存。【磁盘I/O操作第3次】
6、在页8中的键值列表中找到键值28,键值对应的用户信息为(28,po);
B-Tree相对于AVLTree
3. B-tree index
먼저 사용자 테이블을 생성합니다:
rrreeeB-tree를 사용하여 사용자 레코드를 인덱싱한다면 table:
B-트리의 각 노드는 디스크 블록을 차지하고 디스크 블록도 페이지입니다. 위 그림에서 알 수 있듯이 균형 이진 트리와 비교하면 B-트리의 각 노드는 -tree는 더 많은 기본 키와 데이터를 저장하며, 각 노드에는 자식 노드가 많을수록 일반적으로 자식 노드의 수를 순서라고 합니다. 위 그림의 B-트리는 3레벨 B-트리이며 높이는 다음과 같습니다. 또한 감소됩니다. id=28의 사용자 정보를 찾으려면 검색 과정은 다음과 같습니다. 1. 루트 노드에 따라 1페이지를 찾아서 메모리에 읽어옵니다. [디스크 I/O 작업 1차] 🎜🎜2. 간격(17,35)에서 키 값 28을 비교하고, 페이지 1의 포인터 p2를 찾습니다. 🎜🎜3. 기억 속으로 말이죠. [디스크 I/O 작업 2차] 🎜🎜4. 간격(26,35)의 키 값 28을 비교하여 3페이지의 포인터 p2를 찾습니다. 🎜🎜5. p2 포인터에 따라 8페이지를 찾아 메모리에 읽어 들입니다. [디스크 I/O 작업 3번째] 🎜🎜6. 8페이지의 키 값 목록에서 키 값 28을 찾습니다. 키 값에 해당하는 사용자 정보는 (28,po)입니다. AVLTree에 비해 노드 수가 줄어들어 디스크 I/O를 사용할 때마다 메모리에서 가져온 데이터를 사용할 수 있어 쿼리 효율성이 향상됩니다. 🎜🎜4. B+Tree Index🎜🎜B+Tree는 B-Tree 기반의 최적화로, B+Tree의 속성: 🎜🎜1. 노드 키워드 수와 동일합니다. 🎜🎜3. 모든 키워드가 리프 노드에 표시되고 연결된 목록의 키워드가 순서대로 표시됩니다. 리프 노드는 리프 노드의 인덱스와 동일하며, 리프 노드는 (키워드) 데이터를 저장하는 데이터 계층과 동일합니다. 🎜🎜InnoDB 스토리지 엔진은 B+Tree를 사용하여 인덱스 구조를 구현합니다. 🎜🎜B-트리 구조 다이어그램을 보면, 각 노드에는 데이터의 키 값 외에 데이터 값도 포함되어 있음을 알 수 있습니다. 각 페이지의 저장 공간은 제한되어 있으며, 데이터 데이터가 크면 각 노드(즉, 한 페이지)에 저장할 수 있는 키의 수가 매우 적습니다. B - Tree의 깊이가 커져 쿼리 중 디스크 I/O 수가 증가하여 쿼리 효율성에 영향을 미칩니다. B+Tree에서는 모든 데이터 레코드 노드가 키 값 순서로 동일한 레이어의 리프 노드에 저장되며, 리프가 아닌 노드에는 키 값 정보만 저장되므로 각 노드에 저장되는 키 값의 수가 크게 늘어날 수 있습니다. node.B+Tree의 높이를 줄입니다. 🎜🎜🎜B+Tree는 B-Tree와 비교하여 몇 가지 차이점이 있습니다. 🎜🎜🎜1. 리프가 아닌 노드는 하위 노드 페이지 번호에 대한 키 값 정보만 저장합니다. 🎜🎜2. 포인터 🎜🎜3. 데이터 레코드는 리프 노드에 저장됩니다.
위 그림을 바탕으로 B+ 트리와 B-트리의 차이점을 살펴보겠습니다.
(2) B+ 트리에서는 리프가 아닌 노드가 키 값만 저장하는 반면 B-트리 노드는 키 값만 저장합니다. 키 값과 데이터 저장을 모두 저장합니다.
페이지 크기는 고정되어 있으며 InnoDB의 기본 페이지 크기는 16KB입니다. 데이터가 저장되지 않으면 더 많은 키 값이 저장되고 해당 트리의 순서가 커지며 결과적으로 데이터를 검색하는 데 필요한 디스크 IO 횟수가 늘어납니다. 다시 감소합니다. 데이터 쿼리 효율성도 빨라집니다.
또한 B+ 트리의 한 노드가 1000개의 키 값을 저장할 수 있다면 3계층 B+ 트리는 1000×1000×1000=10억 개의 데이터를 저장할 수 있습니다. 일반적으로 루트 노드는 메모리에 상주하므로(처음으로 루트 노드를 검색할 때 디스크를 읽을 필요가 없음) 일반적으로 10억 개의 데이터를 검색하는 데 2개의 디스크 IO만 필요합니다.
(2) B+ 트리 인덱스의 모든 데이터는 리프 노드에 저장되며 데이터가 순서대로 정렬됩니다.
B+ 트리의 페이지는 양방향 연결 목록으로 연결되고, 리프 노드의 데이터는 단방향 연결 목록으로 연결됩니다. 이렇게 하면 테이블의 모든 데이터를 찾을 수 있습니다. B+ 트리는 범위 쿼리, 정렬 쿼리, 그룹 쿼리 및 중복 제거 쿼리를 매우 간단하게 만듭니다. B-트리에서는 데이터가 여러 노드에 분산되어 있기 때문에 이를 구현하기가 쉽지 않습니다.
위 내용은 MySQL의 B-트리 인덱스와 B+-트리 인덱스의 차이점은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 MySQL의 역할 : 웹 응용 프로그램의 데이터베이스
Apr 17, 2025 am 12:23 AM
MySQL의 역할 : 웹 응용 프로그램의 데이터베이스
Apr 17, 2025 am 12:23 AM
웹 응용 프로그램에서 MySQL의 주요 역할은 데이터를 저장하고 관리하는 것입니다. 1. MySQL은 사용자 정보, 제품 카탈로그, 트랜잭션 레코드 및 기타 데이터를 효율적으로 처리합니다. 2. SQL 쿼리를 통해 개발자는 데이터베이스에서 정보를 추출하여 동적 컨텐츠를 생성 할 수 있습니다. 3.mysql은 클라이언트-서버 모델을 기반으로 작동하여 허용 가능한 쿼리 속도를 보장합니다.
 LARAVEL 소개 예
Apr 18, 2025 pm 12:45 PM
LARAVEL 소개 예
Apr 18, 2025 pm 12:45 PM
Laravel은 웹 응용 프로그램을 쉽게 구축하기위한 PHP 프레임 워크입니다. 설치 : Composer를 사용하여 전 세계적으로 Laravel CLI를 설치하고 프로젝트 디렉토리에서 응용 프로그램을 작성하는 등 다양한 기능을 제공합니다. 라우팅 : Routes/Web.php에서 URL과 핸들러 간의 관계를 정의하십시오. 보기 : 리소스/뷰에서보기를 작성하여 응용 프로그램의 인터페이스를 렌더링합니다. 데이터베이스 통합 : MySQL과 같은 데이터베이스와 상자 외 통합을 제공하고 마이그레이션을 사용하여 테이블을 작성하고 수정합니다. 모델 및 컨트롤러 : 모델은 데이터베이스 엔티티를 나타내고 컨트롤러는 HTTP 요청을 처리합니다.
 Docker의 MySQL을 시작하는 방법
Apr 15, 2025 pm 12:09 PM
Docker의 MySQL을 시작하는 방법
Apr 15, 2025 pm 12:09 PM
Docker에서 MySQL을 시작하는 프로세스는 다음 단계로 구성됩니다. MySQL 이미지를 가져와 컨테이너를 작성하고 시작하고 루트 사용자 암호를 설정하고 포트 확인 연결을 매핑하고 데이터베이스를 작성하고 사용자는 데이터베이스에 모든 권한을 부여합니다.
 MySQL 및 Phpmyadmin : 핵심 기능 및 기능
Apr 22, 2025 am 12:12 AM
MySQL 및 Phpmyadmin : 핵심 기능 및 기능
Apr 22, 2025 am 12:12 AM
MySQL 및 Phpmyadmin은 강력한 데이터베이스 관리 도구입니다. 1) MySQL은 데이터베이스 및 테이블을 작성하고 DML 및 SQL 쿼리를 실행하는 데 사용됩니다. 2) PHPMYADMIN은 데이터베이스 관리, 테이블 구조 관리, 데이터 운영 및 사용자 권한 관리에 직관적 인 인터페이스를 제공합니다.
 데이터베이스 연결 문제 해결 : Minii/DB 라이브러리 사용 실질적인 사례
Apr 18, 2025 am 07:09 AM
데이터베이스 연결 문제 해결 : Minii/DB 라이브러리 사용 실질적인 사례
Apr 18, 2025 am 07:09 AM
작은 응용 프로그램을 개발할 때 까다로운 문제가 발생했습니다. 가벼운 데이터베이스 운영 라이브러리를 신속하게 통합해야합니다. 여러 라이브러리를 시도한 후에는 기능이 너무 많거나 호환되지 않는다는 것을 알았습니다. 결국, 나는 내 문제를 완벽하게 해결하는 YII2를 기반으로 단순화 된 버전 인 Minii/DB를 발견했습니다.
 MySQL 대 기타 프로그래밍 언어 : 비교
Apr 19, 2025 am 12:22 AM
MySQL 대 기타 프로그래밍 언어 : 비교
Apr 19, 2025 am 12:22 AM
다른 프로그래밍 언어와 비교할 때 MySQL은 주로 데이터를 저장하고 관리하는 데 사용되는 반면 Python, Java 및 C와 같은 다른 언어는 논리적 처리 및 응용 프로그램 개발에 사용됩니다. MySQL은 데이터 관리 요구에 적합한 고성능, 확장 성 및 크로스 플랫폼 지원으로 유명하며 다른 언어는 데이터 분석, 엔터프라이즈 애플리케이션 및 시스템 프로그래밍과 같은 해당 분야에서 이점이 있습니다.
 Laravel 프레임 워크 설치 방법
Apr 18, 2025 pm 12:54 PM
Laravel 프레임 워크 설치 방법
Apr 18, 2025 pm 12:54 PM
기사 요약 :이 기사는 Laravel 프레임 워크를 쉽게 설치하는 방법에 대한 독자들을 안내하기위한 자세한 단계별 지침을 제공합니다. Laravel은 웹 애플리케이션의 개발 프로세스를 가속화하는 강력한 PHP 프레임 워크입니다. 이 자습서는 시스템 요구 사항에서 데이터베이스 구성 및 라우팅 설정에 이르기까지 설치 프로세스를 다룹니다. 이러한 단계를 수행함으로써 독자들은 라벨 프로젝트를위한 탄탄한 토대를 빠르고 효율적으로 놓을 수 있습니다.
 초보자를위한 MySQL : 데이터베이스 관리를 시작합니다
Apr 18, 2025 am 12:10 AM
초보자를위한 MySQL : 데이터베이스 관리를 시작합니다
Apr 18, 2025 am 12:10 AM
MySQL의 기본 작업에는 데이터베이스, 테이블 작성 및 SQL을 사용하여 데이터에서 CRUD 작업을 수행하는 것이 포함됩니다. 1. 데이터베이스 생성 : createAbasemy_first_db; 2. 테이블 만들기 : CreateTableBooks (idintauto_incrementprimarykey, titlevarchar (100) notnull, authorvarchar (100) notnull, published_yearint); 3. 데이터 삽입 : InsertIntobooks (Title, Author, Published_year) VA
