

7가지 종류의 Java 데이터 구조를 사용하는 방법

1. 삽입 정렬
1. 직접 삽입 정렬
i(i>=1) 요소를 삽입할 때 이전 배열[0],array[1],…,array[i -1 ]가 정렬되었습니다. 이때 array[i-1], array[i-2],...를 비교하여 삽입 위치를 찾아 원래 위치에 배열[i]을 삽입합니다. 순서대로 뒤로 이동합니다.
데이터가 순서에 가까울수록 정렬을 직접 삽입하는 데 걸리는 시간이 줄어듭니다.
시간 복잡도: O(N^2)
공간 복잡도 O(1), 안정적인 알고리즘
직접 삽입 정렬:
public static void insertSort(int[] array){
for (int i = 1; i < array.length; i++) {
int tmp=array[i];
int j=i-1;
for(;j>=0;--j){
if(array[j]>tmp){
array[j+1]=array[j];
}else{
break;
}
}
array[j+1]=tmp;
}
}2. 힐 정렬
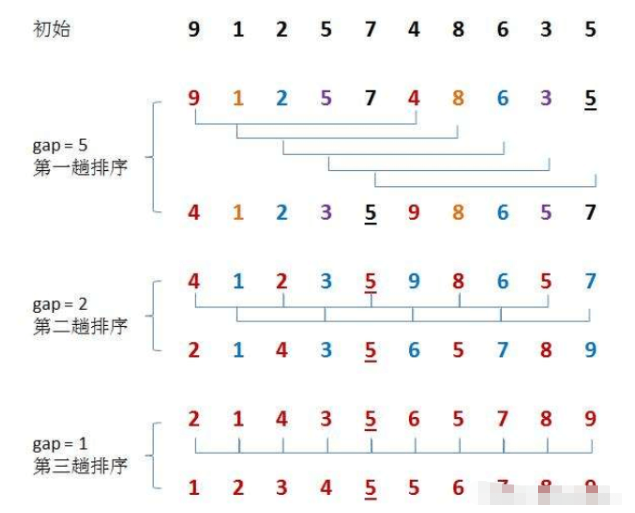
힐 정렬의 기본 아이디어 방법은 먼저 정수 간격을 선택하고, 정렬할 파일의 모든 레코드를 간격 그룹으로 나누고, 간격 간격이 있는 모든 숫자를 같은 그룹에 넣은 다음, 각 그룹의 숫자에 대해 직접 삽입 정렬을 수행합니다. . 그런 다음 gap=gap/2를 취하고 위의 그룹화 및 정렬 작업을 반복합니다. gap=1이면 모든 숫자가 그룹 내에서 직접 정렬됩니다.
힐 정렬은 직접 삽입 정렬을 최적화한 것입니다.
배열을 순서에 가깝게 만드는 것이 목적이므로 간격 > 1일 때 사전 정렬이 수행됩니다. 삽입 정렬은 간격이 1일 때 거의 순서가 지정된 배열을 빠르게 정렬할 수 있습니다.
Hill 정렬의 시간 복잡도는 간격을 계산하는 방법이 다양하여 계산하기 어렵기 때문에 계산하기 어렵습니다.
힐 정렬:
public static void shellSort(int[] array){
int size=array.length;
//这里定义gap的初始值为数组长度的一半
int gap=size/2;
while(gap>0){
//间隔为gap的直接插入排序
for (int i = gap; i < size; i++) {
int tmp=array[i];
int j=i-gap;
for(;j>=0;j-=gap){
if(array[j]>tmp){
array[j+gap]=array[j];
}else{
break;
}
}
array[j+gap]=tmp;
}
gap/=2;
}
}2. 선택 정렬
1. 선택 정렬
요소 집합에서 가장 작은 데이터 요소를 선택합니다. array[i]--array[n-1]
이 세트의 첫 번째 요소가 아닌 경우 이 세트의 첫 번째 요소로 교환하세요
나머지 세트에서 세트에 1개의 요소가 남을 때까지 위 단계를 반복하세요
시간 복잡도 : O(N^2)
공간 복잡도는 O(1), 불안정
선택 정렬:
//交换
private static void swap(int[] array,int i,int j){
int tmp=array[i];
array[i]=array[j];
array[j]=tmp;
}
//选择排序
public static void chooseSort(int[] array){
for (int i = 0; i < array.length; i++) {
int minIndex=i;//记录最小值的下标
for (int j = i+1; j < array.length; j++) {
if (array[j]<array[minIndex]) {
minIndex=j;
}
}
swap(array,i,minIndex);
}
}2. 힙 정렬
힙 정렬의 두 가지 아이디어(예: 오름차순):
작은 루트 힙을 만들고, 힙의 최상위 요소를 꺼내서 힙이 빌 때까지 차례로 배열에 넣습니다.
큰 루트 힙을 만들고, 힙의 꼬리 요소 위치 키를 정의합니다. , 그리고 키가 힙의 상단에 도달할 때까지 요소와 키 위치(key--)의 요소를 매번 교환합니다. 이때 힙에 있는 요소의 계층적 순회는 오름차순입니다. 순서 (다음과 같음)
시간 복잡도: O(N^2)
공간 복잡도: O(N), 불안정
힙 정렬:
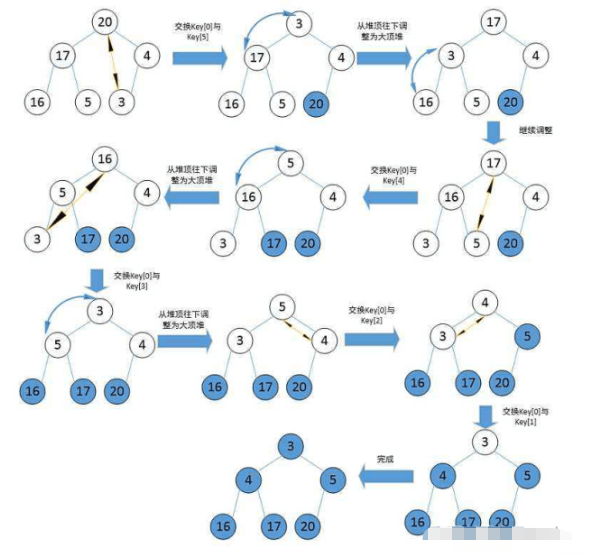
//向下调整
public static void shiftDown(int[] array,int parent,int len){
int child=parent*2+1;
while(child<len){
if(child+1<len){
if(array[child+1]>array[child]){
child++;
}
}
if(array[child]>array[parent]){
swap(array,child,parent);
parent=child;
child=parent*2+1;
}else{
break;
}
}
}
//创建大根堆
private static void createHeap(int[] array){
for (int parent = (array.length-1-1)/2; parent >=0; parent--) {
shiftDown(array,parent,array.length);
}
}
//堆排序
public static void heapSort(int[] array){
//创建大根堆
createHeap(array);
//排序
for (int i = array.length-1; i >0; i--) {
swap(array,0,i);
shiftDown(array,0,i);
}
}3. 교환 정렬
1.
2레벨 루프, 첫 번째 루프 레벨은 정렬할 횟수를 나타내고, 2레벨 루프는 각 패스의 비교 횟수를 나타냅니다. 여기서 버블 정렬은 각 비교 중에 최적화되었습니다. 데이터 교환 횟수를 기록하는 카운터를 정의할 수 있습니다. 교환이 없으면 데이터가 더 이상 정렬되지 않음을 의미합니다.
시간 복잡도: O(N^2)
공간 복잡도는 O(1)이며 이는 안정적인 정렬입니다.
버블 정렬:
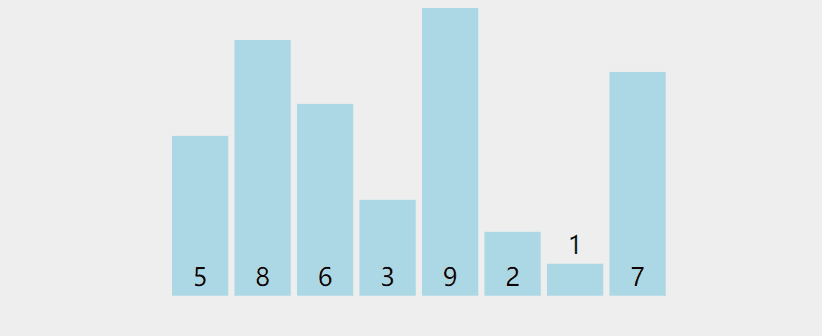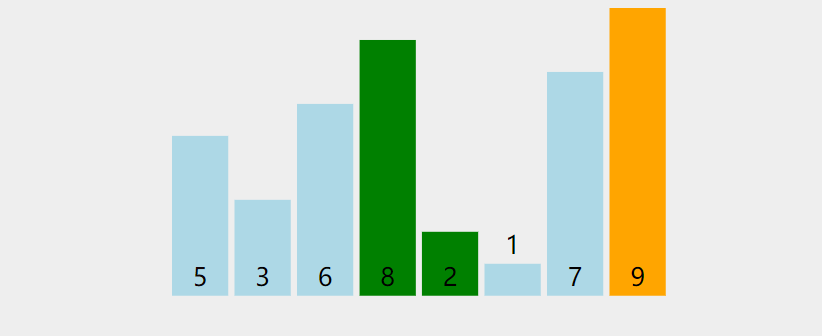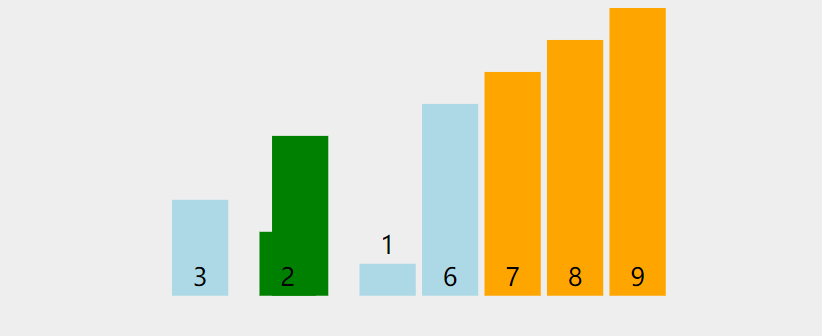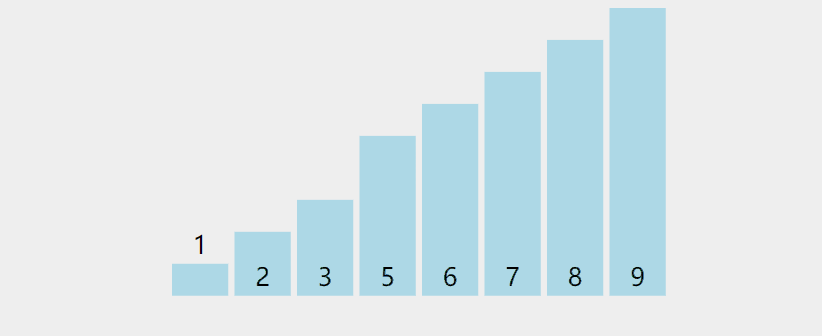
public static void bubbleSort(int[] array){
for(int i=0;i<array.length-1;++i){
int count=0;
for (int j = 0; j < array.length-1-i; j++) {
if(array[j]>array[j+1]){
swap(array,j,j+1);
count++;
}
}
if(count==0){
break;
}
}
}2 빠른 정렬
어떤 선택이든 정렬됩니다. 요소 시퀀스의 요소는 정렬 코드에 따라 두 개의 하위 시퀀스로 구분됩니다. 왼쪽 하위 시퀀스의 모든 요소는 벤치마크 값보다 작습니다. 벤치마크 값보다 큰 경우 가장 왼쪽의 하위 시퀀스 모든 요소가 해당 위치에 배열될 때까지 시퀀스는 이 프로세스를 반복합니다.
시간 복잡도: 최상 O(n*logn): 정렬할 시퀀스를 매번 최대한 균등하게 나눌 수 있음
Worst O(N^2): 정렬할 시퀀스 자체가 정렬됨
공간 복잡도: 기껏해야 O(logn), 최악의 경우 O(N)입니다. 불안정한 정렬
(1) 파기 방법
데이터를 정렬할 때 빠른 정렬은 왼쪽 또는 오른쪽 하위 트리가 없는 이진 트리와 동일합니다. 이 때 공간 복잡도는 O(N)에 도달합니다. 데이터의 양을 정렬하면 스택 오버플로가 발생할 수 있습니다.
public static void quickSort(int[] array,int left,int right){
if(left>=right){
return;
}
int l=left;
int r=right;
int tmp=array[l];
while(l<r){
while(array[r]>=tmp&&l<r){
//等号不能省略,如果省略,当序列中存在相同的值时,程序会死循环
r--;
}
array[l]=array[r];
while(array[l]<=tmp&&l<r){
l++;
}
array[r]=array[l];
}
array[l]=tmp;
quickSort(array,0,l-1);
quickSort(array,l+1,right);
}(2) 퀵 정렬 최적화
세 숫자 중 중간을 취하여 키를 선택하세요
키 값 선택과 관련하여 정렬할 순서가 맞다면 첫 번째 또는 마지막 값을 다음과 같이 선택합니다. 분할이 발생할 수 있는 키의 왼쪽이나 오른쪽이 비어 있는 경우 퀵 정렬의 공간 복잡도가 상대적으로 커지므로 스택 오버플로가 발생하기 쉽습니다. 그런 다음 세 숫자 방법을 사용하여 이 상황을 취소할 수 있습니다. 시퀀스의 첫 번째, 마지막 및 중간 요소의 중간 값이 키 값으로 사용됩니다.
//key值的优化,只在快速排序中使用,则可以为private
private int threeMid(int[] array,int left,int right){
int mid=(left+right)/2;
if(array[left]>array[right]){
if(array[mid]>array[left]){
return left;
}
return array[mid]<array[right]?right:mid;
}else{
if(array[mid]<array[left]){
return left;
}
return array[mid]>array[right]?right:mid;
}
}작은 하위 범위로 재귀할 때 삽입 정렬 사용을 고려할 수 있습니다
随着我们递归的进行,区间会变的越来越小,我们可以在区间小到一个值的时候,对其进行插入排序,这样代码的效率会提高很多。
(3)快速排序的非递归实现
//找到一次划分的下标
public static int patition(int[] array,int left,int right){
int tmp=array[left];
while(left<right){
while(left<right&&array[right]>=tmp){
right--;
}
array[left]=array[right];
while(left<right&&array[left]<=tmp){
left++;
}
array[right]=array[left];
}
array[left]=tmp;
return left;
}
//快速排序的非递归
public static void quickSort2(int[] array){
Stack<Integer> stack=new Stack<>();
int left=0;
int right=array.length-1;
stack.push(left);
stack.push(right);
while(!stack.isEmpty()){
int r=stack.pop();
int l=stack.pop();
int p=patition(array,l,r);
if(p-1>l){
stack.push(l);
stack.push(p-1);
}
if(p+1<r){
stack.push(p+1);
stack.push(r);
}
}
}四、归并排序
归并排序(MERGE-SORT):该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。实现序列的完全有序,需要将已经有序的子序列合并,即先让每个子序列有序,然后再将相邻的子序列段有序。若将两个有序表合并成一个有序表,称为二路归并。
时间复杂度:O(n*logN)(无论有序还是无序)
空间复杂度:O(N)。是稳定的排序。
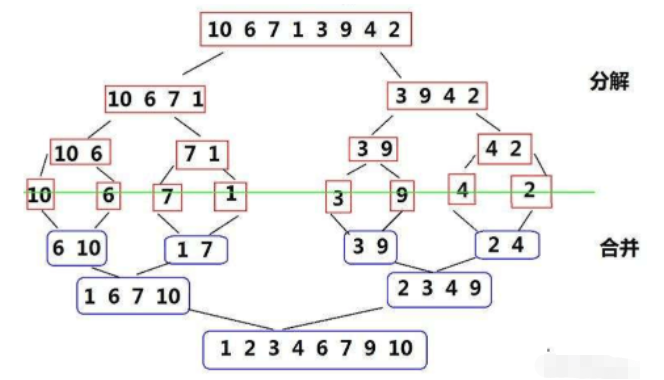
//归并排序:递归
public static void mergeSort(int[] array,int left,int right){
if(left>=right){
return;
}
int mid=(left+right)/2;
//递归分割
mergeSort(array,left,mid);
mergeSort(array,mid+1,right);
//合并
merge(array,left,right,mid);
}
//非递归
public static void mergeSort1(int[] array){
int gap=1;
while(gap<array.length){
for (int i = 0; i < array.length; i+=2*gap) {
int left=i;
int mid=left+gap-1;
if(mid>=array.length){
mid=array.length-1;
}
int right=left+2*gap-1;
if(right>=array.length){
right=array.length-1;
}
merge(array,left,right,mid);
}
gap=gap*2;
}
}
//合并:合并两个有序数组
public static void merge(int[] array,int left,int right,int mid){
int[] tmp=new int[right-left+1];
int k=0;
int s1=left;
int e1=mid;
int s2=mid+1;
int e2=right;
while(s1<=e1&&s2<=e2){
if(array[s1]<=array[s2]){
tmp[k++]=array[s1++];
}else{
tmp[k++]=array[s2++];
}
}
while(s1<=e1){
tmp[k++]=array[s1++];
}
while(s2<=e2){
tmp[k++]=array[s2++];
}
for (int i = left; i <= right; i++) {
array[i]=tmp[i-left];
}
}五、排序算法的分析
| 排序方法 | 最好时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 稳定性 |
| 直接插入排序 | O(n) | O(n^2) | O(1) | 稳定 |
| 希尔排序 | O(n) | O(n^2) | O(1) | 不稳定 |
| 直接排序 | O(n^2) | O(n^2) | O(1) | 不稳定 |
| 堆排序 | O(nlog(2)n) | O(nlog(2)n) | O(1) | 不稳定 |
| 冒泡排序 | O(n) | O(n^2) | O(1) | 稳定 |
| 快速排序 | O(nlog(2)n) | O(n^2) | O(nlog(2)n) | 不稳定 |
| 归并排序 | O(nlog(2)n) | O(nlog(2)n) | O(n) | 稳定 |
위 내용은 7가지 종류의 Java 데이터 구조를 사용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7321
7321
 9
1625
14
1349
46
1261
25
1209
29
9
1625
14
1349
46
1261
25
1209
29



 Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기 안내. 여기서는 예제를 통해 Java의 함수와 예제를 통해 두 가지 다른 생성기에 대해 설명합니다.
 자바의 웨카
Aug 30, 2024 pm 04:28 PM
자바의 웨카
Aug 30, 2024 pm 04:28 PM
Java의 Weka 가이드. 여기에서는 소개, weka java 사용 방법, 플랫폼 유형 및 장점을 예제와 함께 설명합니다.
 자바의 암스트롱 번호
Aug 30, 2024 pm 04:26 PM
자바의 암스트롱 번호
Aug 30, 2024 pm 04:26 PM
자바의 암스트롱 번호 안내 여기에서는 일부 코드와 함께 Java의 Armstrong 번호에 대한 소개를 논의합니다.
 Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 Smith Number 가이드. 여기서는 정의, Java에서 스미스 번호를 확인하는 방법에 대해 논의합니다. 코드 구현의 예.
 Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
이 기사에서는 가장 많이 묻는 Java Spring 면접 질문과 자세한 답변을 보관했습니다. 그래야 면접에 합격할 수 있습니다.
 Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8은 스트림 API를 소개하여 데이터 컬렉션을 처리하는 강력하고 표현적인 방법을 제공합니다. 그러나 스트림을 사용할 때 일반적인 질문은 다음과 같은 것입니다. 기존 루프는 조기 중단 또는 반환을 허용하지만 스트림의 Foreach 메소드는이 방법을 직접 지원하지 않습니다. 이 기사는 이유를 설명하고 스트림 처리 시스템에서 조기 종료를 구현하기위한 대체 방법을 탐색합니다. 추가 읽기 : Java Stream API 개선 스트림 foreach를 이해하십시오 Foreach 메소드는 스트림의 각 요소에서 하나의 작업을 수행하는 터미널 작동입니다. 디자인 의도입니다
