

Python Redis 데이터 처리 방법

1. 서문
Redis: 원격 사전 서비스, 즉 Redis의 하위 계층은 C 언어로 작성되었습니다. 오픈 소스, 메모리 기반 NoSql 데이터베이스입니다.
Redis의 성능이 훨씬 뛰어납니다. 다른 데이터베이스와 클러스터를 지원하며, 분산 및 마스터-슬레이브 동기화의 장점을 가지고 있어 데이터 캐싱 및 고속 읽기/쓰기 등의 시나리오에서 자주 사용됩니다
2. 준비
설치를 맡아드립니다. 클라우드 서버 Centos 7.8의 Redis-Server를 예로
먼저 클라우드 서버 Redis 데이터베이스에 설치
# 下载epel仓库 yum install epel-release # 安装redis yum install redis
그런 다음 vim 명령을 통해 Redis 구성 파일을 수정하고 원격 연결을 열고 연결 비밀번호를 설정하세요
구성 파일 디렉터리: /etc/redis.conf
bind를 0.0.0.0으로 변경하여 외부 네트워크 접근을 허용합니다
requirepass 접근 비밀번호를 설정하세요
# vim /etc/redis.conf # 1、bing从127.0.0.1修改为:0.0.0.0,开放远程连接 bind 0.0.0.0 # 2、设置密码 requirepass 123456
클라우드 서버 데이터의 보안을 보장하려면 Redis가 원격 액세스를 열 때 비밀번호를 강화해야 합니다
그런 다음 Redis 서비스를 시작하고 방화벽과 포트를 열고 클라우드 서버 보안 그룹을 구성합니다
기본적으로 사용되는 포트 번호는 Redis 서비스는 6379입니다
또한 Redis 데이터베이스가 정상적으로 연결될 수 있도록 클라우드 서버 보안 그룹에서 구성해야 합니다
# 启动Redis服务,默认redis端口号是6379 systemctl start redis # 打开防火墙 systemctl start firewalld.service # 开放6379端口 firewall-cmd --zone=public --add-port=6379/tcp --permanent # 配置立即生效 firewall-cmd --reload
위 작업을 완료한 후 Redis-CLI 또는 Redis 클라이언트 도구를 사용할 수 있습니다 to connect
마지막으로 Python을 사용하여 Redis를 작동하려면 pip를 사용하여 종속성을 설치해야 합니다
# 安装依赖,便于操作redis pip3 install redis
3. 실용적인 전투
Redis에서 데이터를 작동하기 전에 호스트, 포트 번호, 비밀번호 인스턴스화를 사용해야 합니다. Redis 연결 개체
from redis import Redis
class RedisF(object):
def __init__(self):
# 实例化Redis对象
# decode_responses=True,如果不加则写入的为字节类型
# host:远程连接地址
# port:Redis端口号
# password:Redis授权密码
self.redis_obj = Redis(host='139.199.**.**',port=6379,password='123456',decode_responses=True,charset='UTF-8', encoding='UTF-8')다음으로 문자열, 목록, 집합 컬렉션, zset 컬렉션, 해시 테이블 및 트랜잭션의 작업을 예로 들어 Python에서 이러한 데이터를 작업하는 방법에 대해 설명합니다
1 문자열 작업
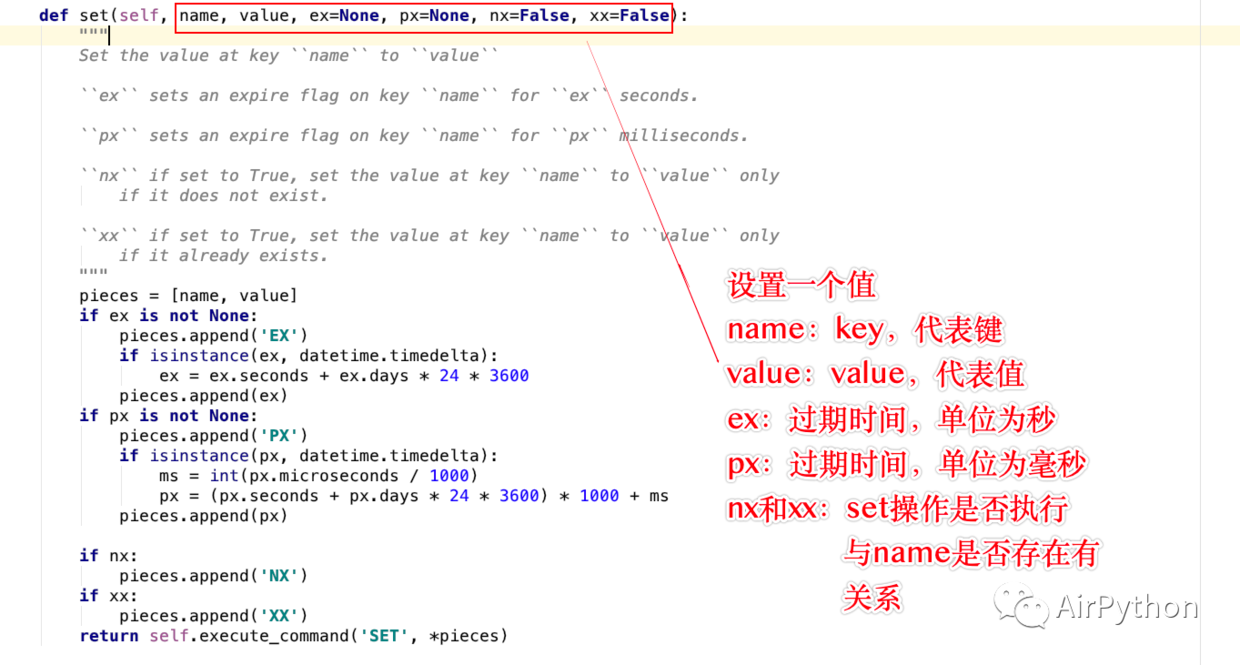
. 문자열을 연산하는 방법에는 두 가지가 있습니다. 연산 방법은 set()과 mset()
그 중 set()은 한 번에 하나의 값만 저장할 수 있습니다. 매개변수의 의미는 다음과 같습니다
이름. : key, 키를 나타냅니다
value: value, 저장할 값
ex: 만료 시간(초), 설정하지 않으면 절대 만료되지 않습니다. 그렇지 않으면 만료될 때 삭제됩니다.
- px: 만료 시간(밀리초) 단위
- nx/xx: 설정 작업의 실행 여부는 name 키의 존재 여부와 관련됩니다.
# set():单字符串操作 # 添加一个值,并设置超时时间为120s self.redis_obj.set('name', 'airpython', ex=120) # get():获取这个值 print(self.redis_obj.get('name')) # delete():删除一个值或多个值 self.redis_obj.delete('name') print(self.redis_obj.get('name'))
# mset():设置多个值
self.redis_obj.mset({"foo": "foo1", "zoo": "zoo1"})
# mget():获取多个值
result = self.redis_obj.mget("foo", "zoo")
print(result)- lpush/rpush: 목록의 헤드 또는 테일에 하나 이상의 값을 삽입합니다. 여기서 lpush는 데이터의 테일 삽입을 나타냅니다. lset: 인덱스를 통해 목록의 해당 위치에 값을 삽입
- linsert: 목록 요소 앞이나 뒤에 데이터 삽입
- lindex : 인덱스를 통해 목록의 요소를 얻습니다. 여기서 0은 첫 번째 요소를 나타냅니다. ; -1은 마지막 요소를 나타냅니다
- lrange: 시작 위치와 끝 위치를 지정하여 목록에서 지정된 영역의 값을 가져옵니다.
- llen: 해당 목록의 길이를 가져옵니다. 키가 존재하지 않으면 0
- lpop: 목록의 첫 번째 요소를 제거하고 반환
- rpop: 목록의 첫 번째 요소를 제거하고 반환 마지막 요소
- 예제 코드는 다음과 같습니다. :3. 작업 세트 컬렉션
def manage_list(self): """ 操作列表 :return: """ # 1、新增一个列表,并左边插入一个数据 # 注意:可以一次加入多个元素,也可以一个个元素的加入 self.redis_obj.lpush('company', '阿里', '腾讯', '百度') # 2、移除第一个元素 self.redis_obj.lpop("company") # 3、右边插入数据 self.redis_obj.rpush('company', '字节跳动', '小米') # 4、移除最后一个元素 self.redis_obj.rpop("company") # 5、获取列表的长度 self.redis_obj.llen("company") # 6、通过索引,获取列表中的某一个元素(第二个元素) print('列表中第二个元素是:', self.redis_obj.lindex("company", 1)) # 7、根据范围,查看列表中所有的值 print(self.redis_obj.lrange('company', 0, -1))로그인 후 복사
- smembers: 집합의 모든 요소를 반환합니다.
- srem: 집합에서 하나 이상의 요소를 제거하고 요소가 존재하지 않으면 무시합니다.
- sinter: 두 집합의 교집합을 반환합니다. 결과는 다음과 같습니다. still one Set
- sunion: 두 집합의 합집합을 반환합니다.
- sdiff: 첫 번째 집합 매개변수를 기준으로 사용하여 두 집합의 차이 집합을 반환합니다.
- sunionstore: 두 집합의 합집합을 계산합니다. 새 컬렉션에 저장
- sismember: 컬렉션에 요소가 존재하는지 확인
- spop: 컬렉션에서 요소를 무작위로 삭제하고 반환
- 구체적인 예제 코드는 다음과 같습니다.
- 4 , zset collection 운영Zset 컬렉션은 일반 세트 컬렉션과 비교하여 순서가 지정됩니다. zset 컬렉션의 요소에는 값과 점수가 포함되며, 점수는 정렬에 사용됩니다
zadd:往集合中新增元素,如果集合不存在,则新建一个集合,然后再插入数据
zrange:通过起始点和结束点,返回集合中的元素值(不包含分数);如果设置withscores=True,则返回结果会带上分数
zscore:获取某一个元素对应的分数
zcard:获取集合中元素个数
zrank:获取元素在集合中的索引
zrem:删除集合中的元素
zcount:通过最小值和最大值,判断分数在这个范围内的元素个数
hset:往哈希表中添加一个键值对值
hmset:往哈希表中添加多个键值对值
hget:获取哈希表中单个键的值
hmget:获取哈希表中多个键的值列表
hgetall:获取哈希表中种所有的键值对
hkeys:获取哈希表中所有的键列表
hvals:获取哈表表中所有的值列表
hexists:判断哈希表中,某个键是否存在
hdel:删除哈希表中某一个键值对
hlen:返回哈希表中键值对个数
首先,定义一个事务管道
然后通过事务对象去执行一系列操作
提交事务操作,结束事务操作
def manage_set(self):
"""
操作set集合
:return:
"""
self.redis_obj.delete("fruit")
# 1、sadd:新增元素到集合中
# 添加一个元素:香蕉
self.redis_obj.sadd('fruit', '香蕉')
# 再添加两个元素
self.redis_obj.sadd('fruit', '苹果', '桔子')
# 2、集合元素的数量
print('集合元素数量:', self.redis_obj.scard('fruit'))
# 3、移除一个元素
self.redis_obj.srem("fruit", "桔子")
# 再定义一个集合
self.redis_obj.sadd("fruit_other", "香蕉", "葡萄", "柚子")
# 4、获取两个集合的交集
result = self.redis_obj.sinter("fruit", "fruit_other")
print(type(result))
print('交集为:', result)
# 5、获取两个集合的并集
result = self.redis_obj.sunion("fruit", "fruit_other")
print(type(result))
print('并集为:', result)
# 6、差集,以第一个集合为标准
result = self.redis_obj.sdiff("fruit", "fruit_other")
print(type(result))
print('差集为:', result)
# 7、合并保存到新的集合中
self.redis_obj.sunionstore("fruit_new", "fruit", "fruit_other")
print('新的集合为:', self.redis_obj.smembers('fruit_new'))
# 8、判断元素是否存在集合中
result = self.redis_obj.sismember("fruit", "苹果")
print('苹果是否存在于集合中', result)
# 9、随机从集合中删除一个元素,然后返回
result = self.redis_obj.spop("fruit")
print('删除的元素是:', result)
# 3、集合中所有元素
result = self.redis_obj.smembers('fruit')
print("最后fruit集合包含的元素是:", result)其中,比较常用的方法如下:
实践代码如下:
def manage_zset(self):
"""
操作zset集合
:return:
"""
self.redis_obj.delete("fruit")
# 往集合中新增元素:zadd()
# 三个元素分别是:"banana", 1/"apple", 2/"pear", 3
self.redis_obj.zadd("fruit", "banana", 1, "apple", 2, "pear", 3)
# 查看集合中所有元素(不带分数)
result = self.redis_obj.zrange("fruit", 0, -1)
# ['banana', 'apple', 'pear']
print('集合中的元素(不带分数)有:', result)
# 查看集合中所有元素(带分数)
result = self.redis_obj.zrange("fruit", 0, -1, withscores=True)
# [('banana', 1.0), ('apple', 2.0), ('pear', 3.0)]
print('集合中的元素(带分数)有:', result)
# 获取集合中某一个元素的分数
result = self.redis_obj.zscore("fruit", "apple")
print("apple对应的分数为:", result)
# 通过最小值和最大值,判断分数在这个范围内的元素个数
result = self.redis_obj.zcount("fruit", 1, 2)
print("集合中分数大于1,小于2的元素个数有:", result)
# 获取集合中元素个数
count = self.redis_obj.zcard("fruit")
print('集合元素格式:', count)
# 获取元素的值获取索引号
index = self.redis_obj.zrank("fruit", "apple")
print('apple元素的索引为:', index)
# 删除集合中的元素:zrem
self.redis_obj.zrem("fruit", "apple")
print('删除apple元素后,剩余元素为:', self.redis_obj.zrange("fruit", 0, -1))4、操作哈希
哈希表中包含很多键值对,并且每一个键都是唯一的
Redis 操作哈希表,下面这些方法比较常用:
对应的操作代码如下:
def manage_hash(self):
"""
操作哈希表
哈希:一个键对应一个值,并且键不容许重复
:return:
"""
self.redis_obj.delete("website")
# 1、新建一个key为website的哈希表
# 往里面加入数据:baidu(field),www.baidu.com(value)
self.redis_obj.hset('website', 'baidu', 'www.alibababaidu.com')
self.redis_obj.hset('website', 'google', 'www.google.com')
# 2、往哈希表中添加多个键值对
self.redis_obj.hmset("website", {"tencent": "www.qq.com", "alibaba": "www.taobao.com"})
# 3、获取某一个键的值
result = self.redis_obj.hget("website", 'baidu')
print("键为baidu的值为:", result)
# 4、获取多个键的值
result = self.redis_obj.hmget("website", "baidu", "alibaba")
print("多个键的值为:", result)
# 5、查看hash表中的所有值
result = self.redis_obj.hgetall('website')
print("哈希表中所有的键值对为:", result)
# 6、哈希表中所有键列表
# ['baidu', 'google', 'tencent', 'alibaba']
result = self.redis_obj.hkeys("website")
print("哈希表,所有的键(列表)为:", result)
# 7、哈希表中所有的值列表
# ['www.alibababaidu.com', 'www.google.com', 'www.qq.com', 'www.taobao.com']
result = self.redis_obj.hvals("website")
print("哈希表,所有的值(列表)为:", result)
# 8、判断某一个键是否存在
result = self.redis_obj.hexists("website", "alibaba")
print('alibaba这个键是否存在:', result)
# 9、删除某一个键值对
self.redis_obj.hdel("website", 'baidu')
print('删除baidu键值对后,哈希表的数据包含:', self.redis_obj.hgetall('website'))
# 10、哈希表中键值对个数
count = self.redis_obj.hlen("website")
print('哈希表键值对一共有:', count)5、操作事务管道
Redis 支持事务管道操作,能够将几个操作统一提交执行
操作步骤是:
下面通过一个简单的例子来说明:
def manage_steps(self):
"""
执行事务操作
:return:
"""
# 1、定义一个事务管道
self.pip = self.redis_obj.pipeline()
# 定义一系列操作
self.pip.set('age', 18)
# 增加一岁
self.pip.incr('age')
# 减少一岁
self.pip.decr('age')
# 执行上面定义3个步骤的事务操作
self.pip.execute()
# 判断
print('通过上面一些列操作,年龄变成:', self.redis_obj.get('age'))위 내용은 Python Redis 데이터 처리 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7554
7554
 15
1382
52
83
11
59
19
28
96
15
1382
52
83
11
59
19
28
96

 Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python과 JavaScript는 커뮤니티, 라이브러리 및 리소스 측면에서 고유 한 장점과 단점이 있습니다. 1) Python 커뮤니티는 친절하고 초보자에게 적합하지만 프론트 엔드 개발 리소스는 JavaScript만큼 풍부하지 않습니다. 2) Python은 데이터 과학 및 기계 학습 라이브러리에서 강력하며 JavaScript는 프론트 엔드 개발 라이브러리 및 프레임 워크에서 더 좋습니다. 3) 둘 다 풍부한 학습 리소스를 가지고 있지만 Python은 공식 문서로 시작하는 데 적합하지만 JavaScript는 MDNWebDocs에서 더 좋습니다. 선택은 프로젝트 요구와 개인적인 이익을 기반으로해야합니다.
 파이썬 : 자동화, 스크립팅 및 작업 관리
Apr 16, 2025 am 12:14 AM
파이썬 : 자동화, 스크립팅 및 작업 관리
Apr 16, 2025 am 12:14 AM
파이썬은 자동화, 스크립팅 및 작업 관리가 탁월합니다. 1) 자동화 : 파일 백업은 OS 및 Shutil과 같은 표준 라이브러리를 통해 실현됩니다. 2) 스크립트 쓰기 : PSUTIL 라이브러리를 사용하여 시스템 리소스를 모니터링합니다. 3) 작업 관리 : 일정 라이브러리를 사용하여 작업을 예약하십시오. Python의 사용 편의성과 풍부한 라이브러리 지원으로 인해 이러한 영역에서 선호하는 도구가됩니다.
 터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
vs 코드에서는 다음 단계를 통해 터미널에서 프로그램을 실행할 수 있습니다. 코드를 준비하고 통합 터미널을 열어 코드 디렉토리가 터미널 작업 디렉토리와 일치하는지 확인하십시오. 프로그래밍 언어 (예 : Python의 Python Your_file_name.py)에 따라 실행 명령을 선택하여 성공적으로 실행되는지 여부를 확인하고 오류를 해결하십시오. 디버거를 사용하여 디버깅 효율을 향상시킵니다.
 VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VS 코드 확장은 악의적 인 코드 숨기기, 취약성 악용 및 합법적 인 확장으로 자위하는 등 악성 위험을 초래합니다. 악의적 인 확장을 식별하는 방법에는 게시자 확인, 주석 읽기, 코드 확인 및주의해서 설치가 포함됩니다. 보안 조치에는 보안 인식, 좋은 습관, 정기적 인 업데이트 및 바이러스 백신 소프트웨어도 포함됩니다.
 VScode 란 무엇입니까?
Apr 15, 2025 pm 06:45 PM
VScode 란 무엇입니까?
Apr 15, 2025 pm 06:45 PM
VS Code는 Full Name Visual Studio Code로, Microsoft가 개발 한 무료 및 오픈 소스 크로스 플랫폼 코드 편집기 및 개발 환경입니다. 광범위한 프로그래밍 언어를 지원하고 구문 강조 표시, 코드 자동 완료, 코드 스 니펫 및 스마트 프롬프트를 제공하여 개발 효율성을 향상시킵니다. 풍부한 확장 생태계를 통해 사용자는 디버거, 코드 서식 도구 및 GIT 통합과 같은 특정 요구 및 언어에 확장을 추가 할 수 있습니다. VS 코드에는 코드에서 버그를 신속하게 찾아서 해결하는 데 도움이되는 직관적 인 디버거도 포함되어 있습니다.
 vScode를 Mac에서 사용할 수 있습니다
Apr 15, 2025 pm 07:45 PM
vScode를 Mac에서 사용할 수 있습니다
Apr 15, 2025 pm 07:45 PM
VS 코드는 MACOS에서 잘 수행되며 개발 효율성을 향상시킬 수 있습니다. 설치 및 구성 단계에는 다음이 포함됩니다. 설치 대 코드 및 구성. 언어 별 확장 (예 : JavaScript 용 Eslint)을 설치하십시오. 과도한 스타트 업이 느려지는 것을 피하려면 확장 기능을주의 깊게 설치하십시오. GIT 통합, 터미널 및 디버거와 같은 기본 기능을 배우십시오. 적절한 테마와 코드 글꼴을 설정하십시오. 참고 잠재적 문제 : 연장 호환성, 파일 권한 등
 Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
 Redis를 구축하는 방법
Apr 15, 2025 am 07:42 AM
Redis를 구축하는 방법
Apr 15, 2025 am 07:42 AM
Docker는 서비스의 보안, 휴대 성 및 확장 성을 보장하기 위해 Redis Containerization을 구현하는 기술입니다. 전제 조건 : Docker 설치 및 Redis 이미지. 단계 : 명령 줄 Docker Run을 실행하여 Redis 컨테이너를 만듭니다. Redis 클라이언트 또는 명령 줄을 사용하여 컨테이너에 연결하십시오. 명령 줄을 통해 컨테이너를 시작/중지/다시 시작합니다. 로그를 보거나 컨테이너를 삭제하십시오.
