

where(선택/업데이트/삭제가 가능한 곳) 이후에 필터 필드에 인덱스를 생성하고, 전체 테이블 스캔을 수행하지 않고 인덱스를 사용하여 필터링 효율성을 높일 수 있습니다.
다음의 경우 고유 요구 사항 필드에 고유 인덱스를 추가하면 쿼리 효율성이 향상됩니다. 찾으면 바로 반환할 수 있습니다.
인덱스가 정렬되어 있으므로 해당 필드에 인덱스를 추가하세요. index는 이미 쿼리한 것과 동일합니다. (여기서 특정 사례 시나리오 7과 결합하여 연구할 수 있는 공동 인덱스 설정 시 필드 순서에 주의해야 합니다.)
다음에 인덱스를 추가합니다. DISTINCT(필드 제거) 이후의 필드입니다. 그러면 동일한 데이터가 서로 옆에 있으므로 빠르게 중복 제거 작업을 수행할 수 있습니다. 그렇지 않으면 동일한 데이터를 찾아 중복 제거 작업을 수행해야 할 수도 있습니다
여러 테이블 조인 시 연결된 필드에 인덱스 생성(작은 테이블이 큰 테이블을 구동함)
문자열의 특정 접두사를 사용하여 인덱스를 생성합니다(전체 문자열을 인덱스로 사용하지 마십시오. 그렇지 않으면 공간이 너무 많음)
자주 사용하는 열에 인덱스를 생성합니다. (결합 인덱스를 설정할 수 있으며 가장 자주 사용되는 필드는 결합 인덱스의 가장 왼쪽에 있어야 한다는 원칙이 가장 왼쪽에 있습니다.)
만들기 구별 정도가 높은 열의 인덱스(모든 키가 모두 고유하기 때문에 기본 키의 구별 정도가 가장 높습니다)
시나리오 1: where 뒤의 필드에 인덱스 만들기 field
-- 描述:当where中有多个条件需要进行匹配的时候,那么可以创建联合索引,这样所有的条件都可以使用索引,大大提高了检索的效率 select * from student_info where student_id = 1; -- 当然数据量比较大的时候给where后面的字段添加索引 create index student_id_index on student_info (student_id)
인덱스 추가 전 0.383초 소요, 기본적으로 테이블 전체 순회

인덱스 추가 후 0.001초 소요, 인덱스 사용(단, 테이블 생성에는 일정 시간 소요) index)
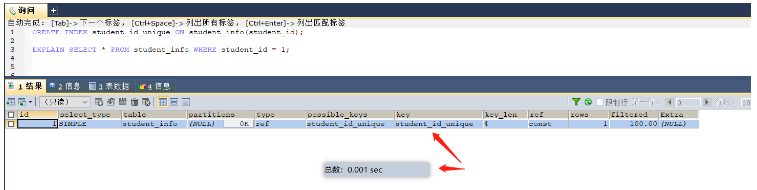
Where로 필터링된 필드에 대해 인덱스를 생성할 수 있습니다. 고유 제약 조건이 있는 필드의 고유 인덱스(검색을 계속하지 않고 대상을 찾아 반환)
select * from student_info where id = 1001; -- 因为学号是唯一的,所以可以在学号这个字段上添加唯一所用 create index id_unique on student_info(id);
고유 인덱스가 생성되더라도 고유 제약 조건이 있는 필드에 고유 인덱스를 설정할 수 있습니다. 인덱스는 삽입 작업에 특정 영향을 미칩니다( 새로 추가된 데이터가 이미 테이블에 있는지 확인해야 하지만 고유 인덱스를 설정하면 쿼리 효율성이 크게 향상됩니다. 예를 들어 위의 예에서는 고유 인덱스가 설정되었으므로 해당 ID를 찾은 후에는 학생 정보가 1001이면 데이터베이스에 ID가 1001인 학생이 있는지 여부를 판단할 필요가 없으며(사본이 하나만 있음) 인덱스가 설정되지 않은 경우 해당 정보를 직접 반환할 수 있습니다. 전체 테이블 스캔이 필요합니다
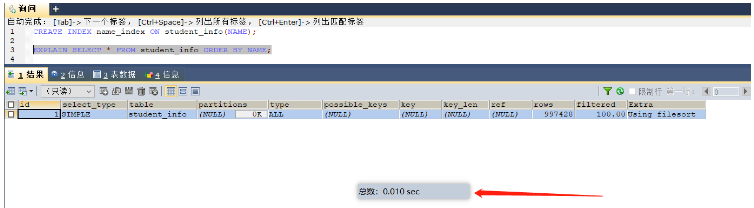
시나리오 3: 그룹 기준 및 순서 기준 필드에서 인덱스가 생성되는 경우가 많습니다(인덱스 자체가 정렬되어 있기 때문에 이는 쿼리 전 정렬과 동일함)
select * from student_info order by name; -- 这里就可以给name字段进行索引的添加 select * from student_info group by class_id; -- 这里就可以给class_id字段添加索引
인덱스를 빌드하기 전에 0.501이 소요됩니다. 초, 메모리에 있는 모든 데이터 사용 중 정렬
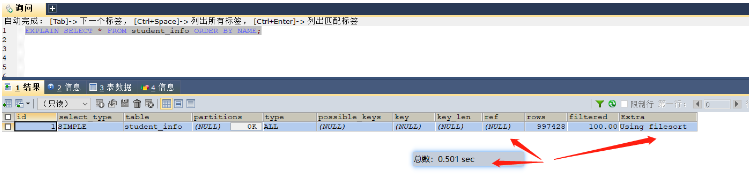 인덱스 생성 후 0.01초 소요
인덱스 생성 후 0.01초 소요
 시나리오 4: DISTINCT 이후 필드에 인덱스 추가(인덱스는 이미 동일한 필드를 정렬했으며, 중복 제거를 더욱 효율적으로 만들기)
시나리오 4: DISTINCT 이후 필드에 인덱스 추가(인덱스는 이미 동일한 필드를 정렬했으며, 중복 제거를 더욱 효율적으로 만들기)
select distinct(student_id) from student_info; -- 这里就可以根据student_id字段建立索引 create index student_id_index on student_info;
일단 인덱스가 설정되면 기본적으로 인덱스 필드의 오름차순으로 정렬되며 동일한 값을 가진 필드가 함께 정렬되므로 중복 제거가 간단하고 효율적이 됩니다
시나리오 5: 여러 테이블을 조인하여 대형 테이블 연결 연결 필드가 인덱스되었습니다
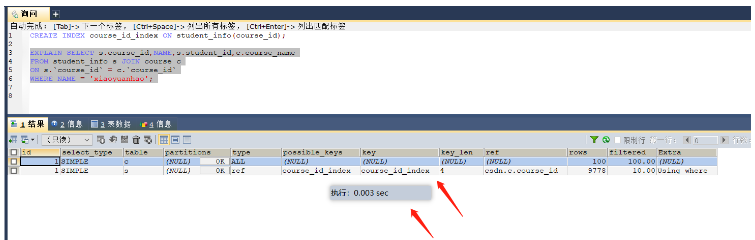
SELECT s.course_id,NAME,s.student_id,c.course_name FROM student_info s JOIN course c ON s.`course_id` = c.`course_id` WHERE NAME = 'xiaoyuanhao'; -- 根据大表驱动小表的原则需要在student_info表的course_id字段上建立索引
인덱스가 생성되기 전 0.697s가 걸렸습니다.인덱스가 없을 때
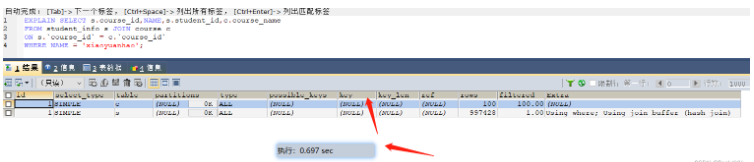 인덱스가 생성된 후 인덱스가 사용되었고 0.003s가 걸렸습니다
인덱스가 생성된 후 인덱스가 사용되었고 0.003s가 걸렸습니다
 작은 테이블이 큰 테이블을 운전하는 것:
작은 테이블이 큰 테이블을 운전하는 것:
작은 테이블을 하나씩 순회하고 큰 테이블의 연결 필드에 인덱스를 생성하면 이 경우 강좌의course_id가 매번 쿼리 속도를 높일 수 있습니다. 연결 작업을 위해 테이블과 학생 테이블의 school_id를 꺼내고 학생 테이블의 Course_id를 연결합니다. Course_id를 인덱스할 수 있습니다
시나리오 6: 문자열의 접두사를 사용하여 인덱스를 생성합니다
create table shop(address varchar(120) not null); alter table shop add index(address(12)); --这里只是对表中的address的前12个字符建立了索引,而不是整个字符串建立索引
접두사 색인을 하는 이유:
如何确定前缀索引中前缀的长度呢?(也就是如果前缀的长度太短,那么索引的区分度就很低,从多个字符串截取的前缀数据可能都是一样的,但是如果前缀索引的前缀过长,那么前缀索引的优点就消失了)
引入了区别度的概念,select count(distinct left(索引字段,前缀索引长度) / count(*) from xxx),该值越接近1,那么区分度就越明显,那么该索引长度就是所求的前缀索引长度
场景七:在频繁使用的列上建立索引或联合索引(频繁使用的字段应该在索引的左侧)
select * from xiaoyuanhao where age = 18; select * from xiaoyuanhao where age = 19 and sex = 'man'; select * from xiaoyuanhao where age = 10 and sex = 'man' and password = '123456'; -- 在这里实际上就可以建立age,sex,password的联合索引,只需要建立一个索引,这三个查询都是可以使用的 create index age_sex_password_index on xiaoyuanhao(age,sex,password); select * from student_info group by class_id order by name; -- 在这里可以建立class_id和name的联合索引,但是一定要注意索引的顺序,一定是要class_id在前,name在后,因为在select语句中执行的顺序是先group by 之后才是 order by 索引如果索引的字段顺序是相反的,那么就无法使用索引 create index class_id_name_index on student(class_id,name);
索引建立需要符合顺序的原因:
索引字段的顺序如果是错误的,那么索引就会失效,因为索引实际上是排好序的,如果索引建立的时候是现根据name排好序之后在根据class_id进行排序,那么在面对需要先根据class_id排序再根据name排序的业务就无法进行使用
补充:
在select * from xxx where age = 19 and sex = ‘man’ and password = '123456’这里索引建立的顺序不一定是(age,sex,password)因为在实际执行的过程中,优化器会优化执行步骤会按照索引的顺序进行查询,但是group by 和 order by的执行顺序是无法改变的,索引必须严格的按照顺序建立索引,否则索引失效
위 내용은 MySQL 인덱스 최적화가 인덱스 구축에 적합한 상황은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



