
백엔드 개발자의 경우 단일 SQL을 사용하여 목록 쿼리 인터페이스를 구현할 수 있습니다. 쿼리 조건이 복잡하고 테이블 데이터베이스 설계가 불합리한 경우 이 문서에서는 Redis 사용 방법을 공유합니다. 검색 인터페이스를 구현합니다.
예를 들어보겠습니다. 쇼핑 웹사이트의 검색 조건입니다. 이러한 검색 인터페이스를 구현하라고 하면 어떻게 구현하시겠습니까?
물론 검색 엔진의 도움으로 그렇게 말씀하셨죠? Elasticsearch라면 반드시 해낼 수 있습니다. 그런데 여기서 하고 싶은 말은, 직접 구현해 보고 싶다면?

위 그림에서 볼 수 있듯이 검색은 크게 6가지 카테고리로 나뉘고, 각 메이저 카테고리는 하위 카테고리로 나누어져 있습니다.
이 경우 필터링 프로세스는 다양한 주요 조건 범주의 교차점을 취하고 각 하위 범주의 단일 선택, 다중 선택 및 사용자 정의를 고려하여 조건을 충족하는 결과 집합을 출력합니다.
자, 이제 요구사항이 명확해졌으니 구현을 시작해 보겠습니다.
구현 1
가장 먼저 등장한 학생 A입니다. 그는 SQL 작성의 "전문가"입니다. Little A는 "단순한 쿼리 인터페이스 아닌가요? 조건이 많지만 풍부한 SQL 경험으로 인해 문제가 되지 않습니다."라고 자신있게 말했습니다.
그래서 저는 다음과 같은 코드 조각을 작성했습니다(MySQL을 예시는 여기):
select ... from table_1 left join table_2 left join table_3 left join (select ... from table_x where ...) tmp_1 ... where ... order by ... limit m,n
테스트 환경에서 코드를 실행했는데, 결과가 일치하는 것 같아서 사전 출시 준비가 되었습니다. 이번 사전 출시로 인해 문제가 나타나기 시작했습니다.
사전 출시는 온라인 환경을 최대한 현실적으로 만들기 위한 것이므로 당연히 테스트보다 데이터 양이 훨씬 많습니다. 따라서 이러한 복잡한 SQL의 경우 실행 효율성을 상상할 수 있습니다. 시험 동급생은 과감하게 Little A의 코드를 다시 입력했습니다.
구현 2
Little A의 실패에서 배운 교훈을 요약했습니다. Little B는 SQL 최적화를 시작했습니다. 먼저 explain 키워드를 전달하여 SQL 성능 분석을 수행하고, 인덱스가 추가된 곳에 인덱스를 추가했습니다.
복잡한 SQL을 동시에 여러 SQL로 분할하면 계산 결과가 프로그램 메모리에서 계산됩니다.
의사 코드는 다음과 같습니다.
$result_1 = query('select ... from table_1 where ...');
$result_2 = query('select ... from table_2 where ...');
$result_3 = query('select ... from table_3 where ...');
...
$result = array_intersect($result_1, $result_2, $result_3, ...);이 솔루션은 성능 측면에서 첫 번째 솔루션보다 확실히 훨씬 낫지만 기능 승인 중에 제품 관리자는 여전히 쿼리 속도가 충분히 빠르지 않다고 느꼈습니다.
Little B 자신도 모든 쿼리가 데이터베이스에 여러 번 쿼리된다는 것을 알고 있으며, 일부 역사적 이유로 특정 조건에서는 단일 테이블 쿼리를 수행할 수 없으므로 쿼리 대기 시간이 불가피합니다.
구현 3
Little C는 위 솔루션에서 최적화할 여지가 있다고 봅니다. 그는 Little B가 자신의 생각에 문제가 없음을 발견하고 복잡한 조건을 분할하고 각 하위 차원의 결과 집합을 계산한 다음 최종적으로 모든 하위 결과 집합을 요약하고 병합하여 최종 원하는 결과를 얻었습니다.
그래서 그는 갑자기 각 하위 차원의 결과 집합을 미리 캐시할 수 있는지에 대해 생각했습니다. 이렇게 하면 매번 계산을 위해 데이터베이스를 확인할 필요 없이 쿼리할 때 원하는 하위 집합을 직접 가져올 수 있습니다.
여기서 Little C는 Redis를 사용하여 캐시 데이터를 저장합니다. 이를 사용하는 주된 이유는 다양한 데이터 구조를 제공하고 Redis에서 집합에 대한 교차 및 합집합 연산을 수행하는 것이 매우 쉽다는 것입니다.
구체적인 계획은 그림과 같습니다.
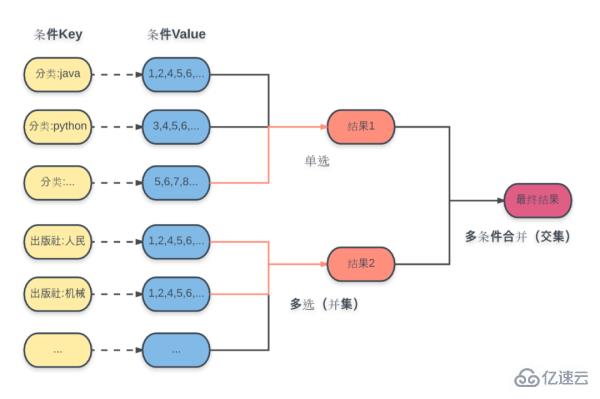
여기서 각 조건에 대해 계산된 결과 집합 ID가 해당 Key에 미리 저장되어 있으며 선택한 데이터 구조가 Set됩니다.
쿼리 작업에는 다음이 포함됩니다.
하위 카테고리 라디오 선택: 조건 키를 기반으로 해당 결과 세트를 직접 얻습니다.
하위 카테고리 다중 선택: 여러 조건 키를 기반으로 합집합 연산을 수행하여 해당 결과 집합을 얻습니다.
최종 결과: 획득된 모든 하위 범주 결과 집합에 대해 교차 연산을 수행하여 최종 결과를 얻습니다.
이것이 사실 소위 역지수입니다. 여기에서 가격 조건이 누락되었음을 확인할 수 있습니다. 수요량을 보면 가격조건이 범위이고 무한하다는 것을 알 수 있다.
그래서 위의 전체 조건을 갖춘 Key-Value 방법은 불가능합니다. 여기서는 Redis의 Ordered Set(Sorted Set)의 데이터 구조를 사용하여
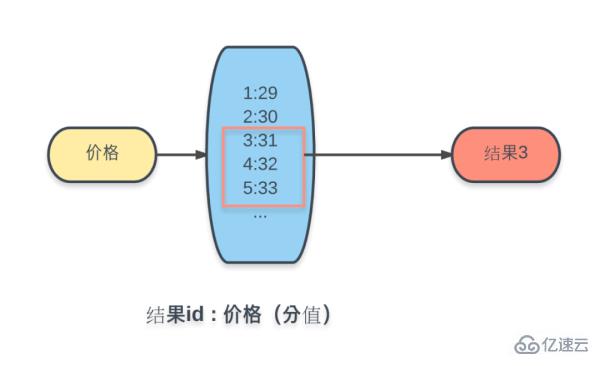
키가 가격이고 값이 제품 ID이며 각 값이 다음에 해당하는 Ordered 세트에 모든 제품을 추가합니다. 점수는 다음과 같습니다. 제품 가격의 수치입니다.
이와 같이 Redis의 Ordered Set에서는 ZRANGEBYSCORE 명령을 사용하여 점수(가격) 범위에 따라 해당 결과 세트를 얻을 수 있습니다.
이 시점에서 플랜 3의 최적화가 완료되었으며, 캐싱을 통해 데이터 쿼리와 계산이 분리되었습니다.
검색할 때마다 Redis를 몇 번만 검색하면 결과를 얻을 수 있습니다. 쿼리 속도가 승인 요구 사항을 충족합니다.
Extension
①Paging
여기에서 심각한 기능적 결함을 발견했을 수 있습니다. 어떻게 목록 쿼리에 페이징이 없을 수 있습니까? 네, Redis가 페이징을 구현하는 방법을 바로 살펴보겠습니다.
페이지네이션에는 주로 정렬이 포함됩니다. 단순화를 위해 생성 시간을 예로 들어보겠습니다. 그림과 같이
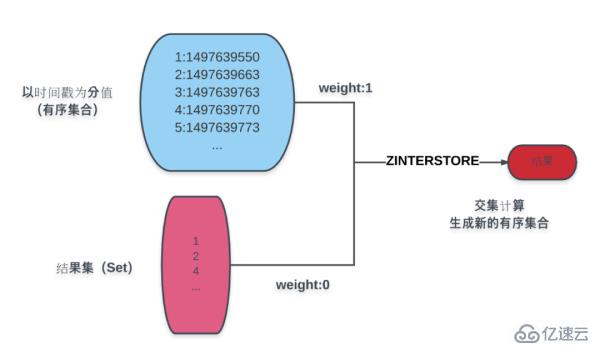
그림의 파란색 부분은 생성 시간을 기준으로 정렬된 제품 모음입니다. 파란색 아래의 결과 집합은 ZINTERSTORE 명령을 통해 할당된 결과입니다. 가중치는 0, 곱의 시간 결과는 1이고, 교차점을 취하여 얻은 결과 집합을 주어 새로운 시간 점수 집합을 생성합니다.
새 결과 세트에 대한 작업을 수행하면 페이징에 필요한 다양한 데이터를 얻을 수 있습니다.
총 페이지 수는 ZCOUNT 명령입니다.
현재 페이지 콘텐츠: ZRANGE 명령.
역순으로 정렬한 경우: ZREVRANGE 명령.
②데이터 업데이트
인덱스 데이터 업데이트 문제와 관련하여 진행 방법은 두 가지가 있습니다. 하나는 제품 데이터 수정을 통해 즉시 업데이트 작업을 시작하는 것이고, 다른 하나는 예약된 스크립트를 통해 일괄 업데이트를 수행하는 것입니다.
여기서 주의할 점은 인덱스 내용 업데이트와 관련하여 무리하게 키를 삭제한 경우에는 키를 재설정해야 한다는 점입니다.
Redis의 두 작업은 원자적으로 수행되지 않으므로 사이에 간격이 있을 수 있으므로 컬렉션에서 잘못된 요소만 제거하고 새 요소를 추가하는 것이 좋습니다.
3성능 최적화
Redis는 메모리 수준 작업이므로 단일 쿼리가 매우 빠릅니다. 그러나 우리 구현에서 여러 Redis 작업을 수행하는 경우 여러 Redis 연결 시간이 불필요한 시간 소모가 될 수 있습니다.
MULTI 명령을 사용하여 트랜잭션을 시작하고 여러 Redis 작업을 하나의 트랜잭션에 넣은 다음 마지막으로 EXEC를 통해 원자 실행을 수행합니다.
참고: 여기서 소위 트랜잭션은 하나의 연결에서만 여러 작업을 실행합니다. 실행 중에 오류가 발생하면 롤백되지 않습니다.
요약
이것은 Redis를 사용하여 쿼리 검색을 최적화하는 간단한 데모입니다. 기존 오픈 소스 검색 엔진에 비해 더 가볍고 그에 따라 학습 비용도 저렴합니다.
둘째, 일부 아이디어는 오픈소스 검색 엔진과 유사합니다. 단어 분석을 추가하면 전체 텍스트 검색과 유사한 기능도 구현할 수 있습니다.
위 내용은 Redis를 사용하여 검색 인터페이스를 구현하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



