

MySql 인덱스를 만드는 방법

1. B+ 트리 인덱스
이름에서 알 수 있듯이 B+ 트리 구조의 인덱스는 일반적인 상황에서 InnoDb 엔진에서 생성되는 일반 인덱스는 B+ 구조를 갖습니다.
B+ 트리 인덱스는 다음과 같습니다.
1.1. 클러스터형 인덱스/클러스터형 인덱스
기본 키를 정의할 때 기본 키에 자동으로 추가되는 인덱스는 클러스터형 인덱스라고도 합니다.
Mysql에서는 구성요소를 사용하여 B+ 트리 구조를 구성합니다. 그림에 표시된 것처럼 각 리프 노드는 기본 키 및 기타 관련 데이터에 해당합니다.
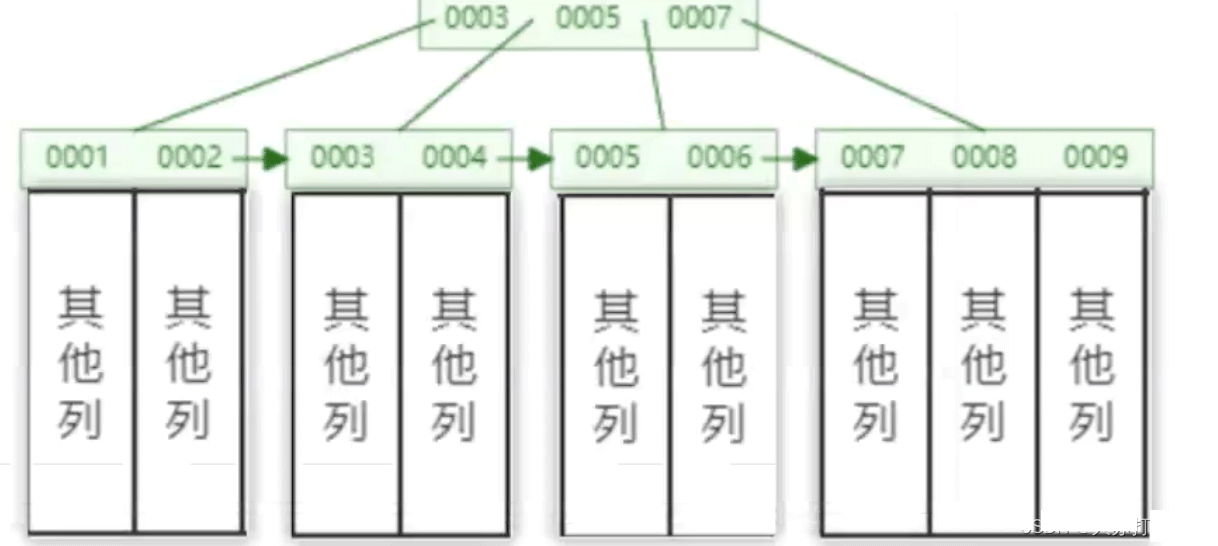
테이블 생성 시 기본 키를 정의하지 않으면 MySQL은 자동으로 기본 키와 해당 인덱스를 생성합니다. 기본 키 이름은 rowIdrowId
1.2、辅助索引/二级索引
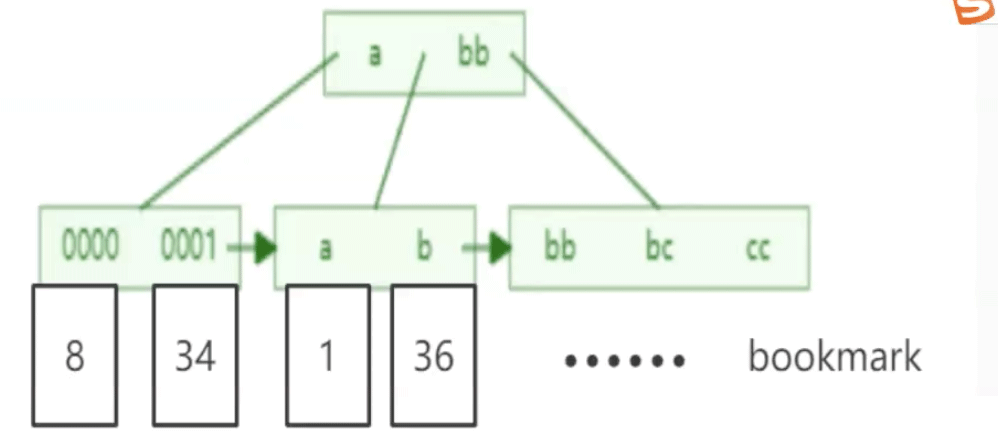
辅助索引,也称为二级索引,是指对于非主键列column创建的索引。同样的,Mysql会为这个索引创建一个B+树,树的叶子节点除了包含这个列column的值以外,就只包含这个列所在行的主键值,这样通过列的索引就可以查到叶子节点,然后叶子节点中的主键信息再从主键的索引中搜索,最终得到一整行的数据。
通过二级索引找到主键,再从主键得到一整行数据的行为叫做回表。
1.3、联合索引/复合索引
1.3.1、什么是复合索引
聚合索引可以说是二级索引的一种特殊情况。一般二级索引都是只对一个非主键的列添加索引,而聚合索引则是一次性对多个列同时添加索引。
一般的二级索引用这样的语句创建:
1 |
|
复合索引则是这样创建:
1 |
|
对于复合索引,Mysql会也会创建一个B+树,但因为是多个列的索引,所以B+树的排序规则比较特殊,是遵循最左原则。下面会讲到什么是最左原则。
之后叶子节点包含的信息有多个,一个是作为索引的各个列的值,另一个就是主键的值。
1.3.2、最左原则
所谓的最左原则是,B+树的排序规则是根据索引定义时,定义的语句中的列名从左到右进行排序。
比如定义语句如下:
1 |
|
那排序规则是先排order_name,如果order_name相同,再排order_type,最后排submit_time。
那当我们查询时,根据定义时列的顺序从左至右,where子句或者order by等子句应该尽量先从order_name开始,然后以此类推。
比如说,我们已经定义了上面的三个列组成的复合索引,那查询或者排序的时候尽量先order_name,再order_type,最后submit_time。
1 2 3 |
|
原因很简单,因为联合索引的排序规则是先排order_name,如果order_name相同,再排order_type,最后排submit_time。所以只有查询排序时也遵循这个规则,我们才能用上索引。
如果我们不完全遵守最左原则,比如查询排序只排两个列,忽略中间那个order by order_name, submit_time。那这个时候Mysql会有智能化的处理,他会自己判断是用索引快还是不用索引快。
1.3.3、联合索引的查询优化
尽量使用到组成联合索引的列,并且保证顺序。可以通过查询索引查看列的顺序。查看sql_in_index
1 |
|

查询返回的字段尽量就只返回组成联合索引的列和主键,不要返回其它的列,以免造成回表。
这应该容易理解,因为联合索引的B+树的叶子节点就只包含主键和组成联合索引的列的值,如果返回的字段就这几列,那在一个B+树种查询就完事了。如果还要返回其它的列的话,就又要去主键的索引中查找,有回表操作。
2、哈希索引
一般数据库都会用B+树索引查询数据,但是当数据库使用一段时间后,InnoDB 会记录一些使用频率较高的热数据,然后为这些热数据建立哈希结构的索引,这就是哈希索引的应用场景。
这个索引在Mysql 5.7开始默认开启。
2.1、查看哈希索引的命中率等信息
使用语句:
1 |
|

其中的status
🎜🎜1.3, 조인트 인덱스/ 복합지수 🎜1.3.1. 복합지수란 무엇인가요?
🎜집계지수는 보조지수의 특별한 경우라고 할 수 있습니다. 일반적으로 보조 인덱스는 기본 키가 아닌 하나의 열에만 인덱스를 추가하는 반면, 집계 인덱스는 한 번에 여러 열에 인덱스를 추가합니다. 🎜🎜일반 보조 인덱스는 다음 명령문으로 생성됩니다:🎜1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
1 |
|
1.3.2. 최좌측 원칙
🎜 소위 B+ 트리의 정렬 규칙은 인덱스가 정의될 때 정의된 문의 열 이름을 왼쪽에서 오른쪽으로 정렬하는 것입니다. . 🎜🎜예를 들어 정의문이 다음과 같은 경우: 🎜1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
order_name을 먼저 정렬하는 것이고, order_name이 동일하고 order_type< /code>을 정렬하면 마지막 행은 <code>submit_time입니다. 🎜🎜그런 다음 쿼리할 때 정의에 따라 왼쪽에서 오른쪽으로 열의 순서에 따라 where 절 또는 order by 및 기타 절이 시작되도록 시도해야 합니다. order_name Start 등으로. 🎜🎜예를 들어, 위의 세 열로 구성된 복합 인덱스를 정의했습니다. 쿼리하거나 정렬할 때 먼저 order_name을 시도한 다음 order_type을 시도하고 마지막으로 를 시도합니다. submit_time. 🎜1 |
|
order_name을 먼저 정렬하고 order_name이 동일하면 order_type<을 정렬하는 것이기 때문입니다. /code>, 마지막으로 < code>submit_time입니다. 따라서 쿼리 정렬 시 이 규칙을 준수해야만 인덱스를 사용할 수 있습니다. 🎜🎜예를 들어, 가장 왼쪽 원칙을 완전히 준수하지 않으면 쿼리 정렬은 가운데 order by order_name, submit_time을 무시하고 두 개의 열만 정렬합니다. 이때 Mysql은 지능적인 처리 기능을 갖게 되며 인덱스를 사용하는 것이 더 빠른지 여부를 판단하게 됩니다. 🎜1.3.3.결합 인덱스 쿼리 최적화
🎜 결합 인덱스를 구성하는 열을 사용하고 순서를 보장해 보세요. 컬럼의 순서는 인덱스를 쿼리하여 확인할 수 있습니다. sql_in_index🎜1 2 3 4 5 6 7 8 9 10 |
|
🎜🎜쿼리가 반환됨 보기 fields 공동 인덱스를 구성하는 열과 기본 키만 반환하고 테이블 백업을 피하기 위해 다른 열은 반환하지 마십시오. 조인 인덱스의 B+ 트리의 리프 노드에는 기본 키와 조인트 인덱스를 구성하는 열의 값만 포함되므로 이해하기 쉽습니다. 열이면 B+ 트리의 쿼리가 완료됩니다. 다른 컬럼을 반환하려면 기본키의 인덱스를 검색하여 테이블 반환 작업을 수행해야 합니다. 🎜🎜2. 해시 인덱스🎜🎜일반 데이터베이스는 B+ 트리 인덱스를 사용하여 데이터를 쿼리하지만, 데이터베이스를 일정 기간 동안 사용하면 InnoDB는 더 자주 사용되는 일부 핫 데이터를 기록한 다음 이에 대한 해시 구조 인덱스를 생성합니다. 이러한 핫 데이터는 해시 인덱스의 적용 시나리오입니다. 🎜🎜이 인덱스는 Mysql 5.7부터 기본적으로 활성화되어 있습니다. 🎜🎜2.1. 해시 인덱스의 적중률 및 기타 정보를 확인하세요. 🎜🎜사용 설명: 🎜
1 |
|
 🎜🎜
🎜🎜상태에는 해시 인덱스를 비롯한 많은 정보가 포함되어 있습니다. 정보를 편집기에 복사하여 봅니다. 이 섹션은 해시 인덱스 정보입니다. 🎜1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
3、索引的创建策略
3.1、 单列索引的策略
3.1.1、列的类型占用的空间越小,越适合作为索引
因为B+树也是占用空间的,所以在固定空间中,如果列的类型占用的空间越小,那我们一次就能读取更多的B+树节点,这样自然就加快了效率。
3.1.2、根据列的值的离散性
离散性是指数据的值重复的程度高不高,假如有N条数据的话,那离散性就可以用数值表示,范围是1/N 到 1。
比如说某个列在数据库中有下面几条数据(1, 2, 3, 4, 5, 5, 3),其中5和3都有重复,去重后应该是(1, 2, 3, 4, 5)。我们将去重后的条数除以总条数就得到离散性。这里是5/7。列中重复数据较多时,对应的数值较小,而重复数据较少时,数值相应较大。
如果一个列的数据的重复性越低,那么这个列就越适合加索引。
因为索引是需要起到筛选的作用。比如我们有个where条件是where id = 1,如果数据重复性较高,那可能根据索引会返回100条数据,然后我们在根据其他where条件在100条数据中再筛选。
如果数据重复性较低,那可能就只返回1条数据,那之后的运算量明显小得多。
所以一个列的数据离散性越高,那这个列越适合添加索引。
我们可以用下面的语句得到某个列的离散性程度。
1 |
|
3.1.3、前缀索引
前缀索引和后缀索引:
有些列的值比较长,比如一些备注日志信息也会记录在数据库当中,这类信息的长度往往比较长,如果我们需要对这类列加索引,那索引并不是索引字符串的全部长度。这时候我们就可以建立前缀索引,即对字符串的前面几位建立索引。
所以前缀索引就是建立范围更小索引,选择一个好前缀位数就能有一个更好的查询效率。
不过有一些缺点,就是这类索引无法应用到order by和group语句上。
Mysql没有后缀索引,如果非要实现后缀索引,那在数据存储时我们应该将数据反转,这样就能用前缀索引达到后缀索引的效果。后缀索引的一个经典应用就是邮箱,快速查询某种类型的邮箱。
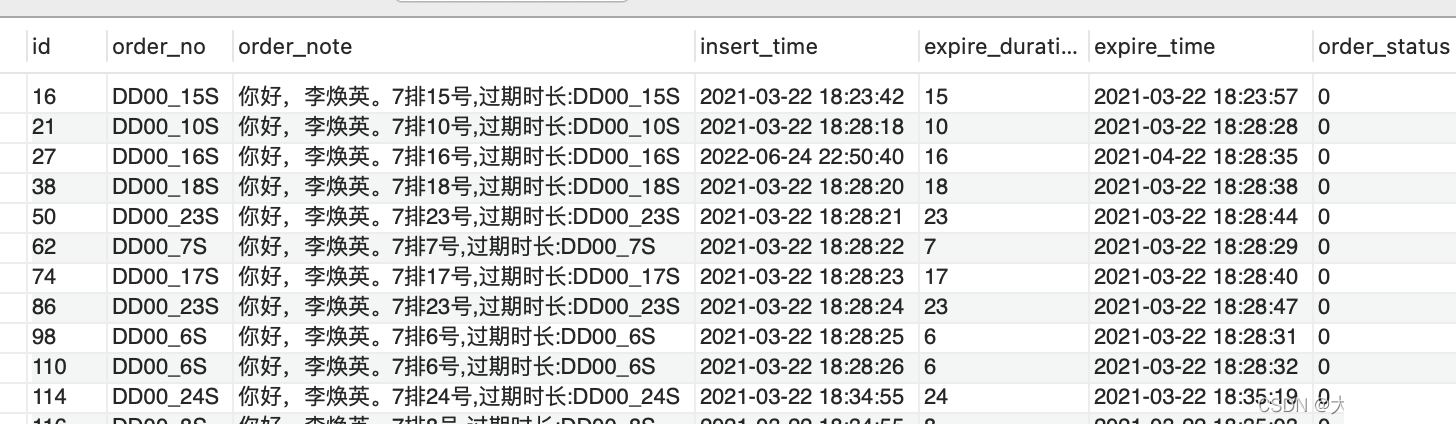
选择前缀索引的位数:
这里的逻辑和列的离散性类似,我们需要看看字符串的前面几位的子字符串的离散性如何。比如对于下面的表,内容是电影票的相关信息,我们需要对order_note建立前缀索引。
来比较一下各个位的子字符串的离散性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|

可以看出,前面几位的子字符串的离散程度较低,后面sel13开始就比较高,那我们可以根据实际情况,建立13~15位的前缀索引。
建立前缀索引SQL语句:
1 |
|
3.1.2、只为搜索、排序和分组的列建索引
这个理由很简单,不解释了。
3.2、 多列索引的策略
3.2.1、离散性最高的列放前面
原因很简单,查询时根据定义复合索引时的列的顺序来查询的,离散性高的列放在前面的话,就能更早的将更多的数据排除在外。
3.2.2、三星索引
三星索引是一种策略。有三种条件,满足一条则索引获得一颗星,三颗星则是很好的索引。
三条策略分别是
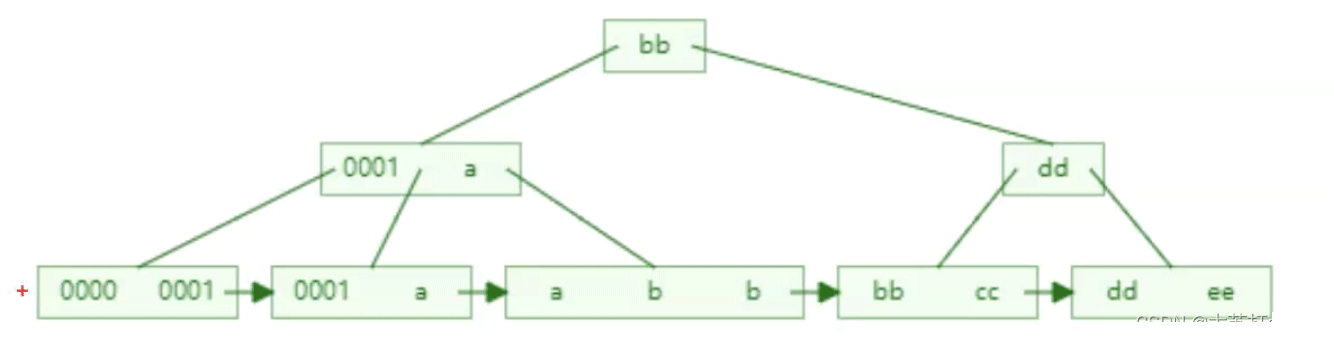
索引将相关记录放在一起。
意思是查询需要的数据在索引树的叶子节点中连续或者足够靠近。举个例子,下面是某个索引的B+树。查询所需数据仅在叶节点的前两个范围内,即0000至a。这很明显,后面的片我们就没必要再去查询了,这无疑增加了效率。当所需数据分布在每个片上时,查询次数就会显著增加。
所以查询需要的数据在叶子节点上越连续,越窄就越好。
索引中的数据顺序与查找中的数据排序一致。
这容易理解,讲解联合索引中说过,B+树的排序顺序和索引中的数据一样,所以查询时的where的数据顺序越贴近索引中的顺序,就越能更好地利用B+树。
索引的列包含查询中的所有列。
这个可以避免回文操作,不多解释。
三星索引的权重:
一般来说第三个策略权重占到50%,之后是第一个策略27%, 第二个策略23%。
三星索引实例:
1 2 3 4 5 6 7 8 9 10 |
|
我们创建以上的索引,那么对于下面的查询语句,这个索引就是三星索引。
1 |
|
首先,查询条件中有lname=’xx’ and city =’yy’,这条件让我们这需要在lname=’xx’ and city =’yy’的那一片B+树的叶子节点中查询,让我们的查询变窄了很多,并且这部分的数据是连续的,因为B+树是先根据city排序,再根据lname查询。
另外,因为已经锁定lname=’xx’ and city =’yy’,所以这部分的数据是根据fname和cno排序。查询语句正好是根据`fname```排序,所以第二点也满足。
最后是查询的结果都包含正在索引中,不会有回文,第三点也满足,所以这个索引是三星索引。
위 내용은 MySql 인덱스를 만드는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!
인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 LARAVEL 소개 예
Apr 18, 2025 pm 12:45 PM
LARAVEL 소개 예
Apr 18, 2025 pm 12:45 PM
Laravel은 웹 응용 프로그램을 쉽게 구축하기위한 PHP 프레임 워크입니다. 설치 : Composer를 사용하여 전 세계적으로 Laravel CLI를 설치하고 프로젝트 디렉토리에서 응용 프로그램을 작성하는 등 다양한 기능을 제공합니다. 라우팅 : Routes/Web.php에서 URL과 핸들러 간의 관계를 정의하십시오. 보기 : 리소스/뷰에서보기를 작성하여 응용 프로그램의 인터페이스를 렌더링합니다. 데이터베이스 통합 : MySQL과 같은 데이터베이스와 상자 외 통합을 제공하고 마이그레이션을 사용하여 테이블을 작성하고 수정합니다. 모델 및 컨트롤러 : 모델은 데이터베이스 엔티티를 나타내고 컨트롤러는 HTTP 요청을 처리합니다.
 MySQL 및 Phpmyadmin : 핵심 기능 및 기능
Apr 22, 2025 am 12:12 AM
MySQL 및 Phpmyadmin : 핵심 기능 및 기능
Apr 22, 2025 am 12:12 AM
MySQL 및 Phpmyadmin은 강력한 데이터베이스 관리 도구입니다. 1) MySQL은 데이터베이스 및 테이블을 작성하고 DML 및 SQL 쿼리를 실행하는 데 사용됩니다. 2) PHPMYADMIN은 데이터베이스 관리, 테이블 구조 관리, 데이터 운영 및 사용자 권한 관리에 직관적 인 인터페이스를 제공합니다.
 MySQL 대 기타 프로그래밍 언어 : 비교
Apr 19, 2025 am 12:22 AM
MySQL 대 기타 프로그래밍 언어 : 비교
Apr 19, 2025 am 12:22 AM
다른 프로그래밍 언어와 비교할 때 MySQL은 주로 데이터를 저장하고 관리하는 데 사용되는 반면 Python, Java 및 C와 같은 다른 언어는 논리적 처리 및 응용 프로그램 개발에 사용됩니다. MySQL은 데이터 관리 요구에 적합한 고성능, 확장 성 및 크로스 플랫폼 지원으로 유명하며 다른 언어는 데이터 분석, 엔터프라이즈 애플리케이션 및 시스템 프로그래밍과 같은 해당 분야에서 이점이 있습니다.
 데이터베이스 연결 문제 해결 : Minii/DB 라이브러리 사용 실질적인 사례
Apr 18, 2025 am 07:09 AM
데이터베이스 연결 문제 해결 : Minii/DB 라이브러리 사용 실질적인 사례
Apr 18, 2025 am 07:09 AM
작은 응용 프로그램을 개발할 때 까다로운 문제가 발생했습니다. 가벼운 데이터베이스 운영 라이브러리를 신속하게 통합해야합니다. 여러 라이브러리를 시도한 후에는 기능이 너무 많거나 호환되지 않는다는 것을 알았습니다. 결국, 나는 내 문제를 완벽하게 해결하는 YII2를 기반으로 단순화 된 버전 인 Minii/DB를 발견했습니다.
 Laravel 프레임 워크 설치 방법
Apr 18, 2025 pm 12:54 PM
Laravel 프레임 워크 설치 방법
Apr 18, 2025 pm 12:54 PM
기사 요약 :이 기사는 Laravel 프레임 워크를 쉽게 설치하는 방법에 대한 독자들을 안내하기위한 자세한 단계별 지침을 제공합니다. Laravel은 웹 애플리케이션의 개발 프로세스를 가속화하는 강력한 PHP 프레임 워크입니다. 이 자습서는 시스템 요구 사항에서 데이터베이스 구성 및 라우팅 설정에 이르기까지 설치 프로세스를 다룹니다. 이러한 단계를 수행함으로써 독자들은 라벨 프로젝트를위한 탄탄한 토대를 빠르고 효율적으로 놓을 수 있습니다.
 MySQL 모드 해결 문제 : theliamysqlmodeschecker 모듈 사용 경험
Apr 18, 2025 am 08:42 AM
MySQL 모드 해결 문제 : theliamysqlmodeschecker 모듈 사용 경험
Apr 18, 2025 am 08:42 AM
Thelia를 사용하여 전자 상거래 웹 사이트를 개발할 때 까다로운 문제가 발생했습니다. MySQL 모드가 제대로 설정되지 않아 일부 기능이 제대로 작동하지 않습니다. 약간의 탐색 후, 나는 theliamysqlmodeschecker라는 모듈을 발견했습니다.이 모듈은 Thelia가 요구하는 MySQL 패턴을 자동으로 수정하여 내 문제를 완전히 해결할 수 있습니다.
 MySQL에서 외국 키의 목적을 설명하십시오.
Apr 25, 2025 am 12:17 AM
MySQL에서 외국 키의 목적을 설명하십시오.
Apr 25, 2025 am 12:17 AM
MySQL에서 외국 키의 기능은 테이블 간의 관계를 설정하고 데이터의 일관성과 무결성을 보장하는 것입니다. 외국 키는 참조 무결성 검사 및 계단식 작업을 통해 데이터의 효과를 유지합니다. 성능 최적화에주의를 기울이고 사용할 때 일반적인 오류를 피하십시오.
 MySQL 및 Mariadb를 비교하고 대조하십시오.
Apr 26, 2025 am 12:08 AM
MySQL 및 Mariadb를 비교하고 대조하십시오.
Apr 26, 2025 am 12:08 AM
MySQL과 Mariadb의 주요 차이점은 성능, 기능 및 라이센스입니다. 1. MySQL은 Oracle에 의해 개발되었으며 Mariadb는 포크입니다. 2. MariaDB는 높은 하중 환경에서 더 나은 성능을 발휘할 수 있습니다. 3. Mariadb는 더 많은 스토리지 엔진과 기능을 제공합니다. 4.MySQL은 듀얼 라이센스를 채택하고 MariaDB는 완전히 오픈 소스입니다. 선택할 때 기존 인프라, 성능 요구 사항, 기능 요구 사항 및 라이센스 비용을 고려해야합니다.
