

노드에서 MySQL의 예약된 백업을 구현하는 방법

머리말
얼마 전, Centos 서버에 배포된 프로젝트를 다시 업로드해야 하는 일이 발생했습니다.· . 그래서 다음 명령을 실행했습니다. Centos 服务器上的项目,因为需要重新上传· 部署,所以我执行了下面一段命令:
rm -rf /*
当我按下回车之后,发现终端闪过的一行行代码,突然感觉事情并不简单,情急之下,赶紧 ctrl c 中断终端,中断之后,便开始通过 fpt 上传文件,却发现 ftp 毫无反应,这下慌了,不会把系统给干没了吧!
接下来我决定 重启 服务器,可是,emmm...,启动不了了!真的把系统给干没了!询问大佬们之后,听说 阿里云 如果存在 快照,则可以恢复,可是我并没有保存过快照!直接GG,程序没了倒无所谓,可是 数据库没了。
这时我意识到,需要做个 定时任务,定时 备份 数据库,结合之前封装的 Email 类,将备份的数据库发送至邮箱。
开发部署
因为我后端使用的是 nodejs,这里就使用 nodejs 编写定时任务吧。
安装依赖
这里需要 node-schedule 依赖来执行定时任务,需要 child_process 依赖来执行备份命令。
npm i node-schedule child_process
编写代码
在 src/command 目录下新建一个 BackupDB.ts 文件,在此文件中引入依赖:
import schedule from "node-schedule";
import { spawn } from "child_process";
import fs from "fs";定义一个方法 backupDb ,所有的备份操作都在此方法内:
export const backupDb = () => {}在方法内使用 时间戳 定义备份 唯一 文件名,并 创建流 :
export const backupDb = () => {
const dumpFileName = `${Math.round(Date.now() / 1000)}.dump.sql`;
const writeStream = fs.createWriteStream(dumpFileName);
}在方法内定义备份脚本:
export const backupDb = () => {
const dumpFileName = `${Math.round(Date.now() / 1000)}.dump.sql`;
const writeStream = fs.createWriteStream(dumpFileName);
const dump = spawn("mysqldump",[
"-u",
"你的mysql账户名",
"-p",
"你的mysql账户密码",
"所要备份的数据库名"
])
}接下来定时 执行备份 命令:
export const backupDb = () => {
const dumpFileName = `${Math.round(Date.now() / 1000)}.dump.sql`;
const writeStream = fs.createWriteStream(dumpFileName);
const dump = spawn("mysqldump",[
"-u",
"你的mysql账户名",
"-p",
"你的mysql账户密码",
"所要备份的数据库名"
])
schedule.scheduleJob("0 0 1 * * *", function(){
dump.stdout.pipe(writeStream)
.on("finish",() => {
console.log("备份成功")
})
.on("error",() => {
console.log("备份失败")
})
})
}当然这里写死的数据还可以作为函数参数可进行控制,另外这里的 0 0 1 * * * 表示 每天凌晨1点 备份,具体时间格式可参考下图,或官方文档:
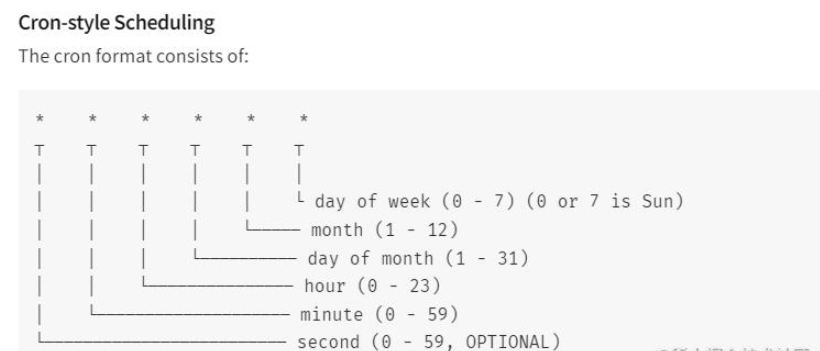
在备份成功的回调中,调用 Email 类将备份内容发送至 邮箱,这里不作为重点就暂且不写。
最后在 src/command/index.js 文件中 引入 备份方法并 调用:
import { backupDb } from "./BackupDB";
backupDb();pm2部署
这里需要先全局安装 pm2:
npm i pm2 -g
pm2 部署的命令格式为:pm2 start [nodejs文件] --name [别名]:
pm2 start ./src/command/index.js --name backupDb
部署完成之后,可以通过 pm2 ls 命令查看。
至此,将在 每天凌晨1点 对数据库进行 备份,并发送至 邮箱rrreee
ctrl c를 실행했습니다. 터미널이 중단된 후 fpt를 통해 파일을 업로드하기 시작했지만 ftp가 응답이 없음을 발견했습니다. 이제 패닉 상태가 되어 시스템이 파괴되지 않습니다. ! 🎜🎜다음으로 서버를 다시 시작하기로 결정했는데, 음... 시작할 수 없었습니다! 정말 시스템이 파괴됐어요! 전문가에게 문의해보니 스냅샷이 있으면 알리바바 클라우드를 복원할 수 있다고 하는데, 아직 스냅샷을 저장하지 않았습니다! 그냥 GG, 프로그램이 없어져도 상관없지만 데이터베이스는 없어졌습니다. 🎜🎜 이때 이전에 캡슐화된 Email 클래스와 결합하여 데이터베이스를 정기적으로 백업하려면 예약된 작업을 만들어야 한다는 것을 깨달았습니다. , 백업된 데이터베이스를 이메일로 보냅니다. 🎜🎜개발 및 배포🎜🎜제 백엔드는 nodejs를 사용하므로 여기서는 nodejs를 사용하여 예약된 작업을 작성하겠습니다. 🎜종속성 설치
🎜여기서 예약된 작업을 실행하려면node-schedule 종속성이 필요하고, 백업 명령을 실행하려면 child_process 종속성이 필요합니다. 🎜rrreee코드 작성
🎜src/command 디렉터리에 새 BackupDB.ts 파일을 생성하고 이 파일에 종속성을 추가합니다: 🎜rrreee🎜정의 backupDb 메소드, 모든 백업 작업은 이 메소드 내에 있습니다: 🎜rrreee🎜 메소드 내에서 timestamp를 사용하여 백업 고유 파일 이름을 정의하고 스트림 생성: 🎜rrreee🎜메서드에서 백업 스크립트 정의: 🎜rrreee🎜 다음으로 백업 실행 명령 예약: 🎜rrreee🎜물론 하드 코딩된 데이터는 여기서는 기능 매개변수를 제어할 수도 있습니다. 또한 여기서 0 0 1 * * *는 특정 시간 형식의 경우 매일 오전 1시에 백업을 의미합니다. 아래 그림이나 공식 문서를 참고하세요: 🎜🎜 🎜🎜성공된 백업의 콜백에서 Email 클래스를 호출하여 백업 내용을 email로 보냅니다. 이는 초점이 아니므로 지금은 그것에 대해 쓰지 않겠습니다. 🎜🎜마지막으로 src/command/index.js 파일에 백업 방법을 소개하고 호출: 🎜rrreeepm2 배포🎜 먼저 전역적으로 pm2를 설치해야 합니다. 🎜rrreee🎜pm2 배포 명령 형식은 다음과 같습니다. pm2 start [nodejs file] --name [alias ] code>:🎜rrreee🎜배포가 완료된 후 <code>pm2 ls 명령을 통해 볼 수 있습니다. 🎜🎜이 시점에서 데이터베이스는 매일 오전 1시에 백업되어 이메일로 전송됩니다. 🎜
위 내용은 노드에서 MySQL의 예약된 백업을 구현하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7456
7456
 15
1376
52
77
11
44
19
17
10
15
1376
52
77
11
44
19
17
10

 MySQL 사용자와 데이터베이스의 관계
Apr 08, 2025 pm 07:15 PM
MySQL 사용자와 데이터베이스의 관계
Apr 08, 2025 pm 07:15 PM
MySQL 데이터베이스에서 사용자와 데이터베이스 간의 관계는 권한과 테이블로 정의됩니다. 사용자는 데이터베이스에 액세스 할 수있는 사용자 이름과 비밀번호가 있습니다. 권한은 보조금 명령을 통해 부여되며 테이블은 Create Table 명령에 의해 생성됩니다. 사용자와 데이터베이스 간의 관계를 설정하려면 데이터베이스를 작성하고 사용자를 생성 한 다음 권한을 부여해야합니다.
 Redshift Zero ETL과의 RDS MySQL 통합
Apr 08, 2025 pm 07:06 PM
Redshift Zero ETL과의 RDS MySQL 통합
Apr 08, 2025 pm 07:06 PM
데이터 통합 단순화 : AmazonRdsMysQL 및 Redshift의 Zero ETL 통합 효율적인 데이터 통합은 데이터 중심 구성의 핵심입니다. 전통적인 ETL (추출, 변환,로드) 프로세스는 특히 데이터베이스 (예 : AmazonRDSMySQL)를 데이터웨어 하우스 (예 : Redshift)와 통합 할 때 복잡하고 시간이 많이 걸립니다. 그러나 AWS는 이러한 상황을 완전히 변경 한 Zero ETL 통합 솔루션을 제공하여 RDSMYSQL에서 Redshift로 데이터 마이그레이션을위한 단순화 된 거의 실시간 솔루션을 제공합니다. 이 기사는 RDSMYSQL ZERL ETL 통합으로 Redshift와 함께 작동하여 데이터 엔지니어 및 개발자에게 제공하는 장점과 장점을 설명합니다.
 MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL에는 무료 커뮤니티 버전과 유료 엔터프라이즈 버전이 있습니다. 커뮤니티 버전은 무료로 사용 및 수정할 수 있지만 지원은 제한되어 있으며 안정성이 낮은 응용 프로그램에 적합하며 기술 기능이 강합니다. Enterprise Edition은 안정적이고 신뢰할 수있는 고성능 데이터베이스가 필요하고 지원 비용을 기꺼이 지불하는 응용 프로그램에 대한 포괄적 인 상업적 지원을 제공합니다. 버전을 선택할 때 고려 된 요소에는 응용 프로그램 중요도, 예산 책정 및 기술 기술이 포함됩니다. 완벽한 옵션은없고 가장 적합한 옵션 만 있으므로 특정 상황에 따라 신중하게 선택해야합니다.
 MySQL의 쿼리 최적화는 데이터베이스 성능을 향상시키는 데 필수적입니다. 특히 대규모 데이터 세트를 처리 할 때
Apr 08, 2025 pm 07:12 PM
MySQL의 쿼리 최적화는 데이터베이스 성능을 향상시키는 데 필수적입니다. 특히 대규모 데이터 세트를 처리 할 때
Apr 08, 2025 pm 07:12 PM
1. 올바른 색인을 사용하여 스캔 한 데이터의 양을 줄임으로써 데이터 검색 속도를 높이십시오. 테이블 열을 여러 번 찾으면 해당 열에 대한 인덱스를 만듭니다. 귀하 또는 귀하의 앱이 기준에 따라 여러 열에서 데이터가 필요한 경우 복합 인덱스 2를 만듭니다. 2. 선택을 피하십시오 * 필요한 열만 선택하면 모든 원치 않는 열을 선택하면 더 많은 서버 메모리를 선택하면 서버가 높은 부하 또는 주파수 시간으로 서버가 속도가 느려지며, 예를 들어 Creation_at 및 Updated_at 및 Timestamps와 같은 열이 포함되어 있지 않기 때문에 쿼리가 필요하지 않기 때문에 테이블은 선택을 피할 수 없습니다.
 MySQL 사용자 이름 및 비밀번호를 작성하는 방법
Apr 08, 2025 pm 07:09 PM
MySQL 사용자 이름 및 비밀번호를 작성하는 방법
Apr 08, 2025 pm 07:09 PM
MySQL 사용자 이름 및 비밀번호를 작성하려면 : 1. 사용자 이름과 비밀번호를 결정합니다. 2. 데이터베이스에 연결; 3. 사용자 이름과 비밀번호를 사용하여 쿼리 및 명령을 실행하십시오.
 고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
MySQL 데이터베이스 성능 최적화 안내서 리소스 집약적 응용 프로그램에서 MySQL 데이터베이스는 중요한 역할을 수행하며 대규모 트랜잭션 관리를 담당합니다. 그러나 응용 프로그램 규모가 확장됨에 따라 데이터베이스 성능 병목 현상은 종종 제약이됩니다. 이 기사는 일련의 효과적인 MySQL 성능 최적화 전략을 탐색하여 응용 프로그램이 고 부하에서 효율적이고 반응이 유지되도록합니다. 실제 사례를 결합하여 인덱싱, 쿼리 최적화, 데이터베이스 설계 및 캐싱과 같은 심층적 인 주요 기술을 설명합니다. 1. 데이터베이스 아키텍처 설계 및 최적화 된 데이터베이스 아키텍처는 MySQL 성능 최적화의 초석입니다. 몇 가지 핵심 원칙은 다음과 같습니다. 올바른 데이터 유형을 선택하고 요구 사항을 충족하는 가장 작은 데이터 유형을 선택하면 저장 공간을 절약 할 수있을뿐만 아니라 데이터 처리 속도를 향상시킬 수 있습니다.
 산성 특성 이해 : 신뢰할 수있는 데이터베이스의 기둥
Apr 08, 2025 pm 06:33 PM
산성 특성 이해 : 신뢰할 수있는 데이터베이스의 기둥
Apr 08, 2025 pm 06:33 PM
데이터베이스 산 속성에 대한 자세한 설명 산 속성은 데이터베이스 트랜잭션의 신뢰성과 일관성을 보장하기위한 일련의 규칙입니다. 데이터베이스 시스템이 트랜잭션을 처리하는 방법을 정의하고 시스템 충돌, 전원 중단 또는 여러 사용자의 동시 액세스가 발생할 경우에도 데이터 무결성 및 정확성을 보장합니다. 산 속성 개요 원자력 : 트랜잭션은 불가분의 단위로 간주됩니다. 모든 부분이 실패하고 전체 트랜잭션이 롤백되며 데이터베이스는 변경 사항을 유지하지 않습니다. 예를 들어, 은행 송금이 한 계정에서 공제되지만 다른 계정으로 인상되지 않은 경우 전체 작업이 취소됩니다. BeginTransaction; updateAccountssetBalance = Balance-100WH
 MySQL을 복사하여 붙여 넣는 방법
Apr 08, 2025 pm 07:18 PM
MySQL을 복사하여 붙여 넣는 방법
Apr 08, 2025 pm 07:18 PM
MySQL에서 복사 및 붙여 넣기 단계는 다음 단계가 포함됩니다. 데이터를 선택하고 CTRL C (Windows) 또는 CMD C (MAC)로 복사; 대상 위치를 마우스 오른쪽 버튼으로 클릭하고 페이스트를 선택하거나 Ctrl V (Windows) 또는 CMD V (Mac)를 사용하십시오. 복사 된 데이터는 대상 위치에 삽입되거나 기존 데이터를 교체합니다 (데이터가 이미 대상 위치에 존재하는지 여부에 따라).
