

MySQL에서 마스터-슬레이브 복제를 구성하는 방법

1. 통신 감지
마스터와 슬레이브의 IP 주소를 확인하고 통신 가능 여부를 확인합니다

마스터와 슬레이브 간의 네트워크가 상호 운용 가능한지 확인하고 ping 명령을 사용하여 확인합니다

이제 우리는 마스터의 IP가 192.168.131.129이고 슬레이브의 IP가 192.168.0.6임을 알고 서로 통신할 수 있습니다. 포트 3306이 열려 있는지 확인하세요
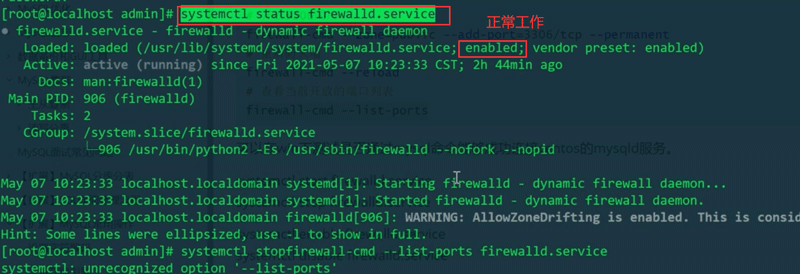

방화벽 상태 확인 systemctl status Firewalld.servicesystemctl status firewalld.service
临时手动启动防火墙systemctl start firewalld.service
临时手动停止防火墙systemctl stop firewalld.service
持久打开防火墙(重启服务生效)systemctl enable firewalld.service
持久关闭防火墙(重启服务生效)systemctl disable firewalld.service
查看当前开放的端口列表firewall-cmd --list-ports
二、master配置
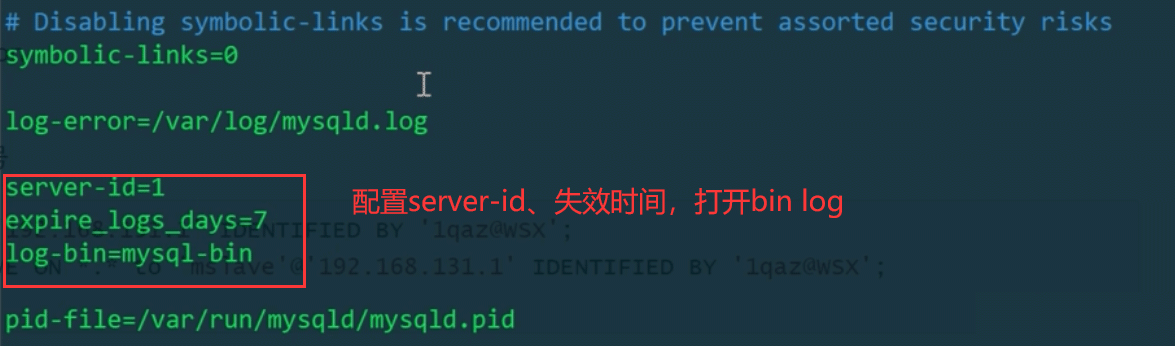
1. 开启二进制日志
配置log_bin和全局唯一的server-id,和slave区分开,不能配置成一样的(如果是my.cnf新添加配置,一定要重启MySQL服务)
vim /etc/my.cnf打开my.cnf文件
2. 创建一个用于主从库通信用的账号
即在master中创建一个账号,用于slave登录master读取binlog
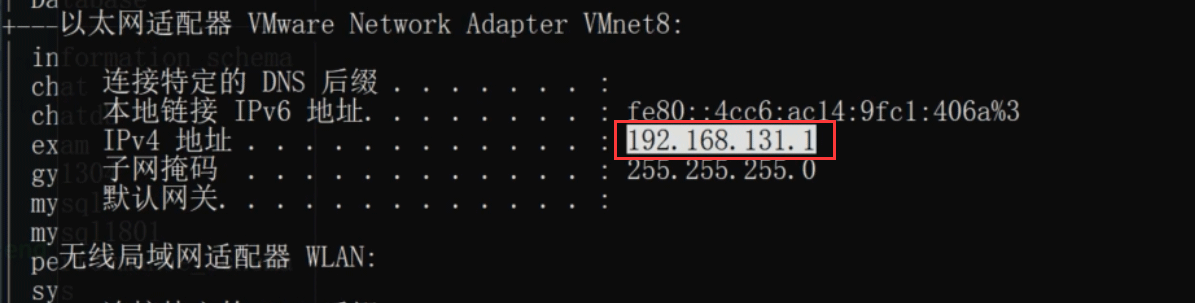
虽然我们在Linux上查看的ip地址是192.168.131.129,但我们创建账户登录时不写这个ip,写的是192.168.131.1。因为我这里虚拟机用的是NAT模式(如果是桥接模式就可以直接用了),虚拟机(master)和物理机(slave)通信的时候,虚拟机先把数据发送到网关192.168.131.1(默认与VMnet8通信),192.168.131.1再转发到物理机,所以物理机接收到的是192.168.131.1的数据,故我们在master上为slave创建账户的时候,应该写192.168.131.1
如果给slave配置的不是网关192.168.131.1地址,vim + /var/log/mysqld.log打开错误日志会有如下信息:
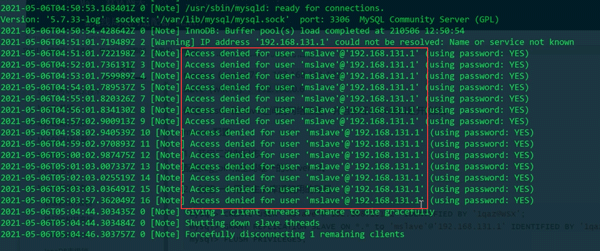
这说的就是从192.168.131.1的mslave权限不够,那是因为我们在master配置的是允许从其他地方登录,并不允许从192.168.131.1地址登录,导致权限不够。
由于master这边收到的是来自192.168.131.1的请求,所以错误日志显示的是192.168.131.1
创建用户的命令:
//如果嫌麻烦可以用%代替192.168.131.1,,它就可以匹配任何ip mysql> CREATE USER 'mslave'@'192.168.131.1' IDENTIFIED BY '1qaz@WSX'; //启动主从,在主库上给当前的mslave用户开启REPLICATION SLAVE主从复制的权限,从库就可以通过1qaz@WSX账户密码 //从192.168.131.1 IP地址来请求访问这台主库上的任意库里面的任意表*.*,同步这个主库的任意库里的任意表 mysql> GRANT REPLICATION SLAVE ON *.* to 'mslave'@'192.168.131.1' IDENTIFIED BY '1qaz@WSX'; mysql> FLUSH PRIVILEGES;
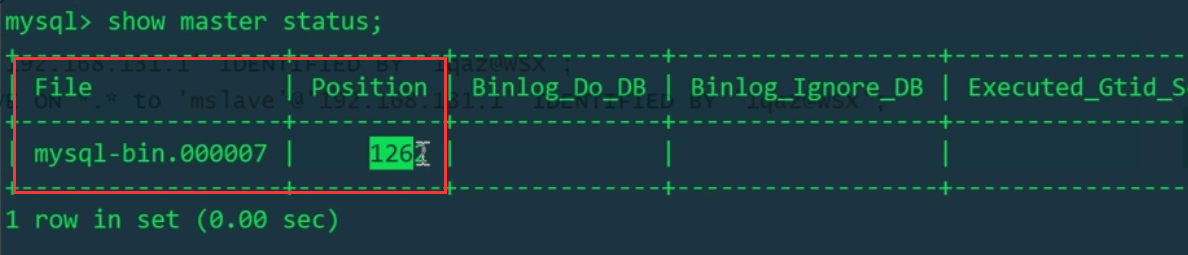
3. 获取binlog的日志文件名和position
show master status
三、slave配置
1. 配置全局唯一的server-id
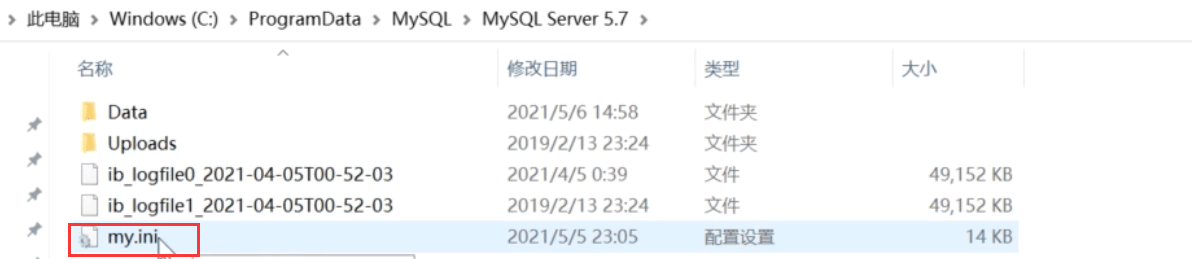
配置全局唯一的server-id

涉及修改配置文件,需要重启MySQL服务
2. 使用master创建的账户读取binlog同步数据
这一步配置主要是给IO线程读取binlog使用:
mysql> CHANGE MASTER TO MASTER_HOST='192.168.131.129', MASTER_PORT=3306, MASTER_USER='mslave', MASTER_PASSWORD='1qaz@WSX', MASTER_LOG_FILE='mysql-bin.000006', MASTER_LOG_POS=1262;
MASTER_HOST:指定master的ip
MASTER_LOG_FILE:binlog文件名
MASTER_LOG_POS:binlog的position
3. 开启slave服务
通过show slave status命令查看主从复制状态,show processlist
systemctl start Firewalld.service< br/>일시적으로 방화벽을 수동으로 중지systemctl stop Firewalld.service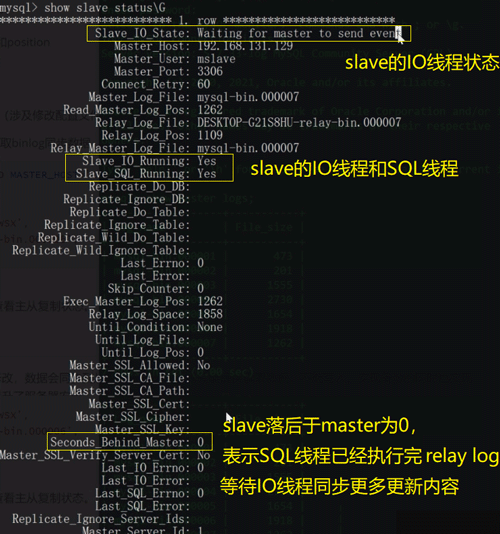 방화벽을 영구적으로 엽니다(서비스를 다시 시작하여 적용)
방화벽을 영구적으로 엽니다(서비스를 다시 시작하여 적용)systemctl 활성화 Firewalld.service
방화벽을 영구적으로 닫습니다(적용하려면 서비스를 다시 시작하세요)< code>systemctl 비활성화 Firewalld.service
현재 열려 있는 포트 목록 보기firewall-cmd --list-ports
2 . 마스터 구성
1. 바이너리 로그 활성화
log_bin과 전역 고유 서버 ID는 슬레이브와 다르므로 동일하게 구성할 수 없습니다. (my.cnf가 새로 추가되면 MySQL 서비스를 다시 시작해야 합니다.)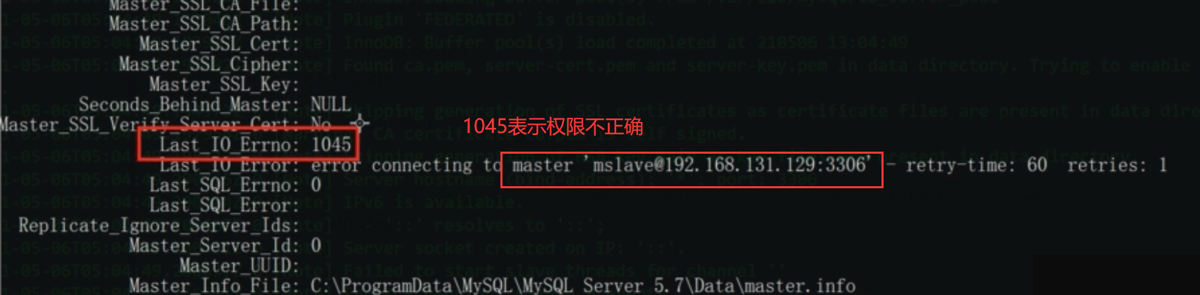
🎜🎜슬레이브인 경우 게이트웨이 192.168.131.1 주소, vim + /var/log/mysqld.log로 구성되지 않았습니다. 오류 로그를 열면 다음 정보가 나타납니다: 🎜🎜🎜🎜이는 192.168.131.1의 mslave 권한이 충분하지 않음을 의미합니다. 이는 다른 곳에서 로그인을 허용하도록 마스터를 구성했고, 192.168.131.1 주소에서는 로그인을 허용하지 않아 권한이 부족했기 때문입니다. 🎜🎜마스터가 192.168.131.1에서 요청을 받았으므로 오류 로그에 192.168.131.1🎜🎜🎜사용자를 생성하는 명령: 🎜🎜telnet xxx.xxx.xxx.xxx 3306
🎜🎜3. 슬레이브 구성🎜🎜1. 전역적으로 고유한 서버 ID를 구성하세요🎜🎜 🎜🎜🎜전역적으로 고유한 서버 ID 구성🎜🎜🎜🎜🎜🎜구성 파일을 수정하고 MySQL 서비스를 다시 시작해야 합니다🎜🎜🎜🎜🎜2. 마스터가 생성한 계정을 사용하여 binlog 동기화 데이터를 읽습니다🎜🎜🎜이것 구성 단계는 주로 IO용입니다. 스레드는 다음을 사용하여 binlog를 읽습니다. 🎜🎜
🎜🎜🎜전역적으로 고유한 서버 ID 구성🎜🎜🎜🎜🎜🎜구성 파일을 수정하고 MySQL 서비스를 다시 시작해야 합니다🎜🎜🎜🎜🎜2. 마스터가 생성한 계정을 사용하여 binlog 동기화 데이터를 읽습니다🎜🎜🎜이것 구성 단계는 주로 IO용입니다. 스레드는 다음을 사용하여 binlog를 읽습니다. 🎜🎜mysql> GRANT REPLICATION SLAVE ON *.* to 'mslave'@'xxx.xxx.xxx.xxx' IDENTIFIED BY '1qaz@WSX';
- 🎜🎜MASTER_HOST: 🎜master의 ip를 지정🎜
- 🎜🎜MASTER_LOG_FILE : 🎜binlog 파일 이름🎜
- 🎜🎜MASTER_LOG_POS: 🎜binlog position🎜
를 통해 마스터-슬레이브 복제 상태를 확인하세요. show slave status 명령, show processlist 마스터 및 슬레이브 관련 스레드의 실행 상태 확인 🎜🎜🎜🎜🎜 IV. 구성에 발생할 수 있는 문제 🎜🎜1. 네트워크 연결 문제 🎜🎜 확인 showslave status 명령을 통한 마스터-슬레이브 복제 상태 🎜🎜🎜🎜🎜🎜연결이 잘못되었습니다. 먼저 네트워크가 상호 연결되어 있는지 확인하고 ping을 수행하세요. 🎜🎜然后再检查从库里面的配置信息是否正确
如果都正确,检查主库所在机器的3306端口是否正常
telnet xxx.xxx.xxx.xxx 3306
如果发现3306端口不能连通,就需要怀疑主库对端口有限制吗,也就是防火墙限制,就需要在防火墙把3306端口开放出来。
如果这个错误还没解决,就查看一个主库的错误日志/var/log/mysql/mysqld.log,查看错误日志中提示的ip是否和自己允许slave登录的ip一致
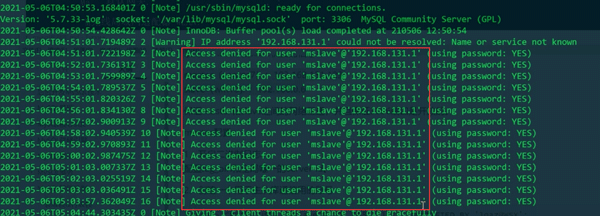
这说的就是从192.168.131.1的mslave权限不够,自己玩的时候,如果虚拟机是NAT模式,则需要写成VMnet8网关ip。如果都是物理机通信,那直接写正确的ip即可
可以在MySQL数据库下的mysql库的user表中更改允许登录的ip
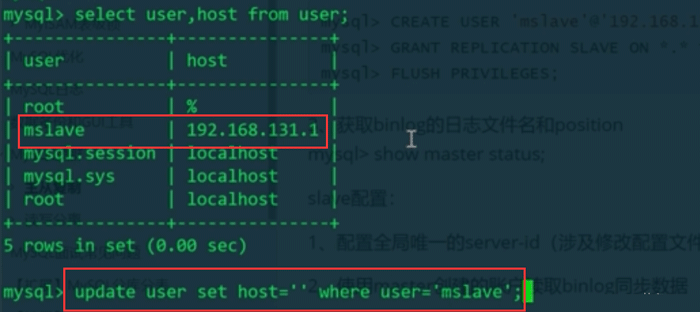
然后重新赋予权限:
mysql> GRANT REPLICATION SLAVE ON *.* to 'mslave'@'xxx.xxx.xxx.xxx' IDENTIFIED BY '1qaz@WSX';
2. binlog的position问题
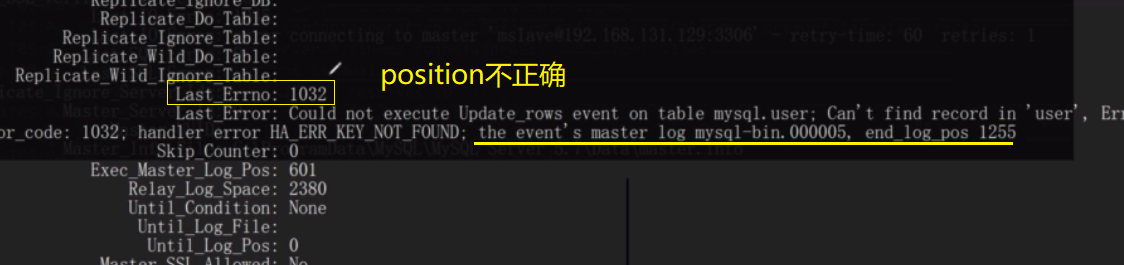
在master中查看show master status一下binlog日志文件名以及position,然后用命令重新配置slave,比如:
mysql> CHANGE MASTER TO MASTER_HOST='192.168.131.129',MASTER_PORT=3306,MASTER_USER='mslave',MASTER_PASSWORD='1qaz@WSX', MASTER_LOG_FILE='mysql-bin.000006',MASTER_LOG_POS=1262;
配置slave前需要stop slave,配置完成再start slave
3. SQL线程出错
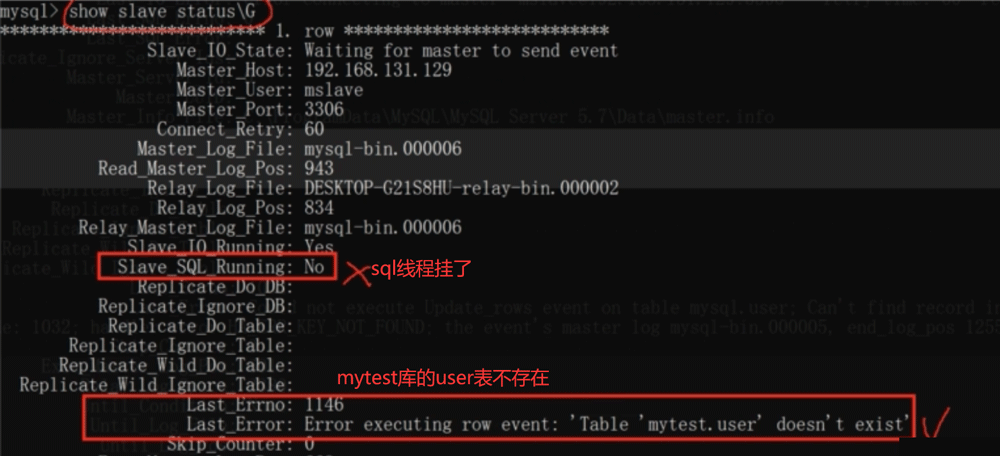
错误原因:首先配置主从复制的时候,slave的mytest库中没有user表,而master的mytest库已经有user表了。配置好主从复制后直接drop table mytest.user,这就会写到binlog里面,然后在通过dump线程和IO线程将这个操作发送到从库的relay log,然后从库的SQL线程从relay log里把drop table mytest.user捞出来在从库执行这个SQL,可从库的mytest根本就没有user表,这就是删除一个不存在的表,于是出现错误了。
一般我们是不会做这样的操作的,我们一般都是主库配置以后,slave从数据开始增量进行同步,不会同步以后一开始就删主库里的东西,如果真的出现这样的问题了,随时可以通过show slave status来查看主从库的状态来解决错误,如果是上图这个错误,
(1)可以在从库stop slave,然后把位置重新设置一下,然后再start slave,相当于重新开始主从同步的位置。
(2)可以在从库stop slave,然后set global sql_slave_skip_counter=1;(跳过一个错误),然后再start slave重启从库的线程,相当于把错误跳过了,异常操作。
可以通过show slave status查看以下标识,IO线程出错一般是网络问题,SQL线程出错一般是SQL在slave库执行出现了问题
위 내용은 MySQL에서 마스터-슬레이브 복제를 구성하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7334
7334
 9
1627
14
1352
46
1264
25
1209
29
9
1627
14
1352
46
1264
25
1209
29

 PHP의 빅데이터 구조 처리 능력
May 08, 2024 am 10:24 AM
PHP의 빅데이터 구조 처리 능력
May 08, 2024 am 10:24 AM
빅 데이터 구조 처리 기술: 청킹(Chunking): 데이터 세트를 분할하고 청크로 처리하여 메모리 소비를 줄입니다. 생성기: 전체 데이터 세트를 로드하지 않고 데이터 항목을 하나씩 생성하므로 무제한 데이터 세트에 적합합니다. 스트리밍: 파일을 읽거나 결과를 한 줄씩 쿼리하므로 대용량 파일이나 원격 데이터에 적합합니다. 외부 저장소: 매우 큰 데이터 세트의 경우 데이터를 데이터베이스 또는 NoSQL에 저장합니다.
 PHP에서 MySQL 쿼리 성능을 최적화하는 방법은 무엇입니까?
Jun 03, 2024 pm 08:11 PM
PHP에서 MySQL 쿼리 성능을 최적화하는 방법은 무엇입니까?
Jun 03, 2024 pm 08:11 PM
선형 복잡성에서 로그 복잡성까지 조회 시간을 줄이는 인덱스를 구축하여 MySQL 쿼리 성능을 최적화할 수 있습니다. SQL 삽입을 방지하고 쿼리 성능을 향상하려면 PREPAREDStatements를 사용하세요. 쿼리 결과를 제한하고 서버에서 처리되는 데이터의 양을 줄입니다. 적절한 조인 유형 사용, 인덱스 생성, 하위 쿼리 사용 고려 등 조인 쿼리를 최적화합니다. 쿼리를 분석하여 병목 현상을 식별하고, 캐싱을 사용하여 데이터베이스 로드를 줄이고, 오버헤드를 최소화합니다.
 PHP에서 MySQL 백업 및 복원을 사용하는 방법은 무엇입니까?
Jun 03, 2024 pm 12:19 PM
PHP에서 MySQL 백업 및 복원을 사용하는 방법은 무엇입니까?
Jun 03, 2024 pm 12:19 PM
PHP에서 MySQL 데이터베이스를 백업하고 복원하는 작업은 다음 단계에 따라 수행할 수 있습니다. 데이터베이스 백업: mysqldump 명령을 사용하여 데이터베이스를 SQL 파일로 덤프합니다. 데이터베이스 복원: mysql 명령을 사용하여 SQL 파일에서 데이터베이스를 복원합니다.
 PHP를 사용하여 MySQL 테이블에 데이터를 삽입하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:26 PM
PHP를 사용하여 MySQL 테이블에 데이터를 삽입하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:26 PM
MySQL 테이블에 데이터를 삽입하는 방법은 무엇입니까? 데이터베이스에 연결: mysqli를 사용하여 데이터베이스에 대한 연결을 설정합니다. SQL 쿼리 준비: 삽입할 열과 값을 지정하는 INSERT 문을 작성합니다. 쿼리 실행: query() 메서드를 사용하여 삽입 쿼리를 실행하면 확인 메시지가 출력됩니다.
 MySQL 8.4에서 mysql_native_password가 로드되지 않음 오류를 수정하는 방법
Dec 09, 2024 am 11:42 AM
MySQL 8.4에서 mysql_native_password가 로드되지 않음 오류를 수정하는 방법
Dec 09, 2024 am 11:42 AM
MySQL 8.4(2024년 최신 LTS 릴리스)에 도입된 주요 변경 사항 중 하나는 "MySQL 기본 비밀번호" 플러그인이 더 이상 기본적으로 활성화되지 않는다는 것입니다. 또한 MySQL 9.0에서는 이 플러그인을 완전히 제거합니다. 이 변경 사항은 PHP 및 기타 앱에 영향을 미칩니다.
 PHP에서 MySQL 저장 프로시저를 사용하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:13 PM
PHP에서 MySQL 저장 프로시저를 사용하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:13 PM
PHP에서 MySQL 저장 프로시저를 사용하려면: PDO 또는 MySQLi 확장을 사용하여 MySQL 데이터베이스에 연결합니다. 저장 프로시저를 호출하는 문을 준비합니다. 저장 프로시저를 실행합니다. 결과 집합을 처리합니다(저장 프로시저가 결과를 반환하는 경우). 데이터베이스 연결을 닫습니다.
 PHP를 사용하여 MySQL 테이블을 만드는 방법은 무엇입니까?
Jun 04, 2024 pm 01:57 PM
PHP를 사용하여 MySQL 테이블을 만드는 방법은 무엇입니까?
Jun 04, 2024 pm 01:57 PM
PHP를 사용하여 MySQL 테이블을 생성하려면 다음 단계가 필요합니다. 데이터베이스에 연결합니다. 데이터베이스가 없으면 작성하십시오. 데이터베이스를 선택합니다. 테이블을 생성합니다. 쿼리를 실행합니다. 연결을 닫습니다.
 오라클 데이터베이스와 mysql의 차이점
May 10, 2024 am 01:54 AM
오라클 데이터베이스와 mysql의 차이점
May 10, 2024 am 01:54 AM
Oracle 데이터베이스와 MySQL은 모두 관계형 모델을 기반으로 하는 데이터베이스이지만 호환성, 확장성, 데이터 유형 및 보안 측면에서 Oracle이 우수하고, MySQL은 속도와 유연성에 중점을 두고 중소 규모 데이터 세트에 더 적합합니다. ① Oracle은 광범위한 데이터 유형을 제공하고, ② 고급 보안 기능을 제공하고, ③ 엔터프라이즈급 애플리케이션에 적합하고, ① MySQL은 NoSQL 데이터 유형을 지원하고, ② 보안 조치가 적고, ③ 중소 규모 애플리케이션에 적합합니다.
