

MySQL에서 on, in, as 및 where의 차이점은 무엇입니까?

Mysql on, in, as, where의 차이점
답변: Where 쿼리 조건은 내부 및 외부 연결 시 on을 별칭으로 사용하여 특정 값이 특정 조건에 있는지 쿼리합니다
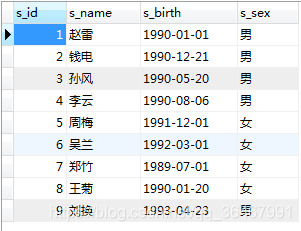
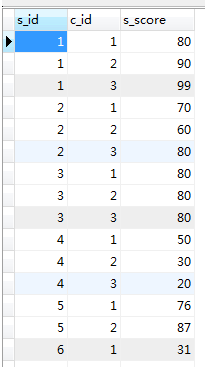
2 생성 테이블: 학생, 점수
학생:
점수:
where
SELECT * FROM student WHERE s_sex='男'
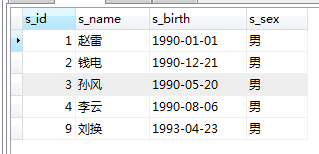
예: 켜기
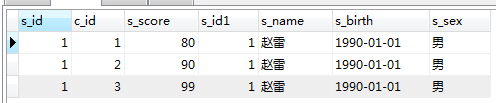
SELECT * FROM student LEFT JOIN score on student.s_id=score.s_id;
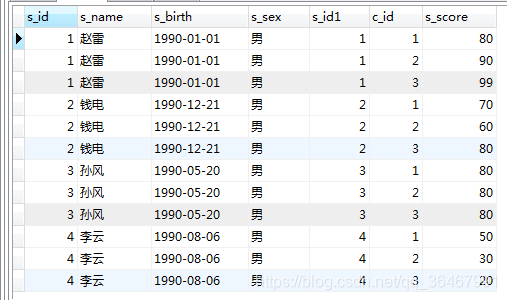
on 및 where 조합 :
SELECT * FROM student LEFT JOIN score on student.s_id=score.s_id WHERE s_name='赵雷'
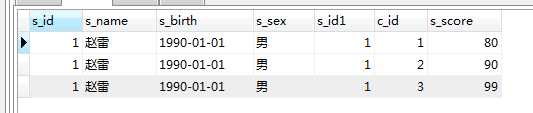
예: in
SELECT * FROM score WHERE s_id in (SELECT s_id FROM student WHERE s_name='赵雷')
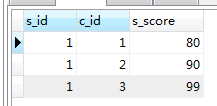
as
select * from score as a LEFT JOIN student as b on a.s_id=b.s_id where s_name='赵雷'
Mysql 문 문제 해결
1. 왼쪽 조인 데이터 필터링 문제
다음 조건에서만 가능합니다. 왼쪽 조인의 오른쪽에 있는 테이블을 필터링합니다. 왼쪽 테이블이 오른쪽 테이블 데이터와 일치하지 않으면 추가 후 원래 오른쪽 테이블 위치에 null이 표시됩니다. 이후의 조건에 따라 모든 데이터가 필터링됩니다.
2. 동일한 데이터가 반복적으로 필터링되어 사용됩니다.
with <name> as()
as를 사용하여 mysql에서 임시 테이블을 생성할 수 있습니다. 예제에 따르면 실행 시간은 더 이상 존재하지 않습니다. 기사 테이블이지만 테이블의 모든 데이터가 필요한 것은 아닙니다. 따라서 먼저 임시 테이블 arc를 필터링하고 생성한 다음 arc를 작동하겠습니다.
위 예제의 단순한 연산이라면 with...as를 사용할 필요는 없지만, 기사 테이블을 다른 테이블과 공동으로 쿼리하거나 심지어 중첩해야 하는 경우 is_del = 0으로 판단됩니다. 최종 SQL 문은 매우 복잡하고 오류가 발생하기 쉬울 수 있지만 arc를 사용하면 데이터를 반복적으로 필터링할 필요가 없습니다.
with...as의 SQL은 더 복잡할 수 있습니다. 예를 들어 기사 테이블에 name_id가 있지만 더 자주 name을 사용하여 검색할 수 있습니다. 이를 수행하려면 임시 테이블을 사용하십시오.
3. 특정 필드를 기준으로 정렬하여 마지막 3개 데이터 또는 각 카테고리의 처음 3개 데이터를 가져옵니다.
저는 초보자이고 문제를 해결하는 방법은 한 가지만 알고 있지만 시도해 보겠습니다. 간단하고 대중적인 방식으로 설명하는 것이 최선입니다.
예:
with arc as(
select id,arc.title,update_time,is_top,cId,pid,name_id from article arc where is_del = 0
)
select * from arc예에서 cId는 카테고리 ID이고 updateTime은 업데이트 시간입니다. 문제에 대한 해결책은 뉴스 홈페이지에서 요구하는 것처럼 arc의 각 카테고리에 대한 최신 세 가지 데이터를 선택하는 것입니다. 세 가지 뉴스에 대해 데이터베이스의 데이터에 따라 order by cId, updateTime desc를 사용하여 카테고리 및 업데이트 시간별로 데이터를 정렬할 수 있습니다. 기존 데이터베이스의 각 카테고리에 대한 데이터를 저장하므로 임시 필드를 추가할 수 있습니다.
updateTimeSort 이 카테고리의 각 카테고리에 있는 각 하위 항목의 정렬을 나타냅니다. 현재 문제에서 이 임시 필드는 업데이트 시간에 따라 카테고리의 각 하위 항목을 정렬하는 updateTime 필드와 관련되어야 합니다.
샘플 코드에서 볼 수 있듯이 두 테이블 a1과 a2는 모두 arc 테이블의 별칭이며 a2를 기본 쿼리로 결합합니다. a2의 현재 데이터와 동일한 카테고리를 찾으려면 테이블에서 업데이트 시간이 a2의 현재 데이터에 있는 데이터 수보다 늦으면 count(*)+1을 볼 수 있습니다. 데이터가 속한 카테고리에서 최신 업데이트 시간이 있는 경우에는 하나를 추가하지 않아도 됩니다. count(*)의 값은 0입니다. count(*)+1을 사용하면 1부터 데이터를 정렬할 수 있습니다.
결국 updateTimeSort <= 3으로 데이터만 선택하면 됩니다. 가장 먼저 게시된 뉴스를 필터링하려면 샘플 코드
a1에서 updateTimeSort의 필터링 논리만 변경하면 됩니다. updateTime > a2 .updateTime은 a1.updateTime < a2.updateTime
으로 변경되었습니다. 샘플 코드에는 실제로 임시 테이블인 또 다른 테이블 a3이 있음을 알 수 있습니다. 임시 테이블이므로 이번에도 반복해 보겠습니다. 코드에서 볼 수 있듯이 임시 테이블은 다른 형태로도 존재할 수 있습니다. 일반적으로 SQL이 복잡할 때만 사용하므로 이 방법을 사용하면 문제를 해결할 수 있습니다. 현재 많은 문제가 있으며 각각 고유한 문제가 있습니다. 장단점은 상황에 따라 다릅니다.
4、业务逻辑书写位置问题
接触sql多了会发现,sql其实能帮我们解决一定的业务问题,明显的有sql的存储过程和方法,对sql语句的批量处理其实在一定程度上帮我们解决一定的业务问题,但缺点也很明显,当新手接触这个项目时他很难搞清楚某个功能到底是如何实现的,不利于维护。
一般来说我们解决业务是在server层,有时会使用sql解决一些问题,但很少,在sever处理受制于计算机硬件,在数据库处理受制于数据库性能,相比之下,计算机硬件更易于扩展,因此还是不推荐大量使用sql解决问题的。
例如上个问题:根据某个字段排序取每个类别最后三条数据或前三条数据问题,虽然问题基本解决但让存在一些 ‘bug’,例如排序时会产生1、2、3、3、4这种排序,这是因为同个类别内有两条数据更新时间重复了,那我们直观想法(还是要看个人经验值)应该是,既然问题出在数据库,那应该在数据库查询的时候就解决这个问题,但事实上,让数据库去解决并不好解决,数据库的强项在于各种搜索算法,不在于逻辑处理,因此我们就要转移到server层处理,会有不少人陷于这个坑,花费大量时间去找办法让数据库去处理这类问题,但其实就算数据库处理得了,它也不一定有server层处理的效率高,当然如果是为了学习更多东西,这些时间也是值得花的,但是这种解题思路还是要改变下的。将1、2、3、3、4问题交给server处理也就是利用java等高级语言处理这种问题,相信熟用这些语言的开发者解决这些问题都是小case了。
5、查找另一表内和本表相关字段的数量
先复习下知识:用过count函数的人都清楚一旦使用count这类聚合函数,不做其他处理数据就会归为一行数据,但很多时候我们并不期望这样的结果,以此就要想些办法能用聚合函数,也能获取很多数据,我常用的是利用group by分组。
回归问题,现有(现不讨论表是否合理)文章表(id,title,content)有文章id,标题,文章内容三个字段,点赞收藏表(id,arc_id,fav,like)有表id,文章id,收藏字段(0未收藏,1收藏),点赞字段(0未点赞,1点赞),现要查询文章表内每篇文章的点赞收藏数,sql语句:
select art.title,art.content, count(case afl.fav when 1 then 1 end) as collectNum, count(case afl.like when 1 then 1 end) as likeNum from article art left join article_favor_like afl on afl.arc_id = art.id group by afl.arc_id //这是关键
如果没有group by afl.arc_id 后果就是,查出来一行数据,数据还牛头不对马嘴,但通过对文章收藏表中的文章id进行分组就可以针对每个文章id查询数据,这样left join时右表就有每个文章id对相应的收藏数与点赞数,而不是表内所有点赞数和收藏数,最终数据也是我们所需的。
6、关于union的使用
例子:
select id,title,content,1 isArc from arc union select id,name,content,0 isArc from news
使用union进行的是上下整合
被联合的数据列数要求一致
列数相同,数据类型不同会自动进行数据类型转换
联合后的列的名字由联合中第一次出现的列名为依据,即使后续被联合数据有自己的列名也不会使用,在例子中最终列名为:id,title,content,name等列名不会使用,因此使用union一般配合别名使用统一结果。
有时候会区分数据是哪个表的,可以通过附加额外的字段来区别,就像例子中的isArc字段,news表中的isArc可以不写,原因也就是第4条,最终列名由第一次出现的列名决定,后续数据列名有没有都可以。
7、limit的巧用
limit一般用于分页,功能是获取指定区间内的数据,因此我们也可以用它来减少数据库的查询,例子:
select * from arc where id = 12 limit 1
数据库查询由索引还好,没有索引是要遍历数据库的,有些数据经由条件筛选在逻辑上应该是唯一的,使用limit 1可以使数据库查询到该数据时不再搜索,减少数据库搜索次数,但这种方法仅是一种技巧,想大幅度优化sql还要另想办法。
8、update ignore和insert ignore的使用
//标题是唯一索引,'新标题'存在则更新操作不执行 update ignore arc set title = '新标题' //标题是唯一索引,'标题1号'存在则插入操作不执行 insert ignore into arc values(null,'标题1号','文章内容')
有这种需求,数据存在时不执行任何操作,不存在则更新或插入,一个办法是使用ingore,它会忽略数据库报错,而数据库执行原子操作时报错是会回滚的,因此只要我们给数据加上主键或唯一索引,当被更新字段或插入字段与原有数据冲突时会报错,但因为ingore会忽视这种报错,后端也就不会报错,sql也未执行,达到了目的,有人会对报错敏感,其实也没什么,报错也是在检查数据是发现不合理之处给的一个提醒或警告,对数据库无害的。
9、mysql存在更新,不存在则插入
区别于上面那个需求,这个是当插入的数据存在时更新数据,不再是不做任何操作,例子:
//本例子中title不是唯一索引,id是主键 insert into arc values(1,'标题1号','文章内容') on duplicate key update title='标题1号' //若要更新多个字段使用','隔开,例:title='标题1号',content='文章内容'
在例子中,当id为1的数据存在时,更新标题和内容,不存在则插入,如果执行更新操作,未设置新值的字段保持原来的值。
还有一个REPLACE INTO也可以达到这种效果,区别在于,REPLACE INTO更新时是先删除后插入会破坏原有索引,id为3的数据更新时会删除插入id为4的数据,未更新新值的字段设置为默认值或null。
无论是两个中的哪种方式判断数据是否存在的依据都是主键和唯一索引。
위 내용은 MySQL에서 on, in, as 및 where의 차이점은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7510
7510
 15
1378
52
78
11
53
19
19
64
15
1378
52
78
11
53
19
19
64

 MySQL : 초보자를위한 데이터 관리의 용이성
Apr 09, 2025 am 12:07 AM
MySQL : 초보자를위한 데이터 관리의 용이성
Apr 09, 2025 am 12:07 AM
MySQL은 설치가 간단하고 강력하며 데이터를 쉽게 관리하기 쉽기 때문에 초보자에게 적합합니다. 1. 다양한 운영 체제에 적합한 간단한 설치 및 구성. 2. 데이터베이스 및 테이블 작성, 삽입, 쿼리, 업데이트 및 삭제와 같은 기본 작업을 지원합니다. 3. 조인 작업 및 하위 쿼리와 같은 고급 기능을 제공합니다. 4. 인덱싱, 쿼리 최적화 및 테이블 파티셔닝을 통해 성능을 향상시킬 수 있습니다. 5. 데이터 보안 및 일관성을 보장하기위한 지원 백업, 복구 및 보안 조치.
 MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) 데이터베이스 및 테이블 작성 : CreateAbase 및 CreateTable 명령을 사용하십시오. 2) 기본 작업 : 삽입, 업데이트, 삭제 및 선택. 3) 고급 운영 : 가입, 하위 쿼리 및 거래 처리. 4) 디버깅 기술 : 확인, 데이터 유형 및 권한을 확인하십시오. 5) 최적화 제안 : 인덱스 사용, 선택을 피하고 거래를 사용하십시오.
 phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
다음 단계를 통해 phpmyadmin을 열 수 있습니다. 1. 웹 사이트 제어판에 로그인; 2. phpmyadmin 아이콘을 찾고 클릭하십시오. 3. MySQL 자격 증명을 입력하십시오. 4. "로그인"을 클릭하십시오.
 Navicat Premium을 만드는 방법
Apr 09, 2025 am 07:09 AM
Navicat Premium을 만드는 방법
Apr 09, 2025 am 07:09 AM
Navicat Premium을 사용하여 데이터베이스 생성 : 데이터베이스 서버에 연결하고 연결 매개 변수를 입력하십시오. 서버를 마우스 오른쪽 버튼으로 클릭하고 데이터베이스 생성을 선택하십시오. 새 데이터베이스의 이름과 지정된 문자 세트 및 Collation의 이름을 입력하십시오. 새 데이터베이스에 연결하고 객체 브라우저에서 테이블을 만듭니다. 테이블을 마우스 오른쪽 버튼으로 클릭하고 데이터 삽입을 선택하여 데이터를 삽입하십시오.
 MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL은 개발자에게 필수적인 기술입니다. 1.MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템이며 SQL은 데이터베이스를 관리하고 작동하는 데 사용되는 표준 언어입니다. 2.MYSQL은 효율적인 데이터 저장 및 검색 기능을 통해 여러 스토리지 엔진을 지원하며 SQL은 간단한 문을 통해 복잡한 데이터 작업을 완료합니다. 3. 사용의 예에는 기본 쿼리 및 조건 별 필터링 및 정렬과 같은 고급 쿼리가 포함됩니다. 4. 일반적인 오류에는 구문 오류 및 성능 문제가 포함되며 SQL 문을 확인하고 설명 명령을 사용하여 최적화 할 수 있습니다. 5. 성능 최적화 기술에는 인덱스 사용, 전체 테이블 스캔 피하기, 조인 작업 최적화 및 코드 가독성 향상이 포함됩니다.
 Navicat에서 MySQL에 새로운 연결을 만드는 방법
Apr 09, 2025 am 07:21 AM
Navicat에서 MySQL에 새로운 연결을 만드는 방법
Apr 09, 2025 am 07:21 AM
응용 프로그램을 열고 새로운 연결 (Ctrl n)을 선택하여 Navicat에서 새로운 MySQL 연결을 만들 수 있습니다. "MySQL"을 연결 유형으로 선택하십시오. 호스트 이름/IP 주소, 포트, 사용자 이름 및 비밀번호를 입력하십시오. (선택 사항) 고급 옵션을 구성합니다. 연결을 저장하고 연결 이름을 입력하십시오.
 SQL이 행을 삭제 한 후 데이터를 복구하는 방법
Apr 09, 2025 pm 12:21 PM
SQL이 행을 삭제 한 후 데이터를 복구하는 방법
Apr 09, 2025 pm 12:21 PM
백업 또는 트랜잭션 롤백 메커니즘이없는 한 데이터베이스에서 직접 삭제 된 행 복구는 일반적으로 불가능합니다. 키 포인트 : 거래 롤백 : 트랜잭션이 데이터를 복구하기 전에 롤백을 실행합니다. 백업 : 데이터베이스의 일반 백업을 사용하여 데이터를 신속하게 복원 할 수 있습니다. 데이터베이스 스냅 샷 : 데이터베이스의 읽기 전용 사본을 작성하고 데이터를 실수로 삭제 한 후 데이터를 복원 할 수 있습니다. 주의해서 삭제 명령문을 사용하십시오. 실수로 데이터를 삭제하지 않도록 조건을주의 깊게 점검하십시오. WHERE 절을 사용하십시오 : 삭제할 데이터를 명시 적으로 지정하십시오. 테스트 환경 사용 : 삭제 작업을 수행하기 전에 테스트하십시오.
 단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
Redis는 단일 스레드 아키텍처를 사용하여 고성능, 단순성 및 일관성을 제공합니다. 동시성을 향상시키기 위해 I/O 멀티플렉싱, 이벤트 루프, 비 블로킹 I/O 및 공유 메모리를 사용하지만 동시성 제한 제한, 단일 고장 지점 및 쓰기 집약적 인 워크로드에 부적합한 제한이 있습니다.
