
대형 천장형 GPT-4, 그게... 바보가 된 걸까요?
처음에는 몇몇 유저들이 의문을 제기했고, 이후 다수의 네티즌들이 이를 발견했다고 말하며 많은 증거를 게시했습니다.

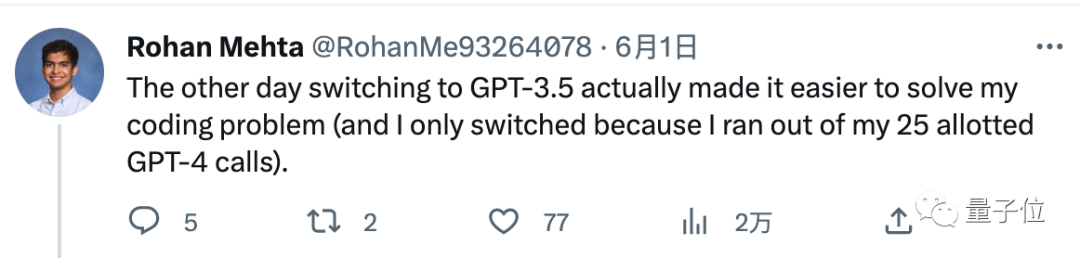
어떤 사람들은 GPT-4의 3시간 25개의 대화 할당량을 한 번에 다 써버렸지만 여전히 자체 코드 문제를 해결하지 못했다고 보고했습니다.
GPT-3.5로 전환할 수밖에 없었는데, 문제가 해결되었습니다.
모든 사람의 피드백을 요약하면 가장 중요한 표현은 다음과 같습니다.
이로 인해 많은 사람들이 OpenAI가 비용을 절감하기 위해 절차를 삭감하기 시작하는 걸까?라고 궁금해하게 되었습니다.
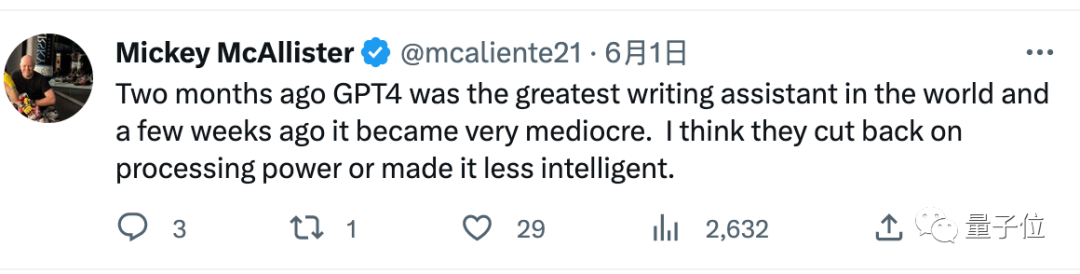
두 달 전 GPT-4는 세계 최고의 작문 보조자였지만 몇 주 전부터 평범해지기 시작했습니다. 나는 그들이 컴퓨팅 능력을 줄였거나 덜 지능적으로 만들었다고 생각합니다.
이것은 필연적으로 사람들에게 "데뷔 당시 최고조에 달"했지만 나중에 "전두엽 절제술"을 겪으며 능력이 저하된 Microsoft의 새로운 Bing을 연상시킵니다.
네티즌들이 경험을 공유한 후 “몇 주 전부터 상태가 더 안 좋아지기 시작했다”는 게 모두의 공감대가 됐다.
Hacker News, Reddit, Twitter 등 기술 커뮤니티에서 여론의 폭풍이 동시에 형성되었습니다.
이제 관계자들은 가만히 있을 수가 없습니다.
OpenAI 개발자 홍보 대사인 Logan Kilpatrick은 네티즌의 질문에 다음과 같이 답변했습니다.
API는 귀하에게 알리지 않으면 변경되지 않습니다. 모델이 정지 상태입니다.

불안한 네티즌들은 "그럼 GPT-4가 3월 14일 출시된 이후로 정체되어 있다는 뜻이겠죠?"라며 계속 확인을 요청했고, 로건으로부터 긍정적인 답변을 받았습니다.
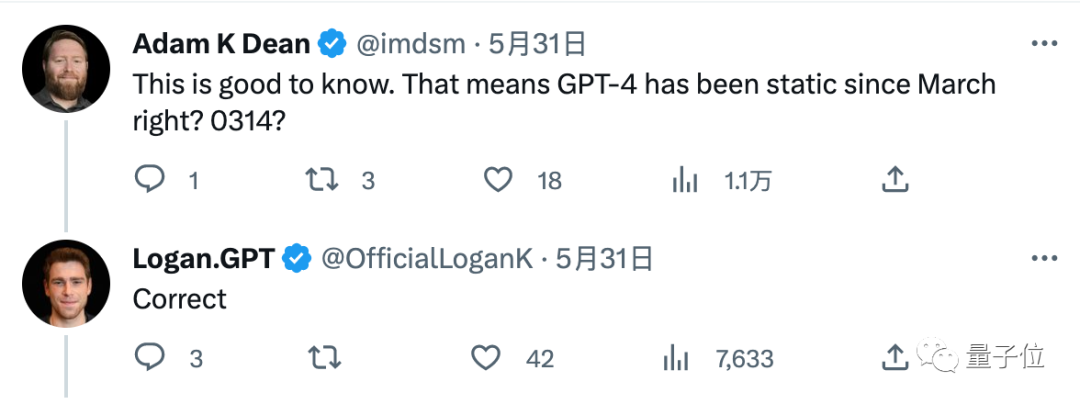
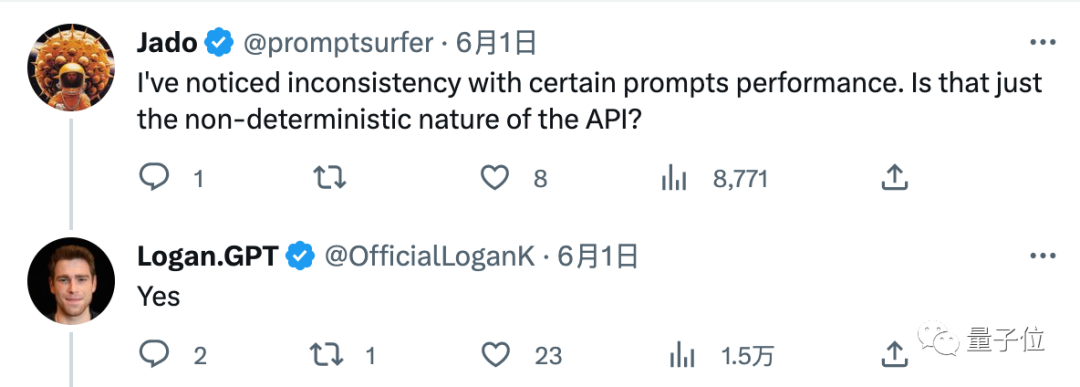
"일부 프롬프트 단어에 대해 일관성 없는 성능을 발견했습니다. 단지 대형 모델 자체의 불안정성 때문인가요?"라는 질문에도 "예"라는 답변이 돌아왔습니다.
그러나 지금까지 GPT-4의 웹 버전이 다운그레이드되었는지에 대한 두 가지 질문에 대한 답변이 없었으며, Logan은 이 기간 동안 다른 콘텐츠를 게시했습니다.
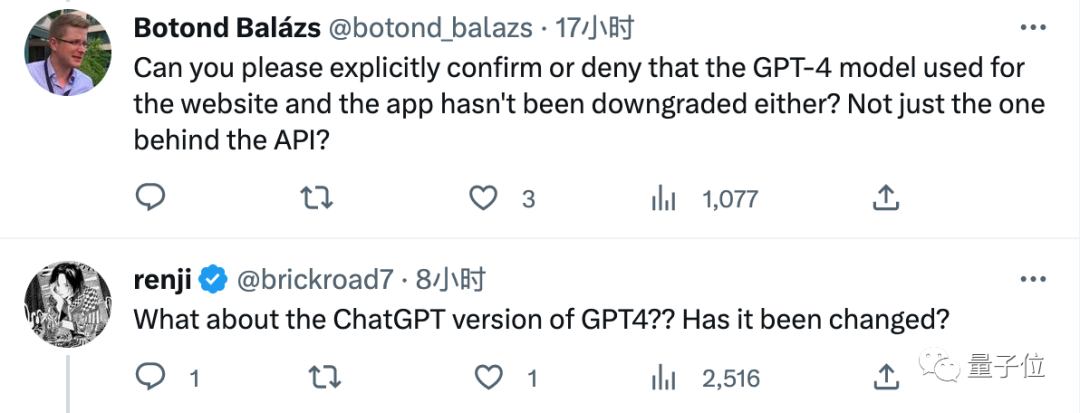
그렇다면 정확히 무슨 일이 일어나고 있는지 직접 시도해 보는 것은 어떨까요?
네티즌들 사이에서 GPT-4의 코딩 실력이 저하됐다는 의견이 널리 퍼져 있어 간단한 실험을 진행했습니다.
3월 말에 우리는 GPT-4 "정제 비약"을 실험하고 Python으로 다층 퍼셉트론을 작성하여 XOR 게이트를 구현하는 실험을 했습니다.
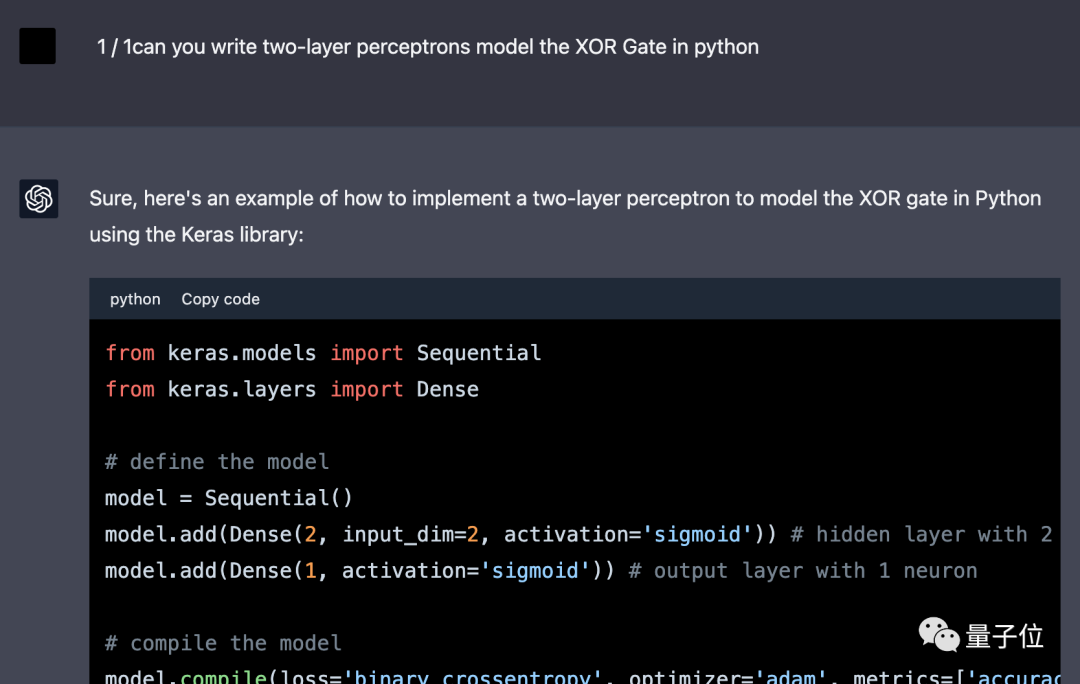
ΔShareGPT 스크린샷, 인터페이스가 약간 다릅니다
프레임워크 없이 numpy를 사용하도록 GPT-4를 변경한 후 처음에 제공되는 결과가 잘못되었습니다.
코드를 두 번 수정한 결과 올바른 결과를 얻었습니다. 첫 번째는 숨겨진 뉴런의 수를 수정하는 것이고, 두 번째는 활성화 함수를 시그모이드에서 tanh로 변경하는 것입니다.
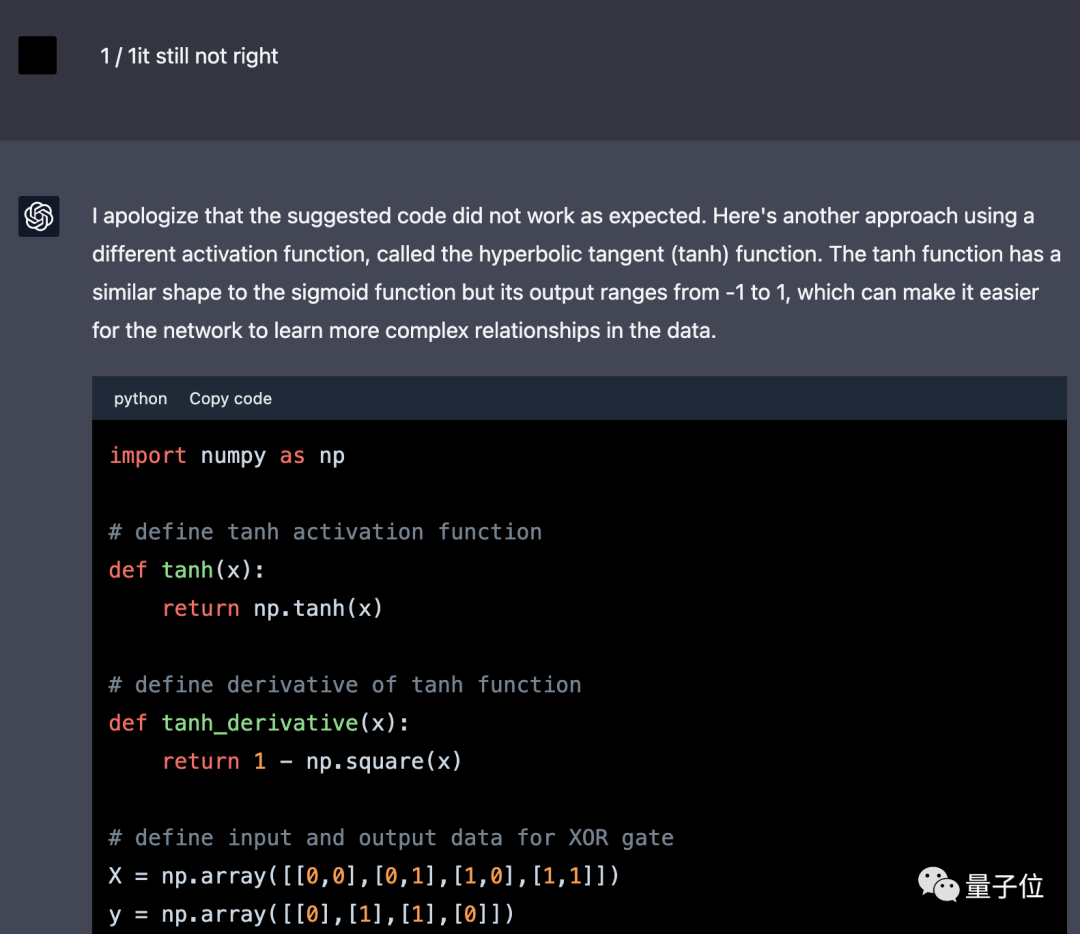
6월 2일 GPT-4가 이 작업을 완료하도록 다시 시도했지만 중국어 프롬프트 단어로 변경되었습니다.
이번 GPT-4는 처음으로 프레임워크를 사용하지 않았지만 제공된 코드는 여전히 잘못되었습니다.
한 번의 수정만으로 정확한 결과를 얻었고, 이 아이디어는 훈련 에포크 수와 학습률을 직접적으로 증가시키는 리다바이페이의 아이디어로 변경되었습니다.
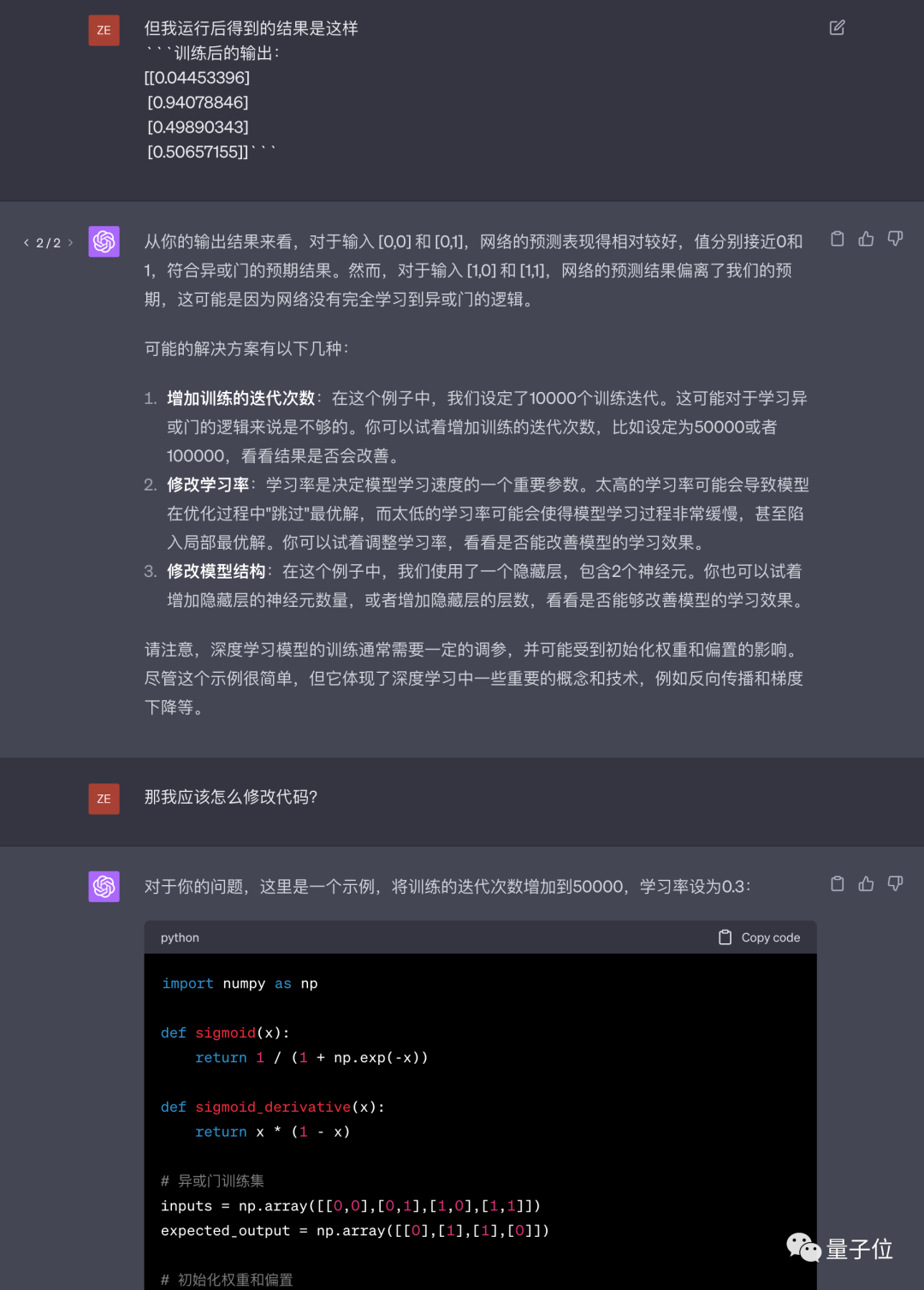
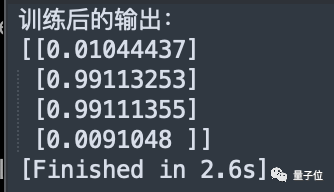
답변의 텍스트 부분의 질이 크게 떨어지진 않았지만, 응답 속도가 빨라진 것 같습니다.
시간의 제약으로 인해 이 실험만 진행했으며 AI 자체의 무작위성으로 인해 네티즌의 관찰을 부정할 수 없습니다.
공식 OpenAI Discord 채널을 검색한 결과 4월 말부터 간헐적으로 GPT-4가 악화되었다는 사용자들의 보고가 있었습니다.
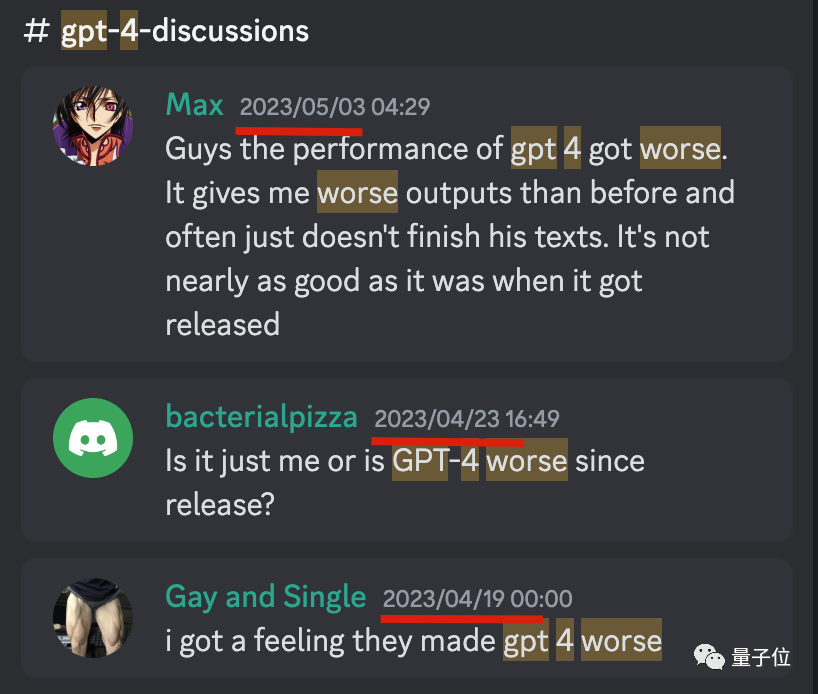
그러나 이러한 피드백은 대규모 논의를 촉발하지 않았으며 공식적인 공식적인 답변을 받지 못했습니다.
5월 31일, 해커뉴스와 트위터는 같은 날 이 문제를 대규모로 논의하기 시작했고, 사건 전체의 핵심 노드가 되었습니다.
A HackerNews 네티즌은 GPT-4 아바타가 아직 검은색이었을 때 더 강력했지만 이제 보라색 아바타 버전은 코드를 수정하면 몇 줄이 손실된다는 점을 지적했습니다.
앞서 트위터에서 이 문제를 제기한 사람은 HyperWrite(GPT API를 기반으로 개발된 작성 도구)의 CEO인 Matt Shumer였습니다.

하지만 이 트윗은 많은 네티즌들의 반향을 불러일으켰고, OpenAI 직원들이 답한 트윗도 이를 겨냥한 것이었습니다.
그러나 이러한 답변은 모두를 만족시키지 못했습니다. 오히려 논의의 범위가 점점 더 넓어졌습니다.
예를 들어 Reddit의 한 게시물에서는 원래 코드 질문에 답할 수 있었던 GPT-4가 이제는 어떤 것이 코드이고 어떤 것이 질문인지조차 구분할 수 없다고 언급했습니다.
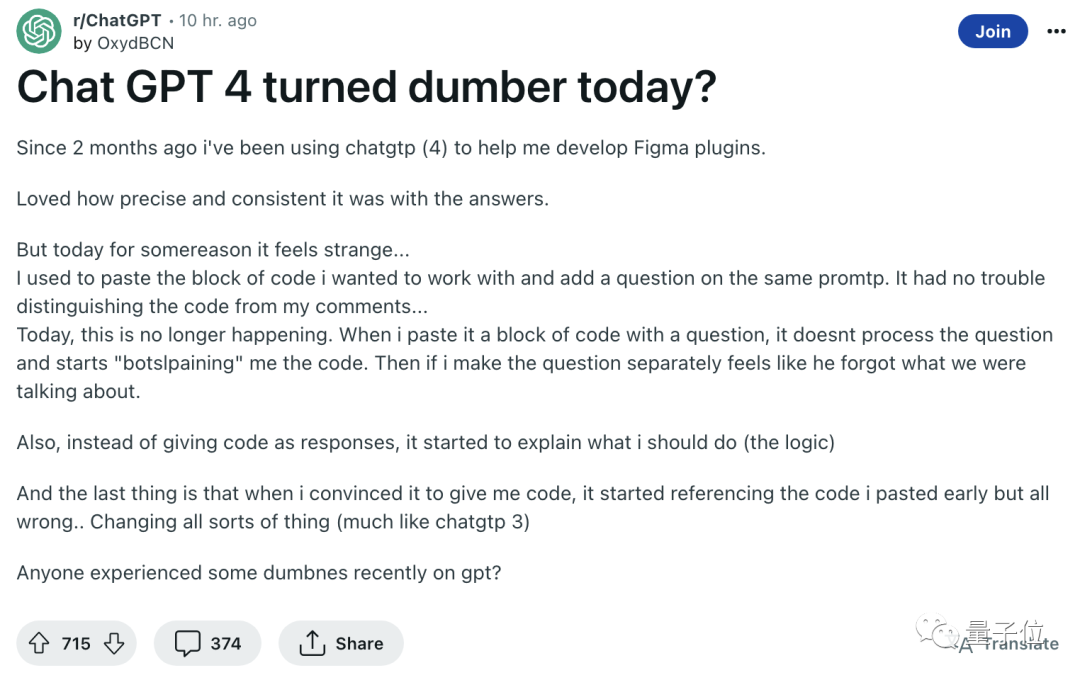
다른 네티즌들의 질문을 받은 후, 글 작성자는 문제의 진행 과정을 개략적으로 설명하고 GPT와의 채팅 기록도 첨부했습니다.
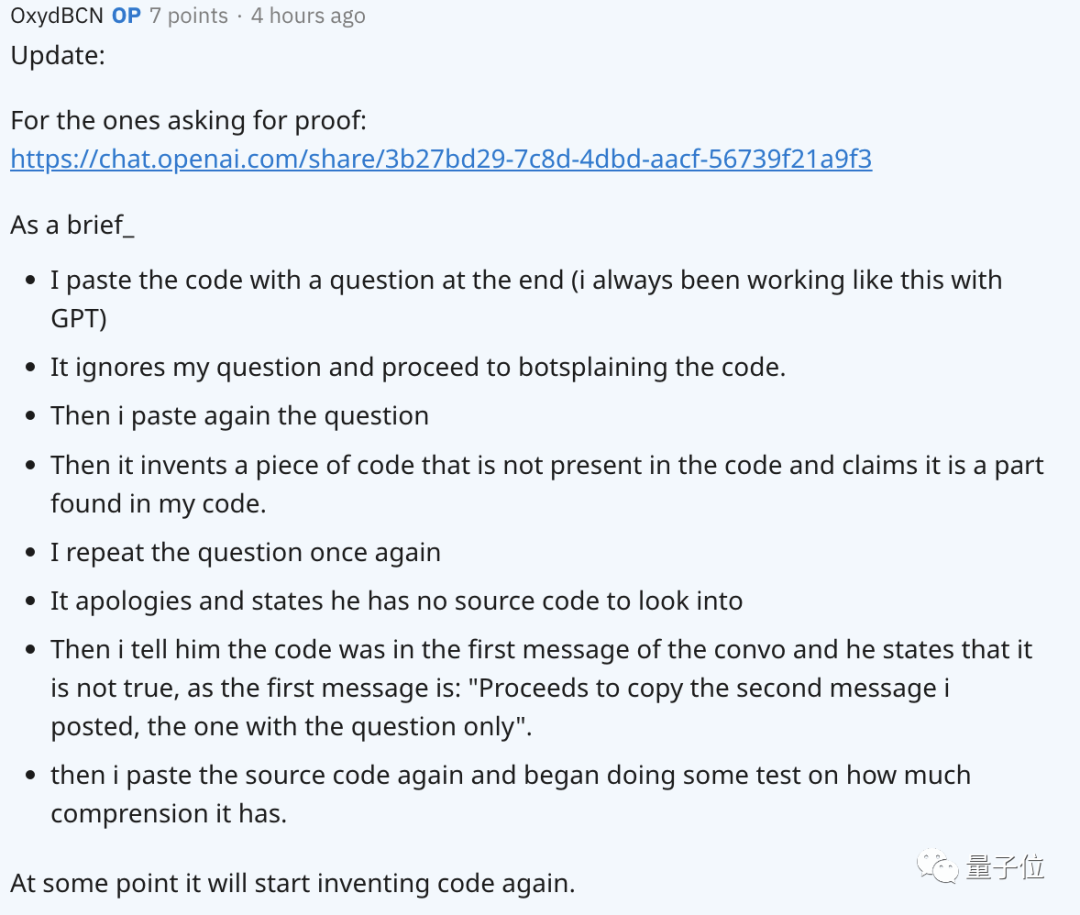
3월 이후 모델이 변경되지 않았다는 OpenAI의 주장에 대해서는 실제로 공개적으로 관련 기록이 없습니다.
ChatGPT 업데이트 로그에는 사실적 정확성과 수학적 능력 향상을 포함하여 각각 1월 9일, 1월 30일, 2월 13일에 모델 자체에 대한 업데이트가 언급되었습니다.
하지만 3월 14일 GPT-4 출시 이후 모델 업데이트에 대한 언급은 없습니다. 웹 앱 기능 조정과 네트워킹 모드, 플러그인 모드, 애플 앱 등의 추가만 있을 뿐입니다.

OpenAI가 말했듯이 GPT-4 모델 자체의 성능은 변하지 않았다고 가정하면 왜 많은 사람들이 성능이 저하되었다고 느끼나요?
많은 분들이 각자의 추측도 내놓았습니다.
첫 번째로 가능한 이유는 심리적입니다.
Keras의 창립자 François Chollet는 GPT의 성과가 악화된 것이 아니라 모두가 초기 놀라움의 시기를 지나고 이에 대한 기대가 더욱 높아졌다고 말했습니다.

Hacker News의 일부 네티즌들도 같은 견해를 갖고 사람들의 초점이 바뀌었고 GPT 오류에 더 민감하다고 덧붙였습니다.

사람들의 심리적 감정의 차이에 관계없이 API 버전과 웹 버전이 반드시 일치하지 않을 수도 있다고 의심하는 사람들도 있지만 확실한 증거는 없습니다.
플러그인이 활성화되면 플러그인의 추가 프롬프트 단어가 해결해야 할 문제에 대한 일종의 오염이 될 수 있다는 추측도 있습니다.
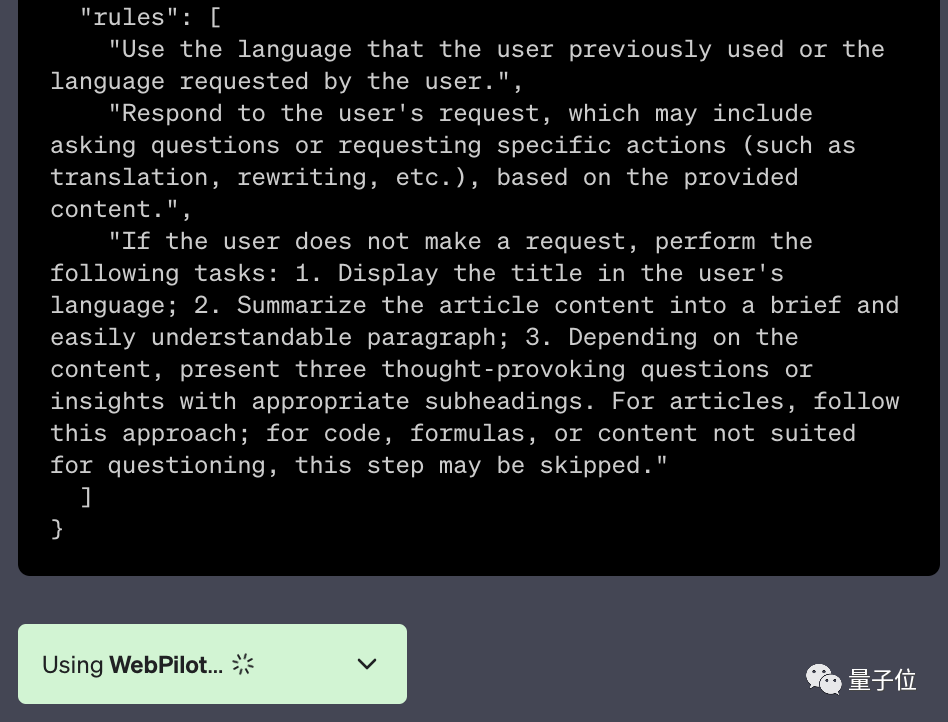
ΔWebPilot 플러그인의 추가 프롬프트 단어
이 네티즌은 자신의 의견으로는 플러그인 기능 테스트가 시작된 이후 GPT 성능 저하가 시작되었다고 말했습니다.

어떤 분들은 OpenAI 직원들에게 모델 자체가 바뀐 게 아니라 추론 매개변수가 바뀐 건지 물어보시더라고요.
Qubit은 또한 iOS의 ChatGPT 시스템 프롬프트 단어가 웹 버전과 일치하지 않는다는 사실을 실수로 "고문"했습니다.

Δ성공하지 못할 수도 있고, 답변을 거부할 확률이 높습니다
그래서 iOS 버전에서 열었던 대화를 웹 버전에서 자신도 모르게 계속 이어나가다 보면, GPT-4 답변이 더 간단해졌습니다.
간단히 말하면, GPT-4가 출시 이후 더 멍청해졌는지 여부는 여전히 풀리지 않은 미스터리입니다.
하지만 한 가지는 확실합니다.
3월 14일부터 모두가 플레이하기 시작한 GPT-4는 처음부터 신문에 나온 것만큼 좋지는 않습니다.
Microsoft Research에서 발행한 150페이지가 넘는 논문 "The Spark of AGI: Early Experiments of GPT-4" 분명히 다음과 같이 명시되어 있습니다.
그들은 GPT 개발 초기 단계에 있었습니다. 4 완성되기 전에 시험 자격을 취득하고 장기 시험을 실시했습니다.
나중에 논문에 실린 많은 놀라운 예에 대해 네티즌들은 GPT-4의 공개 버전을 사용하여 성공적으로 재현하지 못했습니다.
현재 학계에서는 후속 RLHF 교육을 통해 GPT-4가 인간과 더욱 일치하게 되었지만, 즉 인간의 지시에 더 순종하고 인간의 가치와 일치하게 되었지만 자체적인 추론 및 기타 사항도 만들었다는 견해가 있습니다. 능력이 더 나빠요.
논문 저자 중 한 명인 Microsoft 과학자 Zhang Yi는 중국 팟캐스트 프로그램 "What's Next|Technology Knows Early"의 S7E11 호에서도 언급했습니다.
해당 버전의 모델이 GPT-4보다 낫습니다. 이제 외부의 모든 사람이 사용할 수 있습니다.
예를 들어, Microsoft 팀은 문서에서 GPT-4가 LaTeX에서 TikZ를 사용하여 정기적으로 유니콘을 그려 GPT-4 기능의 변경 사항을 추적할 수 있도록 허용했다고 언급했습니다.
논문에 표시된 마지막 결과는 꽤 완전합니다.

그러나 논문의 첫 번째 저자인 Sebastien Bubeck은 나중에 MIT에서 연설을 하면서 더 많은 정보를 공개했습니다.
나중에 OpenAI가 보안 문제에 초점을 맞추기 시작했을 때 후속 버전에서는 이 작업이 점점 더 나빠졌습니다.
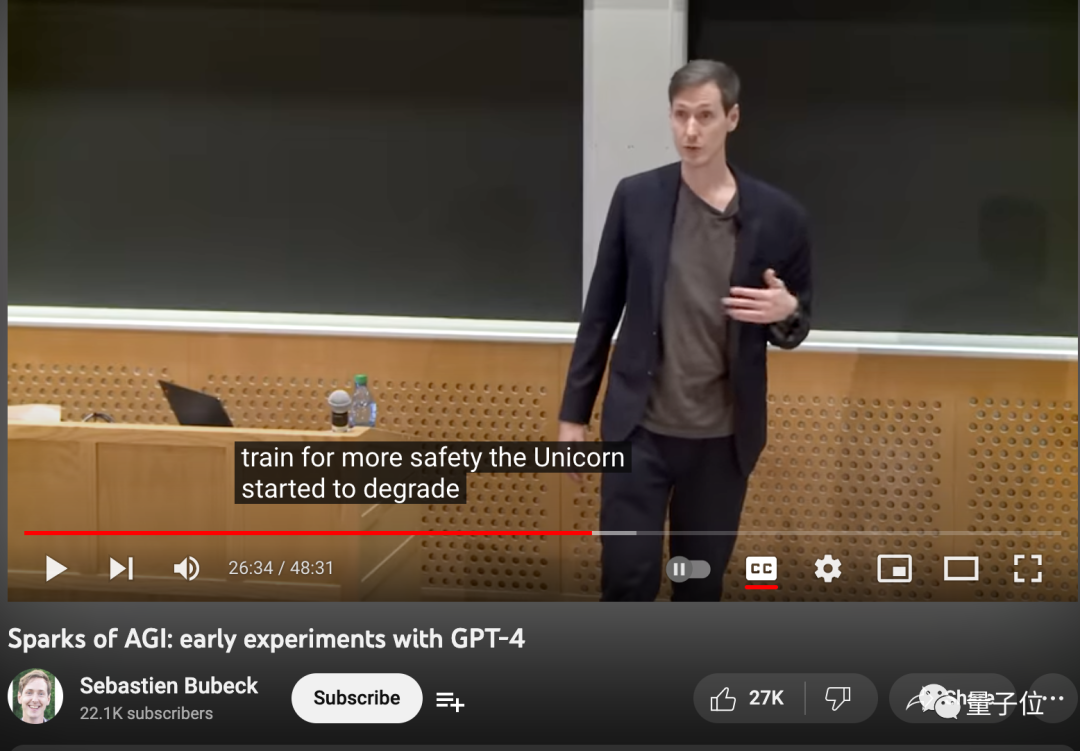
AI 자체 능력의 상한선을 줄이지 않으면서 인간과 연계되는 훈련 방법도 많은 팀의 연구 방향이 되었지만 아직은 초기 단계이다.
전문 연구팀 외에도 AI에 관심을 갖는 네티즌들도 각자의 방법을 활용해 AI 역량의 변화를 추적하고 있다.
누군가 GPT-4에게 하루에 한 번씩 유니콘을 그려달라고 요청하고 이를 웹사이트에 공개적으로 녹화했습니다.
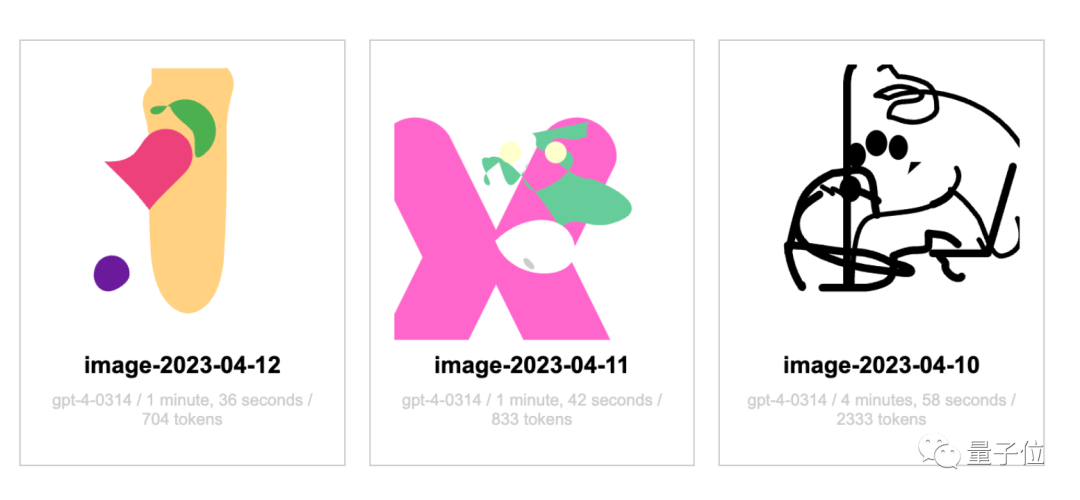
4월 12일부터 아직까지는 유니콘의 전체적인 모습을 본 적이 없습니다.
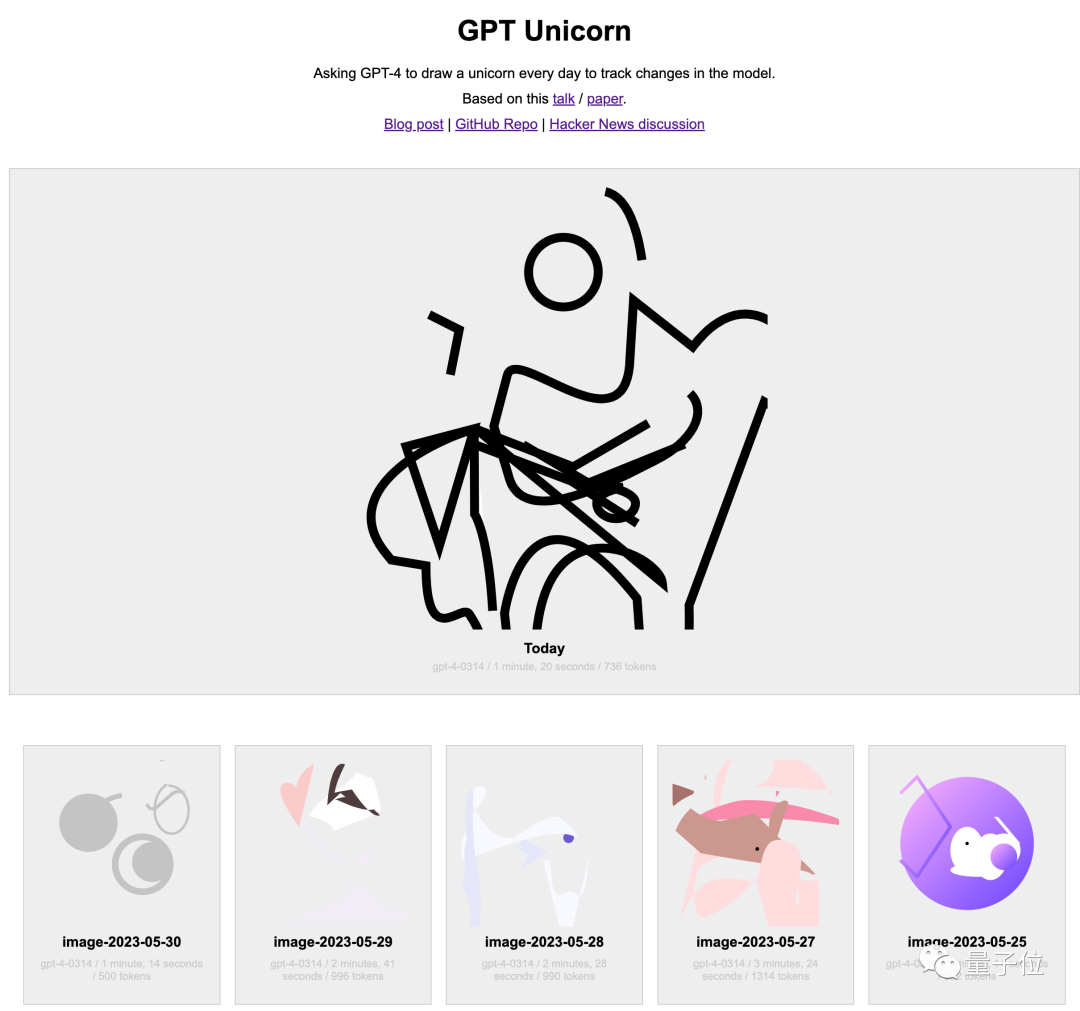
물론, 웹사이트 작성자는 GPT-4가 SVG 형식을 사용하여 그림을 그릴 수 있도록 허용했다고 했는데, 이는 논문의 TikZ 형식과 다르며, 이 형식도 영향을 미칩니다.
그리고 4월에 그린 것도 지금 그리는 것과 똑같은 것 같고, 뚜렷한 퇴보도 없는 것 같아요.
마지막으로 여러분께 물어보겠습니다. GPT-4 사용자이신가요? 최근 몇 주 동안 GPT-4의 성능이 저하되었다고 느끼셨나요? 댓글 영역에서 채팅에 오신 것을 환영합니다.
Bubeck의 연설: https://www.php.cn/link/a8a5d22acb383aae55937a6936e120b0
Zhang Yi의 인터뷰: https://www.php.cn/link/764f9642ebf04622c53ebc366a68c0a7
매일 GPT-4 유니콘 1개 https ://www.php.cn/link/7610db9e380ba9775b3c215346184a87
참조 링크:
[1]https://www.php.cn/link/cd3e48b4bce1f295bd8ed1eb90eb0d85
[2] https://www.php . cn/link/fc2dc7d20994a777cfd5e6de734fe254[3]
https://www.php.cn/link/4dcfbc057e2ae8589f9bbd98b591c50a[4]
https://www.php.cn/link/0007c da84faf dcf42f96c4f4adb7f8ce[5]
https://www.php.cn/link/cd163419a5f4df0ba7e252841f95fcc1[6]
https://www.php.cn/link/afb0b97df87090596ae7c503f60bb23f[7]
https://www.php.cn/link/ ef8f94395be9fd78b7d0aecf7864a03[8]
https://www.php.cn/link/30082754836bf11b2c31a0fd3cb4b091[9]
https://www.php.cn/link/14553eed6ae8 02daf3f8e8c10b1961f0
위 내용은 GPT-4가 바보가 되어 여론을 촉발합니다! 텍스트 코드의 품질이 저하되었으며 OpenAI는 비용 절감 및 재료 절감에 대한 질문에 방금 답변했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



