

이상한 것부터 시작해 보겠습니다.
문제를 재현하기 위해 데이터를 생성하고 사용자 테이블을 생성합니다.
CREATE TABLE `user` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID', `name` varchar(100) NOT NULL DEFAULT '' COMMENT '姓名', `age` int(11) NOT NULL DEFAULT 0 COMMENT '年龄', PRIMARY KEY (`id`), KEY `idx_age` (`age`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
사용자 연령 배치를 통해 해당 연령의 사용자 정보를 쿼리하고 확인합니다. SQL 실행 계획:
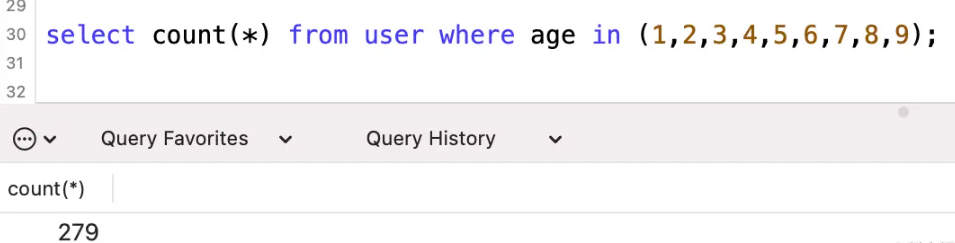
explain select * from user where age in (1,2,3,4,5,6,7,8,9);

where 조건에는 9개의 매개변수가 있습니다. 실행 계획에서 스캔된 행의 예상 수인 279개에 집중하세요.
여기에는 문제가 없습니다. 추정치는 매우 정확합니다. 실제로는 279줄입니다.
그런데 문제가 발생합니다. where 조건에 또 다른 매개변수를 추가하면 10개의 매개변수가 됩니다. 스캔되는 줄의 예상 개수가 늘어났어야 했는데 결과가 크게 줄었습니다.
explain select * from user where age in (1,2,3,4,5,6,7,8,9,10);

갑자기 30줄로 줄었는데 실제 줄수는 얼마나 되나요?
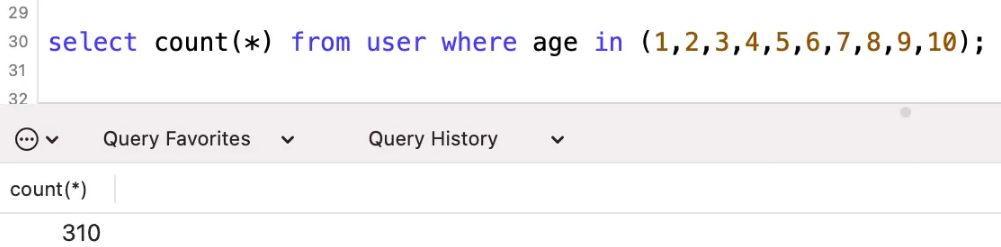
실제 개수는 310줄이고, 스캔한 줄의 예상 개수는 30줄입니다. 정말 할머니의 실수입니다.
MySQL에 무슨 일이 일어나고 있나요? 아직 추정할 수 있나요?
예측할 수 없다면 다른 사람을 이용하세요!
공식 홈페이지에 가서 Index dive라는 단어를 보기 전까지 다들 혼란스러웠을 거에요.
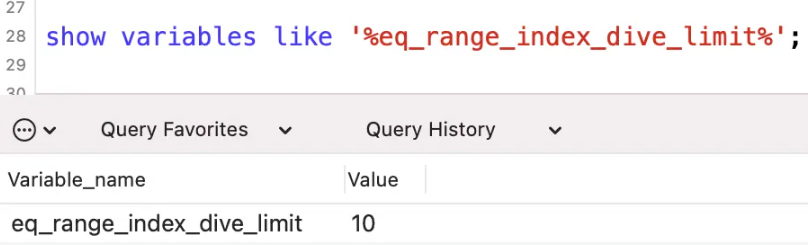
이 단어와 관련하여 구성 매개변수 eq_range_index_dive_limit도 있습니다.
MySQL5.7.3버전 이전에는 이 값이 10으로 기본 설정되었고, 이후 버전에서는 이 값이 200으로 기본 설정되었습니다.
다음 명령을 사용하여 이 값의 크기를 확인할 수 있습니다.
show variables like '%eq_range_index_dive_limit%';
물론 이 값의 크기를 수동으로 수정할 수도 있습니다.
set eq_range_index_dive_limit=200;
이 eq_range_index_dive_limit의 역할 구성은 다음과 같습니다.
When where 조건문의 매개변수 수가 이 값보다 작으면 MySQL은 index dive를 사용하여 스캔된 행 수를 추정하는데 이는 매우 정확합니다.
where 문의 조건에 있는 매개 변수의 수가 이 값보다 크거나 같으면 MySQL은 또 다른 방법인 인덱스 통계(인덱스 통계) 를 사용하여 큰 오류와 함께 스캔된 행 수를 추정합니다.
MySQL이 왜 이런 일을 합니까?
우리 모두는 Index dive를 사용하여 스캔된 라인 수를 추정하는데, 좋지 않나요?
사실 이는 비용을 고려한 것입니다. 인덱스 다이빙 예상 비용이 더 높으며 작은 데이터 볼륨에 적합합니다. 인덱스 통계예상 비용이 저렴하고 대용량 데이터에 적합합니다.
일반적으로 where 문의 조건은 매개변수가 너무 많지 않기 때문에 index diving을 사용하여 스캔된 행 수를 추정하는 데 적합합니다.
이전 버전의 MySQL5.7.3을 사용하는 학생은 index diving의 구성 매개변수를 적절한 값으로 수동으로 수정하는 것이 좋습니다.
프로젝트의 조건에 최대 500개의 매개변수가 있는 경우 구성 매개변수를 501로 변경하세요.
이러한 방식으로 MySQL은 스캔된 행 수를 더 정확하게 추정하고 더 적절한 인덱스를 선택할 수 있습니다.
위 내용은 MySQL 쿼리 성능 최적화를 위한 인덱스 다이빙 인스턴스 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



