

인덱스가 너무 적으면 쿼리 효율성이 낮아지고, 인덱스가 너무 많으면 프로그램 성능에 영향을 미치므로 인덱스 사용은 실제 상황과 일치해야 합니다.
Innodb에서 지원하는 인덱스는 다음과 같습니다.
역 인덱스를 사용하는 전체 텍스트 검색
해시 인덱스, 적응형, 사람 개입 없음, 버퍼 풀의 클러스터형 인덱스 페이지를 기반으로 생성되며 전체 테이블은 해시 인덱싱이 이루어지므로 인덱싱 속도가 매우 빠릅니다.
B+ 트리 인덱스는 전통적인 의미의 인덱스로, 현재 관계형 데이터베이스에서 가장 효과적이고 일반적으로 사용되는 인덱스입니다.
B+ 트리는 테이블에서 특정 행 레코드를 찾을 수 없지만 행 레코드가 있는 페이지를 반환하여 최종적으로 행 레코드의 슬롯 정보와 다음 레코드 정보를 기반으로 메모리에서 정확하게 찾습니다. 머리글.
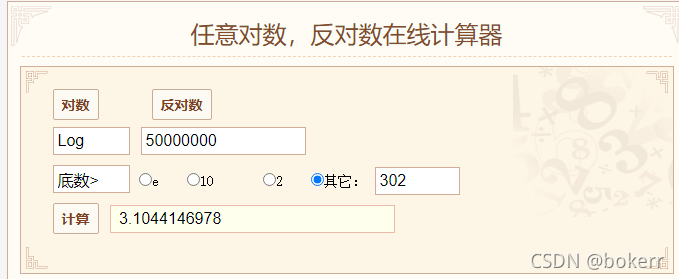
이진 검색은 순서가 지정된 선형 데이터 집합을 검색하는 데만 사용할 수 있으며, 매번 중앙값을 가져와서 가장 작은 값에서 앞으로 이동하고 가장 큰 값에서 뒤로 이동합니다. . 순서 배열에서 숫자 48을 찾는 시간 복잡도는 아래 그림과 같이 log N입니다.
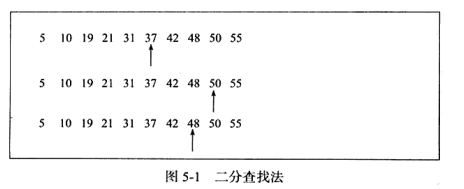
이진 검색 트리는 다음을 만족하는 이진 트리를 말합니다. 모든 노드의 왼쪽 자식 노드는 자신보다 작으며 모든 노드 A 오른쪽 자식 노드가 자신보다 큰 이진 트리는 이진 검색 트리입니다.
일반 이진 트리는 O(logN) 액세스 시간을 보장할 수 없습니다. 극단적인 경우 연결 목록으로 변질될 수도 있기 때문입니다.
이진 트리를 만들기 위해 정렬된 데이터 집합을 구성하면 연결 목록이 얻어집니다. 이때 시간 복잡도는 O(N)
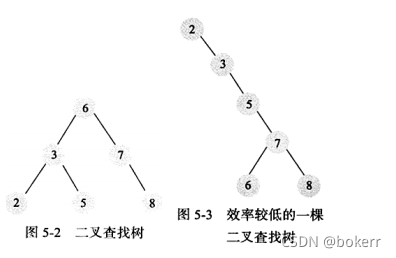
입니다. 균형 이진 트리 및 이진 트리 포크 검색 트리는 유사하지만 제한 사항이 추가됩니다. 즉, 각 노드의 왼쪽 및 오른쪽 하위 트리 높이가 최대 1만큼 다릅니다. 이진 트리를 구축하는 과정에서 이 조건을 위반하면 적절한 회전을 통해 해결할 수 있습니다.
균형 이진 트리는 O(logN)의 시간 복잡도를 보장합니다.
O(logN)의 액세스 시간을 보장할 수 있지만 데이터베이스 인덱싱에는 적합하지 않습니다.
데이터 양이 다음과 같은 경우 매우 크면 이진 트리의 높이가 급격히 증가하므로(예를 들어 1024는 2의 10승과 같습니다) log(N)도 매우 중요합니다.
디스크 IO를 여러 번 수행하는 것은 이진 트리의 리프 노드가 하나의 데이터만 수용할 수 있기 때문인데, 이것이 가장 불리한 특징입니다. 그러나 실제 애플리케이션에서는 CPU가 명령을 실행하는 데 걸리는 시간에 비해 빈번한 디스크 읽기는 재앙이 될 것입니다. 따라서 이진 트리는 데이터베이스 인덱싱에 적합하지 않습니다.
기계식 하드 디스크의 경우 액세스 시간은 디스크 속도와 헤드 이동 시간에 따라 달라지며 이는 모두 기계 구조에 의해 완성됩니다. CPU에서 실행되는 전기 신호 명령과 비교할 때 속도는 매우 다릅니다.
1천만 데이터, 균형 이진 트리를 사용하면(최악의 시간 제한은 1.44 * logN), 최악의 시간 제한을 취하지 않더라도 log(N)을 기준으로 최종 계산하면 약 24가 되며, 이는 이는 24개의 디스크 IO가 필요하다는 것을 의미하며 이는 분명히 작동하지 않습니다.
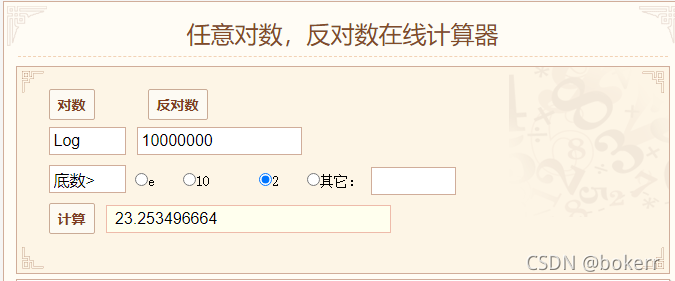
[트리 높이는 반올림된 로그 값입니다. 예: log3 = 1.58, 트리 높이는 2입니다.]
균형 이진 트리의 한계로 인해 B+ 트리가 필요합니다. 소개됩니다.
B+ 트리는 디스크나 기타 직접 액세스 보조 장치를 위해 특별히 설계된 균형 검색 트리입니다. B+ 트리에서는 모든 레코드 노드가 키 값의 크기에 따라 동일한 레이어의 리프 노드에 순차적으로 저장됩니다. 연결을 위한 리프 노드 포인터입니다.
M차 B+ 트리는 다음 속성을 충족해야 합니다.
다음 모든 정의에서 두 숫자의 나눗셈에 대해 정수로 나눌 수 없으면 반올림합니다. 소수점 자리를 버리는 대신 정수. (부등식을 추론하는 경우는 제외)
1) 데이터 항목은 리프 노드에 있어야 합니다
2) 비리프 노드는 검색 방향을 나타내는 M-1 키워드를 저장합니다. 키워드 i는 i + 1번째 비리프 노드를 나타냅니다. 하위 트리에서 가장 작은 키워드입니다. 5차 B+ 트리를 가정하면 5 - 1 = 4개의 키워드가 있습니다.
3) B+ 트리에는 루트 노드로 리프 노드가 하나만 있습니다(하위 노드 없음). 하위 노드가 있는 경우 노드 수는 {2~M} 세트에 속해야 합니다.
4) 루트의 경우 모든 비- 리프 노드의 하위 노드 수는 집합에 속해야 합니다: {M/2, M}
5) 모든 리프는 동일한 깊이에 있으며, 리프 노드는 { L/2, L} 세트에 속해야 합니다.
모든 필드의 총 길이가 50바이트 기본 키를 초과하지 않는다고 가정합니다. 예를 들어, 행 레코드 자체가 차지하는 공간을 포함하여 B+ 트리를 시뮬레이션하고 파생시킵니다
모든 행 레코드는 가변 길이 필드, 행 레코드 헤더, 트랜잭션 ID, 롤백 포인터 등과 같은 행 정보를 기록하기 위해 일부 바이트를 소비하는 것으로 알려져 있습니다.
create table context( id varchar(50) primary key, name varchar(50) not null, description varchar(360) );
리프 노드는 데이터 페이지를 나타내며 M 및 L 값의 선택은 이와 밀접한 관련이 있습니다. 데이터 페이지 크기가 P/바이트라고 가정합니다(이 기사에서 설명하는 MySQL을 예로 들면, 데이터 페이지의 크기는 16K, 즉 16384바이트입니다. )
비리프 노드에서: B+ 트리의 키는 기본 키이고, 이 예에서는 기본 키가 50바이트라고 가정합니다. M 순서 B+ 트리의 키는 M -1이며 다음을 차지합니다. 50 * (M - 1) 바이트의 공간
및 M 하위 노드를 가리키는 분기 포인터(각 분기 포인터가 4바이트의 저장 공간을 차지한다고 가정) 리프가 아닌 노드에서 총 공간 소비는 50 * (M - 1) + 4 * M = 54M - 50바이트입니다.
MySQL을 사용하고 기본 키가 50바이트라고 가정하면 부등식은 54M - 50 <= P로 설정됩니다. 여기서 P = 16384이면 M에 대한 해법은 다음과 같습니다: M <= 302, 최대 옵션 값 M 차수 대략: 302개, 여기서는 최대 302개 차수 B+ 트리를 선택할 수 있습니다.
리프 노드에서 알려진 테이블에 정의된 각 행의 최대 용량은 500바이트입니다. 이때 다음과 같은 식이 성립됩니다. L * 500 <= 16384가 성립됩니다. L < = 32, 이때 선택할 수 있는 최대 L은 32입니다.
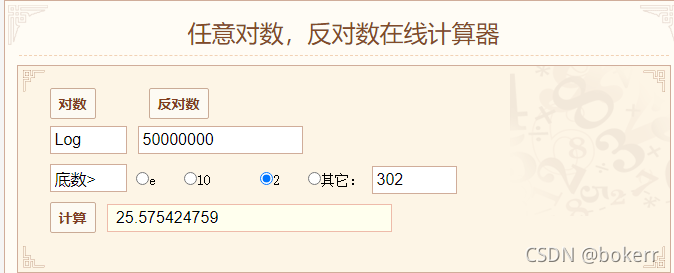
아래 그림과 같이 현재 5000W의 데이터가 있고 트리 높이가 3보다 큽니다. 즉, 데이터를 찾는 데 최대 4개의 디스크 IO만 필요하다는 의미입니다.
아래 그림을 참조하세요. 균형 이진 트리의 최악의 시간 경계는 1.44 * logN = 25.58 * 1.44 = 36.83입니다. 즉, 5000W 데이터가 균형 이진 트리를 사용하면 트리가 초과됩니다. 최악의 경우 36개 디스크 IO 횟수. 최소 26회 디스크 IO 횟수.
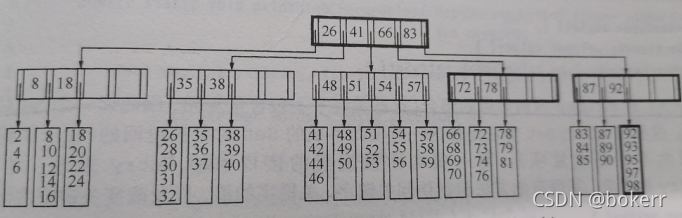
그림은 5차 일반 B+ 트리(M = 5)를 보여줍니다. 여기서 각 노드는 최대 5개의 값을 갖습니다(L = 5). 위에 표시된 것처럼 M과 L이 반드시 동일하지는 않습니다. 분석: M과 L은 실제 조건에 따릅니다.
하하하, 그림 그리는 게 너무 귀찮네요. 이 책에 있는 사진을 자료구조와 알고리즘으로 분석했는데, 저만큼 똑똑하네요.
여기에서는 B+ 트리 정의 및 매개변수 선택 세부 사항에 대해서만 설명합니다. B+ 트리 삽입 및 B+ 트리 삭제에 대해서는 자세히 설명하지 않습니다.
일반적으로 B+ 트리 높이는 2~4레벨입니다. 즉, 행 레코드를 검색할 때 행 레코드가 있는 페이지를 찾는 데 보통 2~4번의 디스크 IO 시간이 걸립니다. 위치하고 있습니다. 클러스터형 인덱스든 비클러스터형 인덱스든 내부는 균형이 잘 잡혀 있고, 인덱스 데이터는 리프 노드에 저장된다. 차이점은 클러스터형 인덱스의 리프 노드에는 전체 행 레코드 데이터가 저장된다는 점이다.
클러스터형 인덱스의 리프 노드는 전체 데이터 행을 저장하며, 각 테이블은 하나의 클러스터형 인덱스만 가질 수 있습니다.
보조 인덱스의 리프 노드에는 키 값과 북마크가 저장되어 Innodb 스토리지 엔진에 인덱스에서 해당 행 레코드의 전체 데이터를 찾을 위치를 알려줍니다. <이 북마크는 테이블의 기본 키인 클러스터형 인덱스의 키워드라고 볼 수 있습니다>
각 테이블은 여러 개의 보조 인덱스를 가질 수 있습니다
보조 인덱스의 한 가지 단점은 완전한 행 데이터를 다음을 통해 얻어야 한다는 것입니다. 보조 인덱스에 저장된 북마크가 발견된 경우에도 개별 클러스터형 인덱스를 사용할 수 있습니다.
카디널리티에 대한 논의는 비클러스터형 인덱스를 기반으로 하며 각 비클러스터형 인덱스는 카디널리티 값을 갖습니다.
쿼리 조건의 모든 열을 색인화할 필요는 없습니다. 예를 들어 성별, 연령, 주제와 같이 값 범위가 작고 분포가 밀집된 사전은 색인화할 필요가 없습니다.
카디널리티는 인덱스의 고유 레코드 수에 대한 추정치를 나타냅니다. 일반적으로: 카디널리티/테이블의 레코드 행 수는 가능한 한 1에 가까워야 합니다. 매우 작은 경우 인덱스를 사용해야 하는지 여부를 고려해야 합니다. 제거됨. (클러스터형 인덱스에서는 이 값이 1에 가까워야 하며 토론값이 없습니다.)
MySQL에서는 각 스토리지 엔진이 B+ 트리 인덱스를 다르게 구현하므로 카디널리티 통계는 스토리지 엔진 계층에서 구현됩니다.
테이블의 데이터 양이 매우 많을 경우 Cardinality에 대한 통계를 수행하는 데 시간이 많이 걸립니다. 일반적으로 샘플링 방법을 사용하여 통계를 수행합니다.
카디널리티의 존재는 인덱스에 어떤 의미가 있는지 분석하는 데 도움이 될 수 있습니다.
[이 섹션에서 설명하는 인덱스는 대부분 보조 인덱스를 의미하며 클러스터형 인덱스에 대한 쿼리를 일반적으로 전체 테이블 스캔이라고 합니다. 】
결합 인덱스는 테이블의 여러 열에 구축된 인덱스이기도 하며 단일 인덱스와 유일한 차이점은 여러 열을 갖는다는 것입니다.
create table t ( a int, b int, primary key (a), key idx_ab (a, b) )engine=innodb;
위 표에서 공동 기본 키 idx_ab를 설정하고 그 저장 구조는 다음과 같습니다.
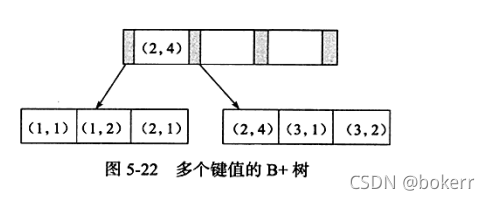
如上图所述,键值有序,需要注意的是,如下SQL可以使用该索引:
select * from t where a = ? and b = ? select * from t where a = ?
如下sql 不能使用该索引;查看示例图中联合索引叶子节点存放的数据我们可以发现:两个叶子节点上,关于字段b的存放显然不是有序的。
select * from t where b = ?
联合索引本身还有一个好处,辅助索引本身已经对第二个键值进行了排序,如下语句可以避免多一次的排序。
select b from t where a = ? order by b desc
辅助索引中已经对 b 列进行了排序,所以此时使用辅助索引更高效。
Innodb 支持覆盖索引(covering index,或称为索引覆盖),即从辅助索引中就可以得到结果,而不需要查询聚集索引中的记录。由于辅助索引不包含完整的行记录,从而比聚集索引小很多,可以极大地减少IO操作。
再形如:select count(*) from table name where b <= ? and b >= ? 的sql,如果有满足条件的辅助索引,它会优先使用辅助索引因为辅助索引体积远远小于聚集索引。
某些情况下,通过EXPLAIN指令会发现一些SQL,并没有选择使用满足条件的辅助索引去查数据,而是直接选择了全表扫描(聚集索引),这种情况一般发生于 范围查找、join链接操作等情况下。
当发生此类查找时,一般是查找一个较大范围内的数据,当范围较大时同样意味着大量的数据需要再进行一次书签访问去获取完整数据,已知顺序读取速度大于离散读取速度,所以此时不会使用辅助索引,而是直接查聚集索引(整表扫描)。一般情况下,当访问数据超过表中数据总数的20%时,索引覆盖不再适用,而需要进行全表扫描。)
create table t ( a int, b int, primary key (a,b), key idx_a (a) )engine=innodb;
如上定义表,a和b两列构成联合索引,列a上有独立的辅助索引,对于语句:
select * from t where a >= 3 and a<= 1000000;
按理说,该语句是可以选择使用辅助索引 idx_a 进行查找的,但是通过执行 explain 发现该语句发生了全表扫描(聚集索引),而不是使用辅助索引: idx_a。
索引提示指MySQL支持在SQL中显式的告诉优化器使用哪个索引。
当优化器选择索引错误,可以手动指定索引。[极小概率事件]
当索引太多时,优化器选择索引的操作时间开销大,此时可以手动指定索引。
使用索引提示的前提是我们自己要对sql的执行非常了解,非常明确该操作能带来更好的效率。
MySQL5.6版本开始支持Multi-Range Read (MRR) 优化,它的目的是减少磁盘的离散读,将离散的访问优化为相对有序的访问,它使用于 range ref eq_ref 类型的查询。
1).MRR优化有如下好处:
它使得数据访问变得较为顺序,当根据辅助索引查询时,会将查询结果按照主键排序后,再去聚集索引进行书签查询。
减少缓冲池中页被替换的次数;
批量处理对键值的查询操作;
2).对于 JOIN 和 范围查询,Innodb 中MRR的工作方式为:
将通过辅助索引查询到的数据放到一个缓存中,此时这些数据是按照辅助索引键值排序的;
将缓存中的数据按照主键顺序排序;
根据主键顺序访问实际数据文件;
想象一下,在缓冲池不够大的情况下进行大范围数据查询,会导致数据页频繁被从LRU列表中移除。如果被查询的辅助索引不是按主键排序的,可能会多次发生如下的情况:一个页在同一次查询中被剔出LRU列表后又再次被加载出来。
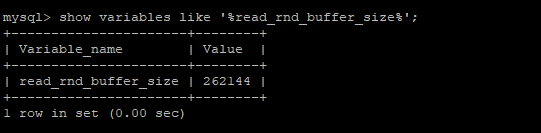
配置项:read_rnd_buffer_size 用来配置上述描述的键值缓冲区大小,默认为256K;当发生溢出时,执行器只对已经缓存的数据进行排序。
3).对于范围查询:MMR还支持对键值的拆分,将范围查询拆分为键值对进行批量的数据查询.
create table t ( a integer, b integer, primary key (a), key idx_ab (a, b) )engine=innodb;
select * from t where a = 50 and b>= 100 and b<= 20000
由于存在辅助索引 idx_ab,上述sql语句的条件可以拆分为键值对集合:{( 50 , 100 ),( 50 , 101 ),......,( 50 , 20000 )},这样就将范围查询优化为对键值对的查询;否则会进行范围查询,将 b ∈ {100,20000} 的所有数据都取出。
Multi-Range Read 是否启用,由如下参数中的,mrr 和 mrr_cost_based 标记进行控制,mrr标记是 MRR优化的开关。若前者设置为on,后者设置为off表示当满足条件时总是使用MRR优化;若前者设置为 on,后者也设置 on 表示通过 cost base 方式判断是否需要 MRR优化。

ICP 최적화는 MySQL 5.6부터 지원됩니다. 이는 인덱스 기반 쿼리를 위한 최적화 방법입니다: range, ref, eq_ref, ref_or_null 유형. 최적화.
ICP가 비활성화되면 스토리지 엔진 계층은 인덱스를 탐색하여 전체 행 레코드를 찾은 다음 이를 데이터베이스 계층(서버 계층)으로 반환한 다음 이러한 데이터 행에 대한 where 조건을 필터링합니다.
ICP가 활성화되면 where 조건이 인덱스를 사용할 수 있는 경우 MySQL은 필터링 작업의 이 부분을 스토리지 엔진 계층에 넣습니다. 스토리지 엔진은 인덱스를 통해 필터링하고 만족하는 전체 데이터 행을 꺼냅니다. where 조건을 반환합니다. ICP를 사용하면 스토리지 엔진 계층이 행 레코드에 액세스하는 빈도를 줄이는 동시에 데이터베이스 계층(서버 계층)이 스토리지 엔진에 액세스해야 하는 횟수를 줄일 수 있습니다.
[이 필터를 사용하기 위한 전제 조건: 필터 조건이 인덱스가 포괄할 수 있는 범위 내에 있어야 함]
인덱스 조건 푸시다운은 다음과 같이 작동합니다.
1) ICP를 사용하지 않는 경우
(1) 스토리지 엔진이 다음 행을 읽을 때 보조 인덱스의 리프 노드에서 해당 행 레코드를 읽은 다음 레코드의 북마크에 있는 기본 키 참조를 사용하여 전체 행 레코드를 쿼리하고 반환합니다. 데이터베이스 계층(서버 계층)으로 이동합니다.
(2) 데이터베이스 계층은 전체 행 레코드에 대해 where 조건 필터링을 수행합니다. 행 데이터가 where 조건을 충족하면 사용되며 그렇지 않으면 폐기됩니다.
(3) 조건을 충족하는 모든 데이터를 읽을 때까지 1단계를 수행합니다.
2) ICP 사용 시 인덱스 스캔을 수행하는 방법
(1) 스토리지 엔진은 인덱스에서 데이터를 하나씩 읽습니다...
(2) 스토리지 엔진이 인덱스에서 데이터를 읽을 때, 인덱스 키 where 조건을 사용하여 필터링합니다. 행 레코드가 조건을 충족하지 않으면 스토리지 엔진은 다음 데이터 조각을 처리합니다(이전 단계로 돌아갑니다). 쿼리 조건이 충족되는 경우에만 클러스터형 인덱스에서 전체 데이터를 읽습니다.
(3) 마지막으로 스토리지 엔진 계층은 쿼리 조건을 충족하는 모든 완전한 행 레코드를 데이터베이스 계층에 반환합니다.
(4) 데이터베이스 계층을 계속 사용하는 경우 인덱스에 포함되지 않는 쿼리 조건 이후는 필터링됩니다.
위 내용은 Mysql Innodb 스토리지 엔진의 인덱스 및 알고리즘 분석 예시의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



