
 기술 주변기기
일체 포함
Alibaba Cloud의 새로운 대형 모델이 출시되었습니다! AI 아티팩트 'Tongyi Listening' 공개 베타 출시: 긴 동영상을 1초 안에 요약할 수 있고 자동으로 메모하고 자막을 뒤집을 수도 있음 |
기술 주변기기
일체 포함
Alibaba Cloud의 새로운 대형 모델이 출시되었습니다! AI 아티팩트 'Tongyi Listening' 공개 베타 출시: 긴 동영상을 1초 안에 요약할 수 있고 자동으로 메모하고 자막을 뒤집을 수도 있음 |
Alibaba Cloud의 새로운 대형 모델이 출시되었습니다! AI 아티팩트 'Tongyi Listening' 공개 베타 출시: 긴 동영상을 1초 안에 요약할 수 있고 자동으로 메모하고 자막을 뒤집을 수도 있음 |

대형 모델 기능에 액세스할 수 있는 그룹 모임을 위한 또 다른 실용적인 도구가 이제 무료 공개 베타로 공개됩니다!
그 뒤에 있는 큰 모델은 Alibaba의 Tongyi Qianwen입니다. 그룹회의 마법의 도구라고 불리는 이유 -
보세요, 스테이션 B에서 학생들에게 큰 모형 논문을 집중적으로 읽도록 지도하고 있는 Li Mu 선생님입니다.
안타깝게도 이 순간 사장님께서 벽돌을 빨리 옮기라고 재촉하셨습니다. 나는 조용히 헤드폰을 벗고 "Tongyi Listening"이라는 플러그인을 클릭한 다음 페이지를 전환할 수밖에 없었습니다.
무엇을 추측할까요? 나는 "그룹 회의"에 참석하지 않았지만 Tingwu는 그룹 회의 내용을 완벽하게 녹음하도록 도와주었습니다.
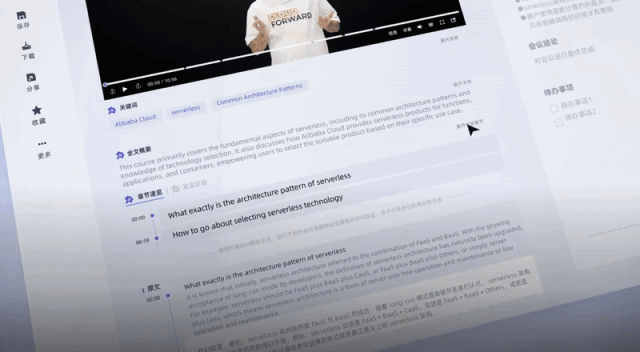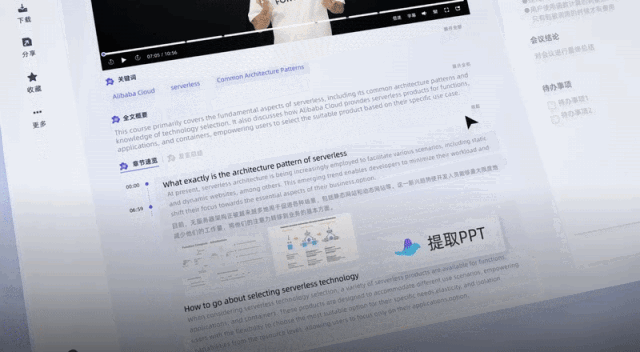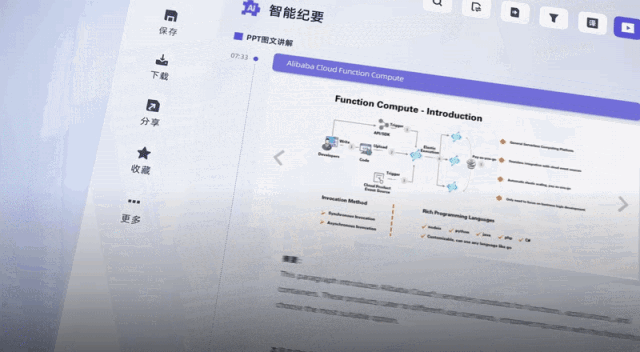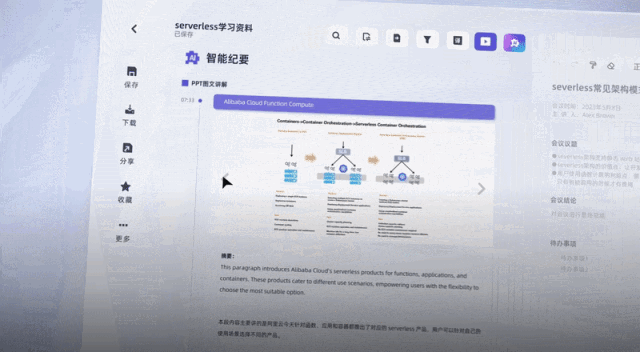
한 번의 클릭으로 핵심 단어, 전체 텍스트 요약 및 학습 포인트를 요약하는 데 도움이 되었습니다.

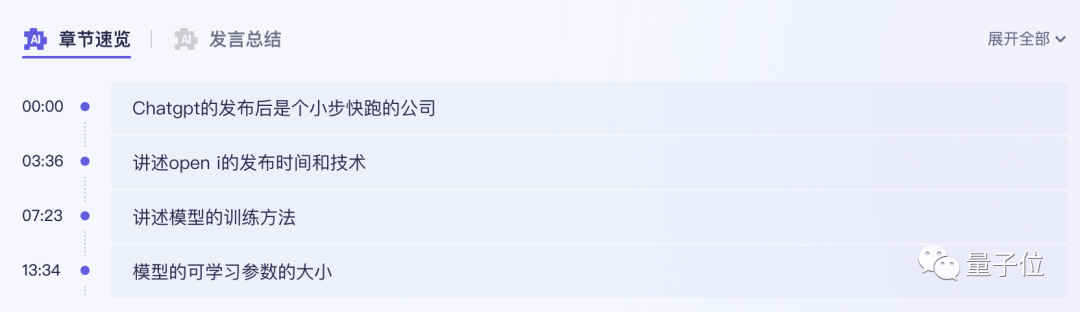
대형 모델 기능에 방금 연결한 이 "일반 의미 듣기"는 간단히 말하면 오디오 및 비디오 콘텐츠에 중점을 둔 업무 학습 AI 도우미의 대형 모델 버전입니다.
이전 녹음 전사 도구와 달리 녹음 및 비디오를 텍스트로 변환할 수 있을 뿐만 아니라 한 번의 클릭으로 전체 텍스트를 요약할 수 있으며, 다양한 화자의 의견도 요약할 수 있습니다:
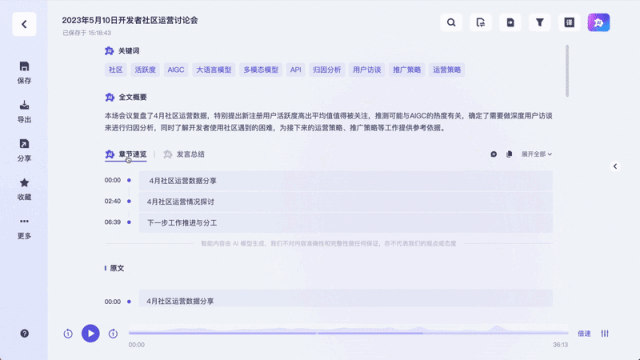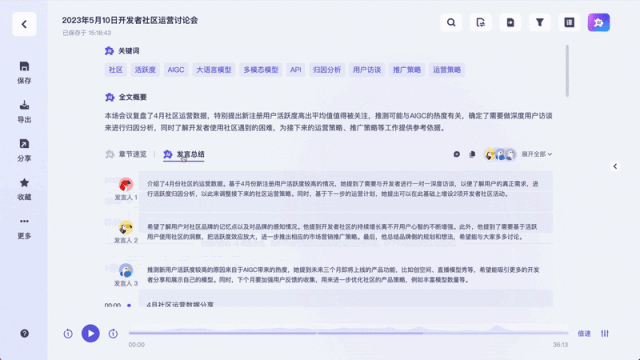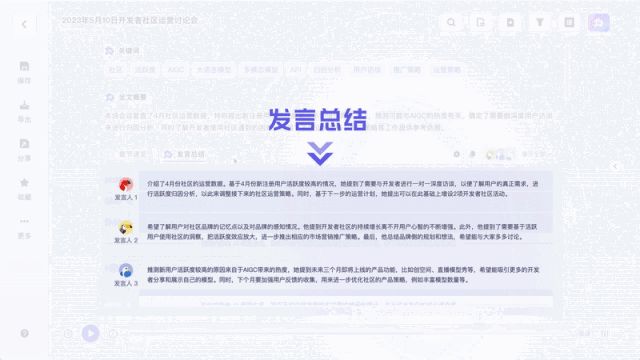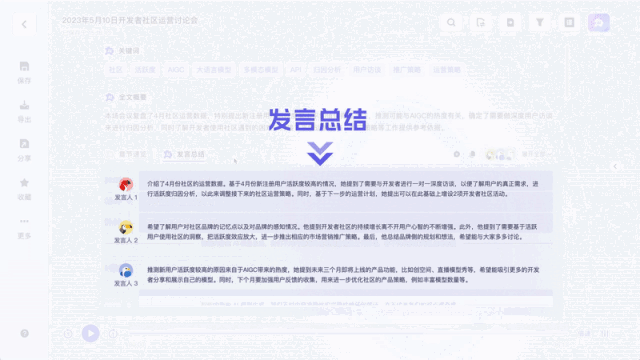
실시간 자막 번역으로도 사용할 수 있습니다:

뿐만 아니라 그룹 회의를 개최하는 데 유용할 뿐만 아니라 정기적인 회의에도 유용합니다. 많은 녹음, 밤샘, 다양한 해외 회의를 처리해야 하는 큐비트의 경우 일상 업무를 위한 정말 새로운 유물입니다.
신속하게 심층 테스트를 진행했습니다.
통이 듣기 실기 테스트
오디오 내용을 정리하고 분석하는데 있어서 가장 기본적이고 중요한 것은 표기의 정확성입니다.
1라운드에서는 먼저 약 10분 분량의 중국어 동영상을 업로드하여 유사한 도구와 비교하여 Tingwu가 정확도 측면에서 어떻게 수행되는지 확인합니다.
기본적으로 AI는 이런 중간 길이의 오디오와 비디오를 매우 빠르게 처리하며, 2분 이내에 전사가 가능합니다.

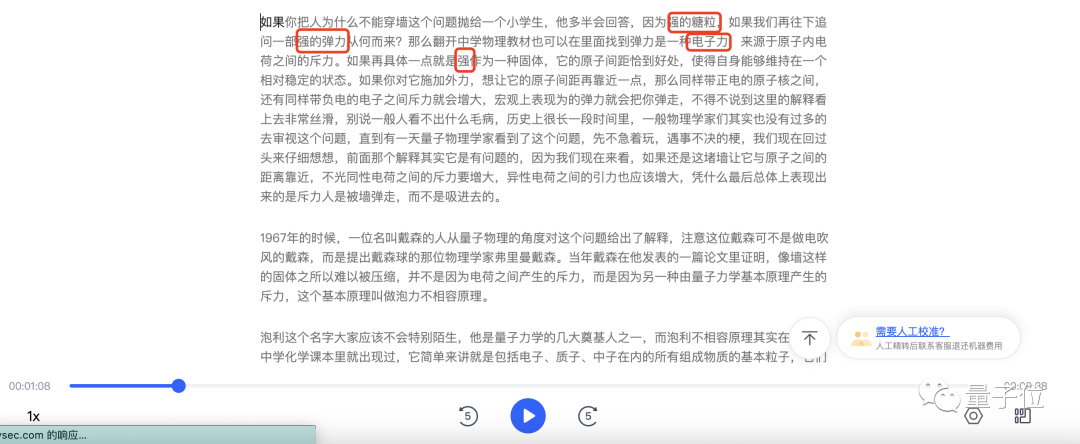
먼저 Tingwu의 퍼포먼스를 살펴보겠습니다:

약 200 단어로 구성된 이 단락에서 Tingwu는 두 가지 실수만 했습니다: 강함 → 벽, 둘 다 좋음 → 딱 맞습니다. 원자핵, 전하, 반발력과 같은 물리적 용어는 들으면 이해할 수 있습니다.
동일한 영상을 이용해 Feishu Miaoji에서도 테스트해봤습니다. 기본적인 문제는 크지 않지만 듣기에 비해 페이슈는 두 가지 실수를 더 했다. '원자' 중 하나를 '정원'으로 썼고, '반발'을 '힘'으로 읽었다.

흥미로운 점은 Feishu도 Hengwu가 저지른 실수를 하나씩 재현했다는 것입니다. 이 냄비는 큐빗(수동 개 머리)으로 말을 삼키고 말하는 어떤 업 마스터가 짊어져야 할 것 같습니다.
iFlytek은 이 말을 듣고 처음 두 참가자가 인식하지 못한 "딱 맞는" 것을 구별할 수 있었습니다. 그러나 iFlytek은 기본적으로 모든 "벽"을 "강함"으로 번역했고 "강한 설탕 알갱이"의 마법 같은 조합이 나타났습니다. 또한, 참가자 3명 중 아이플라이텍만이 '전자기력'을 '전자력'으로 오해한 것으로 나타났다.
일반적으로 이러한 AI 도구에 대한 중국어 인식은 어렵지 않습니다. 그렇다면 그들은 영어 자료 앞에서 어떻게 행동할 것인가?
Musk의 과거 OpenAI와의 분쟁에 대한 최신 인터뷰를 업로드했습니다.
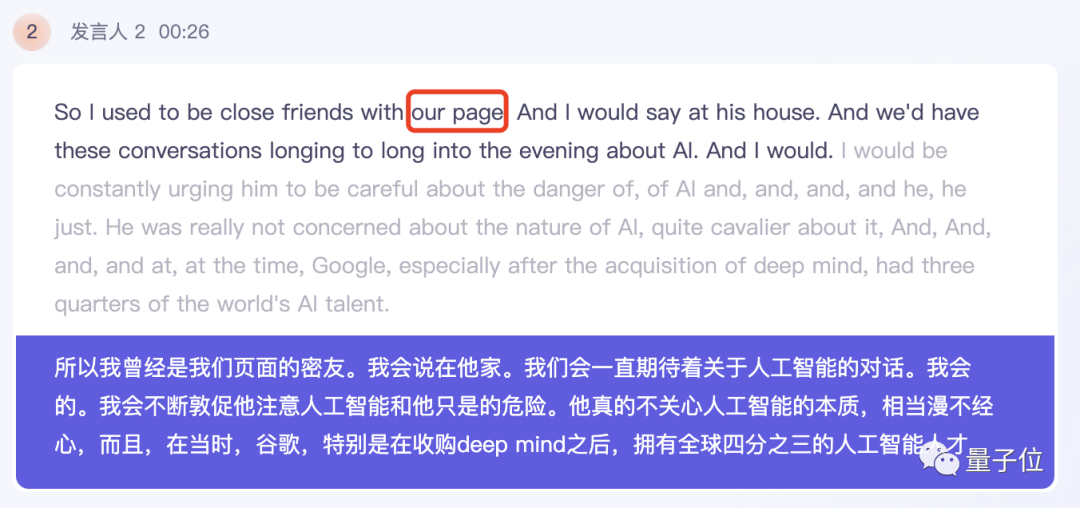
먼저 Tingwu가 제공한 결과를 살펴보겠습니다. 머스크의 답변 중 Huar는 기본적으로 Larry Page의 이름을 제외한 모든 사람을 정확하게 식별했습니다.
Tingwu는 영어 음역 결과를 중국어로 직접 번역하고 이중 언어 비교도 표시할 수 있다는 점을 언급할 가치가 있습니다.
Feishu Miaoji는 성공적으로 Larry Page의 이름을 인식했습니다. 그러나 Listening과 마찬가지로 Musk의 전반적인 말하기 속도와 "stay at his house" 대신 "say this house"와 같은 일부 구어체 표현으로 인해 약간의 오류가 있었습니다. ".

아이플라이텍은 이를 듣고 이름과 발음 세부사항을 잘 처리했습니다. 그러나 "long into the evening"을 "longing to the evening"으로 착각하는 등 머스크의 구어체 표현에 오해를 받는 경우도 있습니다.

기본적인 음성 인식 능력 측면에서 AI 도구는 극도로 높은 효율성에도 불구하고 이미 매우 높은 정확도에 도달한 것 같습니다.
그다음에는 난이도를 2라운드로 올려서 1시간 정도 분량의 영상을 요약하는 능력을 테스트하겠습니다.
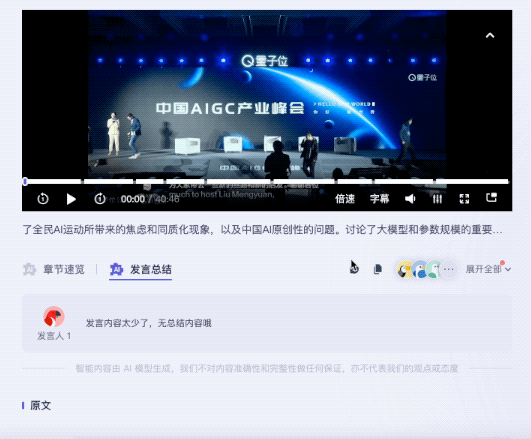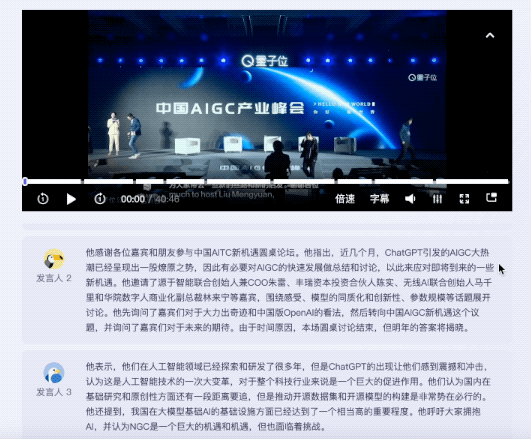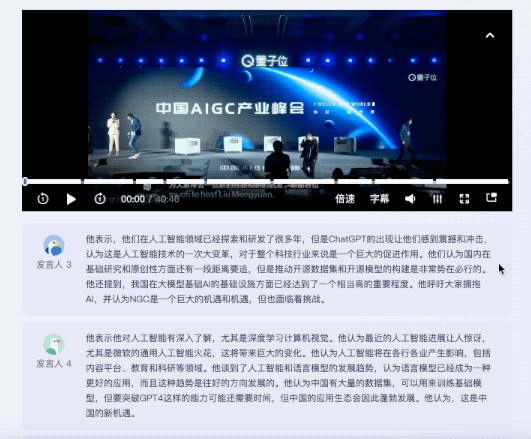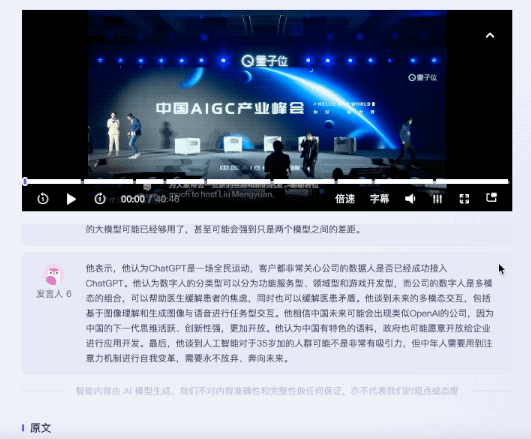
테스트 영상은 중국 AIGC의 새로운 기회를 주제로 한 40분간의 원탁 토론입니다. 원탁토론에는 총 5명이 참여했다.
듣는 측면에서는 전사 완료부터 AI까지 키워드 추출과 전문 요약 제공까지 총 5분도 채 걸리지 않았습니다.
결과는 장아줌마님:


키워드가 주어졌을 뿐만 아니라 원탁 토론의 내용도 잘 요약되었고, 영상의 핵심 포인트도 잘 나누어졌습니다.
인간 편집자들이 발췌한 주제 포인트를 비교해보면 위기의 기운이 느껴지네요...

여러 게스트의 연설에 대해 Listening에서는 해당 연설의 요약을 제공할 수 있다는 점을 언급할 가치가 있습니다.
페이슈 먀오지에게도 같은 질문이 던져졌습니다. 현재 콘텐츠 요약 측면에서 Feishu Miaoji는 키워드만 제공할 수 있습니다.

회의 시간은 기록된 텍스트에 수동으로 표시해야 합니다.

iFlytek은 파일 내용을 분석할 수 있지만 신청서를 작성하고 줄을 서서 기다려야 하는 Spark 인지 대형 모델을 기반으로 한 제품을 내부적으로 테스트하고 있다고 들었습니다. (내부 테스트 자격을 갖춘 친구들의 경험 공유를 환영합니다~)
기본 iFlytek에는 현재 유사한 요약 기능이 없습니다.

이번 테스트는 다음과 같습니다.
그러나 이번 실제 테스트에서 Tongyi Tingwu의 가장 놀라운 점은 실제로 "작은" 디자인입니다:
Chrome 플러그인 기능.
영어 비디오를 시청하든, 라이브 방송을 시청하든, 수업 중 회의에 참석하든, 듣기 플러그인을 클릭하면 오디오 및 비디오의 실시간 전사 및 번역이 가능합니다.
처음에 표시된 것처럼 짧은 대기 시간, 빠른 번역 및 이중 언어 비교 기능을 통해 실시간 자막으로 사용할 수 있으며 동시에 한 번의 클릭으로 녹음 및 복사된 텍스트를 저장하여 나중에 사용할 수 있습니다.
엄마는 더 이상 내가 영어 영상 자료를 읽지 못할까 봐 걱정하지 않아도 됩니다.
게다가 과감한 아이디어가 있는데...
그룹 회의를 할 때 듣기를 켜두시면 더 이상 갑자기 강사에게 확인을 받을 걱정이 없습니다.
현재 Tingwu는 Alibaba Cloud Disk와 연결되어 있습니다. 클라우드 디스크에 저장된 오디오 및 비디오 콘텐츠를 한 번의 클릭으로 전사할 수 있으며, 온라인에서 클라우드 디스크 비디오를 재생할 때 자막이 자동으로 표시될 수 있습니다. AI 처리된 오디오, 비디오 파일은 향후 기업용 버전에서 내부적으로 빠르게 공유될 수 있다.

또한 헝우 관계자는 앞으로도 영상에서 PPT 스크린샷을 직접 추출하고, 오디오 및 영상 콘텐츠에 대해 AI에게 직접 질문하는 등 새로운 대형 모델 기능을 계속해서 추가할 예정이라고 밝혔습니다...

이제 공개 베타 혜택을 누구나 이용할 수 있다는 것이 핵심입니다. 매일 로그인하면 자동으로 2시간의 녹취 시간을 얻을 수 있습니다. 주요 플랫폼 커뮤니티에서도 대량의 20시간 분량의 암호 코드 복사가 제공되며, 기간은 누적될 수 있으며 유효 기간은 1년입니다.
부지런한 양모 장인으로서 100시간 이상의 자유시간(수동 개머리)을 절약하는 것은 꿈이 아닙니다.

뒤에 있는 기술: 대형 언어 모델 + 음성 SOTA
사실 공개 베타 이전에 Tongyi Listening은 Alibaba 내에서 세심하게 다듬어졌습니다.
지난해 말 일부 Qubit 독자들은 Listening Internal 베타 체험 카드를 획득했습니다. 당시 버전에는 이미 오프라인 음성/영상 전사 및 실시간 전사 기능이 포함되어 있었습니다.
이 오픈 베타에서 Tingwu는 주로 Tongyi Qianwen 대형 모델의 요약 및 대화 기능에 액세스합니다. 보다 구체적으로, 이 작업은 Tongyi Qianwen 대규모 모델을 기반으로 하며 추론, 조정 및 대화형 질문 답변에 연구팀의 연구 결과를 통합합니다.
이러한 아티팩트를 통해 우선 핵심 정보를 어떻게 정확하게 추출하느냐가 업무 효율성을 높이는 열쇠입니다. 이를 위해서는 대형 모델의 추론 능력이 필요합니다.
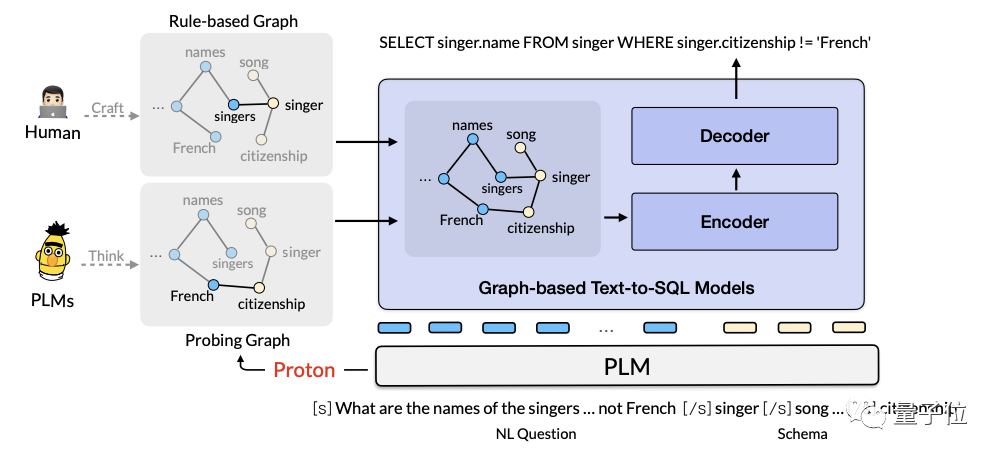
알리바바 AI 팀은 2022년에 대규모 언어 모델을 기반으로 한 지식 탐지 및 추론 활용 프레임워크인 Proton(Probing Turning from Large Language Models)을 제안했습니다. 관련 논문은 KDD2022, SIGIR2023 등 주요 국제 학회에 게재될 예정입니다.

이 프레임워크의 핵심 아이디어는 대형 모델의 내부 지식을 감지하고 사고 체인을 지식 흐름 및 활용을 위한 전달자로 사용하는 것입니다.
Proton은 Commonsense QA2.0, Physical Commonsense Reasoning PIQA 및 Numerical Commonsense Reasoning Numbersense의 세 가지 주요 목록에서 1위를 차지했습니다.
TabFact(사실 검증) 목록에서 Proton은 지식 분해와 신뢰할 수 있는 사고 체인 기술로 최초로 초인적인 결과를 달성했습니다.
둘째, 요약 내용과 형식이 사용자의 기대에 부응하도록 하기 위해 Listening에서는 정렬 측면에서도 인간의 피드백을 기반으로 한 효율적인 정렬 방법인 ELHF를 사용합니다.
이 방법은 정렬을 달성하기 위해 소수의 고품질 수동 피드백 샘플만 필요합니다. 모델 효과의 주관적 평가에서 ELHF는 모델의 승률을 20% 높일 수 있습니다.
또한 Wu의 R&D 팀은 대규모 중국어 문서 대화 데이터 세트인 Doc2Bot도 출시했습니다. 모델의 질문 답변 기능을 향상시키기 위한 팀의 Re3G 방법이 ICASSP 2023에서 선택되었습니다. 이 방법은 Retrieve(검색), Rerank(재순위), Refine(미세 조정) 및 생성의 4단계를 통해 사용자 질문에 대한 모델의 응답을 향상시킬 수 있습니다. (세대) Doc2Dial 및 Multi Doc2Dial의 두 가지 주요 문서 대화 목록에서 이해, 지식 검색 및 응답 생성 기능이 1위를 차지했습니다.
Tingwu는 대형 모델 역량 외에도 Alibaba 음성 기술의 대가이기도 합니다.
Alibaba Damo Academy의 음성 인식 모델인 Paraformer는 산업 응용 수준에서 처음으로 종단 간 인식 효과와 효율성의 균형 문제를 해결합니다.
추론 효율성을 10배 향상시킬 뿐만 아니라 기존 모델과 비교하여 처음 출시되었을 때 많은 권위 있는 데이터 세트의 기록을 깨고 음성 인식 SOTA의 정확성을 새롭게 했습니다. 전문적인 제3자 전체 네트워크 공용 클라우드 중국어 음성 인식 평가 SpeechIO TIOBE 화이트 박스 테스트에서 Paraformer-large는 여전히 가장 높은 정확도를 지닌 중국 음성 인식 모델입니다.
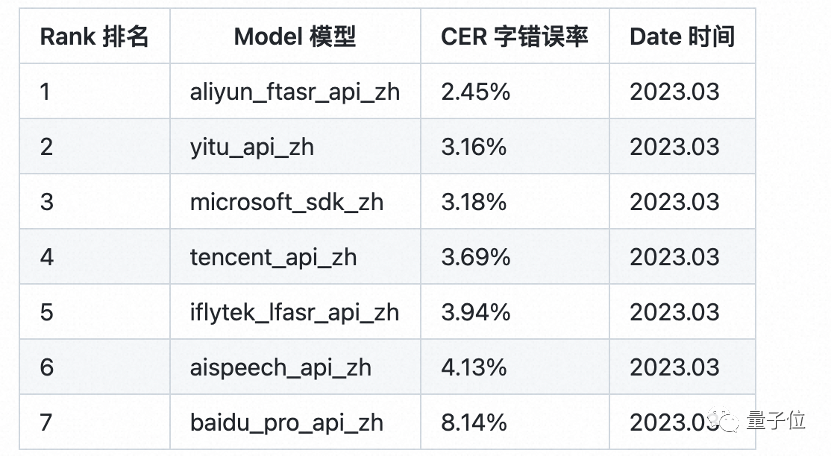
Paraformer는 인코더, 예측기, 샘플러, 디코더 및 손실 함수의 5개 부분으로 구성된 단일 라운드 비자기회귀 모델입니다.
Paraformer는 혁신적인 예측기 설계를 통해 대상 단어 수와 해당 음향 잠재 변수를 정확하게 예측합니다.
또한 연구원들은 기계 번역 분야에서 브라우징 언어 모델(GLM)이라는 아이디어를 도입하고, GLM을 기반으로 한 샘플러를 설계했으며, 모델의 상황별 의미론 모델링을 강화했습니다.
동시에 Paraformer는 풍부한 시나리오를 다루는 초대형 산업 데이터 세트에 대해 수만 시간의 교육을 사용하여 인식 정확도를 더욱 향상시켰습니다.
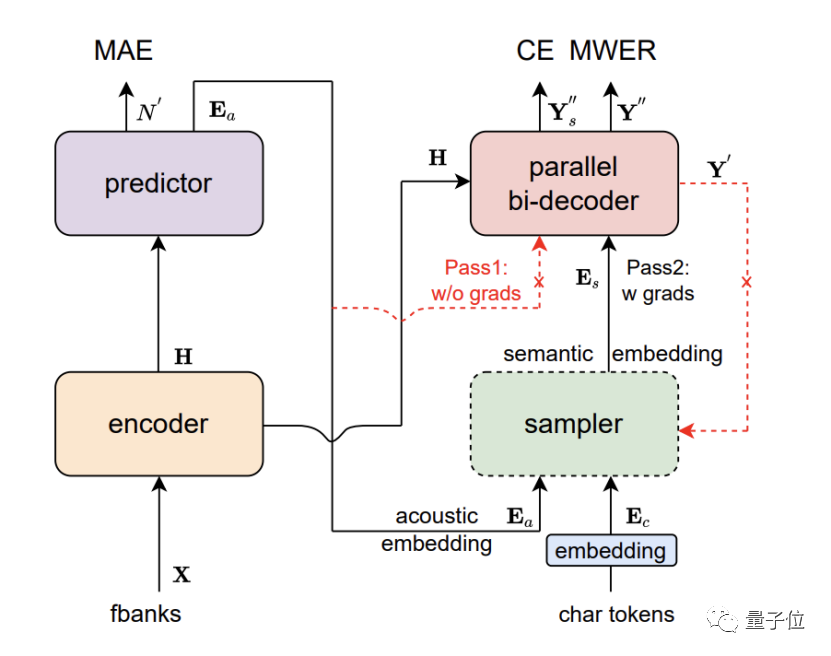
DAMO Academy의 CAM++ 화자 인식 기본 모델을 사용하면 다인 토론에서 화자를 정확하게 식별할 수 있습니다. 이 모델은 조밀한 연결을 기반으로 하는 지연 네트워크 D-TDNN을 사용합니다. 각 계층의 입력은 모든 이전 계층의 출력에서 연결됩니다. 지연 네트워크의 이러한 계층적 기능 다중화 및 1차원 컨볼루션은 계산 효율성을 크게 향상시킬 수 있습니다. 네트워크.
업계의 주류 중국어 및 영어 테스트 세트인 VoxCeleb과 CN-Celeb에서 CAM++가 최고의 정확도를 갱신했습니다.
대형 모델 공개로 사용자 혜택
중국 과학 기술 정보 연구소의 보고에 따르면 불완전한 통계에 따르면 중국에서 79개의 대형 모델이 출시되었습니다.
이러한 대규모 모델 개발 추세 속에서 AI 애플리케이션 진화 속도는 다시 한번 질주 단계에 돌입했습니다.
사용자의 관점에서 볼 때 환영받는 상황이 점차 형성되고 있습니다.
대형 모델의 "조정" 아래 다양한 AI 기술이 애플리케이션 측면에서 번성하기 시작하여 도구가 점점 더 효율적이고 스마트해집니다.
슬래시를 사용하여 작업 계획을 자동으로 작성할 수 있는 스마트 문서부터 요소를 빠르게 요약하는 데 도움이 되는 오디오 및 비디오 녹화 및 분석 도구, 생성적 대형 모델, AGI의 불꽃이 점점 더 많은 사람들을 매료시키고 있습니다. AI의 마법.
동시에 기술 기업에게는 의심의 여지 없이 새로운 도전과 기회가 나타났습니다.
모든 제품이 대형 모델의 폭풍에 휩싸이게 되고 기술 혁신이 피할 수 없는 핵심 이슈가 된 것이 과제입니다.
기존 시장 구조는 새로운 킬러 애플리케이션을 위해 다시 작성할 수 있는 기회의 순간에 도달했습니다. 누가 주도권을 잡을 수 있는지는 누가 기술적으로 더 준비되어 있고 누구의 기술이 더 빠르게 발전하는지에 달려 있습니다.
무슨 일이 있어도 기술 개발은 궁극적으로 사용자에게 이익이 됩니다.
위 내용은 Alibaba Cloud의 새로운 대형 모델이 출시되었습니다! AI 아티팩트 'Tongyi Listening' 공개 베타 출시: 긴 동영상을 1초 안에 요약할 수 있고 자동으로 메모하고 자막을 뒤집을 수도 있음 |의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7552
7552
 15
1382
52
83
11
58
19
22
95
15
1382
52
83
11
58
19
22
95

 Alibaba Cloud는 2024 Yunqi 컨퍼런스가 9월 19일부터 21일까지 항저우에서 개최된다고 발표했습니다.
Aug 07, 2024 pm 07:12 PM
Alibaba Cloud는 2024 Yunqi 컨퍼런스가 9월 19일부터 21일까지 항저우에서 개최된다고 발표했습니다.
Aug 07, 2024 pm 07:12 PM
8월 5일 이 웹사이트의 소식에 따르면 Alibaba Cloud는 2024년 Yunqi 컨퍼런스가 9월 19일부터 21일까지 항저우 Yunqi 타운에서 개최될 것이라고 발표했습니다. 3일간의 메인 포럼, 400개의 하위 포럼 및 병행 주제가 있을 예정입니다. 약 4만 평방미터의 전시 면적도 있습니다. Yunqi Conference는 무료이며 대중에게 공개됩니다. 이제부터 일반인은 Yunqi Conference 공식 웹사이트를 통해 5,000위안의 전체 티켓을 구매할 수 있습니다. 티켓 웹사이트는 다음 웹사이트에 첨부되어 있습니다. https://yunqi.aliyun.com/2024 /ticket-list 보고서에 따르면 Yunqi 컨퍼런스는 2009년에 시작되었으며 원래 2011년에 첫 번째 중국 웹사이트 개발 포럼으로 명명되었으며 2015년에 Alibaba Cloud 개발자 컨퍼런스로 발전했습니다. , 공식적으로 "Yunqi 회의"로 이름이 변경되었으며 계속해서 성공적인 움직임을 이어왔습니다.
 대형 모델 앱 Tencent Yuanbao가 온라인에 출시되었습니다! Hunyuan은 어디서나 휴대할 수 있는 만능 AI 비서로 업그레이드되었습니다.
Jun 09, 2024 pm 10:38 PM
대형 모델 앱 Tencent Yuanbao가 온라인에 출시되었습니다! Hunyuan은 어디서나 휴대할 수 있는 만능 AI 비서로 업그레이드되었습니다.
Jun 09, 2024 pm 10:38 PM
5월 30일, Tencent는 Hunyuan 모델의 포괄적인 업그레이드를 발표했습니다. Hunyuan 모델을 기반으로 하는 앱 "Tencent Yuanbao"가 공식 출시되었으며 Apple 및 Android 앱 스토어에서 다운로드할 수 있습니다. 이전 테스트 단계의 Hunyuan 애플릿 버전과 비교하여 Tencent Yuanbao는 일상 생활 시나리오를 위한 작업 효율성 시나리오를 위한 AI 검색, AI 요약 및 AI 작성과 같은 핵심 기능을 제공하며 Yuanbao의 게임 플레이도 더욱 풍부해지고 다양한 기능을 제공합니다. , 개인 에이전트 생성과 같은 새로운 게임 플레이 방법이 추가됩니다. Tencent Cloud 부사장이자 Tencent Hunyuan 대형 모델 책임자인 Liu Yuhong은 "Tencent는 먼저 대형 모델을 만들기 위해 노력하지 않을 것입니다."라고 말했습니다. Tencent Hunyuan 대형 모델 비즈니스 시나리오에서 풍부하고 방대한 폴란드 기술을 활용하면서 사용자의 실제 요구 사항에 대한 통찰력을 얻습니다.
 Bytedance Beanbao 대형 모델 출시, Volcano Engine 풀스택 AI 서비스로 기업의 지능적 혁신 지원
Jun 05, 2024 pm 07:59 PM
Bytedance Beanbao 대형 모델 출시, Volcano Engine 풀스택 AI 서비스로 기업의 지능적 혁신 지원
Jun 05, 2024 pm 07:59 PM
Volcano Engine의 Tan Dai 사장은 대형 모델을 구현하려는 기업은 모델 효율성, 추론 비용, 구현 어려움이라는 세 가지 주요 과제에 직면하게 된다고 말했습니다. 복잡한 문제를 해결하기 위한 지원으로 좋은 기본 대형 모델이 있어야 하며, 서비스를 통해 대규모 모델을 널리 사용할 수 있으며 기업이 시나리오를 구현하는 데 더 많은 도구, 플랫폼 및 애플리케이션이 필요합니다. ——Tan Dai, Huoshan Engine 01 사장. 대형 빈백 모델이 출시되어 많이 사용되고 있습니다. 모델 효과를 연마하는 것은 AI 구현에 있어 가장 중요한 과제입니다. Tan Dai는 좋은 모델은 많은 양의 사용을 통해서만 연마될 수 있다고 지적했습니다. 현재 Doubao 모델은 매일 1,200억 개의 텍스트 토큰을 처리하고 3,000만 개의 이미지를 생성합니다. 기업이 대규모 모델 시나리오를 구현하는 데 도움을 주기 위해 ByteDance가 독자적으로 개발한 beanbao 대규모 모델이 화산을 통해 출시됩니다.
 NVIDIA 대규모 모델 추론 프레임워크 살펴보기: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
NVIDIA 대규모 모델 추론 프레임워크 살펴보기: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
1. TensorRT-LLM의 제품 포지셔닝 TensorRT-LLM은 NVIDIA에서 LLM(대형 언어 모델)을 위해 개발한 확장 가능한 추론 솔루션입니다. TensorRT 딥 러닝 컴파일 프레임워크를 기반으로 계산 그래프를 구축, 컴파일 및 실행하고 FastTransformer의 효율적인 커널 구현을 활용합니다. 또한 장치 간 통신에는 NCCL을 활용합니다. 개발자는 커틀라스를 기반으로 한 맞춤형 GEMM을 개발하는 등 기술 개발 및 수요 차이를 기반으로 특정 요구 사항을 충족하도록 운영자를 맞춤화할 수 있습니다. TensorRT-LLM은 고성능을 제공하고 실용성을 지속적으로 개선하기 위해 노력하는 NVIDIA의 공식 추론 솔루션입니다. 텐서RT-LL
 산업지식 그래프 고급실습
Jun 13, 2024 am 11:59 AM
산업지식 그래프 고급실습
Jun 13, 2024 am 11:59 AM
1. 배경 소개 먼저 Yunwen Technology의 발전 역사를 소개하겠습니다. Yunwen Technology Company...2023년은 대형 모델이 유행하는 시기입니다. 많은 기업에서는 대형 모델 이후 그래프의 중요성이 크게 감소했으며 이전에 연구된 사전 설정 정보 시스템이 더 이상 중요하지 않다고 생각합니다. 그러나 RAG의 홍보와 데이터 거버넌스의 확산으로 우리는 보다 효율적인 데이터 거버넌스와 고품질 데이터가 민영화된 대형 모델의 효율성을 향상시키는 중요한 전제 조건이라는 것을 알게 되었습니다. 따라서 점점 더 많은 기업이 주목하기 시작했습니다. 지식 구축 관련 콘텐츠에 이는 또한 탐구할 수 있는 많은 기술과 방법이 있는 더 높은 수준으로 지식의 구성 및 처리를 촉진합니다. 신기술의 출현이 기존 기술을 모두 패배시키는 것이 아니라, 신기술과 기존 기술을 통합할 수도 있음을 알 수 있습니다.
 벤치마크 GPT-4! 차이나 모바일의 Jiutian 대형 모델이 이중 등록을 통과했습니다.
Apr 04, 2024 am 09:31 AM
벤치마크 GPT-4! 차이나 모바일의 Jiutian 대형 모델이 이중 등록을 통과했습니다.
Apr 04, 2024 am 09:31 AM
4월 4일 뉴스에 따르면 중국 사이버공간국은 최근 등록된 대형 모델 목록을 공개했는데, 여기에 차이나 모바일의 'Jiutian Natural Language Interaction Large Model'이 포함돼 있어 차이나 모바일의 Jiutian AI 대형 모델이 공식적으로 생성 인공 지능을 제공할 수 있음을 알렸다. 외부 세계에 대한 정보 서비스. 차이나 모바일은 이 모델이 중앙 기업이 개발한 최초의 대규모 모델로 국가 '생성 인공 지능 서비스 등록'과 '국내 심층 합성 서비스 알고리즘 등록' 이중 등록을 모두 통과했다고 밝혔습니다. 보고서에 따르면 Jiutian의 자연어 상호 작용 대형 모델은 향상된 산업 역량, 보안 및 신뢰성을 갖추고 있으며 풀 스택 현지화를 지원하며 90억, 139억, 570억, 1000억 등 다양한 매개변수 버전을 형성했습니다. 클라우드에 유연하게 배포할 수 있으며 엣지와 엔드는 상황이 다릅니다.
 새로운 테스트 벤치마크 공개, 가장 강력한 오픈소스 라마3 당황스럽다
Apr 23, 2024 pm 12:13 PM
새로운 테스트 벤치마크 공개, 가장 강력한 오픈소스 라마3 당황스럽다
Apr 23, 2024 pm 12:13 PM
시험 문제가 너무 단순하면 상위권 학생과 하위 학생 모두 90점을 받을 수 있어 격차가 더 벌어질 수 없다… 클로드3, 라마3, 심지어 GPT-5 등 더욱 강력한 모델이 출시되면서 업계는 보다 어렵고 차별화된 모델 벤치마크가 시급히 필요합니다. 대형 모델 아레나를 운영하는 조직인 LMSYS가 차세대 벤치마크인 Arena-Hard를 출시해 큰 관심을 끌었습니다. Llama3 명령의 두 가지 미세 조정 버전의 강점에 대한 최신 참조도 있습니다. 이전에 비슷한 점수를 받았던 MTBench와 비교하면 Arena-Hard 판별력이 22.6%에서 87.4%로 증가해 한눈에 봐도 강하고 약해졌습니다. Arena-Hard는 경기장의 실시간 인간 데이터를 사용하여 구축되었으며 인간 선호도와 89.1%의 일치율을 가지고 있습니다.
 샤오미 바이트가 힘을 합쳤습니다! Xiao Ai의 Doubao 액세스 대형 모델: 휴대폰과 SU7에 이미 설치되어 있음
Jun 13, 2024 pm 05:11 PM
샤오미 바이트가 힘을 합쳤습니다! Xiao Ai의 Doubao 액세스 대형 모델: 휴대폰과 SU7에 이미 설치되어 있음
Jun 13, 2024 pm 05:11 PM
6월 13일 뉴스에 따르면 Byte의 'Volcano Engine' 공개 계정에 따르면 Xiaomi의 인공 지능 비서인 'Xiao Ai'가 Volcano Engine과 협력을 이루었습니다. 두 당사자는 beanbao 대형 모델을 기반으로 보다 지능적인 AI 상호 작용 경험을 달성할 것입니다. . ByteDance가 만든 대형 빈바오 모델은 매일 최대 1,200억 개의 텍스트 토큰을 효율적으로 처리하고 3,000만 개의 콘텐츠를 생성할 수 있는 것으로 알려졌습니다. Xiaomi는 Doubao 대형 모델을 사용하여 자체 모델의 학습 및 추론 능력을 향상시키고 사용자 요구를 보다 정확하게 파악할 뿐만 아니라 보다 빠른 응답 속도와 보다 포괄적인 콘텐츠 서비스를 제공하는 새로운 "Xiao Ai Classmate"를 만들었습니다. 예를 들어, 사용자가 복잡한 과학 개념에 대해 질문하면 &ldq
