

실시간 통화에 사용되는 AI 기반 음성 향상 기술 중 일부를 이해합니다.


배경 소개
실시간 음성 및 영상 통신 RTC가 사람들의 삶과 업무에 없어서는 안될 인프라로 자리잡은 이후, 오디오 장면과 같은 복잡한 다중 장면 문제를 처리하기 위해 관련된 다양한 기술도 끊임없이 진화하고 있습니다. 여러 장치, 여러 사람, 여러 소음이 있는 시나리오에서 사용자에게 명확하고 실제적인 청각 경험을 제공합니다.
음성 신호 처리 연구 분야의 대표적인 국제 학회인 ICASSP(International Conference on Acoustics, Speech and Signal Process)는 음향학 분야에서 항상 가장 최첨단 연구 방향을 제시해 왔습니다. ICASSP 2023에는 오디오 신호 음성 향상 알고리즘과 관련된 많은 기사가 포함되어 있습니다. 그 중 Volcano Engine RTC 오디오 팀은 컨퍼런스에서 승인한 총 4 개의 연구 논문을 보유하고 있습니다. 스피커별 음성 향상, 에코 제거, 다중 채널 음성 향상, 음질 복구 테마 . 이 기사에서는 이 네 가지 논문을 통해 해결된 장면의 핵심 문제와 기술 솔루션을 소개하고, 음성 잡음 감소, 반향 제거, 간섭 인간 음성 제거 분야에 대한 Volcano Engine RTC 오디오 팀의 생각과 실무를 공유합니다.
"밴드 분할 순환 신경망을 기반으로 한 스피커별 강화"
논문 주소:
https://www.php.cn/link/73740ea85c4ec25f00f9acbd859f861d
실시간 스피커 전용 voice 강화 임무에는 해결해야 할 문제가 많습니다. 첫째, 소리의 전체 주파수 대역폭을 수집하면 모델의 처리 난이도가 높아집니다. 둘째, 비실시간 시나리오에 비해 실시간 시나리오의 모델이 대상 화자를 찾는 것이 더 어렵습니다. 화자 임베딩 벡터와 음성 향상 모델 간의 정보 상호 작용을 개선하는 방법은 실시간으로 어렵습니다. 시간 처리. Volcano Engine은 인간의 청각 주의에서 영감을 얻어 화자 정보를 도입하는 SAM(Speaker Attentive Module)을 제안하고 이를 단일 채널 음성 향상 모델-대역 분할 순환 신경망(Band-Split Recurrent Neural Network, BSRNN) 융합과 결합합니다. 에코 제거 모델의 후처리 모듈로 특정 인간 음성 향상 시스템을 구축하고 두 모델의 캐스케이드를 최적화합니다.
모델 프레임워크 구조
Band-split Recurrent Neural Network (BSRNN)

Band-split RNN (BSRNN)은 전대역 음성 향상 및 음악 분리를 위한 SOTA 모델입니다. 그 구조는 그림과 같습니다. 쇼 위. BSRNN은 Band-Split 모듈, Band and Sequence Modeling 모듈, Band-Merge 모듈이라는 세 가지 모듈로 구성됩니다. 주파수 대역 분할 모듈은 먼저 스펙트럼을 K개의 주파수 대역으로 분할한 후 각 주파수 대역의 특징을 일괄 정규화(BN)한 후 K개의 완전 연결 레이어(FC)를 통해 동일한 특징 차원 C로 압축합니다. 그 후, 모든 주파수 대역의 특징은 3차원 텐서로 연결되고 GRU를 사용하여 특징 텐서의 시간 및 주파수 대역 차원을 교대로 모델링하는 주파수 대역 시퀀스 모델링 모듈에 의해 추가로 처리됩니다. 처리된 특징은 최종적으로 주파수 대역 병합 모듈을 거쳐 최종 스펙트럼 마스킹 함수를 출력으로 얻습니다. 스펙트럼 마스크와 입력 스펙트럼을 곱하면 향상된 음성을 얻을 수 있습니다. 화자별 음성 향상 모델을 구축하기 위해 각 주파수 대역 시퀀스의 모델링 모듈 뒤에 화자 주의 모듈을 추가합니다.
스피커 어텐티브 모듈(SAM)

스피커 어텐티브 모듈의 구조는 위 그림과 같습니다. 핵심 아이디어는 스피커 임베딩 벡터 e를 음성 향상 모델의 중간 특징의 어트랙터로 사용하고, 항상 중간 특징과 주파수 대역 간의 상관관계s를 계산하는 것입니다. 관심 가치. 이 어텐션 값은 중간 기능 h을 확장하고 정규화하는 데 사용됩니다. 구체적인 공식은 다음과 같습니다.
먼저 완전 연결과 컨볼루션을 통해 e와 h를 k와 q로 변환합니다.
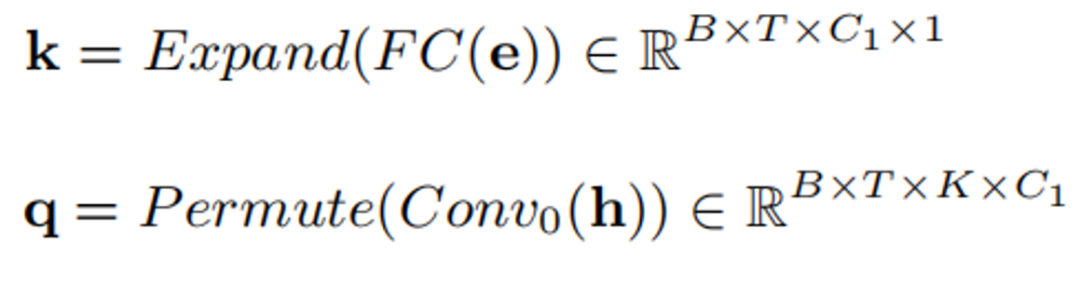
k와 q를 곱하여 어텐션 값을 얻습니다.
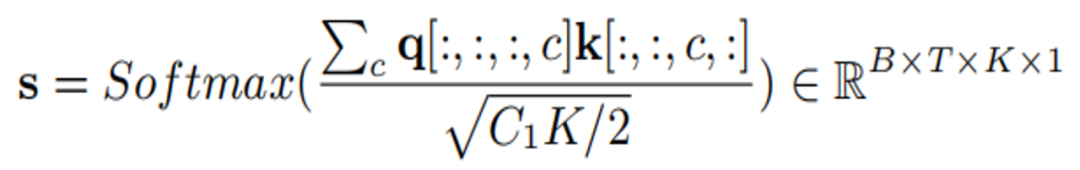
마지막으로 어텐션 값을 얻습니다. Scale 원래 기능이 전달되었습니다:
모델 훈련 데이터
모델 훈련 데이터는 5차 DNS Speaker-Specific Speaker Speech Enhancement Track의 데이터와 DiDispeech의 고품질 음성 데이터를 사용하였으며, 데이터 클리닝을 통해 약 3500명의 화자의 명확한 음성 데이터를 얻었습니다. . 데이터 클리닝 측면에서는 음성 데이터에서 잔여 간섭 화자 음성을 제거하기 위해 ECAPA-TDNN[1] 화자 인식 기반의 사전 훈련된 모델을 사용했으며, 또한 음성 데이터에서 1위를 차지한 사전 훈련된 모델을 사용했습니다. 음성 데이터에서 잔여 잡음을 제거하기 위한 4차 DNS 챌린지입니다. 훈련 단계에서 우리는 100,000개 이상의 4s 음성 데이터를 생성하고, 이러한 오디오에 잔향을 추가하여 다양한 채널을 시뮬레이션하고, 이를 잡음 및 간섭 보컬과 무작위로 혼합하여 한 종류의 잡음, 두 가지 유형의 잡음, 잡음 및 간섭으로 설정했습니다. 음성 간섭 시나리오에는 인간과 간섭하는 화자만 있는 4가지 시나리오가 있습니다. 동시에, 시끄러운 음성과 대상 음성의 레벨은 무작위로 크기 조정되어 다양한 크기의 입력을 시뮬레이션합니다.
"특정 화자 추출 및 반향 제거 융합을 위한 기술 솔루션"
논문 주소:
https://www.php.cn/link/7c7077ca5231fd6ad758b9d49a2a1eeb
답글 소리 취소는 항상 외부에서 수행된 시나리오에서 매우 복잡하고 중요한 문제입니다. Volcano Engine은 고품질 근단 청정 음성 신호를 추출하기 위해 신호 처리와 딥러닝 기술을 결합한 경량 반향 제거 시스템을 제안합니다. pDNS(Personalized Deep Noise Suppression)를 기반으로 pAEC(Personalized Acoustic Echo Cancellation) 시스템을 추가로 구축했습니다. 여기에는 디지털 신호 처리를 기반으로 한 전처리 모듈, 심층 잡음 제거 2단계 모델을 기반으로 한 전처리 모듈이 포함됩니다. BSRNN 및 SAM을 기반으로 하는 신경망 및 화자별 음성 추출 모듈.

스피커별 반향 제거의 전체 프레임워크
디지털 신호 처리 선형 반향 제거 기반 전처리 모듈
전처리 모듈은 주로 시간 지연 보상(TDC) 두 부분으로 구성됩니다. 및 LAEC(선형 반향 제거), 이 모듈은 하위 대역 기능에 대해 수행됩니다.

신호 처리 하위 대역 선형 반향 제거 알고리즘 프레임워크 기반
지연 보상
TDC는 하위 대역 교차 상관을 기반으로 하며, 먼저 각 하위 대역의 지연을 개별적으로 추정합니다. 그런 다음 투표 방법을 사용하여 최종 시간 지연을 결정합니다.
Linear Echo Cancellation
LAEC는 NLMS 기반의 하위 대역 적응 필터링 방법으로, 사전 필터(Pre-filter)와 사후 필터(Post-filter)의 두 가지 필터로 구성됩니다. 매개변수를 적응적으로 업데이트하며 사전 필터는 안정적인 사후 필터의 백업입니다. 프리 필터와 포스트 필터에서 출력되는 잔류 에너지를 비교하여 최종적으로 어떤 오류 신호를 사용할지 결정합니다.

LAEC 처리 흐름도
다단계 합성곱-순환 합성곱 신경망(CRN) 기반 2단계 모델
pAEC 작업을 분리하여 "에코 억제"로 분할하는 것이 좋습니다." 모델 모델링 부담을 줄이기 위한 "특정 화자 추출" 작업. 따라서 후처리 네트워크는 주로 예비 에코 제거 및 잡음 억제를 위한 경량 CRN 기반 모듈과 더 나은 근거리 음성 신호 재구성을 위한 pDNS 기반 후처리 모듈의 두 가지 신경망 모듈로 구성됩니다.
1단계: CRN 기반 경량 모듈
CRN 기반 경량 모듈은 대역 압축 모듈, 인코더, 이중 경로 GRU 2개, 디코더 및 대역 분해 모듈로 구성됩니다. 동시에 멀티 태스킹 학습을 위한 VAD(음성 활동 감지) 모듈도 도입하여 근거리 음성 인식을 향상시키는 데 도움이 됩니다. CRN은 압축 진폭을 입력으로 사용하고 예비 cIRM(복소 이상 비율 마스크) 및 대상 신호의 근거리 VAD 확률을 출력합니다.
두 번째 단계: pDNS 기반 후처리 모듈
이 단계의 pDNS 모듈에는 위에서 소개한 대역 분할 순환 신경망 BSRNN과 스피커 주의 메커니즘 모듈 SAM이 포함되어 있으며 캐스케이드 모듈은 경량 수준 CRN에 직렬로 연결됩니다. 기준 치수. 우리의 pDNS 시스템은 특징적인 화자 음성 향상 작업에서 상대적으로 우수한 성능을 달성했기 때문에 사전 훈련된 pDNS 모델 매개변수를 모델의 두 번째 단계 초기화 매개변수로 사용하여 이전 단계의 출력을 추가로 처리합니다.
캐스케이드 시스템 트레이닝 최적화 손실 함수
1단계에서 근단 음성을 예측하고, 두 번째 단계에서 특정 화자의 근단 음성을 예측할 수 있도록 캐스케이드 최적화를 통해 2단계 모델을 개선합니다. 또한 근거리에서 음성을 인식하는 모델의 능력을 향상시키기 위해 화자와의 근접성에 대한 음성 활동 감지 페널티도 포함합니다. 특정 손실 함수는 다음과 같이 정의됩니다.

여기서
는 각각 모델의 첫 번째 단계와 두 번째 단계에서 예측된 STFT 특성에 해당하며 각각 근단 음성 및 근단 특정의 STFT 특성을 나타냅니다. 화자 음성,
은 각각 모델 예측과 대상 VAD 상태를 나타냅니다.
모델 훈련 데이터
반향 제거 시스템이 다중 장치, 다중 반향 및 다중 소음 수집 장면의 반향을 처리할 수 있도록 반향과 깨끗한 음성을 혼합하여 2000시간 이상의 훈련 데이터를 얻었습니다. 에코 데이터는 AEC Challenge 2023 원격 단일 음성 데이터를 사용하고, 깨끗한 음성은 DNS Challenge 2023 및 LibriSpeech에서 가져오고, 근단 반향을 시뮬레이션하는 데 사용되는 RIR 세트는 DNS Challenge에서 가져옵니다. AEC Challenge 2023 원단 단일 대화 데이터의 에코에는 소량의 잡음 데이터가 포함되어 있으므로 이러한 데이터를 에코로 직접 사용하면 쉽게 근단 음성 왜곡이 발생할 수 있으므로 이 문제를 완화하기 위해 간단한 방식을 채택했습니다. 그러나 사전 처리를 사용하는 효과적인 데이터 정리 전략 훈련된 AEC 모델은 원격 단일 채널 데이터를 처리하고 잔류 에너지가 높은 데이터를 노이즈 데이터로 식별하고 아래 그림에서 정리 프로세스를 반복적으로 반복합니다.
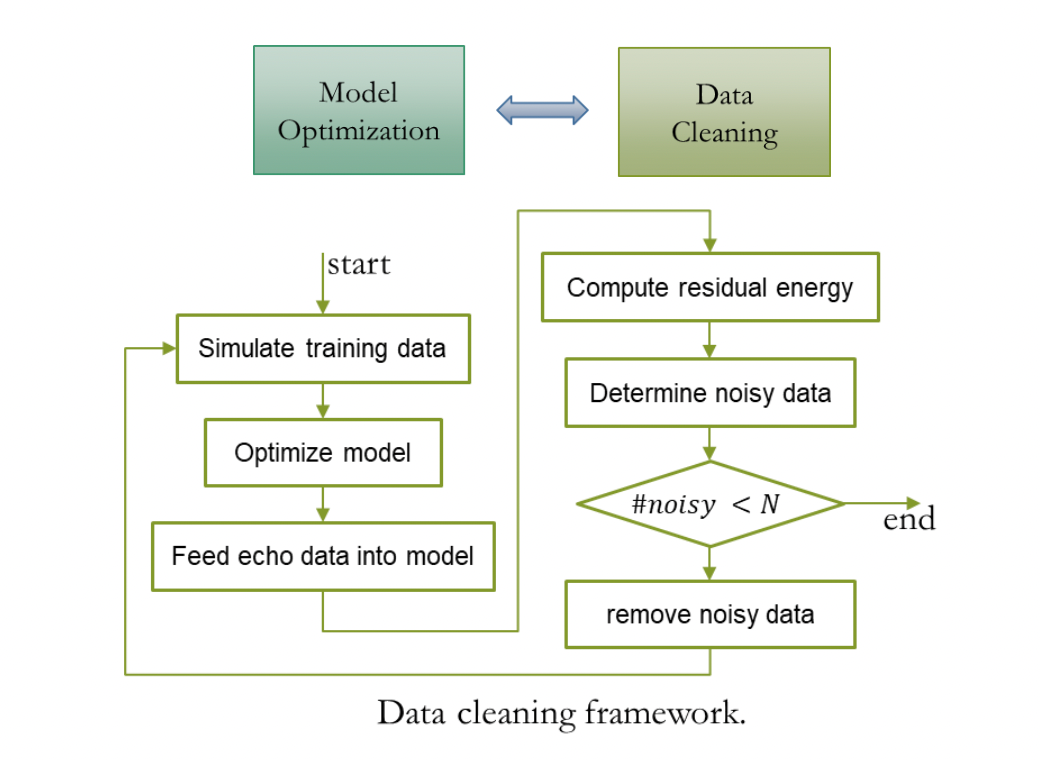
계단식 최적화 체계 시스템 효과
융합 에코 제거 및 특정 화자 추출을 기반으로 한 이러한 음성 향상 시스템은 주관적 및 객관적 지표에 대한 ICASSP 2023 AEC Challenge 블라인드 테스트 세트 [2]에서 검증되었습니다. 장점 - 주관적 달성 의견 점수는 4.44(주관적-MOS), 음성 인식 정확도는 82.2%(WAcc)입니다.

"푸리에 회선 주의 메커니즘을 기반으로 한 다중 채널 음성 향상"
논문 주소:
https://www.php.cn/link/373cb8cd58 cad5f1309b31c56e2d5a83
딥 러닝 기반 빔 가중치 추정은 현재 다중 채널 음성 향상 작업을 해결하는 주류 방법 중 하나입니다. 즉, 순수 음성을 얻기 위해 네트워크를 통해 빔 가중치를 해결하여 다중 채널 신호를 필터링하는 것입니다. 빔 가중치 추정에 있어서 스펙트럼 정보와 공간정보의 역할은 전통적인 빔 형성 알고리즘의 공간 공분산 행렬을 푸는 원리와 유사하다. 그러나 기존의 많은 신경 빔 형성기는 빔 가중치를 최적으로 추정할 수 없습니다. 이러한 문제를 해결하기 위해 Volcano Engine은 주파수 특성 축에 전역 수용 필드를 제공하고 추출 주파수 축의 컨텍스트 특성을 향상시킬 수 있는 FCAE(Fourier Convolutional Attention Encoder)를 제안합니다. 동시에 입력 특징으로부터 스펙트럼 맥락 특징과 공간 정보를 캡처하기 위한 FCAE 기반 CRED(Convolutional Recurrent Encoder-Decoder) 구조도 제안했습니다.
모델 프레임워크 구조
빔 가중치 추정 네트워크

이 네트워크는 EaBNet(EaBNet)의 구조적 패러다임을 사용하여 네트워크를 임베딩 모듈과 빔 모듈의 두 부분으로 나눕니다. 스펙트럼 정보와 공간 정보를 종합한 임베딩 벡터를 추출하고, 임베딩 벡터를 빔 부분으로 보내 빔 가중치를 도출하는 데 사용됩니다. 여기서 CRED 구조는 임베딩 텐서를 학습하는 데 사용됩니다. 다중 채널 입력 신호는 STFT로 변환된 후 임베딩 텐서를 추출하기 위해 CRED 구조로 전송됩니다. 임베딩 텐서는 기존 빔포밍의 공간 공분산 행렬과 유사합니다. 구별 가능한 음성과 소음의 특성을 포함합니다. 임베딩 텐서는 LayerNorm2d 구조를 통과한 다음 두 개의 적층형 LSTM 네트워크를 통과하고 마지막으로 선형 레이어를 통해 빔 가중치가 파생됩니다. 다중 채널 입력 스펙트럼 특성에 빔 가중치를 적용하고 필터링 및 합산 작업을 수행하여 최종적으로 순수 음성 스펙트럼을 얻습니다. ISTFT 변환 후 목표 시간 영역 파형을 얻을 수 있습니다.
CRED 구조
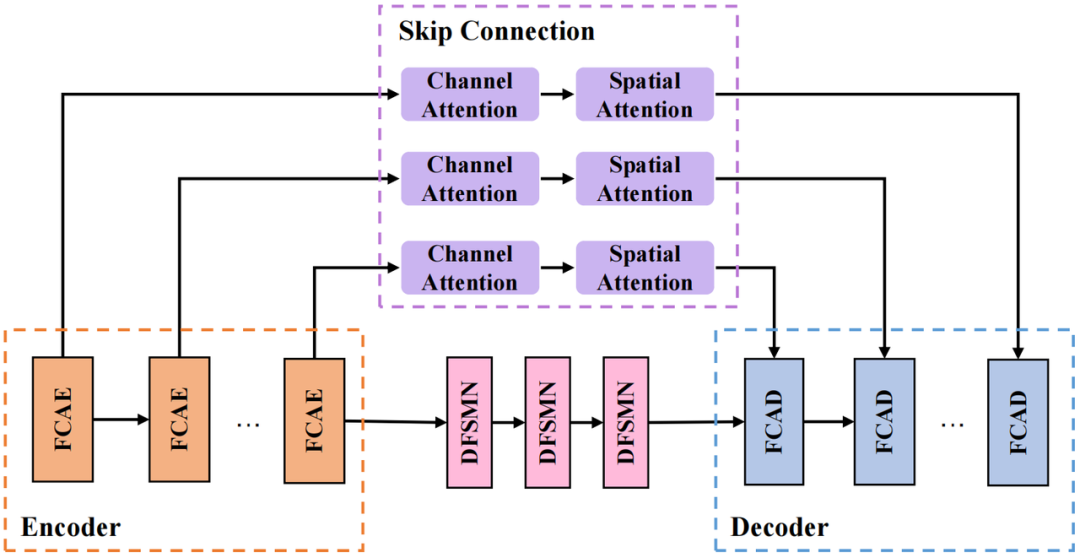
우리가 채택한 CRED 구조는 위 그림과 같습니다. 그중 FCAE는 푸리에 컨볼루셔널 어텐션 인코더이고, FCAD는 FCAE와 대칭인 디코더입니다. 루프 모듈은 DFSMN(Deep Feedward Sequential Memory Network)을 사용하여 모델에 영향을 주지 않고 모델 크기를 줄입니다. 성능; 점프 연결 부분은 직렬 채널 주의(Channel Attention) 및 공간 주의(Spatial Attention) 모듈을 사용하여 교차 채널 공간 정보를 추가로 추출하고 심층 계층을 연결합니다. 특징 및 얕은 특징은 네트워크에서 정보 전송을 용이하게 합니다.
FCAE 구조
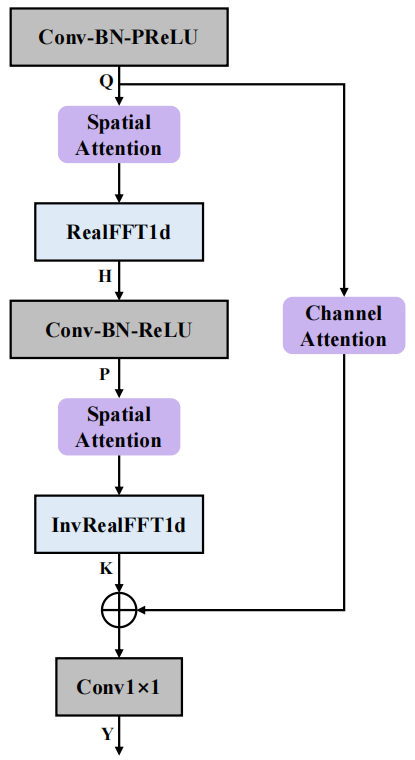
Fourier Convolutional Attention Encoder(FCAE)의 구조는 위 그림과 같습니다. 푸리에 컨볼루션 연산자[3]에서 영감을 받은 이 모듈은 변환 도메인의 임의 지점에서 이산 푸리에 변환을 업데이트하면 원래 도메인의 신호에 전역적인 영향을 미치고 다음을 수행한다는 사실을 활용합니다. 주파수 축 특징의 주파수 분석 차원 FFT 변환을 통해 주파수 축에서 전역 수용 필드를 얻을 수 있으므로 주파수 축에서 컨텍스트 특징 추출이 향상됩니다. 또한, 컨볼루셔널 표현 능력을 더욱 강화하고, 유익한 스펙트럼-공간 결합 정보를 추출하며, 순수 음성 및 소음의 구별 가능한 특징에 대한 네트워크의 학습을 향상시키기 위해 공간 주의 모듈과 채널 주의 모듈을 도입했습니다. 최종 성능 측면에서 네트워크는 단 0.74M 매개변수만으로 탁월한 다중 채널 음성 향상을 달성했습니다.
모델 학습 데이터
데이터 세트 측면에서는 ConferencingSpeech 2021 대회에서 제공하는 오픈 소스 데이터 세트를 사용했습니다. 순수 음성 데이터에는 AISHELL-1, AISHELL-3, VCTK 및 LibriSpeech(train-clean-360)가 포함됩니다. , 그리고 그 중 신호-잡음 데이터를 선택하여 15dB 이상의 비율을 갖는 데이터를 사용하여 다중 채널 혼합 음성을 생성하며, 잡음 데이터 세트는 MUSAN 및 AudioSet을 사용합니다. 동시에 실제 멀티룸 잔향 시나리오를 시뮬레이션하기 위해 공간 크기, 잔향 시간, 음원, 소음원 위치 등의 변화를 시뮬레이션하여 오픈 소스 데이터를 5,000개 이상의 공간 임펄스 응답으로 컨볼루션했으며, 마침내 60,000개 이상의 다중 채널 훈련 샘플이 생성되었습니다.
"2단계 신경망 모델 기반 음질 복원 시스템"
논문 주소:
https://www.php.cn/link/e614f646836aaed9f89ce58e837e2310
화산 엔진은 여전히 음질 복구 작업 중 특정 화자의 음성을 향상하고, 에코를 제거하고, 다중 채널 오디오를 향상시키기 위한 여러 가지 시도가 있었습니다. 실시간 통신 과정에서 다양한 형태의 왜곡이 음성 신호의 품질에 영향을 미쳐 음성 신호의 선명도와 명료도가 저하됩니다. Volcano Engine은 단계적 분할 정복 전략을 사용하여 음성 품질에 영향을 미치는 다양한 왜곡을 복구하는 2단계 모델을 제안합니다.
모델 프레임 구조
아래 사진은 2단 모델의 전체적인 프레임 구성을 보여줍니다. 그 중 1단계 모델은 주로 스펙트럼의 누락된 부분을 복구하고, 2단계 모델은 주로 소음, 잔향을 억제합니다. 및 첫 번째 단계의 필름에서 생성될 수 있는 아티팩트입니다.

1단계 모델: Net 수리
전체 모델은 인코더, 타이밍 모델링 모듈 및 디코더의 세 부분을 포함하는 DCCRN(Deep Complex Convolution Recurrent Network) [4] 아키텍처를 채택합니다. 이미지 복구에서 영감을 받아 인코더 및 디코더의 복소수 값 컨볼루션과 복소수 전치 컨볼루션을 대체하기 위해 게이트 복소수 값 컨볼루션과 게이트 복소수 값 전치 컨볼루션을 도입합니다. 오디오 수리 부분의 자연스러움을 더욱 향상시키기 위해 보조 훈련을 위한 Multi-Period Discriminator와 Multi-Scale Discriminator를 도입했습니다.
2단계 모델: Denoising Net
인코더, 두 개의 경량 DCCRN 하위 모듈 및 디코더를 포함한 전체 S-DCCRN 아키텍처가 채택되었습니다. 두 개의 경량 DCCRN 하위 모듈은 하위 대역 및 전체 규모 처리를 수행합니다. 각각 모델링. 시간 영역 모델링에서 모델의 능력을 향상시키기 위해 DCCRN 하위 모듈의 LSTM을 STCM(Squeezed Temporal Convolutional Module)으로 교체했습니다.
모델 훈련 데이터
음질 복원 훈련에 사용된 클린 오디오, 노이즈, 잔향은 모두 2023년 DNS 경쟁 데이터 세트에서 가져온 것입니다. 클린 오디오의 총 지속 시간은 750시간이고 노이즈의 총 지속 시간은 170시간. 첫 번째 단계 모델의 데이터 증대 동안 우리는 무작위로 생성된 필터와 컨볼루션하기 위해 전대역 오디오를 사용했으며, 창 길이는 20ms로 오디오 샘플링 지점을 무작위로 0으로 설정하고 오디오를 무작위로 다운샘플링하여 스펙트럼 손실을 시뮬레이션했습니다. 데이터 증폭의 두 번째 단계에서는 오디오 진폭 주파수와 오디오 수집 지점에 각각 무작위 스케일을 곱하고, 첫 번째 단계에서 이미 생성된 데이터를 사용하여 다양한 유형의 실내 자극을 컨볼루션합니다. 다양한 수준의 반향음.
오디오 처리 효과
ICASSP 2023 AEC 챌린지에서 Volcano Engine RTC 오디오 팀이 Universal Echo Cancellation(비개인화 AEC)와 특정 스피커 에코 제거(Personalized AEC) 두 트랙에서 우승을 차지했으며, 이중 대화 반향 억제, 이중 대화 근거리 음성 보호, 근거리 단일 대화 배경 소음 억제, 종합 주관적 오디오 품질 채점 및 최종 음성 인식 정확도
는 다른 참가 팀보다 훨씬 뛰어나며 국제 수준에 도달했습니다. 선두적인 수준. 위의 기술 솔루션 이후 다양한 시나리오에서 Volcano Engine RTC의 음성 향상 처리 효과를 살펴보겠습니다. 다양한 신호 대 잡음 에코 비율 시나리오의 에코 제거다음 두 예는 다양한 신호 대 에코 에너지 비율 시나리오에서 처리 전후의 에코 제거 알고리즘의 비교 효과를 보여줍니다.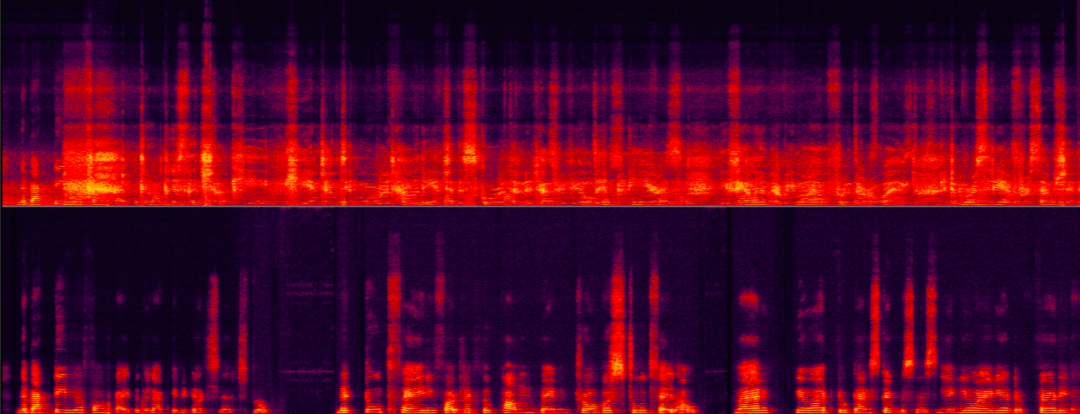
중간 신호 대 에코 비율 장면
초저 신호 대 에코 비율 장면은 현재 에코 제거가 가장 어려운 부분입니다. 고에너지 에코를 효과적으로 제거하는 동시에 약한 대상 음성 보존을 극대화합니다. 대상이 아닌 화자의 음성(에코)이 대상 화자(여성)의 목소리를 거의 완전히 가려 식별이 어렵습니다.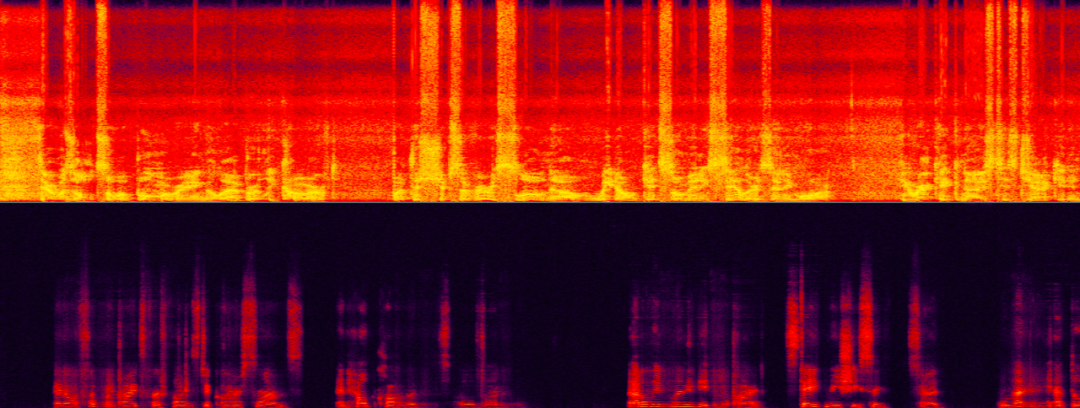
매우 낮은 신호 대 에코 비율 장면
다양한 배경이 화자를 방해하는 시나리오에서 화자 추출다음 두 예는 각각 특정 화자 추출의 성능을 보여줍니다. 소음 및 배경의 알고리즘 인간 간섭 장면에서 처리 전후의 비교 효과. 다음 샘플에서 특정 스피커에는 초인종 소음 간섭과 배경 소음 간섭이 모두 있습니다. AI 소음 감소만으로는 초인종 소음만 제거할 수 있으므로 특정 스피커의 음성을 제거해야 합니다.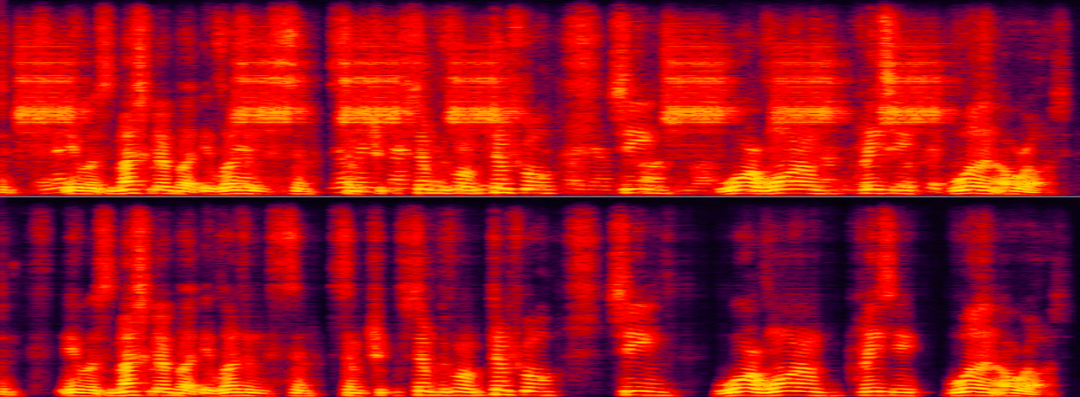
대상 화자와 배경 간섭 음성 및 소음
대상 화자의 성문 특징과 배경 간섭 음성이 매우 근접할 경우 특정 화자를 추출하는 챌린지 알고리즘의 크기가 더 크며 특정 화자 추출 알고리즘의 견고성을 테스트할 수 있습니다. 다음 샘플에서 대상 화자와 배경 간섭 음성은 두 개의 유사한 여성 음성입니다.
타겟 여성 목소리와 간섭 여성 목소리의 혼합
요약 및 전망위는 스피커별 소음 감소, 에코에 대한 딥 러닝 기반의 Volcano Engine RTC 오디오 팀을 소개합니다. 취소 및 다중 채널 음성 향상 방향으로 일부 솔루션과 효과가 만들어졌지만 미래 시나리오는 소음 장면에 음성 잡음 감소를 적용하는 방법, 다중 유형 복구를 수행하는 방법과 같은 여러 방향에서 여전히 과제에 직면해 있습니다. 더 넓은 범위의 음질 수리에 대한 오디오 신호 및 더 넓은 범위의 오디오 신호에 대한 다양한 유형의 수리를 수행하는 방법 유사한 터미널에서 가볍고 복잡하지 않은 모델을 실행하는 이러한 과제는 앞으로도 우리의 초점이 될 것입니다. 🎜위 내용은 실시간 통화에 사용되는 AI 기반 음성 향상 기술 중 일부를 이해합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 C에서 DMA 운영을 이해하는 방법?
Apr 28, 2025 pm 10:09 PM
C에서 DMA 운영을 이해하는 방법?
Apr 28, 2025 pm 10:09 PM
C의 DMA는 직접 메모리 액세스 기술인 DirectMemoryAccess를 말하며 하드웨어 장치는 CPU 개입없이 데이터를 메모리로 직접 전송할 수 있습니다. 1) DMA 운영은 하드웨어 장치 및 드라이버에 크게 의존하며 구현 방법은 시스템마다 다릅니다. 2) 메모리에 직접 액세스하면 보안 위험이 발생할 수 있으며 코드의 정확성과 보안이 보장되어야합니다. 3) DMA는 성능을 향상시킬 수 있지만 부적절하게 사용하면 시스템 성능이 저하 될 수 있습니다. 실습과 학습을 통해 우리는 DMA 사용 기술을 습득하고 고속 데이터 전송 및 실시간 신호 처리와 같은 시나리오에서 효과를 극대화 할 수 있습니다.
 C에서 Chrono 라이브러리를 사용하는 방법?
Apr 28, 2025 pm 10:18 PM
C에서 Chrono 라이브러리를 사용하는 방법?
Apr 28, 2025 pm 10:18 PM
C에서 Chrono 라이브러리를 사용하면 시간과 시간 간격을보다 정확하게 제어 할 수 있습니다. 이 도서관의 매력을 탐구합시다. C의 크로노 라이브러리는 표준 라이브러리의 일부로 시간과 시간 간격을 다루는 현대적인 방법을 제공합니다. 시간과 C 시간으로 고통받는 프로그래머에게는 Chrono가 의심 할 여지없이 혜택입니다. 코드의 가독성과 유지 가능성을 향상시킬뿐만 아니라 더 높은 정확도와 유연성을 제공합니다. 기본부터 시작합시다. Chrono 라이브러리에는 주로 다음 주요 구성 요소가 포함됩니다. std :: Chrono :: System_Clock : 현재 시간을 얻는 데 사용되는 시스템 클럭을 나타냅니다. STD :: 크론
 정량적 거래 순위 2025 디지털 통화 정량 거래 앱에 대한 상위 10 개 권장 사항
Apr 30, 2025 pm 07:24 PM
정량적 거래 순위 2025 디지털 통화 정량 거래 앱에 대한 상위 10 개 권장 사항
Apr 30, 2025 pm 07:24 PM
교환의 내장 양자화 도구에는 다음이 포함됩니다. 1. Binance : Binance 선물 정량 모듈, 낮은 취급 수수료 및 AI 지원 거래를 지원합니다. 2. OKX (OUYI) : 다중 계정 관리 및 지능형 주문 라우팅을 지원하고 기관 수준의 위험 관리를 제공합니다. 독립적 인 정량적 전략 플랫폼에는 다음이 포함됩니다. 4. Quadency : 맞춤형 위험 임계 값을 지원하는 전문 수준 알고리즘 전략 라이브러리. 5. Pionex : 내장 16 사전 설정 전략, 낮은 거래 수수료. 수직 도메인 도구에는 다음이 포함됩니다. 6. Cryptohopper : 클라우드 기반 정량 플랫폼, 150 개의 기술 지표를 지원합니다. 7. BITSGAP :
 C에서 높은 DPI 디스플레이를 처리하는 방법?
Apr 28, 2025 pm 09:57 PM
C에서 높은 DPI 디스플레이를 처리하는 방법?
Apr 28, 2025 pm 09:57 PM
C에서 높은 DPI 디스플레이를 처리 할 수 있습니다. 1) DPI 및 스케일링을 이해하고 운영 체제 API를 사용하여 DPI 정보를 얻고 그래픽 출력을 조정하십시오. 2) 크로스 플랫폼 호환성을 처리하고 SDL 또는 QT와 같은 크로스 플랫폼 그래픽 라이브러리를 사용하십시오. 3) 성능 최적화를 수행하고 캐시, 하드웨어 가속 및 세부 사항 수준의 동적 조정을 통해 성능 향상; 4) 흐릿한 텍스트 및 인터페이스 요소와 같은 일반적인 문제를 해결하고 DPI 스케일링을 올바르게 적용하여 해결합니다.
 C의 실시간 운영 체제 프로그래밍이란 무엇입니까?
Apr 28, 2025 pm 10:15 PM
C의 실시간 운영 체제 프로그래밍이란 무엇입니까?
Apr 28, 2025 pm 10:15 PM
C는 실시간 운영 체제 (RTO) 프로그래밍에서 잘 수행하여 효율적인 실행 효율성과 정확한 시간 관리를 제공합니다. 1) c 하드웨어 리소스의 직접 작동 및 효율적인 메모리 관리를 통해 RTO의 요구를 충족시킵니다. 2) 객체 지향 기능을 사용하여 C는 유연한 작업 스케줄링 시스템을 설계 할 수 있습니다. 3) C는 효율적인 인터럽트 처리를 지원하지만 실시간을 보장하려면 동적 메모리 할당 및 예외 처리를 피해야합니다. 4) 템플릿 프로그래밍 및 인라인 함수는 성능 최적화에 도움이됩니다. 5) 실제 응용 분야에서 C는 효율적인 로깅 시스템을 구현하는 데 사용될 수 있습니다.
 C에서 스레드 성능을 측정하는 방법?
Apr 28, 2025 pm 10:21 PM
C에서 스레드 성능을 측정하는 방법?
Apr 28, 2025 pm 10:21 PM
C에서 스레드 성능을 측정하면 표준 라이브러리에서 타이밍 도구, 성능 분석 도구 및 사용자 정의 타이머를 사용할 수 있습니다. 1. 라이브러리를 사용하여 실행 시간을 측정하십시오. 2. 성능 분석을 위해 GPROF를 사용하십시오. 단계에는 컴파일 중에 -pg 옵션 추가, GMON.out 파일을 생성하기 위해 프로그램을 실행하며 성능 보고서를 생성하는 것이 포함됩니다. 3. Valgrind의 Callgrind 모듈을 사용하여보다 자세한 분석을 수행하십시오. 단계에는 Callgrind.out 파일을 생성하고 Kcachegrind를 사용하여 결과를보기위한 프로그램 실행이 포함됩니다. 4. 사용자 정의 타이머는 특정 코드 세그먼트의 실행 시간을 유연하게 측정 할 수 있습니다. 이 방법은 스레드 성능을 완전히 이해하고 코드를 최적화하는 데 도움이됩니다.
 MySQL 테이블에 필드를 추가 및 삭제하는 단계
Apr 29, 2025 pm 04:15 PM
MySQL 테이블에 필드를 추가 및 삭제하는 단계
Apr 29, 2025 pm 04:15 PM
MySQL에서는 altertabletable_nameaddcolumnnew_columnvarchar (255) 이후에 필드를 추가하여 altertabletable_namedropcolumncolumn_to_drop을 사용하여 필드를 삭제합니다. 필드를 추가 할 때는 쿼리 성능 및 데이터 구조를 최적화하기위한 위치를 지정해야합니다. 필드를 삭제하기 전에 작업이 돌이킬 수 없는지 확인해야합니다. 온라인 DDL, 백업 데이터, 테스트 환경 및 저하 기간을 사용하여 테이블 구조 수정은 성능 최적화 및 모범 사례입니다.
 C에서 문자열 스트림을 사용하는 방법?
Apr 28, 2025 pm 09:12 PM
C에서 문자열 스트림을 사용하는 방법?
Apr 28, 2025 pm 09:12 PM
C에서 문자열 스트림을 사용하기위한 주요 단계와 예방 조치는 다음과 같습니다. 1. 출력 문자열 스트림을 생성하고 정수를 문자열로 변환하는 것과 같은 데이터를 변환합니다. 2. 벡터를 문자열로 변환하는 것과 같은 복잡한 데이터 구조의 직렬화에 적용하십시오. 3. 성능 문제에주의를 기울이고 많은 양의 데이터를 처리 할 때 문자열 스트림을 자주 사용하지 마십시오. std :: string의 Append 메소드를 사용하는 것을 고려할 수 있습니다. 4. 메모리 관리에주의를 기울이고 스트림 스트림 객체의 자주 생성과 파괴를 피하십시오. std :: stringstream을 재사용하거나 사용할 수 있습니다.
