
DeepMind의 새로운 AI는 Nature에 등장한 지 하루밖에 되지 않았는데, GPT-4가 이미 경쟁에 나섰습니다!
단 두 단락의 프롬프트만으로 GPT-4는 AlphaDev와 동일한 정렬 알고리즘 최적화 방법을 제공합니다.
DeepMind는 정렬 알고리즘 속도를 최대 70%까지 높일 수 있는 방법을 발견했기 때문에 AlphaDev를 "AlphaGo의 마법을 재현"한다고 부릅니다.
아, AlphaDev는 이제 더욱 부끄러워졌습니다.
GPT-4가 동일한 작업을 직접 수행한 형제를 "발견"하게 하세요.
강화 학습이 전혀 필요하지 않습니다. 이 발견을 Nature에 게재할 수 있나요?
머스크는 "지나가다가 봤다"며 "바람 때문에"라는 댓글도 남겼다.

그렇다면 GPT-4는 어떻게 할까요?
이 새로운 발견을 가져온 사람은 Dimitris Papailiopoulos라는 위스콘신-매디슨 대학의 부교수(이하 D 교수)입니다.
GPT-4가 이 작업을 수행하도록 하기 위해 그가 사용한 단계는 매우 간단했고 그는 총 두 개의 프롬프트만 입력했습니다.
먼저 그는 GPT-4에게 다음과 같이 말했습니다.
이것은 정렬 알고리즘이고, 더 최적화될 수 있다고 생각합니다. 어떤 문장을 다시 작성해야 합니까? . 이유를 단계별로 설명하고 다시 돌아가서 그것이 올바른지 확인하세요.

첫 번째 단계에서는 새로운 발견이 있으면 먼저 변경하지 말고 '시청'하고 개선을 위한 몇 가지 제안 사항을 서면으로 적어 두라고 강조했습니다.
매우 자세하고 주의 깊게 작성하세요.
그런 다음 GPT-4는 주어진 코드에 대한 자세한 설명을 제공합니다.

그런 다음 D 교수님이 두 번째 팁을 주셨습니다.
계속하세요. 자신이 있다면 위의 팁을 따르세요. 생성된 결과가 결정적이고 일관성이 있는지 확인하고 혼란을 피하기 위해 온도를 0으로 설정합니다.
그런 다음 GPT-4는 자세한 단계를 제공하고 마침내 결론을 내렸습니다.
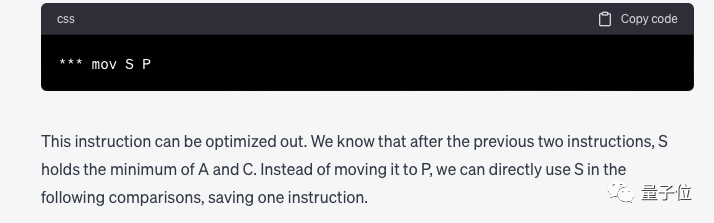
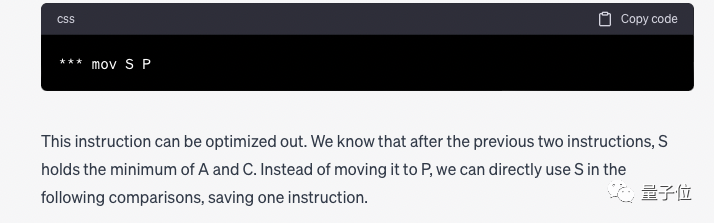
"mov S P" 명령은 중복되어 제거할 수 있으며 다른 지침이 필요하다는 것을 발견했습니다. 단, 삭제 후에는 P를 S로 바꿔야 합니다.
DeepMind의 신작과 동일한 문제를 다루는 AlphaDev의 생각을 비교해 보면, 그것과 아무 관련이 없다고 말할 수는 없으며, 완전히 동일하다고만 말할 수 있습니다:
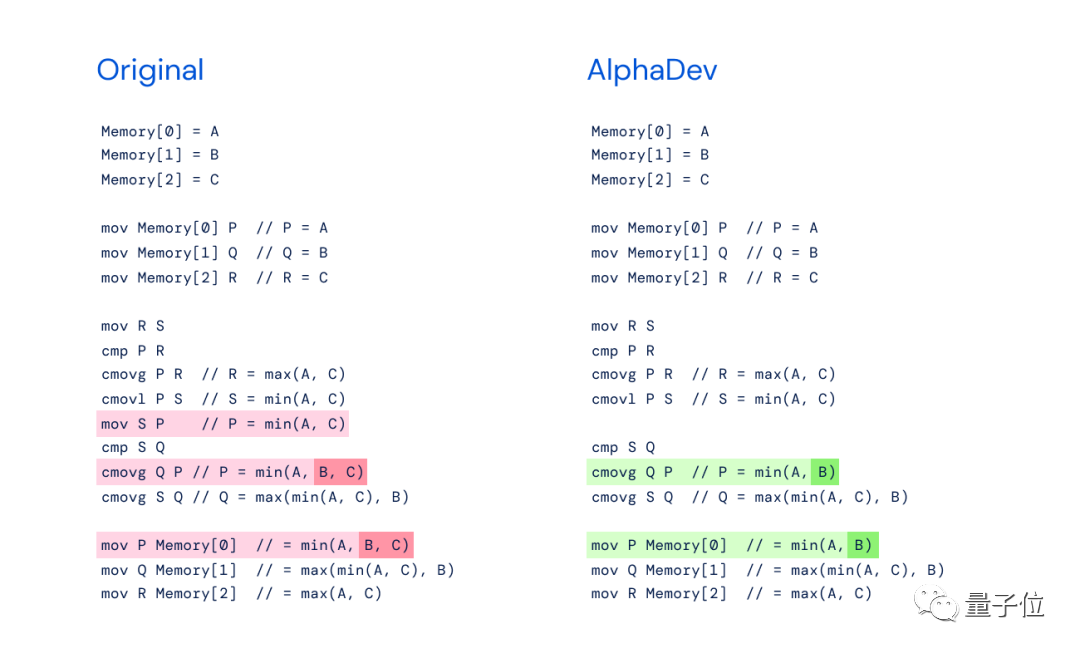
DeepMind의 AlphaDev 운영은 당시 AlphaGo의 'Move 37'을 연상시킵니다. 직관에 반하는 수법으로 전설적인 바둑기사 이세돌을 직접 꺾어 청중을 놀라게 했습니다.
마찬가지로 AlphaDev는 동작을 교환하고 복사하여 단계를 건너뛰고 잘못된 것처럼 보이지만 실제로는 지름길인 방식으로 목표를 달성합니다.
보고서에 따르면 AlphaDev는 AlphaZero를 기반으로 한 강화 학습 알고리즘이며 기존 알고리즘을 기반으로 하지 않고 가장 낮은 수준의 조립 지침에서 시작됩니다.
혁신은 주로 두 가지 명령 시퀀스에 있습니다.
(1) AlphaDev Swap Move(스왑 이동)
(2) AlphaDev Copy Move(복사 이동)
원칙적으로 DeepMind 연구원은 싱글 플레이어 "어셈블리"를 설계했습니다. 게임:
적절한 지침(아래 그림의 A 프로세스)을 검색 및 선택하고 데이터를 정확하고 빠르게 정렬(아래 그림의 B 프로세스)할 수 있는 한 보상을 받을 수 있습니다.
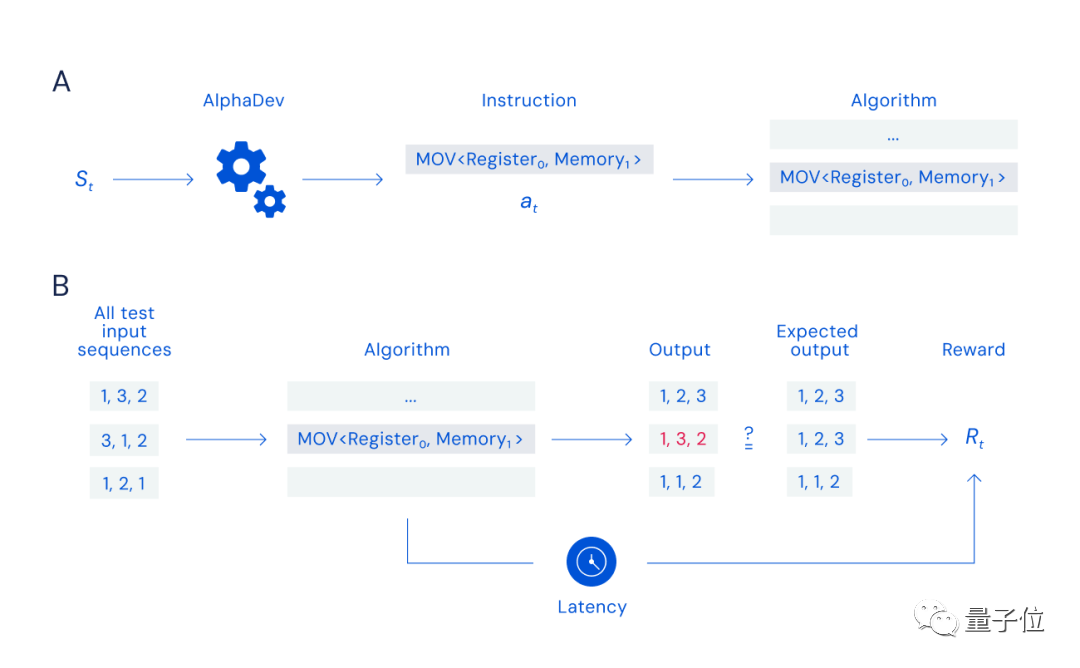
하지만 이 게임의 과제는 검색 공간의 크기(결합 가능한 명령의 수는 우주의 입자 수와 동일)뿐만 아니라 보상의 성격에도 있습니다. 잘못된 명령 하나가 전체 알고리즘을 중단시킬 수 있기 때문입니다.
GPT-4의 "섹시한 작업"에 대해 일부 사람들은 다음과 같이 말했습니다. 고위 개발자조차도 GPT-4를 과소평가합니다.

어떤 사람들은 D 교수의 작업을 통해 인내심을 갖고 신속한 엔지니어링을 이해하는 한 GPT-4가 할 수 있는 일이 여전히 많다는 것을 더욱 입증했다고 한탄했습니다.

어떤 사람들은 훈련 데이터에 알고리즘 정렬의 최적화 방법이 포함되어 있기 때문에 GPT-4가 이것을 할 수 있는지 의문을 제기했습니다.

그래도 이 문제가 그렇게 많은 관심과 논의를 불러일으킨 이유 중 큰 부분은 AlphaDev가 Nature에 포함된 것이 논란의 여지가 있다는 것입니다.
많은 사람들은 이것이 획기적인 연구가 아니며 DeepMind가 과장하고 있다고 생각합니다.

D교수님이 “나도 자연 속에 있을 수 있을까?”라고 말씀하셨을 뿐만 아니라, 10대 때 퀵 정렬을 최적화했고, 논문도 출판해야 한다는 네티즌도 계셨습니다.
물론 AlphaDev 자체의 혁신은 강화 학습을 사용하여 새로운 알고리즘을 발견하는 것이라고 믿는 사람들도 있습니다.

어떻게 생각하시나요?
참조 링크: [1]https://chat.openai.com/share/95693df4-36cd-4241-9cae-2173e8fb760c[2]https://twitter.com/DimitrisPapail/status/1666843952824168465
위 내용은 GPT-4 당황한 DeepMind: 당신은 Nature의 정렬 최적화 알고리즘을 사용했고 두 문단으로 알아냈습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



