

웹상의 얼굴 차단 공격에 대한 실시간 보호(머신러닝 기반)

얼굴 가리는 탄막을 방지하세요. 즉, 다수의 탄막이 떠다니지만, 영상 화면 속 사람들은 사람들 뒤에서 떠다니는 것처럼 보입니다.
머신 러닝은 몇 년 동안 인기가 있었지만 많은 사람들은 이러한 기능이 브라우저에서도 실행될 수 있다는 사실을 모릅니다.
이 기사에서는 기사 마지막 부분에서 몇 가지 시나리오를 소개합니다. 이 솔루션을 적용할 수 있는 곳이 나열되어 있으며 몇 가지 아이디어를 얻을 수 있기를 바랍니다.
mediapipe 데모(https://google.github.io/mediapipe/)는
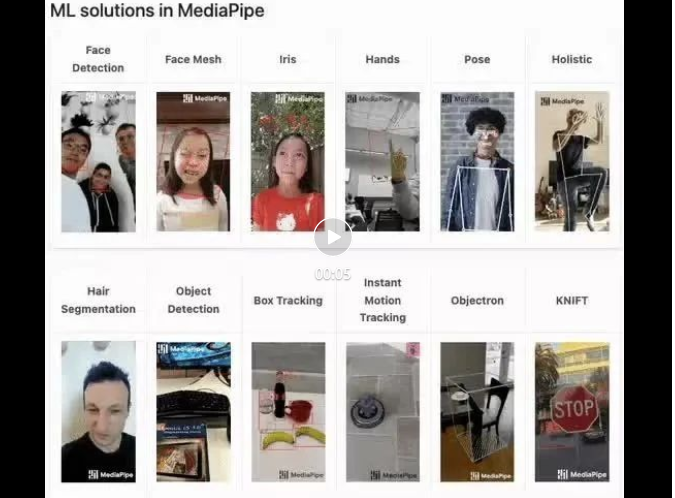
주류 안티 페이스 공세
on-demand
업 업로드 비디오
추출을 위한 서버 백그라운드 계산을 보여줍니다. 비디오 화면의 콘텐츠 세로 영역, svg 저장 공간으로 변환
클라이언트가 비디오를 재생하는 동안 svg가 서버에서 다운로드되어 사격과 결합됩니다. 포격은 세로 영역에 표시되지 않습니다
라이브 방송
- 앵커가 스트림을 푸시하면 실시간으로 화면에서 추출됩니다(앵커 장치) 세로 영역이 svg로 변환됩니다
- svg 데이터를 비디오 스트림(SEI)에 병합하고 스트림을 서버로 푸시합니다
- 클라이언트 동시에 비디오를 재생하고 비디오 스트림(SEI)에서 svg를 구문 분석합니다
- 연발로 svg를 합성하면 세로 영역에는 연발이 표시되지 않습니다
이 기사의 구현 계획
클라이언트가 비디오를 재생하는 동안 , 화면에서 초상화 영역 정보가 실시간으로 추출되어 초상화 영역 정보를 사진으로 내보내어 포격과 결합하며, 초상화 영역에는 포격이 표시되지 않습니다.
구현 원리
- 머신러닝 오픈 소스 라이브러리를 사용하여 신체 분할(https://github.com/tensorflow/tfjs-models/blob/master/body-segmentation)과 같은 영상에서 인물 윤곽선을 실시간으로 추출합니다. /README.md)
- 인물 윤곽선을 그림으로 내보내고 사격 레이어의 마스크 이미지 설정 (https://developer.mozilla.org/zh-CN/docs/Web/CSS/mask-image)
기존(실시간 라이브 방송 SEI) 솔루션과 비교
장점:
- 단 하나의 비디오 태그 매개변수만 필요하며 다중 엔드 조정이 필요하지 않음
- 네트워크 대역폭 소비 없음
단점 :
- 이론적 성능 한계는 기존 솔루션보다 열등합니다. 네트워크 리소스에 대한 성능 리소스와 동일합니다.
문제 발생
JavaScript는 성능이 좋지 않아 CPU 집약적인 작업을 처리하는 데 적합하지 않다는 것이 잘 알려져 있습니다. 공식 데모부터 엔지니어링 실습까지 가장 큰 과제는 성능입니다.
이 연습을 통해 마침내 CPU 사용량이 약 5%(2020 M1 Macbook)로 최적화되어 프로덕션 준비 상태에 도달했습니다.
튜닝 프로세스 연습
기계 학습 모델 선택
BodyPix (https://github.com/tensorflow/tfjs-models/blob/master/body-segmentation/src/body_pix/README.md)
정확도 안타깝지만 얼굴이 너무 좁고 포격의 가장자리와 캐릭터의 얼굴이 명백히 겹칩니다

BlazePose (https://github.com/tensorflow/tfjs-models/blob/master/pose) -Detection/src/ blazepose_mediapipe/README.md)
정확도가 뛰어나고 신체 포인트 정보를 제공하지만 성능이 좋지 않습니다

반환 데이터 구조 예시
[{score: 0.8,keypoints: [{x: 230, y: 220, score: 0.9, score: 0.99, name: "nose"},{x: 212, y: 190, score: 0.8, score: 0.91, name: "left_eye"},...],keypoints3D: [{x: 0.65, y: 0.11, z: 0.05, score: 0.99, name: "nose"},...],segmentation: {maskValueToLabel: (maskValue: number) => { return 'person' },mask: {toCanvasImageSource(): ...toImageData(): ...toTensor(): ...getUnderlyingType(): ...}}}]MediaPipe SelfieSegmentation (https://github.com/tensorflow/tfjs -models/blob/master/body-segmentation/src/selfie_segmentation_mediapipe/README.md)
정확도가 우수하고(BlazePose 모델과 동일) CPU 사용량이 BlazePose 모델보다 약 15% 낮으며 성능도 좋습니다. 림 포인트 정보 제공
반환 데이터 구조 예시
{maskValueToLabel: (maskValue: number) => { return 'person' },mask: {toCanvasImageSource(): ...toImageData(): ...toTensor(): ...getUnderlyingType(): ...}}첫 번째 버전 구현
MediaPipe SelfieSegmentation 모델 공식 구현 참조(https://github.com/tensorflow/tfjs-models/blob) /master/body-segmentation/README.md #bodysegmentationdrawmask), 최적화하지 않으면 CPU가 약 70%를 차지합니다
const canvas = document.createElement('canvas')canvas.width = videoEl.videoWidthcanvas.height = videoEl.videoHeightasync function detect (): Promise<void> {const segmentation = await segmenter.segmentPeople(videoEl)const foregroundColor = { r: 0, g: 0, b: 0, a: 0 }const backgroundColor = { r: 0, g: 0, b: 0, a: 255 } const mask = await toBinaryMask(segmentation, foregroundColor, backgroundColor) await drawMask(canvas, canvas, mask, 1, 9)// 导出Mask图片,需要的是轮廓,图片质量设为最低handler(canvas.toDataURL('image/png', 0)) window.setTimeout(detect, 33)} detect().catch(console.error)추출 빈도를 줄이고 성능-경험의 균형을 맞추세요
일반 영상 30FPS, 연발 마스크를 사용해 보세요(이하 참조) 마스크로) 새로 고침 빈도를 15FPS로 줄이면 경험이 좋습니다. 여전히 허용됩니다
window.setTimeout(detect, 66) // 33 => 66
이때 CPU가 약 50%를 차지합니다
성능 병목 현상을 해결하세요
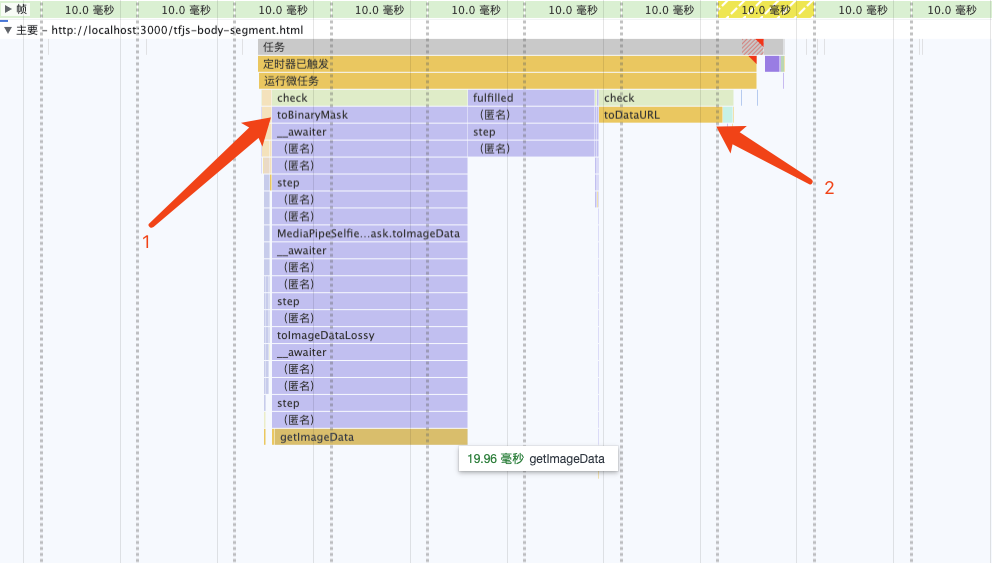
플레임 그래프를 분석해 보면, 성능 병목 현상은 toBinaryMask 및 toDataURL
Rewrite toBinaryMask
소스 코드를 분석하고 분할 정보 인쇄와 결합하여 세그먼트화.mask.toCanvasImageSource에서 추출된 정보인 원본 ImageBitmap 객체를 얻을 수 있음을 발견했습니다. 모델별로. 오픈 소스 라이브러리에서 제공하는 기본 구현을 사용하는 대신 ImageBitmap을 마스크로 변환하는 코드를 직접 작성해 보세요.
구현 원리
async function detect (): Promise<void> {const segmentation = await segmenter.segmentPeople(videoEl) context.clearRect(0, 0, canvas.width, canvas.height)// 1. 将`ImageBitmap`绘制到 Canvas 上context.drawImage(// 经验证 即使出现多人,也只有一个 segmentationawait segmentation[0].mask.toCanvasImageSource(),0, 0,canvas.width, canvas.height)// 2. 设置混合模式context.globalCompositeOperation = 'source-out'// 3. 反向填充黑色context.fillRect(0, 0, canvas.width, canvas.height)// 导出Mask图片,需要的是轮廓,图片质量设为最低handler(canvas.toDataURL('image/png', 0)) window.setTimeout(detect, 66)}2단계와 3단계는 CSS(마스크 이미지)와 협력하기 위해 초상화 영역 외부의 콘텐츠를 검은색으로 채우는 것과 동일합니다(역방향 채우기 ImageBitmap). 그렇지 않으면 사격 시에만 표시됩니다. 초상화 영역에 떠 있습니다(정확히 대상 효과와 반대).
globalCompositeOperation MDN(https://developer.mozilla.org/zh-CN/docs/Web/API/CanvasRenderingContext2D/globalCompositeOperation)
此时,CPU 占用 33% 左右
多线程优化
我原先认为toDataURL是由浏览器内部实现的,无法再进行优化,现在只有优化toDataURL这个耗时操作了。
虽没有替换实现,但可使用 OffscreenCanvas (https://developer.mozilla.org/zh-CN/docs/Web/API/OffscreenCanvas)+ Worker,将耗时任务转移到 Worker 中去, 避免占用主线程,就不会影响用户体验了。
并且ImageBitmap实现了Transferable接口,可被转移所有权,跨 Worker 传递也没有性能损耗(https://hughfenghen.github.io/fe-basic-course/js-concurrent.html#%E4%B8%A4%E4%B8%AA%E6%96%B9%E6%B3%95%E5%AF%B9%E6%AF%94)。
// 前文 detect 的反向填充 ImageBitmap 也可以转移到 Worker 中// 用 OffscreenCanvas 实现, 此处略过 const reader = new FileReaderSync()// OffscreenCanvas 不支持 toDataURL,使用 convertToBlob 代替offsecreenCvsEl.convertToBlob({type: 'image/png',quality: 0}).then((blob) => {const dataURL = reader.readAsDataURL(blob)self.postMessage({msgType: 'mask',val: dataURL})}).catch(console.error)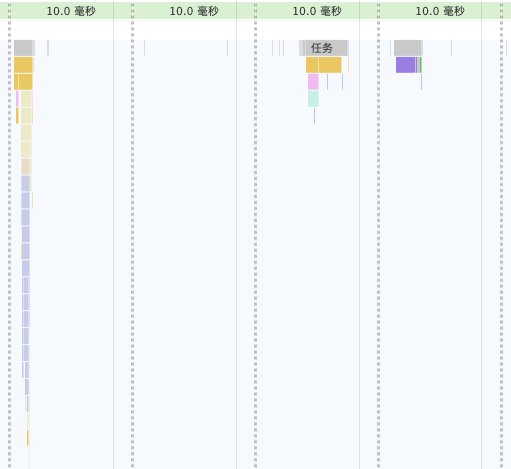
可以看到两个耗时的操作消失了
此时,CPU 占用 15% 左右
降低分辨率
继续分析,上图重新计算样式(紫色部分)耗时约 3ms
Demo 足够简单很容易推测到是这行代码导致的,发现 imgStr 大概 100kb 左右(视频分辨率 1280x720)。
danmakuContainer.style.webkitMaskImage = `url(${imgStr})通过canvas缩小图片尺寸(360P甚至更低),再进行推理。
优化后,导出的 imgStr 大概 12kb,重新计算样式耗时约 0.5ms。
此时,CPU 占用 5% 左右

启动条件优化
虽然提取 Mask 整个过程的 CPU 占用已优化到可喜程度。
当在画面没人的时候,或没有弹幕时候,可以停止计算,实现 0 CPU 占用。
无弹幕判断比较简单(比如 10s 内收超过两条弹幕则启动计算),也不在该 SDK 实现范围,略过
判定画面是否有人
第一步中为了高性能,选择的模型只有ImageBitmap,并没有提供肢体点位信息,所以只能使用getImageData返回的像素点值来判断画面是否有人。
画面无人时,CPU 占用接近 0%
发布构建优化
依赖包的提交较大,构建出的 bundle 体积:684.75 KiB / gzip: 125.83 KiB
所以,可以进行异步加载SDK,提升页面加载性能。
- 分别打包一个 loader,一个主体
- 由业务方 import loader,首次启用时异步加载主体
这个两步前端工程已经非常成熟了,略过细节。
运行效果

总结
过程
- 选择高性能模型后,初始状态 CPU 70%
- 降低 Mask 刷新频率(15FPS),CPU 50%
- 重写开源库实现(toBinaryMask),CPU 33%
- 多线程优化,CPU 15%
- 降低分辨率,CPU 5%
- 判断画面是否有人,无人时 CPU 接近 0%
CPU 数值指主线程占用
注意事项
- 兼容性:Chrome 79及以上,不支持 Firefox、Safari。因为使用了OffscreenCanvas
- 不应创建多个或多次创建segmenter实例(bodySegmentation.createSegmenter),如需复用请保存实例引用,因为:
- 创建实例时低性能设备会有明显的卡顿现象
- 会内存泄露;如果无法避免,这是mediapipe 内存泄露 解决方法(https://github.com/google/mediapipe/issues/2819#issuecomment-1160335349)
经验
- 优化完成之后,提取并应用 Mask 关键计算量在 GPU (30%左右),而不是 CPU
- 性能优化需要业务场景分析,防挡弹幕场景可以使用低分辨率、低刷新率的 mask-image,能大幅减少计算量
- 该方案其他应用场景:
- 替换/模糊人物背景
- 人像马赛克
- 人像抠图
- 卡通头套,虚拟饰品,如猫耳朵、兔耳朵、带花、戴眼镜什么的(换一个模型,略改)
- 关注Web 神经网络 API (https://mp.weixin.qq.com/s/v7-xwYJqOfFDIAvwIVZVdg)进展,以后实现相关功能也许会更简单
本期作者

刘俊
Bilibili 수석 개발 엔지니어
위 내용은 웹상의 얼굴 차단 공격에 대한 실시간 보호(머신러닝 기반)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7488
7488
 15
1377
52
77
11
52
19
19
40
15
1377
52
77
11
52
19
19
40

 CSS를 통해 크기 조정 기호를 사용자 정의하고 배경색으로 균일하게 만드는 방법은 무엇입니까?
Apr 05, 2025 pm 02:30 PM
CSS를 통해 크기 조정 기호를 사용자 정의하고 배경색으로 균일하게 만드는 방법은 무엇입니까?
Apr 05, 2025 pm 02:30 PM
CSS에서 크기 조정 기호를 사용자 정의하는 방법은 배경색으로 통합됩니다. 매일 개발에서, 우리는 종종 조정과 같은 사용자 인터페이스 세부 정보를 사용자 정의 해야하는 상황을 발생시킵니다.
 웹 페이지에 로컬로 설치된 'Jingnan Mai Round Body'를 올바르게 표시하는 방법은 무엇입니까?
Apr 05, 2025 pm 10:33 PM
웹 페이지에 로컬로 설치된 'Jingnan Mai Round Body'를 올바르게 표시하는 방법은 무엇입니까?
Apr 05, 2025 pm 10:33 PM
최근 웹 페이지에 로컬로 설치된 글꼴 파일을 사용하여 인터넷에서 무료 글꼴을 다운로드하여 시스템에 성공적으로 설치했습니다. 지금...
 플렉스 레이아웃 아래의 텍스트는 생략되지만 컨테이너가 열려 있습니까? 그것을 해결하는 방법?
Apr 05, 2025 pm 11:00 PM
플렉스 레이아웃 아래의 텍스트는 생략되지만 컨테이너가 열려 있습니까? 그것을 해결하는 방법?
Apr 05, 2025 pm 11:00 PM
Flex 레이아웃 및 솔루션에서 텍스트를 과도하게 누락하여 컨테이너 개구부 문제가 사용됩니다 ...
 Edge 브라우저의 특정 DIV 요소가 표시되지 않는 이유는 무엇입니까? 이 문제를 해결하는 방법?
Apr 05, 2025 pm 08:21 PM
Edge 브라우저의 특정 DIV 요소가 표시되지 않는 이유는 무엇입니까? 이 문제를 해결하는 방법?
Apr 05, 2025 pm 08:21 PM
사용자 에이전트 스타일 시트로 인한 디스플레이 문제를 해결하는 방법은 무엇입니까? 에지 브라우저를 사용하는 경우 프로젝트의 DIV 요소를 표시 할 수 없습니다. 확인 후 게시했습니다 ...
 JavaScript 또는 CSS를 통해 브라우저 인쇄 설정에서 페이지 상단 및 끝을 제어하는 방법은 무엇입니까?
Apr 05, 2025 pm 10:39 PM
JavaScript 또는 CSS를 통해 브라우저 인쇄 설정에서 페이지 상단 및 끝을 제어하는 방법은 무엇입니까?
Apr 05, 2025 pm 10:39 PM
브라우저의 인쇄 설정에서 페이지의 상단과 끝을 제어하기 위해 JavaScript 또는 CSS를 사용하는 방법. 브라우저의 인쇄 설정에는 디스플레이가 ...인지 제어 할 수있는 옵션이 있습니다.
 Safari의 로컬 웹 페이지에서 맞춤형 스타일 시트가 적용되지만 Baidu 페이지에서는 그렇지 않은 이유는 무엇입니까?
Apr 05, 2025 pm 05:15 PM
Safari의 로컬 웹 페이지에서 맞춤형 스타일 시트가 적용되지만 Baidu 페이지에서는 그렇지 않은 이유는 무엇입니까?
Apr 05, 2025 pm 05:15 PM
Safari에서 사용자 정의 스타일 시트 사용에 대한 토론 오늘 우리는 Safari 브라우저에 대한 사용자 정의 스타일 시트 적용에 대한 질문에 대해 논의 할 것입니다. 프론트 엔드 초보자 ...
 부정적인 마진이 어떤 경우에는 적용되지 않는 이유는 무엇입니까? 이 문제를 해결하는 방법?
Apr 05, 2025 pm 10:18 PM
부정적인 마진이 어떤 경우에는 적용되지 않는 이유는 무엇입니까? 이 문제를 해결하는 방법?
Apr 05, 2025 pm 10:18 PM
어떤 경우에는 부정적인 마진이 적용되지 않는 이유는 무엇입니까? 프로그래밍 중에 CSS의 부정적인 마진 (음수 ...
 웹 페이지에서 로컬로 설치된 글꼴 파일을 사용하는 방법은 무엇입니까?
Apr 05, 2025 pm 10:57 PM
웹 페이지에서 로컬로 설치된 글꼴 파일을 사용하는 방법은 무엇입니까?
Apr 05, 2025 pm 10:57 PM
웹 페이지에서 로컬로 설치된 글꼴 파일을 사용하는 방법 웹 페이지 개발 에서이 상황이 발생 했습니까? 컴퓨터에 글꼴을 설치했습니다 ...
