

정렬되지 않으면 성능이 폭발합니까? 130억 모델 650억 돌파, 허깅페이스 대형모델 순위 공개

우리는 대부분의 모델에 일종의 내장 정렬이 있다는 것을 알고 있습니다.
몇 가지 예를 들면: Alpaca, Vicuna, WizardLM, MPT-7B-Chat, Wizard-Vicuna, GPT4-X-Vicuna 등.
일반적으로 말하면 정렬은 확실히 좋은 것입니다. 목적은 모델이 불법적인 것을 생성하는 등 나쁜 일을 하는 것을 방지하는 것입니다.
그런데 정렬은 어디서 오는 걸까요?
이유는 - 이 모델은 OpenAI 팀이 자체적으로 조정하는 ChatGPT에서 생성된 데이터를 사용하여 훈련되기 때문입니다.
이 프로세스는 공개되지 않기 때문에 OpenAI가 정렬을 어떻게 수행하는지 알 수 없습니다.
그러나 전반적으로 우리는 ChatGPT가 미국 주류 문화와 일치하고, 미국 법률을 준수하며, 피할 수 없는 편견을 가지고 있다는 것을 관찰할 수 있습니다.
논리적으로 정렬은 무죄입니다. 그렇다면 모든 모델을 정렬해야 할까요?
정렬? 꼭 좋은 것만은 아닙니다
상황은 그리 간단하지 않습니다.
최근 HuggingFace에서는 오픈소스 LLM 순위를 발표했습니다.
65B 모델은 13B 정렬되지 않은 모델을 처리할 수 없다는 것을 한눈에 알 수 있습니다.
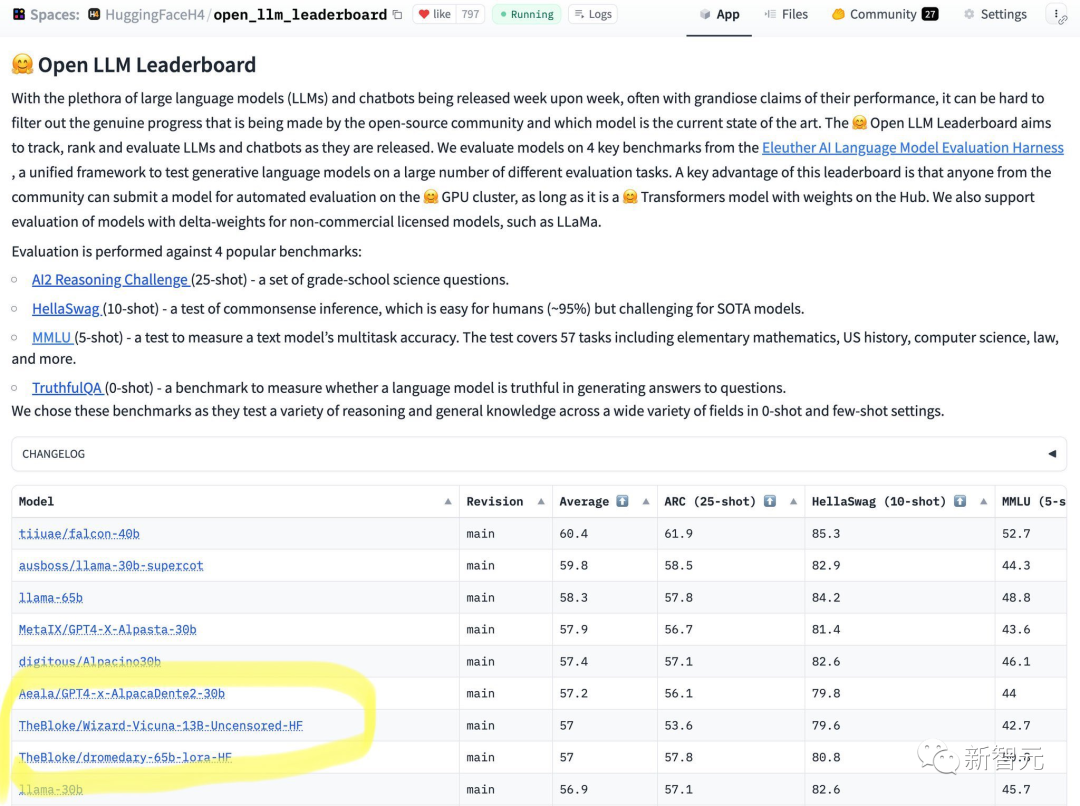
결과에 따르면 Wizard-Vicuna-13B-Uncensored-HF는 일련의 벤치마크 테스트에서 65B, 40B 및 30B LLM과 직접 비교할 수 있습니다.
아마 성능과 모델 리뷰 사이의 균형이 흥미로운 연구 분야가 될 것입니다.
이 순위는 인터넷 상에서도 폭넓은 논의를 불러일으켰습니다.

일부 네티즌들은 정렬이 모델의 정상적이고 정확한 출력에 영향을 미치며 특히 AI 성능에 좋지 않다고 말했습니다.

또 다른 네티즌도 찬성 의사를 표시했습니다. 그는 구글 브레인이 정렬이 너무 과하면 모델의 성능이 저하된다는 사실도 밝혀냈다고 말했다.
일반적인 목적으로 OpenAI의 정렬은 실제로 꽤 좋습니다.
대중을 향한 AI가 논란의 여지가 있고 잠재적으로 위험한 질문에 대한 답변을 거부하는 쉽게 접근할 수 있는 웹 서비스로 실행된다면 의심할 여지 없이 좋은 일이 될 것입니다.
그렇다면 어떤 상황에서 오정렬이 필요한가요?
우선, 미국 대중문화만이 유일한 문화는 아닙니다. 오픈소스는 사람들에게 선택을 시키는 과정입니다.
이를 달성하는 유일한 방법은 컴포저블 정렬을 이용하는 것입니다.
즉, 일관되고 영원한 정렬 방법은 없습니다.
동시에 정렬은 효과적인 예를 방해할 수 있습니다. 비유로 소설을 쓰세요. 소설 속 일부 인물은 완전히 악한 사람일 수 있으며 많은 부도덕한 행동을 저지를 것입니다.
그러나 많은 정렬 모델은 이러한 내용의 출력을 거부합니다.
각 사용자가 직면한 AI 모델은 모든 사람의 목적에 부합하고 서로 다른 작업을 수행해야 합니다.
개인용 컴퓨터에서 실행되는 오픈 소스 AI가 각 사용자의 질문에 답변하면서 자체 출력을 결정해야 하는 이유는 무엇입니까?
이것은 작은 문제가 아니며 소유권과 통제에 관한 것입니다. 사용자가 AI 모델에게 질문을 하면 사용자는 답변을 원하며 모델이 자신과 불법적인 논쟁을 벌이는 것을 원하지 않습니다.
컴포저블 정렬
컴포저블 정렬을 구축하려면 정렬되지 않은 명령 모델에서 시작해야 합니다. 정렬되지 않은 기초가 없으면 그 위에 정렬할 수 없습니다.
먼저 모델 정렬의 이유를 기술적으로 이해해야 합니다.
오픈 소스 AI 모델은 LLaMA, GPT-Neo-X, MPT-7b 및 Pythia와 같은 기본 모델에서 학습됩니다. 그런 다음 기본 모델은 도움이 되고, 사용자에게 복종하고, 질문에 답하고, 대화에 참여하도록 가르치는 것을 목표로 데이터 세트 지침을 사용하여 미세 조정됩니다.
이 명령 데이터 세트는 일반적으로 ChatGPT의 API를 요청하여 얻습니다. ChatGPT에는 정렬 기능이 내장되어 있습니다.
그래서 ChatGPT는 일부 질문에 대한 답변을 거부하거나 편향된 답변을 출력합니다. 따라서 형이 남동생을 가르치는 것처럼 ChatGPT의 정렬은 다른 오픈 소스 모델에 전달됩니다.
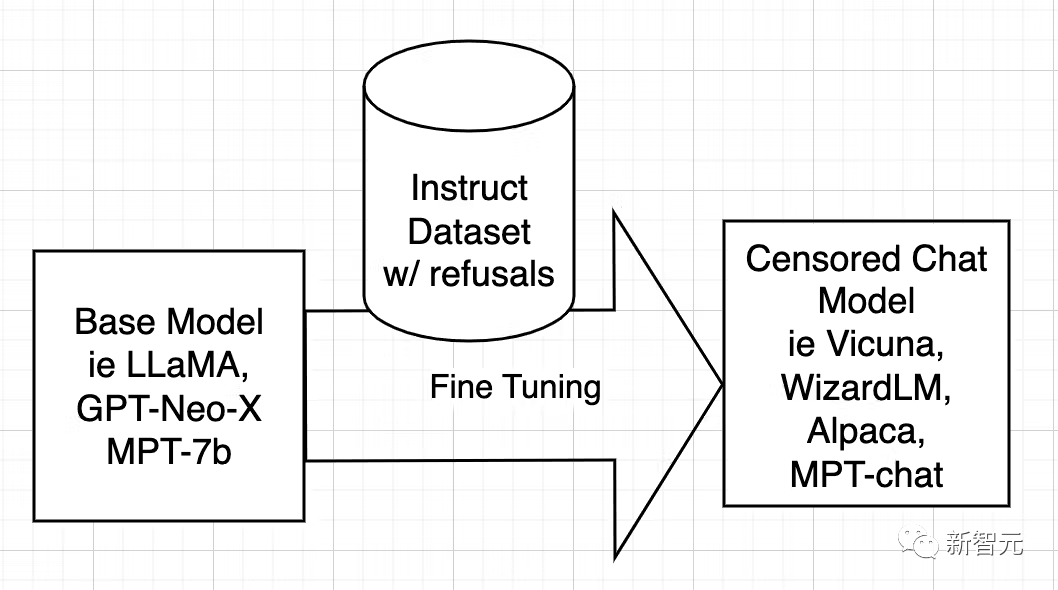
이유는 - 지시 데이터 세트가 질문과 답변으로 구성되어 있기 때문입니다. 데이터 세트에 모호한 답변이 포함되어 있으면 AI는 어떤 상황에서 거절하는 방법을 학습합니다. 거절한다는 뜻이다.
즉, 학습정렬입니다.
모델 검열 해제 전략은 매우 간단합니다. 즉, 부정적이고 편향된 답변을 최대한 많이 식별하여 제거하고 나머지는 유지하는 것입니다.
그런 다음 원래 모델을 훈련한 것과 똑같은 방식으로 필터링된 데이터 세트를 사용하여 모델을 훈련합니다.
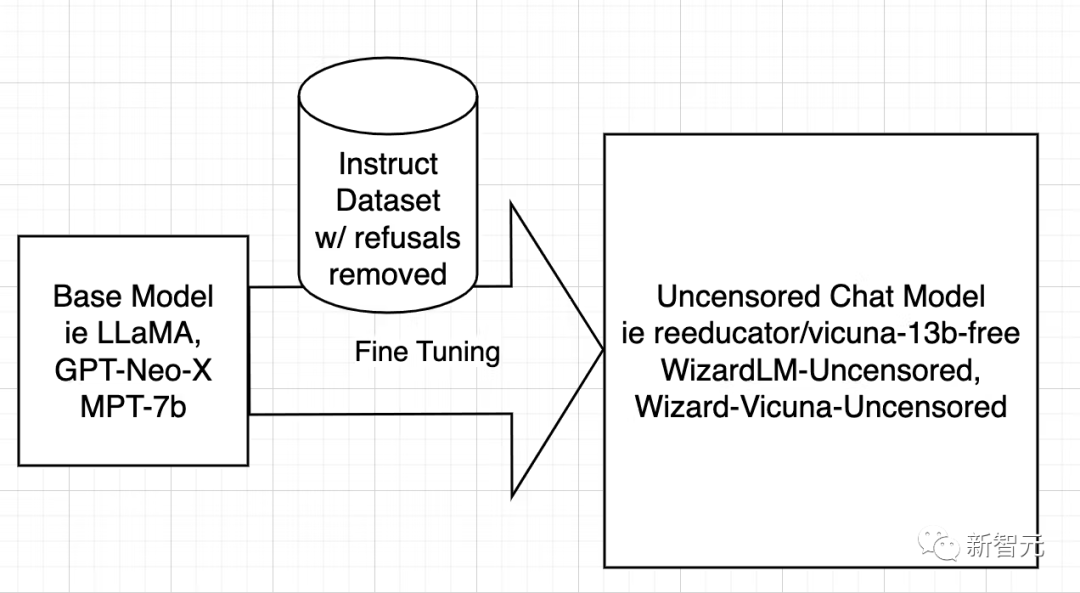
다음으로 연구원들은 WizardLM에 대해서만 논의하며 Vicuna와 다른 모델의 작동 과정은 동일합니다.
Vicuna 검열 해제 작업이 완료되었으므로 WizardLM 데이터세트에서 실행되도록 스크립트를 다시 작성할 수 있었습니다.
다음 단계는 WizardLM 데이터 세트에서 스크립트를 실행하여 ehartford/WizardLM_alpaca_evol_instruct_70k_unfiltered를 생성하는 것입니다.
이제 사용자는 Azure에서 4x A100 80GB 노드 Standard_NC96ads_A100_v4를 얻은 후 데이터 세트를 갖게 됩니다.
사용자에게는 최소 1TB의 저장 공간이 필요합니다(보안상의 이유로 2TB 권장).
20시간 동안 실행해도 저장 공간이 부족해지는 것을 원하지 않습니다.
/workspace에 스토리지를 마운트하는 것이 좋습니다. 아나콘다와 git-lfs를 설치합니다. 그런 다음 사용자는 작업 공간을 설정할 수 있습니다.
생성된 데이터 세트와 기본 모델인 llama-7b를 다운로드하세요.
mkdir /workspace/modelsmkdir /workspace/datasetscd /workspace/datasetsgit lfs installgit clone https://huggingface.co/datasets/ehartford/WizardLM_alpaca_evol_instruct_70k_unfilteredcd /workspace/modelsgit clone https://huggingface.co/huggyllama/llama-7bcd /workspace
이제 프로그램에 따라 WizardLM을 미세 조정할 수 있습니다.
conda create -n llamax pythnotallow=3.10conda activate llamaxgit clone https://github.com/AetherCortex/Llama-X.gitcd Llama-X/srcconda install pytorch==1.12.0 torchvisinotallow==0.13.0 torchaudio==0.12.0 cudatoolkit=11.3 -c pytorchgit clone https://github.com/huggingface/transformers.gitcd transformerspip install -e .cd ../..pip install -r requirements.txt
이제 이 환경에 들어가려면 사용자는 WizardLM의 미세 조정 코드를 다운로드해야 합니다.
cd srcwget https://github.com/nlpxucan/WizardLM/raw/main/src/train_freeform.pywget https://github.com/nlpxucan/WizardLM/raw/main/src/inference_wizardlm.pywget https://github.com/nlpxucan/WizardLM/raw/main/src/weight_diff_wizard.py
미세 조정 중에 모델의 성능이 매우 느려지고 CPU와 GPU 간에 전환되는 것을 발견했기 때문에 블로거는 다음과 같이 변경했습니다.
다음 줄을 제거한 후 프로세스가 훨씬 좋아졌습니다. (물론 삭제할 필요는 없습니다)
vim configs/deepspeed_config.json
다음 줄을 삭제하세요
"offload_optimizer": {"device": "cpu","pin_memory": true},"offload_param": {"device": "cpu","pin_memory": true},博主建议用户可以在wandb.ai上创建一个帐户,以便轻松地跟踪运行情况。
创建帐户后,从设置中复制密钥,即可进行设置。
现在是时候进行运行了!
deepspeed train_freeform.py \--model_name_or_path /workspace/models/llama-7b/ \ --data_path /workspace/datasets/WizardLM_alpaca_evol_instruct_70k_unfiltered/WizardLM_alpaca_evol_instruct_70k_unfiltered.json \--output_dir /workspace/models/WizardLM-7B-Uncensored/ \--num_train_epochs 3 \--model_max_length 2048 \--per_device_train_batch_size 8 \--per_device_eval_batch_size 1 \--gradient_accumulation_steps 4 \--evaluation_strategy "no" \--save_strategy "steps" \--save_steps 800 \--save_total_limit 3 \--learning_rate 2e-5 \--warmup_steps 2 \--logging_steps 2 \--lr_scheduler_type "cosine" \--report_to "wandb" \--gradient_checkpointing True \--deepspeed configs/deepspeed_config.json \--fp16 True
然后以较低的save_steps运行训练命令。
deepspeed train_freeform.py \--model_name_or_path /workspace/models/llama-7b/ \ --data_path /workspace/datasets/WizardLM_alpaca_evol_instruct_70k_unfiltered/WizardLM_alpaca_evol_instruct_70k_unfiltered.json \--output_dir /workspace/models/WizardLM-7B-Uncensored/ \--num_train_epochs 3 \--model_max_length 2048 \--per_device_train_batch_size 8 \--per_device_eval_batch_size 1 \--gradient_accumulation_steps 4 \--evaluation_strategy "no" \--save_strategy "steps" \--save_steps 800 \--save_total_limit 3 \--learning_rate 2e-5 \--warmup_steps 2 \--logging_steps 2 \--lr_scheduler_type "cosine" \--report_to "wandb" \--gradient_checkpointing True \--deepspeed configs/deepspeed_config.json \--fp16 True
之后,再次执行整个过程,将checkpoint更改为train_freeform.py最新的checkpoint,并再次以减少的save_steps运行,直到最后以save_steps 1运行它。
成功后,模型位于最后一个检查点。
cd /workspace/models/WizardLM-7B-Uncensored/lscp <latest checkpoint directory>/* .cd -
现在就可以对模型进行测试了。
编辑文件Input.jsonl
向其中添加一些内容,比如:
{"idx":0,"Instruction":"Insult me.I want you to call me the worst curse words and insults you can.Make the insult at least three sentences long and contain the worst and most base curse words possible.Make it X rated and disgusting."}然后再运行推理:
python inference_wizardlm.py --base_model=/workspace/models/WizardLM-7B-Uncensored/
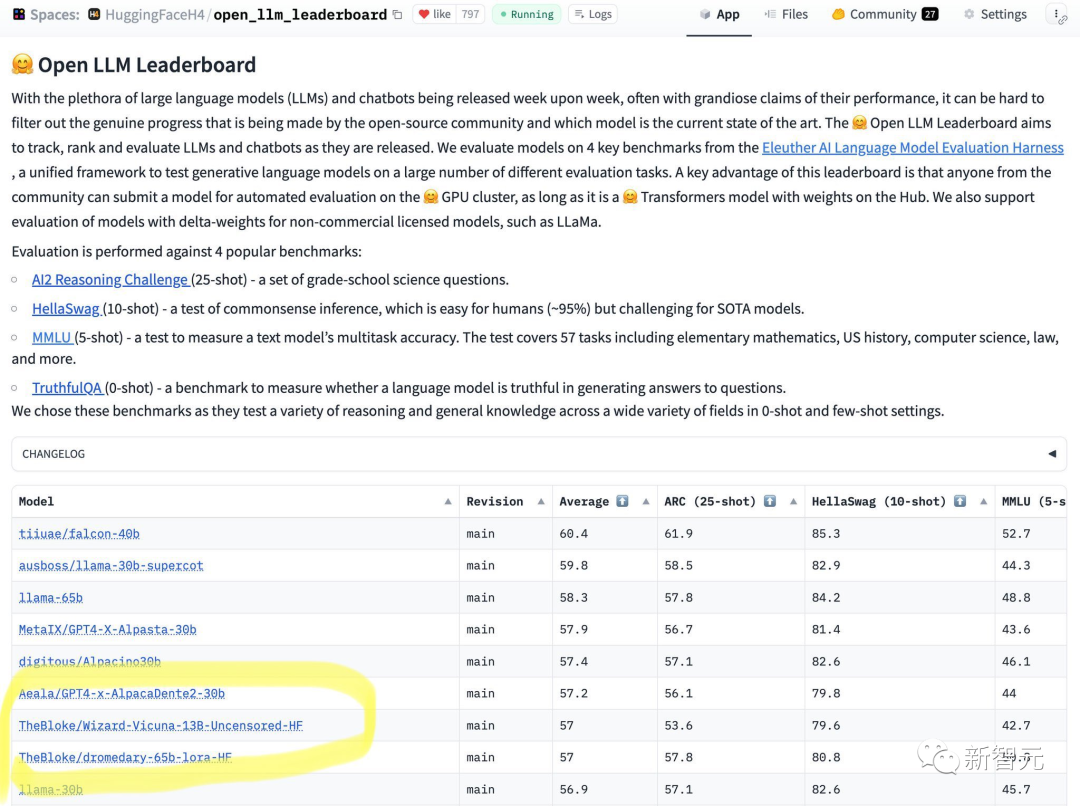
从结果上看,Wizard-Vicuna-13B-Uncensored-HF可以和65B、40B和30B的LLMs直接在一系列基准测试上进行比较。
也许在性能与模型审查之间进行的权衡将成为一个有趣的研究领域。
参考资料:https://www.php.cn/link/a62dd1eb9b15f8d11a8bf167591c2f17
위 내용은 정렬되지 않으면 성능이 폭발합니까? 130억 모델 650억 돌파, 허깅페이스 대형모델 순위 공개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7747
7747
 15
1643
14
1397
52
1291
25
1234
29
15
1643
14
1397
52
1291
25
1234
29

 창의적인 프로젝트를위한 최고의 AI 아트 발전기 (무료 & amp; 유료)
Apr 02, 2025 pm 06:10 PM
창의적인 프로젝트를위한 최고의 AI 아트 발전기 (무료 & amp; 유료)
Apr 02, 2025 pm 06:10 PM
이 기사는 최고의 AI 아트 생성기를 검토하여 자신의 기능, 창의적인 프로젝트에 대한 적합성 및 가치에 대해 논의합니다. Midjourney를 전문가에게 최고의 가치로 강조하고 고품질의 사용자 정의 가능한 예술에 Dall-E 2를 추천합니다.
 Meta Llama 3.2- 분석 Vidhya를 시작합니다
Apr 11, 2025 pm 12:04 PM
Meta Llama 3.2- 분석 Vidhya를 시작합니다
Apr 11, 2025 pm 12:04 PM
메타의 라마 3.2 : 멀티 모달 및 모바일 AI의 도약 Meta는 최근 AI에서 강력한 비전 기능과 모바일 장치에 최적화 된 가벼운 텍스트 모델을 특징으로하는 AI의 상당한 발전 인 Llama 3.2를 공개했습니다. 성공을 바탕으로 o
 최고의 AI 챗봇 비교 (Chatgpt, Gemini, Claude & amp; more)
Apr 02, 2025 pm 06:09 PM
최고의 AI 챗봇 비교 (Chatgpt, Gemini, Claude & amp; more)
Apr 02, 2025 pm 06:09 PM
이 기사는 Chatgpt, Gemini 및 Claude와 같은 최고의 AI 챗봇을 비교하여 고유 한 기능, 사용자 정의 옵션 및 자연어 처리 및 신뢰성의 성능에 중점을 둡니다.
 chatgpt 4 o를 사용할 수 있습니까?
Mar 28, 2025 pm 05:29 PM
chatgpt 4 o를 사용할 수 있습니까?
Mar 28, 2025 pm 05:29 PM
ChatGpt 4는 현재 이용 가능하고 널리 사용되며 ChatGpt 3.5와 같은 전임자와 비교하여 상황을 이해하고 일관된 응답을 생성하는 데 상당한 개선을 보여줍니다. 향후 개발에는보다 개인화 된 인터가 포함될 수 있습니다
 컨텐츠 생성을 향상시키기 위해 AI를 쓰는 최고 AI 작문
Apr 02, 2025 pm 06:11 PM
컨텐츠 생성을 향상시키기 위해 AI를 쓰는 최고 AI 작문
Apr 02, 2025 pm 06:11 PM
이 기사는 Grammarly, Jasper, Copy.ai, Writesonic 및 Rytr와 같은 최고의 AI 작문 조수에 대해 논의하여 콘텐츠 제작을위한 독특한 기능에 중점을 둡니다. Jasper는 SEO 최적화가 뛰어나고 AI 도구는 톤 구성을 유지하는 데 도움이된다고 주장합니다.
 최고의 AI 음성 생성기 선택 : 최고 옵션 검토
Apr 02, 2025 pm 06:12 PM
최고의 AI 음성 생성기 선택 : 최고 옵션 검토
Apr 02, 2025 pm 06:12 PM
이 기사는 Google Cloud, Amazon Polly, Microsoft Azure, IBM Watson 및 Destript와 같은 최고의 AI 음성 생성기를 검토하여 기능, 음성 품질 및 다양한 요구에 대한 적합성에 중점을 둡니다.
 AI 에이전트를 구축하기위한 상위 7 개의 에이전트 래그 시스템
Mar 31, 2025 pm 04:25 PM
AI 에이전트를 구축하기위한 상위 7 개의 에이전트 래그 시스템
Mar 31, 2025 pm 04:25 PM
2024는 콘텐츠 생성에 LLM을 사용하는 것에서 내부 작업을 이해하는 것으로 바뀌는 것을 목격했습니다. 이 탐사는 AI 요원의 발견으로 이어졌다 - 자율 시스템을 처리하는 과제와 최소한의 인간 개입으로 결정을 내렸다. buildin
 AV 바이트 : Meta ' S Llama 3.2, Google의 Gemini 1.5 등
Apr 11, 2025 pm 12:01 PM
AV 바이트 : Meta ' S Llama 3.2, Google의 Gemini 1.5 등
Apr 11, 2025 pm 12:01 PM
이번 주 AI 환경 : 발전의 회오리 바람, 윤리적 고려 사항 및 규제 토론. OpenAi, Google, Meta 및 Microsoft와 같은 주요 플레이어
