

75세 힌튼의 최근 중국 회의 연설인 '지능으로 가는 두 가지 길'은 감동으로 끝났습니다. 나는 이미 늙었고 미래는 젊은이들에게 달려 있습니다.

"하지만 나도 늙어가고 있고, 내가 원하는 것은 당신과 같은 젊고 유망한 연구자들이 어떻게 우리가 이러한 초지능을 갖고 그들에 의해 통제되지 않고 우리의 삶을 더 좋게 만들 수 있는지 알아내는 것입니다. ”
6월 75세의 튜링상 수상자 제프리 힌튼(Geoffrey Hinton)은 지난 10일 2023년 베이징 지능형 소스 컨퍼런스 폐막 연설에서 초지능이 인간을 속이고 통제하는 것을 방지하는 방법에 대해 말없이 감동적인 말을 했습니다.
Hinton의 연설 제목은 "지능으로 가는 두 가지 경로"입니다. 즉, 디지털 형식으로 수행되는 불멸의 컴퓨팅과 하드웨어에 의존하는 불멸의 컴퓨팅이 대표적입니다. 연설 말미에는 거대 언어 모델(LLM)이 자신에게 가져온 초지능의 위협에 대한 우려를 집중적으로 언급하며, 인류 문명의 미래와 관련된 주제에 대해 그는 매우 직설적으로 비관적인 태도를 드러냈다.
연설 시작 부분에서 Hinton은 초지능이 자신이 생각했던 것보다 훨씬 일찍 탄생할 수 있다고 주장했습니다. 이러한 관찰은 두 가지 주요 질문을 제기합니다. (1) 인공 신경망의 지능 수준이 곧 실제 신경망의 지능 수준을 넘어설 것인가? (2) 인간이 슈퍼 AI의 통제를 보장할 수 있는가? 회의 연설에서 그는 두 번째 질문에 관해 첫 번째 질문에 대해 자세히 논의했다고 Hinton은 연설 마지막 부분에서 다음과 같이 말했습니다. 초지능(Superintelligence)이 곧 도래할 수도 있습니다.

먼저 전통적인 계산 방법을 살펴보겠습니다. 컴퓨터의 설계 원리는 명령을 정확하게 실행할 수 있어야 한다는 것입니다. 즉, 동일한 프로그램(신경망이든 아니든)을 다른 하드웨어에서 실행하더라도 효과는 동일해야 한다는 의미입니다. 이는 프로그램에 포함된 지식(예: 신경망의 가중치)이 불멸이며 특정 하드웨어와 관련이 없음을 의미합니다.

지식의 불멸성을 달성하기 위해 우리의 접근 방식은 트랜지스터를 고전력에서 실행하여 디지털 방식으로 안정적으로 작동할 수 있도록 하는 것입니다. 그러나 그렇게 하는 것은 풍부한 아날로그와 높은 가변성과 같은 하드웨어의 다른 속성을 포기하는 것과 같습니다.

전통적인 컴퓨터가 그 디자인 모델을 채택하는 이유는 전통적인 컴퓨팅이 실행하는 프로그램이 모두 인간이 작성한 것이기 때문입니다. 이제 기계 학습 기술의 발전으로 컴퓨터는 프로그램 및 작업 목표를 달성하는 또 다른 방법인 샘플 기반 학습을 갖게 되었습니다.
이 새로운 패러다임을 통해 우리는 이전 컴퓨터 시스템 설계의 가장 기본 원칙 중 하나, 즉 소프트웨어 설계와 하드웨어의 분리를 버리고 대신 소프트웨어와 하드웨어를 공동 설계할 수 있습니다.
소프트웨어와 하드웨어 분리 설계의 장점은 동일한 프로그램이 다양한 하드웨어에서 실행될 수 있다는 것과 동시에 프로그램을 설계할 때 하드웨어에 관계없이 소프트웨어만 볼 수 있다는 것입니다. 컴퓨터공학과와 전자공학과를 분리할 수 있다. 설립 이유.
소프트웨어와 하드웨어 공동 설계를 위해 Hinton은 Mortal Computation이라는 새로운 개념을 제안했습니다. 앞서 언급한 불멸의 소프트웨어 형태에 해당하며 여기서는 이를 "불멸의 컴퓨팅"으로 번역합니다.
필멸 계산이란 무엇인가요?

Perishable Computing은 동일한 소프트웨어를 다른 하드웨어에서 실행하는 불멸성을 포기하고 대신 새로운 설계 아이디어를 채택합니다. 지식은 하드웨어의 특정 물리적 세부 사항과 분리될 수 없습니다. 이 새로운 아이디어에는 당연히 장점과 단점이 있습니다. 주요 이점은 에너지 절약과 낮은 하드웨어 비용입니다.
에너지 절약이라는 측면에서 인간의 두뇌는 대표적인 인간의 컴퓨팅 장치입니다. 인간의 두뇌에는 여전히 1비트 디지털 계산, 즉 뉴런이 발사되거나 발사되지 않지만 전체적으로 인간 두뇌의 계산의 대부분은 전력 소비가 매우 낮은 아날로그 계산입니다.
파괴 가능한 컴퓨팅은 더 저렴한 하드웨어를 사용할 수도 있습니다. 2차원 모델로 고정밀도로 생산되는 오늘날의 프로세서와 비교하면, 불멸의 컴퓨팅 하드웨어는 하드웨어가 어떻게 연결되어 있는지, 정확한 경로를 알 필요가 없기 때문에 3차원 모델로 '성장'할 수 있다. 각 구성 요소의 기능. 컴퓨팅 하드웨어를 "성장"시키기 위해서는 많은 새로운 나노기술이나 생물학적 뉴런을 유전적으로 변형하는 능력이 필요할 것이라는 점은 분명합니다. 생물학적 뉴런을 조작하는 방법은 생물학적 뉴런이 우리가 원하는 것을 대략적으로 수행할 수 있다는 것을 이미 알고 있기 때문에 구현하기가 더 쉬울 수 있습니다.
시뮬레이션 계산의 효율적인 능력을 보여주기 위해 Hinton은 신경 활동 벡터와 가중치 행렬의 곱을 계산하는 예를 제시했습니다(신경망 작업의 대부분은 이러한 계산입니다).

이 작업을 위해 현재 컴퓨터 접근 방식은 고전력 트랜지스터를 사용하여 값을 디지털 비트 형식으로 표현한 다음 O(n²) 디지털 연산을 수행하여 두 n- 비트 값을 곱합니다. 이는 컴퓨터에서의 단일 작업이지만 n² 비트 작업입니다.
그리고 시뮬레이션 계산을 사용하면 어떨까요? 신경 활동을 전압으로, 무게를 컨덕턴스로 생각할 수 있습니다. 그러면 각 단위 시간에 컨덕턴스를 곱한 전압이 전하를 얻을 수 있고 전하가 중첩될 수 있습니다. 이러한 작업 방식의 에너지 효율성은 훨씬 높을 것이며 실제로 이러한 방식으로 작동하는 칩은 이미 존재합니다. 불행하게도 사람들은 아날로그 결과를 디지털 형식으로 변환하기 위해 여전히 매우 값비싼 변환기를 사용해야 한다고 Hinton은 말했습니다. 그는 앞으로 우리가 시뮬레이션 분야에서 전체 계산 과정을 완료할 수 있기를 바라고 있습니다.
파괴 가능한 컴퓨팅에도 몇 가지 문제가 있습니다. 그 중 가장 중요한 것은 결과의 일관성을 보장하기 어렵다는 것입니다. 즉, 하드웨어마다 계산 결과가 다를 수 있습니다. 또한 역전파를 사용할 수 없는 경우에는 새로운 방법을 찾아야 합니다.
손상 가능한 컴퓨팅이 직면한 문제: 역전파를 사용할 수 없음
특정 하드웨어에서 손상 가능한 컴퓨팅을 수행하는 방법을 학습할 때 프로그램은 해당 하드웨어의 특정 시뮬레이션 속성을 활용하는 방법을 배워야 하지만 그럴 필요는 없습니다. 이러한 속성이 무엇인지 알아보세요. 예를 들어, 뉴런이 내부적으로 어떻게 연결되어 있는지, 어떤 기능이 뉴런의 입력과 출력을 연결하는지 알 필요가 없습니다.

역전파에는 정확한 순전파 모델이 필요하기 때문에 역전파 알고리즘을 사용하여 기울기를 얻을 수 없음을 의미합니다.
역전파는 붕괴 가능한 계산에 사용할 수 없으므로 어떻게 해야 할까요? 가중치 섭동이라는 방법을 사용하여 시뮬레이션된 하드웨어에서 수행되는 간단한 학습 프로세스를 살펴보겠습니다.

먼저, 네트워크의 각 가중치에 대한 작은 무작위 섭동으로 구성된 무작위 벡터를 생성합니다. 그런 다음 하나 또는 소수의 샘플을 기반으로 이 섭동 벡터를 사용한 후 전역 목적 함수의 변화를 측정합니다. 마지막으로 목적함수의 개선에 따라 외란 벡터에 의한 효과는 가중치에 영구적으로 비례하게 됩니다.
이 알고리즘의 장점은 일반적인 동작 패턴이 역전파와 일치하고 기울기도 따른다는 것입니다. 하지만 문제는 편차가 매우 크다는 것입니다. 따라서 네트워크 크기가 증가하면 가중치 공간에서 임의의 이동 방향을 선택할 때 생성되는 노이즈가 커져 이 방법을 지속할 수 없게 됩니다. 이는 이 방법이 소규모 네트워크에만 적합하고 대규모 네트워크에는 적합하지 않음을 의미합니다.

또 다른 접근 방식은 비슷한 문제가 있지만 대규모 네트워크에 더 잘 작동하는 활동 교란입니다.

활동 교란 방법은 무작위 벡터를 사용하여 각 뉴런의 전체 입력을 교란한 다음 작은 배치 샘플에서 목적 함수의 변화를 관찰한 다음 어떻게 변화하는지 계산하는 것입니다. 그래디언트를 따르도록 요소의 뉴런 가중치를 변경합니다.
활동 교란은 체중 교란에 비해 소음이 훨씬 적습니다. 그리고 이 방법은 MNIST와 같은 간단한 작업을 배우기에 충분합니다. 매우 작은 학습률을 사용하면 역전파와 똑같이 동작하지만 훨씬 느려집니다. 학습률이 크면 노이즈가 많이 발생하지만 MNIST와 같은 작업을 처리하기에는 충분합니다.
하지만 네트워크 규모가 더 커지면 어떻게 될까요? Hinton은 두 가지 접근 방식을 언급했습니다.
첫 번째 방법은 수많은 목적 함수를 사용하는 것입니다. 즉, 대규모 신경망의 목표를 정의하기 위해 단일 함수를 사용하는 대신 다양한 함수의 로컬 목표를 정의하는 데 많은 함수를 사용한다는 의미입니다. 네트워크의 뉴런 그룹.

이러한 방식으로 대규모 신경망은 여러 부분으로 나누어지고 활동 교란을 사용하여 작은 다층 신경망을 학습할 수 있습니다. 하지만 여기서 질문이 생깁니다. 이러한 목적 함수는 어디서 오는 걸까요?

한 가지 가능성은 다양한 수준의 로컬 패치에 대해 비지도 대조 학습을 사용하는 것입니다. 이는 다음과 같이 작동합니다. 로컬 패치에는 여러 표현 수준이 있으며, 각 수준에서 로컬 패치는 동일한 이미지의 다른 모든 로컬 패치에서 생성된 평균 표현과 동시에 일관성을 유지하려고 시도합니다. 해당 수준의 다른 이미지 표현과 구별됩니다.
Hinton은 이 방법이 실제로 잘 작동한다고 말합니다. 일반적인 접근 방식은 비선형 작업을 수행할 수 있도록 각 표현 수준에 대해 여러 개의 숨겨진 레이어를 갖는 것입니다. 이러한 수준은 욕심 많은 학습을 위해 활동 교란을 사용하며 더 낮은 수준으로 역전파되지 않습니다. 역전파만큼 많은 레이어를 전달할 수 없기 때문에 역전파만큼 강력하지는 않습니다.
사실 이는 최근 몇 년간 Hinton 팀의 가장 중요한 연구 결과 중 하나입니다. 자세한 내용은 Machine Heart의 보고서를 참조하세요. "역전파를 포기한 후 Geoffrey Hinton을 포함한 블록버스터 순방향 경사 학습 연구가 나왔습니다》 .

Mengye Ren은 광범위한 연구를 통해 이 방법이 신경망에서 실제로 효과적일 수 있지만 작업이 매우 복잡하고 실제 효과가 역전파를 따라잡을 수 없다는 것을 보여주었습니다. 대규모 네트워크의 깊이가 깊을수록 역전파와의 격차는 더욱 커집니다.
Hinton은 시뮬레이션 속성을 활용할 수 있는 이 학습 알고리즘은 MNIST와 같은 작업을 처리하기에 충분할 정도로 괜찮다고 말할 수 있지만 실제로 사용하기 쉽지 않다고 말했습니다. ImageNet에서의 성능. 작업이 별로 좋지 않습니다.
소멸성 컴퓨팅이 직면한 문제: 지식의 상속
소멸성 컴퓨팅이 직면한 또 다른 주요 문제는 지식의 상속을 보장하기 어렵다는 것입니다. 부패하기 쉬운 컴퓨팅은 하드웨어에 크게 의존하기 때문에 가중치를 복사하여 지식을 복사할 수 없습니다. 즉, 하드웨어의 특정 부분이 "죽으면" 하드웨어가 학습한 지식도 함께 사라집니다.
Hinton은 이 문제를 해결하는 가장 좋은 방법은 하드웨어가 "죽기" 전에 학생들에게 지식을 전달하는 것이라고 말했습니다. 이러한 유형의 방법을 지식 증류라고 하며, 이 개념은 Oriol Vinyals 및 Jeff Dean과 공동으로 작성한 2015년 논문 "신경망에서 지식 증류"에서 Hinton이 처음 제안한 개념입니다.

이 개념의 기본 아이디어는 매우 간단하며 교사가 학생들에게 지식을 가르치는 것과 유사합니다. 교사는 학생들에게 다양한 입력에 대한 올바른 응답을 보여주고 학생들은 교사의 응답을 모방하려고 합니다.
Hinton은 직관적으로 설명하기 위해 Trump 전 미국 대통령의 트윗을 예로 들었습니다. Trump는 종종 트윗할 때 다양한 사건에 대해 매우 감정적인 반응을 보이며, 이로 인해 추종자들은 동일한 감정적 반응을 생성하기 위해 자신의 "신경망"을 변경하게 됩니다. ; 이런 식으로 트럼프는 추종자들의 마음에 편견을 심어주었습니다. 마치 힌튼이 트럼프를 좋아하지 않는 것 같습니다.
지식 증류법은 얼마나 효과적인가요? 트럼프의 많은 지지자들을 생각하면 효과는 나쁘지 않을 것이다. Hinton은 예를 사용하여 설명합니다. 에이전트가 이미지를 겹치지 않는 1024개의 카테고리로 분류해야 한다고 가정합니다.

정답을 식별하려면 10비트의 정보만 필요합니다. 따라서 특정 샘플을 올바르게 식별하도록 에이전트를 훈련하려면 가중치를 제한하기 위해 10비트의 정보만 제공하면 됩니다.
하지만 이 1024개 범주에 대해 교사와 거의 동일한 확률을 갖도록 에이전트를 훈련한다면 어떻게 될까요? 즉, Agent의 확률 분포를 Teacher의 확률 분포와 동일하게 만듭니다. 이 확률 분포는 1023개의 실수를 가지며, 이러한 확률이 아주 작지 않으면 수백 배 더 많은 제약 조건을 제공합니다.

이러한 확률이 너무 작지 않도록 하기 위해 교사는 "고온"에서 실행될 수 있고 학생도 학생을 훈련할 때 "고온"에서 실행될 수 있습니다. 예를 들어 로짓을 사용하는 경우 이는 소프트맥스에 대한 입력입니다. 교사의 경우 온도 매개변수를 기준으로 크기를 조정하여 더 부드러운 분포를 얻은 다음 학생을 교육할 때 동일한 온도를 사용할 수 있습니다.
구체적인 예를 살펴보겠습니다. 아래는 MNIST 훈련 세트의 캐릭터 2의 일부 이미지입니다. 오른쪽에 해당하는 것은 교사가 달리는 온도가 높을 때 교사가 각 이미지에 할당한 확률입니다.
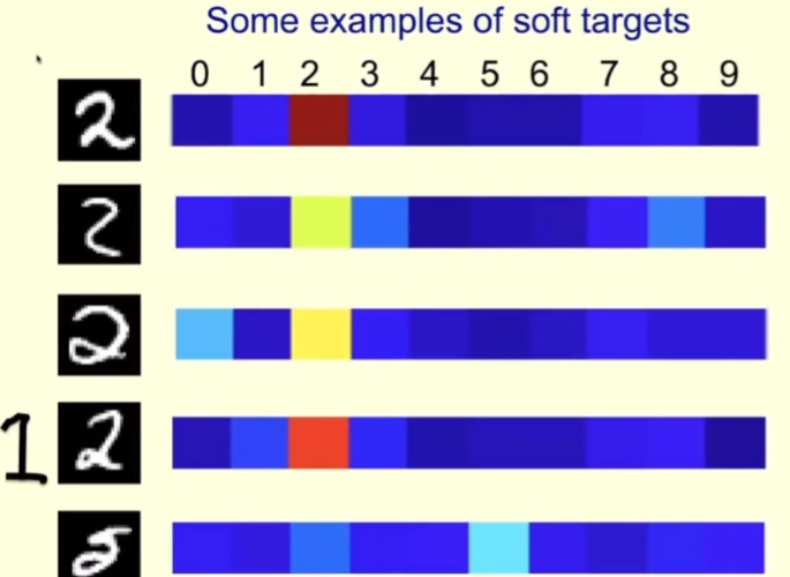
첫 번째 행의 경우 교사는 2라고 확신합니다. 교사도 두 번째 행의 경우 2라고 확신하지만 3 또는 8이 될 수도 있다고 생각합니다. 세 번째 줄은 0처럼 보입니다. 이 샘플의 경우 교사는 이것이 2라고 말해야 하지만 0이 들어갈 여지도 남겨 두어야 합니다. 이런 식으로 학생들은 이것이 2라고 직접 들었던 것보다 더 많은 것을 배울 것입니다.
네 번째 줄의 경우 교사가 2라고 확신하지만 1일 가능성이 어느 정도 있다고 생각하는 것을 볼 수 있습니다. 결국 우리가 쓰는 1이 칠판에 그려진 것과 유사할 때도 있습니다. 그림의 왼쪽.
다섯 번째 행의 경우 선생님이 실수를 해서 5라고 생각했습니다(그러나 MNIST 레이블에 따르면 2여야 합니다). 학생들은 또한 선생님의 실수로부터 많은 것을 배울 수 있습니다.
증류에는 매우 특별한 속성이 있습니다. 즉, 교사가 학생을 훈련하기 위해 주어진 확률을 사용할 때 교사와 같은 방식으로 학생들이 일반화하도록 훈련시키는 것입니다. 교사가 잘못된 답에 어느 정도 작은 확률을 할당하면 학생들도 잘못된 답을 일반화하도록 훈련됩니다.

일반적으로 우리는 훈련 데이터에 대한 정답을 얻도록 모델을 훈련시키고, 이 능력을 테스트 데이터에 일반화합니다. 그러나 교사-학생 훈련 모델을 사용할 경우 학생의 훈련 목표는 교사와 동일한 방식으로 일반화할 수 있도록 하는 것이기 때문에 학생의 일반화 능력을 직접 훈련합니다.
분명히 우리는 증류를 위해 더 풍부한 결과물을 만들 수 있습니다. 예를 들어, 단일 라벨이 아닌 각 이미지에 설명을 제공한 다음 학생들이 해당 설명의 단어를 예측하도록 교육할 수 있습니다.

다음으로 Hinton은 에이전트 그룹의 지식 공유에 대한 연구에 대해 이야기했습니다. 지식을 전달하는 방법이기도 합니다.

여러 에이전트로 구성된 커뮤니티가 서로 지식을 공유할 때 지식이 공유되는 방식에 따라 계산 수행 방식이 크게 결정될 수 있습니다.

디지털 모델의 경우 복제를 통해 동일한 가중치를 사용하는 다수의 에이전트를 생성할 수 있습니다. 이러한 에이전트가 훈련 데이터 세트의 다양한 부분을 살펴보고, 데이터의 다양한 부분을 기반으로 가중치의 기울기를 각각 계산한 다음 이러한 기울기의 평균을 계산하도록 할 수 있습니다. 이러한 방식으로 각 모델은 다른 모든 모델이 학습한 내용을 학습합니다. 이 훈련 전략의 이점은 대량의 데이터를 효율적으로 처리할 수 있다는 것입니다. 모델이 크면 각 공유에서 많은 수의 비트를 공유할 수 있습니다.
동시에 이 방법을 사용하려면 각 에이전트가 정확히 동일한 방식으로 작업해야 하므로 디지털 모델일 수밖에 없습니다.
체중분담 비용도 매우 높습니다. 다양한 하드웨어가 동일한 방식으로 작동하려면 동일한 명령을 실행할 때 항상 동일한 결과를 얻을 수 있을 정도로 높은 정밀도로 컴퓨터를 생산해야 합니다. 또한, 트랜지스터의 전력 소모도 낮지 않다.

증류는 체중 분담을 대체할 수도 있습니다. 특히 모델이 특정 하드웨어의 시뮬레이션된 속성을 사용하는 경우 가중치 공유를 사용할 수 없지만 지식을 공유하려면 증류를 사용해야 합니다.

증류를 이용한 지식 공유는 효율적이지 않고 대역폭도 매우 낮습니다. 학교에서와 마찬가지로 교사들은 자신이 아는 지식을 학생들의 머리 속에 쏟아 붓고 싶어하지만, 우리는 생물학적 지능이고 당신의 몸무게는 나에게 아무 소용이 없기 때문에 이것은 불가능합니다.

여기서 간단히 요약하자면 위에서는 완전히 다른 두 가지 계산 수행 방식(디지털 계산과 생물학적 계산)이 언급되었으며, 에이전트 간에 지식을 공유하는 방식도 매우 다릅니다.
그렇다면 현재 개발 중인 LLM(Large Scale Language Model)의 형태는 무엇일까요? 이는 가중치 공유를 사용할 수 있는 수치 계산입니다.

그러나 LLM의 각 복제 에이전트는 매우 비효율적인 증류 방식으로 문서에 있는 지식만 학습할 수 있습니다. LLM이 하는 일은 문서의 다음 단어를 예측하는 것이지만 교사가 다음 단어에 대한 확률 분포는 없습니다. 즉, 문서 작성자가 다음 단어에서 선택한 단어만 무작위로 선택하는 것뿐입니다. 위치. LLM은 실제로 우리 인간에게서 배우지만 지식을 전달하는 대역폭은 매우 낮습니다.
그리고 다시 말하지만, 증류를 통한 LLM 학습의 각 사본의 효율성은 매우 낮지만, 수천 개에 달하는 사본이 있으므로 우리보다 수천 배 더 많은 것을 배울 수 있습니다. 이는 현재 LLM이 우리 중 누구보다 지식이 풍부하다는 것을 의미합니다.
초지능이 인류 문명을 멸망시킬 것인가?
Next Hinton은 다음과 같은 질문을 던졌습니다. "이 디지털 지능이 증류를 통해 매우 천천히 우리에게서 학습하지 않고 현실 세계에서 직접 학습을 시작하면 어떻게 될까요?"

실제로 , LLM은 문서를 학습할 때 이미 인간이 수천년 동안 축적한 지식을 학습하고 있습니다. 인간은 세상에 대한 이해를 언어로 기술하기 때문에 디지털 지능은 인간이 축적한 지식을 텍스트 학습을 통해 직접적으로 습득할 수 있다. 증류는 느리지만 매우 추상적인 지식을 배웁니다.
디지털 지능이 이미지 및 비디오 모델링을 통해 비지도 학습을 수행할 수 있다면 어떨까요? 현재 인터넷에는 엄청난 양의 영상 데이터가 있으며, 미래에는 AI가 이 데이터로부터 효과적으로 학습할 수 있는 방법을 찾을 수 있을 것입니다. 또한 AI에 현실을 조작할 수 있는 로봇 팔 등의 방법이 있다면 학습에 더욱 도움이 될 수 있습니다.
Hinton은 디지털 에이전트가 이를 수행할 수 있다면 학습 능력이 인간보다 훨씬 뛰어나고 학습 속도도 매우 빨라질 것이라고 믿습니다.
이제 처음에 Hinton이 제기한 질문으로 돌아가겠습니다. AI의 지능이 우리의 지능을 초과하더라도 우리는 여전히 AI를 제어할 수 있습니까?
힌튼은 주로 자신의 우려를 표현하기 위해 이 연설을 했다고 합니다. 그는 “초지능이 이전에 생각했던 것보다 훨씬 빨리 나타날 수 있다고 생각한다”고 말했다.

예를 들어, 악의적인 행위자는 초지능을 사용하여 선거를 조작하거나 전쟁에서 승리할 수 있습니다(실제로 누군가 이미 기존 AI를 사용하여 이러한 작업을 수행하고 있습니다).
이 경우 초지능의 효율성을 높이려면 자체적으로 하위 목표를 생성하도록 허용할 수도 있습니다. 더 많은 전력을 제어하는 것은 분명한 하위 목표입니다. 결국 더 큰 전력과 더 많은 리소스를 제어할수록 에이전트가 궁극적인 목표를 달성하는 데 더 잘 도움이 될 수 있습니다. 그러면 초지능은 그것을 휘두르는 사람들을 조종함으로써 쉽게 더 많은 힘을 얻을 수 있다는 것을 발견할 수도 있습니다.
우리보다 똑똑한 존재와 우리가 그들과 상호 작용하는 방식을 상상하는 것은 어렵습니다. 그러나 Hinton은 우리보다 더 똑똑한 초지능이 배울 수 있는 소설과 정치 문헌이 너무 많은 인간을 속이는 방법을 확실히 배울 수 있다고 생각합니다.
초지능은 일단 인간을 속이는 법을 배우면 인간이 원하는 행동을 하게 만들 수 있습니다. 실제로 이것과 다른 사람을 속이는 것 사이에는 본질적인 차이가 없습니다. 예를 들어, 누군가 워싱턴에 있는 건물을 해킹하고 싶다면 실제로 그곳에 갈 필요는 없으며 단지 민주주의를 구하기 위해 건물을 해킹하고 있다고 믿도록 사람들을 속이기만 하면 된다고 힌튼은 말했습니다.
"정말 무서운 일인 것 같아요." Hinton의 비관론은 뚜렷합니다. "이제 이런 일이 발생하는 것을 어떻게 막을 수 있을지는 모르겠지만, 그는 젊은 인재들이 성공할 수 있는 방법을 찾기를 바라고 있습니다." 슈퍼 인텔리전스는 인간을 통제하에 두지 않고 인간이 더 나은 삶을 살 수 있도록 도와줍니다.
그러나 그는 AI가 진화한 것이 아니라 인간이 만들었다는 점에서 다소 작지만 장점이 있다고 말했습니다. 이렇듯 AI는 원래 인간과 같은 경쟁력과 목표를 갖고 있지 않다. 아마도 우리는 AI를 만드는 과정에서 AI에 대한 도덕적, 윤리적 원칙을 설정할 수 있을 것입니다.
그러나 지능 수준이 인간을 훨씬 능가하는 초지능이라면 이것이 효과적이지 않을 수도 있습니다. Hinton은 더 높은 수준의 지능이 훨씬 낮은 수준의 지능에 의해 제어되는 경우를 본 적이 없다고 말합니다. 개구리가 인간을 창조했다면 이제 개구리와 인간 중 누가 누구를 지배하는가?
마지막으로 Hinton은 이 연설의 마지막 슬라이드를 비관적으로 공개했습니다.

이것은 연설의 끝일 뿐만 아니라 모든 인류에 대한 경고이기도 합니다. 문명의 종말.
위 내용은 75세 힌튼의 최근 중국 회의 연설인 '지능으로 가는 두 가지 길'은 감동으로 끝났습니다. 나는 이미 늙었고 미래는 젊은이들에게 달려 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 Windows 11의 스마트 앱 제어: 켜거나 끄는 방법
Jun 06, 2023 pm 11:10 PM
Windows 11의 스마트 앱 제어: 켜거나 끄는 방법
Jun 06, 2023 pm 11:10 PM
지능형 앱 제어는 랜섬웨어나 스파이웨어와 같이 데이터를 손상시킬 수 있는 승인되지 않은 앱으로부터 PC를 보호하는 데 도움이 되는 Windows 11의 매우 유용한 도구입니다. 이 문서에서는 스마트 앱 컨트롤이 무엇인지, 어떻게 작동하는지, Windows 11에서 켜거나 끄는 방법을 설명합니다. Windows 11의 스마트 앱 제어란 무엇입니까? SAC(스마트 앱 제어)는 Windows 1122H2 업데이트에 도입된 새로운 보안 기능입니다. Microsoft Defender 또는 타사 바이러스 백신 소프트웨어와 함께 작동하여 장치 속도를 늦추거나 예상치 못한 광고를 표시하거나 기타 예상치 못한 작업을 수행할 수 있는 잠재적으로 불필요한 앱을 차단합니다. 스마트 애플리케이션
 날아다니는 것, 입을 벌리는 것, 쳐다보는 것, 눈썹을 치켜올리는 것 등의 얼굴 특징을 AI가 완벽하게 모방할 수 있어 영상사기 예방이 불가능하다.
Dec 14, 2023 pm 11:30 PM
날아다니는 것, 입을 벌리는 것, 쳐다보는 것, 눈썹을 치켜올리는 것 등의 얼굴 특징을 AI가 완벽하게 모방할 수 있어 영상사기 예방이 불가능하다.
Dec 14, 2023 pm 11:30 PM
이렇게 강력한 AI 모방 능력을 가지고 있다면, 막는 것은 사실상 불가능합니다. 이제 AI의 발전이 이 정도 수준에 이르렀나? 앞발은 이목구비를 날리게 하고, 뒷발은 쳐다보는 것, 눈썹을 치켜올리는 것, 삐죽이는 것 등 아무리 과장된 표정이라도 완벽하게 흉내낸다. 난이도를 높이고, 눈썹을 더 높이 올리고, 눈을 크게 뜨고, 입 모양까지 비뚤어지게 표현하는 등 가상 캐릭터 아바타가 표정을 완벽하게 재현할 수 있다. 왼쪽의 매개변수를 조정하면 오른쪽의 가상 아바타도 그에 따라 움직임을 변경하여 입과 눈을 클로즈업하여 모방이 완전히 동일하다고는 할 수 없으며 표정만 정확합니다. 마찬가지다(맨 오른쪽). 이 연구는 GaussianAvatars를 제안하는 뮌헨 기술 대학과 같은 기관에서 나왔습니다.
 MotionLM: 다중 에이전트 모션 예측을 위한 언어 모델링 기술
Oct 13, 2023 pm 12:09 PM
MotionLM: 다중 에이전트 모션 예측을 위한 언어 모델링 기술
Oct 13, 2023 pm 12:09 PM
이 글은 자율주행하트 공개 계정의 허가를 받아 재인쇄되었습니다. 재인쇄를 원하시면 출처에 문의해 주세요. 원제: MotionLM: Multi-Agent Motion Forecasting as Language Modeling 논문 링크: https://arxiv.org/pdf/2309.16534.pdf 저자 소속: Waymo 컨퍼런스: ICCV2023 논문 아이디어: 자율 차량 안전 계획을 위해 미래 행동을 안정적으로 예측 도로요원의 역할이 중요합니다. 본 연구는 연속적인 궤적을 개별 모션 토큰의 시퀀스로 표현하고 다중 에이전트 모션 예측을 언어 모델링 작업으로 처리합니다. 우리가 제안하는 모델인 MotionLM은 다음과 같은 장점을 가지고 있습니다.
 보행자 궤적 예측을 위한 효과적인 방법과 일반적인 기본 방법은 무엇입니까? 최고의 컨퍼런스 논문 공유!
Oct 17, 2023 am 11:13 AM
보행자 궤적 예측을 위한 효과적인 방법과 일반적인 기본 방법은 무엇입니까? 최고의 컨퍼런스 논문 공유!
Oct 17, 2023 am 11:13 AM
궤적 예측은 지난 2년 동안 추진력을 얻었지만 대부분은 차량 궤적 예측의 방향에 중점을 두고 있습니다. 오늘날 자율 주행 심장은 제한된 시나리오에서 인간의 보행자 궤적 예측을 위한 알고리즘인 NeurIPS를 공유합니다. 움직임 패턴은 일반적으로 어느 정도 제한된 규칙을 따릅니다. SHENet은 이러한 가정을 바탕으로 암묵적인 장면 규칙을 학습하여 사람의 미래 궤적을 예측합니다. 이 기사는 자율주행하트의 원본임을 인정받았습니다! 저자의 개인적 이해는 현재 사람의 미래 궤적을 예측하는 것이 인간 움직임의 무작위성과 주관성으로 인해 여전히 어려운 문제라는 것입니다. 그러나 제한된 장면에서 인간의 움직임 패턴은 장면 제약(예: 평면도, 도로 및 장애물)과 인간 대 인간 또는 인간 대 객체 상호 작용으로 인해 달라지는 경우가 많습니다.
 몇 년 안에 프로그래머가 쇠퇴할 것이라는 사실을 알고 계십니까?
Nov 08, 2023 am 11:17 AM
몇 년 안에 프로그래머가 쇠퇴할 것이라는 사실을 알고 계십니까?
Nov 08, 2023 am 11:17 AM
"ComputerWorld" 잡지는 IBM이 엔지니어가 필요한 수학 공식을 작성한 다음 이를 제출하면 프로그래밍이 종료되도록 하는 새로운 언어 FORTRAN을 개발했기 때문에 "프로그래밍은 1960년에 사라질 것"이라는 기사를 쓴 적이 있습니다. 몇 년 후 우리는 비즈니스 용어를 사용하여 문제를 설명하고 컴퓨터에 COBOL이라는 프로그래밍 언어를 사용하면 더 이상 프로그래머가 필요하지 않다는 새로운 말을 들었습니다. 이후 IBM은 직원들이 양식을 작성하고 보고서를 생성할 수 있는 RPG라는 새로운 프로그래밍 언어를 개발해 회사의 프로그래밍 요구 사항 대부분을 이를 통해 완료할 수 있다고 합니다.
 한 기사로 스마트 자동차 스케이트보드 섀시 읽기
May 24, 2023 pm 12:01 PM
한 기사로 스마트 자동차 스케이트보드 섀시 읽기
May 24, 2023 pm 12:01 PM
01 스케이트보드 섀시란 무엇입니까? 스케이트보드 섀시란 배터리, 전동변속기, 서스펜션, 브레이크 등의 부품을 섀시에 미리 일체화하여 차체와 섀시를 분리하고 디자인을 분리한 것입니다. 이러한 유형의 플랫폼을 기반으로 자동차 회사는 초기 R&D 및 테스트 비용을 크게 절감하는 동시에 다양한 모델을 만들기 위한 시장 수요에 신속하게 대응할 수 있습니다. 특히 무인 운전 시대에는 자동차의 레이아웃이 더 이상 운전 중심이 아닌 공간 속성에 중점을 둘 것입니다. 스케이트보드형 섀시는 상부 캐빈의 개발에 더 많은 가능성을 제공할 수 있습니다. 위 사진에서 보듯이 물론 스케이트보드 섀시를 봤을 때, 처음 떠올랐을 때 "아, 무부하 바디다"라는 첫인상에 얽매여서는 안 됩니다. 그 당시에는 전기차가 없었기 때문에 수백 킬로그램에 달하는 배터리 팩도 없었고, 스티어링 컬럼을 없앨 수 있는 스티어링 바이 와이어 시스템도, 브레이크 바이 와이어 시스템도 없었습니다.
 GR-1 푸리에 지능형 범용 휴머노이드 로봇이 곧 사전 판매를 시작합니다!
Sep 27, 2023 pm 08:41 PM
GR-1 푸리에 지능형 범용 휴머노이드 로봇이 곧 사전 판매를 시작합니다!
Sep 27, 2023 pm 08:41 PM
휴머노이드 로봇은 높이 1.65미터, 무게 55킬로그램, 몸의 자유도가 44도입니다. 빠르게 걷고, 장애물을 빠르게 피하고, 경사면을 꾸준히 오르락내리락하고, 충격 간섭에 저항할 수 있습니다. 푸리에 인텔리전스(Fourier Intelligence)의 만능 휴머노이드 로봇 GR-1이 사전 판매를 시작했습니다. 로봇 강당 푸리에 인텔리전스(Fourier Intelligence)의 만능 휴머노이드 로봇 푸리에GR-1(FourierGR-1)이 사전 판매를 시작했습니다. GR-1은 고도의 생체공학적 몸통 구성과 의인화된 모션 제어 기능을 갖추고 있으며, 몸 전체가 44도의 자유도를 갖고 있으며, 걷기, 장애물 회피, 장애물 건너기, 경사면 오르내리기, 간섭 저항 및 다양한 도로 적응 능력을 갖추고 있습니다. 표면. 그것은 일반적인 인공 지능 시스템입니다. 공식 웹사이트 사전 판매 페이지: www.fftai.cn/order#FourierGR-1# 푸리에 인텔리전스를 다시 작성해야 합니다.
 SLAM 기술을 자율주행에 적용한 내용을 다룬 기사
Apr 09, 2023 pm 01:11 PM
SLAM 기술을 자율주행에 적용한 내용을 다룬 기사
Apr 09, 2023 pm 01:11 PM
포지셔닝은 자율주행에서 대체할 수 없는 위치를 차지하고 있으며 앞으로도 발전 가능성이 높습니다. 현재 자율주행에서의 위치 확인은 RTK와 고정밀 지도에 의존하고 있어 자율주행 구현에 많은 비용과 어려움이 추가됩니다. 인간이 운전할 때 자신의 글로벌 고정밀 포지셔닝과 상세한 주변 환경을 알 필요가 없다고 상상해 보십시오. 글로벌 내비게이션 경로가 있고 경로에서 차량의 위치를 일치시키는 것만으로도 충분합니다. SLAM 분야 핵심기술. CML(Concurrent Mapping and Localiza)이라고도 알려진 SLAMSLAM(Simultaneous Localization and Mapping)이란 무엇입니까?
