

이 '실수'는 실제로는 실수가 아닙니다. Transformer 아키텍처 다이어그램의 '잘못'이 무엇인지 이해하려면 4개의 고전 논문으로 시작하세요.

얼마 전, Transformer 아키텍처 다이어그램과 Google Brain 팀의 논문 "Attention Is All You Need"의 코드 사이의 불일치를 지적하는 트윗이 많은 논의를 촉발했습니다.
어떤 사람들은 세바스찬의 발견이 솔직한 실수라고 생각하지만 동시에 이상하기도 합니다. 결국 Transformer 논문의 인기를 고려하면 이러한 불일치는 수천 번 이상 언급되어야 합니다.
Sebastian Raschka는 네티즌 댓글에 대해 "가장 독창적인" 코드가 실제로 아키텍처 다이어그램과 일치하지만 2017년에 제출된 코드 버전은 수정되었지만 아키텍처 다이어그램은 동시에 업데이트되지 않았다고 말했습니다. 이는 '일관되지 않은' 논의의 근본 원인이기도 합니다.
이후 Sebastian은 Ahead of AI에 원래 Transformer 아키텍처 다이어그램이 코드와 일치하지 않는 이유를 구체적으로 설명하는 기사를 게재했으며 여러 논문을 인용하여 Transformer의 개발 및 변경 사항을 간략하게 설명했습니다.
다음은 기사의 원문입니다. 기사의 내용을 살펴보겠습니다.
몇 달 전에 저는 "대형 언어 모델 이해: 십자가"를 공유했습니다. -최고의 "속도를 높이기 위한 관련 문헌" 섹션, 긍정적인 피드백은 매우 고무적입니다! 따라서 목록을 신선하고 관련성 있게 유지하기 위해 몇 가지 논문을 추가했습니다.
동시에 모든 사람이 합리적인 시간 내에 속도를 낼 수 있도록 목록을 간결하고 간결하게 유지하는 것이 중요합니다. 또한 많은 정보가 포함되어 있어 포함되어야 하는 일부 문서도 있습니다.
Transformer를 역사적 관점에서 이해하는 데 유용한 네 편의 논문을 공유하고 싶습니다. 대규모 언어 모델 이해 기사에 직접 추가하는 것뿐이지만, 이전에 대규모 언어 모델 이해를 읽은 사람들이 더 쉽게 찾을 수 있도록 이 기사에서 별도로 공유하기도 합니다.
On Layer Normalization in the Transformer Architecture(2020)
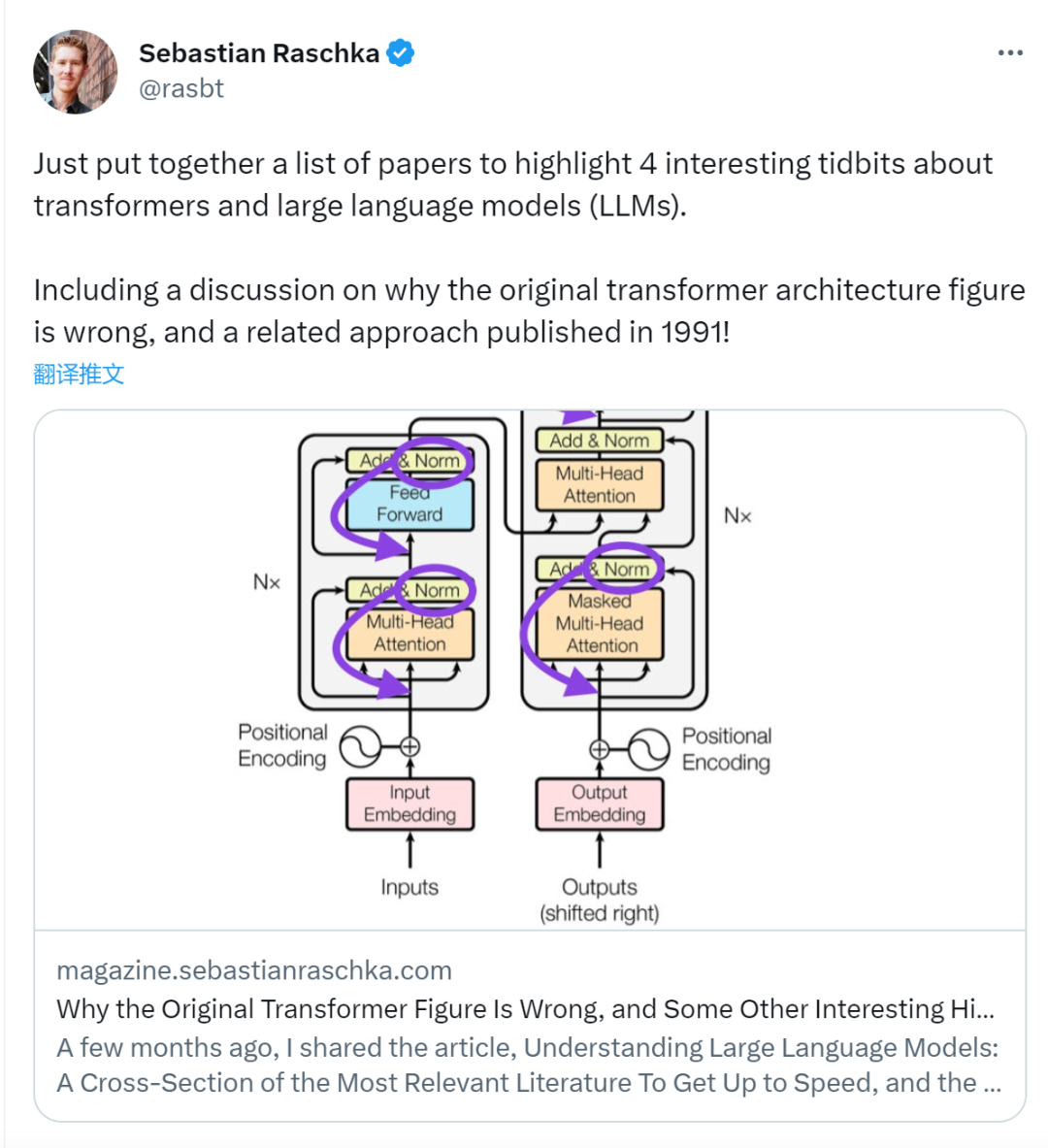
아래 원본 Transformer 이미지(https://arxiv.org/abs/1706.03762)는 원본 인코더 디코딩이지만 유용합니다. 서버 아키텍처를 요약했지만 다이어그램에는 작은 차이점이 하나 있습니다. 예를 들어, 원래 Transformer 문서에 포함된 공식(업데이트된) 코드 구현과 일치하지 않는 잔여 블록 간의 레이어 정규화를 수행합니다. 아래(가운데)에 표시된 변형을 Post-LN 변환기라고 합니다.
Transformer 아키텍처 문서의 레이어 정규화는 Pre-LN이 더 잘 작동하고 아래와 같이 그라데이션 문제를 해결할 수 있음을 보여줍니다. 많은 아키텍처가 실제로 이 접근 방식을 채택하지만 표현이 중단될 수 있습니다.
그래서 여전히 Post-LN 또는 Pre-LN 사용에 대한 논의가 있는 반면, 두 가지를 함께 적용할 것을 제안하는 새로운 논문도 있습니다: "ResiDual: Transformer with Dual Residual Connections" (https://arxiv .org /abs/2304.14802) 그러나 실제로 유용할지 여부는 아직 알 수 없습니다.
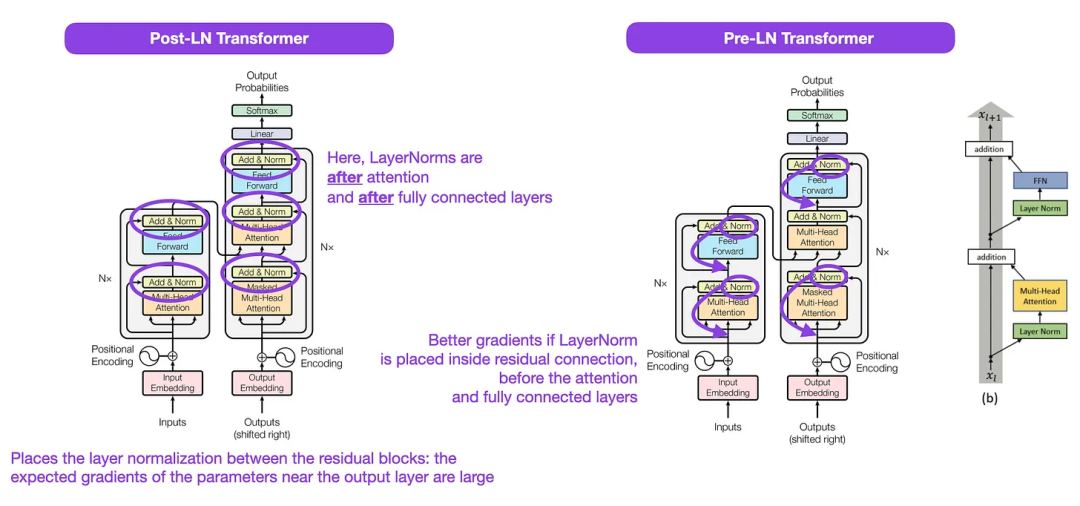
캡션: 이미지 출처 https://arxiv.org/abs/1706.03762(왼쪽 및 가운데) 및 https://arxiv.org/abs/2002.04745(오른쪽)
빠른 무게의 기억 제어 방법 학습: 동적 순환 신경망의 대안(1991)
이 기사는 역사적 정보와 현대 Transformer와 기본적으로 유사한 초기 방법에 관심이 있는 사람들에게 권장됩니다.
예를 들어, Transformer 논문이 나오기 25년 전인 1991년에 Juergen Schmidhuber는 순환 신경망에 대한 대안을 제안했습니다(https://www.semanticscholar.org/paper/Learning-to-Control-Fast-Weight-Memories%3A). -An-to-Schmidhuber/bc22e87a26d020215afe91c751e5bdaddd8e4922), FWP(Fast Weight Programmers)라고 합니다. 빠른 가중치 변화를 달성하는 또 다른 신경망은 경사 하강 알고리즘을 사용하여 천천히 학습하는 FWP 방법에 포함된 피드포워드 신경망입니다.
이 블로그(https://people.idsia.ch//~juergen/fast-weight-programmer-1991-transformer.html#sec2)에서는 이를 최신 Transformer와 다음과 같이 비교합니다.
오늘의 Transformer에서는 FROM과 TO를 각각 키(key)와 값(value)이라고 합니다. 빠른 네트워크가 적용된 입력을 쿼리라고 합니다. 기본적으로 쿼리는 키와 값의 외부 곱의 합인 빠른 가중치 행렬에 의해 처리됩니다(정규화 및 투영 무시). 두 네트워크의 모든 작업이 차별화를 지원하기 때문에 덧셈 외부 곱 또는 2차 텐서 곱을 사용하여 가중치의 급격한 변화에 대한 엔드 투 엔드 미분 활성 제어를 달성할 수 있습니다. 시퀀스 처리 중에 경사하강법을 사용하면 빠른 네트워크를 느린 네트워크의 문제에 신속하게 적응시킬 수 있습니다. 이는 선형화된 self-attention을 갖춘 Transformer(또는 선형 Transformer)로 알려진 것과 수학적으로 동일합니다(정규화 제외).
위의 발췌에서 언급했듯이 이 접근 방식은 이제 선형 변환기 또는 선형화된 self-attention을 갖춘 변환기로 알려져 있습니다. 이는 "Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention"(https://arxiv.org/abs/2006.16236) 및 "Rethinking Attention with Performers"(https://arxiv.org/abs/2009.14794) 논문에서 나온 것입니다. .
2021년 논문 "Linear Transformers Are Secretly Fast Weight Programmers"(https://arxiv.org/abs/2102.11174)에서는 선형화된 self-attention과 1990년대 동등의 빠른 가중치 프로그래머 사이의 차이를 명확하게 보여줍니다.
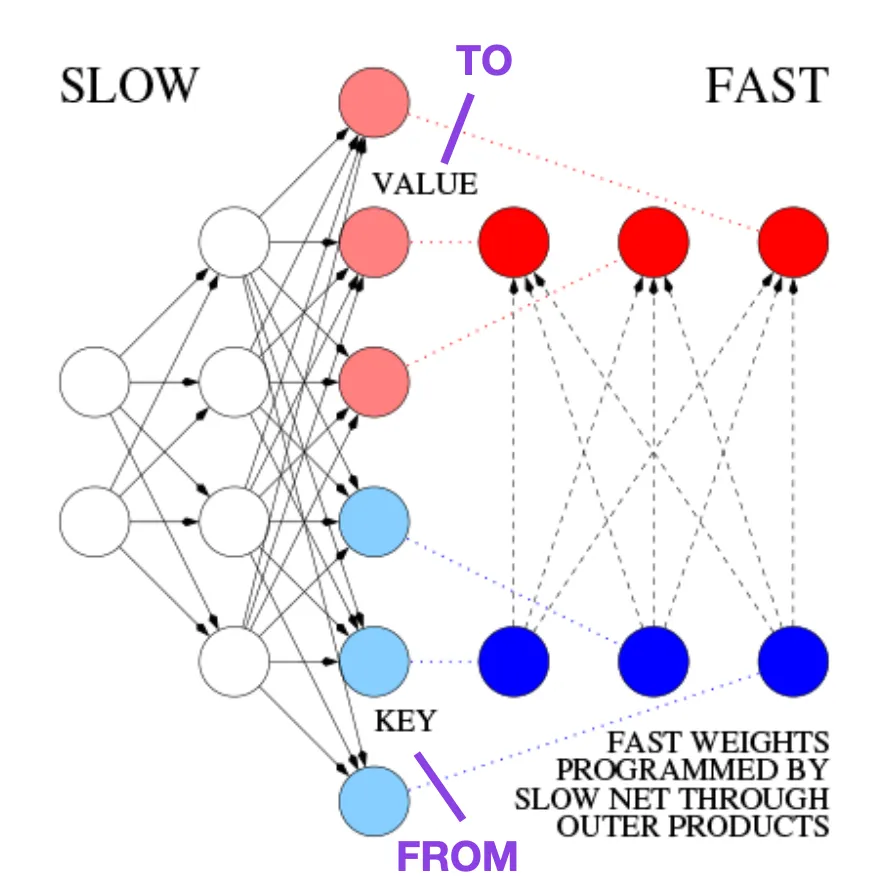
이미지 출처: https://people.idsia.ch//~juergen/fast-weight-programmer-1991-transformer.html#sec2
Universal 텍스트 분류를 위한 언어 모델 미세 조정(2018)
이것은 역사적 관점에서 볼 때 또 다른 매우 흥미로운 논문입니다. 이 책은 오리지널 Attention Is All You Need가 출시된 지 1년 후에 작성되었으며 변환기를 사용하지 않고 대신 순환 신경망에 중점을 두지만 여전히 시청할 가치가 있습니다. 사전 훈련된 언어 모델과 전이 학습의 다운스트림 작업을 효과적으로 제안하기 때문입니다. 전이 학습은 컴퓨터 비전 분야에서 잘 확립되어 있지만 자연어 처리(NLP) 분야에서는 아직 대중화되지 않았습니다. ULMFit(https://arxiv.org/abs/1801.06146)은 사전 훈련된 언어 모델이 특정 작업에 대해 미세 조정될 때 많은 NLP 작업에 대한 SOTA 결과를 생성할 수 있음을 보여주는 최초의 논문 중 하나입니다.
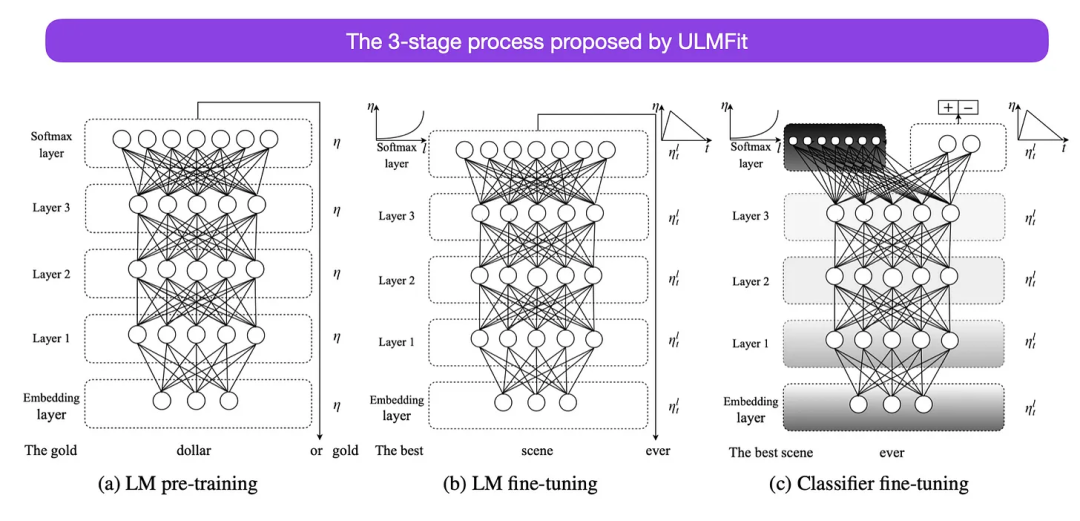
ULMFit이 제안하는 언어 모델 미세 조정 프로세스는 다음 세 단계로 나뉩니다.
- 1. 대규모 텍스트 코퍼스에서 언어 모델 학습
- 2. -특정 데이터 텍스트의 특정 스타일과 어휘에 적응할 수 있도록 모델이 미세 조정되었습니다.
- 3. 레이어를 점차적으로 해제하여 치명적인 망각을 방지하기 위해 작업별 데이터에 대한 분류기를 미세 조정합니다.
대규모 코퍼스에서 언어 모델을 훈련한 후 다운스트림 작업에서 미세 조정하는 이 방법은 Transformer 모델과 기본 모델(예: BERT, GPT-2/3/4, RoBERTa 등)을 기반으로 합니다. ) 사용된 핵심 방법.
그러나 Transformer 아키텍처는 일반적으로 모든 레이어를 한 번에 미세 조정하기 때문에 ULMFiT의 핵심 부분인 점진적 동결 해제는 일반적으로 실제로 수행되지 않습니다.
Gopher는 LLM 교육을 이해하기 위한 광범위한 분석이 포함된 특히 좋은 논문(https://arxiv.org/abs/2112.11446)입니다. 연구원들은 3,000억 개의 토큰에 대해 80층, 2,800억 개의 매개변수 모델을 훈련했습니다. 여기에는 LayerNorm(레이어 정규화) 대신 RMSNorm(제곱평균제곱근 정규화)을 사용하는 등 몇 가지 흥미로운 아키텍처 수정이 포함됩니다. LayerNorm과 RMSNorm은 모두 배치 크기에 제한이 없고 동기화가 필요하지 않기 때문에 BatchNorm보다 낫습니다. 이는 배치 크기가 더 작은 분산 설정에서 이점입니다. RMSNorm은 일반적으로 더 깊은 아키텍처에서 훈련을 안정화하는 것으로 간주됩니다.
위의 흥미로운 이야기 외에도 이 기사의 주요 초점은 작업 성과 분석을 다양한 규모로 분석하는 것입니다. 152개의 다양한 작업을 평가한 결과, 모델 크기를 늘리는 것이 이해, 사실 확인, 유해한 언어 식별과 같은 작업에 가장 유익한 반면, 아키텍처 확장은 논리적 및 수학적 추론과 관련된 작업에는 덜 유익한 것으로 나타났습니다.
캡션: 출처 https://arxiv.org/abs/2112.11446
위 내용은 이 '실수'는 실제로는 실수가 아닙니다. Transformer 아키텍처 다이어그램의 '잘못'이 무엇인지 이해하려면 4개의 고전 논문으로 시작하세요.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7722
7722
 15
1642
14
1396
52
1289
25
1233
29
15
1642
14
1396
52
1289
25
1233
29

 Worldcoin (WLD) 가격 예측 2025-2031 : WLD가 2031 년까지 4 달러에 도달 할 것인가?
Apr 21, 2025 pm 02:42 PM
Worldcoin (WLD) 가격 예측 2025-2031 : WLD가 2031 년까지 4 달러에 도달 할 것인가?
Apr 21, 2025 pm 02:42 PM
Worldcoin (WLD)은 Cryptocurrency 시장에서 고유 한 생체 인정 및 개인 정보 보호 메커니즘으로 눈에 띄고 많은 투자자의 관심을 끌고 있습니다. WLD는 혁신적인 기술, 특히 OpenAi 인공 지능 기술과 함께 Altcoins에서 뛰어난 성과를 거두었습니다. 그러나 향후 몇 년 안에 디지털 자산은 어떻게 행동 할 것인가? WLD의 미래 가격을 함께 예측합시다. 2025 WLD 가격 예측은 2025 년 WLD에서 상당한 성장을 달성 할 것으로 예상됩니다. 시장 분석에 따르면 평균 WLD 가격은 최대 $ 1.36로 $ 1.31에 도달 할 수 있습니다. 그러나 곰 시장에서 가격은 약 $ 0.55로 떨어질 수 있습니다. 이러한 성장 기대는 주로 WorldCoin2에 기인합니다.
 가상 통화 가격의 상승 또는 하락은 왜입니까? 가상 통화 가격의 상승 또는 하락은 왜입니까?
Apr 21, 2025 am 08:57 AM
가상 통화 가격의 상승 또는 하락은 왜입니까? 가상 통화 가격의 상승 또는 하락은 왜입니까?
Apr 21, 2025 am 08:57 AM
가상 통화 가격 상승의 요인은 다음과 같습니다. 1. 시장 수요 증가, 2. 공급 감소, 3. 긍정적 인 뉴스, 4. 낙관적 시장 감정, 5. 거시 경제 환경; 감소 요인에는 다음이 포함됩니다. 1. 시장 수요 감소, 2. 공급 증가, 3. 부정적인 뉴스의 파업, 4. 비관적 시장 감정, 5. 거시 경제 환경.
 Aavenomics는 AAVE 프로토콜 토큰을 수정하고 쿼럼 수의 사람들에게 도달 한 토큰 재구매를 소개하는 권장 사항입니다.
Apr 21, 2025 pm 06:24 PM
Aavenomics는 AAVE 프로토콜 토큰을 수정하고 쿼럼 수의 사람들에게 도달 한 토큰 재구매를 소개하는 권장 사항입니다.
Apr 21, 2025 pm 06:24 PM
Aavenomics는 AAVE 프로토콜 토큰을 수정하고 Aavedao의 쿼럼을 구현 한 Token Repos를 소개하는 제안입니다. AAVE 프로젝트 체인 (ACI)의 설립자 인 Marc Zeller는 X에서 이것을 발표하여 계약의 새로운 시대를 표시한다고 지적했습니다. AAVE 체인 이니셔티브 (ACI)의 설립자 인 Marc Zeller는 AAVENOMICS 제안서에 AAVE 프로토콜 토큰 수정 및 토큰 리포지션 도입이 포함되어 있다고 X에서 AAVEDAO에 대한 쿼럼을 달성했다고 발표했습니다. Zeller에 따르면, 이것은 계약의 새로운 시대를 나타냅니다. Aavedao 회원국은 수요일에 주당 100 인 제안을지지하기 위해 압도적으로 투표했습니다.
 크로스 체인 거래는 무엇을 의미합니까? 크로스 체인 거래는 무엇입니까?
Apr 21, 2025 pm 11:39 PM
크로스 체인 거래는 무엇을 의미합니까? 크로스 체인 거래는 무엇입니까?
Apr 21, 2025 pm 11:39 PM
크로스 체인 거래를 지원하는 교환 : 1. Binance, 2. Uniswap, 3. Sushiswap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN 거래,이 플랫폼은 다양한 기술을 통해 다중 체인 자산 거래를 지원합니다.
 통화에서 레버리지 교환 순위 순위 서클 통화 서클에서 상위 10 개의 레버리지 거래소의 최신 권장 사항
Apr 21, 2025 pm 11:24 PM
통화에서 레버리지 교환 순위 순위 서클 통화 서클에서 상위 10 개의 레버리지 거래소의 최신 권장 사항
Apr 21, 2025 pm 11:24 PM
2025 년에 레버리지 거래, 보안 및 사용자 경험에서 뛰어난 성능을 보이는 플랫폼은 다음과 같습니다. 1. OKX, 고주파 거래자에게 적합하여 최대 100 배의 레버리지를 제공합니다. 2. Binance, 전 세계의 다중 통화 거래자에게 적합하며 125 배 높은 레버리지를 제공합니다. 3. Gate.io, 전문 파생 상품 플레이어에게 적합하며 100 배의 레버리지를 제공합니다. 4. 초보자 및 소셜 트레이더에게 적합한 Bitget, 최대 100 배의 레버리지를 제공합니다. 5. 크라켄은 꾸준한 투자자에게 적합하며 5 배의 레버리지를 제공합니다. 6. Bybit, Altcoin Explorers에 적합하며 20 배의 레버리지를 제공합니다. 7. 저비용 거래자에게 적합한 Kucoin, 10 배의 레버리지를 제공합니다. 8. 비트 피 넥스, 시니어 플레이에 적합합니다
 하이브리드 블록 체인 거래 플랫폼은 무엇입니까?
Apr 21, 2025 pm 11:36 PM
하이브리드 블록 체인 거래 플랫폼은 무엇입니까?
Apr 21, 2025 pm 11:36 PM
cryptocurrency 교환 선택에 대한 제안 : 1. 유동성 요구 사항의 경우 우선 순위는 순서 깊이와 강한 변동성 저항으로 인해 Binance, Gate.io 또는 Okx입니다. 2. 규정 준수 및 보안, 코인베이스, 크라켄 및 쌍둥이 자리는 엄격한 규제 승인을 받았습니다. 3. Kucoin의 소프트 스테이 킹 및 Bybit의 파생 설계 혁신적인 기능은 고급 사용자에게 적합합니다.
 통화 서클 시장의 실시간 데이터에 대한 상위 10 개 무료 플랫폼 권장 사항이 출시됩니다.
Apr 22, 2025 am 08:12 AM
통화 서클 시장의 실시간 데이터에 대한 상위 10 개 무료 플랫폼 권장 사항이 출시됩니다.
Apr 22, 2025 am 08:12 AM
초보자에게 적합한 cryptocurrency 데이터 플랫폼에는 CoinmarketCap 및 비소 트럼펫이 포함됩니다. 1. CoinmarketCap은 초보자 및 기본 분석 요구에 대한 글로벌 실시간 가격, 시장 가치 및 거래량 순위를 제공합니다. 2. 비소 인용문은 중국 사용자가 저 위험 잠재적 프로젝트를 신속하게 선별하는 데 적합한 중국 친화적 인 인터페이스를 제공합니다.
 Binance 전체 프로세스 전략에 대한 커널 에어 드롭 보상을받는 방법
Apr 21, 2025 pm 01:03 PM
Binance 전체 프로세스 전략에 대한 커널 에어 드롭 보상을받는 방법
Apr 21, 2025 pm 01:03 PM
암호 화폐의 번화 한 세계에서는 새로운 기회가 항상 나타납니다. 현재 Kerneldao (Kernel) 에어 드롭 활동은 많은 관심을 끌고 많은 투자자들의 관심을 끌고 있습니다. 그렇다면이 프로젝트의 기원은 무엇입니까? BNB 보유자는 어떤 이점을 얻을 수 있습니까? 걱정하지 마십시오. 다음은 당신을 위해 하나씩 공개 할 것입니다.
