

Dubbo 로드 밸런싱 전략 일관된 해싱

이 글에서는 주로 일관된 해시 알고리즘의 원리와 기존 데이터 왜곡 문제를 설명한 다음 데이터 왜곡 문제를 해결하는 방법을 소개하고 마지막으로 Dubbo에서 일관된 해시 알고리즘의 사용을 분석합니다. 이 글에서는 컨시스턴트 해싱 알고리즘이 어떻게 작동하는지, 그리고 알고리즘이 직면한 문제점과 해결책을 소개합니다.
1. 로드 밸런싱
다음은 dubbo 공식 웹사이트의 인용문입니다.
LoadBalance는 중국어로 로드 밸런싱을 의미합니다. 그 책임은 네트워크 요청이나 다른 형태의 로드를 다른 시스템에 "균등하게 분배"하는 것입니다. 클러스터의 일부 서버는 과도한 압력을 받는 반면 다른 서버는 상대적으로 유휴 상태인 상황을 피하십시오. 로드 밸런싱을 통해 각 서버는 자체 처리 능력에 맞는 로드를 얻을 수 있습니다. 부하가 높은 서버를 오프로드하는 동안 리소스 낭비를 방지하여 일석이조를 달성할 수 있습니다. 로드 밸런싱은 소프트웨어 로드 밸런싱과 하드웨어 로드 밸런싱으로 나눌 수 있습니다. 일상적인 개발에서는 일반적으로 하드웨어 로드 밸런싱에 액세스하기가 어렵습니다. 그러나 Nginx와 같은 소프트웨어 부하 분산은 계속 사용할 수 있습니다. Dubbo에는 로드 밸런싱 개념과 그에 따른 구현도 있습니다.
특정 서비스 제공업체의 과도한 부하를 피하기 위해 Dubbo는 서비스 소비자의 통화 요청을 할당해야 합니다. 서비스 공급자의 로드가 너무 커서 일부 요청이 시간 초과될 수 있습니다. 따라서 각 서비스 제공자에게 부하의 균형을 맞추는 것이 매우 필요합니다. Dubbo는 4가지 로드 밸런싱 구현, 즉 가중 무작위 알고리즘을 기반으로 하는 RandomLoadBalance, 최소 활성 호출 알고리즘을 기반으로 하는 LeastActiveLoadBalance, 해시 일관성을 기반으로 하는 ConciousHashLoadBalance, 가중 폴링 알고리즘을 기반으로 하는 RoundRobinLoadBalance를 제공합니다. 이러한 로드 밸런싱 알고리즘의 코드는 그리 길지 않지만 해당 원리를 이해하려면 특정 전문 지식과 이해가 필요합니다.
2. 해시 알고리즘
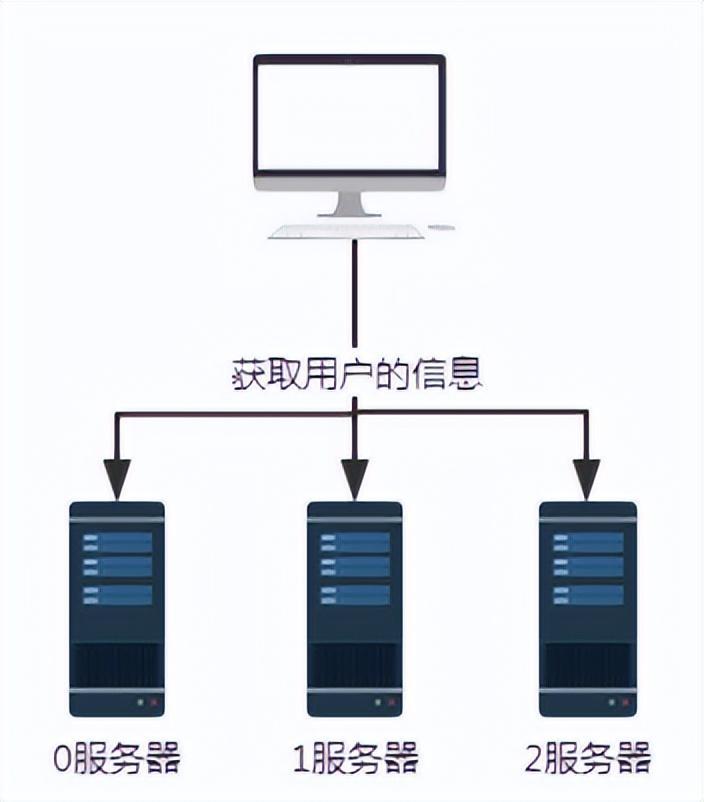
그림 1 해시 알고리즘이 없는 요청
위와 같이 서버 0, 1, 2가 모두 사용자 정보를 저장한다고 가정하면, 특정 사용자 정보를 얻어야 할 때, 사용자 정보가 어느 서버에 저장되어 있는지 모르면 서버 0, 1, 2에 각각 쿼리해야 합니다. 이런 방식으로 데이터를 얻는 효율성은 매우 낮습니다.
이러한 시나리오에는 해시 알고리즘을 도입할 수 있습니다.
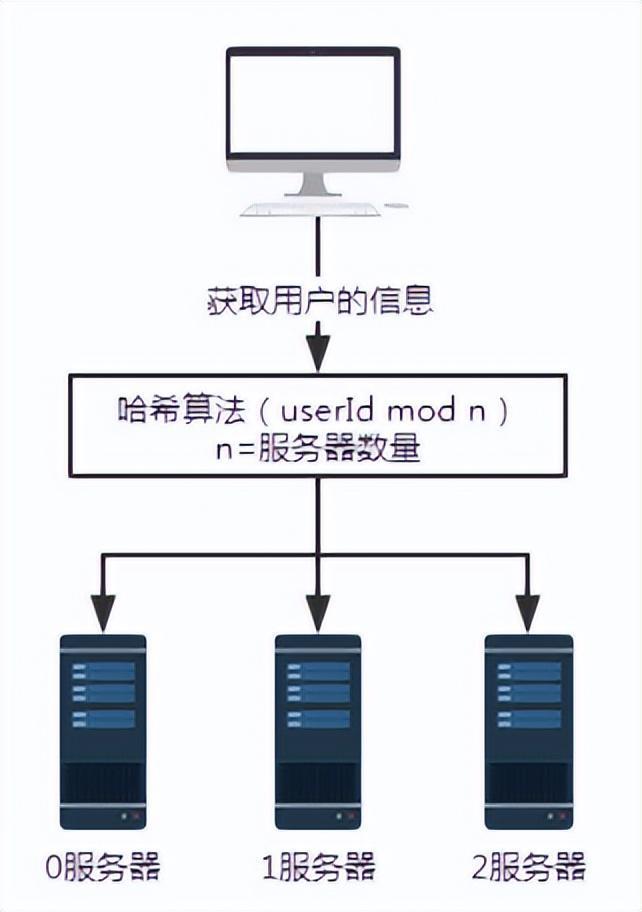
그림 2 해시 알고리즘 도입 후 요청
위 시나리오에서는 각 서버가 동일한 해시 알고리즘을 사용하여 사용자 정보를 저장한다고 가정합니다. 따라서 사용자 정보를 얻을 때 동일한 해싱 알고리즘을 따르기만 하면 됩니다.
사용자 번호가 100인 사용자 정보를 쿼리한다고 가정해 보겠습니다. 여기서 userId mod n, 즉 100 mod 3과 같은 특정 해시 알고리즘 이후 결과는 1입니다. 따라서 사용자 번호 100의 요청은 결국 서버 번호 1에 의해 수신되고 처리됩니다.
이것은 잘못된 쿼리 문제를 해결합니다.
그런 해결책이 어떤 문제를 가져올까요?
확장하거나 축소하면 많은 양의 데이터가 마이그레이션됩니다. 최소한 50%의 데이터가 영향을 받습니다.
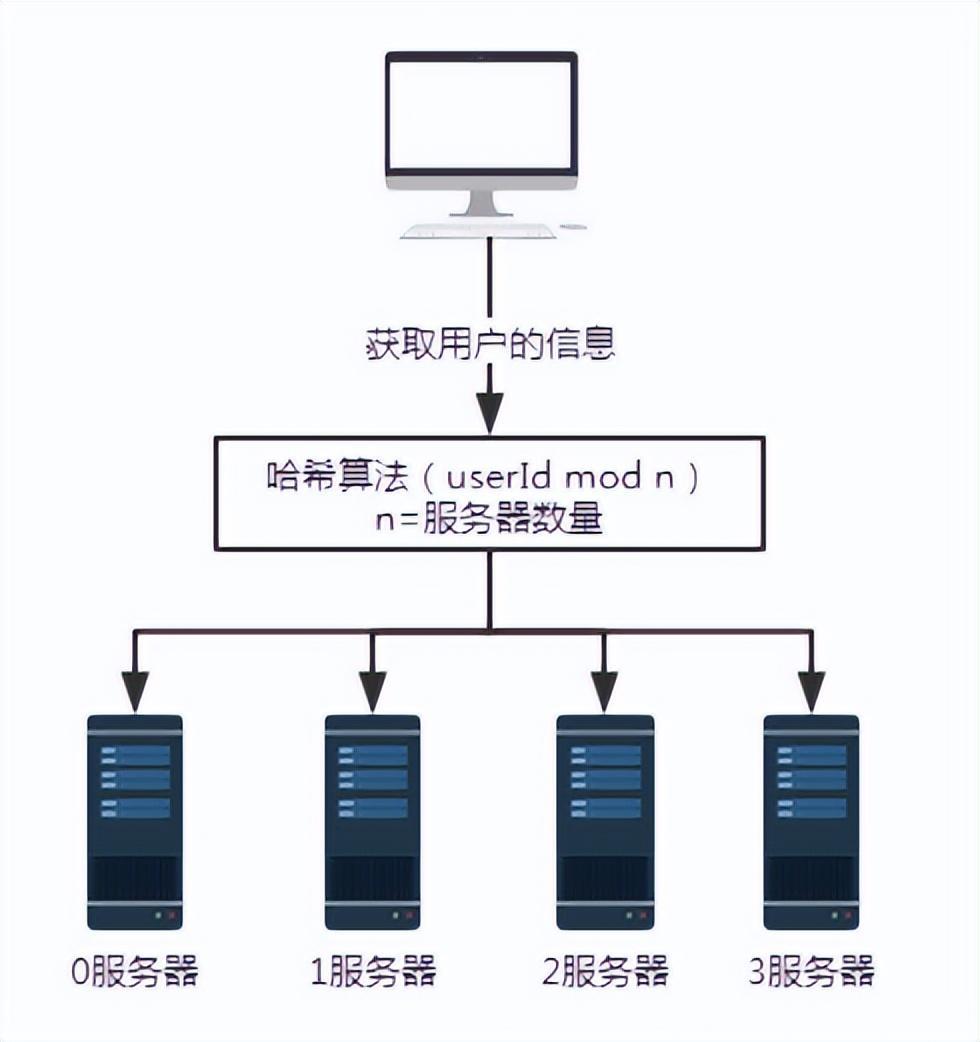
그림 3 서버 추가
문제를 설명하기 위해 서버를 추가합니다. 3. 서버 수 n이 3에서 4로 변경됩니다. 사용자 번호 100으로 사용자 정보를 조회하면 100을 4로 나눈 나머지가 0이 됩니다. 이때 요청은 서버 0에서 수신됩니다.
- 서버 수가 3개인 경우 사용자 번호가 100인 요청은 1번 서버에서 처리됩니다.
- 서버 수가 4개인 경우 사용자 번호 100의 요청은 서버 0에서 처리됩니다.
그래서 서버 수가 늘어나거나 줄어들면 반드시 대량의 데이터 마이그레이션이 수반될 것입니다.
이 해시 알고리즘의 장점은 단순성과 사용 용이성이므로 대부분의 샤딩 규칙이 이를 채택합니다. 일반적으로 파티션 수는 데이터 양에 따라 미리 추정됩니다.
이 기술의 단점은 네트워크의 노드 수가 늘어나거나 줄어들면 노드의 매핑 관계를 다시 계산해야 하므로 데이터 마이그레이션이 필요하다는 것입니다. 따라서 모든 데이터 매핑이 중단되고 전체 마이그레이션이 발생하는 것을 방지하기 위해 용량을 확장할 때 일반적으로 용량을 두 배로 늘리는 것이 사용됩니다.
3. 일관된 해시 알고리즘
** 일관된 해시 알고리즘은 1997년 MIT의 Karger와 그의 동료에 의해 제안되었습니다. 이 알고리즘은 원래 대규모 캐시 시스템의 로드 밸런싱을 위해 제안되었습니다. ** 작동 과정은 다음과 같습니다. 먼저 IP 또는 기타 정보를 기반으로 캐시 노드에 대한 해시가 생성되고 이 해시가 [0, 232 - 1]의 링에 프로젝션됩니다. 쿼리 또는 쓰기 요청이 있을 때마다 캐시 항목의 키에 대한 해시 값이 생성됩니다. 다음으로, 캐시 노드에서 주어진 값보다 크거나 같은 해시 값을 갖는 첫 번째 노드를 찾아 이 노드에 대해 캐시 쿼리나 쓰기 작업을 수행해야 합니다. 현재 노드가 만료되면 다음 캐시 쿼리 또는 쓰기 시 현재 캐시 항목보다 더 큰 해시를 가진 다른 캐시 노드를 조회할 수 있습니다. 일반적인 효과는 아래 그림과 같습니다. 각 캐시 노드는 링에서 한 위치를 차지합니다. 캐시 항목 키의 해시 값이 캐시 노드의 해시 값보다 작으면 캐시 항목이 캐시 노드에 저장되거나 읽혀집니다. 아래 녹색 표시에 해당하는 캐시 항목이 노드 캐시-2에 저장됩니다. 캐시 항목은 원래 Cache-3 노드에 저장될 예정이었으나, 이 노드의 다운타임으로 인해 결국 Cache-4 노드에 저장되었습니다.
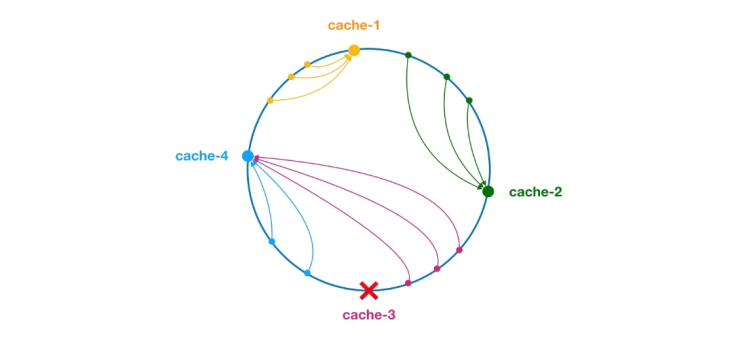
그림 4 일관된 해시 알고리즘
일관적인 해시 알고리즘에서는 노드가 추가되거나 다운되더라도 영향을 받는 범위는 해시 링 공간에서 서버의 증가 또는 다운타임만 발생합니다. 시계 반대 방향으로 회전하면 다른 간격은 영향을 받지 않습니다.
그러나 일관된 해싱에도 문제가 있습니다.
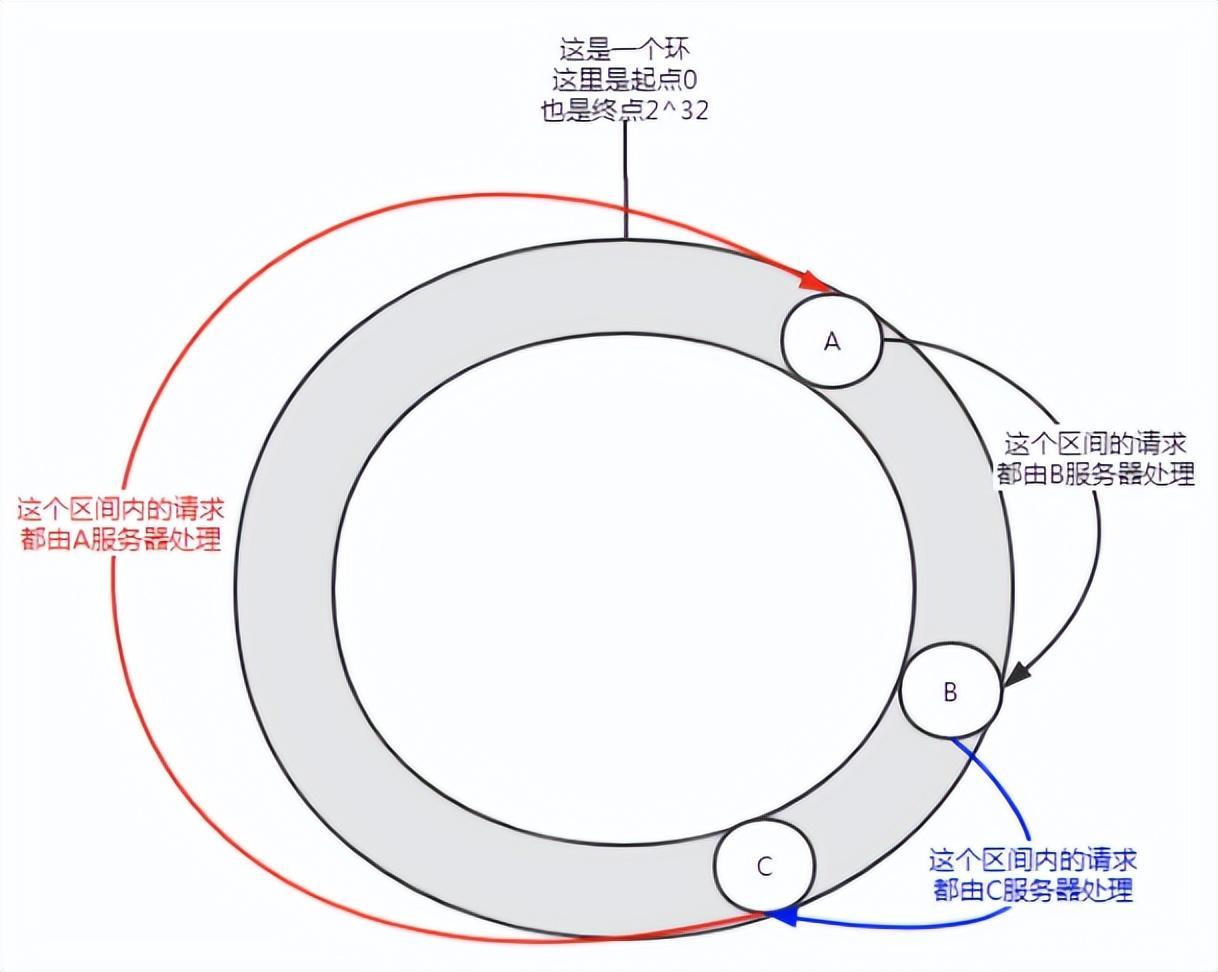
그림 5 데이터 왜곡
노드 수가 적을 때 이러한 배포가 발생할 수 있으며 서비스 A가 대부분의 요청을 처리합니다. 이러한 상황을 데이터 왜곡이라고 합니다.
그렇다면 데이터 왜곡 문제를 어떻게 해결할 수 있을까요?
가상 노드에 참여하세요.
우선, 서버는 필요에 따라 여러 개의 가상 노드를 가질 수 있습니다. 서버에 n개의 가상 노드가 있다고 가정합니다. 해시 계산에서는 IP 주소, 포트 번호, 번호의 조합을 사용하여 해시 값을 계산할 수 있습니다. 숫자는 0부터 n까지의 숫자입니다. 이 n개의 노드는 동일한 IP 주소와 포트 번호를 공유하기 때문에 모두 동일한 시스템을 가리킵니다.
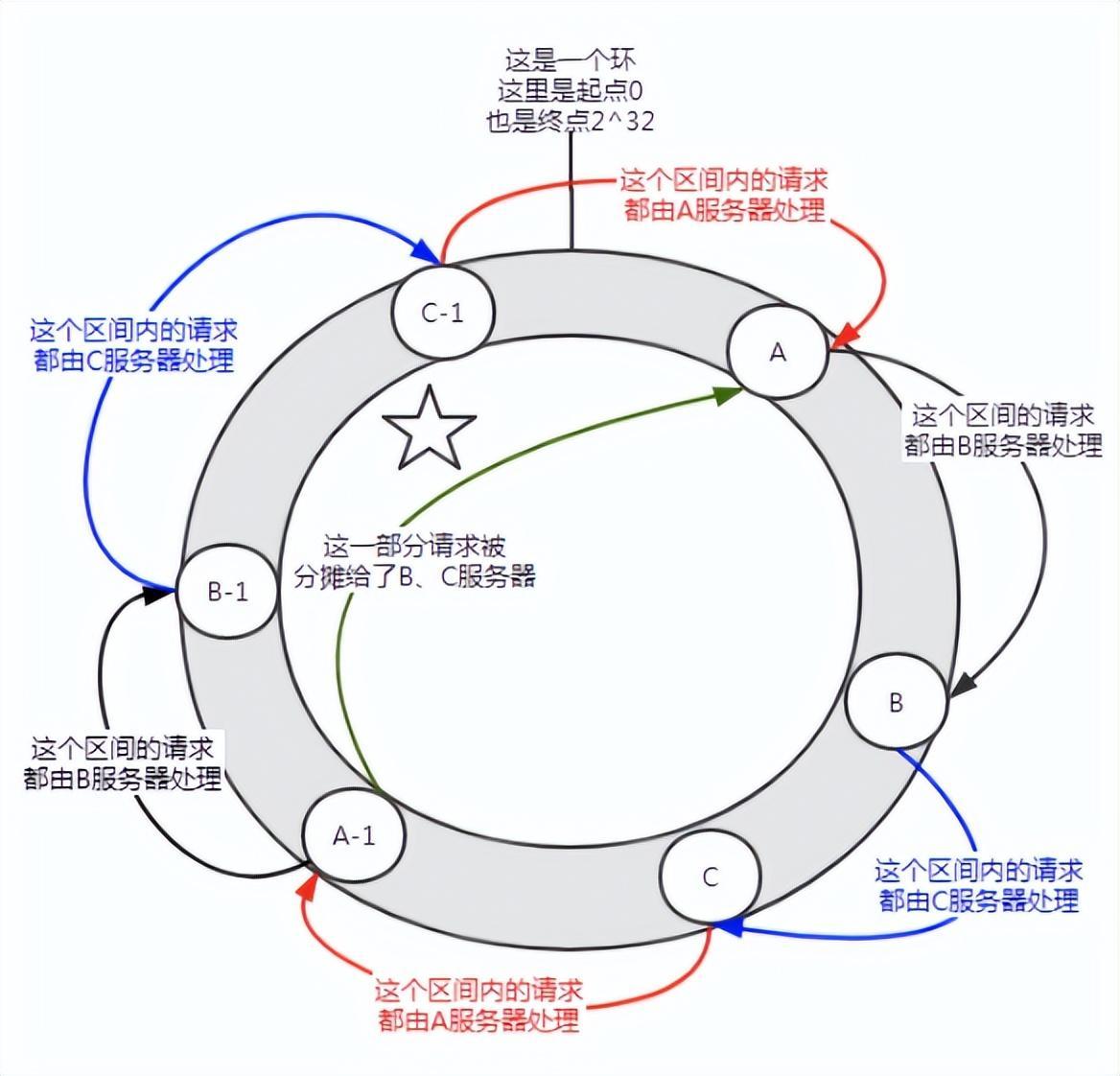
그림 6 가상 노드 소개
가상 노드를 추가하기 전에 서버 A는 대부분의 요청을 처리했습니다. 각 서버에 가상 노드(A-1, B-1, C-1)가 있고, 해시 계산을 통해 위 그림과 같은 위치에 할당된 경우입니다. 그러면 서버 A가 수행한 요청은 B-1 및 C-1 가상 노드에 일정량(그림에서 다섯개 별표로 표시된 부분)에 할당되고, 실제로는 B 및 C 서버에 할당됩니다.
일관된 해싱 알고리즘에서는 가상 노드를 추가하면 데이터 왜곡 문제를 해결할 수 있습니다.
4. DUBBO
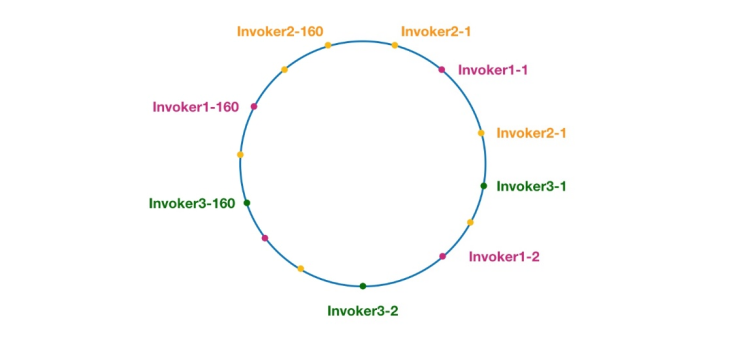
그림 7 Dubbo의 일관된 해싱 링
여기에서 동일한 색상의 노드는 모두 Invoker1-1, Invoker1-2,… 호출자1-160. 가상 노드를 추가하면 해시 링 위에 호출자를 분산시켜 데이터 왜곡 문제를 피할 수 있습니다. 소위 데이터 왜곡은 노드가 충분히 분산되지 않아 동일한 노드에 많은 요청이 떨어지는 상황을 말하며, 다른 노드는 적은 수의 요청만 수신합니다. 예:
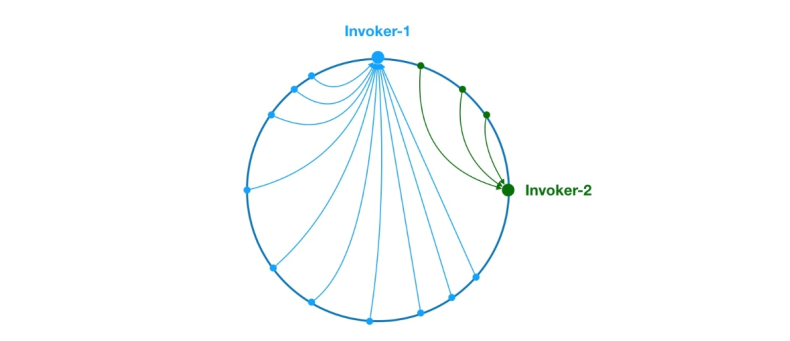
그림 8 데이터 왜곡 문제
위와 같이 링에서 Invoker-1과 Invoker-2의 고르지 않은 분포로 인해 시스템 요청의 75%가 Invoker-1에 속하게 됩니다. 25%만 요청이 Invoker-2에 해당됩니다. 이 문제를 해결하기 위해 가상 노드를 도입하여 각 노드의 요청량 균형을 맞출 수 있습니다.
이제 배경 지식이 대중화되었으니 소스 코드 분석을 시작하겠습니다. 다음과 같이 ConsistentHashLoadBalance의 doSelect 메소드부터 시작하겠습니다.
public class ConsistentHashLoadBalance extends AbstractLoadBalance {private final ConcurrentMap<String, ConsistentHashSelector<?>> selectors = new ConcurrentHashMap<String, ConsistentHashSelector<?>>();@Overrideprotected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {String methodName = RpcUtils.getMethodName(invocation);String key = invokers.get(0).getUrl().getServiceKey() + "." + methodName;// 获取 invokers 原始的 hashcodeint identityHashCode = System.identityHashCode(invokers);ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key);// 如果 invokers 是一个新的 List 对象,意味着服务提供者数量发生了变化,可能新增也可能减少了。// 此时 selector.identityHashCode != identityHashCode 条件成立if (selector == null || selector.identityHashCode != identityHashCode) {// 创建新的 ConsistentHashSelectorselectors.put(key, new ConsistentHashSelector<T>(invokers, methodName, identityHashCode));selector = (ConsistentHashSelector<T>) selectors.get(key);}// 调用 ConsistentHashSelector 的 select 方法选择 Invokerreturn selector.select(invocation);}private static final class ConsistentHashSelector<T> {...}}위와 같이 doSelect 메소드는 주로 호출자 목록이 변경되었는지 감지하고 ConsistencyHashSelector를 생성하는 등의 몇 가지 준비 작업을 수행합니다. 이러한 작업이 완료된 후에는 ConsistencyHashSelector의 select 메서드가 호출되어 로드 밸런싱 논리를 실행합니다. select 메소드를 분석하기 전에 먼저 일관성 있는 해시 선택기인 ConciousHashSelector의 초기화 과정을 다음과 같이 살펴보겠습니다.
private static final class ConsistentHashSelector<T> {// 使用 TreeMap 存储 Invoker 虚拟节点private final TreeMap<Long, Invoker<T>> virtualInvokers;private final int replicaNumber;private final int identityHashCode;private final int[] argumentIndex;ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) {this.virtualInvokers = new TreeMap<Long, Invoker<T>>();this.identityHashCode = identityHashCode;URL url = invokers.get(0).getUrl();// 获取虚拟节点数,默认为160this.replicaNumber = url.getMethodParameter(methodName, "hash.nodes", 160);// 获取参与 hash 计算的参数下标值,默认对第一个参数进行 hash 运算String[] index = Constants.COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, "hash.arguments", "0"));argumentIndex = new int[index.length];for (int i = 0; i < index.length; i++) {argumentIndex[i] = Integer.parseInt(index[i]);}for (Invoker<T> invoker : invokers) {String address = invoker.getUrl().getAddress();for (int i = 0; i < replicaNumber / 4; i++) {// 对 address + i 进行 md5 运算,得到一个长度为16的字节数组byte[] digest = md5(address + i);// 对 digest 部分字节进行4次 hash 运算,得到四个不同的 long 型正整数for (int h = 0; h < 4; h++) {// h = 0 时,取 digest 中下标为 0 ~ 3 的4个字节进行位运算// h = 1 时,取 digest 中下标为 4 ~ 7 的4个字节进行位运算// h = 2, h = 3 时过程同上long m = hash(digest, h);// 将 hash 到 invoker 的映射关系存储到 virtualInvokers 中,// virtualInvokers 需要提供高效的查询操作,因此选用 TreeMap 作为存储结构virtualInvokers.put(m, invoker);}}}}}ConsistentHashSelector 的构造方法执行了一系列的初始化逻辑,比如从配置中获取虚拟节点数以及参与 hash 计算的参数下标,默认情况下只使用第一个参数进行 hash。需要特别说明的是,ConsistentHashLoadBalance 的负载均衡逻辑只受参数值影响,具有相同参数值的请求将会被分配给同一个服务提供者。注意到 ConsistentHashLoadBalance 无需考虑权重的影响。
在获取虚拟节点数和参数下标配置后,接下来要做的事情是计算虚拟节点 hash 值,并将虚拟节点存储到 TreeMap 中。ConsistentHashSelector的初始化工作在此完成。接下来,我们来看看 select 方法的逻辑。
public Invoker<T> select(Invocation invocation) {// 将参数转为 keyString key = toKey(invocation.getArguments());// 对参数 key 进行 md5 运算byte[] digest = md5(key);// 取 digest 数组的前四个字节进行 hash 运算,再将 hash 值传给 selectForKey 方法,// 寻找合适的 Invokerreturn selectForKey(hash(digest, 0));}private Invoker<T> selectForKey(long hash) {// 到 TreeMap 中查找第一个节点值大于或等于当前 hash 的 InvokerMap.Entry<Long, Invoker<T>> entry = virtualInvokers.tailMap(hash, true).firstEntry();// 如果 hash 大于 Invoker 在圆环上最大的位置,此时 entry = null,// 需要将 TreeMap 的头节点赋值给 entryif (entry == null) {entry = virtualInvokers.firstEntry();}// 返回 Invokerreturn entry.getValue();}如上,选择的过程相对比较简单了。首先,需要对参数进行 md5 和 hash 运算,以生成一个哈希值。接着使用这个值去 TreeMap 中查找需要的 Invoker。
到此关于 ConsistentHashLoadBalance 就分析完了。
在阅读 ConsistentHashLoadBalance 源码之前,建议读者先补充背景知识,不然看懂代码逻辑会有很大难度。
五、应用场景
- DNS 负载均衡最早的负载均衡技术是通过 DNS 来实现的,在 DNS 中为多个地址配置同一个名字,因而查询这个名字的客户机将得到其中一个地址,从而使得不同的客户访问不同的服务器,达到负载均衡的目的。DNS 负载均衡是一种简单而有效的方法,但是它不能区分服务器的差异,也不能反映服务器的当前运行状态。
- 代理服务器负载均衡使用代理服务器,可以将请求转发给内部的服务器,使用这种加速模式显然可以提升静态网页的访问速度。然而,也可以考虑这样一种技术,使用代理服务器将请求均匀转发给多台服务器,从而达到负载均衡的目的。
- 地址转换网关负载均衡支持负载均衡的地址转换网关,可以将一个外部 IP 地址映射为多个内部 IP 地址,对每次 TCP 连接请求动态使用其中一个内部地址,达到负载均衡的目的。
- 协议内部支持负载均衡除了这三种负载均衡方式之外,有的协议内部支持与负载均衡相关的功能,例如 HTTP 协议中的重定向能力等,HTTP 运行于 TCP 连接的最高层。
- NAT 负载均衡 NAT(Network Address Translation 网络地址转换)简单地说就是将一个 IP 地址转换为另一个 IP 地址,一般用于未经注册的内部地址与合法的、已获注册的 Internet IP 地址间进行转换。适用于解决 Internet IP 地址紧张、不想让网络外部知道内部网络结构等的场合下。
- 反向代理负载均衡普通代理方式是代理内部网络用户访问 internet 上服务器的连接请求,客户端必须指定代理服务器,并将本来要直接发送到 internet 上服务器的连接请求发送给代理服务器处理。反向代理(Reverse Proxy)方式是指以代理服务器来接受 internet 上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给 internet 上请求连接的客户端,此时代理服务器对外就表现为一个服务器。反向代理负载均衡技术是把将来自 internet 上的连接请求以反向代理的方式动态地转发给内部网络上的多台服务器进行处理,从而达到负载均衡的目的。
- 混合型负载均衡在有些大型网络,由于多个服务器群内硬件设备、各自的规模、提供的服务等的差异,可以考虑给每个服务器群采用最合适的负载均衡方式,然后又在这多个服务器群间再一次负载均衡或群集起来以一个整体向外界提供服务(即把这多个服务器群当做一个新的服务器群),从而达到最佳的性能。将这种方式称之为混合型负载均衡。此种方式有时也用于单台均衡设备的性能不能满足大量连接请求的情况下。
作者:京东物流 乔杰
来源:京东云开发者社区
위 내용은 Dubbo 로드 밸런싱 전략 일관된 해싱의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7322
7322
 9
1625
14
1350
46
1262
25
1209
29
9
1625
14
1350
46
1262
25
1209
29

 Linux 시스템의 TCP/IP 성능 및 네트워크 성능을 최적화하는 방법
Nov 07, 2023 am 11:15 AM
Linux 시스템의 TCP/IP 성능 및 네트워크 성능을 최적화하는 방법
Nov 07, 2023 am 11:15 AM
현대 컴퓨터 분야에서 TCP/IP 프로토콜은 네트워크 통신의 기초입니다. 오픈 소스 운영 체제인 Linux는 많은 기업과 조직에서 선호하는 운영 체제가 되었습니다. 그러나 네트워크 애플리케이션과 서비스가 점점 더 비즈니스의 중요한 구성 요소가 되면서 관리자는 빠르고 안정적인 데이터 전송을 보장하기 위해 네트워크 성능을 최적화해야 하는 경우가 많습니다. 이 기사에서는 Linux 시스템의 TCP/IP 성능과 네트워크 성능을 최적화하여 Linux 시스템의 네트워크 전송 속도를 향상시키는 방법을 소개합니다. 이 기사에서는 다음 사항에 대해 논의할 것입니다.
 Nginx 로드 밸런싱 솔루션의 장애 조치 및 복구 메커니즘
Oct 15, 2023 am 11:14 AM
Nginx 로드 밸런싱 솔루션의 장애 조치 및 복구 메커니즘
Oct 15, 2023 am 11:14 AM
Nginx 로드 밸런싱 솔루션의 장애 조치 및 복구 메커니즘 소개: 로드 밸런싱이 높은 웹 사이트의 경우 로드 밸런싱을 사용하는 것은 웹 사이트의 고가용성을 보장하고 성능을 향상시키는 중요한 수단 중 하나입니다. 강력한 오픈소스 웹 서버로서 Nginx의 로드 밸런싱 기능이 널리 사용되고 있습니다. 로드 밸런싱에서는 장애 조치 및 복구 메커니즘을 구현하는 방법이 고려해야 할 중요한 문제입니다. 이 기사에서는 Nginx 로드 밸런싱의 장애 조치 및 복구 메커니즘을 소개하고 특정 코드 예제를 제공합니다. 1. 장애 조치 메커니즘
 Nginx 로드 밸런싱 솔루션을 위한 고가용성 및 재해 복구 솔루션
Oct 15, 2023 am 11:43 AM
Nginx 로드 밸런싱 솔루션을 위한 고가용성 및 재해 복구 솔루션
Oct 15, 2023 am 11:43 AM
Nginx 로드 밸런싱 솔루션의 고가용성 및 재해 복구 솔루션 인터넷의 급속한 발전으로 인해 웹 서비스의 고가용성은 핵심 요구 사항이 되었습니다. 고가용성과 재해 내성을 달성하기 위해 Nginx는 항상 가장 일반적으로 사용되고 안정적인 로드 밸런서 중 하나였습니다. 이 기사에서는 Nginx의 고가용성 및 재해 복구 솔루션을 소개하고 구체적인 코드 예제를 제공합니다. Nginx의 고가용성은 주로 여러 서버를 사용하여 달성됩니다. 로드 밸런서로서 Nginx는 트래픽을 여러 백엔드 서버로 분산하여
 고가용성 로드 밸런싱 시스템 구축: Nginx Proxy Manager 모범 사례
Sep 27, 2023 am 08:22 AM
고가용성 로드 밸런싱 시스템 구축: Nginx Proxy Manager 모범 사례
Sep 27, 2023 am 08:22 AM
고가용성 로드 밸런싱 시스템 구축: NginxProxyManager 모범 사례 소개: 인터넷 애플리케이션 개발에서 로드 밸런싱 시스템은 필수 구성 요소 중 하나입니다. 여러 서버에 요청을 분산하여 높은 동시성 및 고가용성 서비스를 달성할 수 있습니다. NginxProxyManager는 일반적으로 사용되는 로드 밸런싱 소프트웨어입니다. 이 기사에서는 NginxProxyManager를 사용하여 고가용성 로드 밸런싱 시스템을 구축하고 제공하는 방법을 소개합니다.
 Nginx 로드 밸런싱 솔루션의 동적 장애 감지 및 로드 가중치 조정 전략
Oct 15, 2023 pm 03:54 PM
Nginx 로드 밸런싱 솔루션의 동적 장애 감지 및 로드 가중치 조정 전략
Oct 15, 2023 pm 03:54 PM
Nginx 로드 밸런싱 솔루션의 동적 오류 감지 및 로드 가중치 조정 전략에는 특정 코드 예제가 필요합니다. 소개 높은 동시성 네트워크 환경에서 로드 밸런싱은 웹 사이트의 가용성과 성능을 효과적으로 향상시킬 수 있는 일반적인 솔루션입니다. Nginx는 강력한 로드 밸런싱 기능을 제공하는 오픈 소스 고성능 웹 서버입니다. 이 기사에서는 Nginx 로드 밸런싱의 두 가지 중요한 기능인 동적 오류 감지 및 로드 가중치 조정 전략을 소개하고 구체적인 코드 예제를 제공합니다. 1. 동적 장애 감지 동적 장애 감지
 Java 프레임워크 성능 최적화에 로드 밸런싱 전략 적용
May 31, 2024 pm 08:02 PM
Java 프레임워크 성능 최적화에 로드 밸런싱 전략 적용
May 31, 2024 pm 08:02 PM
로드 밸런싱 전략은 효율적인 요청 배포를 위해 Java 프레임워크에서 매우 중요합니다. 동시성 상황에 따라 다양한 전략의 성능이 다릅니다. 폴링 방법: 낮은 동시성에서 안정적인 성능. 가중 폴링 방법: 낮은 동시성에서 성능은 폴링 방법과 유사합니다. 최소 연결 수 방법: 높은 동시성에서 최고의 성능을 발휘합니다. 무작위 방법: 간단하지만 성능이 좋지 않습니다. 일관된 해싱: 서버 로드 균형을 조정합니다. 실제 사례와 결합하여 이 기사에서는 성능 데이터를 기반으로 적절한 전략을 선택하여 애플리케이션 성능을 크게 향상시키는 방법을 설명합니다.
 exe에서 php로: 기능 확장을 위한 효과적인 전략
Mar 04, 2024 pm 09:36 PM
exe에서 php로: 기능 확장을 위한 효과적인 전략
Mar 04, 2024 pm 09:36 PM
EXE에서 PHP로: 기능 확장을 위한 효과적인 전략 인터넷의 발전과 함께 더 많은 사용자 액세스와 더 편리한 작업을 위해 점점 더 많은 응용 프로그램이 웹으로 마이그레이션되기 시작했습니다. 이 과정에서 원래 EXE(실행 파일)로 실행되는 기능을 PHP 스크립트로 변환하려는 요구도 점차 늘어나고 있다. 이 기사에서는 기능 확장을 위해 EXE를 PHP로 변환하는 방법에 대해 설명하고 구체적인 코드 예제를 제공합니다. EXE를 PHP 크로스 플랫폼으로 변환하는 이유: PHP는 크로스 플랫폼 언어입니다.
 Nginx 로드 밸런싱 솔루션의 백엔드 서버 상태 확인 및 동적 조정
Oct 15, 2023 am 11:37 AM
Nginx 로드 밸런싱 솔루션의 백엔드 서버 상태 확인 및 동적 조정
Oct 15, 2023 am 11:37 AM
Nginx 로드 밸런싱 솔루션의 백엔드 서버 상태 확인 및 동적 조정에는 특정 코드 예제가 필요합니다. 요약: Nginx 로드 밸런싱 솔루션에서 백엔드 서버의 상태는 중요한 고려 사항입니다. 이 기사에서는 Nginx의 상태 확인 모듈과 동적 조정 모듈을 사용하여 백엔드 서버의 상태 확인 및 동적 조정을 구현하는 방법을 소개하고 구체적인 코드 예제를 제공합니다. 소개 최신 애플리케이션 아키텍처에서 로드 밸런싱은 애플리케이션 성능과 안정성을 향상시키기 위해 일반적으로 사용되는 솔루션 중 하나입니다. 응기
