
 기술 주변기기
일체 포함
NTU와 Shanghai AI Lab은 300개 이상의 논문을 편집했습니다. Transformer를 기반으로 한 시각적 분할에 대한 최신 리뷰가 공개되었습니다.
기술 주변기기
일체 포함
NTU와 Shanghai AI Lab은 300개 이상의 논문을 편집했습니다. Transformer를 기반으로 한 시각적 분할에 대한 최신 리뷰가 공개되었습니다.
NTU와 Shanghai AI Lab은 300개 이상의 논문을 편집했습니다. Transformer를 기반으로 한 시각적 분할에 대한 최신 리뷰가 공개되었습니다.

SAM(Segment Anything)은 기본적인 시각적 분할 모델로 불과 3개월 만에 많은 연구자들의 관심과 후속 연구를 이끌어냈습니다. SAM 이면의 기술을 체계적으로 이해하고, 혁신의 속도를 따라가고, 자신만의 SAM 모델을 만들고 싶다면 이 Transformer-Based Segmentation Survey를 놓치지 마세요! 최근 Nanyang Technological University와 Shanghai Artificial Intelligence Laboratory의 여러 연구원이 Transformer 기반 분할에 대한 리뷰를 작성하여 최근 몇 년 동안 Transformer 기반 분할 및 감지 모델을 체계적으로 검토했습니다. 조사된 최신 모델은 올해 6월까지입니다! 동시에 리뷰에는 관련 분야의 최신 논문과 다수의 실험 분석 및 비교가 포함되어 있으며, 폭넓은 전망을 갖춘 다수의 향후 연구 방향이 밝혀졌습니다!
시각적 분할은 이미지, 비디오 프레임 또는 포인트 클라우드를 여러 세그먼트나 그룹으로 분할하도록 설계되었습니다. 이 기술은 자율주행, 이미지 편집, 로봇 인식, 의료 분석 등 실생활에 많이 적용됩니다. 지난 10년 동안 딥러닝 기반 방법은 이 분야에서 상당한 발전을 이루었습니다. 최근 Transformer는 원래 자연어 처리를 위해 설계된 self-attention 메커니즘을 기반으로 하는 신경망이 되었으며, 이는 다양한 시각적 처리 작업에서 이전의 컨벌루션 또는 반복 방법을 크게 능가합니다. 특히 Vision Transformer는 다양한 세분화 작업을 위한 강력하고 통합되며 더욱 간단한 솔루션을 제공합니다. 이 리뷰는 Transformer 기반 시각적 분할에 대한 포괄적인 개요를 제공하고 최근 발전을 요약합니다. 먼저, 이 논문에서는 문제 정의, 데이터 세트 및 이전 컨볼루션 방법을 포함한 배경을검토합니다. 다음으로, 이 문서에서는 최신 Transformer 기반 방법을 모두 통합하는 메타 아키텍처를 요약합니다. 이 문서에서는 이 메타 아키텍처를 기반으로 이 메타 아키텍처 및 관련 애플리케이션에 대한 수정을 포함하여 다양한 방법 설계를 연구합니다. 또한 이 문서에서는 3D 포인트 클라우드 분할, 기본 모델 조정, 도메인 적응형 분할, 효율적인 분할 및 의료 분할을 포함한 여러 관련 설정도 소개합니다. 또한 이 문서에서는 널리 알려진 여러 데이터 세트에서 이러한 방법을 컴파일하고 재평가합니다. 마지막으로, 이 논문은 이 분야의 열린 과제를 식별하고 향후 연구 방향을 제안합니다. 이 기사에서는 계속해서 최신 Transformer 기반 분할 및 탐지 방법을 추적합니다.
Pictures 프로젝트 주소: https://github.com/lxtGH/Awesome-Segmentation-With-Transformer
프로젝트 주소: https://github.com/lxtGH/Awesome-Segmentation-With-Transformer
논문 주소: https://arxiv.org/pdf/2304.09854.pdf
연구 동기
ViT와 DETR의 출현으로 분할 및 탐지 분야에서 완전한 발전이 이루어졌습니다. 현재 거의 모든 데이터 세트 벤치마크에서 상위권에 있는 방법은 Transformer를 기반으로 합니다. 그렇기 때문에 이 방향의 방식과 기술적 특징을 체계적으로 요약하고 비교할 필요가 있다.
- 최근 대형 모델 아키텍처는 다중 모드 모델, 분할 기본 모델(SAM) 등 모두 Transformer 구조를 기반으로 하며, 다양한 시각적 작업이 통합 모델 모델링에 가까워지고 있습니다.
- 분할 및 감지를 통해 많은 관련 다운스트림 작업이 파생되었으며 이러한 작업 중 상당수도 Transformer 구조를 사용하여 해결됩니다.
- 검토 기능
- 체계적이고 읽기 쉽습니다.
- 이 기사에서는 세분화의 각 작업 정의와 관련 작업 정의 및 평가 지표를 체계적으로 검토합니다. 그리고 이 글은 컨볼루션 방법에서 시작하여 ViT와 DETR 기반의 메타 아키텍처를 요약한다. 본 리뷰에서는 이러한 메타 아키텍처를 기반으로 관련 방법들을 정리, 정리하고 최신 방법들을 체계적으로 검토한다. 구체적인 기술 검토 경로는 그림 1에 나와 있습니다. 기술적인 관점에서 세밀하게 분류한 것입니다.
- 이전 Transformer 리뷰와 비교하여 이 기사의 방법 분류가 더 자세히 설명됩니다. 이 기사에서는 유사한 아이디어를 가진 논문을 모아서 유사점과 차이점을 비교합니다. 예를 들어, 이 기사에서는 메타 아키텍처의 디코더 측면을 이미지 기반 Cross Attention과 비디오 기반 시공간 Cross Attention 모델링으로 동시에 수정하는 방법을 분류합니다. 연구 질문의 포괄성.
- 이 글에서는 이미지, 비디오, 포인트 클라우드 분할 작업을 포함한 분할의 모든 방향을 체계적으로 검토합니다. 동시에 이 기사에서는 개방형 분할 및 탐지 모델, 비지도 분할 및 약한 지도 분할과 같은 관련 방향도 검토합니다.
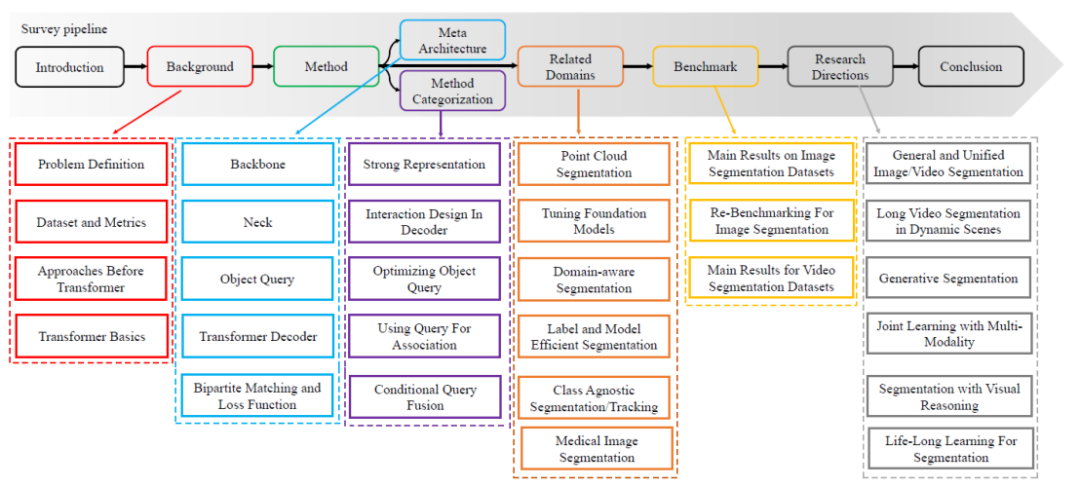 그림 1. 설문조사 콘텐츠 로드맵
그림 1. 설문조사 콘텐츠 로드맵
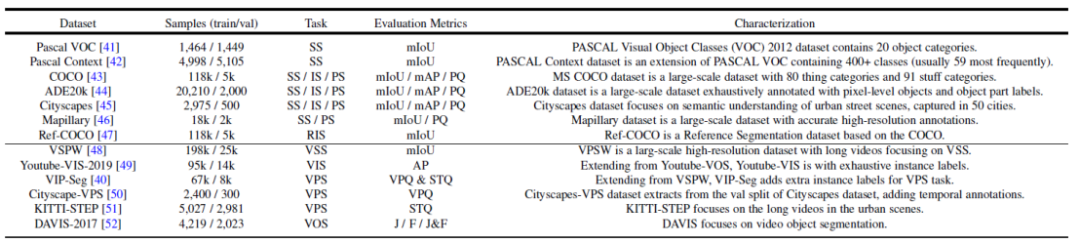
그림 2. 일반적으로 사용되는 데이터 세트 및 분할 작업 요약
Transformer 기반 분할 및 탐지 방법 요약 및 비교
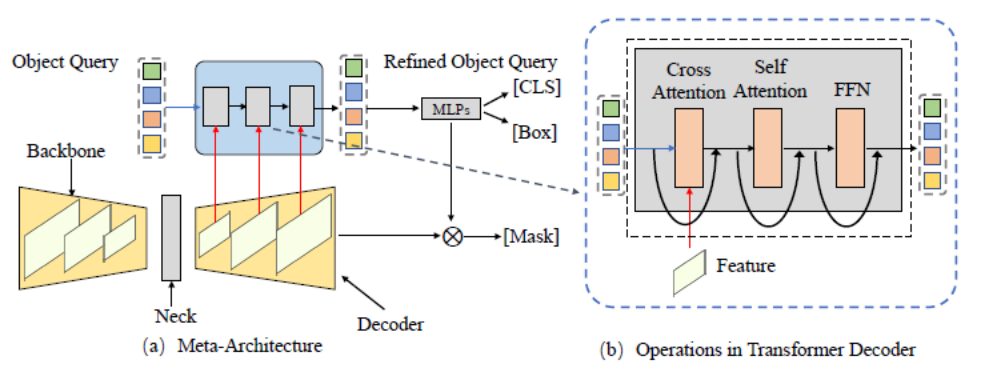
그림 3. 일반 메타 아키텍처 프레임워크(Meta - 아키텍처)
이 기사에서는 먼저 DETR 및 MaskFormer 프레임워크를 기반으로 한 메타 아키텍처를 요약합니다. 이 모델에는 다음과 같은 다양한 모듈이 포함되어 있습니다.
- 백본: 이미지 특징을 추출하는 데 사용되는 특징 추출기.
- 목: 다중 규모의 물체를 처리할 수 있는 다중 규모 기능을 구축하세요.
- 객체 쿼리: 쿼리 객체는 전경 객체와 배경 객체를 포함하여 장면의 각 엔터티를 나타내는 데 사용됩니다.
- 디코더: 디코더, 개체 쿼리 및 해당 기능을 점진적으로 최적화하는 데 사용됩니다.
- 엔드 투 엔드 교육: 객체 쿼리를 기반으로 한 디자인은 엔드 투 엔드 최적화를 달성할 수 있습니다.
이 메타 아키텍처를 기반으로 기존 방법은 작업에 따른 최적화 및 조정을 위해 다음과 같은 5가지 방향으로 나눌 수 있습니다. 그림 4에서 볼 수 있듯이 각 방향에는 여러 가지 하위 방향이 포함되어 있습니다.
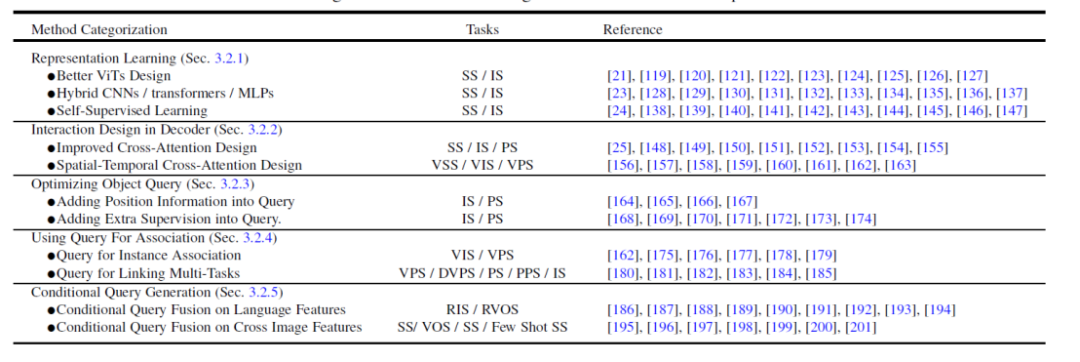
그림 4. 변환기 기반 분할 방법의 요약 및 비교
- 더 나은 기능 표현 학습, 표현 학습. 강력한 시각적 특징 표현은 항상 더 나은 분할 결과로 이어집니다. 이 기사에서는 관련 작업을 더 나은 시각적 Transformer 설계, 하이브리드 CNN/Transformer/MLP 및 자기 지도 학습의 세 가지 측면으로 나눕니다.
- 디코더 측의 메소드 디자인, 디코더의 인터랙션 디자인. 이 장에서는 새로운 Transformer 디코더 디자인을 검토합니다. 본 논문에서는 디코더 설계를 두 그룹으로 나눕니다. 하나는 이미지 분할에서 교차 주의 설계를 개선하는 데 사용되고, 다른 하나는 비디오 분할에서 시공간 교차 주의 설계를 개선하는 데 사용됩니다. 전자는 원래 DETR의 디코더를 개선하는 더 나은 디코더를 설계하는 데 중점을 둡니다. 후자는 쿼리 객체 기반 객체 감지기와 분할기를 비디오 객체 감지(VOD), 비디오 인스턴스 분할(VIS) 및 비디오 픽셀 분할(VPS)을 위한 비디오 도메인으로 확장하여 시간적 일관성 및 상관 성별 모델링에 중점을 둡니다.
- 쿼리 객체 최적화 관점에서 객체 쿼리 최적화를 시도해보세요. Faster-RCNN에 비해 DETR은 수렴 시간표가 더 깁니다. 쿼리 개체의 핵심 역할로 인해 훈련 속도를 높이고 성능을 향상시키기 위해 일부 기존 방법이 연구되었습니다. 본 논문에서는 객체 질의 방법에 따라 다음과 같은 문헌을 위치 정보 추가와 추가 감독 활용이라는 두 가지 측면으로 나눈다. 위치 정보는 쿼리 특징의 빠른 학습 샘플링에 대한 단서를 제공합니다. 추가 감독은 DETR 기본 손실 기능 외에도 특정 손실 기능 설계에 중점을 둡니다.
- 연결 쿼리를 사용하여 쿼리 개체를 사용하여 기능과 인스턴스를 연결합니다. 쿼리 개체의 단순성 이점을 활용하여 최근의 여러 연구에서는 쿼리 개체를 다운스트림 작업을 해결하기 위한 상관 관계 도구로 사용했습니다. 두 가지 주요 용도가 있습니다. 하나는 인스턴스 수준 연결이고 다른 하나는 작업 수준 연결입니다. 전자는 인스턴스 판별이라는 아이디어를 활용하여 비디오 분할, 추적 등 비디오의 인스턴스 수준 매칭 문제를 해결합니다. 후자는 효율적인 다중 작업 학습을 달성하기 위해 쿼리 개체를 사용하여 다양한 하위 작업을 연결합니다.
- 다중 모드 조건부 쿼리 개체 생성, 조건부 쿼리 생성. 이 장에서는 주로 다중 모드 분할 작업에 중점을 둡니다. 조건부 쿼리 쿼리 개체는 주로 모달 간 및 이미지 간 기능 일치 작업을 처리하는 데 사용됩니다. 작업 입력 조건에 따라 디코더 헤드는 서로 다른 쿼리를 사용하여 해당 분할 마스크를 얻습니다. 다양한 입력 소스에 따라 본 논문에서는 이러한 작품을 언어 특성과 이미지 특성이라는 두 가지 측면으로 나눕니다. 이러한 방법은 쿼리 개체를 다양한 모델 기능과 융합하는 전략을 기반으로 하며 다중 다중 모드 분할 작업 및 소수 샷 분할에서 좋은 결과를 얻었습니다.
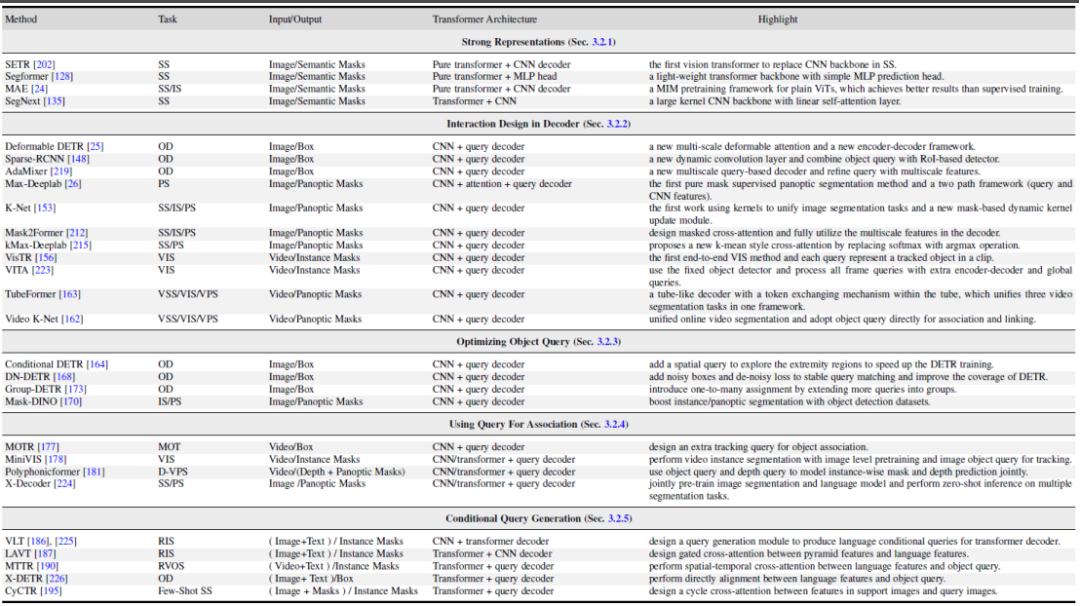
그림 5는 이러한 5가지 방향의 대표적인 작업 비교를 보여줍니다. 보다 구체적인 방법 세부 정보 및 비교는 논문에서 확인할 수 있습니다.
 Pictures
Pictures
그림 5. Transformer 기반 세분화 및 탐지 대표 방법의 요약 및 비교
관련 연구 분야의 방법 요약 및 비교
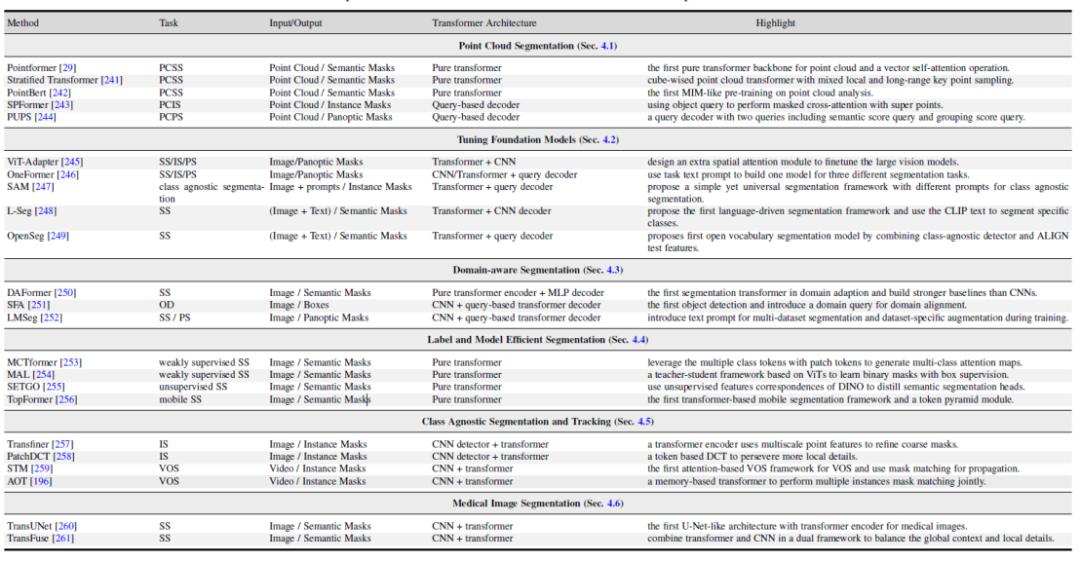
이 기사에서는 여러 관련 분야도 살펴봅니다. 1. 변환기 기반 포인트 클라우드 분할 방법. 2. 비전 및 다중 모드 대형 모델 튜닝. 3. 도메인 전이 학습, 도메인 일반화 학습을 포함한 도메인 관련 분할 모델에 대한 연구. 4. 효율적인 의미론적 분할: 비지도 및 약한 지도 분할 모델. 5. 클래스 독립적 분할 및 추적. 6. 의료영상 분할.
 Pictures
Pictures
Figure 6. 관련 연구 분야의 Transformer 기반 방법 요약 및 비교
다양한 방법의 실험 결과 비교
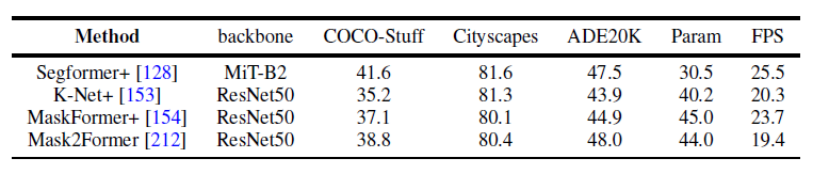
Figure 7. 의미론에 대한 벤치마크 실험 분할 데이터세트
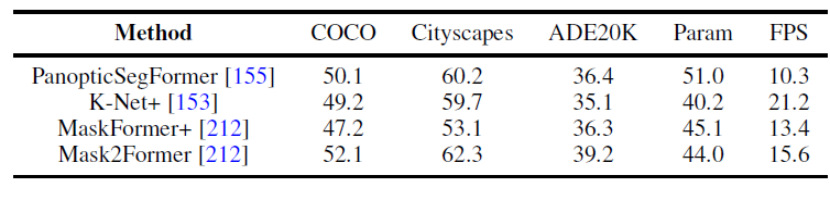
그림 8. 파노라마 분할 데이터세트의 벤치마크 실험
이 기사에서는 파노라마 분할 및 의미론적 분할에 대한 여러 데이터 세트에 대한 여러 대표적인 연구 결과를 비교하기 위해 동일한 실험 설계 조건을 균일하게 사용합니다. 동일한 훈련 전략과 인코더를 사용하면 방법 성능 간의 격차가 좁아지는 것으로 나타났습니다.
또한 이 기사에서는 여러 다른 데이터 세트 및 작업에 대한 최신 Transformer 기반 분할 방법의 결과를 비교합니다. (의미론적 분할, 인스턴스 분할, 파노라마 분할 및 해당 비디오 분할 작업)
Future Directions
또한 이 기사에서는 가능한 미래 연구 방향에 대한 분석도 제공합니다. 여기에는 세 가지 다른 방향이 예로 제시되어 있습니다.
- Update범용적이고 통합된 세분화 모델을 추가하세요. Transformer 구조를 사용하여 다양한 분할 작업을 통합하는 것이 추세입니다. 최근 연구에서는 쿼리 개체 기반 변환기를 사용하여 하나의 아키텍처에서 다양한 분할 작업을 수행합니다. 가능한 연구 방향 중 하나는 하나의 모델을 통해 다양한 분할 데이터 세트에 대한 이미지 및 비디오 분할 작업을 통합하는 것입니다. 이러한 일반 모델은 다양한 시나리오에서 다양하고 강력한 분할을 달성할 수 있습니다. 예를 들어, 다양한 시나리오에서 희귀한 범주를 감지하고 분할하면 로봇이 더 나은 결정을 내리는 데 도움이 됩니다.
- 시각적 추론과 결합된 분할 모델입니다. 시각적 추론을 위해서는 로봇이 장면에 있는 객체 간의 연결을 이해해야 하며, 이러한 이해는 모션 계획에서 중요한 역할을 합니다. 이전 연구에서는 객체 추적 및 장면 이해와 같은 다양한 애플리케이션을 위한 시각적 추론 모델에 대한 입력으로 분할 결과를 사용하는 방법을 연구했습니다. 공동 분할과 시각적 추론은 분할과 관계형 분류 모두에 대해 상호 이익이 되는 잠재력을 지닌 유망한 방향이 될 수 있습니다. 분할 프로세스에 시각적 추론을 통합함으로써 연구자는 추론의 힘을 활용하여 분할 정확도를 향상시킬 수 있으며, 분할 결과는 시각적 추론을 위한 더 나은 입력을 제공할 수도 있습니다.
- 지속학습의 분할 모델 연구. 기존 세분화 방법은 일반적으로 사전 정의된 범주 집합이 있는 폐쇄형 데이터 세트에서 벤치마킹됩니다. 즉, 훈련 샘플과 테스트 샘플이 동일한 범주와 사전에 알려진 기능 공간을 갖는다고 가정합니다. 그러나 실제 시나리오는 개방적이고 불안정한 경우가 많으며 새로운 데이터 범주가 지속적으로 나타날 수 있습니다. 예를 들어 자율주행차나 의료 진단 분야에서는 예상치 못한 상황이 갑자기 발생할 수 있습니다. 실제 시나리오와 폐쇄형 시나리오에서 기존 방법의 성능과 기능 간에는 분명한 차이가 있습니다. 따라서 새로운 개념이 세분화 모델의 기존 지식 기반에 점진적이고 지속적으로 통합되어 모델이 평생 학습에 참여할 수 있기를 기대합니다.
자세한 연구방향은 원문을 참고해주세요.
위 내용은 NTU와 Shanghai AI Lab은 300개 이상의 논문을 편집했습니다. Transformer를 기반으로 한 시각적 분할에 대한 최신 리뷰가 공개되었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7467
7467
 15
1376
52
77
11
48
19
19
22
15
1376
52
77
11
48
19
19
22

 Stable Diffusion 3 논문이 드디어 공개되고, 아키텍처의 세부 사항이 공개되어 Sora를 재현하는 데 도움이 될까요?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3 논문이 드디어 공개되고, 아키텍처의 세부 사항이 공개되어 Sora를 재현하는 데 도움이 될까요?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3의 논문이 드디어 나왔습니다! 이 모델은 2주 전에 출시되었으며 Sora와 동일한 DiT(DiffusionTransformer) 아키텍처를 사용합니다. 출시되자마자 큰 화제를 불러일으켰습니다. 이전 버전과 비교하여 StableDiffusion3에서 생성된 이미지의 품질이 크게 향상되었습니다. 이제 다중 테마 프롬프트를 지원하고 텍스트 쓰기 효과도 향상되었으며 더 이상 잘못된 문자가 표시되지 않습니다. StabilityAI는 StableDiffusion3이 800M에서 8B 범위의 매개변수 크기를 가진 일련의 모델임을 지적했습니다. 이 매개변수 범위는 모델이 많은 휴대용 장치에서 직접 실행될 수 있어 AI 사용이 크게 줄어든다는 것을 의미합니다.
 ICCV'23 논문상 'Fighting of Gods'! Meta Divide Everything과 ControlNet이 공동 선정되었는데, 심사위원들을 놀라게 한 기사가 또 있었습니다.
Oct 04, 2023 pm 08:37 PM
ICCV'23 논문상 'Fighting of Gods'! Meta Divide Everything과 ControlNet이 공동 선정되었는데, 심사위원들을 놀라게 한 기사가 또 있었습니다.
Oct 04, 2023 pm 08:37 PM
프랑스 파리에서 열린 최고의 컴퓨터 비전 컨퍼런스 ICCV2023이 막 끝났습니다! 올해 최우수 논문상은 그야말로 '신들의 싸움'이다. 예를 들어 최우수 논문상을 수상한 두 논문에는 빈센트 그래프 AI 분야를 전복한 작품인 ControlNet이 포함됐다. 오픈 소스 이후 ControlNet은 GitHub에서 24,000개의 별을 받았습니다. 확산 모델이든, 컴퓨터 비전 전체 분야이든, 이 논문의 수상은 당연한 것입니다. 최우수 논문상에 대한 명예로운 언급은 또 다른 유명한 논문인 Meta의 "Separate Everything" "Model SAM에 수여되었습니다. "Segment Everything"은 출시 이후 뒤에서 나온 모델을 포함해 다양한 이미지 분할 AI 모델의 "벤치마크"가 되었습니다.
 NeRF와 자율주행의 과거와 현재, 10편에 가까운 논문 요약!
Nov 14, 2023 pm 03:09 PM
NeRF와 자율주행의 과거와 현재, 10편에 가까운 논문 요약!
Nov 14, 2023 pm 03:09 PM
Neural Radiance Fields가 2020년에 제안된 이후 관련 논문의 수가 기하급수적으로 늘어났습니다. 이는 3차원 재구성의 중요한 분야가 되었을 뿐만 아니라 자율 주행을 위한 중요한 도구로서 연구 분야에서도 점차 활발해졌습니다. NeRF는 지난 2년 동안 갑자기 등장했습니다. 주로 특징점 추출 및 일치, 에피폴라 기하학 및 삼각측량, PnP 및 번들 조정 및 기존 CV 재구성 파이프라인의 기타 단계를 건너뛰고 메쉬 재구성, 매핑 및 광 추적도 건너뛰기 때문입니다. , 2D에서 직접 입력된 이미지를 이용해 방사선장을 학습한 후, 방사선장에서 실제 사진에 가까운 렌더링 이미지를 출력합니다. 즉, 신경망을 기반으로 한 암시적 3차원 모델을 지정된 관점에 맞추도록 합니다.
 확산 모델을 사용하여 종이 일러스트레이션을 자동으로 생성할 수도 있으며 ICLR에서도 허용됩니다.
Jun 27, 2023 pm 05:46 PM
확산 모델을 사용하여 종이 일러스트레이션을 자동으로 생성할 수도 있으며 ICLR에서도 허용됩니다.
Jun 27, 2023 pm 05:46 PM
생성형 AI(Generative AI)는 인공 지능 커뮤니티를 휩쓸었습니다. 개인과 기업 모두 Vincent 사진, Vincent 비디오, Vincent 음악 등과 같은 관련 모달 변환 애플리케이션을 만드는 데 열중하기 시작했습니다. 최근 ServiceNow Research, LIVIA 등 과학 연구 기관의 여러 연구자들이 텍스트 설명을 기반으로 논문에서 차트를 생성하려고 시도했습니다. 이를 위해 그들은 FigGen이라는 새로운 방법을 제안했고, 관련 논문도 ICLR2023에 TinyPaper로 포함됐다. 그림 논문 주소: https://arxiv.org/pdf/2306.00800.pdf 어떤 사람들은 '논문에서 차트를 생성하는 데 무엇이 그렇게 어렵나요?'라고 묻습니다. 이것이 과학 연구에 어떻게 도움이 됩니까?
 채팅 스크린샷을 통해 AI 리뷰의 숨겨진 규칙을 밝혀보세요! AAAI 3000위안은 강력하게 받아들여집니까?
Apr 12, 2023 am 08:34 AM
채팅 스크린샷을 통해 AI 리뷰의 숨겨진 규칙을 밝혀보세요! AAAI 3000위안은 강력하게 받아들여집니까?
Apr 12, 2023 am 08:34 AM
AAAI 2023 논문 제출 마감일이 다가오던 무렵, AI 제출 그룹의 익명 채팅 스크린샷이 갑자기 Zhihu에 나타났습니다. 그 중 한 명은 "3000위안 강력한 수락" 서비스를 제공할 수 있다고 주장했습니다. 해당 소식이 알려지자 네티즌들은 곧바로 공분을 샀다. 그러나 아직 서두르지 마십시오. Zhihu 상사 "Fine Tuning"은 이것이 아마도 "언어적 즐거움"일 가능성이 높다고 말했습니다. 『파인튜닝』에 따르면 인사와 갱범죄는 어느 분야에서나 피할 수 없는 문제다. openreview의 등장으로 cmt의 다양한 단점이 점점 더 명확해졌습니다. 앞으로는 작은 서클이 운영할 수 있는 공간은 더 작아지겠지만 항상 여유가 있을 것입니다. 이는 개인적인 문제이지 투고 시스템이나 메커니즘의 문제가 아니기 때문입니다. 오픈R을 소개합니다
 CVPR 2023 순위 공개, 합격률 25.78%! 2,360편의 논문이 접수되었고, 제출 건수는 9,155편으로 급증했습니다.
Apr 13, 2023 am 09:37 AM
CVPR 2023 순위 공개, 합격률 25.78%! 2,360편의 논문이 접수되었고, 제출 건수는 9,155편으로 급증했습니다.
Apr 13, 2023 am 09:37 AM
방금 CVPR 2023에서는 다음과 같은 기사를 발표했습니다. 올해 우리는 기록적인 9,155편의 논문을 접수했으며(CVPR2022보다 12% 더 많음), 2,360편의 논문을 접수했으며 합격률은 25.78%입니다. 통계에 따르면 2010년부터 2016년까지 7년간 CVPR 제출 건수는 1,724건에서 2,145건으로 증가하는 데 그쳤다. 2017년 이후 급등하며 급속한 성장기에 접어들었고, 2019년에는 처음으로 5,000건을 돌파했고, 2022년에는 투고 건수가 8,161건에 이르렀다. 보시다시피 올해 총 9,155편의 논문이 제출되어 역대 최고 기록을 세웠습니다. 전염병이 완화된 후 올해 CVPR 정상회담은 캐나다에서 개최될 예정입니다. 올해는 단일 트랙 컨퍼런스 형식을 채택하고 기존 구술 선발 방식을 폐지한다. 구글 조사
 중국팀이 최우수 논문상과 최우수 시스템 논문상을 수상하며 CoRL 연구 결과가 발표됐다.
Nov 10, 2023 pm 02:21 PM
중국팀이 최우수 논문상과 최우수 시스템 논문상을 수상하며 CoRL 연구 결과가 발표됐다.
Nov 10, 2023 pm 02:21 PM
CoRL은 2017년 처음 개최된 이후 로봇공학과 머신러닝이 교차하는 분야에서 세계 최고의 학술 컨퍼런스 중 하나로 자리매김했습니다. CoRL은 이론과 응용을 포함하여 로봇공학, 기계학습, 제어 등 다양한 주제를 다루는 로봇학습 연구를 위한 단일 주제 컨퍼런스입니다. 2023 CoRL 컨퍼런스는 11월 6일부터 9일까지 미국 애틀랜타에서 개최됩니다. 공식 자료에 따르면 올해 CoRL에는 25개국 199편의 논문이 선정됐다. 인기 있는 주제로는 운영, 강화 학습 등이 있습니다. CoRL은 AAAI, CVPR 등 대규모 AI 학술회의에 비해 규모는 작지만, 올해 대형 모델, 체화된 지능, 휴머노이드 로봇 등 개념의 인기가 높아지면서 관련 연구도 주목할 만하다.
 Microsoft의 새로운 핫 페이퍼: Transformer가 10억 개의 토큰으로 확장됩니다.
Jul 22, 2023 pm 03:34 PM
Microsoft의 새로운 핫 페이퍼: Transformer가 10억 개의 토큰으로 확장됩니다.
Jul 22, 2023 pm 03:34 PM
모든 사람이 계속해서 자신의 대형 모델을 업그레이드하고 반복함에 따라 컨텍스트 창을 처리하는 LLM(대형 언어 모델)의 능력도 중요한 평가 지표가 되었습니다. 예를 들어, 스타 모델 GPT-4는 50페이지의 텍스트에 해당하는 32k 토큰을 지원합니다. OpenAI의 전 멤버가 설립한 Anthropic은 Claude의 토큰 처리 능력을 약 75,000단어에 해당하는 100k로 늘렸습니다. "해리포터"를 한 번의 클릭으로 요약하는 것과 같습니다. "First. Microsoft의 최신 연구에서는 이번에 Transformer를 10억 개의 토큰으로 직접 확장했습니다. 이는 전체 코퍼스 또는 전체 인터넷을 하나의 시퀀스로 처리하는 등 매우 긴 시퀀스를 모델링하는 새로운 가능성을 열어줍니다. 비교하자면 일반적인
