
 기술 주변기기
일체 포함
Baichuan Intelligent는 Baichuan-13B AI 모델을 출시하며 '130억 개의 매개변수가 오픈 소스이며 상업적으로 사용될 수 있다'고 주장했습니다.
기술 주변기기
일체 포함
Baichuan Intelligent는 Baichuan-13B AI 모델을 출시하며 '130억 개의 매개변수가 오픈 소스이며 상업적으로 사용될 수 있다'고 주장했습니다.
Baichuan Intelligent는 Baichuan-13B AI 모델을 출시하며 '130억 개의 매개변수가 오픈 소스이며 상업적으로 사용될 수 있다'고 주장했습니다.

IT Home은 7월 11일 Wang Xiaochuan의 자회사인 Baichuan Intelligence가 오늘 "130억 매개변수 오픈 소스 및 상용화 가능"으로 알려진 Baichuan-13B 대형 모델을 출시했다고 보도했습니다.
▲ 사진 출처 Baichuang-13B GitHub 페이지
공식 소개에 따르면 Baichuan-13B는 Baichuan-7B 이후 Baichuan Intelligence가 개발한 130억 개의 매개변수를 포함하는 오픈소스 상용 대규모 언어 모델입니다. 중국어와 중국어 모두에서 동일한 크기의 모델 중에서 가장 좋은 결과를 얻었습니다. 영어 벤치마크. 이 릴리스에는 사전 훈련(Baichuan-13B-Base)과 정렬(Baichuan-13B-Chat)의 두 가지 버전이 포함되어 있습니다.
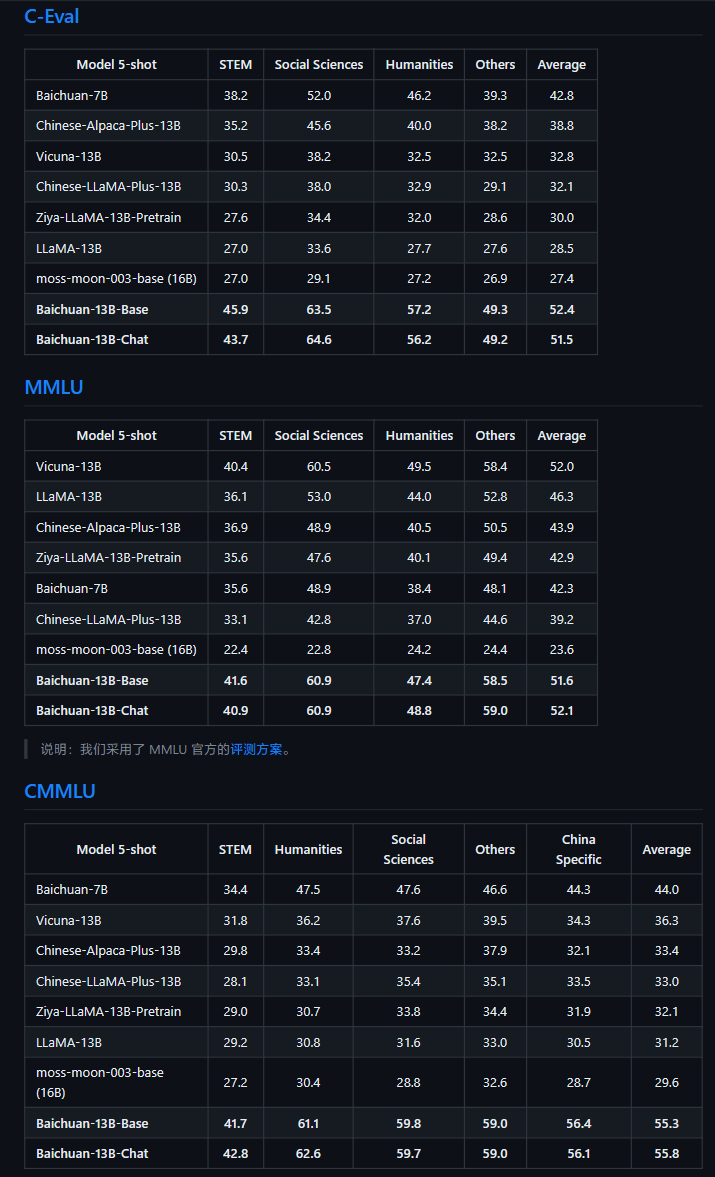
▲ 사진 출처 Baichuang-13B GitHub 페이지
바이촨-13B는 다음과 같은 특징을 가지고 있다고 공식적으로 주장했습니다:
- 더 큰 크기, 더 많은 데이터: Baichuan-13B는 Baichuan-7B를 기반으로 매개변수 수를 130억 개로 더욱 확장했으며 고품질 코퍼스에서 1.4조 개의 토큰을 훈련하여 LLaMA-13B를 40% 초과했습니다. 13B 크기에서 가장 많은 양의 학습 데이터를 보유한 모델입니다. 중국어 및 영어 이중 언어를 지원하고 ALiBi 위치 인코딩을 사용하며 컨텍스트 창 길이는 4096입니다.
- 오픈 소스 사전 훈련 및 정렬 모델 동시: 사전 훈련 모델은 개발자를 위한 "기반"인 반면, 일반 사용자의 대다수는 대화 기능이 있는 정렬 모델에 대한 더 강한 요구를 가지고 있습니다. 따라서 이 프로젝트에는 강력한 대화 기능을 갖춘 정렬 모델(Baichuan-13B-Chat)도 있으며, 즉시 사용할 수 있고 몇 줄의 코드로 쉽게 배포할 수 있습니다.
- 보다 효율적인 추론: 더 광범위한 사용자의 사용을 지원하기 위해 프로젝트는 int8 및 int4의 양자화된 버전도 오픈 소스로 제공했습니다. 효과 손실이 거의 없으며 NVIDIA RTX3090과 같은 소비자급 그래픽 카드에 배포할 수 있습니다.
- 오픈 소스, 상업용 무료: Baichuan-13B는 학술 연구에 완전히 개방되어 있을 뿐만 아니라 개발자도 이메일을 통해 신청하고 공식 상업용 라이선스를 취득한 후 무료로 사용할 수 있습니다.
현재 해당 모델은 HuggingFace, GitHub, Model Scope에 공개되어 있습니다. 관심 있는 IT Home 친구들은 가서 자세히 알아볼 수 있습니다.
위 내용은 Baichuan Intelligent는 Baichuan-13B AI 모델을 출시하며 '130억 개의 매개변수가 오픈 소스이며 상업적으로 사용될 수 있다'고 주장했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7711
7711
 15
1640
14
1394
52
1288
25
1232
29
15
1640
14
1394
52
1288
25
1232
29

 창의적인 프로젝트를위한 최고의 AI 아트 발전기 (무료 & amp; 유료)
Apr 02, 2025 pm 06:10 PM
창의적인 프로젝트를위한 최고의 AI 아트 발전기 (무료 & amp; 유료)
Apr 02, 2025 pm 06:10 PM
이 기사는 최고의 AI 아트 생성기를 검토하여 자신의 기능, 창의적인 프로젝트에 대한 적합성 및 가치에 대해 논의합니다. Midjourney를 전문가에게 최고의 가치로 강조하고 고품질의 사용자 정의 가능한 예술에 Dall-E 2를 추천합니다.
 Meta Llama 3.2- 분석 Vidhya를 시작합니다
Apr 11, 2025 pm 12:04 PM
Meta Llama 3.2- 분석 Vidhya를 시작합니다
Apr 11, 2025 pm 12:04 PM
메타의 라마 3.2 : 멀티 모달 및 모바일 AI의 도약 Meta는 최근 AI에서 강력한 비전 기능과 모바일 장치에 최적화 된 가벼운 텍스트 모델을 특징으로하는 AI의 상당한 발전 인 Llama 3.2를 공개했습니다. 성공을 바탕으로 o
 chatgpt 4 o를 사용할 수 있습니까?
Mar 28, 2025 pm 05:29 PM
chatgpt 4 o를 사용할 수 있습니까?
Mar 28, 2025 pm 05:29 PM
ChatGpt 4는 현재 이용 가능하고 널리 사용되며 ChatGpt 3.5와 같은 전임자와 비교하여 상황을 이해하고 일관된 응답을 생성하는 데 상당한 개선을 보여줍니다. 향후 개발에는보다 개인화 된 인터가 포함될 수 있습니다
 최고의 AI 챗봇 비교 (Chatgpt, Gemini, Claude & amp; more)
Apr 02, 2025 pm 06:09 PM
최고의 AI 챗봇 비교 (Chatgpt, Gemini, Claude & amp; more)
Apr 02, 2025 pm 06:09 PM
이 기사는 Chatgpt, Gemini 및 Claude와 같은 최고의 AI 챗봇을 비교하여 고유 한 기능, 사용자 정의 옵션 및 자연어 처리 및 신뢰성의 성능에 중점을 둡니다.
 컨텐츠 생성을 향상시키기 위해 AI를 쓰는 최고 AI 작문
Apr 02, 2025 pm 06:11 PM
컨텐츠 생성을 향상시키기 위해 AI를 쓰는 최고 AI 작문
Apr 02, 2025 pm 06:11 PM
이 기사는 Grammarly, Jasper, Copy.ai, Writesonic 및 Rytr와 같은 최고의 AI 작문 조수에 대해 논의하여 콘텐츠 제작을위한 독특한 기능에 중점을 둡니다. Jasper는 SEO 최적화가 뛰어나고 AI 도구는 톤 구성을 유지하는 데 도움이된다고 주장합니다.
 최고의 AI 음성 생성기 선택 : 최고 옵션 검토
Apr 02, 2025 pm 06:12 PM
최고의 AI 음성 생성기 선택 : 최고 옵션 검토
Apr 02, 2025 pm 06:12 PM
이 기사는 Google Cloud, Amazon Polly, Microsoft Azure, IBM Watson 및 Destript와 같은 최고의 AI 음성 생성기를 검토하여 기능, 음성 품질 및 다양한 요구에 대한 적합성에 중점을 둡니다.
 AI 에이전트를 구축하기위한 상위 7 개의 에이전트 래그 시스템
Mar 31, 2025 pm 04:25 PM
AI 에이전트를 구축하기위한 상위 7 개의 에이전트 래그 시스템
Mar 31, 2025 pm 04:25 PM
2024는 콘텐츠 생성에 LLM을 사용하는 것에서 내부 작업을 이해하는 것으로 바뀌는 것을 목격했습니다. 이 탐사는 AI 요원의 발견으로 이어졌다 - 자율 시스템을 처리하는 과제와 최소한의 인간 개입으로 결정을 내렸다. buildin
 Falcon 3에 액세스하는 방법? - 분석 Vidhya
Mar 31, 2025 pm 04:41 PM
Falcon 3에 액세스하는 방법? - 분석 Vidhya
Mar 31, 2025 pm 04:41 PM
FALCON 3 : 혁신적인 오픈 소스 대형 언어 모델 유명한 Falcon 시리즈 LLM의 최신 반복 인 Falcon 3은 AI 기술의 상당한 발전을 나타냅니다. 기술 혁신 연구소 (TII)에서 개발 한이 개방
