이 시리즈에는 Go 언어 포인터, 스택, 힙, 이스케이프 분석 및 값/포인터 의미론의 메커니즘과 디자인 개념을 주로 설명하는 4개의 기사가 포함되어 있습니다. 이 기사는 스택과 포인터를 주로 설명하는 시리즈의 첫 번째 기사입니다.
포인터에 대해 좋은 말을 하려는 것이 아닙니다. 포인터는 정말 이해하기 어렵습니다. 잘못 사용하면 성가신 버그와 성능 문제가 발생할 수 있습니다. 이는 동시 또는 다중 스레드 소프트웨어를 작성할 때 특히 그렇습니다. 많은 프로그래밍 언어가 프로그래머를 위한 포인터 사용을 피하려고 하는 것은 놀라운 일이 아닙니다. 그러나 Go 프로그래밍 언어를 사용하면 포인터가 불가피합니다. 포인터를 깊이 이해해야만 깔끔하고 간결하며 효율적인 코드를 작성할 수 있습니다.
프레임 경계는 각 기능별로 별도의 메모리 공간을 제공하며, 해당 기능은 프레임 경계 내에서 실행됩니다. 프레임 경계를 통해 함수는 자체 컨텍스트에서 실행되고 흐름 제어도 제공됩니다. 함수는 프레임 포인터를 통해 프레임 내의 메모리에 직접 액세스할 수 있지만 프레임 외부의 메모리에 액세스하는 것은 간접적으로만 수행할 수 있습니다. 각 기능에 대해 프레임 외부의 메모리에 액세스할 수 있으려면 이 메모리를 기능과 공유해야 합니다. 공유 구현을 이해하려면 먼저 프레임 경계 설정을 위한 메커니즘과 제약 조건을 배우고 이해해야 합니다.
함수가 호출되면 두 프레임 경계 사이에 컨텍스트 전환이 발생합니다. 호출 함수에서 호출된 함수로, 함수가 호출될 때 매개변수를 전달해야 하는 경우 이러한 매개변수는 호출된 함수의 프레임 경계 내에서도 전달되어야 합니다. Go 언어에서는 데이터가 두 프레임 간에 값으로 전송됩니다.
값으로 데이터를 전달하는 장점은 가독성이 좋다는 것입니다. 함수가 호출될 때 표시되는 값은 함수 호출자와 호출 수신자 간에 복사되고 수신된 값입니다. 이것이 바로 내가 "가치에 의한 전달"을 WYSIWYG와 연관시키는 이유입니다. 왜냐하면 당신이 보는 것이 곧 당신이 얻는 것이기 때문입니다.
정수 데이터를 값으로 전달하는 코드를 살펴보겠습니다.
목록 1
package main
func main() {
// Declare variable of type int with a value of 10.
count := 10
// Display the "value of" and "address of" count.
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
// Pass the "value of" the count.
increment(count)
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
}
//go:noinline
func increment(inc int) {
// Increment the "value of" inc.
inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")
}Go 프로그램을 시작하면 런타임은 main() 함수의 코드를 포함한 모든 초기화 코드를 실행하는 기본 코루틴을 생성합니다. 고루틴은 운영체제 스레드에 위치한 실행 경로로, 최종적으로 특정 코어에서 실행됩니다. Go 1.8부터 각 고루틴은 2048바이트의 연속 메모리 블록을 스택 공간으로 할당합니다. 초기 스택 공간의 크기는 수년에 걸쳐 변화해 왔으며 앞으로도 다시 변경될 수 있습니다.
스택은 각 개별 기능의 프레임 경계에 대한 물리적 메모리 공간을 제공하기 때문에 매우 중요합니다. Listing 1에 따르면 메인 코루틴이 main() 함수를 실행할 때 스택 공간은 다음과 같이 분배됩니다.
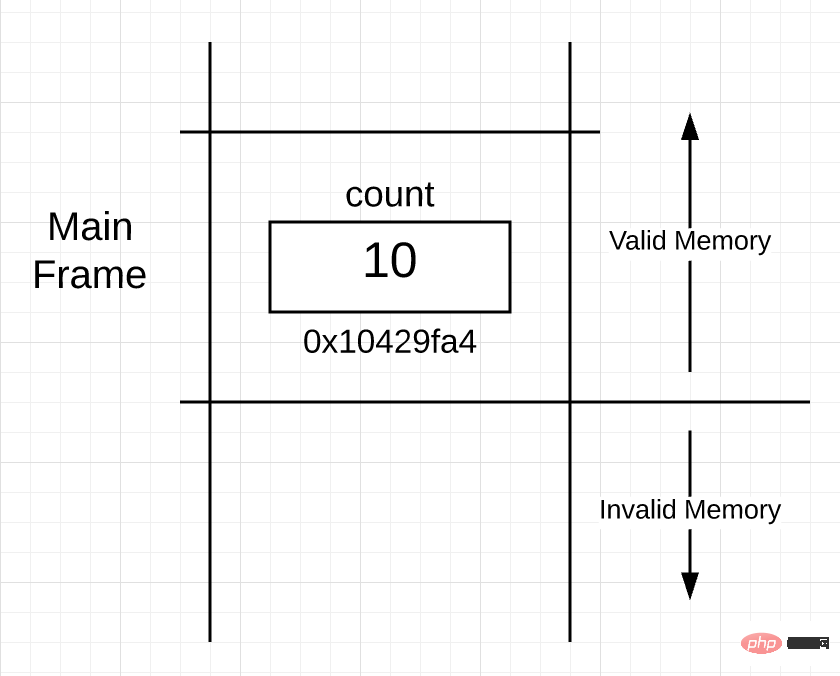
그림 1
그림 1에서 메인 함수의 스택 부분을 볼 수 있습니다. 프레임 아웃되었습니다. 이 부분을 "스택 프레임"이라고 하며, 이 프레임은 스택에서 주 기능의 경계를 나타냅니다. 호출된 함수가 실행될 때 프레임이 생성됩니다. 또한 변수 count가 메모리 주소 0x10429fa4의 main() 함수 프레임에 배치되는 것을 볼 수 있습니다.
그림 1은 또 다른 흥미로운 점을 보여줍니다. 활성 프레임 아래의 모든 스택 메모리는 사용할 수 없습니다. 사용 가능한 스택 공간과 사용할 수 없는 스택 공간 간의 경계를 명확히 해야 합니다.
변수의 목적은 특정 메모리 주소에 이름을 할당하여 코드를 더 읽기 쉽게 만들고 처리 중인 데이터를 분석하는 데 도움을 주는 것입니다. 변수가 있고 해당 값을 메모리에 저장할 수 있는 경우 이 값을 저장하는 메모리 주소에 주소가 있어야 합니다. 코드 9행에서 main() 함수는 내장 함수 println()을 호출하여 변수 count의 값과 주소를 표시합니다.
목록 2
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")변수가 위치한 메모리 위치의 주소를 얻기 위해 & 연산자를 사용하는 것은 놀라운 일이 아니며, 다른 언어에서도 이 연산자를 사용합니다. 코드가 go Playground와 같은 32비트 컴퓨터에서 실행되는 경우 출력은 다음과 유사합니다.
清单3
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
接下来的第 12 行代码,main() 函数调用 increment() 函数。
清单4
increment(count)
调用函数意味着协程需要在栈上构建出一块新的栈帧。但是,事情有点复杂。要想成功地调用函数,在发生上下文切换时,数据需要跨越帧边界传递到新的帧范围内。具体一点来说,函数调用的时候,整型值会被复制和传递。通过第 18 行代码、increment() 函数的声明,你就可以知道。
清单5
func increment(inc int) {如果你回过头来再次看第 12 行代码函数 increment() 的调用,你会发现 count 变量是传值的。这个值会被拷贝、传递,最后存储在 increment() 函数的栈中。记住,increment() 函数只能在自己的栈内读写内存,因此,它需要 inc 变量来接收、存储和访问传递的 count 变量的副本。
就在 increment() 函数内部代码开始执行之前,协程的栈(站在一个非常高的角度)应该是像下图这样的:
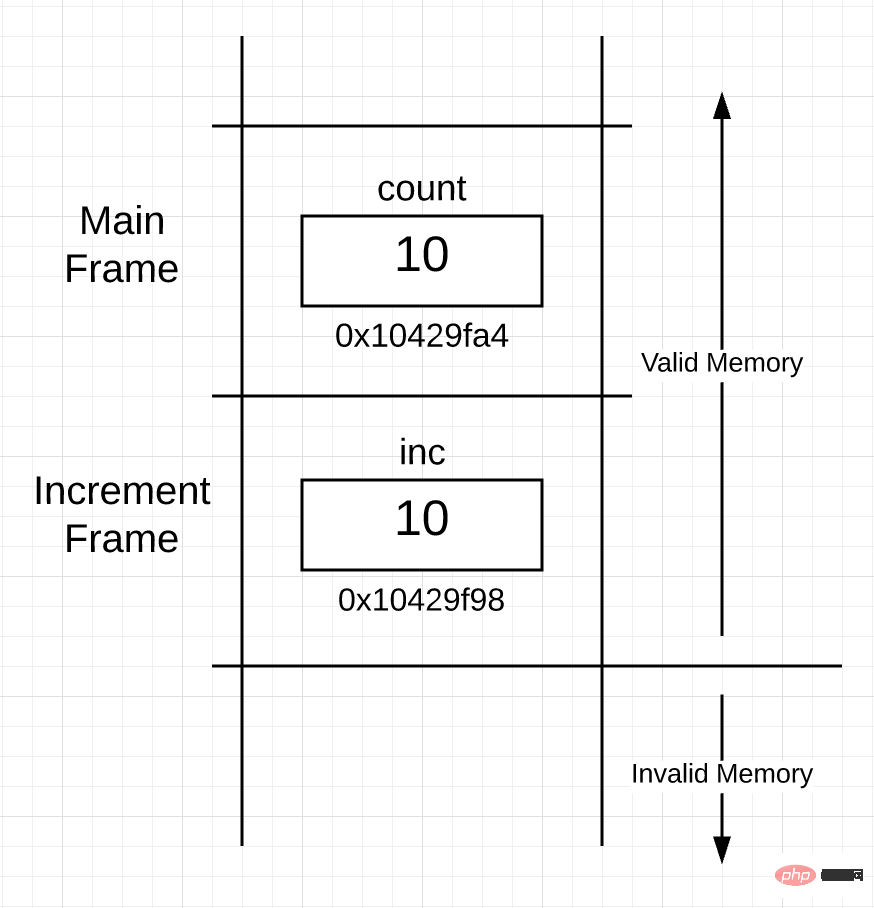
图 2
你可以看到栈上现在有两个帧,一个属于 main() 函数,另一个属于 increment() 函数。在 increment() 函数的帧里面,你可以看到 inc 变量,它的值 10,是函数调用时拷贝、传递进来的。变量 inc 的地址是 0x10429f98,因为栈帧是从上至下使用栈空间的,所以它的内存地址较小,这只是具体的实现细节,并没任何意义。重要的是,协程从 main() 的栈帧里获取变量 count 的值,并使用 inc 变量将该值的副本放置在 increment() 函数的栈帧里。
increment() 函数的剩余代码显示 inc 变量的值和地址。
清单6
inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")第 22 行代码输出类似下面这样:
清单7
inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ]
执行这些代码之后,栈就会像下面这样:
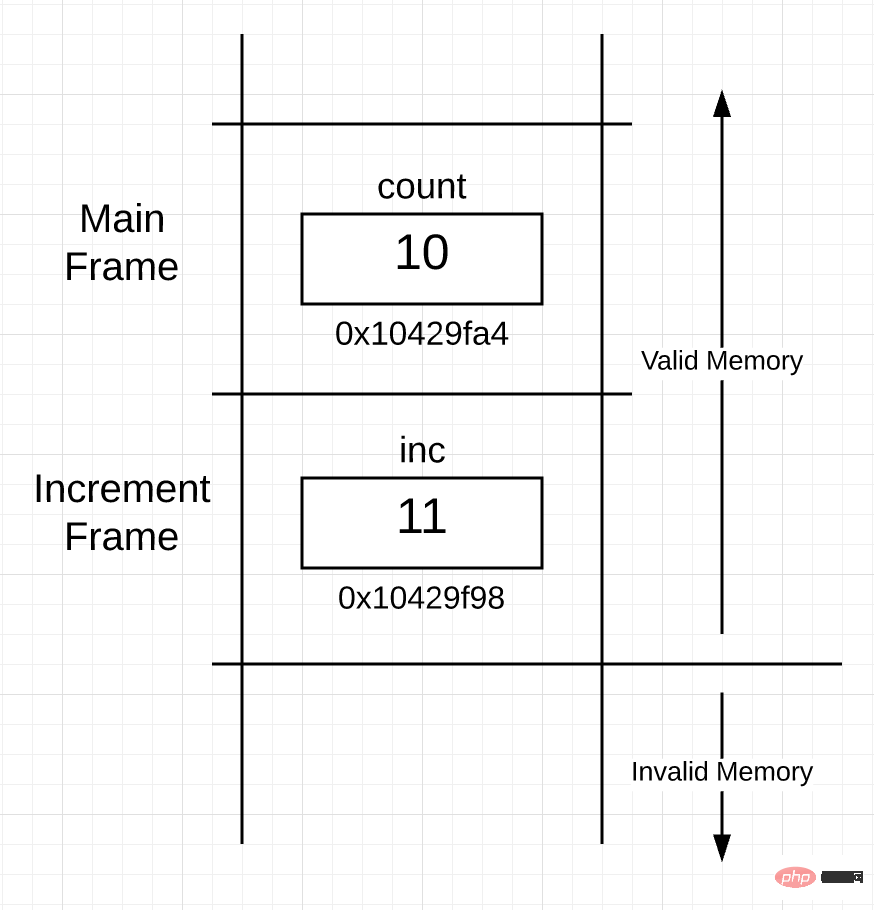
图 3
第 21、22 行代码执行之后,increment() 函数返回并且 CPU 控制权交还给 main() 函数。第 14 行代码,main() 函数会再次显示 count 变量的值和地址。
清单8
println("count:\tValue Of[",count, "]\tAddr Of[", &count, "]")上面例子完整的输出会像下面这样:
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ] inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ] count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
main() 函数栈帧里,变量 count 的值在调用 increment() 函数前后是相同的。
当函数返回并且控制权交还给调用函数时,栈上的内存实际上会发生什么?回答是:不会发生任何事情。当 increment() 函数返回时,栈上的空间看起来像下面这样:
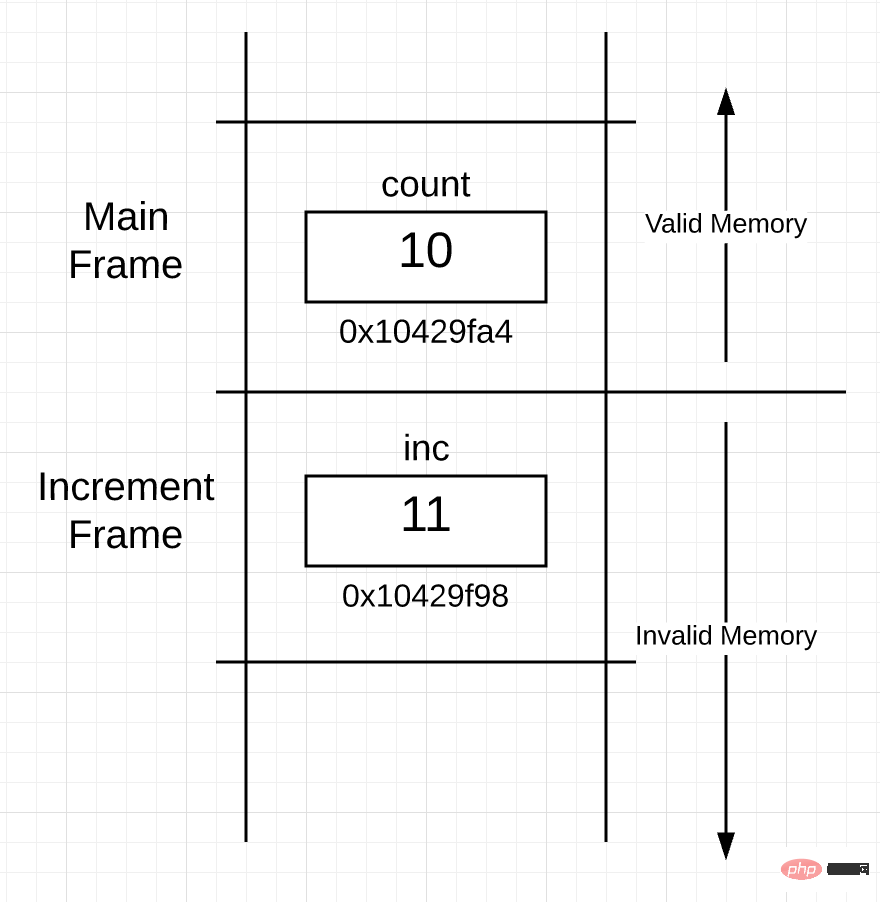
그림 4
increment() 함수를 위해 생성된 스택 프레임을 사용할 수 없게 되는 점을 제외하면 스택의 분포는 기본적으로 그림 3과 동일합니다. 이는 main() 함수의 프레임이 활성 프레임이 되기 때문입니다. increment() 함수의 스택 프레임에서는 처리가 수행되지 않습니다.
함수가 반환되면 함수의 프레임을 정리하는 것은 이 메모리가 다시 사용될지 모르기 때문에 시간을 낭비하게 됩니다. 따라서 이 메모리는 어떠한 처리도 수행하지 않습니다. 함수가 호출될 때마다 스택에 할당된 프레임은 프레임이 필요할 때 지워집니다. 이는 프레임에 저장된 변수를 초기화할 때 수행됩니다. 모든 값은 해당 0 값으로 초기화되므로 함수가 호출될 때마다 스택이 올바르게 정리됩니다.
increment() 함수가 main() 함수 프레임에 저장된 count 변수를 직접 연산하는 것이 매우 중요하다면 어떨까요? 이를 위해서는 포인터를 사용해야 합니다! 포인터의 목적은 함수 간에 값을 공유하는 것입니다. 값이 자체 함수의 프레임에 있지 않더라도 함수는 이를 읽고 쓸 수 있습니다.
공유 개념이 없다면 아마도 포인터를 사용하지 않을 것입니다. 포인터를 학습할 때는 단순히 연산자나 구문을 외우는 것보다 명확한 어휘를 사용하는 것이 중요합니다. 따라서 포인터는 공유되어야 한다는 점을 기억하고 코드를 읽을 때 "공유"를 생각할 때 & 연산자를 생각해야 합니다.
사용자가 맞춤 설정하거나 Go 언어와 함께 제공되는지 여부에 관계없이 선언된 각 유형에 대해 해당 유형을 기반으로 해당 포인터 유형을 얻어 공유할 수 있습니다. 예를 들어 내장 유형 int의 경우 해당 포인터 유형은 *int입니다. User 유형을 직접 선언하는 경우 해당 포인터 유형은 *User입니다.
모든 포인터 유형은 동일한 특성을 갖습니다. 첫째, * 기호로 시작하고 둘째, 동일한 메모리 공간을 차지하고 둘 다 주소를 표시하기 위해 4 또는 8바이트 길이를 사용하여 주소를 나타냅니다. 32비트 시스템(예: 놀이터)에서 포인터에는 4바이트의 메모리가 필요하고, 64비트 시스템(예: 컴퓨터)에서는 8바이트의 메모리가 필요합니다.
规范里有说明,指针类型可以看成是类型字面量,这意味着它们是有现有类型组成的未命名类型。
让我们来看一段代码,这段代码展示了函数调用时按值传递地址。main() 和 increment() 函数的栈帧会共享 count 变量:
清单10
package main
func main() {
// Declare variable of type int with a value of 10.
count := 10
// Display the "value of" and "address of" count.
println("count:\tValue Of[", count, "]\t\tAddr Of[", &count, "]")
// Pass the "address of" count.
increment(&count)
println("count:\tValue Of[", count, "]\t\tAddr Of[", &count, "]")
}
//go:noinline
func increment(inc *int) {
// Increment the "value of" count that the "pointer points to". (dereferencing)
*inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]\tValue Points To[", *inc, "]")
}基于原来的代码有三处改动的地方,第 12 行是第一处改动:
清单11
increment(&count)
现在,第 12 行代码拷贝、传递的并非 count 变量的值,而是变量的地址。可以认为,main() 函数与 increment() 函数是共享 count 变量的。这是 & 操作符起的作用。
重点理解,现在依旧是传值,唯一不同的是现在传递的是地址而不是一个整型数据。地址也是一个值,是函数调用时会跨帧边界发生拷贝和传递的内容。
因为地址会发生拷贝和传递,在 increment() 函数里面需要一个变量接收和存储该地址值。所以在第 18 行声明了整型的指针变量。
清单12
func increment(inc *int) {如果你传递的是 User 类型值的地址,变量就应该声明成 *User。尽管指针变量存储的是地址,也不能传递任何类型的地址,只能传递与指针类型相一致的地址。关键在于,共享值的原因是因为接收函数能够对值进行读写操作。只有知道值的类型信息才能够进行读写操作。编译器会保证只有与指针类型相一致的值才能够实现函数间共享。
调用 increment() 函数时候,栈空间就像下面这样:
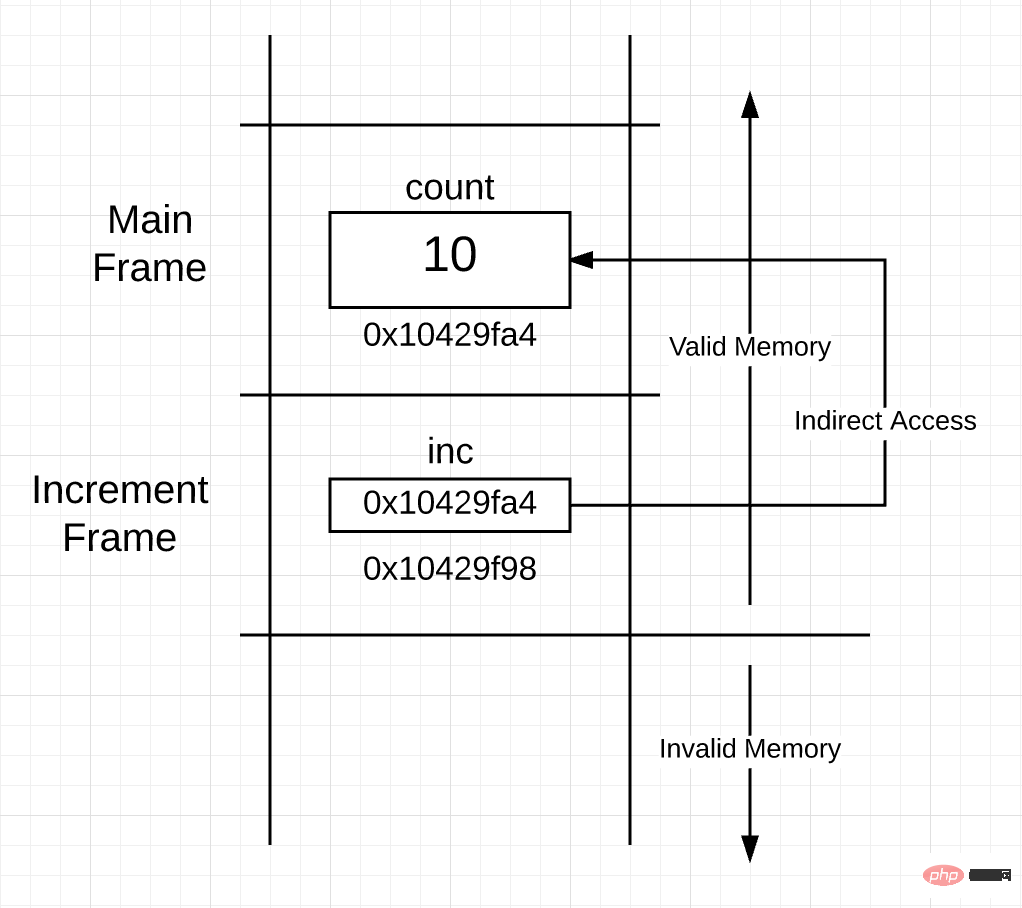
图 5
当一个地址作为值执行按值传递之后,你可以从图 5 看出栈是如何分布的。现在,increment() 函数帧空间里面的指针变量指向 count 变量,该变量在 main() 函数的帧空间里。
通过使用指针变量,increment() 函数可以间接对 count 变量执行读写操作。
清单 13
*inc++
这一次,字符 * 充当操作符,与指针变量搭配使用。使用 * 操作符是“获取指针指向的值”的意思。指针变量允许在帧外对函数帧内的内存进行间接访问。有时候,间接的读写操作也称为解引用。increment() 函数必须有指针变量,才能够对其他函数帧空间执行间接访问。
执行第 21 行代码之后,栈空间分布如图 6 所示。
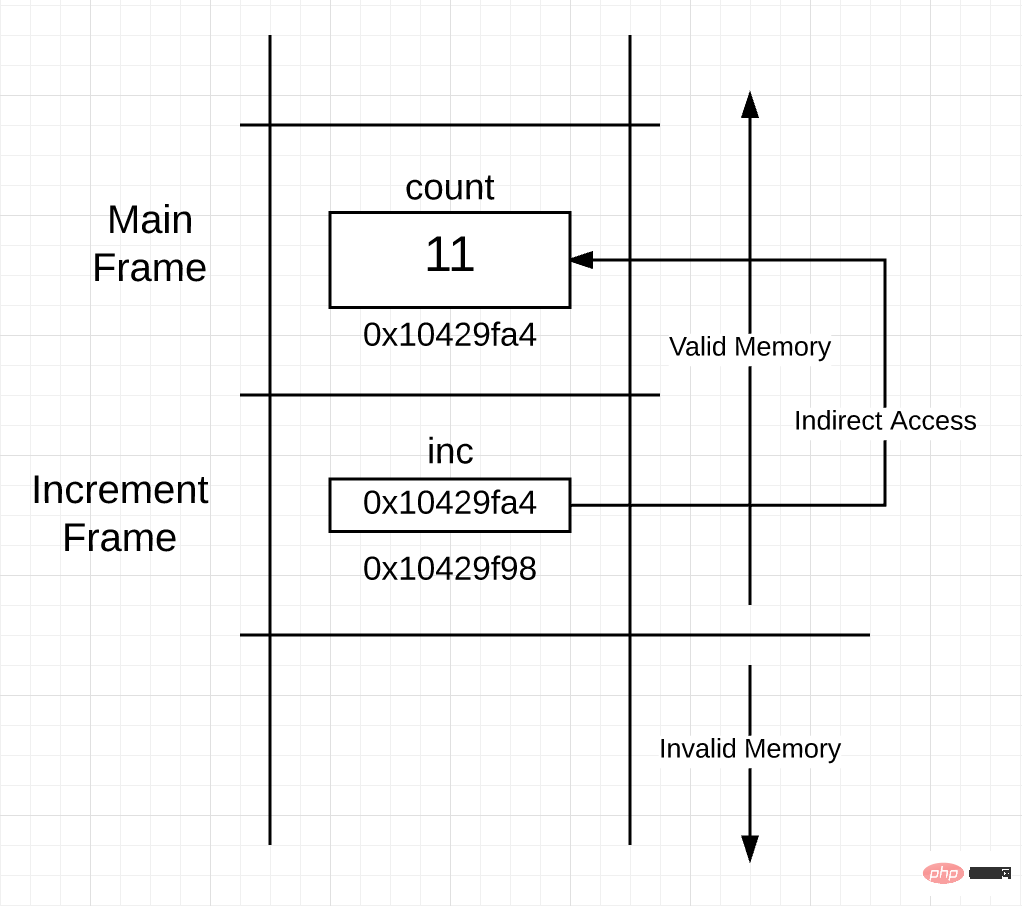
图 6
程序最后输出:
清单 14
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ] inc: Value Of[ 0x10429fa4 ] Addr Of[ 0x10429f98 ] Value Points To[ 11 ] count: Value Of[ 11 ] Addr Of[ 0x10429fa4 ]
你可以看到,指针变量 inc 的值和 count 变量的地址是相同的。这将建立起共享关系,允许在帧外执行内存的间接访问。在 increment() 函数里,一旦通过指针执行了写操作,改变也会体现在 main() 函数里。
指针变量并不特别,它们和其他变量一样也是变量,有内存地址和值。正巧的是,无论指针变量指向的值的类型如何,所有的指针变量都有同样的大小和表现形式。唯一困惑的是使用 * 字符充当操作符,用来声明指针类型。如果你能分清指针类型声明和指针操作,你就没有那么困惑了。
这篇文章描述了设计指针背后的目的和 Go 语言中栈和指针的工作机制。这是理解 Go 语言机制、设计哲学的第一步,也对编写一致性且可读性的代码提供一些指导作用。
总结一下,通过这篇文章你能学习到的知识:
1.프레임 경계는 각 함수에 대해 별도의 메모리 공간을 제공하며 함수는 프레임 범위 내에서 실행됩니다. 2.함수가 호출되면 컨텍스트 환경이 두 프레임 사이를 전환합니다. 3.값 전달의 장점은 가독성이 좋다는 것입니다. 4.스택은 각 함수의 프레임 경계에 대해 접근 가능한 물리적 메모리 공간을 제공하기 때문에 중요합니다. 5. 활성 프레임을 사용할 수 없으며 활성 프레임과 그 위의 스택 메모리만 유용합니다. 6.함수를 호출하면 코루틴이 스택 메모리에서 새 스택 프레임을 엽니다. 7.Every; 함수가 호출될 때 프레임이 사용되면 해당 스택 메모리가 초기화됩니다. 8.포인터를 설계하는 목적은 함수 자체에 값이 없더라도 함수 간 값 공유를 구현하는 것입니다. 스택 프레임에서도 읽고 쓸 수 있습니다. 9.각 유형에 대해 Go 언어에 내장되어 있는지 여부에 관계없이 해당 포인터 유형이 있습니다. 10.통과됨 포인터 변수를 사용하면 함수 프레임 외부에서 간접적인 메모리 액세스가 가능합니다. 11.다른 변수와 비교할 때 포인터 변수는 메모리 주소와 값이 있는 변수이기 때문에 특별한 것이 아닙니다.
위 내용은 의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!













![Golang Gin 프레임워크로 빠르게 시작하기 [Gin을 사용하여 백만 레벨 동시 IM 인스턴트 메시징 시스템 구축]](https://img.php.cn/upload/course/000/000/068/63a2b21046723283.jpg)






![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



