/1 서문/

/2 프로젝트 목표/
Maoyan Movies의 향후 영화 세부 정보를 확인하세요.
/3 프로젝트 준비/
소프트웨어: PyCharm
필수 라이브러리: 퀘스트、lxml、random、 시간
플러그인: https://maoyan.com/films?showType=2&offset={}
다음 페이지를 클릭하면 추가 페이지마다 offset=()가 30씩 증가하므로 {}를 사용하여 변환된 변수를 바꿀 수 있습니다. 그런 다음 for 루프를 사용하여 URL을 탐색하여 여러 URL 요청을 구현합니다.
1. 클래스를 정의하여 객체를 상속하고, init 메서드를 정의하여 self를 상속하며, 주요 함수 main 자기를 상속받기 위해. 필요한 라이브러리와 URL을 가져오세요. 코드는 다음과 같습니다.
import requests
from lxml import etree
import time
import random
class MaoyanSpider(object):
def __init__(self):
self.url = "https://maoyan.com/films?showType=2&offset={}"
def main(self):
pass
if __name__ == '__main__':
spider = MaoyanSpider()
spider.main() for i in range(1, 50):
# ua.random,一定要写在这里,每次请求都会随机选择。
self.headers = {
'User-Agent': ua.random,
}def get_page(self, url): # random.choice一定要写在这里,每次请求都会随机选择 res = requests.get(url, headers=self.headers) res.encoding = 'utf-8' html = res.text self.parse_page(html)
1)基准xpath节点对象列表。
# 创建解析对象 parse_html = etree.HTML(html) # 基准xpath节点对象列表 dd_list = parse_html.xpath('//dl[@class="movie-list"]//dd')
for dd in dd_list:
name = dd.xpath('.//div[@class="movie-hover-title"]//span[@class="name noscore"]/text()')[0].strip()
star = dd.xpath('.//div[@class="movie-hover-info"]//div[@class="movie-hover-title"][3]/text()')[1].strip()
type = dd.xpath('.//div[@class="movie-hover-info"]//div[@class="movie-hover-title"][2]/text()')[1].strip()
dowld=dd.xpath('.//div[@class="movie-item-hover"]/a/@href')[0].strip()
# print(movie_dict)
movie = '''【即将上映】 movie = '''【即将上映】
电影名字: %s
主演:%s
类型:%s
详情链接:https://maoyan.com%s
=========================================================
''' % (name, star, type,dowld)
print( movie)time.sleep(random.randint(1, 3))
html = self.get_page(url) self.parse_page(html)
/5 효과 표시/
1. 녹색 삼각형을 클릭하면 입력 시작 페이지와 끝 페이지가 실행됩니다.
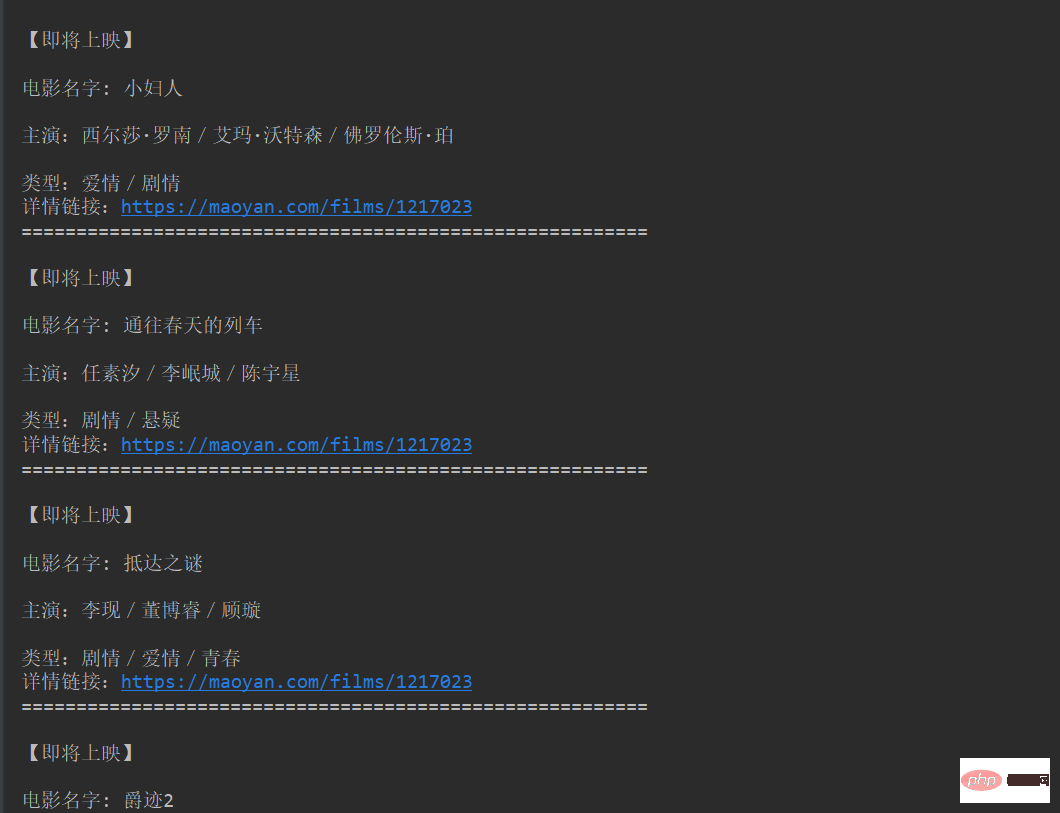
2. 프로그램을 실행하면 아래 그림과 같이 결과가 콘솔에 표시됩니다.
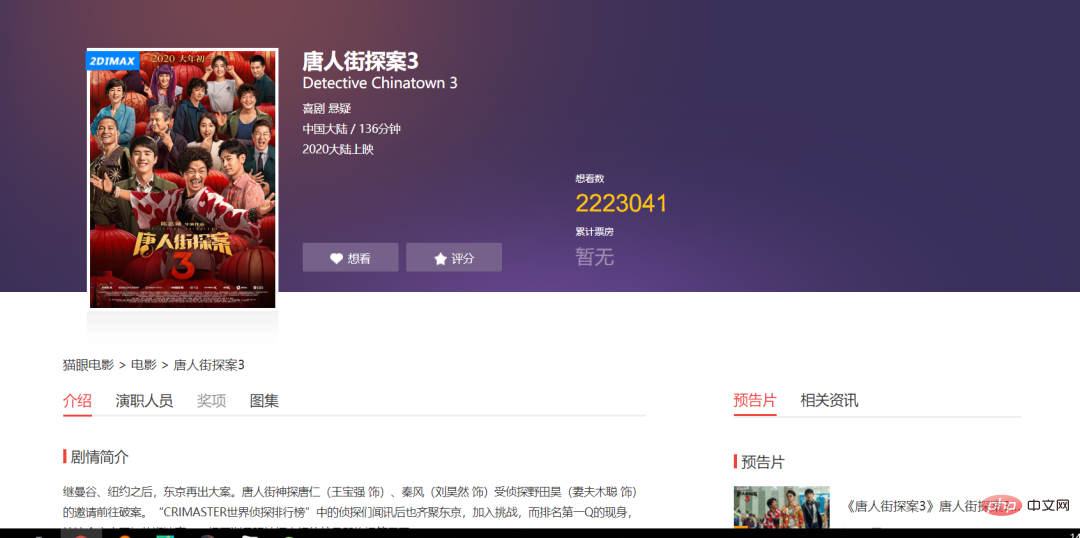
3. 온라인으로 세부 정보를 보려면 파란색 다운로드 링크를 클릭하세요.
/6 요약/
1 너무 많은 데이터를 캡처하는 것은 권장되지 않습니다. 이로 인해 서버에 부하가 발생하기 쉽습니다.
2. 이 기사는 Python 웹 크롤러를 기반으로 하며 크롤러 라이브러리를 사용하여 Maoyan 영화를 크롤링합니다.
위 내용은 Python 웹 크롤러를 사용하여 현재 극장에서 상영 중인 영화를 확인하세요.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



