

Flask를 사용하여 ES 검색 엔진을 구축하는 방법을 단계별로 가르쳐줍니다(준비 부분).
/1 서문/
Elasticsearch는 오픈 소스 검색 엔진으로, 전체 텍스트 검색 엔진 라이브러리를 기반으로 구축되었습니다. Apache Lucene™ 기본에 충실합니다.

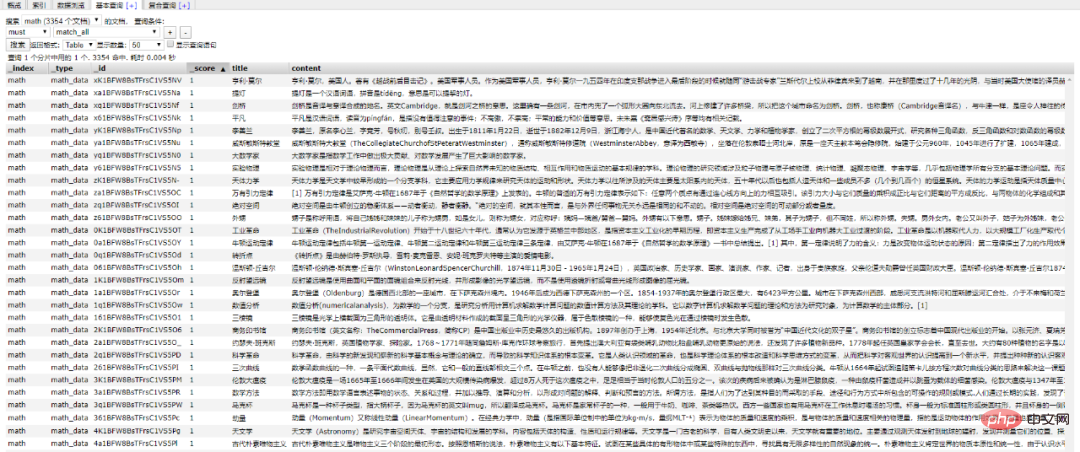
Elasticsearch 및 Python 도킹이 우리에게 걱정거리가 되었습니다(왜 우리는 Python과 관련된 모든 것을 연결하려면? /2 Python 상호 작용/ 또한 Elasticsearch에 연결할 수 있는 종속성 라이브러리도 제공합니다. . 작업 개체에 대한 연결을 초기화합니다. Elasticsearch의 로컬 환경이 설정되어 있는지 확인하세요. ID를 기준으로 문서 데이터 가져오기 插入文档数据 搜索文档数据 删除文档数据 好啊,封装 search 类也是为了方便调用,整体贴一下。 尝试一下把 Mongodb 中的数据插入到 ES 中。 到 ES 中查看一下,启动 elasticsearch-head 插件。 如果是 npm 安装的那么 cd 到根目录之后直接 npm run start 就跑起来了。 本地访问 http://localhost:9100/ 发现新加的 spider 数据文档确实已经进去了。 /3 爬虫入库/ 要想实现 ES 搜索,首先要有数据支持,而海量的数据往往来自爬虫。 为了节省时间,编写一个最简单的爬虫,抓取 百度百科。 简单粗暴一点,先 递归获取 很多很多的 url 链接 把全部 url 存到 url.txt 文件中之后,然后启动任务。 run.py 飞起来 黑窗口键入 哦豁 !! 你居然使用了 Celery 任务队列,gevent 模式,-c 就是10个线程刷刷刷就干起来了,速度杠杠的 !! 啥?分布式? 那就加多几台机器啦,直接把代码拷贝到目标服务器,通过 redis 共享队列协同多机抓取。 这里是先将数据存储到了 MongoDB 上(个人习惯),你也可以直接存到 ES 中,但是单条单条的插入速度堪忧(接下来会讲到优化,哈哈)。 使用前面的例子将 Mongo 中的数据批量导入到 ES 中,OK !!! 到这一个简单的数据抓取就已经完毕了。 好啦,现在 ES 中已经有了数据啦,接下来就应该是 Flask web 的操作啦,当然,Django,FastAPI 也很优秀。嘿嘿,你喜欢 !! 关于FastAPI 的文章可以看这个系列文章: 1、(入门篇)简析Python web框架FastAPI——一个比Flask和Tornada更高性能的API 框架 2、(进阶篇)Python web框架FastAPI——一个比Flask和Tornada更高性能的API 框架 3、(完结篇)Python web框架FastAPI——一个比Flask和Tornada更高性能的API 框架 /4 Flask 项目结构/ 这样一来前期工作就差不多了,接下来剩下的工作主要集中于 Flask 的实际开发中,蓄力中 !!pip install elasticsearch
def __init__(self, index_type: str, index_name: str, ip="127.0.0.1"):
# self.es = Elasticsearch([ip], http_auth=('username', 'password'), port=9200)
self.es = Elasticsearch("localhost:9200")
self.index_type = index_type
self.index_name = index_namedef get_doc(self, uid):
return self.es.get(index=self.index_name, id=uid)def insert_one(self, doc: dict):
self.es.index(index=self.index_name, doc_type=self.index_type, body=doc)
def insert_array(self, docs: list):
for doc in docs:
self.es.index(index=self.index_name, doc_type=self.index_type, body=doc)def search(self, query, count: int = 30):
dsl = {
"query": {
"multi_match": {
"query": query,
"fields": ["title", "content", "link"]
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
match_data = self.es.search(index=self.index_name, body=dsl, size=count)
return match_data
def __search(self, query: dict, count: int = 20): # count: 返回的数据大小
results = []
params = {
'size': count
}
match_data = self.es.search(index=self.index_name, body=query, params=params)
for hit in match_data['hits']['hits']:
results.append(hit['_source'])
return resultsdef delete_index(self):
try:
self.es.indices.delete(index=self.index_name)
except:
passfrom elasticsearch import Elasticsearch
class elasticSearch():
def __init__(self, index_type: str, index_name: str, ip="127.0.0.1"):
# self.es = Elasticsearch([ip], http_auth=('elastic', 'password'), port=9200)
self.es = Elasticsearch("localhost:9200")
self.index_type = index_type
self.index_name = index_name
def create_index(self):
if self.es.indices.exists(index=self.index_name) is True:
self.es.indices.delete(index=self.index_name)
self.es.indices.create(index=self.index_name, ignore=400)
def delete_index(self):
try:
self.es.indices.delete(index=self.index_name)
except:
pass
def get_doc(self, uid):
return self.es.get(index=self.index_name, id=uid)
def insert_one(self, doc: dict):
self.es.index(index=self.index_name, doc_type=self.index_type, body=doc)
def insert_array(self, docs: list):
for doc in docs:
self.es.index(index=self.index_name, doc_type=self.index_type, body=doc)
def search(self, query, count: int = 30):
dsl = {
"query": {
"multi_match": {
"query": query,
"fields": ["title", "content", "link"]
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
match_data = self.es.search(index=self.index_name, body=dsl, size=count)
return match_dataimport json
from datetime import datetime
import pymongo
from app.elasticsearchClass import elasticSearch
client = pymongo.MongoClient('127.0.0.1', 27017)
db = client['spider']
sheet = db.get_collection('Spider').find({}, {'_id': 0, })
es = elasticSearch(index_type="spider_data",index_name="spider")
es.create_index()
for i in sheet:
data = {
'title': i["title"],
'content':i["data"],
'link': i["link"],
'create_time':datetime.now()
}
es.insert_one(doc=data)
import requests
import re
import time
exist_urls = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36',
}
def get_link(url):
try:
response = requests.get(url=url, headers=headers)
response.encoding = 'UTF-8'
html = response.text
link_lists = re.findall('.*?<a target=_blank href="/item/([^:#=<>]*?)".*?</a>', html)
return link_lists
except Exception as e:
pass
finally:
exist_urls.append(url)
# 当爬取深度小于10层时,递归调用主函数,继续爬取第二层的所有链接
def main(start_url, depth=1):
link_lists = get_link(start_url)
if link_lists:
unique_lists = list(set(link_lists) - set(exist_urls))
for unique_url in unique_lists:
unique_url = 'https://baike.baidu.com/item/' + unique_url
with open('url.txt', 'a+') as f:
f.write(unique_url + '\n')
f.close()
if depth < 10:
main(unique_url, depth + 1)
if __name__ == '__main__':
start_url = 'https://baike.baidu.com/item/%E7%99%BE%E5%BA%A6%E7%99%BE%E7%A7%91'
main(start_url)# parse.py
from celery import Celery
import requests
from lxml import etree
import pymongo
app = Celery('tasks', broker='redis://localhost:6379/2')
client = pymongo.MongoClient('localhost',27017)
db = client['baike']
@app.task
def get_url(link):
item = {}
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36'}
res = requests.get(link,headers=headers)
res.encoding = 'UTF-8'
doc = etree.HTML(res.text)
content = doc.xpath("//div[@class='lemma-summary']/div[@class='para']//text()")
print(res.status_code)
print(link,'\t','++++++++++++++++++++')
item['link'] = link
data = ''.join(content).replace(' ', '').replace('\t', '').replace('\n', '').replace('\r', '')
item['data'] = data
if db['Baike'].insert(dict(item)):
print("is OK ...")
else:
print('Fail')from parse import get_url
def main(url):
result = get_url.delay(url)
return result
def run():
with open('./url.txt', 'r') as f:
for url in f.readlines():
main(url.strip('\n'))
if __name__ == '__main__':
run()celery -A parse worker -l info -P gevent -c 10

위 내용은 Flask를 사용하여 ES 검색 엔진을 구축하는 방법을 단계별로 가르쳐줍니다(준비 부분).의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7561
7561
 15
1384
52
84
11
60
19
28
98
15
1384
52
84
11
60
19
28
98

 React와 Flask를 사용하여 간단하고 사용하기 쉬운 웹 애플리케이션을 구축하는 방법
Sep 27, 2023 am 11:09 AM
React와 Flask를 사용하여 간단하고 사용하기 쉬운 웹 애플리케이션을 구축하는 방법
Sep 27, 2023 am 11:09 AM
React와 Flask를 사용하여 간단하고 사용하기 쉬운 웹 애플리케이션을 구축하는 방법 소개: 인터넷의 발전과 함께 웹 애플리케이션의 요구 사항은 점점 더 다양해지고 복잡해지고 있습니다. 사용 편의성과 성능에 대한 사용자 요구 사항을 충족하기 위해 최신 기술 스택을 사용하여 네트워크 애플리케이션을 구축하는 것이 점점 더 중요해지고 있습니다. React와 Flask는 프런트엔드 및 백엔드 개발을 위한 매우 인기 있는 프레임워크이며, 함께 잘 작동하여 간단하고 사용하기 쉬운 웹 애플리케이션을 구축합니다. 이 글에서는 React와 Flask를 활용하는 방법을 자세히 설명합니다.
 Django와 Flask: Python 웹 프레임워크 비교 분석
Jan 19, 2024 am 08:36 AM
Django와 Flask: Python 웹 프레임워크 비교 분석
Jan 19, 2024 am 08:36 AM
Django와 Flask는 모두 Python 웹 프레임워크의 리더이며 둘 다 고유한 장점과 적용 가능한 시나리오를 가지고 있습니다. 이 기사에서는 이 두 프레임워크를 비교 분석하고 구체적인 코드 예제를 제공합니다. 개발 소개 Django는 모든 기능을 갖춘 웹 프레임워크이며, 주요 목적은 복잡한 웹 애플리케이션을 신속하게 개발하는 것입니다. Django는 ORM(Object Relational Mapping), 양식, 인증, 관리 백엔드 등과 같은 다양한 내장 기능을 제공합니다. 이러한 기능을 통해 Django는 대규모 처리를 수행할 수 있습니다.
 처음부터 시작하여 Flask를 설치하고 개인 블로그를 빠르게 구축하는 방법을 단계별로 안내합니다.
Feb 19, 2024 pm 04:01 PM
처음부터 시작하여 Flask를 설치하고 개인 블로그를 빠르게 구축하는 방법을 단계별로 안내합니다.
Feb 19, 2024 pm 04:01 PM
Flask를 설치하는 방법과 개인 블로그를 빠르게 구축하는 방법을 처음부터 차근차근 가르쳐드리겠습니다. 글쓰기를 좋아하는 사람으로서 개인 블로그를 갖는 것은 매우 중요합니다. 경량 Python 웹 프레임워크인 Flask를 사용하면 간단하고 완전한 기능을 갖춘 개인 블로그를 빠르게 구축할 수 있습니다. 이 기사에서는 처음부터 시작하여 Flask를 설치하고 개인 블로그를 빠르게 구축하는 방법을 단계별로 가르쳐 드리겠습니다. 1단계: Python 및 pip 설치 시작하기 전에 먼저 Python 및 pi를 설치해야 합니다.
 Flask 프레임워크 설치 가이드: Flask를 올바르게 설치하는 데 도움이 되는 자세한 단계
Feb 18, 2024 pm 10:51 PM
Flask 프레임워크 설치 가이드: Flask를 올바르게 설치하는 데 도움이 되는 자세한 단계
Feb 18, 2024 pm 10:51 PM
Flask 프레임워크 설치 튜토리얼: Flask 프레임워크를 올바르게 설치하는 방법을 단계별로 설명합니다. 특정 코드 예제가 필요합니다. 소개: Flask는 간단하고 유연한 Python 웹 개발 프레임워크입니다. 배우기 쉽고 사용하기 쉬우며 강력한 기능이 가득합니다. 이 문서에서는 Flask 프레임워크를 올바르게 설치하는 방법을 단계별로 안내하고 참조할 수 있는 자세한 코드 예제를 제공합니다. 1단계: Python 설치 Flask 프레임워크를 설치하기 전에 먼저 Python이 컴퓨터에 설치되어 있는지 확인해야 합니다. P부터 시작할 수 있습니다.
 Flask와 Intellij IDEA 통합: Python 웹 애플리케이션 개발 팁(2부)
Jun 17, 2023 pm 01:58 PM
Flask와 Intellij IDEA 통합: Python 웹 애플리케이션 개발 팁(2부)
Jun 17, 2023 pm 01:58 PM
첫 번째 부분에서는 기본적인 Flask와 Intellij IDEA 통합, 프로젝트 및 가상 환경 설정, 종속성 설치 등에 대해 소개합니다. 다음으로 우리는 더 효율적인 작업 환경을 구축하기 위해 더 많은 Python 웹 애플리케이션 개발 팁을 계속 탐색할 것입니다. FlaskBlueprintsFlaskBlueprints를 사용하면 더 쉽게 관리하고 유지 관리할 수 있도록 애플리케이션 코드를 구성할 수 있습니다. Blueprint는 패키지를 구성하는 Python 모듈입니다.
 Flask vs FastAPI: 효율적인 웹 API 개발을 위한 최선의 선택
Sep 27, 2023 pm 09:01 PM
Flask vs FastAPI: 효율적인 웹 API 개발을 위한 최선의 선택
Sep 27, 2023 pm 09:01 PM
FlaskvsFastAPI: 효율적인 WebAPI 개발을 위한 최선의 선택 소개: 현대 소프트웨어 개발에서 WebAPI는 없어서는 안 될 부분이 되었습니다. 이는 서로 다른 애플리케이션 간의 통신과 상호 운용성을 가능하게 하는 데이터와 서비스를 제공합니다. WebAPI 개발을 위한 프레임워크를 선택할 때 많은 관심을 받은 두 가지 선택은 Flask와 FastAPI입니다. 두 프레임워크 모두 매우 인기가 높으며 각각 고유한 장점이 있습니다. 이번 글에서는 Fl에 대해 알아보겠습니다.
 Flask 애플리케이션 배포를 위한 Gunicorn과 uWSGI의 성능 비교
Jan 17, 2024 am 08:52 AM
Flask 애플리케이션 배포를 위한 Gunicorn과 uWSGI의 성능 비교
Jan 17, 2024 am 08:52 AM
Flask 애플리케이션 배포: Gunicorn과 suWSGI 비교 소개: 경량 Python 웹 프레임워크인 Flask는 많은 개발자들에게 사랑을 받고 있습니다. Flask 애플리케이션을 프로덕션 환경에 배포할 때 적절한 SGI(서버 게이트웨이 인터페이스)를 선택하는 것은 중요한 결정입니다. Gunicorn과 uWSGI는 두 가지 일반적인 SGI 서버입니다. 이 기사에서는 이에 대해 자세히 설명합니다.
 Flask-RESTful 및 Swagger: Python 웹 애플리케이션에서 RESTful API를 구축하기 위한 모범 사례(2부)
Jun 17, 2023 am 10:39 AM
Flask-RESTful 및 Swagger: Python 웹 애플리케이션에서 RESTful API를 구축하기 위한 모범 사례(2부)
Jun 17, 2023 am 10:39 AM
Flask-RESTful 및 Swagger: Python 웹 애플리케이션에서 RESTful API를 구축하기 위한 모범 사례(2부) 이전 기사에서는 Flask-RESTful 및 Swagger를 사용하여 RESTful API를 구축하기 위한 모범 사례를 살펴보았습니다. Flask-RESTful 프레임워크의 기본 사항을 소개하고 Swagger를 사용하여 RESTful API에 대한 문서를 작성하는 방법을 보여주었습니다. 책
