

오늘 드디어 MySQL 서브 데이터베이스와 서브 테이블을 알아냈으니 인터뷰에서 자랑할 수 있겠네요!
머리말
회사에서는 최근 서비스 분리 및 데이터 세분화에 힘쓰고 있습니다. 단일 패키지 테이블에 담긴 데이터의 양이 정말 너무 많고, 아직도 하루 60W씩 증가하고 있기 때문입니다.
이전에도 서브데이터베이스와 데이터베이스의 서브테이블에 대해 배워본 적이 있고 블로그 글도 몇개 읽어봤지만 막연한 개념만 알고 있었는데 지금 생각해보면 모든게 막연하네요.
오후 내내 데이터베이스 하위 테이블을 읽고 많은 기사를 읽었습니다. 이제 요약하겠습니다.
1부: 실제 웹사이트 개발 과정에서 직면한 문제.
2부: 다양한 분할 방법, 수직과 수평의 차이점 및 적용 가능한 측면은 무엇입니까?
3부: 현재 시장에 나와 있는 일부 오픈 소스 제품 및 기술과 그 장점과 단점은 무엇입니까?
4부: 아마도 가장 중요한 것은 데이터베이스를 수평으로 분할하는 것이 권장되지 않는 이유입니다! ? 이를 통해 계획 초기 단계에서 신중하게 처리하고 분할로 인해 발생하는 문제를 피할 수 있습니다.
용어 설명
라이브러리: 데이터베이스; 테이블: 테이블; 하위 데이터베이스 및 하위 테이블: 샤딩
데이터베이스 아키텍처의 진화 처음에는 단일 머신 데이터베이스만 사용하다가 직면했습니다. 점점 더 많은 요청이 발생하고 있습니다. 데이터베이스의 쓰기 작업과 읽기 작업을 분리하고 여러 슬레이브 데이터베이스 복사본(Slaver 복제)을 사용하여 읽기를 담당하며 마스터 데이터베이스(마스터)를 사용하여 쓰기를 담당합니다. 데이터 일관성을 유지하기 위해 마스터 데이터베이스에서 데이터를 동기식으로 가져옵니다. 구조적으로는 데이터베이스 마스터-슬레이브 동기화입니다. 슬레이브 라이브러리는 수평으로 확장할 수 있으므로 더 많은 읽기 요청이 문제가 되지 않습니다.
하지만 사용자 레벨이 높아지고 쓰기 요청이 점점 더 많아지면 어떻게 해야 할까요? 데이터는 일관되어야 하고 쓰기 작업에는 두 마스터 간의 동기화가 필요하기 때문에 마스터를 추가해도 문제가 해결되지 않습니다. 이는 복제와 동일하고 더 복잡합니다.
이때 쓰기 작업을 분할하려면 샤딩을 사용해야 합니다.
데이터베이스 및 테이블을 샤딩하기 전의 문제
모든 문제는 너무 크거나 작습니다. 여기서 직면하는 문제는 데이터의 양이 너무 크다는 것입니다.
사용자 요청량이 너무 많습니다
단일 서버 TPS, 메모리, IO가 제한되어 있기 때문입니다.
해결책: 요청을 여러 서버에 분산합니다. 실제로 사용자 요청과 SQL 쿼리 실행은 모두 리소스를 요청한다는 점에서 본질적으로 동일하지만 사용자 요청은 게이트웨이, 라우팅, http 서버 등을 통과합니다.
단일 데이터베이스가 너무 큽니다.
단일 데이터베이스의 처리 용량이 제한되어 있습니다.
단일 데이터베이스가 있는 서버의 디스크 공간이 부족합니다.
단일 데이터베이스 작업의 IO 병목 현상. 해결 방법: 더 작은 라이브러리로 분할
CRUD가 문제입니다. 색인 확장, 쿼리 시간 초과단일 테이블이 너무 큰 경우
해결 방법: 더 작은 데이터 세트를 사용하여 여러 테이블로 분할합니다.
데이터베이스와 테이블을 샤딩하는 방법
은 일반적으로 수직 분할과 수평 분할이 있는데 이는 결과 집합으로 설명되는 분할 방법으로 물리적인 공간 분할입니다.
우리는 직면한 문제에서 시작하여 해결합니다.설명:
첫째, 사용자 요청 수가 너무 많아서 이를 처리하기 위해 머신을 쌓아둡니다(이 기사의 초점은 아닙니다)그리고 이때 단일 라이브러리가 너무 큽니다. 테이블이 너무 많아서 데이터가 너무 많은지, 아니면 단일 데이터베이스 때문인지 확인하려면테이블이 많고 데이터가 많은 경우 수직 분할을 사용하여 업무에 따라 서로 다른 라이브러리로 나눕니다.
. 왜냐하면 수직적 분할은 우리가 실제 문제를 다루는 방식과 더 간단하고 일관성이 있기 때문입니다.
단일 테이블의 데이터 양이 너무 많으면 수평 분할을 사용해야 합니다. 즉, 테이블 데이터를 특정 규칙에 따라 여러 테이블로 나누거나 여러 라이브러리의 여러 테이블로 나누는 것입니다.
수직 분할
수직 테이블 분할
은 열 필드를 기반으로 하는 "큰 테이블을 작은 테이블로 분할"이기도 합니다. 일반적으로 테이블에는 많은 필드가 있으며 일반적으로 사용되지 않는 필드, 대용량 데이터, 긴 필드(예: 텍스트 유형 필드)는 "확장 테이블"로 분할됩니다. 일반적으로 수백 개의 열이 있는 대규모 테이블을 목표로 하며 쿼리 시 너무 많은 데이터로 인해 발생하는 "페이지 간" 문제도 방지합니다.
수직형 하위 라이브러리
수직형 하위 라이브러리는 사용자용 데이터베이스, 제품용 데이터베이스, 주문용 데이터베이스 등 시스템 내에서 서로 다른 비즈니스를 분할하는 것을 목표로 합니다. 분할한 후에는 하나의 서버가 아닌 여러 서버에 배치해야 합니다. 왜? 쇼핑 웹사이트가 외부 세계에 서비스를 제공하고 사용자, 제품, 주문 등에 대한 CRUD를 가지고 있다고 가정해 보겠습니다. 분할하기 전에는 모든 것이 단일 라이브러리에 포함되어 데이터베이스가 단일 데이터베이스의 처리 능력이 병목 현상을 일으켰습니다. 데이터베이스를 수직으로 분할한 후에도 여전히 데이터베이스 서버에 배치하면 사용자 수가 증가함에 따라 단일 데이터베이스의 처리 용량에 병목 현상이 발생하여 단일 서버의 디스크 공간, 메모리, tps 등이 매우 부족합니다. 따라서 위의 문제를 해결하고 향후 단일 시스템 리소스 문제에 직면하지 않도록 여러 서버로 분할해야 합니다. 单库处理能力成为瓶颈。按垂直分库后,如果还是放在一个数据库服务器上, 随着用户量增大,这会让单个数据库的处理能力成为瓶颈,还有单个服务器的磁盘空间,内存,tps等非常吃紧。所以我们要拆分到多个服务器上,这样上面的问题都解决了,以后也不会面对单机资源问题。
数据库业务层面的拆分,和服务的治理,降级机制类似,也能对不同业务的数据分别的进行管理,维护,监控,扩展等。数据库往往最容易成为应用系统的瓶颈,而数据库本身属于有状态的,相对于Web和应用服务器来讲,是比较难实现横向扩展
다운그레이드 메커니즘은 유사하며, 다양한 비즈니스의 데이터를 별도로 관리, 유지, 모니터링, 확장 등을 할 수도 있습니다. 데이터베이스는 종종 응용 프로그램 시스템의 병목 현상이 될 가능성이 가장 높으며 데이터베이스 자체는 color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(239, 112, 96);" >Stateful은 웹 및 애플리케이션 서버보다 구현하기가 더 어렵습니다수평 확장. 데이터베이스 연결 리소스는 소중하며 단일 시스템 처리 기능은 제한되어 있습니다. 동시성이 높은 시나리오에서는 수직 하위 데이터베이스가 IO 병목 현상, 연결 수 및 단일 시스템 하드웨어 리소스를 어느 정도 돌파할 수 있습니다. 🎜수평 분할
수평 하위 테이블
방대한 양의 데이터(예: 주문 테이블)가 포함된 단일 테이블의 경우 특정 규칙에 따라(RANGE,HASH取模等),切分到多张表里面去。但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈. 권장하지 않습니다.
수평 하위- 데이터베이스 및 하위 테이블
은 단일 테이블의 데이터가 여러 서버로 분할됩니다. 각 서버에는 해당 데이터베이스와 테이블이 있지만 테이블의 데이터 수집은 다릅니다. 수평 샤딩은 성능 병목 현상과 부담을 효과적으로 완화할 수 있습니다. IO의 병목 현상, 연결 수, 하드웨어 리소스 등을 돌파합니다.
수평 샤딩 규칙
RANGE
0에서 10000까지의 테이블 1개, 10001에서 10001까지의 테이블 1개 20000;
-
HASH 추출 모델
쇼핑몰 시스템은 일반적으로 사용자와 주문을 기본 테이블로 사용하고 관련 테이블을 보조 테이블로 사용하므로 데이터베이스 간 거래와 같은 문제가 발생하지 않습니다. 사용자 ID를 가져온 다음 해시를 가져와 다른 데이터베이스에 배포합니다.
- 예를 들어 Qiniu Cloud는 6개월 전의 데이터를 잘라내야 합니다. 1년 전이라도 다른 테이블에 넣어두면 시간이 지날수록 이 테이블의 데이터가 쿼리될 확률이 작아지므로 "핫 데이터"와 함께 넣을 필요가 없습니다. 핫 데이터와 콜드 데이터 분리"
.
하위 데이터베이스 및 테이블 이후에 발생하는 문제
트랜잭션 지원
하위 데이터베이스 및 테이블 이후에는 분산 트랜잭션. 分布式事务了。
如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
多库结果集合并(group by,order by)
类似于group by,order by
여러 데이터베이스 결과 세트 병합(그룹화, 정렬)
🎜Group by, order by이러한 그룹화 및 정렬 문은 사용할 수 없습니다🎜🎜Cross-database Join🎜🎜데이터베이스가 테이블로 분할된 후에는 테이블 간의 연결 작업이 제한되며, 서로 다른 위치에 있는 테이블을 조인할 수 없습니다. 하위 데이터베이스의 테이블은 서로 다른 하위 테이블 단위로 조인될 수 없습니다. 따라서 하나의 쿼리로 완료할 수 있는 비즈니스를 완료하려면 여러 쿼리가 필요할 수 있습니다. 대략적인 해결책: 전역 테이블: 기본 데이터, 모든 라이브러리에 복사본이 있습니다. 필드 중복성: 이러한 방식으로 일부 필드는 조인으로 쿼리할 필요가 없습니다. 시스템 레이어 어셈블리: 모든 것을 개별적으로 쿼리한 다음 이를 어셈블하는 것이 더 복잡합니다. 🎜하위 데이터베이스 및 하위 테이블 솔루션 제품
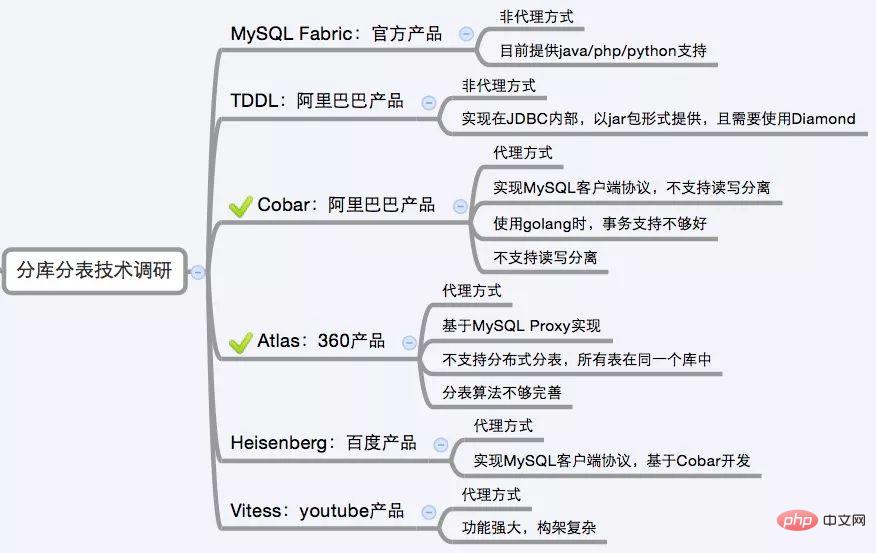
시중에는 상대적으로 많은 하위 데이터베이스 및 하위 테이블 미들웨어가 있으며, 그중 프록시 기반 미들웨어에는 MySQL 프록시 및 Amoeba는 Hibernate 프레임워크를 기반으로 Hibernate 샤드, jdbc Dangdangsharding-jdbc, Mogujie와 유사한 mybatis 기반 Maven 플러그인 TSharding, spring의 ibatis 템플릿 클래스의 Cobar 클라이언트. MySQL Proxy和Amoeba, 基于Hibernate框架的是Hibernate Shards,基于jdbc的有当当sharding-jdbc, 基于mybatis的类似maven插件式的有蘑菇街的蘑菇街TSharding, 通过重写spring的ibatis template类的Cobar Client。
还有一些大公司的开源产品:
我是程序员青戈,一个爱生活、爱分享的90后程序员。
本期关于Mysql分库分表的介绍和解决方案介绍到这里,希望能帮助到大家,后续更多Java面试类的文章请持续关注公众号Java学习指南일부 대기업의 오픈 소스 제품도 있습니다:
🎜🎜나는프로그래머 Qingge, 삶과 공유를 사랑하는 90년대 이후 프로그래머. 🎜
이 문제에서는 Mysql 하위 데이터베이스 및 하위 테이블이 소개됩니다. 여기에 솔루션이 소개되어 있습니다. 앞으로 더 많은 Java 인터뷰 기사를 보려면 공식 계정에 계속 관심을 가져주시기 바랍니다.Java 학습 가이드🎜. 🎜🎜
위 내용은 오늘 드디어 MySQL 서브 데이터베이스와 서브 테이블을 알아냈으니 인터뷰에서 자랑할 수 있겠네요!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7518
7518
 15
1378
52
81
11
53
19
21
68
15
1378
52
81
11
53
19
21
68

 MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) 데이터베이스 및 테이블 작성 : CreateAbase 및 CreateTable 명령을 사용하십시오. 2) 기본 작업 : 삽입, 업데이트, 삭제 및 선택. 3) 고급 운영 : 가입, 하위 쿼리 및 거래 처리. 4) 디버깅 기술 : 확인, 데이터 유형 및 권한을 확인하십시오. 5) 최적화 제안 : 인덱스 사용, 선택을 피하고 거래를 사용하십시오.
 phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
다음 단계를 통해 phpmyadmin을 열 수 있습니다. 1. 웹 사이트 제어판에 로그인; 2. phpmyadmin 아이콘을 찾고 클릭하십시오. 3. MySQL 자격 증명을 입력하십시오. 4. "로그인"을 클릭하십시오.
 Navicat Premium을 만드는 방법
Apr 09, 2025 am 07:09 AM
Navicat Premium을 만드는 방법
Apr 09, 2025 am 07:09 AM
Navicat Premium을 사용하여 데이터베이스 생성 : 데이터베이스 서버에 연결하고 연결 매개 변수를 입력하십시오. 서버를 마우스 오른쪽 버튼으로 클릭하고 데이터베이스 생성을 선택하십시오. 새 데이터베이스의 이름과 지정된 문자 세트 및 Collation의 이름을 입력하십시오. 새 데이터베이스에 연결하고 객체 브라우저에서 테이블을 만듭니다. 테이블을 마우스 오른쪽 버튼으로 클릭하고 데이터 삽입을 선택하여 데이터를 삽입하십시오.
 MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL은 개발자에게 필수적인 기술입니다. 1.MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템이며 SQL은 데이터베이스를 관리하고 작동하는 데 사용되는 표준 언어입니다. 2.MYSQL은 효율적인 데이터 저장 및 검색 기능을 통해 여러 스토리지 엔진을 지원하며 SQL은 간단한 문을 통해 복잡한 데이터 작업을 완료합니다. 3. 사용의 예에는 기본 쿼리 및 조건 별 필터링 및 정렬과 같은 고급 쿼리가 포함됩니다. 4. 일반적인 오류에는 구문 오류 및 성능 문제가 포함되며 SQL 문을 확인하고 설명 명령을 사용하여 최적화 할 수 있습니다. 5. 성능 최적화 기술에는 인덱스 사용, 전체 테이블 스캔 피하기, 조인 작업 최적화 및 코드 가독성 향상이 포함됩니다.
 Navicat에서 MySQL에 새로운 연결을 만드는 방법
Apr 09, 2025 am 07:21 AM
Navicat에서 MySQL에 새로운 연결을 만드는 방법
Apr 09, 2025 am 07:21 AM
응용 프로그램을 열고 새로운 연결 (Ctrl n)을 선택하여 Navicat에서 새로운 MySQL 연결을 만들 수 있습니다. "MySQL"을 연결 유형으로 선택하십시오. 호스트 이름/IP 주소, 포트, 사용자 이름 및 비밀번호를 입력하십시오. (선택 사항) 고급 옵션을 구성합니다. 연결을 저장하고 연결 이름을 입력하십시오.
 SQL이 행을 삭제 한 후 데이터를 복구하는 방법
Apr 09, 2025 pm 12:21 PM
SQL이 행을 삭제 한 후 데이터를 복구하는 방법
Apr 09, 2025 pm 12:21 PM
백업 또는 트랜잭션 롤백 메커니즘이없는 한 데이터베이스에서 직접 삭제 된 행 복구는 일반적으로 불가능합니다. 키 포인트 : 거래 롤백 : 트랜잭션이 데이터를 복구하기 전에 롤백을 실행합니다. 백업 : 데이터베이스의 일반 백업을 사용하여 데이터를 신속하게 복원 할 수 있습니다. 데이터베이스 스냅 샷 : 데이터베이스의 읽기 전용 사본을 작성하고 데이터를 실수로 삭제 한 후 데이터를 복원 할 수 있습니다. 주의해서 삭제 명령문을 사용하십시오. 실수로 데이터를 삭제하지 않도록 조건을주의 깊게 점검하십시오. WHERE 절을 사용하십시오 : 삭제할 데이터를 명시 적으로 지정하십시오. 테스트 환경 사용 : 삭제 작업을 수행하기 전에 테스트하십시오.
 단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
Redis는 단일 스레드 아키텍처를 사용하여 고성능, 단순성 및 일관성을 제공합니다. 동시성을 향상시키기 위해 I/O 멀티플렉싱, 이벤트 루프, 비 블로킹 I/O 및 공유 메모리를 사용하지만 동시성 제한 제한, 단일 고장 지점 및 쓰기 집약적 인 워크로드에 부적합한 제한이 있습니다.
 MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템으로, 주로 데이터를 신속하고 안정적으로 저장하고 검색하는 데 사용됩니다. 작업 원칙에는 클라이언트 요청, 쿼리 해상도, 쿼리 실행 및 반환 결과가 포함됩니다. 사용의 예로는 테이블 작성, 데이터 삽입 및 쿼리 및 조인 작업과 같은 고급 기능이 포함됩니다. 일반적인 오류에는 SQL 구문, 데이터 유형 및 권한이 포함되며 최적화 제안에는 인덱스 사용, 최적화 된 쿼리 및 테이블 분할이 포함됩니다.
