모든 시대에 배울 줄 아는 사람은 나쁜 대우를 받지 않을 것입니다
최근에 회사의 새로운 동료들이 잠금에 대해 오해를 하고 있다는 것을 알게 되었습니다. 그래서 오늘은 "잠금"과 동시 보안 컨테이너에 대해 이야기해 보겠습니다. 자바 사용 시 주의사항은 무엇인가요?
하지만 그 전에 왜 이것을 잠궈야 하는지 설명해야 합니다. 이는 동시성 버그의 원인부터 시작됩니다.
2019년에 이 문제에 대한 글을 쓴 적이 있습니다. 지금 그 글을 다시 보면 정말 부끄럽습니다.

컴퓨터에는 CPU, 메모리, 하드디스크가 있다는 것을 알고 있는데, 하드디스크의 읽기 속도가 가장 느리고, 그 다음이 메모리의 읽기 속도입니다. .. CPU의 동작보다 메모리를 읽는 속도가 너무 느려서 CPU캐시 L1, L2, L3을 하나 더 만들었습니다.
동시성 BUG를 생성하는 것은 바로 이 CPU 캐시와 현재 멀티 코어 CPU 상황입니다.

이 메서드를 CPU-A와 CPU-B에서 각각 실행하는 스레드 A와 스레드 B가 있는 경우 해당 작업은 먼저 메인 메모리에서 CPU로 각각 액세스하는 것입니다. 캐시에 있는 a 값은 현재 모두 0입니다.
그러면 각각 a++를 실행하는데 이때 각자의 눈에 있는 a의 값은 1입니다. 나중에 a가 메인 메모리에 플래싱되면 여전히 a의 값이 1입니다. 이는 문제가 됩니다. 1의 마지막 추가는 두 번 실행됩니다. 결과는 2가 아니라 1입니다.
이 문제를 가시성 문제라고 합니다.
우리의 a++ 문을 보면, 우리의 현재 언어는 모두 고급 언어입니다. 이는 실제로 사용하기 매우 편리한 것 같습니다. 실제로 실행해야 할 명령.
고급 언어의 문은 두 개 이상의 CPU 명령어로 변환될 수 있습니다. 예를 들어 a++는 최소 세 개의 CPU 명령어로 변환될 수 있습니다.
등록할 메모리에서
+1을
결과를 캐시나 메모리에 기록합니다.
이것은 불가능합니다. 원자적이기 때문에 명령문을 중단합니다. 실제로 CPU는 타임 슬라이스가 실행될 때 명령을 실행할 수 있습니다. 이 때 컨텍스트는 다른 스레드로 전환되어 역시 a++를 실행합니다. 다시 다시 전환하면 a 값이 실제로 잘못되었습니다.
이 문제를 원자성 문제라고 합니다.
그리고 성능을 최적화하기 위해 컴파일러나 해석기가 명령문의 실행 순서를 변경할 수 있습니다. 이를 명령어 재배열이라고 합니다. 가장 전형적인 예는 싱글톤 모드의 이중 확인입니다. 실행 효율성을 높이기 위해 CPU는 순서 없이 실행됩니다. 예를 들어 CPU가 메모리 데이터가 로드되기를 기다리는 동안 다음 추가 명령이 이전 명령의 계산 결과에 의존하지 않는다는 것을 알게 됩니다. 덧셈 명령어를 먼저 실행합니다.
이 문제를 주문 문제라고 합니다.
이제 우리는 동시성 버그의 원인, 즉 세 가지 주요 문제를 분석했습니다. CPU 캐시든, 멀티코어 CPU든, 고급 언어든, 비순차적 재배열이든 실제로는 꼭 필요한 일이므로 이러한 문제를 정면으로 마주할 수 밖에 없다는 것을 알 수 있습니다.
이러한 문제를 해결하려면 캐싱을 비활성화하고 컴파일러 명령 재배열, 상호 배제 등을 금지해야 합니다. 오늘 우리의 주제는 상호 배제와 관련이 있습니다.
상호 배제는 공유 변수에 대한 수정이 상호 배타적임을 보장합니다. 즉, 동시에 하나의 스레드만 실행됩니다. 상호배제하면 다들 자물쇠 생각나실 거라 믿습니다. 네, 오늘 주제는 자물쇠입니다! 잠금은 원자성 문제를 해결하도록 설계되었습니다.
자물쇠에 대해 이야기하면 Java 학생들의 첫 번째 반응은 결국 동기화 키워드입니다. 먼저 동기화에 대해 살펴보겠습니다. 일부 학생들은 동기화를 잘 이해하지 못하므로 사용에 있어 많은 함정이 있습니다.
먼저 코드를 살펴보겠습니다. 이 코드는 결국 임금을 늘리는 방법입니다. 그리고 스레드는 항상 우리의 임금이 동일한지 비교합니다. 간단히 말해 IntStream .rangeClosed(1,1000000).forEach, 일부 사람들은 이에 대해 익숙하지 않을 수 있습니다. 이 코드는 for 루프를 백만 번 실행하는 것과 같습니다. IntStream.rangeClosed(1,1000000).forEach,可能有些人对这个不太熟悉,这个代码的就等于 for 循环了100W次。
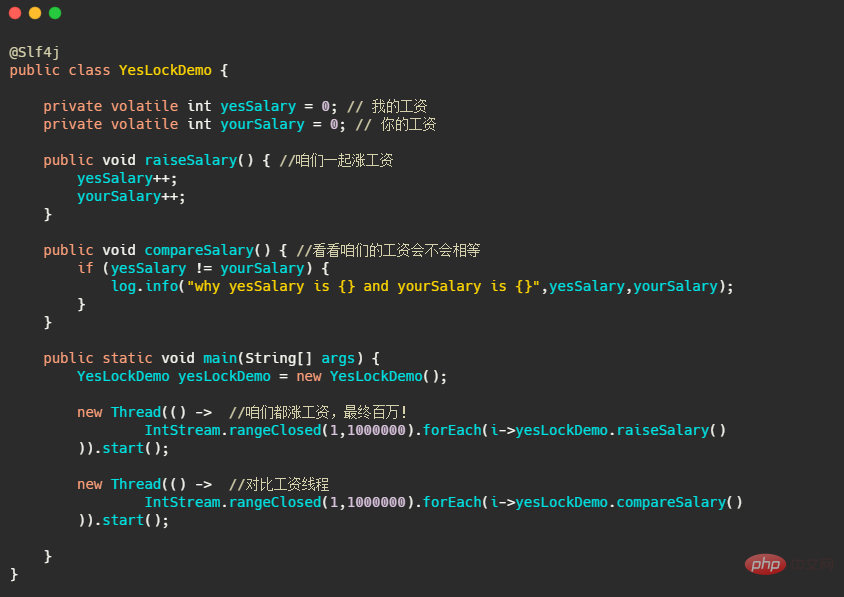
你先自己理解下,看看觉得有没有什么问题?第一反应好像没问题,你看着涨工资就一个线程执行着,这比工资也没有修改值,看起来好像没啥毛病?没有啥并发资源的竞争,也用 volatile 修饰了保证了可见性。
让我们来看一下结果,我截取了一部分。
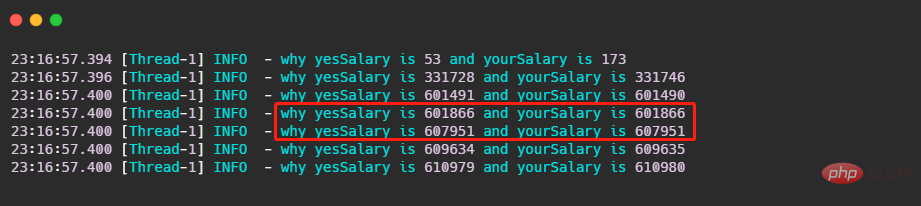
可以看到首先有 log 打出来就已经不对了,其次打出来的值竟然还相等!有没有出乎你的意料之外?有同学可能下意识就想到这就raiseSalary在修改,所以肯定是线程安全问题来给raiseSalary 加个锁!
请注意只有一个线程在调用raiseSalary方法,所以单给raiseSalary
raiseSalary가 수정 중이므로 raiseSalary 잠금을 추가하세요! 🎜🎜raiseSalary 메소드를 사용하므로 raiseSalary 메소드 잠금은 쓸모가 없습니다. 🎜이것은 실제로 위에서 언급한 원자성 문제입니다. 급여 인상 스레드가 yesSalary++가 아직 실행되지 않았습니다yourSalary++, 급여 스레드는 yesSalary != yourSalary 정말 사실인가요? 이것이 로그가 인쇄되는 이유입니다. yesSalary++还未执行yourSalary++时,比工资线程刚好执行到yesSalary != yourSalary 是不是肯定是 true ?所以才会打印出 log。
再者由于用 volatile 修饰保证了可见性,所以当打 log 的时候,可能yourSalary++已经执行完了,这时候打出来的 log 才会是yesSalary == yourSalary。
所以最简单的解决办法就是把raiseSalary() 和 compareSalary() 都用 synchronized 修饰,这样涨工资和比工资两个线程就不会在同一时刻执行,因此肯定就安全了!
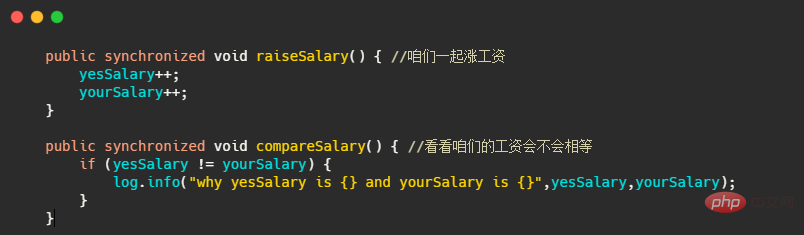
看起来锁好像也挺简单,不过这个 synchronized 的使用还是对于新手来说还是有坑的,就是你要关注 synchronized 锁的究竟是什么。
比如我改成多线程来涨工资。这里再提一下parallel
yourSalary++가 실행되었으며, 이때 로그 출력은 yesSalary == yourSalary. 🎜🎜그래서 가장 간단한 해결책은 raiseSalary() 및 compareSalary()는 모두 동기화로 수정되어 급여 인상과 급여 비교의 두 스레드가 동시에 실행되지 않으므로 확실히 안전합니다! 🎜병렬 , 이는 실제로 ForkJoinPool 스레드 풀 작업을 사용하며 기본 스레드 수는 CPU 코어 수입니다. 🎜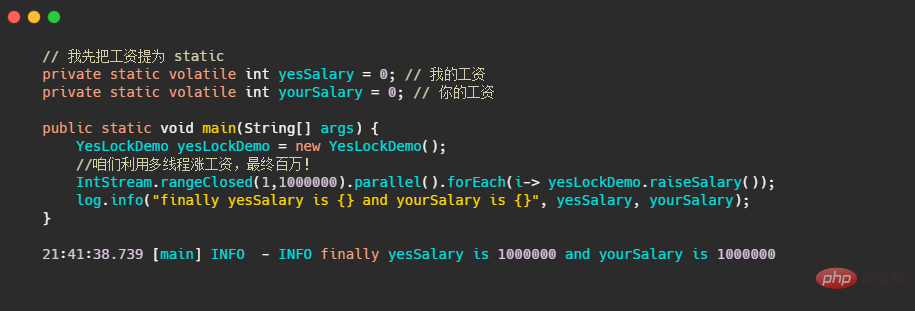
raiseSalary() 加了锁,所以最终的结果是对的。这是因为 synchronized 修饰的是yesLockDemo 인스턴스로 인해 우리 메인에는 인스턴스가 하나만 있으므로 멀티 스레드가 경쟁하는 것은 잠금이므로 최종 계산된 데이터가 정확합니다.
그런 다음 급여를 높이기 위해 각 스레드가 자체 yesLockDemo 인스턴스를 갖도록 코드를 수정하겠습니다.
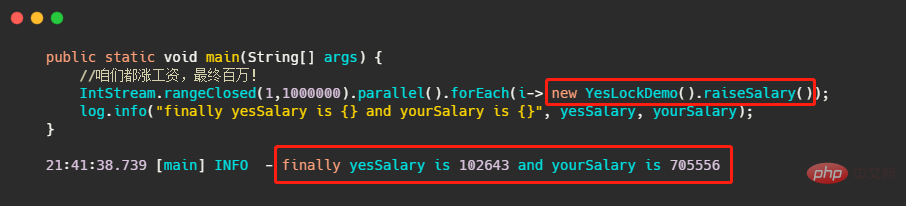
이 자물쇠가 왜 쓸모없는지 알게 될까요? 약속된 연봉 100만에서 10만으로 바뀐다? ? 다행히도 아직 70W가 남아 있습니다.
이것은 현재 lock이 비정적 메서드인 인스턴스 수준 잠금을 수정하고 각 스레드에 대해 인스턴스를 생성했기 때문에 이러한 스레드가 경쟁하는 것은 전혀 잠금이 아니기 때문입니다 그리고 위의 다중 스레드 계산에 대한 올바른 코드는 각 스레드가 동일한 인스턴스를 사용하므로 잠금을 위해 경쟁하기 때문입니다. 이때 코드가 정확해지기를 원한다면 인스턴스 수준 잠금을 클래스 수준 잠금으로 변경하기만 하면 됩니다.
매우 간단합니다. 정적 메서드를 동기화하는 것은 클래스 수준 잠금입니다.

또 다른 방법은 정적 변수를 선언하는 것입니다. 이 방법이 더 권장됩니다. 왜냐하면 비정적 메서드를 정적 메서드로 바꾸는 것은 실제로 코드 구조를 변경하는 것과 동일하기 때문입니다.

요약하자면, 동기화를 사용할 때 잠금이 무엇인지 주의해야 합니다. 정적 필드와 정적 메서드를 수정하면 클래스 수준 잠금이 됩니다. -정적 방법, 인스턴스 수준 잠금입니다 .
Hashtable을 사용하고 싶다면 ConcurrentHashMap을 사용하세요. Hashtable은 스레드에 안전하지만 모든 메소드를 너무 거칠게 다루기 때문입니다. 같은 방법으로 잠금! 소스코드를 살펴보겠습니다.
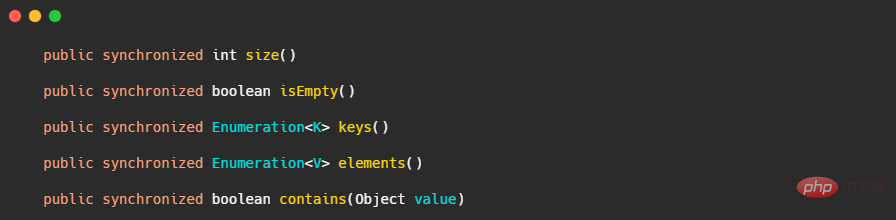
이 내용이 크기 계산과 관련이 있다고 생각하시나요? 포함을 호출할 때 크기를 조정하는 것이 허용되지 않는 이유는 잠금 세분성이 너무 낮기 때문입니다. 스레드 안전성을 높이기 위해 다양한 방법에서 다른 잠금을 사용해야 합니다.
그러나 메서드마다 잠금을 다르게 설정하는 것만으로는 충분하지 않습니다. 때로는 메서드의 일부 작업이 실제로 스레드로부터 안전하기 때문입니다. 경주 리소스 경쟁과 관련된 코드만 잠그면 됩니다. 특히 잠금을 필요로 하지 않는 코드의 경우 시간이 매우 많이 소요되며, 다음 코드와 같이 잠금을 오랫동안 점유하게 되고 다른 스레드는 줄을 서서만 대기할 수 있습니다.

분명히 두 번째 코드는 자물쇠를 사용하는 일반적인 방법이지만 일반적인 비즈니스 코드에서는 내 코드에 게시된 잠만큼 한눈에 확인하기가 쉽지 않습니다. 때로는 그럴 필요가 있습니다. 코드 실행 순서 등을 수정하여 잠금 세분성이 충분한지 확인하세요.
때로는 잠금이 충분히 두꺼운지 확인해야 하지만 JVM의 이 부분이 감지되어 다음 코드와 같이 최적화하는 데 도움이 됩니다.

메서드에서 호출되는 로직이 加锁-执行A-解锁-加锁-执行B-解锁,很明显的可以看出其实只需要经历加锁-执行A-执行B-解锁을 거친 것을 볼 수 있습니다.
그래서 JVM은 다음 상황과 유사하게 JIT(Just-In-Time) 컴파일 중에 잠금을 대략화하고 잠금 범위를 확장합니다.

그리고 JVM에는 잠금 제거작업도 있습니다. 이스케이프 분석을 통해 인스턴스 개체가 스레드 프라이빗인 것으로 판단되면 스레드로부터 안전해야 하므로 개체의 잠금 작업이 무시됩니다. 그리고 직접 전화했다.
읽기-쓰기 잠금은 시나리오에 따라 잠금의 세분성을 줄이기 위해 위에서 제출한 것입니다. 잠금을 읽기 잠금과 쓰기 잠금으로 나눕니다. 읽기는 많고 쓰기는 적은 상황에 적합합니다. 예를 들어 캐시를 직접 구현해 보세요.
은 여러 스레드가 동시에 공유 변수를 읽을 수 있도록 허용하지만 쓰기 작업은 상호 배타적입니다. 즉, 쓰기-쓰기는 상호 배타적이며 읽기 -쓰기는 상호 배타적입니다. 직설적으로 말하면, 쓰기 작업을 할 때 하나의 스레드만 쓸 수 있고 다른 스레드는 읽거나 쓸 수 없습니다.
작은 세부 사항도 포함된 작은 예를 살펴보겠습니다. 이 코드는 캐시 읽기를 시뮬레이션합니다. 먼저 캐시에 읽기 잠금을 설정하여 데이터를 가져옵니다. 캐시에 데이터가 없으면 읽기 잠금을 해제합니다. 그런 다음 데이터베이스에 쓰기 잠금을 설정합니다. 데이터를 캐시에 저장하고 반환합니다.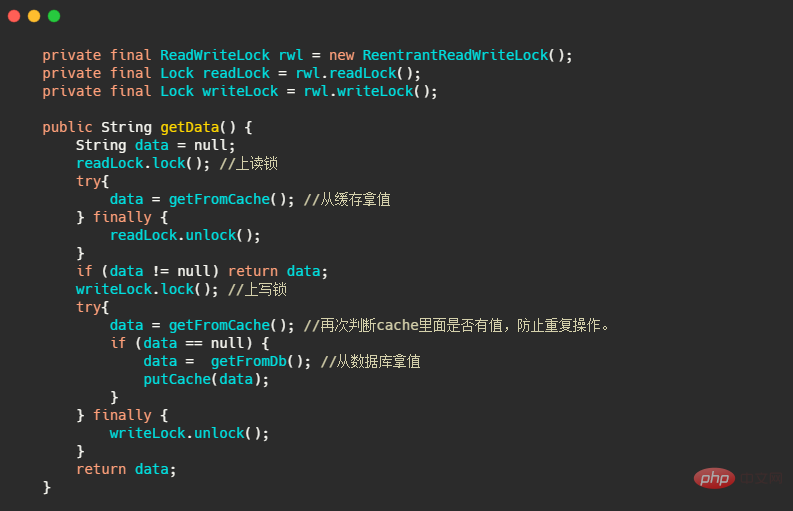
그러면 캐시가 비어 있으므로 모두 쓰기 잠금을 놓고 경쟁합니다. 결국 단 하나의 스레드만이 쓰기 잠금을 먼저 얻은 다음 데이터를 채울 것입니다. 캐시에. data = getFromCache() 是否有值,因为同一时刻可能会有多个线程调用getData()
물론 Lock의 사용 패러다임은 모두가 알고 있습니다. 최종 시도를 통해 잠금이 해제되는지 확인하세요. 읽기-쓰기 잠금에 대해 주의해야 할 또 다른 중요한 사항은 try- finally,来保证一定会解锁。而读写锁还有一个要点需要注意,也就是说锁不能升级。什么意思呢?我改一下上面的代码。
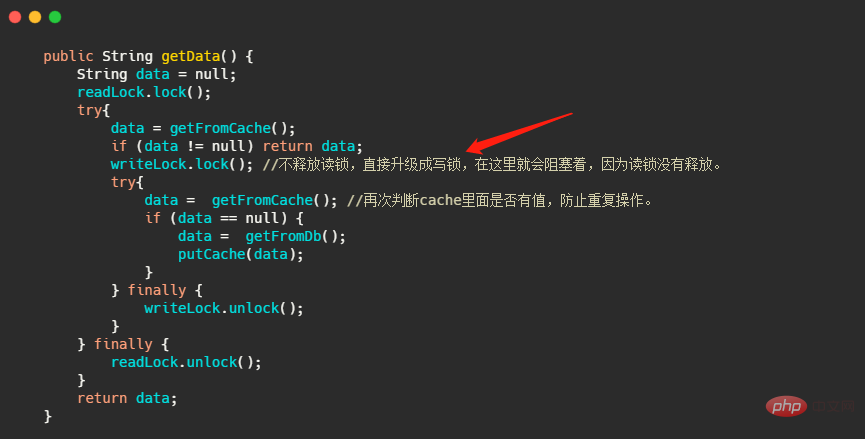
但是写锁内可以再用读锁,来实现锁的降级,有些人可能会问了这写锁都加了还要什么读锁。
还是有点用处的,比如某个线程抢到了写锁,在写的动作要完毕的时候加上读锁,接着释放了写锁,此时它还持有读锁可以保证能马上使用写锁操作完的数据,而别的线程也因为此时写锁已经没了也能读数据。
其实就是当前已经不需要写锁这种比较霸道的锁!所以来降个级让大家都能读。
小结一下,读写锁适用于读多写少的情况,无法升级,但是可以降级。Lock 的锁需要配合 try- finally잠금을 업그레이드할 수 없다는 것
지금도 여전히 읽기 잠금을 유지하고 있습니다. 즉시 쓰기를 사용할 수 있도록 데이터를 잠근 후 이 시점에서 쓰기 잠금이 해제되므로 다른 스레드도 데이터를 읽을 수 있습니다.
사실 쓰기 잠금과 같은 더 강력한 잠금은 필요하지 않습니다! 그러니 누구나 읽을 수 있도록 다운그레이드해 보겠습니다.그래서
읽기-쓰기 잠금에 적합하지 않은 시나리오에서는 뮤텍스 잠금을 직접 사용하는 것이 좋습니다. 읽기-쓰기 잠금도 상태 및 기타 작업에 대한 변위 판단을 수행해야 하기 때문입니다.
🎜🎜🎜🎜StampedLock🎜🎜🎜🎜🎜이 점도 조금 언급하고 싶은데 1.8이고 출현율이 ReentrantReadWriteLock만큼 높지는 않은 것 같습니다. 쓰기 잠금, 비관적 읽기 잠금, 낙관적 읽기를 지원합니다. 쓰기 잠금 및 비관적 읽기 잠금은 실제로 추가 낙관적 읽기가 있는 ReentrantReadWriteLock의 읽기-쓰기 잠금과 동일합니다. 🎜🎜위 분석을 통해 우리는 읽기-쓰기 잠금이 실제로 읽을 때 쓸 수 없다는 것을 알고 있으며 🎜StampedLock의 낙관적 읽기는 하나의 스레드에서 쓰기를 허용합니다🎜. 낙관적 읽기는 실제로 우리가 알고 있는 데이터베이스 낙관적 잠금과 동일합니다. 데이터베이스의 낙관적 잠금은 다음 SQL과 같은 버전 필드로 판단됩니다. 🎜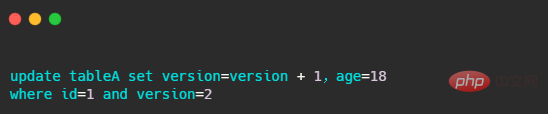
StampedLock 낙관적 독서도 이와 비슷합니다. 간단한 사용법을 살펴보겠습니다.

이것은 ReentrantReadWriteLock과 비교되는 부분입니다. 다른 것들은 좋지 않습니다. 예를 들어 StampedLock은 재진입을 지원하지 않으며 조건 변수를 지원하지 않습니다. 또 다른 점은 StampedLock을 사용할 때 인터럽트 연산을 호출하면 CPU가 100%가 되기 때문입니다 Concurrent 프로그래밍 웹사이트에서 제공하는 예제를 실행하여 재현했습니다.
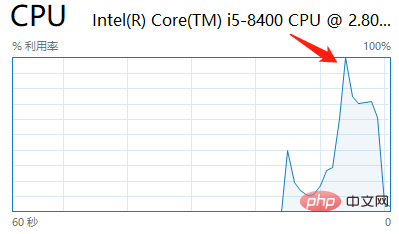
여기에서는 구체적인 이유를 자세히 설명하지 않습니다. 위의 내용은 매우 자세하게 설명되어 있습니다.
그래서 뭔가 강력해 보이는 것이 나올 때, 그것을 정말로 이해하고 익숙해져야 타겟이 될 수 있습니다.
Copy-on-write는 processfork() 작업. 읽기 작업이 쓰기를 차단하지 않고 쓰기 작업이 읽기를 차단하지 않기 때문에 비즈니스 코드 수준에도 매우 유용합니다. 읽기량이 많고 쓰기량이 적은 시나리오에 적합합니다. fork() 操作。对于我们业务代码层面而言也是很有帮助的,在于它的读操作不会阻塞写,写操作也不会阻塞读。适用于读多写少的场景。
例如 Java 中的实现 CopyOnWriteArrayList,有人可能一听,这玩意线程安全读的时候还不会阻塞写,好家伙就用它了!
你得先搞清楚,写时复制是会拷贝一份数据,你的任何一个修改动作在CopyOnWriteArrayList 中都会触发一次Arrays.copyOf
CopyOnWriteArrayList, 일부 사람들은 읽기가 스레드로부터 안전할 때 쓰기를 차단하지 않는다는 말을 들을 수 있으므로 좋은 사람들이 사용합니다! 🎜🎜먼저 🎜기록 중 복사가 데이터 복사본을 복사한다는 점을 이해해야 합니다🎜. 모든 수정 사항은 CopyOnWriteArrayList가 한 번 트리거됩니다Arrays.copyOf를 클릭한 다음 복사본을 수정합니다. 수정 작업이 많고 복사된 데이터도 크다면 재앙이 될 것입니다! 🎜마지막으로 동시 안전 컨테이너의 사용에 대해 이야기해 보겠습니다. 비교적 친숙한 ConcurrentHashMap을 예로 들어보겠습니다. 새로운 동료들은 동시 안전 컨테이너를 사용하는 한 스레드로부터 안전해야 한다고 생각하는 것 같습니다. 사실 반드시 그런 것은 아니고 어떻게 사용하느냐에 따라 다릅니다.
먼저 다음 코드를 살펴보겠습니다. 간단히 말하면 ConcurrentHashMap을 사용하여 모든 사람의 급여를 최대 100까지 기록합니다.
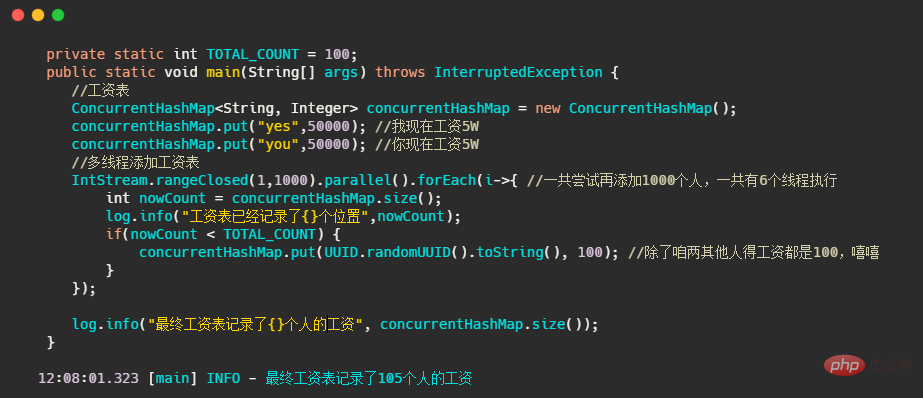
최종 결과는 기준을 초과하게 됩니다. 즉, 지도에 기록된 사람이 100명만이 아닙니다. 그렇다면 어떻게 결과가 정확할 수 있습니까? 잠금을 추가하는 것만큼 간단합니다.
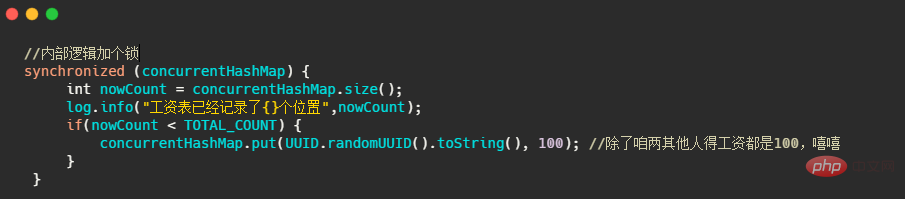
누군가 이것을 보고 이렇게 말했습니다. 이미 잠긴 경우 왜 ConcurrentHashMap을 사용해야 하나요? HashMap에 잠금만 추가하면 괜찮을 것 같아요! 그래 네가 맞아! 현재 사용 시나리오는 복합 작업이므로 먼저 맵의 크기를 판단한 다음 put 메서드를 실행합니다. ConcurrentHashMap 은 복합 작업이 스레드로부터 안전하다는 것을 보장할 수 없습니다!
그리고 ConcurrentHashMap은 사용에만 적합합니다. 복합 작업 대신 스레드로부터 안전한 메서드를 노출합니다. 예를 들어 다음 코드

물론 오늘은 간단하게 이야기를 했는데요, 앞서 분석했던 Kafka 이벤트 처리의 전체 과정처럼 스레드로부터 안전한 코드를 작성하는 것은 사실 쉽지 않습니다. 원래 버전은 다양한 잠금으로 제어되는 동시성과 보안이 전부였습니다. 나중에는 버그를 전혀 수정할 수 없었고, 디버깅도 어려웠고, 버그 수정도 어려웠습니다.
그래서 Kafka 이벤트 처리 모듈은 마침내 단일 스레드 이벤트 큐 모드로 변경되었습니다. 이는 공유 데이터 경쟁과 관련된 액세스를 이벤트로 추상화하고 해당 이벤트를 차단 큐에 넣은 다음 단일 스레드에서 처리합니다. .
그러면 자물쇠를 사용하기 전에 먼저 생각해봐야 할 게, 꼭 필요한 걸까요? 단순화할 수 있나요? 그렇지 않으면 나중에 유지하는 것이 얼마나 고통스러운지 알게 될 것입니다.
위 내용은 올바른 자물쇠를 사용하셨나요? Java '잠금' 문제에 대한 간략한 논의의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



