

코드 사양에서 SQL 문에 조인을 너무 많이 포함하지 않도록 요구하는 이유는 무엇입니까?
하위 질문 보내기
인터뷰어: Linux를 사용해 본 적이 있나요?
나: 예
인터뷰어:메모리 사용량을 확인하려면 어떤 명령어를 사용해야 하나요
나:free 또는 top
인터뷰어:free 명령어를 사용하면 어떤 정보를 볼 수 있는지 알려주실 수 있나요
나:글쎄요, 아래 그림처럼 메모리와 캐시 사용량을 볼 수 있어요
총계 memory
used 사용된 메모리
free free memory
버프/캐시 사용된 캐시
사용 가능한 메모리

면접관: 그럼 사용한 캐시(버프/캐시)를 지우는 방법을 아시나요
나: ... 모르겠어요
면접관: sync; echo 3 > /proc/sys/vm/drop_caches 그러면 버프/캐시를 지울 수 있어요. 이 명령을 온라인으로 실행할 수 있는지 알려주실 수 있나요?

em…., 돌아가서 알림을 기다립니다
SQL Join에 대해 다시 이야기합시다인터뷰어:
주제를 바꿔서 Join에 대한 이해에 대해 이야기해 보세요
나:좋아요 (한 번 더 틀리면 종료) 기회를 잡으세요)
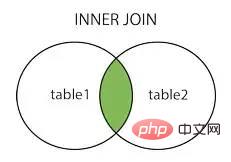
ReviewJoin in SQL은 특정 조건에 따라 지정된 테이블을 결합하여 클라이언트에 데이터를 반환할 수 있습니다
참여하는 방법이 있습니다내부 조인 내부 조인

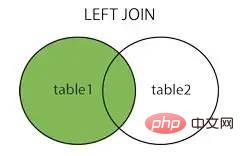
왼쪽 조인 왼쪽 조인
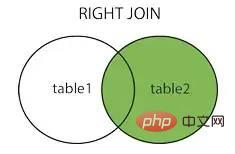
오른쪽 조인 오른쪽 조인
완전 가입
이미지 출처: https://www.cnblogs.com/reaptomorrow-flydream/p/8145610.html
인터뷰어: 프로젝트 개발 중에 조인 문을 사용해야 하는 경우 어떻게 성능을 최적화하고 개선합니까?
나: 데이터 크기가 작은 상황과 데이터 크기가 큰 상황 두 가지가 있습니다.
인터뷰어: 그럼?
나:
1. 데이터 크기가 작으면 메모리에 다 넣으면 됩니다
2 데이터 크기가 크다면
. 인덱스를 늘릴 수 있습니다. 조인문 실행 속도를 최적화하세요
중복 정보를 통해 조인 수를 줄일 수 있습니다.
테이블 연결 수를 줄여보세요. 하나의 SQL 문당 5회를 초과하면 안 됩니다
인터뷰어: 조인 문은 상대적으로 성능을 많이 잡아먹는다고 요약할 수 있죠?
나: 네
인터뷰어: 왜요?
Buffer
나: 조인문을 실행할 때 비교 과정이 있어야 해요
인터뷰어: 네
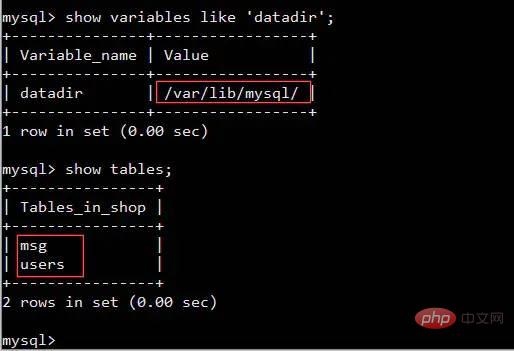
나:두 테이블을 하나씩 비교하는 건 상대적으로 느리기 때문에 할 수 있어요. 두 테이블의 데이터를 순서대로 메모리 블록으로 읽어옵니다. MySQL의 InnoDB 엔진을 예로 들면 그림과 같이 다음 명령문을 사용하여 관련 메모리 영역을 확실히 찾을 수 있습니다show variables like '%buffer%'
join_buffer_size 크기가 영향을 미칩니다. 조인 문의 실행 성능
인터뷰어: 또 뭐가 있나요?
주요 전제
나:모든 프로젝트는 결국 온라인화되고 데이터 생성은 불가피합니다. 데이터 규모가 너무 클 수는 없습니다. small
인터뷰어: 그렇습니다
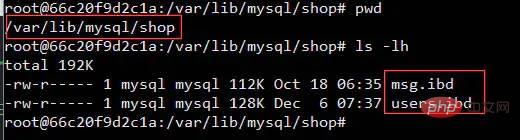
나:데이터베이스에 있는 대부분의 데이터는 결국 하드디스크에 저장되어 파일 형태로 저장됩니다.
MySQL의 InnoDB 엔진을 예로 들어보세요
InnoDB는 페이지를 기본 IO 단위로 사용하며 각 페이지의 크기는 16KB입니다
InnoDB는 각 테이블에 대한 저장소를 생성합니다. Data .ibd 파일
Verification
Me:이것은 연결할 테이블 수만큼 파일을 읽어야 한다는 뜻입니다. 인덱스를 사용할 수는 있지만 여전히 잦은 이동은 불가피합니다. 하드디스크
인터뷰어:즉, 자기헤드를 자주 움직이면 성능에 영향을 미치게 되겠죠?
나:네, 현재 오픈소스 프레임워크에서는 성능이 크게 향상됐다고 말하고 싶지 않나요? hbase, kafka와 같은 순차 읽기 및 쓰기를 통해 성능을 향상시켰나요?
인터뷰어: 그렇습니다. Linux에서 이를 최적화했다고 생각하시나요? 팁, 무료 명령을 다시 실행하여 살펴보세요
나: 이상합니다. 캐시 점유량 1.2G 이상
이미지 출처: https://www.linuxatemyram.com/
인터뷰어: 혹시
버프/ 캐시에 저장됨 무엇 이다?
버프/캐시가 왜 이렇게 많은 메모리를 차지하고, 사용 가능한 메모리도 있는데 아직 1.1G가 남아있나요?
버프/캐시가 차지한 메모리를 정리하기 위해 두 가지 명령을 사용할 수 있는데, 프로세스를 종료해야만 사용을 해제할 수 있는 이유는 무엇입니까?
핀, 신중하게 생각해 보셨나요
몇 분 후
나: 버프/캐시가 차지하는 메모리를 너무 가볍게 해제하는 것은 중요하지 않으며 이를 삭제해도 시스템 작동에 영향을 미치지 않는다는 의미입니다.
인터뷰어: 전혀 옳지 않습니다
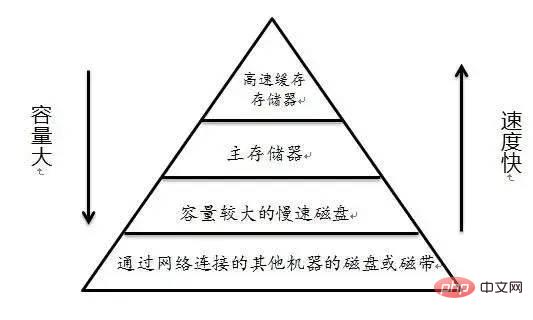
나: 그럴까요? "CSAPP"(컴퓨터 시스템 심층 이해)의 한 문장이 생각납니다
메모리 계층 구조의 본질은 저장 장치의 각 계층이 하위 계층 장치의 캐시라는 것입니다
Inlayman's 즉, Linux는 메모리를 하드 디스크의 캐시로 취급합니다
관련 정보: http://tldp.org/LDP/sag/html/buffer-cache.html
인터뷰어: 이제 알았네요 포인트 질문에 어떻게 대답해야 할까요
나:나...
Join Algorithm
인터뷰어:한 번 더 기회를 달라고 하면 어떻게 하시겠습니까? Join 알고리즘을 구현하려면?
나: 색인이 없으면 중첩 루프가 종료됩니다. 색인이 있는 경우 색인을 사용하여 성능을 향상시킬 수 있습니다.
인터뷰어: join_buffer로 돌아가서, Join_buffer에 무엇이 저장되어 있다고 생각하시나요?
Me: 스캐닝 과정에서 데이터베이스는 테이블을 선택하고 반환하려는 데이터를 넣고 다른 테이블과 비교해야 합니다. .join_buffer
인터뷰어: 인덱스가 있을 때 어떻게 처리하나요?
나: 두 테이블의 인덱스 트리를 읽고 비교하면 됩니다. 인덱스 없는 처리 방법을 소개하겠습니다.
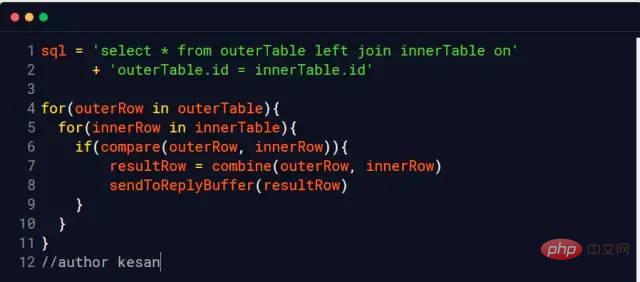
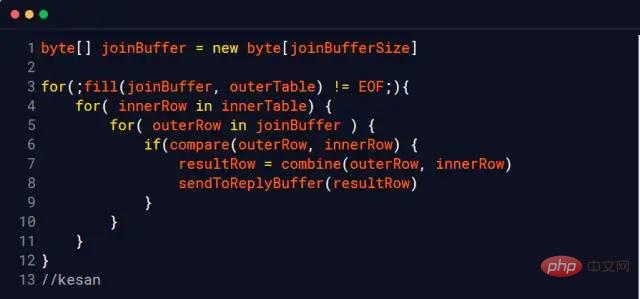
Nested Loop Join
Nested 루프만 한 번에 한 행의 데이터를 읽습니다. 즉, 외부 테이블에 100,000개의 데이터 행이 있고 내부 테이블에 100개의 데이터 행이 있으면 10,000,000번 읽어야 합니다(이 두 테이블의 파일이 있다고 가정). 작동되지 않음) 시스템은 이를 메모리에 캐시하므로 이를 콜드 데이터 테이블이라고 부릅니다.)
물론 현재 이 알고리즘을 사용하는 데이터베이스 엔진은 없습니다(너무 느림)
중첩 루프 차단
블록 블록, 즉 I/O 오버헤드를 줄이기 위해 매번 데이터 조각을 메모리로 가져오는 것을 말합니다
MySQL InnoDB는 인덱스를 사용할 수 없을 때 이 알고리즘을 사용합니다.
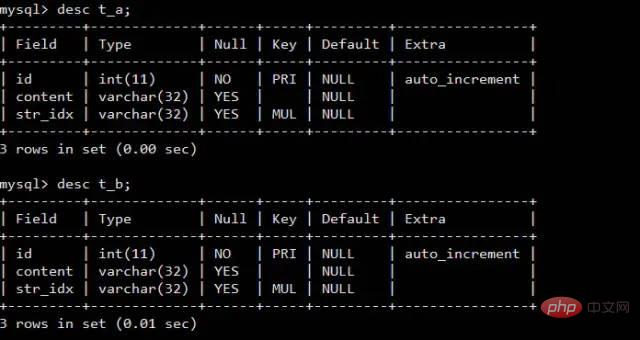
다음 두 테이블 t_a 및 t_b를 고려하세요.
인덱스를 조인 작업 수행에 사용할 수 없는 경우 InnoDB는 자동으로 차단 중첩 루프 알고리즘을 사용합니다.
요약
학교 다닐 때 데이터베이스 선생님이 데이터베이스 패러다임 시험을 가장 좋아하셨어요. , 중복될 수 없는 경우 가입하십시오. 실제로 성능에 영향을 미칩니다. Join_buffer_size를 늘리거나 솔리드 스테이트 드라이브로 변경해 보세요.
References
"컴퓨터 시스템에 대한 심층적인 이해" - 6장 메모리 계층
"리눅스 디스크 캐시를 이용한 실험과 재미" 저자는 하드 디스크 캐시가 프로그램 실행 성능에 미치는 영향을 설명하기 위해 몇 가지 예를 사용합니다.
"리눅스가 내 램을 먹었다》무료 매개변수 설명
리눅스에서 버퍼/페이지 캐시(디스크 캐시)를 지우는 방법 기사 시작 부분의 하위 질문 명령에 대한 설명
MySQL 실행 방법: 루트에서 MySQL 이해하기
Block MariaDB의 최고 루프 공식 문서는 Block-Nested-Loop 알고리즘의 구현을 설명합니다

. 인덱스를 늘릴 수 있습니다. 조인문 실행 속도를 최적화하세요
중복 정보를 통해 조인 수를 줄일 수 있습니다.
테이블 연결 수를 줄여보세요. 하나의 SQL 문당 5회를 초과하면 안 됩니다
show variables like '%buffer%'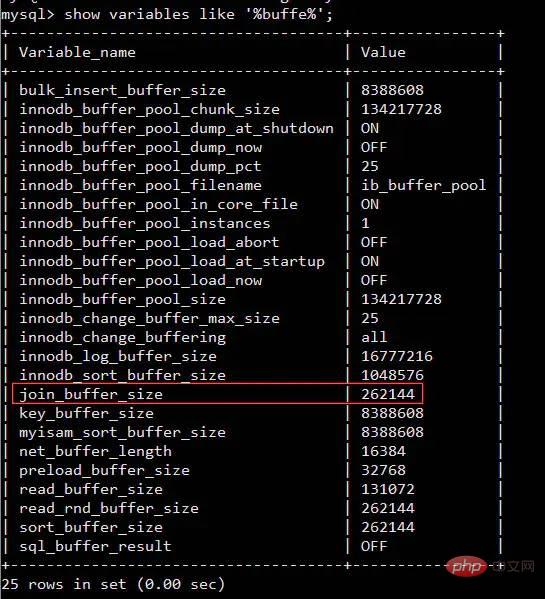
InnoDB는 페이지를 기본 IO 단위로 사용하며 각 페이지의 크기는 16KB입니다
InnoDB는 각 테이블에 대한 저장소를 생성합니다. Data .ibd 파일


버프/ 캐시에 저장됨 무엇 이다?
버프/캐시가 왜 이렇게 많은 메모리를 차지하고, 사용 가능한 메모리도 있는데 아직 1.1G가 남아있나요?
버프/캐시가 차지한 메모리를 정리하기 위해 두 가지 명령을 사용할 수 있는데, 프로세스를 종료해야만 사용을 해제할 수 있는 이유는 무엇입니까?
메모리 계층 구조의 본질은 저장 장치의 각 계층이 하위 계층 장치의 캐시라는 것입니다
관련 정보: http://tldp.org/LDP/sag/html/buffer-cache.html


"컴퓨터 시스템에 대한 심층적인 이해" - 6장 메모리 계층
"리눅스 디스크 캐시를 이용한 실험과 재미" 저자는 하드 디스크 캐시가 프로그램 실행 성능에 미치는 영향을 설명하기 위해 몇 가지 예를 사용합니다.
"리눅스가 내 램을 먹었다》무료 매개변수 설명
리눅스에서 버퍼/페이지 캐시(디스크 캐시)를 지우는 방법 기사 시작 부분의 하위 질문 명령에 대한 설명
MySQL 실행 방법: 루트에서 MySQL 이해하기
Block MariaDB의 최고 루프 공식 문서는 Block-Nested-Loop 알고리즘의 구현을 설명합니다
위 내용은 코드 사양에서 SQL 문에 조인을 너무 많이 포함하지 않도록 요구하는 이유는 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7644
7644
 15
1392
52
91
11
73
19
34
152
15
1392
52
91
11
73
19
34
152

 Hibernate 프레임워크에서 HQL과 SQL의 차이점은 무엇입니까?
Apr 17, 2024 pm 02:57 PM
Hibernate 프레임워크에서 HQL과 SQL의 차이점은 무엇입니까?
Apr 17, 2024 pm 02:57 PM
HQL과 SQL은 Hibernate 프레임워크에서 비교됩니다. HQL(1. 객체 지향 구문, 2. 데이터베이스 독립적 쿼리, 3. 유형 안전성), SQL은 데이터베이스를 직접 운영합니다(1. 데이터베이스 독립적 표준, 2. 복잡한 실행 파일) 쿼리 및 데이터 조작).
 Oracle SQL의 나누기 연산 사용법
Mar 10, 2024 pm 03:06 PM
Oracle SQL의 나누기 연산 사용법
Mar 10, 2024 pm 03:06 PM
"OracleSQL의 나눗셈 연산 사용법" OracleSQL에서 나눗셈 연산은 일반적인 수학 연산 중 하나입니다. 데이터 쿼리 및 처리 중에 나누기 작업은 필드 간의 비율을 계산하거나 특정 값 간의 논리적 관계를 도출하는 데 도움이 될 수 있습니다. 이 문서에서는 OracleSQL의 나누기 작업 사용법을 소개하고 구체적인 코드 예제를 제공합니다. 1. OracleSQL의 두 가지 분할 연산 방식 OracleSQL에서는 두 가지 방식으로 분할 연산을 수행할 수 있습니다.
 Oracle과 DB2의 SQL 구문 비교 및 차이점
Mar 11, 2024 pm 12:09 PM
Oracle과 DB2의 SQL 구문 비교 및 차이점
Mar 11, 2024 pm 12:09 PM
Oracle과 DB2는 일반적으로 사용되는 관계형 데이터베이스 관리 시스템으로, 각각 고유한 SQL 구문과 특성을 가지고 있습니다. 이 기사에서는 Oracle과 DB2의 SQL 구문을 비교 및 차이점을 설명하고 구체적인 코드 예제를 제공합니다. 데이터베이스 연결 Oracle에서는 다음 문을 사용하여 데이터베이스에 연결합니다. CONNECTusername/password@database DB2에서 데이터베이스에 연결하는 문은 다음과 같습니다. CONNECTTOdataba
 MyBatis 동적 SQL 태그의 Set 태그 기능에 대한 자세한 설명
Feb 26, 2024 pm 07:48 PM
MyBatis 동적 SQL 태그의 Set 태그 기능에 대한 자세한 설명
Feb 26, 2024 pm 07:48 PM
MyBatis 동적 SQL 태그 해석: Set 태그 사용법에 대한 자세한 설명 MyBatis는 풍부한 동적 SQL 태그를 제공하고 데이터베이스 작업 명령문을 유연하게 구성할 수 있는 탁월한 지속성 계층 프레임워크입니다. 그 중 Set 태그는 업데이트 작업에서 매우 일반적으로 사용되는 UPDATE 문에서 SET 절을 생성하는 데 사용됩니다. 이 기사에서는 MyBatis에서 Set 태그의 사용법을 자세히 설명하고 특정 코드 예제를 통해 해당 기능을 보여줍니다. Set 태그란 무엇입니까? Set 태그는 MyBati에서 사용됩니다.
 SQL의 ID 속성은 무엇을 의미합니까?
Feb 19, 2024 am 11:24 AM
SQL의 ID 속성은 무엇을 의미합니까?
Feb 19, 2024 am 11:24 AM
SQL에서 ID란 무엇입니까? SQL에서 ID는 자동 증가 숫자를 생성하는 데 사용되는 특수 데이터 유형으로, 테이블의 각 데이터 행을 고유하게 식별하는 데 사용됩니다. ID 열은 일반적으로 기본 키 열과 함께 사용되어 각 레코드에 고유한 식별자가 있는지 확인합니다. 이 문서에서는 Identity를 사용하는 방법과 몇 가지 실제 코드 예제를 자세히 설명합니다. Identity를 사용하는 기본 방법은 테이블을 생성할 때 Identit을 사용하는 것입니다.
 여러 테이블을 추가하기 위해 SQL 문을 사용하지 않고 Springboot+Mybatis-plus를 구현하는 방법
Jun 02, 2023 am 11:07 AM
여러 테이블을 추가하기 위해 SQL 문을 사용하지 않고 Springboot+Mybatis-plus를 구현하는 방법
Jun 02, 2023 am 11:07 AM
Springboot+Mybatis-plus가 다중 테이블 추가 작업을 수행하기 위해 SQL 문을 사용하지 않을 때 내가 직면한 문제는 테스트 환경에서 생각을 시뮬레이션하여 분해됩니다. 매개 변수가 있는 BrandDTO 개체를 생성하여 배경으로 매개 변수 전달을 시뮬레이션합니다. Mybatis-plus에서 다중 테이블 작업을 수행하는 것은 매우 어렵다는 것을 Mybatis-plus-join과 같은 도구를 사용하지 않으면 해당 Mapper.xml 파일을 구성하고 냄새나고 긴 ResultMap만 구성하면 됩니다. 해당 SQL 문을 작성합니다. 이 방법은 번거로워 보이지만 매우 유연하며 다음을 수행할 수 있습니다.
 SQL에서 5120 오류를 해결하는 방법
Mar 06, 2024 pm 04:33 PM
SQL에서 5120 오류를 해결하는 방법
Mar 06, 2024 pm 04:33 PM
해결 방법: 1. 로그인한 사용자에게 데이터베이스에 액세스하거나 운영할 수 있는 충분한 권한이 있는지 확인하고 해당 사용자에게 올바른 권한이 있는지 확인하십시오. 2. SQL Server 서비스 계정에 지정된 파일에 액세스할 수 있는 권한이 있는지 확인하십시오. 3. 지정된 데이터베이스 파일이 다른 프로세스에 의해 열렸거나 잠겼는지 확인하고 파일을 닫거나 해제한 후 쿼리를 다시 실행하십시오. .관리자로 Management Studio를 실행해 보세요.
 MySQL에서 데이터 집계 및 통계를 위해 SQL 문을 사용하는 방법은 무엇입니까?
Dec 17, 2023 am 08:41 AM
MySQL에서 데이터 집계 및 통계를 위해 SQL 문을 사용하는 방법은 무엇입니까?
Dec 17, 2023 am 08:41 AM
MySQL에서 데이터 집계 및 통계를 위해 SQL 문을 사용하는 방법은 무엇입니까? 데이터 집계 및 통계는 데이터 분석 및 통계를 수행할 때 매우 중요한 단계입니다. 강력한 관계형 데이터베이스 관리 시스템인 MySQL은 데이터 집계 및 통계 작업을 쉽게 수행할 수 있는 풍부한 집계 및 통계 기능을 제공합니다. 이 기사에서는 SQL 문을 사용하여 MySQL에서 데이터 집계 및 통계를 수행하는 방법을 소개하고 구체적인 코드 예제를 제공합니다. 1. COUNT 함수를 사용합니다. COUNT 함수는 가장 일반적으로 사용됩니다.
