처음 이 글을 쓰기 시작했을 때 상당히 혼란스러웠습니다. 온라인에서 "URL을 입력하면 페이지 표시에 어떤 일이 일어나는지"라고 검색하면 많은 정보를 찾을 수 있기 때문입니다. 게다가 이 면접질문은 기본적으로 필수질문인데, 지난 2월 면접에서는 무슨 일이 있었는지 알고 있었지만, 면접관님이 차근차근 계속해서 질문을 하시다보니 내용이 명확하지 않은 부분이 많았습니다.
이 글의 목적은 URL을 입력한 후 일어나는 일을 통해 지식을 요약하고 확장하는 것입니다. 그래서 글이 복잡할 수도 있습니다.
전체 프로세스는 다음과 같습니다.
브라우저에 URL을 입력하기 시작하면 브라우저는 실제로 이미 가능한 URL과 지능적으로 일치하며 시작됩니다. 기록 기록, 북마크 등에서 입력한 문자열에 해당할 수 있는 URL을 찾은 다음, URL 주소를 완성할 수 있도록 지능적인 프롬프트를 제공합니다. Google Chrome 브라우저의 경우 캐시에서 직접 웹페이지를 표시합니다. 즉, Enter 키를 누르기 전에 페이지가 표시됩니다.
1. 요청이 시작되면 브라우저가 가장 먼저 하는 일은 도메인 이름을 확인하는 것입니다. 일반적으로 브라우저는 먼저 호스트를 확인합니다. 이 도메인 이름에 해당하는 규칙이 있습니까? 그렇다면 호스트 파일의 IP 주소를 직접 사용하십시오.
2. 로컬 호스트 파일에서 해당 IP 주소를 찾을 수 없으면 브라우저는 로컬 DNS 서버로 DNS 요청을 보냅니다. 로컬 DNS 서버는 일반적으로 China Telecom 및 China Mobile과 같은 네트워크 액세스 서버 공급자가 제공합니다.
3. 입력한 URL에 대한 DNS 요청이 로컬 DNS 서버에 도달한 후 로컬 DNS 서버는 먼저 캐시 레코드를 쿼리하고 이 레코드가 캐시에 있으면 결과를 직접 반환할 수 있습니다. 재귀적으로 쿼리하는 방법입니다. 그렇지 않은 경우 로컬 DNS 서버는 DNS 루트 서버에도 쿼리합니다.
4. 루트 DNS 서버는 도메인 이름과 IP 주소 간의 구체적인 대응을 기록하지 않고 대신 도메인 서버로 가서 계속 쿼리하고 도메인 서버 주소를 제공할 수 있음을 로컬 DNS 서버에 알려줍니다. 이 프로세스는 반복적인 프로세스입니다.
5. 로컬 DNS 서버는 계속해서 도메인 서버에 요청을 보냅니다. 이 예에서 요청 개체는 .com 도메인 서버입니다. .com 도메인 서버는 요청을 받은 후 도메인 이름과 IP 주소 간의 대응을 직접 반환하지 않고 대신 로컬 DNS 서버에 도메인 이름에 대한 확인 서버의 주소를 알려줍니다.
6. 마지막으로 로컬 DNS 서버는 도메인 이름 확인 서버에 요청을 보낸 다음 도메인 이름과 IP 주소 간의 통신을 받습니다. 로컬 DNS 서버는 IP 주소를 사용자의 컴퓨터에 반환할 뿐만 아니라 또한 이 통신 내용을 캐시에 저장하여 다음에 다른 사용자가 쿼리할 때 결과를 직접 반환하여 네트워크 액세스 속도를 높일 수 있습니다.
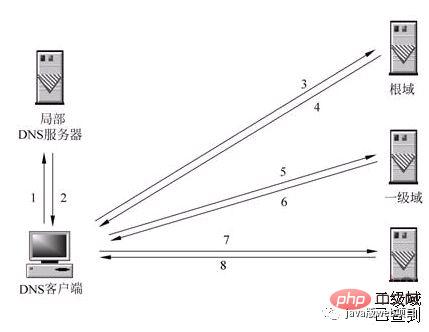
아래 그림은 이 과정을 완벽하게 설명합니다:

DNS(Domain Name System, Domain Name System)는 도메인 이름과 IP 주소를 서로 매핑하는 인터넷상의 분산 데이터베이스로, 사용자가 기억할 필요 없이 보다 편리하게 인터넷에 접속할 수 있도록 해줍니다. 무엇을 사용할 수 있습니까? 기기에서 직접 읽은 IP 번호 문자열입니다. 최종적으로 호스트 이름을 통해 호스트 이름에 해당하는 IP 주소를 얻는 과정을 도메인 이름 확인(또는 호스트 이름 확인)이라고 합니다.
일반인의 관점에서 보면 우리는 167.23.10.2와 같은 IP 주소를 기억하는 것보다 www.baidu.com과 같은 웹사이트 이름을 기억하는 데 더 익숙합니다. 그리고 컴퓨터는 www.baidu.com과 같은 링크보다 웹사이트의 IP 주소를 더 잘 기억합니다. DNS는 전화번호부와 같기 때문입니다. 예를 들어, 도메인 이름 www.baidu.com을 찾고 있다면 전화번호부를 보면 아, 전화번호(IP)가 167.23.10.2라는 것을 알 수 있습니다. .
1. 재귀 분석
로컬 DNS 서버가 클라이언트의 DNS 쿼리에 스스로 응답할 수 없는 경우 필요합니다. 다른 DNS 서버에 쿼리합니다. 이때 두 가지 방법이 있는데, 그림에 보이는 것이 재귀적 방법이다. 로컬 DNS 서버는 다른 DNS 서버에 대한 쿼리를 담당합니다. 일반적으로 먼저 도메인 이름의 루트 도메인 서버에 쿼리한 다음 루트 도메인 이름 서버에서 한 번에 한 수준 아래로 쿼리합니다. 최종 쿼리 결과는 로컬 DNS 서버로 반환되고, 로컬 DNS 서버는 이를 클라이언트로 반환합니다.

2. 반복 분석
로컬 DNS 서버 자체가 클라이언트의 DNS 쿼리에 응답할 수 없는 경우 그림과 같이 반복 쿼리를 통해 해결할 수도 있습니다. 로컬 DNS 서버는 자체적으로 다른 DNS 서버에 쿼리하지 않지만 도메인 이름을 확인할 수 있는 다른 DNS 서버의 IP 주소를 클라이언트 DNS 프로그램에 반환한 다음 클라이언트 DNS 프로그램은 쿼리 결과가 나올 때까지 계속해서 이러한 DNS 서버에 쿼리합니다. 까지 얻었습니다. 즉, 반복 분석은 관련 서버를 찾는 데만 도움이 될 뿐, 확인하는 데에는 도움이 되지 않습니다. 예를 들어, baidu.com의 서버 IP 주소는 192.168.4.5입니다. 제가 매우 바빠서 여기에서만 도움을 드릴 수 있습니다.
앞에서 루트 DNS 서버와 도메인 DNS 서버에 대해 언급했습니다. DNS 도메인 네임 공간이 구성되는 방식입니다. 기능에 따라 네임스페이스에서 DNS 도메인 이름을 설명하는 데 사용되는 5가지 범주와 각 이름 유형의 예가 아래 표에 소개되어 있습니다. 웹사이트에 충분한 사용자가 있을 때 매번 요청되는 리소스가 동일한 시스템에 있으면 시스템이 언제든지 중단될 수 있습니다. 해결 방법은 DNS 로드 밸런싱 기술을 사용하는 것입니다. DNS 서버에서 동일한 호스트 이름에 대해 여러 IP 주소를 구성하는 것입니다. DNS 쿼리에 응답할 때 DNS 서버는 호스트가 기록한 IP 주소로 각 쿼리에 응답합니다. DNS 파일에서 서로 다른 구문 분석 결과를 순서대로 반환하고 클라이언트 액세스를 서로 다른 시스템으로 안내하여 서로 다른 클라이언트가 서로 다른 서버에 액세스하도록 하여 예를 들어 각 시스템의 로드에 따라 시스템과 시스템 사이의 거리를 조정합니다. 사용자는 지리적 거리 등일 수 있습니다.
 3. 브라우저는 웹 서버에 HTTP 요청을 보냅니다
3. 브라우저는 웹 서버에 HTTP 요청을 보냅니다
</h4>에서 TCP 연결 요청을 시작합니다. <p style="margin: 10px auto;line-height: 25px;font-family: 微软雅黑;font-size: 14px;white-space: normal;background-color: rgb(255, 255, 255);">이 연결 요청이 서버에 도달한 후(LAN을 제외한 다양한 라우팅 장치를 통해) 네트워크 카드에 들어간 다음 커널의 TCP/IP 프로토콜 스택에 들어갑니다(연결 요청을 식별하는 데 사용됨) , 패킷을 캡슐화 해제하고 계층별로 벗겨내고 Netfilter 방화벽(커널에 속한 모듈)에 의해 필터링될 수도 있으며 마지막으로 WEB 프로그램에 도달하고 마지막으로 TCP/IP 연결을 설정합니다. 그림과 같은 TCP 연결: TCP 연결을 설정한 후 http 요청을 시작합니다. 일반적인 http 요청 헤더에는 일반적으로 GET 또는 POST 등과 같은 요청 방법이 포함되어야 합니다. 덜 일반적으로 사용되는 방법은 PUT 및 DELETE, HEAD, OPTION 및 TRACE 방법입니다. 일반 브라우저는 GET 또는 POST 요청만 시작할 수 있습니다. 클라이언트가 서버에 http 요청을 시작하면 일부 요청 정보가 포함됩니다. | 요청 방법 URI 프로토콜/버전 | | 요청 텍스트: 다음은 전체 HTTP 요청 예입니다. (1) 요청의 첫 번째 줄은 "메소드 URL 제안/버전"입니다: GET/sample.jsp HTTP/1.1<span style="font-size: 16px;">。</span>GET/sample.jspHTTP/1.1Accept:image/gif.image/jpeg,*/*Accept-Language:zh-cn
Connection:Keep-Alive
Host:localhost
User-Agent:Mozila/4.0(compatible;MSIE5.01;Window NT5.0)
Accept-Encoding:gzip,deflate
username=jinqiao&password=1234
(2) 요청 헤더(Request Header)Accept:image/gif.image/jpeg.*/*
Accept-Language:zh-cn
Connection:Keep-Alive
Host:localhost
User-Agent:Mozila/4.0(compatible:MSIE5.01:Windows NT5.0)
Accept-Encoding:gzip,deflate.
username=jinqiao&password=1234
사용자가 보고 싶은 웹페이지 콘텐츠를 직접 보내는 대신 서버에서 리디렉션을 해야 하는 이유는 무엇인가요? 그 이유 중 하나는 검색 엔진 순위와 관련이 있습니다. 페이지에 http://www.yy.com/ 및 http://yy.com/과 같이 두 개의 주소가 있는 경우 검색 엔진은 해당 페이지를 두 개의 웹사이트로 간주하므로 각 검색 링크가 줄어들게 됩니다. 검색결과가 낮아집니다. 그리고 검색 엔진은 301 영구 리디렉션이 무엇을 의미하는지 알고 있으므로 동일한 웹 사이트 순위에서 www가 있는 주소와 없는 주소의 순위를 매깁니다. 또한, 다른 주소를 사용하면 캐시 친화성이 저하됩니다. 페이지 이름이 여러 개인 경우 캐시에 여러 번 나타날 수 있습니다.
301 및 302 상태 코드는 모두 리디렉션을 나타냅니다. 즉, 서버에서 반환된 상태 코드를 받은 후 브라우저가 자동으로 새 URL 주소로 이동합니다. 이 주소는 응답의 Location 헤더에서 얻을 수 있습니다. 사용자가 보는 효과는 그가 입력한 주소 A가 즉시 다른 주소 B로 변경된다는 것입니다. 이것이 공통점입니다.
차이점은. 301은 이전 주소 A의 리소스가 영구적으로 제거되었음을 의미합니다(이 리소스는 더 이상 액세스할 수 없음). 검색 엔진은 새 콘텐츠를 크롤링하는 동안 이전 URL을 리디렉션된 URL로 교환합니다;
302는 의미합니다. 이전 주소 A의 리소스가 여전히 존재합니다(여전히 액세스 가능). 이 리디렉션은 일시적으로 이전 주소 A에서 주소 B로 이동합니다. 검색 엔진은 새 콘텐츠를 크롤링하고 이전 URL을 저장합니다. SEO302가 301보다 낫습니다
2) 리디렉션 이유:
(1) 웹사이트 조정(예: 웹 디렉토리 구조 변경) (2) 웹페이지가 새 주소로 이동되었습니다. ; (3 ) 웹 페이지 확장자 변경(응용 프로그램이 .php를 .Html 또는 .shtml로 변경해야 하는 경우). 이 경우 리디렉션이 수행되지 않으면 사용자 즐겨찾기 또는 검색 엔진 데이터베이스의 이전 주소로 인해 방문하는 고객에게 404 페이지 오류 메시지가 표시될 뿐이며 액세스 트래픽도 손실됩니다. 일부 등록된 여러 도메인 이름 웹사이트에서는 이러한 도메인 이름을 방문하는 사용자를 자동으로 기본 사이트로 이동하도록 리디렉션해야 합니다.이제 브라우저는 "http://www.google.com/"이 액세스할 올바른 주소임을 인식하므로 또 다른 http 요청을 보냅니다. 여기서는 할 말이 없습니다
6. 서버 처리 요청이전 단계를 거쳐 마침내 HTTP 요청을 서버에 보냈습니다. 사실 이전 리디렉션은 이미 서버에 도달했습니다. 우리의 요청을 처리하는 것은 어떻습니까?
后端从在固定的端口接收到TCP报文开始,它会对TCP连接进行处理,对HTTP协议进行解析,并按照报文格式进一步封装成HTTP Request对象,供上层使用。
一些大一点的网站会将你的请求到反向代理服务器中,因为当网站访问量非常大,网站越来越慢,一台服务器已经不够用了。于是将同一个应用部署在多台服务器上,将大量用户的请求分配给多台机器处理。此时,客户端不是直接通过HTTP协议访问某网站应用服务器,而是先请求到Nginx,Nginx再请求应用服务器,然后将结果返回给客户端,这里Nginx的作用是反向代理服务器。同时也带来了一个好处,其中一台服务器万一挂了,只要还有其他服务器正常运行,就不会影响用户使用。
如图所示:
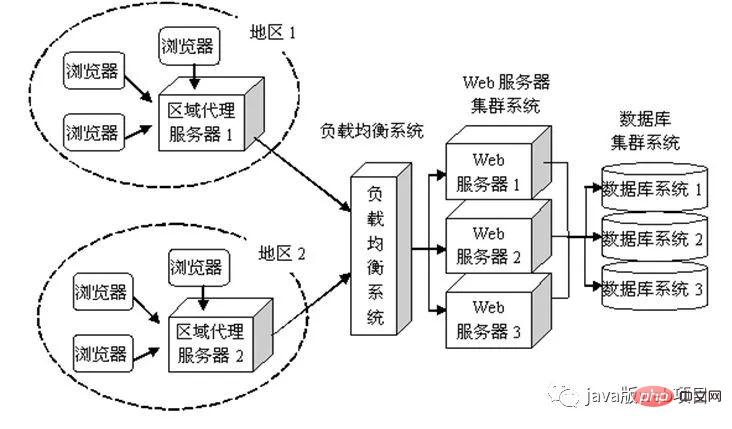
通过Nginx的反向代理,我们到达了web服务器,服务端脚本处理我们的请求,访问我们的数据库,获取需要获取的内容等等,当然,这个过程涉及很多后端脚本的复杂操作。由于对这一块不熟,所以这一块只能介绍这么多了。
经过前面的6个步骤,服务器收到了我们的请求,也处理我们的请求,到这一步,它会把它的处理结果返回,也就是返回一个HTPP响应。
HTTP响应与HTTP请求相似,HTTP响应也由3个部分构成,分别是:
l 状态行
l 响应头(Response Header)
l 响应正文
HTTP/1.1 200 OK Date: Sat, 31 Dec 2005 23:59:59 GMT Content-Type: text/html;charset=ISO-8859-1 Content-Length: 122<html> <head> <title>http</title> </head><body> <!-- body goes here --> </body> </html>
状态行:
状态行由协议版本、数字形式的状态代码、及相应的状态描述,各元素之间以空格分隔。
格式: HTTP-Version Status-Code Reason-Phrase CRLF
例如: HTTP/1.1 200 OK
--프로토콜 버전: http1.0을 사용할지 아니면 다른 버전을 사용할지
-- 상태 설명: 상태 설명은 상태 코드에 대한 간단한 텍스트 설명을 제공합니다. 예를 들어 상태 코드가 200이면 설명은 ok입니다
-- 상태 코드: 상태 코드는 세 자리 숫자로 구성되며 첫 번째 숫자는 응답 범주를 정의하며 5개의 가능한 값을 갖습니다. 다음과 같습니다
1xx: 서버가 클라이언트 요청을 수신했으며 클라이언트가 계속 요청을 보낼 수 있음을 나타내는 정보용 상태 코드입니다.
100 Continue
101 Switching Protocols
2xx: 서버가 요청을 성공적으로 수신하고 처리했음을 나타내는 성공 상태 코드입니다.
200 OK 클라이언트 요청이 성공했음을 나타냅니다.
204 콘텐츠 없음 성공했지만 엔터티의 주요 부분을 반환하지 않습니다.
206 부분 콘텐츠 범위 요청이 성공적으로 실행되었습니다.
3xx : 서버가 클라이언트의 리디렉션을 요구함을 나타내는 리디렉션 상태 코드입니다.
301 영구 이동됨 영구 리디렉션, 응답 메시지의 Location 헤더에는 리소스의 새 URL이 있어야 합니다.
302 발견 임시 리디렉션, 응답 메시지의 Location 헤더에 제공된 URL이 임시 위치에 사용됩니다. 리소스
303 기타 요청한 리소스에 다른 URI가 있습니다. 클라이언트는 요청된 리소스를 얻으려면 GET 메서드를 사용해야 합니다.
304 수정되지 않음 서버 콘텐츠가 업데이트되지 않았으며 브라우저 캐시를 직접 읽을 수 있습니다.
307 임시 리디렉션 임시 리디렉션입니다. 302 Found와 같은 의미입니다. 302는 POST를 GET으로 변환하는 것을 금지하지만 실제 사용에서는 반드시 그런 것은 아닙니다. 307 더 많은 브라우저가 이 표준을 따를 수 있지만 브라우저의 특정 구현에 따라 다릅니다
4xx: 클라이언트 오류 상태 코드, 클라이언트의 요청에 불법 콘텐츠가 포함되어 있음을 나타냅니다.
400 Bad Request는 클라이언트 요청에 구문 오류가 있어 서버가 이해할 수 없음을 나타냅니다.
401 Unauthonzed는 요청이 승인되지 않았음을 나타냅니다. 이 상태 코드는 WWW-Authenticate 헤더 필드와 함께 사용해야 합니다. 403 Forbidden은 서버가 요청을 받았지만 서비스가 거부되면 서비스를 제공하지 않는 이유가 일반적으로 응답 본문에 제공된다는 것을 나타냅니다.
404 Not Found 요청한 리소스가 존재하지 않습니다. 예를 들어 , 잘못된 URL이 입력되었습니다.
5xx
: 서버 오류 상태 코드로, 서버가 클라이언트의 요청을 정상적으로 처리하지 못해 예상치 못한 오류가 발생했음을 나타냅니다. 500 Internel Server Error는 서버에 예상치 못한 오류가 발생하여 클라이언트의 요청을 완료할 수 없음을 의미합니다.
503 Service Unavailable은 일정 기간이 지난 후 서버가 현재 클라이언트의 요청을 처리할 수 없음을 의미합니다. 시간이 지나면 서버가 정상으로 돌아올 수 있습니다
응답 헤더:
응답 헤더: 키워드/값 쌍으로 구성, 한 줄에 한 쌍, 키워드와 값은 영어 콜론 ":"으로 구분됩니다. , 일반적인 응답 헤더는 다음과 같습니다.
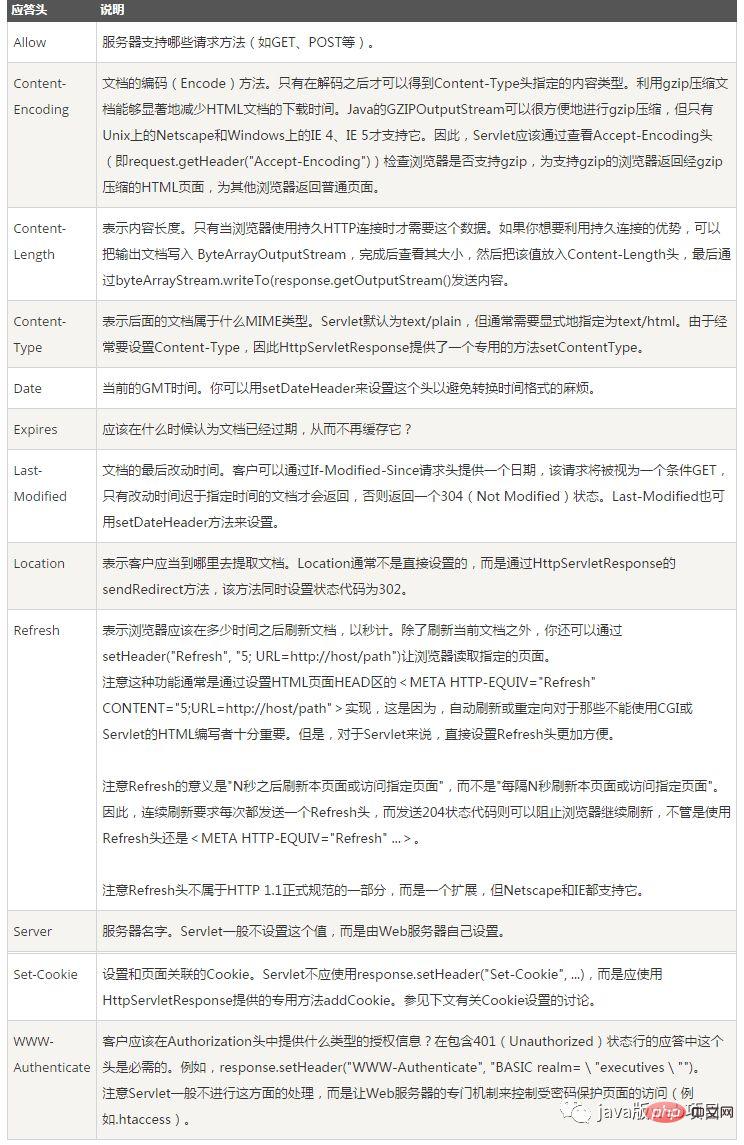
에는 쿠키, HTML, 이미지, 백엔드에서 반환된 요청 데이터 등과 같이 필요한 특정 정보가 포함되어 있습니다. 여기에서 응답 본문과 응답 헤더 사이에 공백이 있다는 점에 유의해야 합니다. 이는 응답 헤더 정보가 공백까지 있음을 나타냅니다. 아래 그림은 빨간색 상자에 피들러가 캡처한 요청 본문입니다.
응답 본문: 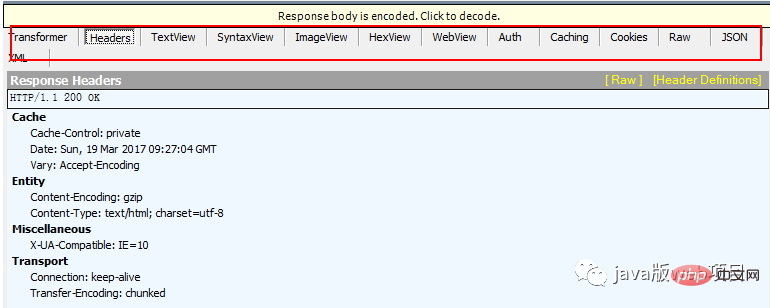 8. 브라우저가 HTML
8. 브라우저가 HTML
HTML을 구문 분석하여 DOM 트리 만들기-> 레이아웃 렌더링 트리 만들기-> 렌더 트리 그리기
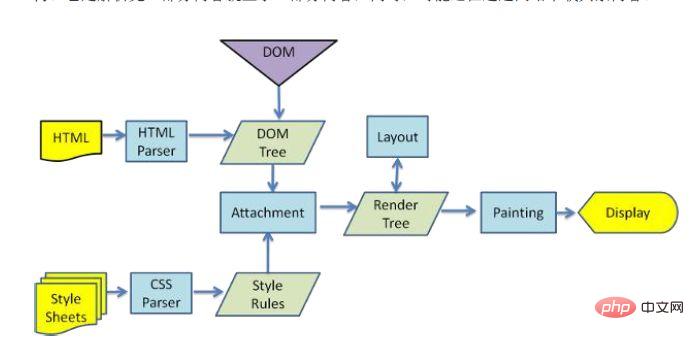
브라우저가 html 파일을 구문 분석하면 "하향식"으로 로드됩니다. . 그리고 로딩 프로세스 중에 구문 분석 및 렌더링을 수행합니다. 구문 분석 과정에서 그림, 외부 링크 CSS, 아이콘 글꼴 등과 같은 외부 리소스에 대한 요청이 있는 경우 요청 프로세스는 비동기식이며 HTML 문서 로딩에 영향을 미치지 않습니다.
구문 분석 프로세스 중에 브라우저는 먼저 HTML 파일을 구문 분석하여 DOM 트리를 구축한 다음 CSS 파일을 구문 분석하여 렌더링 트리를 구축한 후 렌더링을 레이아웃하기 시작합니다. 트리를 만들어 화면에 그립니다. 이 프로세스는 상대적으로 복잡하며 리플로우와 리페인트라는 두 가지 개념을 포함합니다.
DOM 노드의 각 요소는 상자 모델의 형태로 존재하며, 이를 위해서는 브라우저가 위치와 크기를 계산해야 합니다. 상자 모델의 위치, 크기 및 기타 속성을 relow라고 합니다. 색상, 글꼴 등이 결정된 후 브라우저는 콘텐츠를 그리기 시작합니다. 이 프로세스를 다시 그리기라고 합니다.
페이지가 처음 로드되면 필연적으로 리플로우와 리페인이 발생합니다. 리플로우 및 리페인 프로세스는 성능을 많이 소모하며, 특히 모바일 장치에서는 사용자 경험을 파괴하고 페이지가 정지되는 경우도 있습니다. 따라서 리플로우를 줄이고 리패인을 가능한 한 줄여야 합니다.
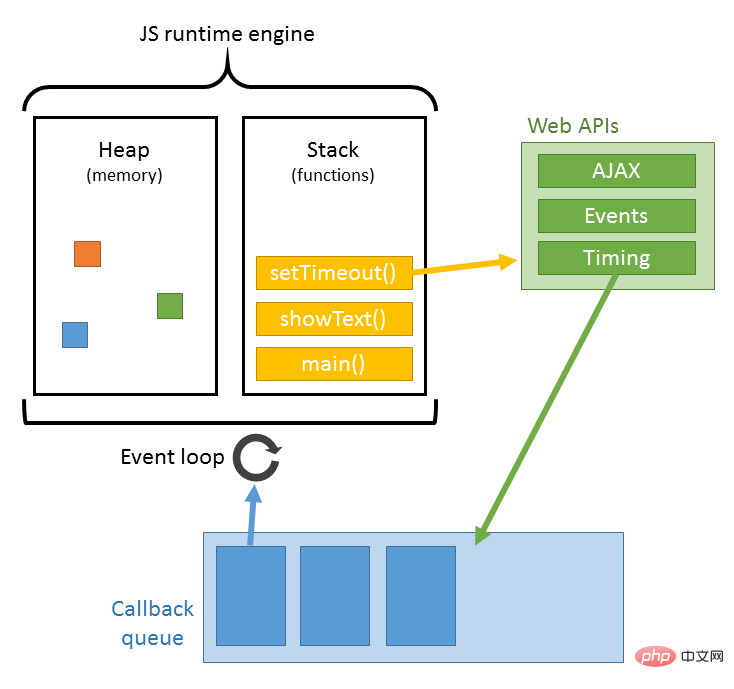
문서 로딩 중에 js 파일이 발견되면 HTML 문서는 문서의 js 파일이 로드되기를 기다리는 것이 아니라 렌더링(로딩, 구문 분석 및 렌더링 동기화) 스레드를 일시 중지합니다. , 또한 구문 분석이 실행되기를 기다리고 있습니다. 완료 후 HTML 문서의 렌더링 스레드를 재개할 수 있습니다. JS는 가장 고전적인 document.write인 DOM을 수정할 수 있기 때문에 이는 JS 실행이 완료되기 전에 모든 리소스의 후속 다운로드가 필요하지 않을 수 있음을 의미합니다. 이것이 js가 후속 리소스 다운로드를 차단하는 근본적인 이유입니다. 그래서 나는 일반적인 코드에서 js가 html 문서의 끝에 배치된다는 것을 이해합니다.
JS 파싱은 Google의 V8과 같은 브라우저의 JS 파싱 엔진에 의해 완료됩니다. JS는 단일 스레드에서 실행됩니다. 즉, 동시에 한 가지 작업만 수행할 수 있습니다. 즉, 모든 작업은 다음 작업을 시작하기 전에 대기열에 넣어야 합니다. 그러나 IO 읽기 및 쓰기 등과 같이 시간이 많이 걸리는 일부 작업이 있으므로 이후 작업, 즉 동기 작업(동기) 및 비동기 작업(비동기)을 먼저 실행하기 위한 메커니즘이 필요합니다.
JS의 실행 메커니즘은 메인 스레드와 작업 대기열로 간주할 수 있습니다. 동기 작업은 메인 스레드에서 실행되는 작업이고, 비동기 작업은 작업 큐에 배치되는 작업입니다. 모든 동기 작업은 메인 스레드에서 실행되며, 실행 스택을 형성하면 스크립트가 실행 중일 때 먼저 실행 스택이 순서대로 실행되고, 비동기 작업은 작업 대기열에 이벤트를 배치합니다. 그런 다음 작업 큐에서 이벤트를 추출하고 실행합니다. 작업 큐에 있는 작업의 경우 이 프로세스가 계속 반복되므로 이벤트 루프라고도 합니다. 구체적인 프로세스를 보려면 내 기사를 읽어보세요. 여기를 클릭하세요
실제로 이 단계는 8단계와 병행될 수 있습니다. 브라우저가 HTML을 표시할 때 , 다른 주소 콘텐츠에 대한 태그를 가져와야 함을 알 수 있습니다. 이 시점에서 브라우저는 파일을 검색하기 위해 가져오기 요청을 보냅니다. 예를 들어 다음 링크와 유사한 외부 사진, CSS, JS 파일 등을 얻고 싶습니다.
Picture: http://static.ak.fbcdn.net/rsrc.php/z12E0/hash/ 8q2anwu7.gif
CSS 스타일시트: http://static.ak.fbcdn.net/rsrc.php/z448Z/hash/2plh8s4n.css
JavaScript 파일: http://static.ak.fbcdn. net/rsrc.php/zEMOA/hash/c8yzb6ub.js
이 주소는 HTML 읽기와 유사한 과정을 거쳐야 합니다. 따라서 브라우저는 DNS에서 이러한 도메인 이름을 조회하고, 요청을 보내고, 리디렉션하는 등의 작업을 수행합니다.
동적 페이지와 달리 정적 파일을 사용하면 브라우저가 이를 캐시할 수 있습니다. 일부 파일은 서버와 통신할 필요가 없지만 캐시에서 직접 읽을 수 있거나 CDN
에 저장할 수 있습니다. 이제 URL 입력부터 페이지 표시까지의 과정이 최종적으로 완료됩니다. 물론 글의 형식이 제한되어 있고 오류가 있을 수 있습니다. 이 글은 많은 글을 참고하고 있다는 점 지적해주시면 감사하겠습니다만, 많은 글의 링크가 기억나지 않아 다음 세 가지 참고 링크만 나열합니다.
위 내용은 인터뷰에서 꼭 물어봐야 할 질문: URL을 입력하면 페이지 표시까지 정확히 어떤 일이 발생하나요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



