

Alibaba가 서비스 검색을 위해 ZooKeeper를 사용하지 않는 이유는 무엇입니까?
미래의 갈림길에 서서 잃어버린 역사의 길을 되돌아보는 일은 종종 흥미롭습니다. 왜냐하면 우리는 무심코 어떤 일이 미리 일어났더라면 어땠을지, 다른 일이 일어났더라면 어땠을까 하는 미친 생각을 하게 되기 때문입니다. 일어나지 않았나요? 오스트로-헝가리 제국의 왕위 계승자인 페르디난트 대공과 그의 아내가 열정적인 세르비아 청년 프린시프의 총에 맞아 죽지 않았다면, 그리고 치우 라오다오가 통과하지 않았다면 무슨 일이 일어났을 것처럼. 뉴자 마을?
타오바오는 2007년말 'Colorful Stone'이라는 내부 재구축 프로젝트를 시작했습니다. 이 프로젝트는 이후 타오바오의 서비스화, 유통을 위한 자체 연구로 발전해 인터넷 미들웨어에서 벗어났습니다. 시스템과 Taobao 서비스 등록 센터 ConfigServer가 같은 해에 탄생했습니다.
2008년경, 전 인터넷 거대 기업인 야후는 자사의 빅데이터 분산 조정 제품인 ZooKeeper를 점차적으로 공개하기 시작했습니다. 이 제품은 Google이 Chubby 및 Paxos에 대해 발표한 논문을 참조한 것입니다.
2010년 11월 ZooKeeper는 Apache Hadoop의 하위 프로젝트에서 Apache의 최상위 프로젝트로 개발하여 ZooKeeper가 산업 등급의 성숙하고 안정적인 제품이 되었음을 공식적으로 발표했습니다.
2011년에 Alibaba는 Dubbo를 오픈 소스로 만들기 위해 Alibaba의 내부 시스템과의 관계를 분리해야 했습니다. 나중에 중국에서는 열심히 노력하여 오픈 소스 ZooKeeper를 지원했습니다. 업계 선두주자 중 Dubbo + ZooKeeper의 대표적인 서비스 솔루션으로 인해 ZooKeeper는 등록 센터로 유명해졌습니다.
Double 11 2015년, ConfigServer 서비스가 출시된 지 거의 8년이 지났습니다. Alibaba의 내부 '서비스 규모'가 수백만을 넘어섰고, '수천 마일 떨어진' IDC 재해 복구 기술 전략 추진 등도 이루어졌습니다. , 이는 Alibaba가 내부를 공개하도록 공동으로 유도했습니다. ConfigServer 2.0에서 ConfigServer 3.0으로의 아키텍처 업그레이드 경로가 설명됩니다.
2018년을 향해 시간이 흐르고 있습니다. 10년의 교차점에 서서, 끊임없이 변화하는 새로운 기술 개념을 쫓으면서 조금이라도 속도를 늦추고 서비스 발견 분야를 자세히 살펴볼 의향이 있는 사람은 얼마나 될까요? 생각했거나 생각했나요? 질문:
서비스 발견, ZooKeeper가 정말 최선의 선택인가요?
역사를 되돌아보면 가끔 신화가 나오기도 합니다. 만약 ZooKeeper가 HSF 등록 센터 ConfigServer보다 일찍 탄생했다면 어떻게 되었을까요?
먼저 ZooKeeper를 사용한 다음 Alibaba의 서비스 지향 시나리오와 요구 사항에 맞게 ZooKeeper를 미친 듯이 변형하고 패치하여 우회할 수 있을까요?
그러나 오늘날과 전임자의 어깨 위에 서서 우리는 오늘날처럼 확고하게 깨닫지 못했습니다. 서비스 발견 분야에서 ZooKeeper는 우리 모두와 마찬가지로 단순히 최선의 선택이 아닙니다. Fellow Eureka와 이 기사 Eureka! 서비스 검색에 ZooKeeper를 사용하면 안되는 이유 서비스 검색에 ZooKeeper를 사용하면 안되는 이유를 확실하게 설명합니다!
나만의 길은 나 혼자가 아닙니다.
등록 센터 요구 사항 분석 및 주요 설계 고려 사항
다음으로 주요 시나리오에서 Alibaba의 사례와 결합된 서비스 검색에 대한 수요 분석으로 돌아가서 하나씩 분석하고 ZooKeeper가 가장 적합한 등록 센터가 아닌 이유에 대해 논의하겠습니다. 해결책.
등록 센터는 CP 시스템입니까, AP 시스템입니까?
독자들은 CAP 및 BASE 이론에 대해 잘 알고 있으며 분산 시스템 및 인터넷 애플리케이션 구축을 안내하는 핵심 원칙 중 하나가 되었다고 생각합니다. 그들의 이론에 대한 자세한 내용은 여기에서 등록 센터의 데이터 일관성 및 가용성 요구 사항 분석을 직접 입력합니다.
데이터 일관성 요구 사항 분석
등록 센터의 가장 중요한 기능은 다음과 같습니다. 쿼리 함수로 Si = F(service-name),以 service-name 为查询参数,service-name 对应的服务的可用的 endpoints (ip:port) 목록은 반환 값입니다.
참고: 다음 텍스트에서는 서비스를 svc로 축약합니다.
먼저, 불일치가 주요 데이터에 미치는 영향을 살펴보겠습니다endpoints (ip:port), 즉 CAP에서 C를 충족하지 못한 결과:
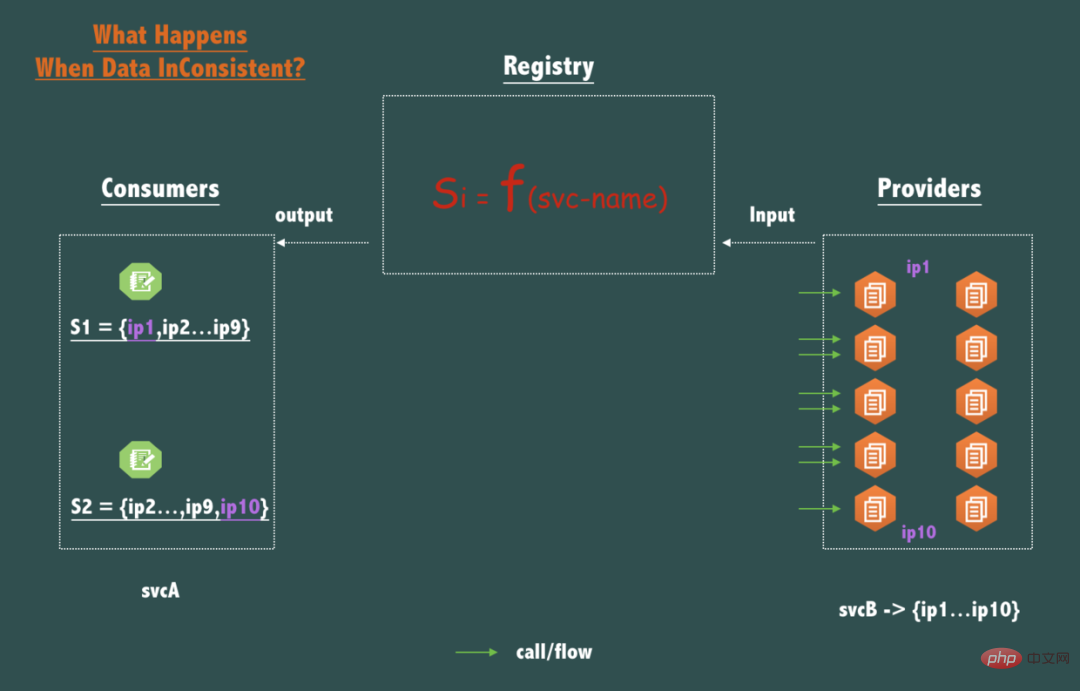
위 그림과 같이 svcB가 10개의 노드를 배포하는 경우( copy/ Replica), 동일한 서비스 이름 svcB에 대해 호출자 svcA의 두 노드에 대한 두 쿼리가 일치하지 않는 데이터를 반환하는 경우(예: S1 = { ip1,ip2,ip3...,ip9 }, S2 = { ip2) , ip3,....ip10}, 그렇다면 이러한 불일치가 미치는 영향은 무엇입니까?
SvcB의 각 노드 트래픽이 약간 불균형하다는 점을 눈치채셨을 거라 생각합니다.
다른 8개 노드 {ip2...ip9}와 비교하면 ip1 및 ip10의 요청 트래픽은 약간 작지만 분산 시스템에서는 P2P 배포 서비스의 경우에도 요청 도착 시간, 하드웨어 상태, 운영 체제 스케줄링, 가상 머신 GC 등 어떤 시점에서든 이러한 피어 배포 노드의 상태는 완전히 일관될 수 없으며, 일관되지 않은 트래픽의 경우 등록 센터가 SLA에서 약속한 시간(예: 1초 이내) 내에 데이터가 일관된 상태(즉, 최종 일관성을 충족함)로 수렴되므로 트래픽은 곧 통계적 의미에서 일관성을 유지하는 경향이 있으므로 등록 센터는 최종적으로 일관된 모델로 설계되었으며 이는 생산 실무에서 완전히 수용 가능합니다.
Partition Tolerance and Availability Requirement Analysis
다음으로 네트워크 파티션(Network Partition)의 경우, 즉 A가 인 경우에 등록 센터의 비가용성이 서비스 호출에 미치는 영향을 살펴보겠습니다. CAP가 만족되지 않습니다. 영향.
다음과 같이 일반적인 ZooKeeper 3개 컴퓨터실 재해 복구 5노드 배포 구조(예: 2-2-1 구조)를 생각해 보세요.
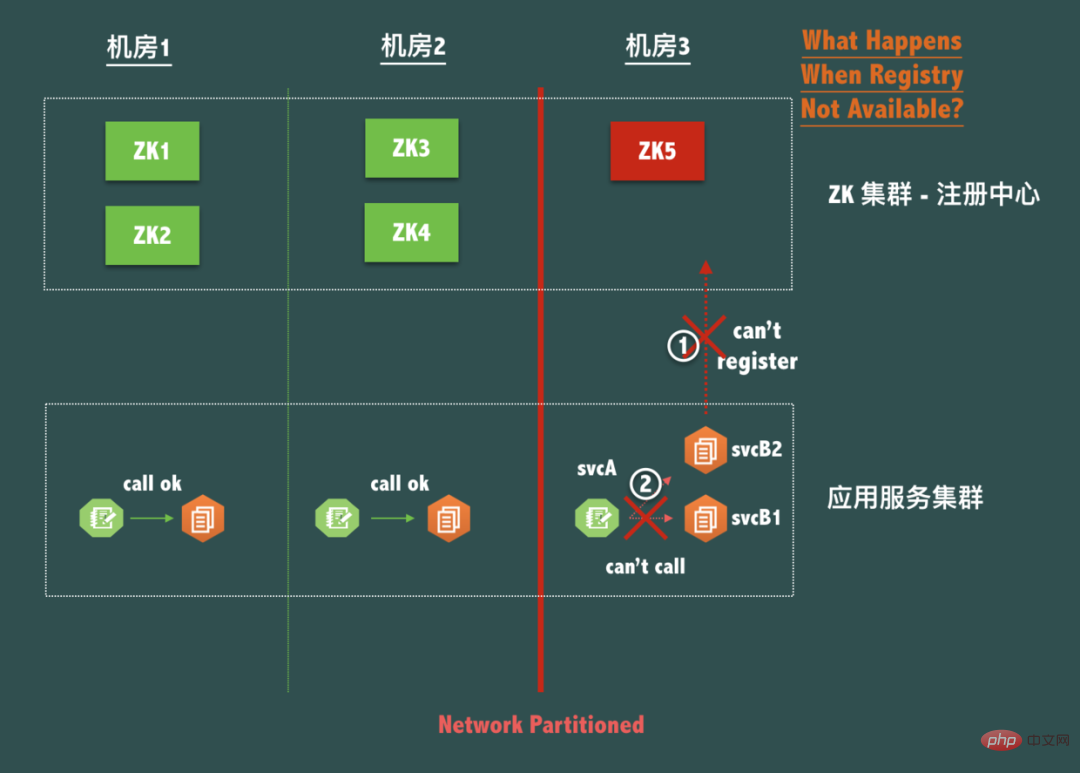
컴퓨터실 3번, 즉 컴퓨터에서 네트워크 파티션이 발생하는 경우 room 3은 네트워크가 고립된 섬이 되었다는 것을 우리는 전체적인 ZooKeeper 서비스가 가능함에도 불구하고 Leader에 접속할 수 없기 때문에 노드 ZK5에 쓸 수 없다는 것을 알고 있습니다.
즉, 이때 전산실 3의 응용 서비스 svcB는 새로 배포, 재시작, 확장 또는 축소가 불가능하지만 네트워크 및 서비스 호출 측면에서 전산실 3의 svcA는 전산실 1을 호출할 수는 없지만 그리고 컴퓨터실 2의 svcB는 문제가 없지만 컴퓨터실 3의 svcB와의 네트워크는 당연히 괜찮습니다. 이 컴퓨터실의 서비스를 호출하면 어떨까요?
이제는 분할 브레인(P) 하에서 데이터 일관성(C)을 보장하기 위해 등록 센터 자체에서 가용성을 포기했기 때문에 동일한 전산실의 서비스를 호출할 수 없습니다. 실제로 등록 센터는 어떤 이유로든 서비스 간 연결을 파괴할 수 없다고 할 수 있습니다. 이는 등록 센터 디자인이 따라야 하는 철칙입니다! 등록센터 클라이언트의 재해복구에 대해서는 추후 계속해서 논의하도록 하겠습니다.
동시에, 전산실 1, 2, 3이 모두 고립된 섬이 되면 각 전산실의 svcA가 이 전산실에 있는 svcB의 IP 목록만 가져오는 경우 데이터 불일치를 고려해 보겠습니다. 즉, 각 전산실에 있는 svcB의 IP 목록 데이터가 완전히 일치하지 않는 영향이 있습니까?
사실 큰 영향은 없지만 이 경우에는 모두 같은 전산실에서 전화가 걸려오는 경우가 있습니다. 저희가 등록 센터를 디자인할 때 때로는 등록 센터의 데이터를 적극적으로 활용하여 일관성이 떨어지기도 합니다. 애플리케이션이 동일한 전산실에서 적극적으로 호출을 수행할 수 있도록 지원하여 서비스 호출 링크 RT의 효과를 최적화합니다!
위의 설명을 통해 CAP 트레이드 오프에서 등록 센터의 가용성이 데이터의 강력한 일관성보다 더 중요하므로 전반적인 디자인은 CP 데이터보다는 AP에 더 편향되어야 함을 알 수 있습니다. 불일치는 허용 가능한 범위 내에 있는 반면, P Dropping A는 등록 센터가 어떤 이유로든 서비스 자체의 연결을 파괴할 수 없다는 원칙을 완전히 위반합니다.
서비스 규모, 용량, 서비스 연결성
귀사의 "마이크로서비스" 규모는 어느 정도입니까? 수백 개의 마이크로서비스? 수백 개의 노드를 배포했습니까? 3년 뒤에는 어떨까요? 인터넷은 기적이 일어나는 곳입니다. 귀하의 "서비스"가 하룻밤 사이에 유명해지면 트래픽이 두 배로 늘어나고 규모도 두 배로 커질 수도 있습니다.
데이터 센터 서비스 규모가 일정 수(서비스 규모 = F{서비스 퍼브 수, 서비스 서브 수})를 초과하면 등록 센터인 ZooKeeper는 곧 아래 그림의 당나귀처럼 압도당하게 됩니다

실제로 ZooKeeper를 올바른 위치, 즉 세분화된 분산 잠금 및 분산 조정 시나리오에서 사용하는 경우 ZooKeeper가 지원하는 tps 및 연결 수는 충분합니다. ZooKeeper의 확장성과 용량.
그러나 서비스 검색 및 상태 모니터링 시나리오에서는 서비스 규모가 증가함에 따라 애플리케이션이 자주 릴리스될 때 서비스 등록으로 인한 쓰기 요청인지, 밀리초 수준의 서비스 상태 상태를 브러싱하여 발생한 쓰기 요청인지, 아니면 모든 머신이 또는 전체 데이터 센터의 컨테이너가 등록 센터에 오랫동안 연결되어 있으면 ZooKeeper는 곧 이로 인해 발생하는 연결 압력에 대처할 수 없게 됩니다. 그러나 ZooKeeper는 확장성이 없으며 노드를 추가하여 수평 확장성 문제를 해결할 수 없습니다.
ZooKeeper를 기반으로 한 서비스 규모 성장의 문제를 해결하고 싶다면, 사업을 정리하고, 사업 영역을 수직적으로 나누어 여러 개의 ZooKeeper 등록 센터로 나누는 현실적인 방법을 고려할 수 있지만, 보편적으로 서비스 플랫폼 조직군이 서비스 역량이 부족하여 기술봉에 따라 사업을 나누어 관리하는 것이 과연 가능한 일인가?
그리고 이는 등록 센터 자체(용량 부족)가 서비스의 연결성을 파괴한다는 사실에 위배됩니다. 간단한 예를 들자면 검색 사업, 지도 사업, 대형 엔터테인먼트 사업, 게임 사업 사이에서 서비스를 해야 할까요? 상호 배타적인가요? 오늘은 그럴 수도 있겠지만, 내일은 어떨까요? 지금으로부터 1년 후, 10년 후에는 어떨까요? 미래에는 이상한 비즈니스 혁신을 창출하기 위해 여러 비즈니스 영역이 개방될 것이라는 것을 누가 알겠습니까? 기본 서비스로서 등록 센터는 미래를 예측할 수 없으며 미래의 고유한 연결성에 대한 비즈니스 서비스의 요구를 확실히 방해할 수 없습니다.
등록 센터에 영구 저장 및 거래 로그가 필요합니까?
필요하든 말든.
우리는 ZooKeeper의 ZAB 프로토콜이 쓰기 요청마다 각 ZooKeeper 노드에 트랜잭션 로그를 계속 기록하는 동시에 정기적으로 메모리 데이터를 디스크에 미러링(스냅샷)하여 일관성과 내구성을 보장한다는 것을 알고 있습니다. 이는 충돌 후 데이터 복구뿐만 아니라 매우 좋은 기능입니다. 그러나 서비스 검색 시나리오에서 핵심 데이터(정상 서비스의 실시간 주소 목록)에 실제로 데이터 지속성이 필요한지 질문해야 합니다. ?
이 데이터에 대한 대답은 '아니오'입니다.
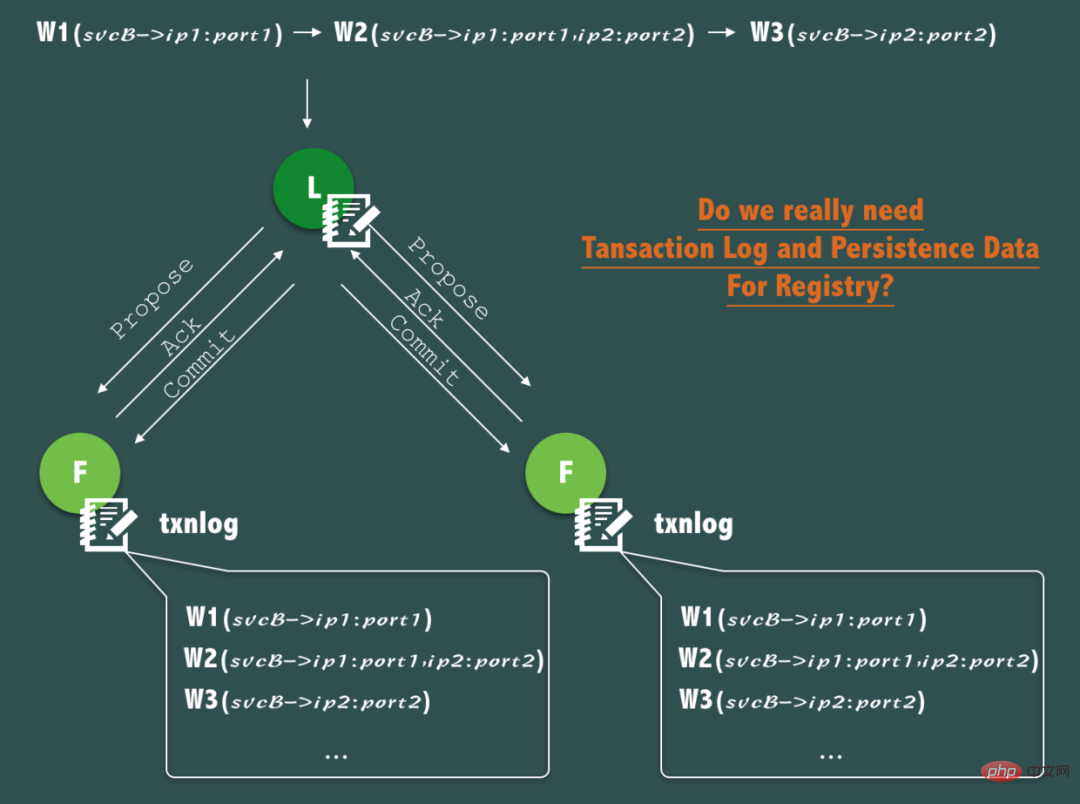
위 그림과 같이 svcB가 등록 서비스(ip1), 2개 노드로 확장(ip1, ip2), 다운타임으로 인한 축소(ip1 다운타임)를 거친다면 이 과정은 3번 발생합니다. ZooKeeper에 대한 작업입니다.
그러나 면밀히 분석해 보면 이러한 변경 과정을 트랜잭션 로그를 통해 지속적으로 기록하는 것은 실제로 별 의미가 없습니다. 서비스 검색에서는 서비스 호출 개시자가 실시간 주소 목록과 실시간 상태에 더 관심을 두기 때문입니다. 호출하려는 서비스. 호출이 시작될 때마다 호출할 서비스의 과거 서비스 주소 목록과 과거 상태에 관심이 없습니다.
그런데 왜 필요한가요? 완전한 생산 가능 등록 센터는 서비스의 실시간 주소 목록 및 실시간 상태 외에도 서비스 버전과 같은 서비스의 일부 메타데이터 정보도 저장하기 때문입니다. , 그룹화, 데이터 센터가 위치한 데이터 센터, 중량, 인증 정책 정보, 서비스 라벨 등과 같은 메타 정보. 이러한 데이터는 지속적으로 저장되어야 하며, 등록 센터에서는 이 메타 정보를 검색할 수 있는 기능을 제공해야 합니다.
Service Health Check
ZooKeeper를 서비스 등록 센터로 사용할 때 서비스 상태 감지는 ZooKeeper의 Session active Track 메커니즘과 Ephemeral ZNode와 결합된 메커니즘을 사용하는 경우가 많습니다. 간단히 말해 서비스 상태 모니터링은 ZooKeeper에 바인딩됩니다. . 세션 상태 모니터링 또는 TCP 긴 링크 활동 감지에 대한 바인딩.
이것은 또한 많은 경우에 치명적인 문제를 일으킬 수 있습니다. ZK와 서비스 제공자 시스템 간의 TCP 긴 링크 활동 감지가 정상이라면 서비스는 정상입니까? 대답은 물론 아니오입니다! 등록 센터는 보다 풍부한 상태 모니터링 솔루션을 제공해야 하며, 서비스의 정상 여부에 대한 논리는 일률적인 TCP 활동 테스트로 만드는 대신 서비스 공급자가 정의할 수 있도록 공개되어야 합니다.
건강 감지의 기본 설계 원칙 중 하나는 서비스 자체의 실제 건강 상태를 최대한 진실되게 피드백하는 것입니다. 그렇지 않으면 서비스 호출자가 믿지 않는 건강 상태 결정 결과는 건강 감지가 없는 것보다 나쁩니다.
등록 센터에 대한 재해 복구 고려 사항
앞서 언급했듯이 실제로 등록 센터는 어떤 이유로든 서비스 간의 연결을 파괴할 수 없습니다. 따라서 가용성 측면에서 필수적인 문제입니다. 등록 센터(레지스트리) 자체가 완전히 다운되었습니다. svcA가 svcB를 호출하는 링크가 영향을 받아야 합니까?
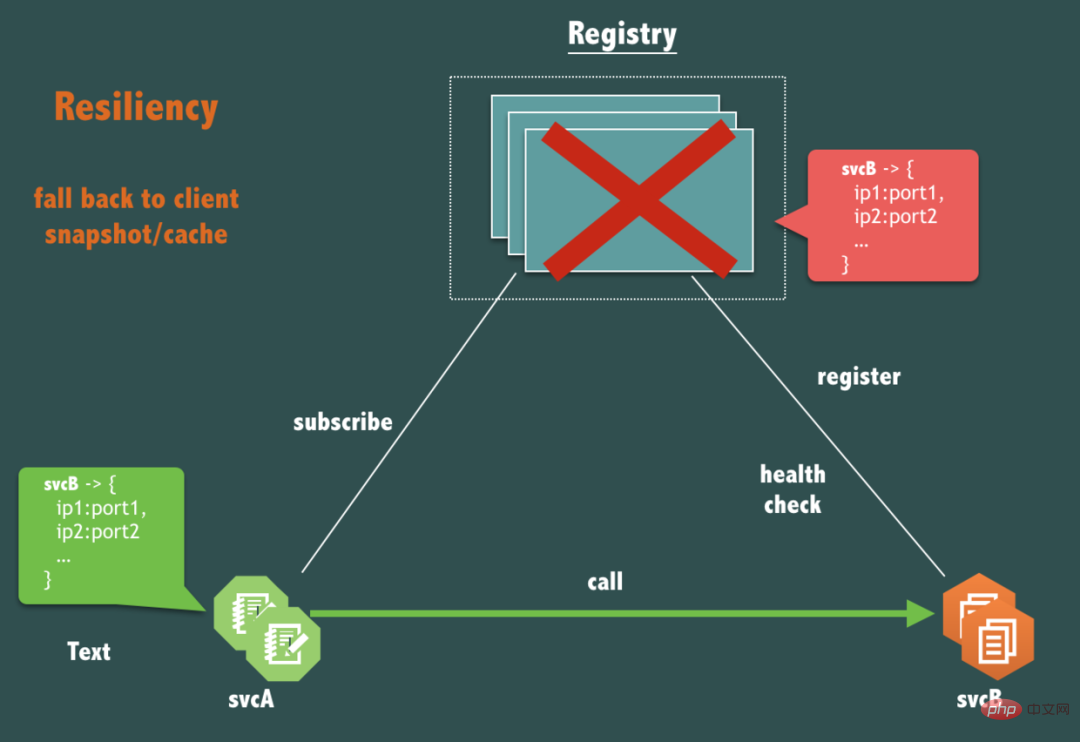
예, 영향을 받지 않아야 합니다.
서비스 호출(요청 응답 흐름) 링크는 등록 센터에 약하게 의존해야 합니다. 서비스 출시, 기계 온라인 및 오프라인, 서비스 확장 및 축소 등에 필요한 경우에만 등록 센터에 의존해야 합니다.
이를 위해서는 등록 센터가 제공하는 클라이언트를 신중하게 설계해야 합니다. 예를 들어 클라이언트 캐시 데이터 메커니즘(클라이언트 스냅샷이라고 함)을 설계하는 것은 괜찮습니다. . 효과적인 수단. 또한, 이러한 상황에서 비우는 등의 상황이 발생하지 않도록 등록센터의 상태 점검 메커니즘을 세심하게 설계해야 합니다.
ZooKeeper의 기본 클라이언트에는 이 기능이 없으므로 ZooKeeper를 사용하여 등록 센터를 구현할 때 모든 ZooKeeper 노드가 종료되면 프로덕션의 모든 서비스 호출 링크가 영향을 받지 않습니까? 그리고 이 점에 대해서는 정기적으로 실패 훈련을 실시해야 합니다.
의뢰할 수 있는 ZooKeeper 전문가가 있나요?
ZooKeeper는 아주 단순한 제품인 것 같지만, 생산에 있어서 대규모로 사용하고 잘 활용하는 것은 당연한 일이 아닙니다. ZooKeeper를 프로덕션에 도입하기로 결정했다면 언제든지 ZooKeeper 기술 전문가의 도움을 구할 준비를 하는 것이 좋습니다. 가장 일반적인 증상은 두 가지 측면입니다.
-
마스터하기 어려운 클라이언트/세션 상태 시스템.
ZooKeeper의 기본 클라이언트는 확실히 사용하기 쉽지 않습니다. 큐레이터가 더 좋을 것이지만 실제로는 ZooKeeper 클라이언트와 서버 간의 상호 작용 프로토콜을 완전히 이해하는 것이 쉽지 않습니다. ZooKeeper를 완전히 이해하고 마스터하기 쉽습니다. 클라이언트/세션 상태 머신(아래 그림)은 그렇게 간단하고 명확하지 않습니다.
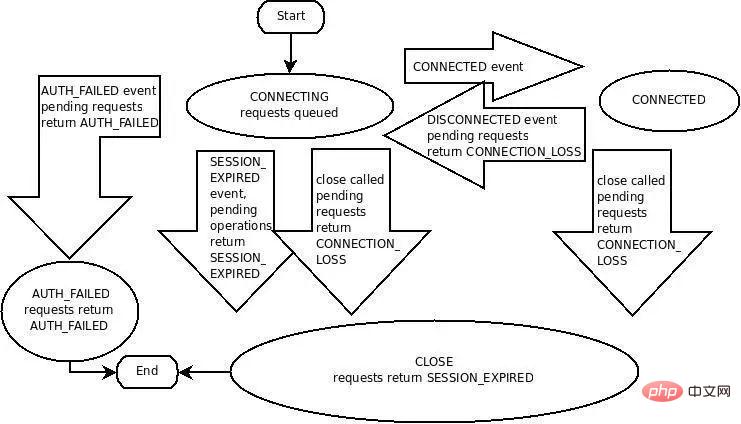
하지만 ZooKeeper를 기반으로 하는 서비스 검색 솔루션은 긴 연결/세션 관리인 Ephemeral ZNode에 의존합니다. ZooKeeper에서 제공하는 이벤트 및 알림, 핑 메커니즘 따라서 ZooKeeper를 서비스 검색에 효과적으로 활용하려면 ZooKeeper의 핵심 메커니즘과 원칙을 이해해야 합니다. 이로 인해 서비스 검색이 필요한 경우가 있습니다. 그렇게? 그리고 이 모든 것을 이해하고 어떤 함정에도 빠지지 않는다면, 축하합니다. 당신은 ZooKeeper 기술 전문가가 되셨습니다.
견딜 수 없는 예외 처리
ZooKeeper를 Alibaba의 내부 애플리케이션에 연결했을 때 "ZooKeeper 애플리케이션 통합에 대해 알아야 할 사항"이라는 WIKI가 있었는데, 여기서는 다음과 같이 예외 처리를 논의했습니다.
무엇을 선택하고 싶은지 애플리케이션 개발자는 ZooKeeper를 사용할 때 가장 명확하게 알아야 합니까? 따라서 이전 지원 경험을 바탕으로 예외 처리가 되어야 합니다.
다행히 모든 것(호스트, 디스크, 네트워크 등)이 제대로 작동하면 애플리케이션과 ZooKeeper도 잘 실행될 수 있지만 안타깝게도 하루 종일 다양한 놀라움에 직면하게 될 것입니다. 그리고 이는 머피의 법칙에 따라 항상 예상치 못한 나쁜 일이 발생합니다 당신이 그들에 대해 가장 걱정할 때 일어납니다.
따라서 일부 시나리오에서 ZooKeeper에서 발생할 수 있는 예외 및 오류를 주의 깊게 이해하고, 이러한 예외 및 오류를 올바르게 이해하고, 애플리케이션이 이러한 상황을 올바르게 처리하는 방법을 알아야 합니다.
ConnectionLossException 및 Disconnected 이벤트
간단히 말하면 동일한 ZooKeeper Session(복구 가능)에서 복구할 수 있는 예외이지만, 애플리케이션 개발자는 애플리케이션을 올바른 상태로 복원할 책임이 있습니다.
이 예외에는 응용 프로그램 시스템과 ZooKeeper 노드 간의 네트워크 중단, ZooKeeper 노드 가동 중지 시간, 서버 측 Full GC 시간이 너무 길거나 응용 프로그램 프로세스가 중단되고 응용 프로그램 프로세스 전체 GC 시간 등 여러 가지 이유가 있습니다. 너무 깁니다. 나중에 복구가 가능합니다.
이 예외를 이해하려면 아래와 같이 분산 애플리케이션의 일반적인 문제를 이해해야 합니다. 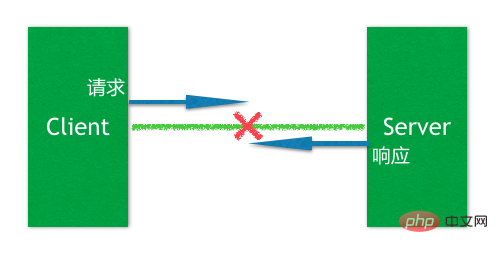
일반적인 클라이언트 요청과 서버 응답에서 둘 사이의 긴 연결이 중단되면 클라이언트가 이 플래시 이벤트를 감지할 때 , 당황스러운 상황에 처하게 됩니다. 즉, 이벤트가 발생했을 때 근처 요청의 상태를 확인할 수 없습니다. 서버가 이 요청을 받았습니까? 처리됐나요? 이를 판단할 수 없기 때문에 클라이언트가 서버에 재접속할 때 요청을 재시도(Retry)해야 하는지에 대한 물음표가 표시됩니다.
따라서 연결 끊김 이벤트를 처리할 때 애플리케이션 개발자는 중단에 가까운 요청이 무엇인지(종종 판단하기 어렵습니다), 요청이 멱등적인지 여부, 서버 측 서비스 처리의 비즈니스 요청에 대해 알아야 합니다. "한 번만 처리", "최대 한 번 처리" 및 "최소 한 번 처리"는 선택적이고 예상되어야 합니다.
예를 들어 애플리케이션이 ConnectionLossException을 수신하고 이전 요청이 Create 작업인 경우 애플리케이션이 이 예외를 포착하면 애플리케이션에 가능한 복구 논리는 이전 요청에 의해 생성된 노드가 이미 존재하는지 여부를 확인하는 것입니다. 존재하는 경우 생성하지 말고, 존재하지 않는 경우 생성하십시오.
또 다른 예로, 애플리케이션이 존재하지 않는 노드의 생성 이벤트를 모니터링하기 위해 존재하는 경우 ConnectionLossException 중에 이 중단 기간 동안 다른 클라이언트 프로세스가 생성되었을 수 있는 상황이 발생할 수 있습니다. 노드가 삭제되어 현재 애플리케이션의 경우 해당 노드의 생성 이벤트가 누락되면 애플리케이션에 어떤 영향을 미치나요? 용납할 수 있는 일인가, 아니면 받아들일 수 없는 일인가? 애플리케이션 개발자는 비즈니스 의미에 따라 이를 평가하고 처리해야 합니다.
SessionExpiredException 및 SessionExpired 이벤트
세션 시간 초과는 복구할 수 없는 예외입니다. 즉, 애플리케이션이 이 예외를 포착하면 애플리케이션이 동일한 세션에서 애플리케이션 상태를 복원할 수 없으며 새 세션을 다시 설정해야 합니다. 이전 세션과 연결된 임시 노드도 만료되었을 수 있으며 해당 노드가 소유한 잠금도 만료되었을 수 있습니다. ...
ZooKeeper를 자체적으로 서비스 검색에 사용하려고 시도하는 과정에서 Alibaba의 친구들은 인트라넷 기술 포럼

에서 경험 공유를 요약한 적이 있습니다. 기사에서 적절하게 언급한 내용은 다음과 같습니다.
... 코딩 과정에서 가능한 많은 함정이 발견되었습니다. 대략적으로 zk를 사용하여 클러스터 관리를 처음 구현하는 사람들 중 80% 이상이 함정에 빠지게 되며, 일부 함정은 상대적으로 숨겨져 있습니다. 네트워크 문제나 비정상적인 장면이 있을 때만 나타나며 노출되기까지 시간이 오래 걸릴 수 있습니다...
왼쪽으로 오른쪽으로
ZooKeeper를 사용하면 완전 무료인가요? 설마.
Alibaba의 기술 시스템에 익숙한 사람이라면 Alibaba가 실제로 중국에서 가장 큰 ZooKeeper 클러스터를 유지하고 있으며 전체 규모가 약 1,000개에 달하는 ZooKeeper 서비스 노드라는 것을 알고 있습니다.
동시에 Alibaba 미들웨어는 ZooKeeper의 코드 브랜치인 TaoKeeper도 유지 관리하고 있습니다. TaoKeeper는 대규모 생산을 지향하고 가용성이 높으며 다양한 비즈니스에서 ZooKeeper를 사용하는 관행을 바탕으로 모니터링 및 운영이 더 쉽습니다. 지난 10년간의 라인과 생산, ZooKeeper를 평가한다면 ZooKeeper는 "빅 데이터 조정의 제왕"이어야 한다고 생각합니다!
높은 TPS 지원이 필요하지 않은 성긴 분산 잠금, 분산 마스터 선택, 활성-대기 고가용성 전환 등의 시나리오에서 대체할 수 없는 역할을 하며 이러한 요구는 빅데이터에 집중되는 경우가 많습니다. , 오프라인 작업 등 비즈니스 분야에서는 빅데이터 분야이기 때문에 데이터 세트를 분할하는 것이 중요하며, 대부분의 경우 이러한 데이터 세트를 작업으로 나누어 여러 프로세스/스레드에 의해 병렬로 처리됩니다. , 이러한 작업과 프로세스를 통합하고 조정해야 하는 지점이 항상 있습니다. 이때 ZooKeeper는 큰 역할을 수행합니다.
그러나 거래 시나리오의 거래 링크에는 주요 비즈니스 데이터 액세스, 대규모 서비스 검색, 대규모 상태 모니터링 등에 자연스러운 단점이 있습니다. 이러한 시나리오에서는 ZooKeeper를 도입하지 않도록 최선을 다해야 합니다. Alibaba의 프로덕션에서 실제로 애플리케이션은 ZooKeeper 사용을 신청할 때 시나리오, 용량 및 SLA 요구 사항을 엄격하게 평가해야 합니다.
그래서 ZooKeeper를 사용할 수 있지만 왼쪽은 빅데이터, 오른쪽은 거래, 왼쪽은 분산 조정, 오른쪽은 서비스 검색입니다.
결론
여기까지 읽어주셔서 감사합니다. 현 시점에서는 ZooKeeper를 완전히 부정하기 위해 이 글을 쓰는 것이 아니라 과거 Alibaba의 대규모 서비스화를 기반으로 작성했다는 점을 이해해 주셨으리라 믿습니다. 실제로 10년 동안 서비스 검색 및 등록 센터의 설계 및 사용에 대한 경험과 교훈을 요약할 것입니다. ZooKeeper를 더 잘 사용하는 방법과 자체 서비스 등록 센터를 더 잘 설계하는 방법에 대해 업계에 영감을 주고 도움을 주기를 바랍니다. 드디어 모든 길은 로마로 통하고, 여러분의 등록센터가 로마에서 직접 탄생하길 진심으로 바랍니다.
위 내용은 Alibaba가 서비스 검색을 위해 ZooKeeper를 사용하지 않는 이유는 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7555
7555
 15
1382
52
83
11
59
19
28
96
15
1382
52
83
11
59
19
28
96

 Java API 개발에서 분산 잠금 처리를 위해 ZooKeeper 사용
Jun 17, 2023 pm 10:36 PM
Java API 개발에서 분산 잠금 처리를 위해 ZooKeeper 사용
Jun 17, 2023 pm 10:36 PM
최신 애플리케이션이 계속 발전하고 고가용성 및 동시성에 대한 요구가 증가함에 따라 분산 시스템 아키텍처가 점점 일반화되고 있습니다. 분산 시스템에서는 여러 프로세스 또는 노드가 동시에 실행되고 함께 작업을 완료하며 프로세스 간의 동기화가 특히 중요합니다. 분산 환경에서는 다수의 노드가 공유 자원에 동시에 접근할 수 있기 때문에 동시성 및 동기화 문제를 어떻게 처리하는가는 분산 시스템에서 중요한 작업이 되었습니다. 이런 점에서 ZooKeeper는 매우 인기 있는 솔루션이 되었습니다. 주키
 Beego의 분산 조정 및 관리를 위해 ZooKeeper 및 Curator 사용
Jun 22, 2023 pm 09:27 PM
Beego의 분산 조정 및 관리를 위해 ZooKeeper 및 Curator 사용
Jun 22, 2023 pm 09:27 PM
인터넷의 급속한 발전으로 인해 분산 시스템은 많은 기업과 조직의 인프라 중 하나가 되었습니다. 분산 시스템이 제대로 작동하려면 조정 및 관리가 필요합니다. 이와 관련하여 ZooKeeper와 Curator는 사용할 가치가 있는 두 가지 도구입니다. ZooKeeper는 클러스터의 노드 간 상태와 데이터를 조정하는 데 도움이 되는 매우 인기 있는 분산 조정 서비스입니다. 큐레이터는 ZooKeeper를 캡슐화한 것입니다.
 분산 잠금에 Redis나 Zookeeper를 사용해야 합니까?
Aug 22, 2023 pm 03:48 PM
분산 잠금에 Redis나 Zookeeper를 사용해야 합니까?
Aug 22, 2023 pm 03:48 PM
분산 잠금의 구현 방법에는 일반적으로 데이터베이스, 캐시(예: Redis), Zookeeper 등이 포함됩니다. 실제 개발에서는 Redis와 Zookeeper가 가장 일반적으로 사용되므로 이 기사에서는 이 두 가지에 대해서만 설명합니다.
 PHP의 Zookeeper 확장을 사용하는 방법은 무엇입니까?
Jun 02, 2023 pm 09:01 PM
PHP의 Zookeeper 확장을 사용하는 방법은 무엇입니까?
Jun 02, 2023 pm 09:01 PM
PHP는 웹 애플리케이션 및 서버 측 개발에 널리 사용되는 매우 인기 있는 프로그래밍 언어입니다. Zookeeper는 분산 애플리케이션 및 서비스를 관리, 조정 및 모니터링하는 데 사용되는 분산 조정 서비스입니다. PHP 애플리케이션에서 Zookeeper를 사용하면 애플리케이션의 성능과 안정성을 향상시킬 수 있습니다. 이 기사에서는 PHP용 Zookeeper 확장 기능을 사용하는 방법을 소개합니다. 1. Zookeeper 확장을 설치합니다. Zookeeper 확장을 사용하려면 Zookeeper를 설치해야 합니다.
 ZooKeeper를 사용하여 Beego에서 서비스 등록 및 검색 구현
Jun 22, 2023 am 08:21 AM
ZooKeeper를 사용하여 Beego에서 서비스 등록 및 검색 구현
Jun 22, 2023 am 08:21 AM
마이크로서비스 아키텍처에서 서비스 등록 및 검색은 매우 중요한 문제입니다. 이 문제를 해결하기 위해 ZooKeeper를 서비스 등록 센터로 사용할 수 있습니다. 이 기사에서는 Beego 프레임워크에서 ZooKeeper를 사용하여 서비스 등록 및 검색을 구현하는 방법을 소개합니다. 1. ZooKeeper 소개 ZooKeeper는 분산형 오픈소스 분산 조정 서비스로 Apache Hadoop의 하위 프로젝트 중 하나입니다. ZooKeeper의 주요 역할
![[추천컬렉션] 영혼의 고문! 사육사의 31발 대포](https://img.php.cn/upload/article/202308/28/2023082816453271532.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) [추천컬렉션] 영혼의 고문! 사육사의 31발 대포
Aug 28, 2023 pm 04:45 PM
[추천컬렉션] 영혼의 고문! 사육사의 31발 대포
Aug 28, 2023 pm 04:45 PM
ZooKeeper는 오픈 소스 분산 조정 서비스입니다. 분산 애플리케이션에 일관성 서비스를 제공하는 소프트웨어입니다. 분산 애플리케이션은 데이터 게시/구독, 로드 밸런싱, 이름 지정 서비스, 분산 조정/알림, 클러스터 관리, 마스터 선택, 분산 잠금 및 분산 대기열 및 기타 기능을 구현할 수 있습니다.
 분산 잠금의 Redis 구현에 대한 ZooKeeper 비교
Jun 20, 2023 pm 03:19 PM
분산 잠금의 Redis 구현에 대한 ZooKeeper 비교
Jun 20, 2023 pm 03:19 PM
인터넷 기술의 급속한 발전으로 인해 분산 시스템은 현대 응용 프로그램, 특히 대규모 인터넷 회사에서 널리 사용되었습니다. 그러나 분산 시스템에서는 노드 간 일관성을 유지하는 것이 매우 어렵기 때문에 분산 잠금 메커니즘이 이 문제를 해결하기 위한 기반 중 하나가 되었습니다. 분산 잠금 구현에서 Redis와 ZooKeeper는 모두 널리 사용되는 도구입니다. 이 기사에서는 이를 비교하고 분석합니다. Redis는 분산 잠금을 구현합니다. Redis는 오픈 소스 메모리 데이터 저장소입니다.
 SpringBoot에 Dubbo 사육사를 통합하는 방법
May 17, 2023 pm 02:16 PM
SpringBoot에 Dubbo 사육사를 통합하는 방법
May 17, 2023 pm 02:16 PM
dockerpullzookeeperdockerrun --namezk01-p2181:2181--restartalways-d2e30cac00aca는 Zookeeper가 Zookeeper 및 Dubbo를 성공적으로 시작했음을 나타냅니다. • ZooKeeperZooKeeper는 분산형 오픈 소스 분산 애플리케이션 조정 서비스입니다. 분산 애플리케이션에 일관된 서비스를 제공하는 소프트웨어입니다. 제공되는 기능에는 구성 유지 관리, 도메인 이름 서비스, 분산 동기화, 그룹 서비스 등이 있습니다. DubboDubbo는 Alibaba의 오픈소스 분산 서비스 프레임워크로, 계층적으로 구성되어 있다는 점이 가장 큰 특징입니다.
