

효율적인 로그 분석을 위해 Linux 명령 사용

使用Linux命令实现高效的日志分析
概述:
日志分析是我们在处理系统运行时产生的大量数据时常常遇到的问题。在Linux系统中,我们可以利用一些强大的命令和工具来分析和处理日志数据。本文将介绍一些常用的Linux命令,以及如何使用这些命令来实现高效的日志分析。
- grep命令
grep命令是Linux系统常用的文本搜索工具,可以根据正则表达式搜索文件中的内容。我们可以利用grep命令来过滤出我们感兴趣的日志信息。例如,我们可以使用以下命令来查找包含特定关键字的日志行:
grep "error" logfile
这个命令将从logfile文件中过滤出包含"error"关键字的日志行。我们也可以使用正则表达式来进行更加复杂的匹配。
- awk命令
awk命令是一个强大的文本处理工具,其可以根据自定义的规则对文本进行处理和分析。我们可以使用awk命令来提取日志中的特定字段,并进行计算。以下是一个示例:
awk '{print $4}' logfile | sort | uniq -c这个命令将从logfile文件中提取第4个字段,并使用sort命令对其进行排序,然后使用uniq命令统计每个唯一值的数量。这样我们就可以获得日志中出现频率最高的字段值。
- sed命令
sed命令是一个流编辑器,其可以用来将文本按照规则进行替换或者删除。我们可以使用sed命令来对日志进行清洗和修复。以下是一个示例:
sed -i 's/error/ERROR/g' logfile
这个命令将把logfile文件中的所有"error"替换为"ERROR"。我们也可以使用正则表达式来进行更加复杂的替换。
- sort命令
sort命令可以对文本进行排序。我们可以利用sort命令对日志进行排序来获取相关信息。例如,我们可以使用以下命令将日志按照时间顺序排序:
sort -k 4 logfile
这个命令将按照第4个字段(假设是时间戳)进行排序。我们也可以使用更多的选项来定义排序规则。
- wc命令
wc命令可以统计文件中的字数、行数和字符数。我们可以使用wc命令来统计日志的数量和大小。以下是一个示例:
wc -l logfile
这个命令将统计logfile文件中的行数,也就是日志的数量。
- find命令
find命令可以用来查找符合特定条件的文件。我们可以使用find命令来查找特定日期范围内的日志文件。以下是一个示例:
find /logdir -name "logfile*" -mtime -7
这个命令将在/logdir目录中查找以"logfile"开头且最近7天更新过的文件。
结论:
利用以上这些Linux命令,我们可以高效地对日志数据进行分析和处理。这些命令非常强大且灵活,可以通过结合使用来满足各种不同的需求。在实际使用中,我们可以根据具体的使用场景和需求,结合这些命令的不同选项和参数,来实现更加复杂和精确的日志分析。同时,也可以将这些命令结合到脚本中,实现自动化的日志处理和分析,进一步提高工作效率。希望本文对大家在日志分析方面有所帮助。
注: 以上命令的示例仅供参考,实际使用时需要根据具体情况进行调整。
위 내용은 효율적인 로그 분석을 위해 Linux 명령 사용의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 Linux에서 작업 관리자 사용
Aug 15, 2024 am 07:30 AM
Linux에서 작업 관리자 사용
Aug 15, 2024 am 07:30 AM
Linux 초보자들이 자주 묻는 질문이 있습니다. "Linux에 작업 관리자가 있나요?", "Linux에서 작업 관리자를 여는 방법은 무엇입니까?" Windows 사용자는 작업 관리자가 매우 유용하다는 것을 알고 있습니다. Windows에서는 Ctrl+Alt+Del을 눌러 작업 관리자를 열 수 있습니다. 이 작업 관리자는 실행 중인 모든 프로세스와 이들이 소비하는 메모리를 표시하며, 작업 관리자 프로그램에서 프로세스를 선택하고 종료할 수 있습니다. Linux를 처음 사용하면 Linux의 작업 관리자와 동일한 기능도 찾을 수 있습니다. Linux 전문가는 명령줄을 사용하여 프로세스, 메모리 소비 등을 찾는 것을 선호하지만 반드시 그럴 필요는 없습니다.
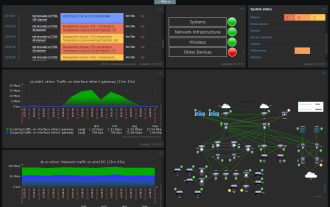 Zabbix 중국 모니터링 서버에서 그래프와 차트가 왜곡되어 표시되는 문제를 해결합니다.
Jul 31, 2024 pm 02:10 PM
Zabbix 중국 모니터링 서버에서 그래프와 차트가 왜곡되어 표시되는 문제를 해결합니다.
Jul 31, 2024 pm 02:10 PM
Zabbix의 중국어 지원은 그다지 좋지 않지만 때로는 관리 목적으로 중국어를 선택하는 경우가 있습니다. Zabbix가 모니터링하는 웹 인터페이스에서 그래픽 아이콘 아래의 중국어는 잘못된 것이며 글꼴을 다운로드해야 합니다. 예를 들어 "Microsoft Yahei", "Microsoft Yahei.ttf"의 이름은 "msyh.ttf"이고, 다운로드한 글꼴을 /zabbix/fonts/fonts에 업로드하고 /zabbix/include/defines.inc.php에서 두 문자를 수정합니다. 파일 정의('ZBX_GRAPH_FONT_NAME','DejaVuSans');define('ZBX_FONT_NAME'
 Linux 사용자의 등록 날짜를 확인하는 데 도움이 되는 7가지 방법
Aug 24, 2024 am 07:31 AM
Linux 사용자의 등록 날짜를 확인하는 데 도움이 되는 7가지 방법
Aug 24, 2024 am 07:31 AM
Linux 시스템에서 계정 생성 날짜를 확인하는 방법을 알고 계셨습니까? 알고 있다면 무엇을 할 수 있습니까? 성공하셨나요? 그렇다면 어떻게 해야 합니까? 기본적으로 Linux 시스템은 이 정보를 추적하지 않습니다. 그렇다면 이 정보를 얻을 수 있는 다른 방법은 무엇입니까? 내가 왜 이것을 확인하고 있는지 물어볼 수 있습니다. 예, 귀하가 이 정보를 검토해야 할 상황이 있을 수 있으며, 그 때 귀하에게 도움이 될 것입니다. 다음 7가지 방법으로 확인할 수 있습니다. /var/log/secure 사용 aureport 도구 사용 .bash_logout 사용 chage 명령 사용 useradd 명령 사용 passwd 명령 사용 마지막 명령 사용 방법 1: /var/l 사용
 Linux 시스템에서 WPS 누락 글꼴로 인해 파일이 깨졌을 경우 어떻게 해야 합니까?
Jul 31, 2024 am 12:41 AM
Linux 시스템에서 WPS 누락 글꼴로 인해 파일이 깨졌을 경우 어떻게 해야 합니까?
Jul 31, 2024 am 12:41 AM
1. 인터넷에서 Wingdings,wingdings2,wingdings3,Webdings,MTExtra 글꼴을 찾습니다. 2. 기본 폴더에 들어가서 Ctrl+h(숨겨진 파일 표시)를 누르고 .fonts 폴더가 있는지 확인합니다. 3. 다운로드한wingdings,wingdings2,wingdings3, Webdings, MTExtra를 기본 폴더의 .fonts 폴더에 복사한 다음 wps를 시작하여 "시스템 누락 글꼴..." 알림 대화 상자가 있는지 확인하세요. 상자가 아닌 경우 성공합니다. 참고:wingdings,wingdin
 5분 안에 Fedora에 글꼴을 추가하는 방법을 가르쳐주세요.
Jul 23, 2024 am 09:45 AM
5분 안에 Fedora에 글꼴을 추가하는 방법을 가르쳐주세요.
Jul 23, 2024 am 09:45 AM
시스템 전체 설치 시스템 전체에 글꼴을 설치하면 모든 사용자가 사용할 수 있습니다. 이를 수행하는 가장 좋은 방법은 공식 소프트웨어 저장소의 RPM 패키지를 사용하는 것입니다. 시작하기 전에 Fedora Workstation에서 "소프트웨어" 도구를 열거나 공식 저장소를 사용하는 다른 도구를 엽니다. 선택 표시줄에서 "추가 기능" 카테고리를 선택하세요. 그런 다음 카테고리 내에서 "글꼴"을 선택하십시오. 아래 스크린샷과 유사한 사용 가능한 글꼴이 표시됩니다. 글꼴을 선택하면 일부 세부정보가 표시됩니다. 여러 시나리오에 따라 글꼴의 일부 샘플 텍스트를 미리 볼 수 있습니다. 시스템에 추가하려면 "설치" 버튼을 클릭하세요. 시스템 속도 및 네트워크 대역폭에 따라 이 프로세스를 완료하는 데 다소 시간이 걸릴 수 있습니다.
 Centos 7 설치 및 구성 NTP 네트워크 시간 동기화 서버
Aug 05, 2024 pm 10:35 PM
Centos 7 설치 및 구성 NTP 네트워크 시간 동기화 서버
Aug 05, 2024 pm 10:35 PM
실험 환경: OS: LinuxCentos7.4x86_641 현재 서버 시간대 보기 & 시간대 나열 및 시간대 설정(이미 올바른 시간대인 경우 건너뛰기): #timedatectl#timedatectllist-timezones#timedatectlset-timezoneAsia /상하이2. 시간대 개념의 이해: GMT, UTC, CST, DSTUTC: 지구 전체는 24개의 시간대로 나누어져 있습니다. 국제 무선 통신 상황에서는 통일을 위해 각각의 시간대가 있습니다. UTC(Universal Coordinated Time)라는 통합 시간이 사용됩니다.
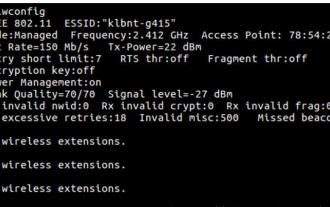 하나의 네트워크 케이블을 사용하여 두 개의 Ubuntu 호스트를 인터넷에 연결하는 방법
Aug 07, 2024 pm 01:39 PM
하나의 네트워크 케이블을 사용하여 두 개의 Ubuntu 호스트를 인터넷에 연결하는 방법
Aug 07, 2024 pm 01:39 PM
하나의 네트워크 케이블을 사용하여 두 개의 우분투 호스트를 인터넷에 연결하는 방법 1. 호스트 A: ubuntu16.04 및 호스트 B: ubuntu16.042를 준비합니다. 호스트 A에는 두 개의 네트워크 카드가 있는데, 하나는 외부 네트워크에 연결되고 다른 하나는 연결됩니다. B를 호스트하기 위해 호스트의 모든 네트워크 카드를 보려면 iwconfig 명령을 사용하십시오. 위 그림과 같이 작성자의 A 호스트(노트북)에 있는 네트워크 카드는 다음과 같습니다. wlp2s0: 무선 네트워크 카드입니다. enp1s0: 유선 네트워크 카드, 호스트 B에 연결된 네트워크 카드. 나머지는 우리와 관련이 없으며 신경 쓸 필요도 없습니다. 3. A의 고정 IP를 구성합니다. #vim/etc/network/interfaces 파일을 편집하여 아래와 같이 인터페이스 enp1s0에 대한 고정 IP 주소를 구성합니다(여기서 #==========
 던져 올림! 라즈베리 파이에서 DOS 실행
Jul 19, 2024 pm 05:23 PM
던져 올림! 라즈베리 파이에서 DOS 실행
Jul 19, 2024 pm 05:23 PM
CPU 아키텍처가 다르다는 것은 라즈베리 파이에서 DOS를 실행하는 것이 쉽지는 않지만 그다지 문제가 되지 않는다는 것을 의미합니다. FreeDOS는 누구에게나 친숙할 수 있습니다. 이는 DOS용 완벽하고 무료이며 잘 호환되는 운영 체제로 일부 오래된 DOS 게임이나 상용 소프트웨어를 실행할 수 있으며 임베디드 응용 프로그램도 개발할 수 있습니다. 프로그램이 MS-DOS에서 실행될 수 있는 한 FreeDOS에서도 실행될 수 있습니다. FreeDOS의 창시자이자 프로젝트 코디네이터로서 많은 사용자가 내부자로서 나에게 질문을 할 것입니다. 제가 가장 자주 받는 질문은 "FreeDOS가 Raspberry Pi에서 실행될 수 있습니까?"입니다. 이 질문은 놀라운 일이 아닙니다. 결국 Linux는 Raspberry Pi에서 매우 잘 실행됩니다.
