

리눅스 명령 목록

참고: 코드 읽기를 용이하게 하기 위해 관리자 모드를 나타내는 #이 기사 코드 블록에서 제거되었습니다. 이는 오류가 아닙니다. 실수 하지마! !
1. 기본 조작 명령어
우선 단축키가 몇개 있으니 꼭 기억해두세요
Tab 키 - 명령어 완성 기능
Ctrl+c 키 - 실행 중인 프로그램 중지
Ctrl+d 키 - 종료와 동일, 종료
Ctrl+l 키 - 화면 지우기
1.1 종료 및 다시 시작
1. 종료 명령: shutdown
은 Linux 분야의 서버에서 주로 사용되며 종료 작업은 거의 발생하지 않습니다. 결국 서버에서 서비스를 실행하는 것은 끝이 없습니다. 특별한 경우가 아니면 최후의 수단으로 서비스를 종료하게 됩니다.
올바른 종료 프로세스는 다음과 같습니다. sync > shutdown >
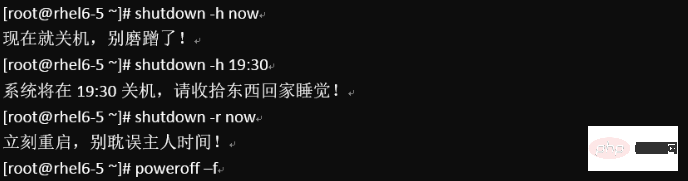
最后总结一下,不管是重启系统还是关闭系统,首先要运行 sync 命令,把内存中的数据写到磁盘中。
关机的命令有 shutdown –h now halt poweroff 和 init 0 , 重启系统的命令有 shutdown –r now reboot init 6。
2.重启命令:reboot

1.2 帮助命令
–-help命令
shutdown --help:ifconfig --help:查看网卡信息
man命令(命令说明书)
man shutdown注意:man shutdown 打开命令说明书之后,使用按键q退出
二、目录操作命令
我们知道Linux的目录结构为树状结构,最顶级的目录为根目录 /。
其他目录通过挂载可以将它们添加到树中,通过解除挂载可以移除它们。
首先我们需要先知道什么是绝对路径与相对路径。
绝对路径:路径的写法,由根目录 / 写起,例如:/usr/share/doc 这个目录。
相对路径:路径的写法,不是由
/写起,例如由/usr/share/doc要到/usr/share/man底下时,可以写成:cd ../man这就是相对路径的写法啦!
2.1 目录切换 cd
命令:cd 目录
cd是Change Directory的缩写,这是用来变换工作目录的命令。
cd / 切换到根目录cd /usr 切换到根目录下的usr目录cd ../ 切换到上一级目录 或者 cd ..cd ~ 切换到home目录cd - 切换到上次访问的目录
2.2 目录查看 ls [-al]
命令:ls [-al]
语法:
ls [-aAdfFhilnrRSt] 目录名称ls [--color={never,auto,always}] 目录名称ls [--full-time] 目录名称ls 查看当前目录下的所有目录和文件ls -a 查看当前目录下的所有目录和文件(包括隐藏的文件)ls -l 或 ll 列表查看当前目录下的所有目录和文件(列表查看,显示更多信息)ls /dir 查看指定目录下的所有目录和文件 如:ls /usr
将家目录下的所有文件列出来(含属性与隐藏档)
ls -al ~
2.3 目录操作【增,删,改,查】
2.3.1 创建目录【增】 mkdir
如果想要创建新的目录的话,那么就使用mkdir (make directory)吧。
语法:
mkdir [-mp] 目录名称
选项与参数:
-m :配置文件的权限喔!直接配置,不需要看默认权限 (umask) 的脸色~
-p :帮助你直接将所需要的目录(包含上一级目录)递归创建起来!
实例:请到/tmp底下尝试创建数个新目录看看:
cd /tmp[root@www tmp] mkdir test <==创建一名为 test 的新目录[root@www tmp] mkdir test1/test2/test3/test4mkdir: cannot create directory `test1/test2/test3/test4': No such file or directory <== 没办法直接创建此目录啊![root@www tmp] mkdir -p test1/test2/test3/test4
加了这个 -p 的选项,可以自行帮你创建多层目录!
实例:创建权限为 rwx–x—x 的目录。
[root@www tmp] mkdir -m 711 test2[root@www tmp] ls -ldrwxr-xr-x 3 root root 4096 Jul 18 12:50 testdrwxr-xr-x 3 root root 4096 Jul 18 12:53 test1drwx--x--x 2 root root 4096 Jul 18 12:54 test2
上面的权限部分,如果没有加上 -m 来强制配置属性,系统会使用默认属性。
如果我们使用 -m ,如上例我们给予 -m 711 来给予新的目录 drwx–x—x 的权限。
2.3.2 删除目录或文件【删】rm
rm [-fir] 文件或目录
选项与参数:
-f :就是 force 的意思,忽略不存在的文件,不会出现警告信息;
-i :互动模式,在删除前会询问使用者是否动作
-r :递归删除啊!最常用在目录的删除了!这是非常危险的选项!!!
删除文件:rm 文件 删除当前目录下的文件rm -f 文件 删除当前目录的的文件(不询问)
删除目录:rm -r aaa 递归删除当前目录下的aaa目录rm -rf aaa 递归删除当前目录下的aaa目录(不询问)
全部删除:rm -rf 将当前目录下的所有目录和文件全部删除rm -rf / 【慎用!慎用!慎用!】将根目录下的所有文件全部删除
注意:rm不仅可以删除目录,也可以删除其他文件或压缩包,为了方便大家的记忆,无论删除任何目录或文件,都直接使用 rm -rf 目录/文件/压缩包
rmdir (删除空的目录)
语法:
rmdir [-p] 目录名称
选项与参数:
-p :连同上一级『空的』目录也一起删除
删除 runoob 目录
[root@www tmp] rmdir runoob
将 mkdir 实例中创建的目录(/tmp 底下)删除掉!
[root@www tmp] ls -l <==看看有多少目录存在?drwxr-xr-x 3 root root 4096 Jul 18 12:50 testdrwxr-xr-x 3 root root 4096 Jul 18 12:53 test1drwx--x--x 2 root root 4096 Jul 18 12:54 test2[root@www tmp] rmdir test <==可直接删除掉,没问题[root@www tmp] rmdir test1 <==因为尚有内容,所以无法删除!rmdir: `test1': Directory not empty[root@www tmp] rmdir -p test1/test2/test3/test4[root@www tmp] ls -l <==您看看,底下的输出中test与test1不见了!drwx--x--x 2 root root 4096 Jul 18 12:54 test2
利用 -p 这个选项,立刻就可以将 test1/test2/test3/test4 一次删除。
不过要注意的是,这个 rmdir 仅能删除空的目录,你可以使用 rm 命令来删除非空目录。
2.3.3 目录修改【改】mv 和 cp
mv (移动文件与目录,或修改名称)
语法:
[root@www ~] mv [-fiu] source destination[root@www ~] mv [options] source1 source2 source3 .... directory
选项与参数:
-f :force 强制的意思,如果目标文件已经存在,不会询问而直接覆盖;
-i :若目标文件 (destination) 已经存在时,就会询问是否覆盖!
-u :若目标文件已经存在,且 source 比较新,才会升级 (update)
cp (复制文件或目录)
cp 即拷贝文件和目录。
语法:
[root@www ~] cp [-adfilprsu] 来源档(source) 目标档(destination)[root@www ~] cp [options] source1 source2 source3 .... directory
选项与参数:
-a:相当於 -pdr 的意思,至於 pdr 请参考下列说明;(常用)
-d:若来源档为连结档的属性(link file),则复制连结档属性而非文件本身;
-f:为强制(force)的意思,若目标文件已经存在且无法开启,则移除后再尝试一次;
-i:若目标档(destination)已经存在时,在覆盖时会先询问动作的进行(常用)
-l:进行硬式连结(hard link)的连结档创建,而非复制文件本身;
-p:连同文件的属性一起复制过去,而非使用默认属性(备份常用);
-r:递归持续复制,用於目录的复制行为;(常用)
-s:复制成为符号连结档 (symbolic link),亦即『捷径』文件;
-u:若 destination 比 source 旧才升级 destination !
一、重命名目录命令:mv 当前目录 新目录例如:mv aaa bbb 将目录aaa改为bbb注意:mv的语法不仅可以对目录进行重命名而且也可以对各种文件,压缩包等进行 重命名的操作
二、剪切目录命令:mv 目录名称 目录的新位置示例:将/usr/tmp目录下的aaa目录剪切到 /usr目录下面 mv /usr/tmp/aaa /usr注意:mv语法不仅可以对目录进行剪切操作,对文件和压缩包等都可执行剪切操作
三、拷贝目录命令:cp -r 目录名称 目录拷贝的目标位置 -r代表递归示例:将/usr/tmp目录下的aaa目录复制到 /usr目录下面 cp /usr/tmp/aaa /usr注意:cp命令不仅可以拷贝目录还可以拷贝文件,压缩包等,拷贝文件和压缩包时不 用写-r递归
2.3.4 搜索目录【查】find
Linux find 命令用来在指定目录下查找文件。任何位于参数之前的字符串都将被视为欲查找的目录名。如果使用该命令时,不设置任何参数,则 find 命令将在当前目录下查找子目录与文件。并且将查找到的子目录和文件全部进行显示。
find path -option [ -print ] [ -exec -ok command ] {} \;命令:find 目录 参数 文件名称
部分参数:
find 根据下列规则判断 path 和 expression,在命令列上第一个 - ( ) , ! 之前的部份为 path,之后的是 expression。如果 path 是空字串则使用目前路径,如果 expression 是空字串则使用 -print 为预设 expression。
expression 中可使用的选项有二三十个之多,在此只介绍最常用的部份。
-mount, -xdev : 只检查和指定目录在同一个文件系统下的文件,避免列出其它文件系统中的文件
-amin n : 在过去 n 分钟内被读取过
-anewer file : 比文件 file 更晚被读取过的文件
-atime n : 在过去n天内被读取过的文件
-cmin n : 在过去 n 分钟内被修改过
-cnewer file :比文件 file 更新的文件
-ctime n : 在过去n天内被修改过的文件
实例
将目前目录及其子目录下所有延伸档名是 c 的文件列出来。
find . -name "*.c"
将目前目录其其下子目录中所有一般文件列出
find . -type f
将目前目录及其子目录下所有最近 20 天内更新过的文件列出
find . -ctime -20
2.4 当前目录显示 pwd
pwd (显示目前所在的目录)
pwd 是 Print Working Directory 的缩写,也就是显示目前所在目录的命令。
[root@www ~] pwd [-P]
选项与参数:
-P :显示出确实的路径,而非使用连结 (link) 路径。
实例:单纯显示出目前的工作目录:
[root@www ~] pwd/root <== 显示出目录啦~
实例显示出实际的工作目录,而非连结档本身的目录名而已。
[root@www ~] cd /var/mail <==注意,/var/mail是一个连结档[root@www mail] pwd/var/mail <==列出目前的工作目录[root@www mail] pwd -P/var/spool/mail <==怎么回事?有没有加 -P 差很多~[root@www mail] ls -ld /var/maillrwxrwxrwx 1 root root 10 Sep 4 17:54 /var/mail -> spool/mail# 看到这里应该知道为啥了吧?因为 /var/mail 是连结档,连结到 /var/spool/mail # 所以,加上 pwd -P 的选项后,会不以连结档的数据显示,而是显示正确的完整路径啊!
三、文件操作命令
3.1 文件操作【增,删,改,查】
3.1.1 新建文件【增】touch
Linux touch命令用于修改文件或者目录的时间属性,包括存取时间和更改时间。若文件不存在,系统会建立一个新的文件。
ls -l 可以显示档案的时间记录。
语法
touch [-acfm][-d<日期时间>][-r<参考文件或目录>] [-t<日期时间>][--help][--version][文件或目录…]
参数说明:
a 改变档案的读取时间记录。
m 改变档案的修改时间记录。
c 假如目的档案不存在,不会建立新的档案。与 —no-create 的效果一样。
f 不使用,是为了与其他 unix 系统的相容性而保留。
r 使用参考档的时间记录,与 —file 的效果一样。
d 设定时间与日期,可以使用各种不同的格式。
t 设定档案的时间记录,格式与 date 指令相同。
–no-create 不会建立新档案。
–help 列出指令格式。
–version 列出版本讯息。
实例
使用指令”touch”修改文件”testfile”的时间属性为当前系统时间,输入如下命令:
$ touch testfile #修改文件的时间属性
首先,使用ls命令查看testfile文件的属性,如下所示:
$ ls -l testfile #查看文件的时间属性 #原来文件的修改时间为16:09 -rw-r--r-- 1 hdd hdd 55 2011-08-22 16:09 testfile
执行指令”touch”修改文件属性以后,并再次查看该文件的时间属性,如下所示:
$ touch testfile #修改文件时间属性为当前系统时间 $ ls -l testfile #查看文件的时间属性 #修改后文件的时间属性为当前系统时间 -rw-r--r-- 1 hdd hdd 55 2011-08-22 19:53 testfile
使用指令”touch”时,如果指定的文件不存在,则将创建一个新的空白文件。例如,在当前目录下,使用该指令创建一个空白文件”file”,输入如下命令:
$ touch file #创建一个名为“file”的新的空白文件
3.1.2 删除文件 【删】 rm
rm (移除文件或目录)
语法:
rm [-fir] 文件或目录
选项与参数:
-f :就是 force 的意思,忽略不存在的文件,不会出现警告信息;
-i :互动模式,在删除前会询问使用者是否动作
-r :递归删除啊!最常用在目录的删除了!这是非常危险的选项!!!
将创建的 bashrc 删除掉!
[root@www tmp]# rm -i bashrcrm: remove regular file `bashrc'? y
如果加上 -i 的选项就会主动询问喔,避免你删除到错误的档名!
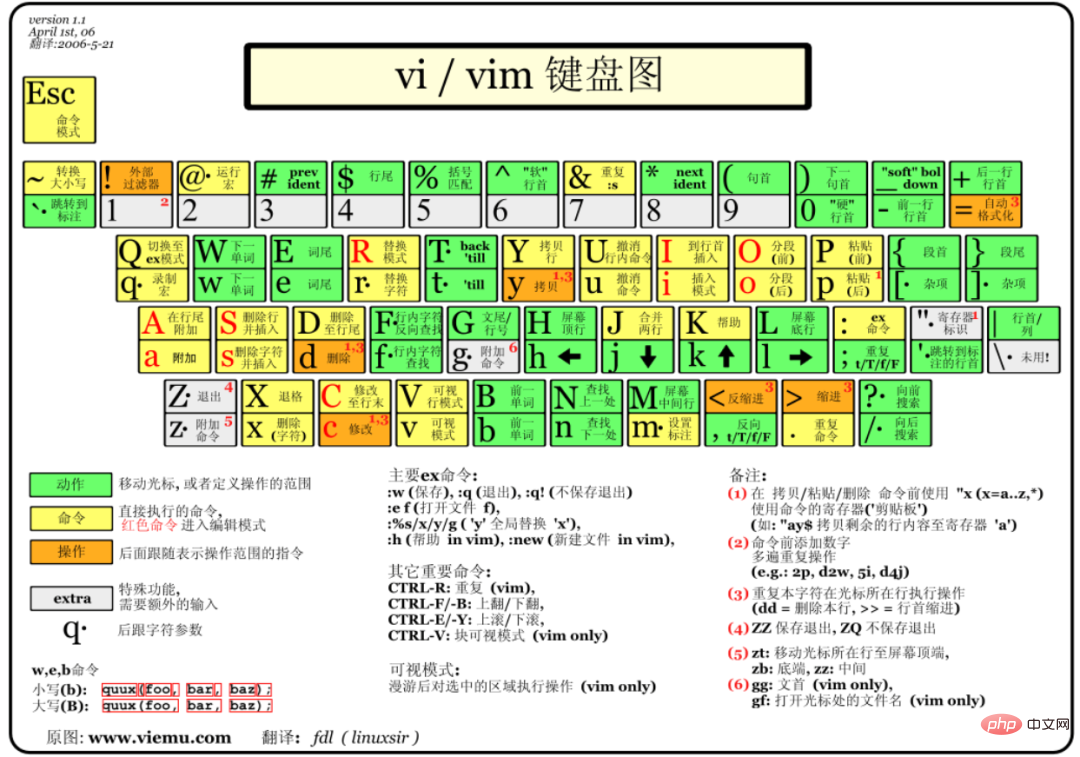
3.1.3 修改文件【改】 vi或vim
先来个vim键盘图!
vi/vim 的使用
基本上 vi/vim 共分为三种模式,分别是命令模式(Command mode),输入模式(Insert mode)和 底线命令模式(Last line mode)。这三种模式的作用分别是:
3.1.3.1 命令模式:
用户刚刚启动 vi/vim,便进入了命令模式。
이 상태에서 키를 누르면 Vim은 문자를 입력하는 대신 명령으로 인식합니다. 예를 들어 이때 i를 누르면 문자가 입력되지 않습니다. i는 명령으로 처리됩니다.
다음은 일반적으로 사용되는 몇 가지 명령입니다.
i 문자를 입력하려면 입력 모드로 전환하세요.
x현재 커서 위치의 문자를 삭제합니다.
:하단 명령 모드로 전환하여 하단에 명령을 입력하세요.
텍스트를 편집하려면 Vim을 시작하고 명령 모드로 들어간 다음 i를 눌러 입력 모드로 전환하세요.
명령 모드에는 가장 기본적인 명령 중 일부만 있으므로 더 많은 명령을 입력하려면 여전히 최종 명령 모드에 의존해야 합니다.
3.1.3.2 입력 모드
명령 모드에서 i를 누르면 입력 모드로 들어갑니다.
입력 모드에서는 다음 키를 사용할 수 있습니다:
문자 키 및 Shift 조합, 문자 입력
ENTER, Enter 키, 줄 바꿈
BACK SPACE, 백스페이스 키, 커서 앞의 문자 삭제
DEL , 삭제 키, 커서 뒤의 한 문자 삭제
방향 키, 텍스트에서 커서 이동
HOME/END, 커서를 줄의 시작/끝으로 이동
Page Up /Page Down, 페이지를 위로/아래로
Insert, 커서를 입력/바꾸기 모드로 전환하면 커서가 세로 막대/밑줄이 됩니다
ESC, 입력 모드 종료, 명령 모드로 전환
3.1.3.4 하단 명령 모드
명령 모드에서 : (영문 콜론)을 눌러 하단 명령 모드로 들어갑니다.
최하위 명령 모드를 사용하면 단일 또는 다중 문자 명령을 입력할 수 있으며 사용 가능한 명령이 많이 있습니다.
최하위 명령 모드에서 기본 명령은 다음과 같습니다(콜론은 생략되었습니다):
q 프로그램 종료
w 파일 저장
언제든지 최종 명령 모드를 종료하려면 ESC 키를 누르세요.
간단히 말하면 이 세 가지 모드를 아래 아이콘으로 생각할 수 있습니다.
Open file
명령: vi 파일 이름 예: 현재 디렉터리에서 aa를 통해 aa.txt 파일을 엽니다. .txt 또는 vim aa.txt
참고: vi 편집기를 사용하여 파일을 연 후에는 명령 모드이므로 편집 모드로 들어가려면 키보드 i/a/o를 클릭하여 편집할 수 없습니다.
파일 편집
vi 편집기를 사용하여 파일을 열고 i, a 또는 o 키를 클릭하여 편집 모드로 들어갑니다.
i: 커서가 있는 문자 이전에 삽입 시작: a: 커서가 있는 문자 이후에 삽입 시작 o: 커서가 있는 줄 아래에 새 줄 삽입 시작
편집 저장 또는 취소
파일 저장:
1단계: ESC 명령줄 모드 입력 2단계: 최종 모드 입력 3단계: wq 저장 및 편집 종료
편집 취소:
단계 1: ESC를 눌러 명령줄 모드로 들어갑니다. 2단계: 최종 모드로 들어갑니다. 3단계: q! 이 수정 사항을 취소하고 편집을 종료합니다
3.1.4 파일 보기 [확인]
Linux 시스템에서 다음 명령을 사용하여 내용을 확인합니다. 파일:
cat은 첫 번째 줄부터 파일 내용을 표시합니다.
tac는 마지막 줄부터 시작합니다. tac은 cat이 거꾸로 쓰여 있는 것을 볼 수 있습니다!
nl 표시되면 줄번호를 출력!
more 파일 내용을 페이지 단위로 표시
less 与 more 类似,但是比 more 更好的是,他可以往前翻页!
head 只看头几行
tail 只看尾巴几行
你可以使用 man [命令]来查看各个命令的使用文档,如 :man cp。
3.1.4.1 cat
由第一行开始显示文件内容
语法:
cat [-AbEnTv]
选项与参数:
-A :相当於 -vET 的整合选项,可列出一些特殊字符而不是空白而已;
-b :列出行号,仅针对非空白行做行号显示,空白行不标行号!
-E :将结尾的断行字节 $ 显示出来;
-n :列印出行号,连同空白行也会有行号,与 -b 的选项不同;
-T :将 [tab] 按键以 ^I 显示出来;
-v :列出一些看不出来的特殊字符
检看 /etc/issue 这个文件的内容:
[root@www ~] cat /etc/issueCentOS release 6.4 (Final)Kernel \r on an \m
3.1.3.2 tac
tac与cat命令刚好相反,文件内容从最后一行开始显示,可以看出 tac 是 cat 的倒着写!如:
[root@www ~] tac /etc/issueKernel \r on an \mCentOS release 6.4 (Final)
3.1.3.3 nl
显示行号
语法:
nl [-bnw] 文件
选项与参数:
-b :指定行号指定的方式,主要有两种:-b a :表示不论是否为空行,也同样列出行号(类似 cat -n);-b t :如果有空行,空的那一行不要列出行号(默认值);
-n :列出行号表示的方法,主要有三种:-n ln :行号在荧幕的最左方显示;-n rn :行号在自己栏位的最右方显示,且不加 0 ;-n rz :行号在自己栏位的最右方显示,且加 0 ;
-w :行号栏位的占用的位数。
实例一:用 nl 列出 /etc/issue 的内容
牛逼啊!接私活必备的 N 个开源项目!赶快收藏吧
[root@www ~] nl /etc/issue 1 CentOS release 6.4 (Final) 2 Kernel \r on an \m123
3.1.3.5 more
一页一页翻动
[root@www ~] more /etc/man_db.config ## Generated automatically from man.conf.in by the# configure script.## man.conf from man-1.6d....(中间省略)....--More--(28%) <== 重点在这一行喔!你的光标也会在这里等待你的命令
在 more 这个程序的运行过程中,你有几个按键可以按的:
空白键 (space):代表向下翻一页;
Enter :代表向下翻『一行』;
/字串 :代表在这个显示的内容当中,向下搜寻『字串』这个关键字;
:f :立刻显示出档名以及目前显示的行数;
q :代表立刻离开 more ,不再显示该文件内容。
b 或 [ctrl]-b :代表往回翻页,不过这动作只对文件有用,对管线无用。
3.1.3.6 less
一页一页翻动,以下实例输出/etc/man.config文件的内容:
[root@www ~] less /etc/man.config## Generated automatically from man.conf.in by the# configure script.## man.conf from man-1.6d....(中间省略)....: <== 这里可以等待你输入命令!
less运行时可以输入的命令有:
空白键 :向下翻动一页;
[pagedown]:向下翻动一页;
[pageup] :向上翻动一页;
/字串 :向下搜寻『字串』的功能;
?字串 :向上搜寻『字串』的功能;
n :重复前一个搜寻 (与 / 或 ? 有关!)
N :反向的重复前一个搜寻 (与 / 或 ? 有关!)
q :离开 less 这个程序;
3.1.3.7 head
取出文件前面几行
语法:
head [-n number] 文件
选项与参数:
-n :后面接数字,代表显示几行的意思
[root@www ~] head /etc/man.config
默认的情况中,显示前面 10 行!若要显示前 20 行,就得要这样:
[root@www ~] head -n 20 /etc/man.config
3.1.3.8 tail
取出文件后面几行
语法:
tail [-n number] 文件
选项与参数:
-n :后面接数字,代表显示几行的意思
-f :表示持续侦测后面所接的档名,要等到按下[ctrl]-c才会结束tail的侦测
[root@www ~] tail /etc/man.config# 默认的情况中,显示最后的十行!若要显示最后的 20 行,就得要这样:[root@www ~] tail -n 20 /etc/man.config
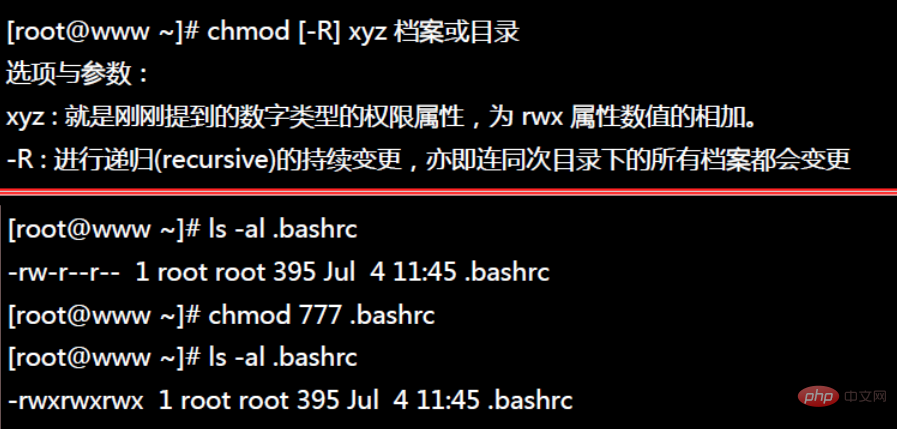
3.2 权限修改
Linux/Unix 的文件调用权限分为三级 : 文件拥有者、群组、其他。利用 chmod 可以藉以控制文件如何被他人所调用。
使用权限 : 所有使用者
语法
chmod [-cfvR] [--help] [--version] mode file...
参数说明
mode : 权限设定字串,格式如下 :
[ugoa...][[+-=][rwxX]...][,...]
其中:
u는 파일의 소유자를 나타내고, g는 파일의 소유자와 같은 그룹에 속한 사람을 나타내고, o는 다른 사람을 나타내고, a는 세 가지 모두를 나타냅니다.
+는 권한 추가, - 권한 취소, = 권한만 설정을 의미합니다.
r은 읽기 가능, w는 쓰기 가능, x는 실행 가능, X는 파일이 하위 디렉터리이거나 파일이 실행 가능하도록 설정된 경우에만 의미합니다.
기타 매개변수 설명:
-c: 파일 권한이 실제로 변경된 경우 변경 작업이 표시됩니다.
-f: 파일 권한을 변경할 수 없는 경우 표시하지 않습니다. 오류 메시지
-
-v: 권한 변경 세부 정보 표시
-R: 현재 디렉터리의 모든 파일과 하위 디렉터리에 동일한 권한 변경을 적용합니다(즉, 재귀적인 방식으로 하나씩 변경합니다).
–도움말: 보조 지침 표시
–버전: 표시 버전
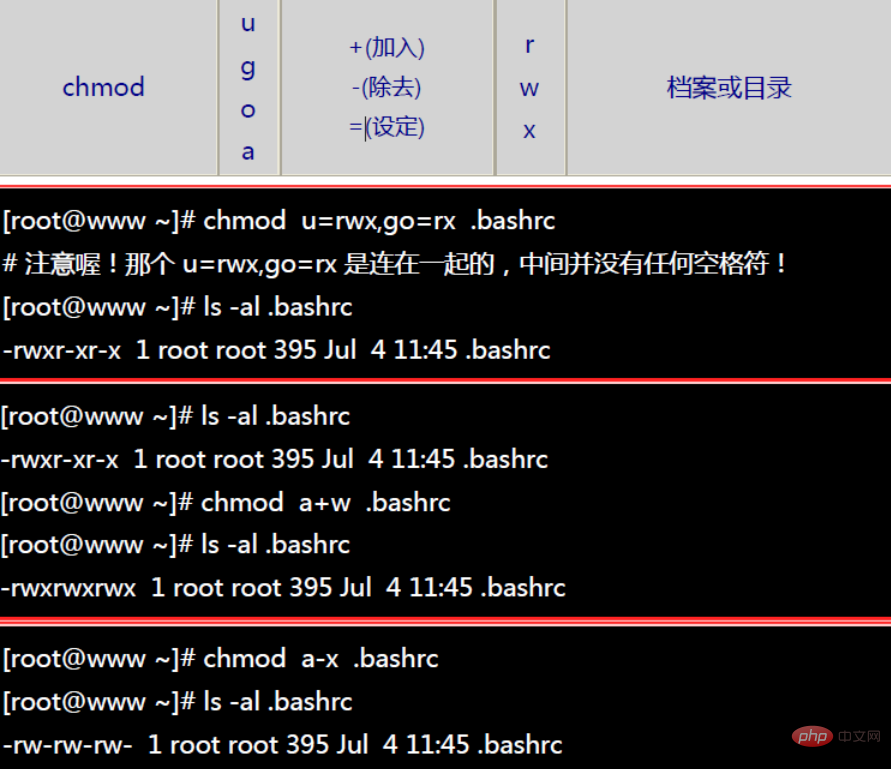
권한을 설정하는 방법에는 두 가지가 있습니다. 숫자나 기호를 사용하여 권한을 변경할 수 있습니다.
숫자 유형 변경 파일 권한:
기호 유형 변경 파일 권한:
4. 압축된 파일 작업
Linux에서 일반적으로 사용되는 압축 및 압축 풀기 명령에는 tar, gzip, gunzip, bzip2, bunzip2,compress, uncompress, zip, unzip, rar, unrar 등이 있습니다.
4.1 패키징, 압축 및 압축 풀기
Windows의 압축 파일 확장자는 .zip/.rar입니다. Linux의 패키지 파일: aa.tarlinux. 패키지 및 압축 파일입니다. Linux: .tar.gz
Linux의 패키지 파일은 일반적으로 .tar로 끝나고, 압축 명령은 일반적으로 .gz로 끝납니다. 일반적인 상황에서는 패키징과 압축이 함께 이루어지며, 패키징되고 압축된 파일의 접미사 이름은 일반적으로 .tar.gz입니다.
4.1.1 tar
가장 일반적으로 사용되는 패키징 명령은 tar입니다. tar 프로그램을 사용하여 만든 패키지를 tar 패키지라고 하는 경우가 많습니다. 일반적으로 tar 패키지 파일에 대한 명령은 .tar로 끝납니다. tar 패키지를 생성한 후 다른 프로그램을 이용하여 압축할 수 있으므로 먼저 tar 명령어의 기본적인 사용법에 대해 알아보겠습니다.
tar 명령에는 많은 옵션이 있지만(man tar로 볼 수 있음) 일반적으로 사용되는 옵션은 몇 가지뿐입니다.
tar -cf all.tar *.jpg
这条命令是将所有 .jpg 的文件打成一个名为 all.tar 的包。-c 是表示产生新的包,-f 指定包的文件名。
tar -rf all.tar *.gif
这条命令是将所有 .gif 的文件增加到 all.tar 的包里面去,-r 是表示增加文件的意思。
tar -uf all.tar logo.gif
这条命令是更新原来 tar 包 all.tar 中 logo.gif 文件,-u 是表示更新文件的意思。
tar -tf all.tar
这条命令是列出 all.tar 包中所有文件,-t 是列出文件的意思。
tar -xf all.tar
这条命令是解出 all.tar 包中所有文件,-x 是解开的意思。
以上就是 tar 的最基本的用法。为了方便用户在打包解包的同时可以压缩或解压文件,tar 提供了一种特殊的功能。这就是 tar 可以在打包或解包的同时调用其它的压缩程序,比如调用 gzip、bzip2 等。
4.1.1.1 tar调用
gzip 是 GNU 组织开发的一个压缩程序,.gz 结尾的文件就是 gzip 压缩的结果。与 gzip 相对的解压程序是 gunzip。tar 中使用 -z 这个参数来调用gzip。下面来举例说明一下:
tar -czf all.tar.gz *.jpg
这条命令是将所有 .jpg 的文件打成一个 tar 包,并且将其用 gzip 压缩,生成一个 gzip 压缩过的包,包名为 all.tar.gz。
tar -xzf all.tar.gz
这条命令是将上面产生的包解开。
4.1.1.2 tar 调用 bzip2
bzip2 是一个压缩能力更强的压缩程序,.bz2 结尾的文件就是 bzip2 压缩的结果。
与 bzip2 相对的解压程序是 bunzip2。tar 中使用 -j 这个参数来调用 gzip。下面来举例说明一下:
tar -cjf all.tar.bz2 *.jpg
这条命令是将所有 .jpg 的文件打成一个 tar 包,并且将其用 bzip2 压缩,生成一个 bzip2 压缩过的包,包名为 all.tar.bz2
tar -xjf all.tar.bz2
这条命令是将上面产生的包解开。
4.1.1.3 tar 调用 compress
compress 也是一个压缩程序,但是好象使用 compress 的人不如 gzip 和 bzip2 的人多。.Z 结尾的文件就是 bzip2 压缩的结果。与 compress 相对的解压程序是 uncompress。tar 中使用 -Z 这个参数来调用 compress。下面来举例说明一下:
tar -cZf all.tar.Z *.jpg
这条命令是将所有 .jpg 的文件打成一个 tar 包,并且将其用 compress 压缩,生成一个 uncompress 压缩过的包,包名为 all.tar.Z。
tar -xZf all.tar.Z
这条命令是将上面产生的包解开。
有了上面的知识,你应该可以解开多种压缩文件了,下面对于 tar 系列的压缩文件作一个小结:
1) 对于.tar结尾的文件
tar -xf all.tar
2) 对于 .gz 结尾的文件
gzip -d all.gzgunzip all.gz
3)对于 .tgz 或 .tar.gz 结尾的文件
tar -xzf all.tar.gztar -xzf all.tgz
4) 对于 .bz2 结尾的文件
bzip2 -d all.bz2bunzip2 all.bz2
5) 对于 tar.bz2 结尾的文件
tar -xjf all.tar.bz2
6) 对于 .Z 结尾的文件
uncompress all.Z
7) 对于 .tar.Z 结尾的文件
tar -xZf all.tar.z
另外对于 Windows 下的常见压缩文件 .zip 和 .rar,Linux 也有相应的方法来解压它们:
1) 对于 .zip
linux 下提供了 zip 和 unzip 程序,zip 是压缩程序,unzip 是解压程序。它们的参数选项很多,这里只做简单介绍,依旧举例说明一下其用法:
zip all.zip *.jpg
这条命令是将所有 .jpg 的文件压缩成一个 zip 包:
unzip all.zip
这条命令是将 all.zip 中的所有文件解压出来。
2) 对于 .rar
要在 linux 下处理 .rar 文件,需要安装 RAR for Linux。下载地址:http://www.rarsoft.com/download.htm,下载后安装即可。
tar -xzpvf rarlinux-x64-5.6.b5.tar.gz cd rar make
这样就安装好了,安装后就有了 rar 和 unrar 这两个程序,rar 是压缩程序,unrar 是解压程序。它们的参数选项很多,这里只做简单介绍,依旧举例说明一下其用法:
rar a all *.jpg
这条命令是将所有 .jpg 的文件压缩成一个 rar 包,名为 all.rar,该程序会将 .rar 扩展名将自动附加到包名后。
unrar e all.rar
这条命令是将 all.rar 中的所有文件解压出来
4.2 扩展内容
tar
-c: 建立压缩档案 -x:解压 -t:查看内容 shell-r:向压缩归档文件末尾追加文件 -u:更新原压缩包中的文件
这五个是独立的命令,压缩解压都要用到其中一个,可以和别的命令连用但只能用其中一个。下面的参数是根据需要在压缩或解压档案时可选的。
-z:有gzip属性的 -j:有bz2属性的 -Z:有compress属性的 -v:显示所有过程 -O:将文件解开到标准输出
下面的参数 -f 是必须的:
-f: 使用档案名字,切记,这个参数是最后一个参数,后面只能接档案名。
# tar -cf all.tar *.jpg
这条命令是将所有 .jpg 的文件打成一个名为 all.tar 的包。-c 是表示产生新的包,-f 指定包的文件名。
tar -rf all.tar *.gif
这条命令是将所有 .gif 的文件增加到 all.tar 的包里面去。-r 是表示增加文件的意思。
tar -uf all.tar logo.gif
这条命令是更新原来 tar 包 all.tar 中 logo.gif 文件,-u 是表示更新文件的意思。
tar -tf all.tar
这条命令是列出 all.tar 包中所有文件,-t 是列出文件的意思。
tar -xf all.tar
这条命令是解出 all.tar 包中所有文件,-x 是解开的意思。
压缩
tar –cvf jpg.tar *.jpg // 将目录里所有jpg文件打包成 tar.jpg tar –czf jpg.tar.gz *.jpg // 将目录里所有jpg文件打包成 jpg.tar 后,并且将其用 gzip 压缩,生成一个 gzip 压缩过的包,命名为 jpg.tar.gz tar –cjf jpg.tar.bz2 *.jpg // 将目录里所有jpg文件打包成 jpg.tar 后,并且将其用 bzip2 压缩,生成一个 bzip2 压缩过的包,命名为jpg.tar.bz2 tar –cZf jpg.tar.Z *.jpg // 将目录里所有 jpg 文件打包成 jpg.tar 后,并且将其用 compress 压缩,生成一个 umcompress 压缩过的包,命名为jpg.tar.Z rar a jpg.rar *.jpg // rar格式的压缩,需要先下载 rar for linux zip jpg.zip *.jpg // zip格式的压缩,需要先下载 zip for linux
解压
tar –xvf file.tar // 解压 tar 包 tar -xzvf file.tar.gz // 解压 tar.gz tar -xjvf file.tar.bz2 // 解压 tar.bz2 tar –xZvf file.tar.Z // 解压 tar.Z unrar e file.rar // 解压 rar unzip file.zip // 解压 zip
总结
1、*.tar 用 tar –xvf 解压 2、*.gz 用 gzip -d或者gunzip 解压 3、*.tar.gz和*.tgz 用 tar –xzf 解压 4、*.bz2 用 bzip2 -d或者用bunzip2 解压 5、*.tar.bz2用tar –xjf 解压 6、*.Z 用 uncompress 解压 7、*.tar.Z 用tar –xZf 解压 8、*.rar 用 unrar e解压 9、*.zip 用 unzip 解压
五、查找命令
5.1 grep
grep命令是一种强大的文本搜索工具
使用实例:
ps -ef | grep sshd 查找指定ssh服务进程 ps -ef | grep sshd | grep -v grep 查找指定服务进程,排除gerp身 ps -ef | grep sshd -c 查找指定进程个数
从文件内容查找匹配指定字符串的行:
$ grep "被查找的字符串" 文件名
例子:在当前目录里第一级文件夹中寻找包含指定字符串的 .in 文件
grep "thermcontact" /.in
从文件内容查找与正则表达式匹配的行:
$ grep –e "正则表达式" 文件名
查找时不区分大小写:
$ grep –i "被查找的字符串" 文件名
查找匹配的行数:
$ grep -c “被查找的字符串” 文件名
从文件内容查找不匹配指定字符串的行:
$ grep –v "被查找的字符串" 文件名
5.2 find
find命令在目录结构中搜索文件,并对搜索结果执行指定的操作。
find 默认搜索当前目录及其子目录,并且不过滤任何结果(也就是返回所有文件),将它们全都显示在屏幕上。另外,搜索公众号编程技术圈后台回复“1024”,获取一份惊喜礼包。
使用实例:
find . -name "*.log" -ls 在当前目录查找以.log结尾的文件,并显示详细信息。find /root/ -perm 600 查找/root/目录下权限为600的文件 find . -type f -name "*.log" 查找当目录,以.log结尾的普通文件 find . -type d | sort 查找当前所有目录并排序 find . -size +100M 查找当前目录大于100M的文件
从根目录开始查找所有扩展名为 .log 的文本文件,并找出包含 “ERROR” 的行:
$ find / -type f -name "*.log" | xargs grep "ERROR"
例子:从当前目录开始查找所有扩展名为 .in 的文本文件,并找出包含 “thermcontact” 的行:
find . -name "*.in" | xargs grep "thermcontact"
5.3 locate
locate 让使用者可以很快速的搜寻某个路径。默认每天自动更新一次,所以使用locate 命令查不到最新变动过的文件。为了避免这种情况,可以在使用locate之前,先使用updatedb命令,手动更新数据库。如果数据库中没有查询的数据,则会报出locate: can not stat () `/var/lib/mlocate/mlocate.db’: No such file or directory该错误!updatedb即可!
yum -y install mlocate 如果是精简版CentOS系统需要安装locate命令
使用实例:
updatedblocate /etc/sh 搜索etc目录下所有以sh开头的文件 locate pwd 查找和pwd相关的所有文件
5.4 whereis
whereis命令是定位可执行文件、源代码文件、帮助文件在文件系统中的位置。这些文件的属性应属于原始代码,二进制文件,或是帮助文件。
使用实例:
whereis ls 将和ls文件相关的文件都查找出来
5.5 which
which命令的作用是在PATH变量指定的路径中,搜索某个系统命令的位置,并且返回第一个搜索结果。
使用实例:
which pwd 查找pwd命令所在路径 which java 查找path中java的路径
六、su、sudo
6.1 su
Linux su命令用于变更为其他使用者的身份,除 root 外,需要键入该使用者的密码。
使用权限:所有使用者。
语法
su [-fmp] [-c command] [-s shell] [--help] [--version] [-] [USER [ARG]]
参数说明:
-f 或 —fast 不必读启动档(如 csh.cshrc 等),仅用于 csh 或 tcsh
-m -p 或 —preserve-environment 执行 su 时不改变环境变数
-c command 或 —command=command 变更为帐号为 USER 的使用者并执行指令(command)后再变回原来使用者
-s shell 或 —shell=shell 指定要执行的 shell (bash csh tcsh 等),预设值为 /etc/passwd 内的该使用者(USER) shell
–help 显示说明文件
–version 显示版本资讯
- -l 或 —login 这个参数加了之后,就好像是重新 login 为该使用者一样,大部份环境变数(HOME SHELL USER等等)都是以该使用者(USER)为主,并且工作目录也会改变,如果没有指定 USER ,内定是 root
USER 欲变更的使用者帐号
ARG 传入新的 shell 参数
实例
变更帐号为 root 并在执行 ls 指令后退出变回原使用者
su -c ls root
变更帐号为 root 并传入 -f 参数给新执行的 shell
su root -f
变更帐号为 clsung 并改变工作目录至 clsung 的家目录(home dir)
su - clsung
切换用户
hnlinux@runoob.com:~$ whoami //显示当前用户hnlinuxhnlinux@runoob.com:~$ pwd //显示当前目录/home/hnlinuxhnlinux@runoob.com:~$ su root //切换到root用户密码:root@runoob.com:/home/hnlinux# whoami rootroot@runoob.com:/home/hnlinux# pwd/home/hnlinux
切换用户,改变环境变量
hnlinux@runoob.com:~$ whoami //显示当前用户hnlinuxhnlinux@runoob.com:~$ pwd //显示当前目录/home/hnlinuxhnlinux@runoob.com:~$ su - root //切换到root用户密码:root@runoob.com:/home/hnlinux# whoami rootroot@runoob.com:/home/hnlinux# pwd //显示当前目录/root
su用于用户之间的切换。但是切换前的用户依然保持登录状态。如果是root 向普通或虚拟用户切换不需要密码,反之普通用户切换到其它任何用户都需要密码验证。
su test:切换到test用户,但是路径还是/root目录su - test : 切换到test用户,路径变成了/home/testsu : 切换到root用户,但是路径还是原来的路径su - : 切换到root用户,并且路径是/rootsu不足:如果某个用户需要使用root权限、则必须要把root密码告诉此用户。退出返回之前的用户:exit
6.2 sudo
sudo是为所有想使用root权限的普通用户设计的。可以让普通用户具有临时使用root权限的权利。只需输入自己账户的密码即可。
进入sudo配置文件命令:
vi /etc/sudoer或者visudo
案例:允许hadoop用户以root身份执行各种应用命令,需要输入hadoop用户的密码。hadoop ALL=(ALL) ALL
案例:只允许hadoop用户以root身份执行ls 、cat命令,并且执行时候免输入密码。配置文件中:hadoop ALL=NOPASSWD: /bin/ls, /bin/cat
su root -f
变更帐号为 clsung 并改变工作目录至 clsung 的家目录(home dir)
su - clsung
切换用户
hnlinux@runoob.com:~$ whoami //显示当前用户hnlinuxhnlinux@runoob.com:~$ pwd //显示当前目录/home/hnlinuxhnlinux@runoob.com:~$ su root //切换到root用户密码:root@runoob.com:/home/hnlinux# whoami rootroot@runoob.com:/home/hnlinux# pwd/home/hnlinux
切换用户,改变环境变量
hnlinux@runoob.com:~$ whoami //显示当前用户hnlinuxhnlinux@runoob.com:~$ pwd //显示当前目录/home/hnlinuxhnlinux@runoob.com:~$ su - root //切换到root用户密码:root@runoob.com:/home/hnlinux# whoami rootroot@runoob.com:/home/hnlinux# pwd //显示当前目录/root
su用于用户之间的切换。但是切换前的用户依然保持登录状态。如果是root 向普通或虚拟用户切换不需要密码,反之普通用户切换到其它任何用户都需要密码验证。
su test:切换到test用户,但是路径还是/root目录su - test : 切换到test用户,路径变成了/home/testsu : 切换到root用户,但是路径还是原来的路径su - : 切换到root用户,并且路径是/rootsu不足:如果某个用户需要使用root权限、则必须要把root密码告诉此用户。退出返回之前的用户:exit
七、下载与安装 yum
yum( Yellow dog Updater, Modified)是一个在Fedora和RedHat以及SUSE中的Shell前端软件包管理器。
基於RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软体包,无须繁琐地一次次下载、安装。
yum提供了查找、安装、删除某一个、一组甚至全部软件包的命令,而且命令简洁而又好记。
7.1 yum 语法
yum [options] [command] [package ...]
options:可选,选项包括-h(帮助),-y(当安装过程提示选择全部为”yes”),-q(不显示安装的过程)等等。
command:要进行的操作。
package操作的对象。
7.2 yum常用命令
1.列出所有可更新的软件清单命令:yum check-update
2.更新所有软件命令:yum update
3.仅安装指定的软件命令:yum install
4.仅更新指定的软件命令:yum update
5.列出所有可安裝的软件清单命令:yum list
6.删除软件包命令:yum remove
7.查找软件包 命令:yum search
8.清除缓存命令:
yum clean packages: 清除缓存目录下的软件包
yum clean headers: 清除缓存目录下的 headers
yum clean oldheaders: 清除缓存目录下旧的 headers
yum clean, yum clean all (= yum clean packages; yum clean oldheaders) :清除缓存目录下的软件包及旧的headers
实例 1
安装 pam-devel
[root@www ~] yum install pam-develSetting up Install ProcessParsing package install argumentsResolving Dependencies <==先检查软件的属性相依问题--> Running transaction check---> Package pam-devel.i386 0:0.99.6.2-4.el5 set to be updated--> Processing Dependency: pam = 0.99.6.2-4.el5 for package: pam-devel--> Running transaction check---> Package pam.i386 0:0.99.6.2-4.el5 set to be updatedfilelists.xml.gz 100% |=========================| 1.6 MB 00:05filelists.xml.gz 100% |=========================| 138 kB 00:00-> Finished Dependency Resolution……(省略)
实例 2
移除 pam-devel
[root@www ~] yum remove pam-develSetting up Remove ProcessResolving Dependencies <==同样的,先解决属性相依的问题--> Running transaction check---> Package pam-devel.i386 0:0.99.6.2-4.el5 set to be erased--> Finished Dependency ResolutionDependencies Resolved============================================================================= Package Arch Version Repository Size=============================================================================Removing: pam-devel i386 0.99.6.2-4.el5 installed 495 kTransaction Summary=============================================================================Install 0 Package(s)Update 0 Package(s)Remove 1 Package(s) <==还好,并没有属性相依的问题,单纯移除一个软件Is this ok [y/N]: yDownloading Packages:Running rpm_check_debugRunning Transaction TestFinished Transaction TestTransaction Test SucceededRunning Transaction Erasing : pam-devel ######################### [1/1]Removed: pam-devel.i386 0:0.99.6.2-4.el5Complete!
实例 3
利用 yum 的功能,找出以 pam 为开头的软件名称有哪些?
[root@www ~] yum list pam*Installed Packagespam.i386 0.99.6.2-3.27.el5 installedpam_ccreds.i386 3-5 installedpam_krb5.i386 2.2.14-1 installedpam_passwdqc.i386 1.0.2-1.2.2 installedpam_pkcs11.i386 0.5.3-23 installedpam_smb.i386 1.1.7-7.2.1 installedAvailable Packages <==底下则是『可升级』的或『未安装』的pam.i386 0.99.6.2-4.el5 basepam-devel.i386 0.99.6.2-4.el5 basepam_krb5.i386 2.2.14-10 base
7.3 国内 yum 源
网易(163)yum源是国内最好的yum源之一 ,无论是速度还是软件版本,都非常的不错。
将yum源设置为163 yum,可以提升软件包安装和更新的速度,同时避免一些常见软件版本无法找到。
安装步骤
首先备份/etc/yum.repos.d/CentOS-Base.repo
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup1
下载对应版本 repo 文件, 放入 /etc/yum.repos.d/ (操作前请做好相应备份)
CentOS5 :http://mirrors.163.com/.help/CentOS5-Base-163.repo
CentOS6 :http://mirrors.163.com/.help/CentOS6-Base-163.repo
CentOS7 :http://mirrors.163.com/.help/CentOS7-Base-163.repo
wget http://mirrors.163.com/.help/CentOS6-Base-163.repomv CentOS6-Base-163.repo CentOS-Base.repo
运行以下命令生成缓存
yum clean allyum makecache
除了网易之外,国内还有其他不错的 yum 源,比如中科大和搜狐。
中科大的 yum 源,安装方法查看:https://lug.ustc.edu.cn/wiki/mirrors/help/centos
sohu 的 yum 源安装方法查看: http://mirrors.sohu.com/help/centos.htm
八. Linux 三剑客(awk,sed,grep)
awk、sed、grep更适合的方向:
grep 更适合单纯的查找或匹配文本
sed 更适合编辑匹配到的文本
awk 更适合格式化文本,对文本进行较复杂格式处理
8.1 awk
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。
之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
语法
awk [选项参数] 'script' var=value file(s)或awk [选项参数] -f scriptfile var=value file(s)
选项参数说明:
-F fs or —field-separator fs指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。
-v var=value or —asign var=value赋值一个用户定义变量。
-f scripfile or —file scriptfile从脚本文件中读取awk命令。
-mf nnn and -mr nnn对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
-W compact or —compat, -W traditional or —traditional在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。
-W copyleft or —copyleft, -W copyright or —copyright打印简短的版权信息。
-W help or —help, -W usage or —usage打印全部awk选项和每个选项的简短说明。
-W lint or —lint打印不能向传统unix平台移植的结构的警告。
-W lint-old or —lint-old打印关于不能向传统unix平台移植的结构的警告。
-W posix打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符 和 =不能代替^ 和 ^=;fflush无效。
-W re-interval or —re-inerval允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。
-W source program-text or —source program-text使用program-text作为源代码,可与-f命令混用。
-W version or —version打印bug报告信息的版本。
基本用法
log.txt文本内容如下:
2 this is a test3 Are you like awkThis's a test10 There are orange,apple,mongo
用法一:
awk '{[pattern] action}' {filenames} # 行匹配语句 awk '' 只能用单引号实例:
# 每行按空格或TAB分割,输出文本中的1、4项 $ awk '{print $1,$4}' log.txt --------------------------------------------- 2 a 3 like This's 10 orange,apple,mongo # 格式化输出 $ awk '{printf "%-8s %-10s\n",$1,$4}' log.txt --------------------------------------------- 2 a 3 like This's 10 orange,apple,mongo用法二:
awk -F #-F相当于内置变量FS, 指定分割字符
实例:
# 使用","分割 $ awk -F, '{print $1,$2}' log.txt --------------------------------------------- 2 this is a test 3 Are you like awk This's a test 10 There are orange apple # 或者使用内建变量 $ awk 'BEGIN{FS=","} {print $1,$2}' log.txt --------------------------------------------- 2 this is a test 3 Are you like awk This's a test 10 There are orange apple # 使用多个分隔符.先使用空格分割,然后对分割结果再使用","分割 $ awk -F '[ ,]' '{print $1,$2,$5}' log.txt --------------------------------------------- 2 this test 3 Are awk This's a 10 There apple用法三:
awk -v # 设置变量
实例:
$ awk -va=1 '{print $1,$1+a}' log.txt --------------------------------------------- 2 3 3 4 This's 1 10 11 $ awk -va=1 -vb=s '{print $1,$1+a,$1b}' log.txt --------------------------------------------- 2 3 2s 3 4 3s This's 1 This'ss 10 11 10s用法四:
awk -f {awk脚本} {文件名}实例:
$ awk -f cal.awk log.txt
运算符
| 运算符 | 描述 | ||
|---|---|---|---|
| = += -= = /= %= ^= *= | 赋值 | ||
| ?: | C条件表达式 | ||
| \ | \ | 逻辑或 | |
| && | 逻辑与 | ||
| ~ 및 !~ | 정규식과 일치하지만 정규식과 일치하지 않습니다. | ||
| < | Space | ||
+ - | |||
| | * / % | ||
+ - ! | |||
| ^ * | 지수 | ||
| ++ – | 접두사 또는 접미사로 증가 또는 감소 | ||
| $ | 필드 참조 | ||
| in | Array member |
过滤第一列大于2的行
$ awk '$1>2' log.txt #命令#输出3 Are you like awkThis's a test10 There are orange,apple,mongo12345
过滤第一列等于2的行
$ awk '$1==2 {print $1,$3}' log.txt #命令#输出2 is123过滤第一列大于2并且第二列等于’Are’的行。另外,搜索公众号Java架构师技术后台回复“面试题”,获取一份惊喜礼包。
$ awk '$1>2 && $2=="Are" {print $1,$2,$3}' log.txt #命令#输出3 Are you123内建变量
| 变量 | 描述 |
|---|---|
| $n | 当前记录的第n个字段,字段间由FS分隔 |
| $0 | 完整的输入记录 |
| ARGC | 命令行参数的数目 |
| ARGIND | 命令行中当前文件的位置(从0开始算) |
| ARGV | 包含命令行参数的数组 |
| CONVFMT | 数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组 |
| ERRNO | 最后一个系统错误的描述 |
| FIELDWIDTHS | 필드 너비 목록(스페이스바로 구분) |
| FILENAME | 현재 파일 이름 |
| FNR | 줄 번호는 각 파일에 대해 별도로 계산됩니다. |
| FS | 필드 구분 기호(기본값은 공백) |
| IGNORECASE | true인 경우 대소문자 무시 일치를 수행합니다. |
| NF | 레코드의 필드 수 |
| NR | 읽은 레코드 수는 Line입니다. 1부터 시작하는 숫자 |
| OFMT | 숫자 출력 형식(기본값은 %.6g) |
| OFS | 출력 레코드 구분 기호(개행 문자 출력), 출력 시 지정된 기호를 사용하여 새 줄을 대체합니다. 탈리스만 |
| ORS | 출력 레코드 구분 기호(기본값은 개행 문자) |
| RLENGTH | 일치 함수와 일치하는 문자열의 길이 |
| RS | 레코드 구분 기호(기본값은 개행 문자) ) |
| RSART | 일치 함수와 일치하는 문자열의 첫 번째 위치 |
| SUBSEP | 배열 첨자 구분 기호(기본값은 /034) |
$ awk 'BEGIN{printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n","FILENAME","ARGC","FNR","FS","NF","NR","OFS","ORS","RS";printf "---------------------------------------------\n"} {printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n",FILENAME,ARGC,FNR,FS,NF,NR,OFS,ORS,RS}' log.txtFILENAME ARGC FNR FS NF NR OFS ORS RS---------------------------------------------log.txt 2 1 5 1log.txt 2 2 5 2log.txt 2 3 3 3log.txt 2 4 4 4$ awk -F\' 'BEGIN{printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n","FILENAME","ARGC","FNR","FS","NF","NR","OFS","ORS","RS";printf "---------------------------------------------\n"} {printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n",FILENAME,ARGC,FNR,FS,NF,NR,OFS,ORS,RS}' log.txtFILENAME ARGC FNR FS NF NR OFS ORS RS---------------------------------------------log.txt 2 1 ' 1 1log.txt 2 2 ' 1 2log.txt 2 3 ' 2 3log.txt 2 4 ' 1 4# 输出顺序号 NR, 匹配文本行号$ awk '{print NR,FNR,$1,$2,$3}' log.txt---------------------------------------------1 1 2 this is2 2 3 Are you3 3 This's a test4 4 10 There are# 指定输出分割符$ awk '{print $1,$2,$5}' OFS=" $ " log.txt---------------------------------------------2 $ this $ test3 $ Are $ awkThis's $ a $10 $ There $使用正则,字符串匹配
# 输出第二列包含 "th",并打印第二列与第四列$ awk '$2 ~ /th/ {print $2,$4}' log.txt---------------------------------------------this a~ 表示模式开始。// 中是模式。
# 输出包含 "re" 的行$ awk '/re/ ' log.txt---------------------------------------------3 Are you like awk10 There are orange,apple,mongo
忽略大小写
$ awk 'BEGIN{IGNORECASE=1} /this/' log.txt---------------------------------------------2 this is a testThis's a test模式取反
$ awk '$2 !~ /th/ {print $2,$4}' log.txt---------------------------------------------Are likeaThere orange,apple,mongo$ awk '!/th/ {print $2,$4}' log.txt---------------------------------------------Are likeaThere orange,apple,mongoawk脚本
关于 awk 脚本,我们需要注意两个关键词 BEGIN 和 END。
BEGIN{ 这里面放的是执行前的语句 }
END {这里面放的是处理完所有的行后要执行的语句 }
{这里面放的是处理每一行时要执行的语句}
假设有这么一个文件(学生成绩表):
$ cat score.txtMarry 2143 78 84 77Jack 2321 66 78 45Tom 2122 48 77 71Mike 2537 87 97 95Bob 2415 40 57 62
我们的 awk 脚本如下:
$ cat cal.awk#!/bin/awk -f#运行前BEGIN { math = 0 english = 0 computer = 0 printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n" printf "---------------------------------------------\n"}#运行中{ math+=$3 english+=$4 computer+=$5 printf "%-6s %-6s %4d %8d %8d %8d\n", $1, $2, $3,$4,$5, $3+$4+$5}#运行后END { printf "---------------------------------------------\n" printf " TOTAL:%10d %8d %8d \n", math, english, computer printf "AVERAGE:%10.2f %8.2f %8.2f\n", math/NR, english/NR, computer/NR}123456789101112131415161718192021222324我们来看一下执行结果:
$ awk -f cal.awk score.txtNAME NO. MATH ENGLISH COMPUTER TOTAL---------------------------------------------Marry 2143 78 84 77 239Jack 2321 66 78 45 189Tom 2122 48 77 71 196Mike 2537 87 97 95 279Bob 2415 40 57 62 159--------------------------------------------- TOTAL: 319 393 350AVERAGE: 63.80 78.60 70.00
另外一些实例
AWK 的 hello world 程序为:
BEGIN { print "Hello, world!" }计算文件大小
$ ls -l *.txt | awk '{sum+=$5} END {print sum}'--------------------------------------------------666581从文件中找出长度大于 80 的行:
awk 'length>80' log.txt
打印九九乘法表
seq 9 | sed 'H;g' | awk -v RS='' '{for(i=1;i<=NF;i++)printf("%dx%d=%d%s", i, NR, i*NR, i==NR?"\n":"\t")}'8.2 sed
Linux sed 命令是利用脚本来处理文本文件。
sed 可依照脚本的指令来处理、编辑文本文件。
Sed 主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。
语法
sed [-hnV][-e<script>][-f<script文件>][文本文件]
参数说明:
-e<script>或--expression=<script>以选项中指定的script来处理输入的文本文件。-f
文件>文件>-h或–help 显示帮助。
-n或–quiet或–silent 仅显示script处理后的结果。
-V或–version 显示版本信息。
动作说明:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
实例
在testfile文件的第四行后添加一行,并将结果输出到标准输出,在命令行提示符下输入如下命令:
sed -e 4a\newLine testfile
首先查看testfile中的内容如下:
$ cat testfile #查看testfile 中的内容 HELLO LINUX! Linux is a free unix-type opterating system. This is a linux testfile! Linux test
使用sed命令后,输出结果如下:
$ sed -e 4a\newline testfile #使用sed 在第四行后添加新字符串 HELLO LINUX! #testfile文件原有的内容 Linux is a free unix-type opterating system. This is a linux testfile! Linux test newline
以行为单位的新增/删除
将 /etc/passwd 的内容列出并且列印行号,同时,请将第 2~5 行删除!
[root@www ~] nl /etc/passwd | sed '2,5d'1 root:x:0:0:root:/root:/bin/bash6 sync:x:5:0:sync:/sbin:/bin/sync7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown.....(后面省略).....
sed 的动作为 ‘2,5d’ ,那个 d 就是删除!因为 2-5 行给他删除了,所以显示的数据就没有 2-5 行罗~ 另外,注意一下,原本应该是要下达 sed -e 才对,没有 -e 也行啦!同时也要注意的是, sed 后面接的动作,请务必以 ‘’ 两个单引号括住喔!
只要删除第 2 行
nl /etc/passwd | sed '2d'
要删除第 3 到最后一行
nl /etc/passwd | sed '3,$d'
在第二行后(亦即是加在第三行)加上『drink tea?』字样!
[root@www ~] nl /etc/passwd | sed '2a drink tea'1 root:x:0:0:root:/root:/bin/bash2 bin:x:1:1:bin:/bin:/sbin/nologindrink tea3 daemon:x:2:2:daemon:/sbin:/sbin/nologin.....(后面省略).....
那如果是要在第二行前
nl /etc/passwd | sed '2i drink tea'
如果是要增加两行以上,在第二行后面加入两行字,例如 Drink tea or … 与 drink beer?
[root@www ~] nl /etc/passwd | sed '2a Drink tea or ......\> drink beer ?'1 root:x:0:0:root:/root:/bin/bash2 bin:x:1:1:bin:/bin:/sbin/nologinDrink tea or ......drink beer ?3 daemon:x:2:2:daemon:/sbin:/sbin/nologin.....(后面省略).....
每一行之间都必须要以反斜杠『 \ 』来进行新行的添加喔!所以,上面的例子中,我们可以发现在第一行的最后面就有 \ 存在。
以行为单位的替换与显示
将第2-5行的内容取代成为『No 2-5 number』呢?
[root@www ~] nl /etc/passwd | sed '2,5c No 2-5 number'1 root:x:0:0:root:/root:/bin/bashNo 2-5 number6 sync:x:5:0:sync:/sbin:/bin/sync.....(后面省略).....
透过这个方法我们就能够将数据整行取代了!
仅列出 /etc/passwd 文件内的第 5-7 行
[root@www ~] nl /etc/passwd | sed -n '5,7p'5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin6 sync:x:5:0:sync:/sbin:/bin/sync7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
可以透过这个 sed 的以行为单位的显示功能, 就能够将某一个文件内的某些行号选择出来显示。
数据的搜寻并显示
搜索 /etc/passwd有root关键字的行
nl /etc/passwd | sed '/root/p'1 root:x:0:0:root:/root:/bin/bash1 root:x:0:0:root:/root:/bin/bash2 daemon:x:1:1:daemon:/usr/sbin:/bin/sh3 bin:x:2:2:bin:/bin:/bin/sh4 sys:x:3:3:sys:/dev:/bin/sh5 sync:x:4:65534:sync:/bin:/bin/sync....下面忽略
如果root找到,除了输出所有行,还会输出匹配行。
使用-n的时候将只打印包含模板的行。
nl /etc/passwd | sed -n '/root/p'1 root:x:0:0:root:/root:/bin/bash
数据的搜寻并删除
删除/etc/passwd所有包含root的行,其他行输出
nl /etc/passwd | sed '/root/d'2 daemon:x:1:1:daemon:/usr/sbin:/bin/sh3 bin:x:2:2:bin:/bin:/bin/sh....下面忽略#第一行的匹配root已经删除了
数据的搜寻并执行命令
搜索/etc/passwd,找到root对应的行,执行后面花括号中的一组命令,每个命令之间用分号分隔,这里把bash替换为blueshell,再输出这行:
nl /etc/passwd | sed -n '/root/{s/bash/blueshell/;p;q}' 1 root:x:0:0:root:/root:/bin/blueshell最后的q是退出。
数据的搜寻并替换
除了整行的处理模式之外, sed 还可以用行为单位进行部分数据的搜寻并取代。基本上 sed 的搜寻与替代的与 vi 相当的类似!他有点像这样:
sed 's/要被取代的字串/新的字串/g'
先观察原始信息,利用 /sbin/ifconfig 查询 IP
[root@www ~] /sbin/ifconfig eth0eth0 Link encap:Ethernet HWaddr 00:90:CC:A6:34:84inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0inet6 addr: fe80::290:ccff:fea6:3484/64 Scope:LinkUP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1.....(以下省略).....
本机的ip是192.168.1.100。
将 IP 前面的部分予以删除
[root@www ~] /sbin/ifconfig eth0 | grep 'inet addr' | sed 's/^.*addr://g'192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
接下来则是删除后续的部分,亦即:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
将 IP 后面的部分予以删除
[root@www ~] /sbin/ifconfig eth0 | grep 'inet addr' | sed 's/^.*addr://g' | sed 's/Bcast.*$//g'192.168.1.100
多点编辑
一条sed命令,删除/etc/passwd第三行到末尾的数据,并把bash替换为blueshell
nl /etc/passwd | sed -e '3,$d' -e 's/bash/blueshell/'1 root:x:0:0:root:/root:/bin/blueshell2 daemon:x:1:1:daemon:/usr/sbin:/bin/sh
-e表示多点编辑,第一个编辑命令删除/etc/passwd第三行到末尾的数据,第二条命令搜索bash替换为blueshell。
直接修改文件内容(危险动作)
sed 可以直接修改文件的内容,不必使用管道命令或数据流重导向!不过,由於这个动作会直接修改到原始的文件,所以请你千万不要随便拿系统配置来测试!我们还是使用文件 regular_express.txt 文件来测试看看吧!
regular_express.txt 文件内容如下:
[root@www ~] cat regular_express.txt runoob.google.taobao.facebook.zhihu-weibo-
利用 sed 将 regular_express.txt 内每一行结尾若为 . 则换成 !
[root@www ~] sed -i 's/\.$/\!/g' regular_express.txt[root@www ~] cat regular_express.txt runoob!google!taobao!facebook!zhihu-weibo-
:q:q
利用 sed 直接在 regular_express.txt 最后一行加入 # This is a test:
[root@www ~] sed -i '$a # This is a test' regular_express.txt[root@www ~] cat regular_express.txt runoob!google!taobao!facebook!zhihu-weibo-# This is a test
由於 $ 代表的是最后一行,而 a 的动作是新增,因此该文件最后新增 # This is a test!
sed 的 -i 选项可以直接修改文件内容,这功能非常有帮助!举例来说,如果你有一个 100 万行的文件,你要在第 100 行加某些文字,此时使用 vim 可能会疯掉!因为文件太大了!那怎办?就利用 sed 啊!透过 sed 直接修改/取代的功能,你甚至不需要使用 vim 去修订!
追加行的说明:
sed -e 4a\newLine testfile
a 动作是在匹配的行之后追加字符串,追加的字符串中可以包含换行符(实现追加多行的情况)。
追加一行的话前后都不需要添加换行符 \n,只有追加多行时在行与行之间才需要添加换行符(最后一行最后也无需添加,添加的话会多出一个空行)。
man sed 信息:
Append text, which has each embedded newline preceded by a backslash.
例如:
4 行之后添加一行:
sed -e '4 a newline' testfile
4 行之后追加 2 行:
sed -e '4 a newline\nnewline2' testfile
4 行之后追加 3 行(2 行文字和 1 行空行)
sed -e '4 a newline\nnewline2\n' testfile
4 行之后追加 1 行空行:
#错误:sed -e '4 a \n' testfilesed -e '4 a \ ' testfile 实际上
实际上是插入了一个含有一个空格的行,插入一个完全为空的空行没有找到方法(不过应该没有这个需求吧,都要插入行了插入空行干嘛呢?)
添加空行:
# 可以添加一个完全为空的空行sed '4 a \\'# 可以添加两个完全为空的空行sed '4 a \\n'
8.3 grep
Linux grep 命令用于查找文件里符合条件的字符串。
grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
语法
grep [-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]
参数:
-a 또는 —text: 이진 데이터를 무시하지 마세요.
-A<행 수 표시> 또는 —after-context=<행 수 표시> : 템플릿 스타일에 맞는 열을 표시하고 행 뒤의 내용을 표시합니다. .
-b 또는 —byte-offset: 스타일과 일치하는 줄을 표시하기 전에 줄의 첫 번째 문자 번호를 나타냅니다.
-B<줄 수 표시> 또는 —before-context=<줄 수 표시> : 스타일에 맞는 줄을 표시하는 것 외에도 줄 앞에 내용을 표시합니다.
-c 또는 —count: 스타일과 일치하는 열 수를 셉니다.
-C<줄 수 표시> 또는 —context=<줄 수 표시> 또는 -<줄 수 표시> : 스타일에 맞는 줄을 표시하는 것 외에도 해당 줄 앞과 뒤의 내용입니다.
-d
또는 —directories= : 이 매개변수는 검색할 파일이 아닌 디렉터리를 지정할 때 사용해야 합니다. 그렇지 않으면 grep 명령이 정보를 보고하고 작업을 중지합니다. .-e<템플릿 스타일> 또는 —regexp=<템플릿 스타일> : 파일 콘텐츠 검색 스타일로 문자열을 지정합니다.
-E 또는 —extended-regexp: 확장 정규식 스타일을 사용합니다.
-f
또는 -file= : grep이 규칙 조건을 충족하는 파일 콘텐츠를 찾을 수 있도록 하나 이상의 규칙 패턴이 포함된 규칙 파일을 지정합니다. 형식은 한 줄에 하나의 규칙 스타일입니다.-F 또는 —fixed-regexp: 스타일을 고정 문자열 목록으로 처리합니다.
-G 또는 —basic-regexp: 스타일을 일반 표기법으로 사용합니다.
-h 또는 —no-filename: 스타일과 일치하는 행을 표시하기 전에 해당 행이 속한 파일 이름을 표시하지 마십시오.
-H 또는 —with-filename: 스타일과 일치하는 줄을 표시하기 전에 해당 줄이 속한 파일 이름을 나타냅니다.
-i 또는 —ignore-case: 대소문자 차이를 무시합니다.
-l 或 —file-with-matches : 列出文件内容符合指定的样式的文件名称。
-L 或 —files-without-match : 列出文件内容不符合指定的样式的文件名称。
-n 或 —line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
-o 或 —only-matching : 只显示匹配PATTERN 部分。
-q 或 —quiet或–silent : 不显示任何信息。
-r 或 —recursive : 此参数的效果和指定”-d recurse”参数相同。
-s 或 —no-messages : 不显示错误信息。
-v 或 —revert-match : 显示不包含匹配文本的所有行。
-V 或 —version : 显示版本信息。
-w 或 —word-regexp : 只显示全字符合的列。
-x —line-regexp : 只显示全列符合的列。
-y : 此参数的效果和指定”-i”参数相同。
实例
1、在当前目录中,查找后缀有 file 字样的文件中包含 test 字符串的文件,并打印出该字符串的行。此时,可以使用如下命令:
grep test *file
结果如下所示:
$ grep test test* #查找前缀有“test”的文件包含“test”字符串的文件 testfile1:This a Linux testfile! #列出testfile1 文件中包含test字符的行 testfile_2:This is a linux testfile! #列出testfile_2 文件中包含test字符的行 testfile_2:Linux test #列出testfile_2 文件中包含test字符的行
2、以递归的方式查找符合条件的文件。例如,查找指定目录/etc/acpi 及其子目录(如果存在子目录的话)下所有文件中包含字符串”update”的文件,并打印出该字符串所在行的内容,使用的命令为:
grep -r update /etc/acpi
输出结果如下:
$ grep -r update /etc/acpi #以递归的方式查找“etc/acpi” #下包含“update”的文件 /etc/acpi/ac.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of IO.) Rather than /etc/acpi/resume.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of IO.) Rather than /etc/acpi/events/thinkpad-cmos:action=/usr/sbin/thinkpad-keys--update
3、反向查找。前面各个例子是查找并打印出符合条件的行,通过”-v”参数可以打印出不符合条件行的内容。
查找文件名中包含 test 的文件中不包含test 的行,此时,使用的命令为:
grep -v test *test*
结果如下所示:
$ grep-v test* #查找文件名中包含test 的文件中不包含test 的行 testfile1:helLinux! testfile1:Linis a free Unix-type operating system. testfile1:Lin testfile_1:HELLO LINUX! testfile_1:LINUX IS A FREE UNIX-TYPE OPTERATING SYSTEM. testfile_1:THIS IS A LINUX TESTFILE! testfile_2:HELLO LINUX! testfile_2:Linux is a free unix-type opterating system.
위 내용은 리눅스 명령 목록의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7515
7515
 15
1378
52
79
11
53
19
19
64
15
1378
52
79
11
53
19
19
64

 아파치를 시작하는 방법
Apr 13, 2025 pm 01:06 PM
아파치를 시작하는 방법
Apr 13, 2025 pm 01:06 PM
Apache를 시작하는 단계는 다음과 같습니다. Apache 설치 (명령 : Sudo apt-get Apache2를 설치하거나 공식 웹 사이트에서 다운로드) 시작 apache (linux : sudo systemctl start : windes (선택 사항, Linux : Sudo SystemCtl
 Apache80 포트가 점유 된 경우해야 할 일
Apr 13, 2025 pm 01:24 PM
Apache80 포트가 점유 된 경우해야 할 일
Apr 13, 2025 pm 01:24 PM
Apache 80 포트가 점유되면 솔루션은 다음과 같습니다. 포트를 차지하고 닫는 프로세스를 찾으십시오. 방화벽 설정을 확인하여 Apache가 차단되지 않았는지 확인하십시오. 위의 방법이 작동하지 않으면 Apache를 재구성하여 다른 포트를 사용하십시오. Apache 서비스를 다시 시작하십시오.
 Debian Readdir의 성능을 최적화하는 방법
Apr 13, 2025 am 08:48 AM
Debian Readdir의 성능을 최적화하는 방법
Apr 13, 2025 am 08:48 AM
Debian Systems에서 ReadDir 시스템 호출은 디렉토리 내용을 읽는 데 사용됩니다. 성능이 좋지 않은 경우 다음과 같은 최적화 전략을 시도해보십시오. 디렉토리 파일 수를 단순화하십시오. 대규모 디렉토리를 가능한 한 여러 소규모 디렉토리로 나누어 읽기마다 처리 된 항목 수를 줄입니다. 디렉토리 컨텐츠 캐싱 활성화 : 캐시 메커니즘을 구축하고 정기적으로 캐시를 업데이트하거나 디렉토리 컨텐츠가 변경 될 때 캐시를 업데이트하며 readDir로 자주 호출을 줄입니다. 메모리 캐시 (예 : Memcached 또는 Redis) 또는 로컬 캐시 (예 : 파일 또는 데이터베이스)를 고려할 수 있습니다. 효율적인 데이터 구조 채택 : 디렉토리 트래버스를 직접 구현하는 경우 디렉토리 정보를 저장하고 액세스하기 위해보다 효율적인 데이터 구조 (예 : 선형 검색 대신 해시 테이블)를 선택하십시오.
 Apache 서버를 다시 시작하는 방법
Apr 13, 2025 pm 01:12 PM
Apache 서버를 다시 시작하는 방법
Apr 13, 2025 pm 01:12 PM
Apache 서버를 다시 시작하려면 다음 단계를 따르십시오. Linux/MacOS : Sudo SystemCTL 실행 Apache2를 다시 시작하십시오. Windows : Net Stop Apache2.4를 실행 한 다음 Net Start Apache2.4를 시작하십시오. Netstat -A |를 실행하십시오 서버 상태를 확인하려면 Findstr 80.
 데비안 syslog를 배우는 방법
Apr 13, 2025 am 11:51 AM
데비안 syslog를 배우는 방법
Apr 13, 2025 am 11:51 AM
이 안내서는 데비안 시스템에서 syslog를 사용하는 방법을 배우도록 안내합니다. Syslog는 로깅 시스템 및 응용 프로그램 로그 메시지를위한 Linux 시스템의 핵심 서비스입니다. 관리자가 시스템 활동을 모니터링하고 분석하여 문제를 신속하게 식별하고 해결하는 데 도움이됩니다. 1. syslog에 대한 기본 지식 syslog의 핵심 기능에는 다음이 포함됩니다. 로그 메시지 중앙 수집 및 관리; 다중 로그 출력 형식 및 대상 위치 (예 : 파일 또는 네트워크) 지원; 실시간 로그보기 및 필터링 기능 제공. 2. Syslog 설치 및 구성 (RSYSLOG 사용) Debian 시스템은 기본적으로 RSYSLOG를 사용합니다. 다음 명령으로 설치할 수 있습니다 : sudoaptupdatesud
 Apache를 시작할 수없는 문제를 해결하는 방법
Apr 13, 2025 pm 01:21 PM
Apache를 시작할 수없는 문제를 해결하는 방법
Apr 13, 2025 pm 01:21 PM
다음과 같은 이유로 Apache가 시작할 수 없습니다. 구성 파일 구문 오류. 다른 응용 프로그램 포트와 충돌합니다. 권한 문제. 기억이 없습니다. 프로세스 교착 상태. 데몬 실패. Selinux 권한 문제. 방화벽 문제. 소프트웨어 충돌.
 인터넷은 Linux에서 실행됩니까?
Apr 14, 2025 am 12:03 AM
인터넷은 Linux에서 실행됩니까?
Apr 14, 2025 am 12:03 AM
인터넷은 단일 운영 체제에 의존하지 않지만 Linux는 이에 중요한 역할을합니다. Linux는 서버 및 네트워크 장치에서 널리 사용되며 안정성, 보안 및 확장 성으로 인기가 있습니다.
 아파치 취약성을 수정하는 방법
Apr 13, 2025 pm 12:54 PM
아파치 취약성을 수정하는 방법
Apr 13, 2025 pm 12:54 PM
Apache 취약점을 수정하는 단계는 다음과 같습니다. 1. 영향을받는 버전을 결정합니다. 2. 보안 업데이트를 적용합니다. 3. Apache를 다시 시작하십시오. 4. 수정을 확인하십시오. 5. 보안 기능을 활성화합니다.
