

차세대 모니터링 시스템으로 알려진, 얼마나 강력한지 한번 보시죠!

Prometheus는 시계열 데이터베이스를 기반으로 하는 오픈 소스 모니터링 및 경보 시스템입니다. Prometheus에 관해 말하자면 비디오 공유를 위한 YouTube와 유사한 온라인 음악 공유 플랫폼인 SoundCloud를 언급해야 합니다. 수백 또는 수천 개의 서비스가 등장하는 마이크로서비스 아키텍처의 길로 점점 더 나아가면서 전통적인 모니터링 시스템인 StatsD 및 Graphite를 사용하는 데에는 많은 제한이 있습니다.
그래서 그들은 2012년에 새로운 모니터링 시스템을 개발하기 시작했습니다. Prometheus의 원저자는 2012년에 SoundCloud에 합류한 Matt T. Proud입니다. 실제로 Matt는 SoundCloud에 합류하기 전에 Google에서 근무하면서 Google의 클러스터 관리자인 Borg와 모니터링 시스템인 Borgmon에서 영감을 얻어 오픈 소스를 개발했습니다. 소스 모니터링 시스템 Prometheus는 많은 Google 프로젝트와 마찬가지로 Go를 사용하는 프로그래밍 언어입니다.
분명히 마이크로서비스 아키텍처 모니터링 시스템을 위한 솔루션으로서 Prometheus는 컨테이너와도 분리될 수 없습니다. 2006년 8월 9일, Eric Schmidt는 Search Engine Conference에서 처음으로 클라우드 컴퓨팅(Cloud Computing) 개념을 제안했습니다. 이후 10년 동안 클라우드 컴퓨팅의 발전은 급속도로 이루어졌습니다.
2013년 Pivotal의 Matt Stine은 기업이 신속하고 지속적이며 안정적으로 소프트웨어를 확장할 수 있도록 돕기 위해 마이크로서비스 아키텍처, DevOps 및 민첩한 인프라로 구성된 Cloud Native의 개념을 제안했습니다.
클라우드 컴퓨팅 인터페이스와 관련 표준을 통일하기 위해 2015년 7월 리눅스재단 산하 CNCF(Cloud Native Computing Foundation)가 탄생했습니다. CNCF에 처음으로 합류한 프로젝트는 구글의 쿠버네티스(Kubernetes)였으며, 프로메테우스(Prometheus)가 두 번째로 합류했다(2016년).
1. Prometheus 개요
SoundCloud의 공식 블로그에서 새로운 모니터링 시스템인 Prometheus: Monitoring at SoundCloud를 개발해야 하는 이유에 대한 기사를 찾을 수 있습니다. 이 기사에서 그들이 소개한 모니터링 시스템은 다음과 같습니다. 요구 사항은 다음 네 가지 특성을 충족해야 합니다.
인스턴스, 서비스, 엔드포인트 및 메서드와 같은 차원에 따라 데이터를 마음대로 쪼개고 쪼갤 수 있는 다차원 데이터 모델입니다. 운영 단순성으로 분산 스토리지 백엔드를 설정하거나 환경을 재구성하지 않고도 로컬 워크스테이션에서도 원할 때 언제 어디서나 모니터링 서버를 가동할 수 있습니다. 확장 가능한 데이터 수집 및 분산 아키텍처, 서비스의 많은 인스턴스를 안정적으로 모니터링할 수 있으며 독립 팀은 독립적인 모니터링 서버를 설정할 수 있습니다. 마지막으로 의미 있는 경고(손쉬운 침묵 포함) 및 그래프 작성을 위해 데이터 모델을 활용하는 강력한 쿼리 언어입니다. (대시보드용 및 임시 탐색용).
간단히 말하면 다음과 같은 4가지 특징입니다.
다차원 데이터 모델 편리한 배포 및 유지 관리 유연한 데이터 수집 강력한 쿼리 언어
사실 두 부분으로 구성된 다차원 데이터 모델과 강력한 쿼리 언어 이 기능은 바로 시계열 데이터베이스에 필요한 기능이므로 Prometheus는 모니터링 시스템일 뿐만 아니라 시계열 데이터베이스이기도 합니다. 그렇다면 Prometheus는 왜 기존 시계열 데이터베이스를 백엔드 스토리지로 직접 사용하지 않습니까? SoundCloud는 모니터링 시스템이 시계열 데이터베이스의 특성을 갖기를 원할 뿐만 아니라 배포 및 유지 관리가 매우 쉬워야 하기 때문입니다.
더 인기 있는 시계열 데이터베이스(아래 부록 참조)를 살펴보면 구성 요소가 너무 많거나 외부 종속성이 높습니다. 예를 들어 Druid에는 Historical, MiddleManager, Broker, Coordinator, Overlord, 및 라우터가 있으며 ZooKeeper, Deep Storage(HDFS 또는 S3 등), 메타데이터 저장소(PostgreSQL 또는 MySQL)에 따라 배포 및 유지 관리 비용이 매우 높습니다. Prometheus는 외부 분산 스토리지에 의존하지 않고 독립적으로 배포할 수 있는 분산형 아키텍처를 사용하여 몇 분 안에 모니터링 시스템을 구축할 수 있습니다.
또한 Prometheus 데이터 수집 방법도 매우 유연합니다. 대상의 모니터링 데이터를 수집하려면 먼저 대상에 데이터 수집 구성 요소를 설치해야 합니다. 이는 대상에서 모니터링 데이터를 수집하고 Prometheus가 Pull을 통해 이를 수집할 수 있도록 HTTP 인터페이스를 노출합니다. .데이터, 이는 기존 푸시 모드와 다릅니다.
그러나 Prometheus는 Push Gateway로 데이터를 Push할 수 있는 방법도 제공하며, Prometheus는 Pull을 통해 Push Gateway에서 데이터를 얻습니다. 현재 내보내기는 이미 Docker, HAProxy, StatsD, JMX 등과 같은 대부분의 타사 데이터를 수집할 수 있습니다. 공식 웹사이트에는 내보내기 목록이 있습니다.
Prometheus는 이러한 네 가지 주요 기능 외에도 서비스 검색, 더욱 풍부한 차트 표시, 외부 저장소 사용, 강력한 경보 규칙 및 다양한 알림 방법과 같은 점점 더 많은 고급 기능을 지원하기 시작합니다.
다음 그림은 Prometheus의 전체 아키텍처 다이어그램입니다.
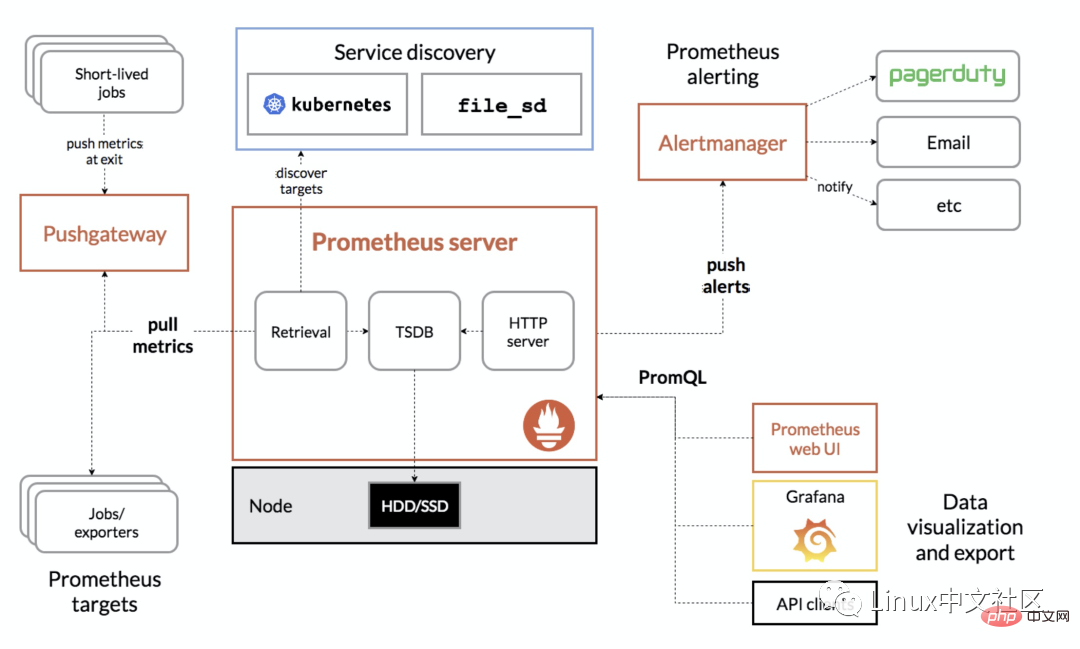
2. Prometheus 서버 설치
Prometheus는 Docker, Ansible, Chef, Puppet, Saltstack 등 다양한 설치 방법을 지원할 수 있습니다. 가장 간단한 두 가지 방법을 소개합니다. 하나는 바로 사용할 수 있는 컴파일된 실행 파일을 직접 사용하는 것이고, 다른 하나는 Docker 이미지를 사용하는 것입니다.
2.1은 기본적으로 작동합니다
먼저 공식 웹사이트의 다운로드 페이지에서 Prometheus의 최신 버전과 다운로드 주소를 얻으세요. 최신 버전은 2.4.3(2018년 10월)입니다. 다운로드하고 압축을 풀려면 다음 명령을 실행하세요.
$ wget https://github.com/prometheus/prometheus/releases/download/v2.4.3/prometheus-2.4.3.linux-amd64.tar.gz $ tar xvfz prometheus-2.4.3.linux-amd64.tar.gz
$ cd prometheus-2.4.3.linux-amd64 $ ./prometheus --version prometheus, version 2.4.3 (branch: HEAD, revision: 167a4b4e73a8eca8df648d2d2043e21bdb9a7449) build user: root@1e42b46043e9 build date: 20181004-08:42:02 go version: go1.11.1
$ ./prometheus --config.file=prometheus.yml
$ sudo docker run -d -p 9090:9090 prom/prometheus
$ sudo docker run -d -p 9090:9090 \ -v ~/docker/prometheus/:/etc/prometheus/ \ prom/prometheus
위치에 넣습니다. 이 위치는 prometheus가 컨테이너에 로드한 기본 구성 파일 위치입니다. ~/docker/prometheus/prometheus.yml,这样可以方便编辑和查看,通过 -v 参数将本地的配置文件挂载到 /etc/prometheus/
如果我们不确定默认的配置文件在哪,可以先执行上面的不带 -v 参数的命令,然后通过 docker inspect 命名看看容器在运行时默认的参数有哪些(下面的 Args 参数):
$ sudo docker inspect 0c [...] "Id": "0c4c2d0eed938395bcecf1e8bb4b6b87091fc4e6385ce5b404b6bb7419010f46", "Created": "2018-10-15T22:27:34.56050369Z", "Path": "/bin/prometheus", "Args": [ "--config.file=/etc/prometheus/prometheus.yml", "--storage.tsdb.path=/prometheus", "--web.console.libraries=/usr/share/prometheus/console_libraries", "--web.console.templates=/usr/share/prometheus/consoles" ], [...]
2.3 配置 Prometheus
正如上面两节看到的,Prometheus 有一个配置文件,通过参数 <span style="outline: 0px;color: rgb(0, 0, 0);">--config.file</span> 来指定,配置文件格式为 YAML。我们可以打开默认的配置文件 <span style="outline: 0px;color: rgb(0, 0, 0);">prometheus.yml</span> 看下里面的内容:
/etc/prometheus $ cat prometheus.yml # my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090']
Prometheus 默认的配置文件分为四大块:
전역 블록: scrape_interval은 방법을 나타냅니다. 긴 Prometheus는 Fetch 데이터를 한 번 사용합니다.evaluation_interval은 경보 규칙이 감지되는 빈도를 나타냅니다. ;alerting 块:关于 Alertmanager 的配置,这个我们后面再看; rule_files 块:告警规则,这个我们后面再看; scrape_config 块:这里定义了 Prometheus 要抓取的目标,我们可以看到默认已经配置了一个名称为
prometheus的 job,这是因为 Prometheus 在启动的时候也会通过 HTTP 接口暴露自身的指标数据,这就相当于 Prometheus 自己监控自己,虽然这在真正使用 Prometheus 时没啥用处,但是我们可以通过这个例子来学习如何使用 Prometheus;可以访问http://localhost:9090/metrics查看 Prometheus 暴露了哪些指标;
scrape_interval 表示 Prometheus 多久抓取一次数据,evaluation_interval 表示多久检测一次告警规则;三、学习 PromQL
通过上面的步骤安装好 Prometheus 之后,我们现在可以开始体验 Prometheus 了。Prometheus 提供了可视化的 Web UI 方便我们操作,直接访问 http://localhost:9090/
scrape_config block: Prometheus는 여기에 정의되어 있습니다. 캡처된 대상에 대해 prometheus</code > 작업, 이는 Prometheus가 시작될 때 HTTP 인터페이스를 통해 자체 표시기 데이터도 노출하기 때문입니다. 이는 Prometheus 모니터링 자체와 동일합니다. 실제로 Prometheus를 사용할 때는 거의 쓸모가 없지만 이 예를 사용하여 Prometheus 사용 방법을 알아보세요. <code style="margin: 3px;padding: 3px;outline: 0px;font-size: 14px;border-radius: 4px;font-family: "Operator Mono", Consolas를 방문하세요. , 모나코, 멘로 , 고정 폭;단어 나누기: break-all;색상: rgb(155, 110, 35);배경색: rgb(255, 245, 227);">http://localhost:9090/metrics Prometheus가 노출하는 지표를 확인하세요. 🎜
3. PromQL 알아보기
위 단계를 거쳐 Prometheus를 설치하고 나면 이제 Prometheus를 체험해 볼 수 있습니다. Prometheus는 작업을 용이하게 하기 위해 시각적 웹 UI를 제공합니다. http://localhost:9090 /, 기본적으로 그래프 페이지로 이동합니다: 🎜
이 페이지를 처음 방문하면 당황스러울 수 있습니다. 예를 들어 경고는 정의된 모든 경보 규칙을 표시하며 런타임 및 빌드 정보를 포함한 다양한 Prometheus 상태 정보를 볼 수 있습니다. , 명령줄 플래그, 구성, 규칙, 대상, 서비스 검색 등
사실 그래프 페이지는 Prometheus의 가장 강력한 기능입니다. 여기서는 Prometheus에서 제공하는 특수 표현식을 사용하여 모니터링 데이터를 쿼리할 수 있습니다. PromQL을 통해 그래프 페이지의 데이터를 쿼리할 수 있을 뿐만 아니라, Prometheus에서 제공하는 HTTP API를 통해서도 쿼리할 수 있습니다. 조회된 모니터링 데이터는 목록과 그래프의 두 가지 형태로 표시될 수 있습니다(위 그림의 콘솔과 그래프 두 레이블에 해당).
위에서 말했듯이 Prometheus 자체도 그래프 페이지에서 쿼리할 수 있는 많은 모니터링 지표를 노출합니다. 실행 버튼 옆의 드롭다운 상자를 확장하면 많은 지표 이름을 선택할 수 있습니다. 예를 들어, promhttp_metric_handler_requests_total, 이 표시는 /metrics 페이지 방문 횟수. Prometheus는 이 페이지를 사용하여 자체 모니터링 데이터를 캡처합니다. . 콘솔 태그의 쿼리 결과는 다음과 같습니다. promhttp_metric_handler_requests_total,这个指标表示 /metrics 页面的访问次数,Prometheus 就是通过这个页面来抓取自身的监控数据的。在 Console 标签中查询结果如下:

上面在介绍 Prometheus 的配置文件时,可以看到 scrape_interval 参数是 15s,也就是说 Prometheus 每 15s 访问一次 /metrics
scrape_interval 매개변수 즉, Prometheus는 15초마다 한 번씩 액세스합니다. /metrics 페이지를 통과했기 때문에 15초 후에 페이지를 새로 고치면 표시기 값이 자동으로 증가하는 것을 볼 수 있습니다. 이는 그래프 태그에서 더 명확하게 볼 수 있습니다: 🎜🎜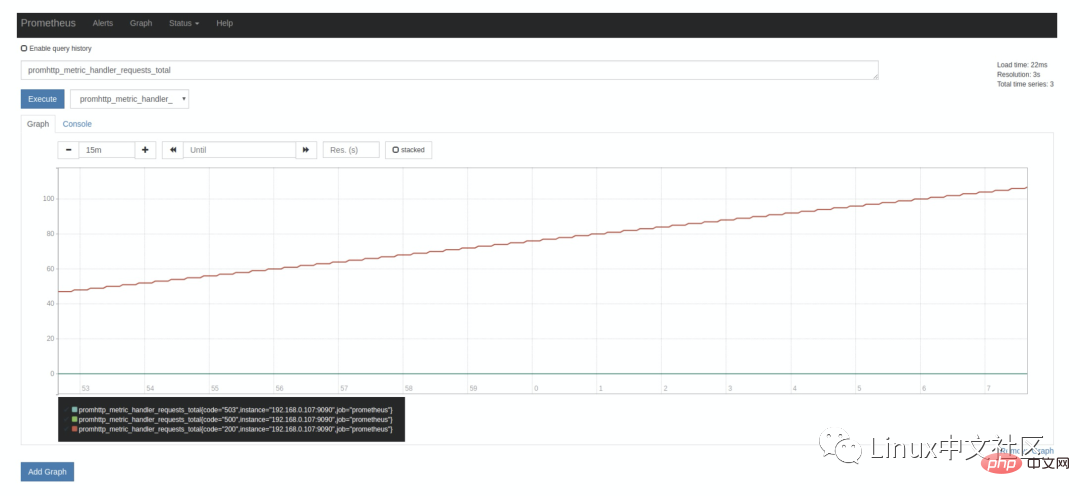
要学习 PromQL,首先我们需要了解下 Prometheus 的数据模型,一条 Prometheus 数据由一个指标名称(metric)和 N 个标签(label,N >= 0)组成的,比如下面这个例子:
promhttp_metric_handler_requests_total{code="200",instance="192.168.0.107:9090",job="prometheus"} 106这条数据的指标名称为 promhttp_metric_handler_requests_total,并且包含三个标签 code、instance 和 job,这条记录的值为 106。上面说过,Prometheus 是一个时序数据库,相同指标相同标签的数据构成一条时间序列。如果以传统数据库的概念来理解时序数据库,可以把指标名当作表名,标签是字段,timestamp 是主键,还有一个 float64 类型的字段表示值(Prometheus 里面所有值都是按 float64 存储)。
이 데이터 모델은 OpenTSDB의 데이터 모델과 유사합니다. 자세한 내용은 공식 웹사이트 문서 데이터 모델을 참조하세요. 또한 지표 및 레이블 이름 지정과 관련하여 공식 웹사이트에 몇 가지 안내 제안이 있습니다. 측정항목 및 레이블 이름 지정을 참조하세요.
프로메테우스에 저장된 데이터는 float64 값이지만, 유형별로 나누면 프로메테우스 데이터는 크게 4가지 카테고리로 나눌 수 있습니다.
Counter Gauge Histogram 요약
카운터는 요청 수, 작업 완료 수, 오류 수 등을 계산하는 데 사용됩니다. 이 값은 항상 증가하고 감소하지 않습니다. 게이지는 온도 변화, 메모리 사용량 변화 등 클 수도 있고 작을 수도 있는 일반적인 값입니다. 히스토그램은 요청 시간 및 응답 크기와 같은 이벤트 규모를 추적하는 데 자주 사용되는 히스토그램 또는 히스토그램입니다.
녹화된 콘텐츠를 그룹화할 수 있고 카운트 및 합계 기능을 제공하는 것이 특징입니다. 요약은 히스토그램과 매우 유사하며 이벤트 발생 규모를 추적하는 데에도 사용됩니다. 차이점은 추적 결과를 백분율로 나눌 수 있는 분위수 기능을 제공한다는 것입니다. 예를 들어, 분위수 값 0.95는 샘플링된 값에 있는 데이터의 95%를 취함을 의미합니다. 자세한 내용은 공식 웹 사이트 문서 메트릭 유형을 참조하세요. 요약 및 히스토그램의 개념은 상대적으로 혼동하기 쉽고 상대적으로 높은 순위의 지표 유형입니다. 여기의 히스토그램 및 요약에 대한 설명을 참조할 수 있습니다.
这四种类型的数据只在指标的提供方作区分,也就是上面说的 Exporter,如果你需要编写自己的 Exporter 或者在现有系统中暴露供 Prometheus 抓取的指标,你可以使用 Prometheus client libraries,这个时候你就需要考虑不同指标的数据类型了。如果你不用自己实现,而是直接使用一些现成的 Exporter,然后在 Prometheus 里查查相关的指标数据,那么可以不用太关注这块,不过理解 Prometheus 的数据类型,对写出正确合理的 PromQL 也是有帮助的。
3.2 PromQL 入门
我们从一些例子开始学习 PromQL,最简单的 PromQL 就是直接输入指标名称,比如:
# 表示 Prometheus 能否抓取 target 的指标,用于 target 的健康检查 up
这条语句会查出 Prometheus 抓取的所有 target 当前运行情况,譬如下面这样:
up{instance="192.168.0.107:9090",job="prometheus"} 1 up{instance="192.168.0.108:9090",job="prometheus"} 1 up{instance="192.168.0.107:9100",job="server"} 1 up{instance="192.168.0.108:9104",job="mysql"} 0也可以指定某个 label 来查询:
up{job="prometheus"}这种写法被称为 Instant vector selectors,这里不仅可以使用 = 号,还可以使用 !=、=~、!~,比如下面这样:
up{job!="prometheus"} up{job=~"server|mysql"} up{job=~"192\.168\.0\.107.+"}=~ 是根据正则表达式来匹配,必须符合 RE2 的语法。
和 Instant vector selectors 相应的,还有一种选择器,叫做 Range vector selectors,它可以查出一段时间内的所有数据:
http_requests_total[5m]
这条语句查出 5 分钟内所有抓取的 HTTP 请求数,注意它返回的数据类型是 Range vector,没办法在 Graph 上显示成曲线图,一般情况下,会用在 Counter 类型的指标上,并和 rate() 或 irate() 函数一起使用(注意 rate 和 irate 的区别)。
搜索公众号Java后端栈回复“面试”,送你一份惊喜礼包。
# 计算的是每秒的平均值,适用于变化很慢的 counter # per-second average rate of increase, for slow-moving counters rate(http_requests_total[5m]) # 计算的是每秒瞬时增加速率,适用于变化很快的 counter # per-second instant rate of increase, for volatile and fast-moving counters irate(http_requests_total[5m])
此外,PromQL 还支持 count、sum、min、max、topk 等 聚合操作,还支持 rate、abs、ceil、floor 等一堆的 内置函数,更多的例子,还是上官网学习吧。如果感兴趣,我们还可以把 PromQL 和 SQL 做一个对比,会发现 PromQL 语法更简洁,查询性能也更高。
3.3 HTTP API
我们不仅仅可以在 Prometheus 的 Graph 页面查询 PromQL,Prometheus 还提供了一种 HTTP API 的方式,可以更灵活的将 PromQL 整合到其他系统中使用,譬如下面要介绍的 Grafana,就是通过 Prometheus 的 HTTP API 来查询指标数据的。实际上,我们在 Prometheus 的 Graph 页面查询也是使用了 HTTP API。
我们看下 Prometheus 的 HTTP API 官方文档,它提供了下面这些接口:
GET /api/v1/query GET /api/v1/query_range GET /api/v1/series GET /api/v1/label/ /values 짐/API/V1/TARGETS Get/API/V1/RULENGETAGET/API/V1/ALERTS GET/API/V1/TARGETS/METADATA -
GET /api/v1/alertmanagers GET /api/v1/status/config GET /api/v1/status/flags Prometheus v2.1부터 몇 가지 새로운 항목이 추가되었습니다. TSDB 관리 인터페이스: POST /api/v1/admin/tsdb/snapshot POST /api/v1/admin/tsdb/delete_series POST /api/v1/admin/tsdb/clean_tombstones
4. Grafana 설치
Prometheus에서 제공하는 웹 UI도 다양한 지표에 대한 좋은 보기를 제공할 수 있지만 이 기능은 매우 간단하며 디버깅에만 적합합니다. 강력한 모니터링 시스템을 구현하려면 다양한 지표를 표시하고 다양한 유형의 프레젠테이션 방법(곡선 차트, 파이 차트, 히트 맵, TopN 등)을 지원하도록 사용자 정의할 수 있는 패널도 필요합니다. 이것이 대시보드 기능입니다.
그래서 Prometheus는 대시보드 시스템 PromDash를 개발했지만 이 시스템은 곧 폐기되었습니다. 관계자들은 Grafana를 사용하여 Prometheus의 지표 데이터를 시각화할 것을 권장하기 시작했습니다. 이는 Grafana가 매우 강력할 뿐만 아니라 완벽하고 원활하게 작동할 수 있기 때문입니다. 프로메테우스와 통합되었습니다.
Grafana는 대규모 측정 데이터를 시각화하기 위한 오픈 소스 시스템으로, 매우 강력한 기능과 매우 아름다운 인터페이스를 갖추고 있어 표시할 데이터와 표시 방법을 구성할 수 있습니다. 패널에서는 Graphite, InfluxDB, OpenTSDB, Elasticsearch, Prometheus 등과 같은 다양한 데이터 소스를 지원하며 많은 플러그인도 지원합니다.
Grafana를 사용하여 Prometheus 표시기 데이터를 표시해 보겠습니다. 먼저 Grafana를 설치하고 가장 간단한 Docker 설치 방법을 사용합니다.
$ docker run -d -p 3000:3000 grafana/grafana
로그인 후 복사运行上面的 docker 命令,Grafana 就安装好了!你也可以采用其他的安装方式,参考 官方的安装文档。安装完成之后,我们访问
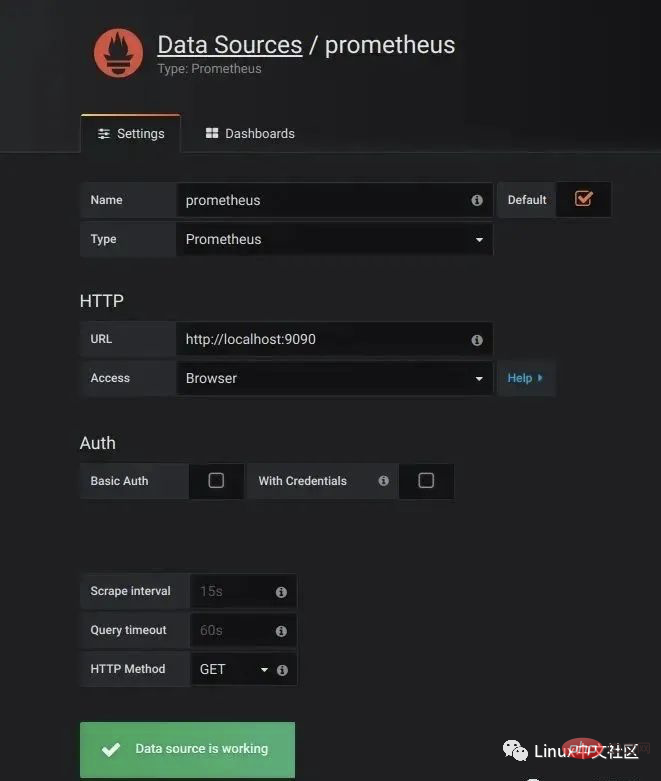
http://localhost:3000/进入 Grafana 的登陆页面,输入默认的用户名和密码(admin/admin)即可。要使用 Grafana,第一步当然是要配置数据源,告诉 Grafana 从哪里取数据,我们点击 Add data source 进入数据源的配置页面:
 图片
图片我们在这里依次填上:
Name: prometheus Type: Prometheus URL: http://localhost:9090 Access: Browser
要注意的是,这里的 Access 指的是 Grafana 访问数据源的方式,有 Browser 和 Proxy 两种方式。Browser 方式表示当用户访问 Grafana 面板时,浏览器直接通过 URL 访问数据源的;而 Proxy 方式表示浏览器先访问 Grafana 的某个代理接口(接口地址是
/api/datasources/proxy/),由 Grafana 的服务端来访问数据源的 URL,如果数据源是部署在内网,用户通过浏览器无法直接访问时,这种方式非常有用。데이터 소스를 구성한 후 Grafana는 기본적으로 사용할 수 있도록 구성된 여러 패널을 제공합니다. 아래 그림에 표시된 것처럼 Prometheus Stats, Prometheus 2.0 Stats 및 Grafana Metrics라는 세 가지 패널이 기본적으로 제공됩니다. 이 패널을 가져와서 사용하려면 가져오기를 클릭하세요.
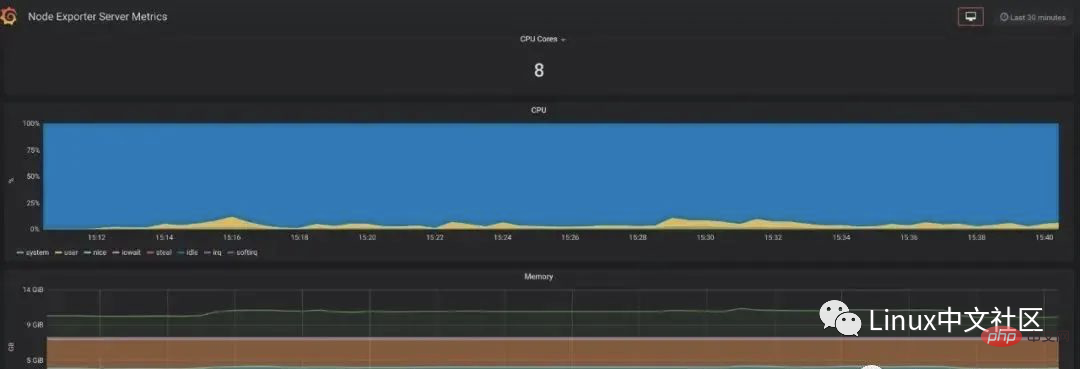
Prometheus 2.0 Stats 패널을 가져오면 다음과 같은 모니터링 패널을 볼 수 있습니다. 회사가 여건이 된다면 대형 모니터를 신청해 벽에 걸고, 이 패널을 대형 화면에 투사해 온라인 시스템의 상태를 실시간으로 관찰할 수 있다는 점은 매우 멋지다고 할 수 있습니다. 5. 내보내기를 사용하여 지표 수집
지금까지 본 것은 실제로 사용되지 않는 일부 지표일 뿐 실제로 프로덕션 환경에서 Prometheus를 사용하려면 종종 필요합니다. 서버 CPU 로드, 메모리 사용량, IO 오버헤드, 들어오고 나가는 네트워크 트래픽 등과 같은 다양한 지표에 주의를 기울이십시오.
위에서 언급했듯이 Prometheus는 지표 데이터를 얻기 위해 Pull 메서드를 사용합니다. Prometheus가 대상에서 데이터를 얻으려면 먼저 대상에 지표 수집 프로그램을 설치하고 이 지표를 쿼리할 수 있는 HTTP 인터페이스를 노출해야 합니다. 수집 프로그램을 수출업체라고 합니다. 다양한 지표에 따라 수집하려면 다양한 수출업체가 필요합니다. 현재 우리가 일반적으로 사용하는 거의 모든 종류의 시스템과 소프트웨어를 포괄하는 다양한 수출업체가 있습니다.
공식 웹사이트에는 일반적으로 사용되는 내보내기 목록이 나열되어 있습니다. 각 내보내기는 포트 충돌을 피하기 위해 포트 규칙을 따릅니다. 즉, 전체 내보내기 포트 목록은 9100부터 시작하여 증가합니다. Kubernetes, Grafana, Etcd, Ceph 등과 같은 일부 소프트웨어 및 시스템은 자체적으로 Prometheus 형식으로 지표 데이터를 노출하는 기능을 제공하기 때문에 내보내기를 설치할 필요가 없다는 점도 주목할 가치가 있습니다.
这一节就让我们来收集一些有用的数据。
5.1 收集服务器指标
首先我们来收集服务器的指标,这需要安装 node_exporter,这个 exporter 用于收集 *NIX 内核的系统,如果你的服务器是 Windows,可以使用 WMI exporter。
和 Prometheus server 一样,node_exporter 也是开箱即用的:
$ wget https://github.com/prometheus/node_exporter/releases/download/v0.16.0/node_exporter-0.16.0.linux-amd64.tar.gz $ tar xvfz node_exporter-0.16.0.linux-amd64.tar.gz $ cd node_exporter-0.16.0.linux-amd64 $ ./node_exporter
로그인 후 복사node_exporter 启动之后,我们访问下
/metrics接口看看是否能正常获取服务器指标:$ curl http://localhost:9100/metrics
로그인 후 복사如果一切 OK,我们可以修改 Prometheus 的配置文件,将服务器加到
scrape_configs中:scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['192.168.0.107:9090'] - job_name: 'server' static_configs: - targets: ['192.168.0.107:9100']
로그인 후 복사修改配置后,需要重启 Prometheus 服务,或者发送
HUP信号也可以让 Prometheus 重新加载配置:$ killall -HUP prometheus
로그인 후 복사在 Prometheus Web UI 的 Status -> Targets 中,可以看到新加的服务器:
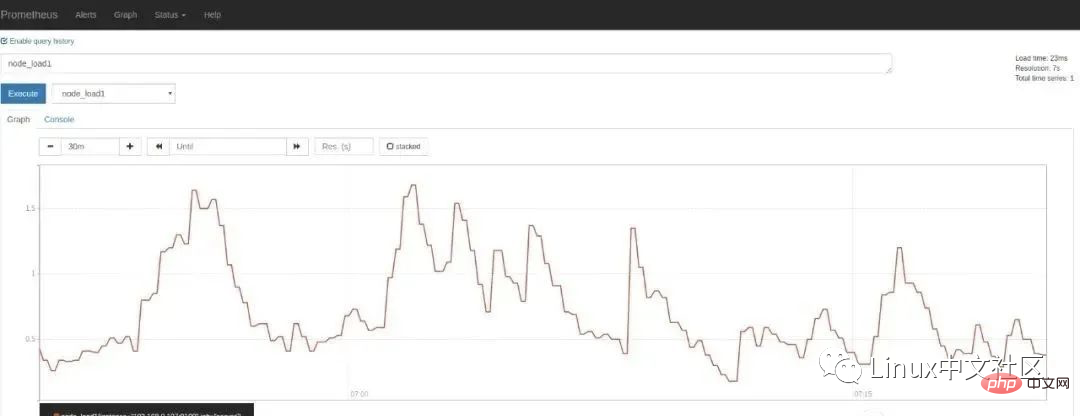
在 Graph 页面的指标下拉框可以看到很多名称以 node 开头的指标,譬如我们输入
node_load1观察服务器负载:如果想在 Grafana 中查看服务器的指标,可以在 Grafana 的 Dashboards 页面 搜索
node exporter,有很多的面板模板可以直接使用,譬如:Node Exporter Server Metrics 或者 Node Exporter Full 等。我们打开 Grafana 的 Import dashboard 页面,输入面板的 URL(https://grafana.com/dashboards/405)或者 ID(405)即可。注意事项
一般情况下,node_exporter 都是直接运行在要收集指标的服务器上的,官方不推荐用 Docker 来运行 node_exporter。如果逼不得已一定要运行在 Docker 里,要特别注意,这是因为 Docker 的文件系统和网络都有自己的 namespace,收集的数据并不是宿主机真实的指标。可以使用一些变通的方法,比如运行 Docker 时加上下面这样的参数:
docker run -d \ --net="host" \ --pid="host" \ -v "/:/host:ro,rslave" \ quay.io/prometheus/node-exporter \ --path.rootfs /host
로그인 후 복사关于 node_exporter 的更多信息,可以参考 node_exporter 的文档 和 Prometheus 的官方指南 Monitoring Linux host metrics with the Node Exporter,另外,Julius Volz 的这篇文章 How To Install Prometheus using Docker on Ubuntu 14.04 也是很好的入门材料。
5.2 收集 MySQL 指标
mysqld_exporter 是 Prometheus 官方提供的一个 exporter,我们首先 下载最新版本 并解压(开箱即用):
$ wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.11.0/mysqld_exporter-0.11.0.linux-amd64.tar.gz $ tar xvfz mysqld_exporter-0.11.0.linux-amd64.tar.gz $ cd mysqld_exporter-0.11.0.linux-amd64/
로그인 후 복사mysqld_exporter 需要连接到 mysqld 才能收集它的指标,可以通过两种方式来设置 mysqld 数据源。第一种是通过环境变量
DATA_SOURCE_NAME,这被称为 DSN(数据源名称),它必须符合 DSN 的格式,一个典型的 DSN 格式像这样:user:password@(host:port)/。$ export DATA_SOURCE_NAME='root:123456@(192.168.0.107:3306)/' $ ./mysqld_exporter
로그인 후 복사另一种方式是通过配置文件,默认的配置文件是
~/.my.cnf,或者通过--config.my-cnf参数指定:$ ./mysqld_exporter --config.my-cnf=".my.cnf"
로그인 후 복사配置文件的格式如下:
$ cat .my.cnf [client] host=localhost port=3306 user=root password=123456
로그인 후 복사如果要把 MySQL 的指标导入 Grafana,可以参考 这些 Dashboard JSON。另外,MySQL 系列面试题和答案全部整理好了,微信搜索互联网架构师,在后台发送:2T,可以在线阅读。
注意事项
这里为简单起见,在 mysqld_exporter 中直接使用了 root 连接数据库,在真实环境中,可以为 mysqld_exporter 创建一个单独的用户,并赋予它受限的权限(PROCESS、REPLICATION CLIENT、SELECT),最好还限制它的最大连接数(MAX_USER_CONNECTIONS)。
CREATE USER 'exporter'@'localhost' IDENTIFIED BY 'password' WITH MAX_USER_CONNECTIONS 3; GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'localhost';
로그인 후 복사5.3 收集 Nginx 指标
官方提供了两种收集 Nginx 指标的方式。另外,Nginx 系列面试题和答案全部整理好了,微信搜索互联网架构师,在后台发送:2T,可以在线阅读。
第一种是 Nginx metric library,这是一段 Lua 脚本(prometheus.lua),Nginx 需要开启 Lua 支持(libnginx-mod-http-lua 模块)。为方便起见,也可以使用 OpenResty 的 OPM(OpenResty Package Manager) 或者 luarocks(The Lua package manager) 来安装。
第二种是 Nginx VTS exporter,这种方式比第一种要强大的多,安装要更简单,支持的指标也更丰富,它依赖于 nginx-module-vts 模块,vts 模块可以提供大量的 Nginx 指标数据,可以通过 JSON、HTML 等形式查看这些指标。Nginx VTS exporter 就是通过抓取
/status/format/json接口来将 vts 的数据格式转换为 Prometheus 的格式。그러나 최신 버전의 nginx-module-vts에 새로운 인터페이스가 추가되었습니다:
/status/format/prometheus, 이 인터페이스는 Prometheus의 형식을 직접 반환할 수 있습니다. 이 지점에서 Prometheus의 영향도 볼 수 있습니다. 곧 Nginx VTS 내보내기가 종료될 것으로 추정됩니다. 확인됩니다)./status/format/prometheus,这个接口可以直接返回 Prometheus 的格式,从这点这也能看出 Prometheus 的影响力,估计 Nginx VTS exporter 很快就要退役了(TODO:待验证)。除此之外,还有很多其他的方式来收集 Nginx 的指标,比如:
또한 다음과 같은 Nginx 표시기를 수집하는 다른 방법이 많이 있습니다:nginx_exporter通过抓取 Nginx 自带的统计页面/nginx_status可以获取一些比较简单的指标(需要开启ngx_http_stub_status_module模块);nginx_request_exporter通过 syslog 协议 收集并分析 Nginx 的 access log 来统计 HTTP 请求相关的一些指标;nginx-prometheus-shiny-exporter和nginx_request_exporter类似,也是使用 syslog 协议来收集 access log,不过它是使用 Crystal 语言 写的。还有vovolie/lua-nginx-prometheusnginx_exporter< /code> Nginx와 함께 제공되는 통계 페이지 <code style="margin: 3px;padding: 3px;outline: 0px;font-size: 14px;border-radius: 4px;font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(155, 110, 35); background-color: rgb(255, 245, 227);">/nginx_status</code > 다음을 수행할 수 있습니다. 비교적 간단한 표시기를 얻습니다( <code style="margin: 3px;padding: 3px;outline: 0px;font-size: 14px;border-radius: 4px;font-family: "Operator Mono", Consolas 를 켜야 함). 모나코, 멘로, 모노스페이스;단어 나누기: 나누기-모두;색상: rgb(155, 110, 35);배경색: rgb(255, 245, 227);">ngx_http_stub_status_module모듈);< 코드 style="margin: 3px;padding: 3px;outline: 0px;font-size: 14px;border-radius: 4px;font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break - all;color: rgb(155, 110, 35); background-color: rgb(255, 245, 227);">nginx_request_exporter syslog 프로토콜을 통해 Nginx 액세스 로그를 수집 및 분석하여 HTTP 요청 관련 통계를 수집합니다 일부 표시기;nginx-prometheus-shiny-exporter및nginx_request_exporter마찬가지로 syslog 프로토콜을 사용하여 액세스 로그를 수집하지만 Crystal 언어로 작성되었습니다. . 그리고vovolie/lua-nginx-prometheusOpenresty, Prometheus, Consul 기반 Grafana는 도메인 이름 및 엔드포인트 수준에서 트래픽 통계를 구현합니다. 필요하거나 관심이 있는 학생들은 설명서를 참고하여 직접 설치하고 체험해 볼 수 있지만 여기서는 하나씩 해보지는 않겠습니다. 🎜5.4 收集 JMX 指标
最后让我们来看下如何收集 Java 应用的指标,Java 应用的指标一般是通过 JMX(Java Management Extensions) 来获取的,顾名思义,JMX 是管理 Java 的一种扩展,它可以方便的管理和监控正在运行的 Java 程序。
JMX Exporter 用于收集 JMX 指标,很多使用 Java 的系统,都可以使用它来收集指标,比如:Kafaka、Cassandra 等。首先我们下载 JMX Exporter:
$ wget https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.3.1/jmx_prometheus_javaagent-0.3.1.jar
로그인 후 복사JMX Exporter 是一个 Java Agent 程序,在运行 Java 程序时通过
-javaagent参数来加载:$ java -javaagent:jmx_prometheus_javaagent-0.3.1.jar=9404:config.yml -jar spring-boot-sample-1.0-SNAPSHOT.jar
로그인 후 복사其中,9404 是 JMX Exporter 暴露指标的端口,
config.yml是 JMX Exporter 的配置文件,它的内容可以 参考 JMX Exporter 的配置说明 。然后检查下指标数据是否正确获取:
$ curl http://localhost:9404/metrics
로그인 후 복사六、告警和通知
至此,我们能收集大量的指标数据,也能通过强大而美观的面板展示出来。不过作为一个监控系统,最重要的功能,还是应该能及时发现系统问题,并及时通知给系统负责人,这就是 Alerting(告警)。
Prometheus 的告警功能被分成两部分:一个是告警规则的配置和检测,并将告警发送给 Alertmanager,另一个是 Alertmanager,它负责管理这些告警,去除重复数据,分组,并路由到对应的接收方式,发出报警。常见的接收方式有:Email、PagerDuty、HipChat、Slack、OpsGenie、WebHook 等。
6.1 配置告警规则
我们在上面介绍 Prometheus 的配置文件时了解到,它的默认配置文件 prometheus.yml 有四大块:
global、alerting、rule_files、scrape_config,其中rule_files块就是告警规则的配置项,alerting 块用于配置 Alertmanager,这个我们下一节再看。现在,先让我们在rule_files块中添加一个告警规则文件:rule_files: - "alert.rules"
로그인 후 복사然后参考 官方文档,创建一个告警规则文件
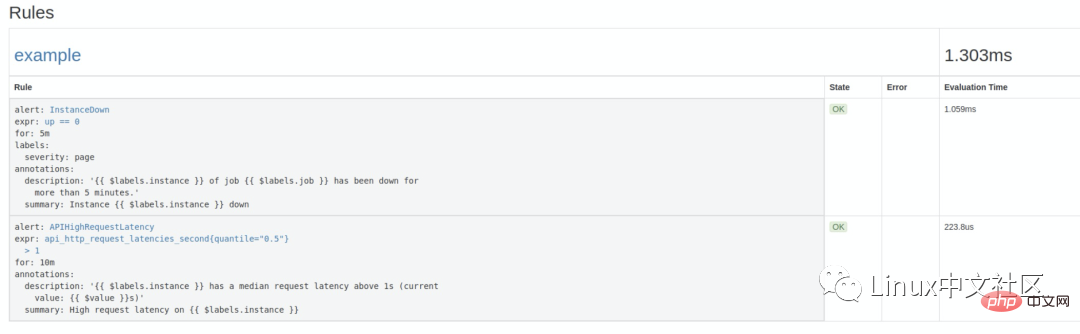
alert.rules:groups: - name: example rules: # Alert for any instance that is unreachable for >5 minutes. - alert: InstanceDown expr: up == 0 for: 5m labels: severity: page annotations: summary: "Instance {{ $labels.instance }} down" description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes." # Alert for any instance that has a median request latency >1s. - alert: APIHighRequestLatency expr: api_http_request_latencies_second{quantile="0.5"} > 1 for: 10m annotations: summary: "High request latency on {{ $labels.instance }}" description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"로그인 후 복사这个规则文件里,包含了两条告警规则:
InstanceDown和APIHighRequestLatency。顾名思义,InstanceDown 表示当实例宕机时(up === 0)触发告警,APIHighRequestLatency 表示有一半的 API 请求延迟大于 1s 时(api_http_request_latencies_second{quantile="0.5"} > 1)触发告警。搜索公众号GitHub猿回复“理财”,送你一份惊喜礼包。
配置好后,需要重启下 Prometheus server,然后访问
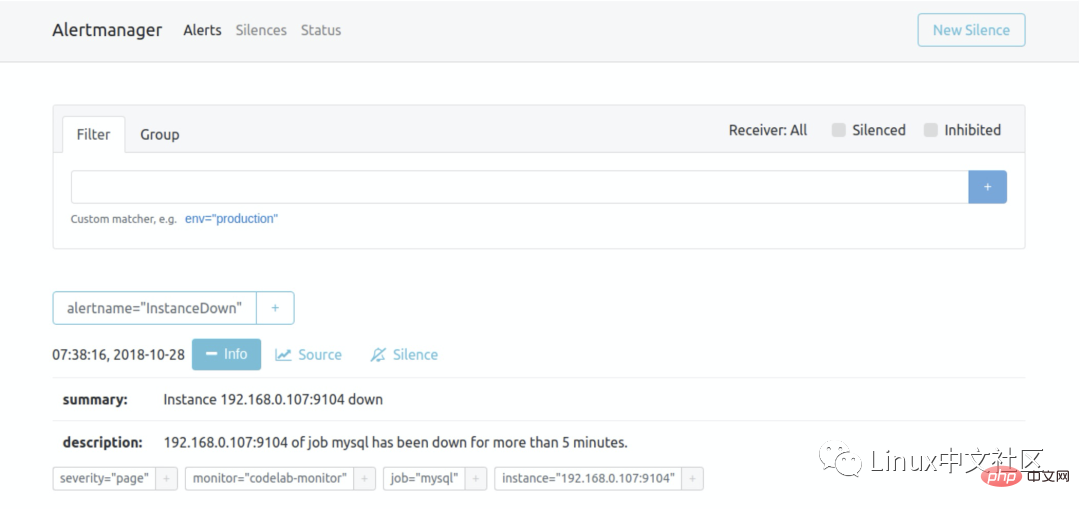
http://localhost:9090/rules可以看到刚刚配置的规则:访问
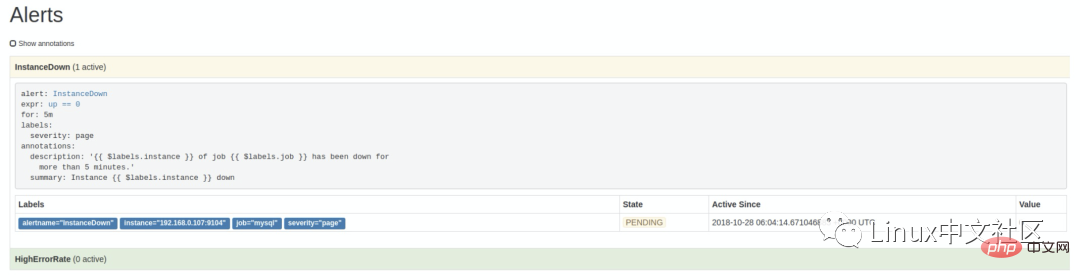
http://localhost:9090/alerts可以看到根据配置的规则生成的告警:这里我们将一个实例停掉,可以看到有一条 alert 的状态是
PENDING,这表示已经触发了告警规则,但还没有达到告警条件。这是因为这里配置的for参数是 5m,也就是 5 分钟后才会触发告警,我们等 5 分钟,可以看到这条 alert 的状态变成了FIRING。6.2 使用 Alertmanager 发送告警通知
虽然 Prometheus 的
<span style="outline: 0px;color: rgb(0, 0, 0);">/alerts</span>页面可以看到所有的告警,但是还差最后一步:触发告警时自动发送通知。这是由 Alertmanager 来完成的,我们首先 下载并安装 Alertmanager,和其他 Prometheus 的组件一样,Alertmanager 也是开箱即用的:$ wget https://github.com/prometheus/alertmanager/releases/download/v0.15.2/alertmanager-0.15.2.linux-amd64.tar.gz $ tar xvfz alertmanager-0.15.2.linux-amd64.tar.gz $ cd alertmanager-0.15.2.linux-amd64 $ ./alertmanager
로그인 후 복사Alertmanager 启动后默认可以通过
http://localhost:9093/来访问,但是现在还看不到告警,因为我们还没有把 Alertmanager 配置到 Prometheus 中,我们回到 Prometheus 的配置文件prometheus.yml,添加下面几行:alerting: alertmanagers: - scheme: http static_configs: - targets: - "192.168.0.107:9093"
로그인 후 복사这个配置告诉 Prometheus,当发生告警时,将告警信息发送到 Alertmanager,Alertmanager 的地址为
http://192.168.0.107:9093。也可以使用命名行的方式指定 Alertmanager:$ ./prometheus -alertmanager.url=http://192.168.0.107:9093
로그인 후 복사这个时候再访问 Alertmanager,可以看到 Alertmanager 已经接收到告警了:
下面的问题就是如何让 Alertmanager 将告警信息发送给我们了,我们打开默认的配置文件
alertmanager.ym:global: resolve_timeout: 5m route: group_by: ['alertname'] group_wait: 10s group_interval: 10s repeat_interval: 1h receiver: 'web.hook' receivers: - name: 'web.hook' webhook_configs: - url: 'http://127.0.0.1:5001/' inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance']
로그인 후 복사参考 官方的配置手册 了解各个配置项的功能,其中 global 块表示一些全局配置;route 块表示通知路由,可以根据不同的标签将告警通知发送给不同的 receiver,这里没有配置 routes 项,表示所有的告警都发送给下面定义的 web.hook 这个 receiver;如果要配置多个路由,可以参考 这个例子:
routes: - receiver: 'database-pager' group_wait: 10s match_re: service: mysql|cassandra - receiver: 'frontend-pager' group_by: [product, environment] match: team: frontend
로그인 후 복사紧接着,receivers 块表示告警通知的接收方式,每个 receiver 包含一个 name 和一个 xxx_configs,不同的配置代表了不同的接收方式,Alertmanager 内置了下面这些接收方式:
email_config hipchat_config pagerduty_config pushover_config slack_config opsgen _config victorops_config wechat_configs webhook_config
while 받기 받는 방법은 여러 가지가 있지만 대부분 중국에서는 거의 사용되지 않습니다. 가장 일반적으로 사용되는 것은
email_config和webhook_config,另外wechat_configs경고를 위해 WeChat 사용을 지원할 수 있다는 것인데, 이는 국가 상황에도 상당히 부합합니다.사실, 다양한 메시징 소프트웨어가 있고, 국가마다 다를 수 있으므로 포괄적인 알람 알림 방법을 제공하기가 어렵습니다. 따라서 Alertmanager는 새로운 기능을 추가하지 않기로 결정했습니다. 하지만 맞춤형 수신 방법을 통합하려면 웹훅을 사용하는 것이 좋습니다. DingTalk를 Prometheus AlertManager WebHook에 연결하는 등의 통합 예시를 참고할 수 있습니다.
7. 자세히 알아보기
지금까지 Prometheus + Grafana + Alertmanager를 결합하면 매우 완벽한 모니터링 시스템을 구축할 수 있습니다. 하지만 실제로 사용해보면 더 많은 문제점을 발견하게 됩니다.
7.1 Service Discovery
Prometheus는 Pull을 통해 모니터링 데이터를 적극적으로 획득하기 때문에 모니터링 노드의 목록을 수동으로 지정해야 하며, 모니터링되는 노드 수가 증가할 경우 노드가 추가될 때마다 구성 파일을 변경해야 합니다. 이는 매우 번거로운 일입니다. 현재 이 문제는 서비스 검색(SD) 메커니즘을 통해 해결되어야 합니다.
Prometheus는 여러 서비스 검색 메커니즘을 지원하며 수집할 대상을 자동으로 얻을 수 있습니다. 포함된 서비스 검색 메커니즘에는 azure, consul, dns, ec2, openstack, file, gce, kubernetes, marathon, triton이 포함됩니다. , Zookeeper(nerve, serverset)의 구성 방법은 매뉴얼의 구성 페이지를 참조하세요. SD 메커니즘은 매우 풍부하다고 할 수 있지만 현재 개발 리소스가 제한되어 있기 때문에 새로운 SD 메커니즘은 더 이상 개발되지 않고 파일 기반 SD 메커니즘만 유지됩니다.
인터넷에는 서비스 검색에 대한 튜토리얼이 많이 있습니다. 예를 들어 Prometheus 공식 블로그인 Advanced Service Discovery in Prometheus 0.14.0의 이 기사에는 이에 대한 비교적 체계적인 소개가 나와 있으며 레이블 변경 구성과 방법에 대해 포괄적으로 설명되어 있습니다. DNS-SRV와 Consul 및 파일을 사용하여 서비스 검색을 수행합니다.
또한 공식 웹사이트에서는 파일 기반 서비스 검색에 대한 소개 예제도 제공합니다. Julius Volz가 작성한 Prometheus 워크샵 입문 튜토리얼에서도 서비스 검색에 DNS-SRV를 사용합니다. 또한 마이크로서비스 시리즈 인터뷰 질문과 답변을 정리했습니다. WeChat에서 인터넷 설계자를 검색하고 백그라운드에서 2T를 보내면 온라인에서 읽을 수 있습니다.
7.2 경고 구성 관리
Prometheus 구성이나 Alertmanager 구성에 관계없이 동적으로 수정할 수 있는 API는 없습니다. 매우 일반적인 시나리오는 Prometheus를 기반으로 사용자 정의 가능한 규칙을 사용하여 경보 시스템을 구축해야 한다는 것입니다. 사용자는 자신의 필요에 따라 페이지에서 경보 규칙을 생성, 수정 또는 삭제하거나 다음과 같이 경보 알림 방법 및 연락 담당자를 수정할 수 있습니다. Prometheus Google 그룹스에서 이 사용자의 질문: API 등을 통해 rule.conf 및 prometheus yml 파일에 경고 규칙을 동적으로 추가하는 방법은 무엇입니까?
그러나 불행히도 Simon Pasquier는 현재 그러한 API가 없으며 앞으로도 그러한 API를 개발할 계획이 없다고 말했습니다. 왜냐하면 그러한 기능은 Puppet, Chef, Ansible, 및 Salt. 이러한 구성 관리 시스템.
7.3 Pushgateway 사용
Pushgateway는 주로 일부 단기 작업을 수집하는 데 사용됩니다. 이러한 작업은 단기간 존재하기 때문에 Prometheus가 Pull에 오기 전에 사라질 수 있습니다. 관계자는 Pushgateway를 언제 사용해야 하는지 잘 설명해줍니다. 요약
이 블로그는 1046102779의 프로메테우스 비공식 중국어 설명서, 송지아양의 전자책 "Prometheus in Action" 등 문서와 블로그를 포함하여 인터넷에 있는 프로메테우스에 관한 수많은 중국어 자료를 참조합니다. , 여기 원저자들에게 찬사를 보냅니다. Prometheus 공식 문서의 미디어 페이지에서도 많은 학습 리소스를 제공합니다.
Prometheus에 관해서는 아직 이 블로그에서 다루지 않은 매우 중요한 부분이 있습니다. 블로그 시작 부분에서 언급했듯이 Prometheus는 Prometheus가 Docker 및 Kubernetes를 사용하여 CNCF에 합류한 두 번째 프로젝트입니다. Docker 및 Kubernetes의 모니터링 시스템으로 점점 더 주류가 되고 있습니다.
Docker 모니터링의 경우 공식 웹사이트의 가이드를 참조할 수 있습니다. cAdvisor를 사용하여 Docker 컨테이너 메트릭 모니터링(cAdvisor를 사용하여 컨테이너를 모니터링하는 방법을 소개). 그러나 Docker는 이제 Prometheus 모니터링도 기본적으로 지원하기 시작했습니다. 공식 문서 Prometheus로 Docker 메트릭 수집; Kubernetes 모니터링과 관련하여 Kubernetes 중국 커뮤니티에는 Promehtheus에 대한 많은 리소스가 있습니다. 또한 전자책 "우아한 자세로 Kubernetes를 모니터링하는 방법"에도 Kubernetes 모니터링에 대한 비교적 포괄적인 소개가 있습니다. .
지난 2년 동안 프로메테우스는 매우 빠르게 발전했고, 커뮤니티도 매우 활발하며, 중국에서 점점 더 많은 사람들이 프로메테우스를 공부하고 있습니다. 마이크로서비스, DevOps, 클라우드 컴퓨팅, 클라우드 네이티브와 같은 개념이 대중화됨에 따라 점점 더 많은 회사가 Docker와 Kubernetes를 사용하여 자체 시스템과 애플리케이션을 구축하기 시작하고 있으며 Nagios 및 Cacti와 같은 오래된 모니터링 시스템이 점점 더 대중화될 것입니다. 적용성이 낮을수록 프로메테우스는 결국 클라우드 환경에 가장 적합한 모니터링 시스템으로 발전할 것이라고 믿습니다.
부록: 시계열 데이터베이스란 무엇인가요?
위에서 언급했듯이 Prometheus는 시계열 데이터베이스를 기반으로 하는 모니터링 시스템입니다. 시계열 데이터베이스는 흔히 TSDB(Time Series Database)로 약칭됩니다. 시계열 데이터베이스의 특성이 모니터링 시스템과 일치하기 때문에 널리 사용되는 많은 모니터링 시스템은 시계열 데이터베이스를 사용하여 데이터를 저장합니다.
추가됨: 빈번한 쓰기 작업이 필요하며 쓰기는 시간순으로 수행됩니다. 삭제됨: 일반적인 상황에서는 시간 블록의 모든 데이터가 직접 삭제됩니다. 변경됨: 작성된 데이터를 업데이트할 필요가 없습니다 확인: 높은 동시성 읽기 작업을 지원해야 합니다. 읽기 작업은 시간에 따라 오름차순 또는 내림차순으로 이루어집니다. 데이터 양이 매우 많고 캐시도 많습니다. 작동하지 않습니다 DB-Engines 시계열 데이터베이스 순위가 있으며 다음은 상위 데이터베이스입니다(2018년 10월):
InfluxDB: https://influxdata.com/
Kdb+: http://kx.com/ Graphite: http://graphiteapp.org/ RRDtool: http://oss.oetiker.ch/rrdtool/ OpenTSDB: http:// opentsdb.net/ Prometheus: https://prometheus.io/ Druid: http://druid.io/ 또한 Liubin은 시계열 데이터베이스에 관한 일련의 기사를 다음 사이트에 썼습니다. 그의 블로그: 시계열 데이터베이스 무술 컨퍼런스를 추천합니다.
 图片
图片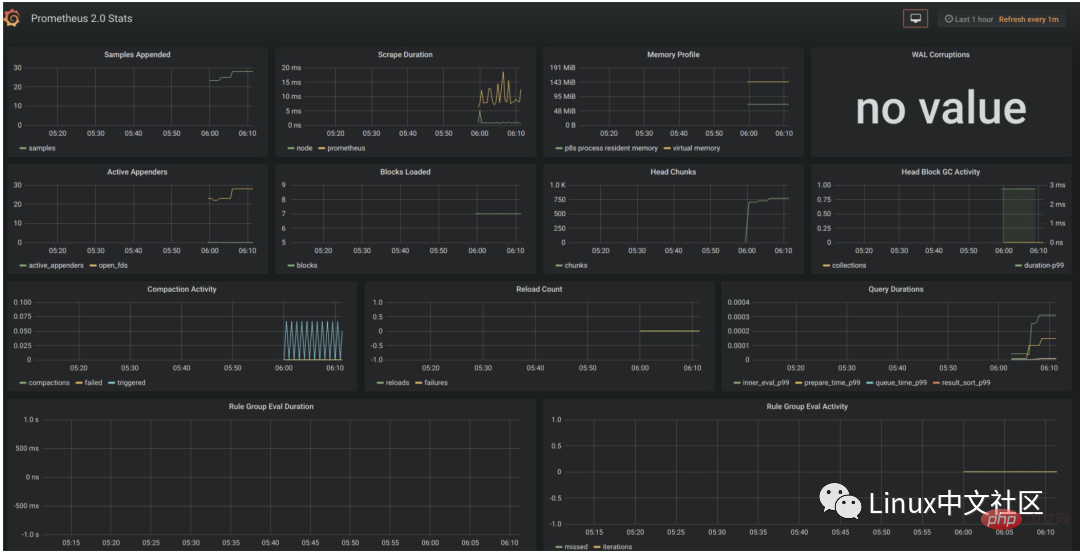
위 내용은 차세대 모니터링 시스템으로 알려진, 얼마나 강력한지 한번 보시죠!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7425
7425
 15
1359
52
76
11
27
19
15
1359
52
76
11
27
19

 차세대 모니터링 시스템으로 알려져 있습니다! 얼마나 멋진지 볼까요?
Aug 03, 2023 pm 02:53 PM
차세대 모니터링 시스템으로 알려져 있습니다! 얼마나 멋진지 볼까요?
Aug 03, 2023 pm 02:53 PM
지난 2년 동안 프로메테우스는 매우 빠르게 발전했고, 커뮤니티도 매우 활발해졌으며, 중국 내에서도 점점 더 많은 사람들이 프로메테우스를 연구하고 있습니다. 마이크로서비스, DevOps, 클라우드 컴퓨팅, 클라우드 네이티브 등의 개념이 인기를 끌면서 점점 더 많은 회사가 Docker와 Kubernetes를 사용하여 자체 시스템과 애플리케이션을 구축하기 시작했습니다.
 C++ 개발을 통해 지능형 보안 모니터링 시스템을 구현하는 방법은 무엇입니까?
Aug 25, 2023 pm 02:48 PM
C++ 개발을 통해 지능형 보안 모니터링 시스템을 구현하는 방법은 무엇입니까?
Aug 25, 2023 pm 02:48 PM
C++ 개발을 통해 지능형 보안 모니터링 시스템을 구현하는 방법은 무엇입니까? 지능형 보안 모니터링 시스템은 현대 사회에서 국민의 생명과 재산의 안전을 보장하는 데 매우 중요한 역할을 합니다. 개발에 C++ 언어를 사용하면 효율성, 안정성 및 유연성이라는 특성을 최대한 활용할 수 있습니다. 이 기사에서는 C++를 사용하여 간단한 지능형 보안 모니터링 시스템을 개발 및 구현하는 방법을 소개하고 해당 코드 예제를 제공합니다. 우선, 지능형 보안 모니터링 시스템의 기능적 요구사항을 명확히 해야 합니다. 기본적인 지능형 보안 모니터링 시스템에는 영상감시, 이동표적 감지 등이 포함되어야 합니다.
 MongoDB 기반의 로그 분석 및 모니터링 시스템 구축 경험 요약
Nov 04, 2023 pm 01:17 PM
MongoDB 기반의 로그 분석 및 모니터링 시스템 구축 경험 요약
Nov 04, 2023 pm 01:17 PM
1. 요구사항 분석 및 시스템 설계 인터넷 및 모바일 기기의 대중화로 인해 다양한 네트워크 애플리케이션 및 시스템의 로그 수가 급격히 증가했습니다. 이러한 대규모 로그를 분석하고 모니터링하면 기업은 시스템 운영을 실시간으로 이해하고 잠재적인 문제를 발견하여 적시에 복구할 수 있으며 시스템의 안정성과 신뢰성을 향상시킬 수 있습니다. 이러한 요구를 충족시키기 위해 우리 팀은 MongoDB를 기반으로 로그 분석 및 모니터링 시스템을 구축했습니다. 이 문서에서는 빌드 프로세스 동안의 경험을 요약합니다. 1.1 로그 분석 및 모니터링 시스템 구축 시 요구사항 분석
 이 기사는 시스템 모니터링에 충분합니다! Zabbix 및 Prometheus와 같은 일반적인 모니터링 튜토리얼
Aug 01, 2023 pm 04:31 PM
이 기사는 시스템 모니터링에 충분합니다! Zabbix 및 Prometheus와 같은 일반적인 모니터링 튜토리얼
Aug 01, 2023 pm 04:31 PM
모니터링은 일반적으로 "제 3의 눈"으로 알려져 있습니다. 속담처럼 모니터링도 없고 운영 및 유지 관리도 없으며 모니터링 상태는 특히 시대에 자명합니다. 운영 및 유지 관리 자동화, 기존 운영 및 유지 관리, DevOps 또는 SRE, 모니터링은 필요한 기술입니다.
 PHP와 Redis를 이용하여 실시간 자판기 모니터링 시스템을 구현하는 방법
Jun 28, 2023 am 08:31 AM
PHP와 Redis를 이용하여 실시간 자판기 모니터링 시스템을 구현하는 방법
Jun 28, 2023 am 08:31 AM
기술의 발전과 사물 인터넷의 대중화로 인해 자판기는 사람들의 생활에 흔한 기기 중 하나가 되었습니다. 그러나 자판기의 모니터링 및 관리는 전통적인 방법을 사용한다면 매우 번거롭고 시간이 많이 걸리는 매우 복잡한 작업입니다. 따라서 본 글에서는 PHP와 Redis를 활용하여 실시간 자판기 모니터링 시스템을 구현하여 자판기의 관리 효율성과 정확성을 향상시키는 방법을 소개하겠습니다. Redis는 데이터를 저장하고 액세스하는 데 사용할 수 있는 인 메모리 데이터 스토리지 시스템입니다. 또한 문자열, 해시 테이블, 목록 및 세트와 같은 다양한 데이터 구조를 지원합니다.
 Go 언어를 사용하여 모니터링 및 경보 시스템을 개발하고 구현하는 방법
Aug 04, 2023 pm 01:10 PM
Go 언어를 사용하여 모니터링 및 경보 시스템을 개발하고 구현하는 방법
Aug 04, 2023 pm 01:10 PM
Go 언어를 사용하여 모니터링 및 경보 시스템을 개발하고 구현하는 방법 소개: 인터넷 기술의 급속한 발전으로 대규모 분산 시스템이 현대 소프트웨어 개발의 주류가 되었으며 그에 따른 과제 중 하나는 시스템 모니터링 및 경보 시스템입니다. 알리다. 시스템의 안정성과 성능을 보장하려면 효율적이고 신뢰할 수 있는 모니터링 및 경보 시스템을 개발하고 구현하는 것이 매우 중요합니다. 이 기사에서는 Go 언어를 사용하여 모니터링 및 경보 시스템을 개발 및 구현하는 방법을 소개하고 관련 코드 예제를 제공합니다. 1. 모니터링 시스템의 설계 및 아키텍처 모니터링 시스템의 주요 구성 요소는 다음과 같습니다.
 효율적인 로그 분석 및 모니터링 시스템 구축: Go 언어 개발 가이드
Nov 20, 2023 pm 02:48 PM
효율적인 로그 분석 및 모니터링 시스템 구축: Go 언어 개발 가이드
Nov 20, 2023 pm 02:48 PM
효율적인 로그 분석 및 모니터링 시스템 구축: Go 언어 개발 가이드 인터넷의 급속한 발전으로 인해 수많은 애플리케이션과 서비스에서는 대용량 로그 데이터를 처리하고 기록해야 합니다. 로그 분석 및 모니터링 시스템은 애플리케이션의 고가용성과 최적화된 성능을 보장하는 핵심 도구 중 하나가 되었습니다. 효율적이고 사용하기 쉬우며 동시성을 지원하는 프로그래밍 언어인 Go 언어는 점차 로그 분석 및 모니터링 시스템 개발에 선택되는 언어가 되고 있습니다. 이 기사에서는 Go 언어를 사용하여 효율적인 로그 분석 및 모니터링 시스템을 구축하는 방법을 소개하고 몇 가지 제안 및 개발 지침을 제공합니다.
 차세대 모니터링 시스템으로 알려진, 얼마나 강력한지 한번 보시죠!
Aug 03, 2023 pm 03:40 PM
차세대 모니터링 시스템으로 알려진, 얼마나 강력한지 한번 보시죠!
Aug 03, 2023 pm 03:40 PM
Prometheus는 시계열 데이터베이스를 기반으로 하는 오픈 소스 모니터링 및 경보 시스템입니다. Prometheus에 관해 말하자면 비디오 공유를 위한 YouTube와 유사한 온라인 음악 공유 플랫폼인 SoundCloud를 언급해야 합니다. 요즘에는 수백, 수천 개의 서비스가 등장하고 있으며, 전통적인 모니터링 시스템인 StatsD와 Graphite를 사용하는 데에는 많은 한계가 있습니다.