
오늘 저는 Python을 사용하여 Jin Yong이 쓴 세계를 탐험하는 Xiao Ming의 독창적인 창작물을 공유하겠습니다!
파이썬으로 소설을 읽으면서 재미와 학습을 동시에 누릴 수 있습니다.
관련된 지식 포인트는 다음과 같습니다:
이 문서에서는 전통적인 일치 논리 분석에서 기계 학습 단어 벡터로 전환하여 전반적인 텍스트 처리를 수행합니다. 분석, 배울 가치가 있고 유용한 정보가 가득합니다.
예전에는 진용 소설 사이트가 많았지만, 대부분 접속이 불가능합니다. 하지만 많은 진용 팬이 존재하면서 새로운 사이트들이 꾸준히 생겨나고 있습니다. 최근 바이두를 통해 접속할 수 있는 진용 소설 사이트를 찾았습니다: aHR0cDovL2ppbnlvbmcxMjMuY29tLw==

데이터 소스 다운로드 주소: https://gitcode.net/as604049322/blog_data
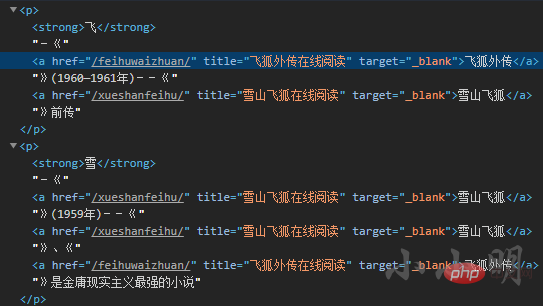
다음은 먼저 이 15권의 이름, 창작 연도 및 해당 작품을 가져옵니다. 링크 작동합니다. 개발자 도구에서 우리가 필요로 하는 노드의 특징은 다음과 같은 생성 날짜 문자열이 뒤따른다는 것입니다.
import requests
from lxml import etree
import pandas as pd
import re
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"Accept-Language": "zh-CN,zh;q=0.9"
}
res = requests.get(base_url, headers=headers)
res.encoding = res.apparent_encoding
html = etree.HTML(res.text)
a_tags = html.xpath("//div[@class='jianjie']/p/a")
data = []
for a_tag in a_tags:
m_obj = re.search("\((\d{4}(?:—\d{4})?年)\)", a_tag.tail)
if m_obj:
data.append((a_tag.text, m_obj.group(1), a_tag.attrib["href"]))
data = pd.DataFrame(data, columns=["名称", "创作时间", "网址"])생성 날짜별로 정렬하여 볼 수 있습니다.
data.sort_values("创作时间", ignore_index=True, inplace=True)
data| 名称 | 创作时间 | 网址 |
|---|---|---|
| 书剑恩仇录 | 1955年 | /shujianenchoulu/ |
| 碧血剑 | 1956年 | /bixuejian/ |
| 射雕英雄传 | 1957—1959年 | /shediaoyingxiongzhuan/ |
| 神雕侠侣 | 1959—1961年 | /shendiaoxialv/ |
| Snow Mountain Flying Fox | 1959 | /xueshanfeihu/ |
| Flying Fox Gaiden | 1960-1 96 1년 | /feihuwaizhuan/ |
| 白马울부짖는 서풍 | 1961 | /baimaxiaoxifeng/ |
| Yitian Slaying the Dragon | 1961 | /yitiantulongji/ |
| 鸳鸯刀 | 1961 | /yuanyangdao/ㅋㅋㅋ | 1963
| /lianchengjue/ | 시아 케 싱 | 1965 |
| /xiakexing/ | Xiaoaojianghu | 1967 |
| /xiaoaojianghu/ | 사슴과 가마솥 | 1969-1972년 |
| /ludingji/ | ||
| Yue Nu Sword | 1970 | /yuenvjian/ |
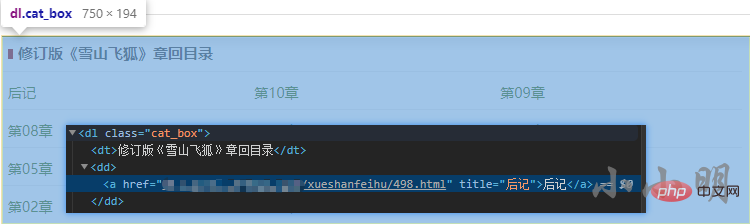
下面看看章节页节点的分布情况,以《雪山飞狐》为例:
from urllib.parse import urljoin
def getTitleAndUrl(url):
url = urljoin(base_url, url)
data = []
res = requests.get(url, headers=headers)
res.encoding = res.apparent_encoding
html = etree.HTML(res.text)
reverse, last_num = False, None
for i, a_tag in enumerate(html.xpath("//dl[@class='cat_box']/dd/a")):
data.append([re.sub("\s+", " ", a_tag.text), a_tag.attrib["href"]])
nums = re.findall("第(\d+)章", a_tag.text)
if nums:
if last_num and int(nums[0]) < last_num:
reverse = True
last_num = int(nums[0])
# 顺序校正并删除后记之后的内容
if reverse:
data.reverse()
return data测试一下:
title2url = getTitleAndUrl(data.query("名称=='雪山飞狐'").网址.iat[0])
title2url[['第01章', '/xueshanfeihu/488.html'], ['第02章', '/xueshanfeihu/489.html'], ['第03章', '/xueshanfeihu/490.html'], ['第04章', '/xueshanfeihu/491.html'], ['第05章', '/xueshanfeihu/492.html'], ['第06章', '/xueshanfeihu/493.html'], ['第07章', '/xueshanfeihu/494.html'], ['第08章', '/xueshanfeihu/495.html'], ['第09章', '/xueshanfeihu/496.html'], ['第10章', '/xueshanfeihu/497.html'], ['后记', '/xueshanfeihu/498.html']]
可以看到章节已经顺利的正序排列。
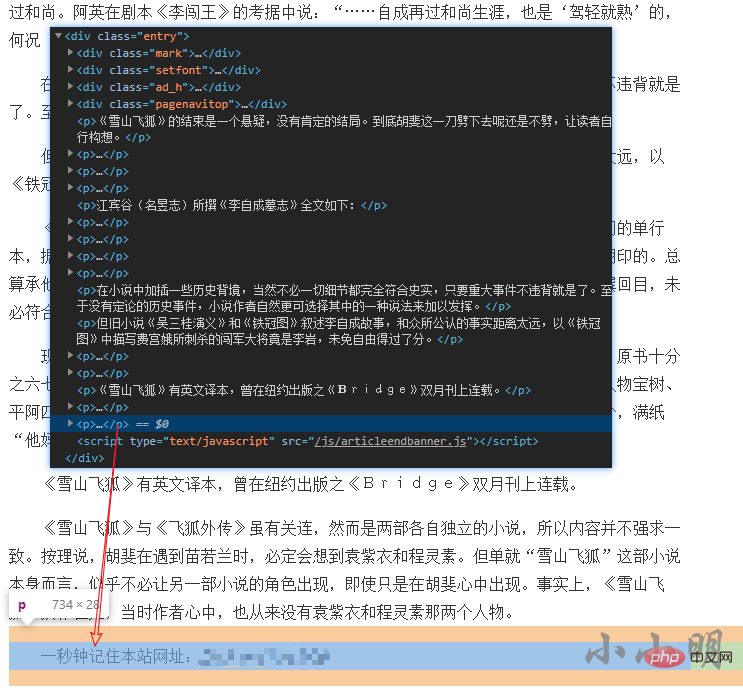
小说每一章的详细页最后一行的数据我们不需要:
def download_page_content(url):
res = requests.get(url, headers=headers)
res.encoding = res.apparent_encoding
html = etree.HTML(res.text)
content = "\n".join(html.xpath("//div[@class='entry']/p/text()")[:-1])
return content然后我们就可以批量下载全部小说了:
import os
def download_one_novel(filename, url):
"下载单部小说"
title2url = getTitleAndUrl(url)
print("创建文件:", filename)
for title, url in title2url:
with open(filename, "a", encoding="u8") as f:
f.write(title)
f.write("\n\n")
print("下载:", title)
content = download_page_content(url)
f.write(content)
f.write("\n\n")
os.makedirs("novels", exist_ok=True)
for row in data.itertuples():
filename = f"novels/{row.名称}.txt"
os.remove(filename)
download_one_novel(filename, row.网址)为了更好分析金庸小说,我们还需要采集金庸小说的人物、武功和门派,个人并没有找到还可以访问相关数据的网站,于是自行收集整理了相关数据:
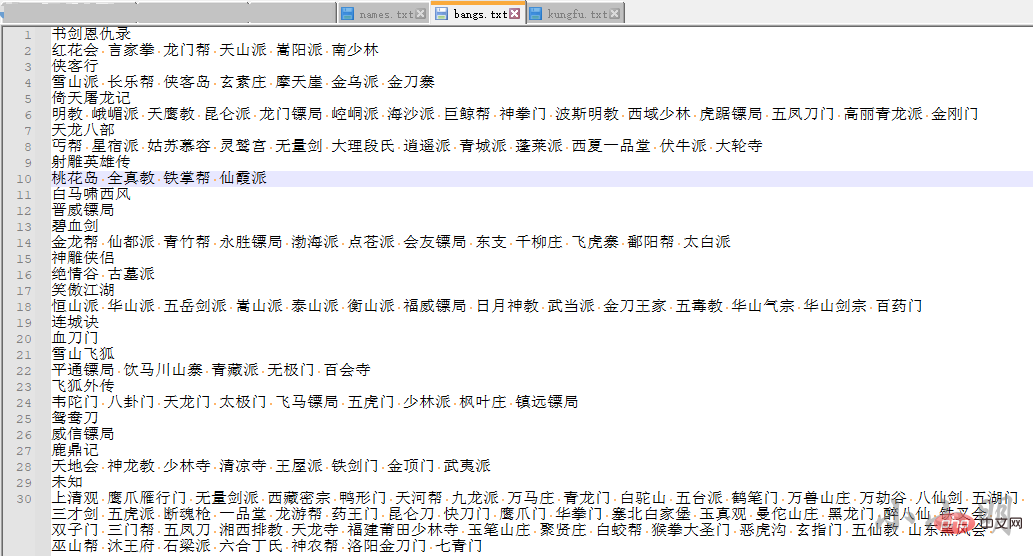
小说1 人物1 人物2 …… 小说2 人物1 人物2 …… 小说3 人物1 人物2 ……
武功:
小说1 武功1 武功2 …… 小说2 武功1 武功2 …… 小说3 武功1 武功2 ……
数据源下载地址:https://gitcode.net/as604049322/blog_data
定义一个加载小说的方法:
def load_novel(novel):
with open(f'novels/{novel}.txt', encoding="u8") as f:
return f.read()首先我们加载人物数据:
with open('data/names.txt',encoding="utf-8") as f:
data = [line.rstrip() for line in f]
novels = data[::2]
names = data[1::2]
novel_names = {k: v.split() for k, v in zip(novels, names)}
del novels, names, data可以预览一下天龙八部中的人物:
print(",".join(novel_names['天龙八部'][:20]))刀白凤,丁春秋,马夫人,马五德,小翠,于光豪,巴天石,不平道人,邓百川,风波恶,甘宝宝,公冶乾,木婉清,包不同,天狼子,太皇太后,王语嫣,乌老大,无崖子,云岛主
下面我们寻找一下每部小说的主角,统计每个人物的出场 次数,显然次数越多主角光环越强,下面我们看看每部小说,出现次数最多的前十个人物:
from collections import Counter
def find_main_charecters(novel, num=10, content=None):
if content is None:
content = load_novel(novel)
count = Counter()
for name in novel_names[novel]:
count[name] = content.count(name)
return count.most_common(num)
for novel in novel_names:
print(novel, dict(find_main_charecters(novel, 10)))书剑恩仇录 {'陈家洛': 2095, '张召重': 760, '徐天宏': 685, '霍青桐': 650, '余鱼同': 605, '文泰来': 601, '骆冰': 594, '周绮': 556, '李沅芷': 521, '陆菲青': 486}
碧血剑 {'袁承志': 3028, '何铁手': 306, '温青': 254, '阿九': 215, '洪胜海': 200, '焦宛儿': 197, '皇太极': 183, '崔秋山': 180, '穆人清': 171, '闵子华': 163}
射雕英雄传 {'郭靖': 5009, '黄蓉': 3650, '洪七公': 1041, '黄药师': 868, '周伯通': 654, '欧阳克': 611, '丘处机': 606, '梅超风': 480, '杨康': 439, '柯镇恶': 431}
神雕侠侣 {'杨过': 5991, '小龙女': 2133, '郭靖': 1431, '黄蓉': 1428, '李莫愁': 1016, '郭芙': 850, '郭襄': 778, '陆无双': 575, '周伯通': 555, '赵志敬': 482}
雪山飞狐 {'胡斐': 230, '曹云奇': 228, '宝树': 225, '苗若兰': 217, '胡一刀': 207, '苗人凤': 129, '刘元鹤': 107, '陶子安': 107, '田青文': 103, '范帮主': 83}
飞狐外传 {'胡斐': 2761, '程灵素': 765, '袁紫衣': 425, '苗人凤': 405, '马春花': 331, '福康安': 287, '赵半山': 287, '田归农': 227, '徐铮': 217, '商宝震': 217}
白马啸西风 {'李文秀': 441, '苏普': 270, '阿曼': 164, '苏鲁克': 147, '陈达海': 106, '车尔库': 99, '李三': 31, '丁同': 29, '霍元龙': 23, '桑斯': 22}
倚天屠龙记 {'张无忌': 4665, '赵敏': 1250, '谢逊': 1211, '张翠山': 1146, '周芷若': 825, '殷素素': 550, '杨逍': 514, '张三丰': 451, '灭绝师太': 431, '小昭': 346}
鸳鸯刀 {'萧中慧': 103, '袁冠南': 82, '卓天雄': 76, '周威信': 74, '林玉龙': 52, '任飞燕': 51, '萧半和': 48, '盖一鸣': 45, '逍遥子': 28, '常长风': 19}
天龙八部 {'段誉': 3372, '萧峰': 1786, '虚竹': 1636, '阿紫': 1150, '乔峰': 1131, '阿朱': 986, '慕容复': 925, '王语嫣': 859, '段正淳': 757, '木婉清': 734}
连城诀 {'狄云': 1433, '水笙': 439, '戚芳': 390, '丁典': 364, '万震山': 332, '万圭': 288, '花铁干': 256, '吴坎': 155, '血刀老祖': 144, '戚长发': 117}
侠客行 {'石破天': 1804, '石清': 611, '丁珰': 446, '白万剑': 446, '丁不四': 343, '谢烟客': 337, '闵柔': 327, '贝海石': 257, '丁不三': 217, '白自在': 199}
笑傲江湖 {'令狐冲': 5838, '岳不群': 1184, '林平之': 926, '岳灵珊': 919, '仪琳': 729, '田伯光': 708, '任我行': 525, '向问天': 513, '左冷禅': 473, '方证': 415}
鹿鼎记 {'韦小宝': 9731, '吴三桂': 949, '双儿': 691, '鳌拜': 479, '陈近南': 472, '方怡': 422, '茅十八': 400, '小桂子': 355, '施琅': 296, '吴应熊': 290}
越女剑 {'范蠡': 121, '阿青': 64, '勾践': 47, '薛烛': 29, '西施': 26, '文种': 23, '风胡子': 7}上述结果用文本展示了每部小说的前5个主角,但是不够直观,下面我用pyecharts的树图展示一下:
from pyecharts import options as opts
from pyecharts.charts import Tree
data = []
for novel in novel_kungfus:
tmp = []
data.append({"name": novel, "children": tmp})
for name, count in find_main_kungfus(novel, 5):
tmp.append({"name": name, "value": count})
c = (
TreeMap()
.add("", data, levels=[
opts.TreeMapLevelsOpts(),
opts.TreeMapLevelsOpts(
color_saturation=[0.3, 0.6],
treemap_itemstyle_opts=opts.TreeMapItemStyleOpts(
border_color_saturation=0.7, gap_width=5, border_width=10
),
upper_label_opts=opts.LabelOpts(
is_show=True, position='insideTopLeft', vertical_align='top'
)
),
])
.set_global_opts(title_opts=opts.TitleOpts(title="金庸小说主角"))
)
c.render_notebook()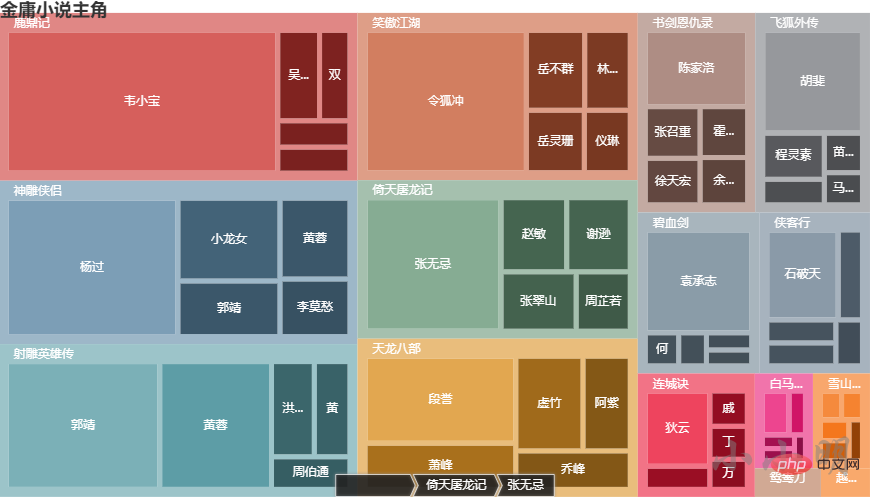
使用上述相同的方法,分析各种武功的出现频次,首先加载武功数据:
with open('data/kungfu.txt', encoding="utf-8") as f:
data = [line.rstrip() for line in f]
novels = data[::2]
kungfus = data[1::2]
novel_kungfus = {k: v.split() for k, v in zip(novels, kungfus)}
del novels, kungfus, data定义计数方法:
def find_main_kungfus(novel, num=10, content=None):
if content is None:
content = load_novel(novel)
count = Counter()
for name in novel_kungfus[novel]:
count[name] = content.count(name)
return count.most_common(num)
for novel in novel_kungfus:
print(novel, dict(find_main_kungfus(novel, 10)))书剑恩仇录 {'芙蓉金针': 16, '柔云剑术': 15, '百花错拳': 13, '追魂夺命剑': 12, '三分剑术': 12, '八卦刀': 10, '铁琵琶手': 9, '无极玄功拳': 9, '甩手箭': 7, '黑沙掌': 7}
侠客行 {'雪山剑法': 46, '金乌刀法': 33, '碧针清掌': 8, '五行六合掌': 8, '梅花拳': 8, '罗汉伏魔神功': 3, '无妄神功': 1, '神倒鬼跌三连环': 1, '上清快剑': 1, '黑煞掌': 1}
倚天屠龙记 {'七伤拳': 98, '乾坤大挪移': 93, '九阳真经': 46, '玄冥神掌': 43, '龙爪手': 24, '金刚伏魔圈': 21, '千蛛万毒手': 18, '幻阴指': 17, '寒冰绵掌': 16, '真武七截阵': 10}
天龙八部 {'六脉神剑': 148, '生死符': 124, '凌波微步': 77, '化功大法': 52, '北冥神功': 36, '般若掌': 36, '火焰刀': 34, '小无相功': 28, '天山六阳掌': 25, '大金刚拳': 24}
射雕英雄传 {'九阴真经': 191, '铁掌': 169, '降龙十八掌': 92, '打狗棒法': 47, '蛤蟆功': 39, '空明拳': 25, '一阳指': 22, '先天功': 14, '双手互搏': 13, '杨家枪法': 13}
碧血剑 {'伏虎掌': 30, '混元功': 23, '两仪剑法': 21, '神行百变': 18, '蝎尾鞭': 12, '破玉拳': 9, '金蛇剑法': 5, '软红蛛索': 4, '混元掌': 4, '斩蛟拳': 4}
神雕侠侣 {'玉女素心剑法': 25, '黯然销魂掌': 19, '五毒神掌': 18, '龙象般若功': 12, '玉箫剑法': 10, '七星聚会': 8, '美女拳法': 8, '天罗地网势': 7, '上天梯': 5, '三无三不手': 4}
笑傲江湖 {'辟邪剑法': 160, '独孤九剑': 80, '吸星大法': 67, '紫霞神功': 36, '易筋经': 33, '嵩山剑法': 33, '华山剑法': 30, '玉女剑十九式': 20, '恒山剑法': 20, '无双无对,宁氏一剑': 13}
连城诀 {'连城剑法': 29, '神照经': 23, '六合拳': 4}
雪山飞狐 {'胡家刀法': 8, '苗家剑法': 7, '龙爪擒拿手': 5, '追命毒龙锥': 2, '大擒拿手': 2, '飞天神行': 1}
飞狐外传 {'西岳华拳': 26, '八极拳': 20, '八仙剑法': 8, '四象步': 6, '燕青拳': 5, '赤尻连拳': 5, '一路华拳': 4, '金刚拳': 3, '毒砂掌': 3, '四门刀法': 2}
鸳鸯刀 {'夫妻刀法': 17, '呼延十八鞭': 6, '震天三十掌': 1}
鹿鼎记 {'化骨绵掌': 24, '拈花擒拿手': 12, '大慈大悲千叶手': 11, '沐家拳': 11, '八卦游龙掌': 10, '少林长拳': 7, '金刚护体神功': 5, '波罗蜜手': 4, '散花掌': 3, '金刚神掌': 2}每部小说频次前5的武功可视化:
from pyecharts import options as opts
from pyecharts.charts import Tree
data = []
for novel in novel_kungfus:
tmp = []
data.append({"name": novel, "children": tmp})
for name, count in find_main_kungfus(novel, 5):
tmp.append({"name": name, "value": count})
c = (
TreeMap()
.add("", data, levels=[
opts.TreeMapLevelsOpts(),
opts.TreeMapLevelsOpts(
color_saturation=[0.3, 0.6],
treemap_itemstyle_opts=opts.TreeMapItemStyleOpts(
border_color_saturation=0.7, gap_width=5, border_width=10
),
upper_label_opts=opts.LabelOpts(
is_show=True, position='insideTopLeft', vertical_align='top'
)
),
])
.set_global_opts(title_opts=opts.TitleOpts(title="金庸高频武功"))
)
c.render_notebook()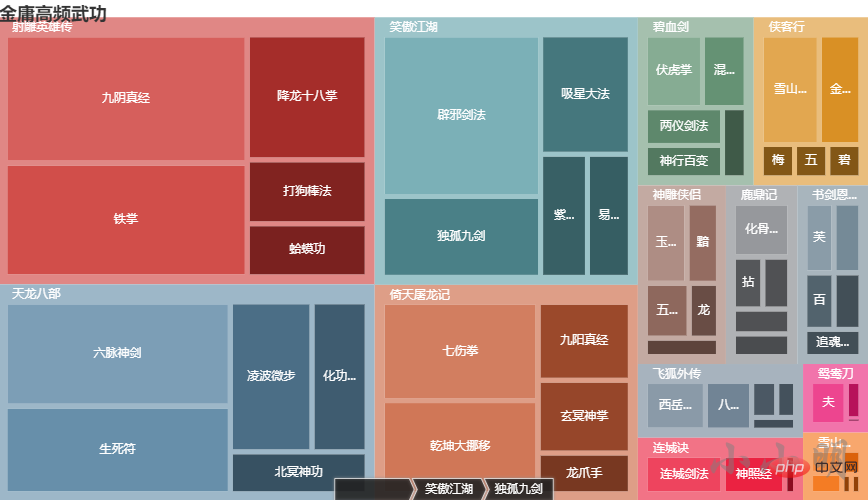
加载数据并获取每部小说前10的门派:
with open('data/bangs.txt', encoding="utf-8") as f:
data = [line.rstrip() for line in f]
novels = data[::2]
bangs = data[1::2]
novel_bangs = {k: v.split() for k, v in zip(novels, bangs) if k != "未知"}
del novels, bangs, data
def find_main_bangs(novel, num=10, content=None):
if content is None:
content = load_novel(novel)
count = Counter()
for name in novel_bangs[novel]:
count[name] = content.count(name)
return count.most_common(num)
for novel in novel_bangs:
print(novel, dict(find_main_bangs(novel, 10)))书剑恩仇录 {'红花会': 394, '言家拳': 7, '龙门帮': 7, '天山派': 5, '嵩阳派': 3, '南少林': 3}
侠客行 {'雪山派': 358, '长乐帮': 242, '侠客岛': 143, '金乌派': 48, '摩天崖': 38, '玄素庄': 37, '金刀寨': 25}
倚天屠龙记 {'明教': 738, '峨嵋派': 289, '天鹰教': 224, '昆仑派': 130, '龙门镖局': 85, '崆峒派': 83, '海沙派': 58, '巨鲸帮': 37, '神拳门': 20, '波斯明教': 16}
天龙八部 {'丐帮': 562, '星宿派': 203, '灵鹫宫': 157, '姑苏慕容': 150, '无量剑': 83, '逍遥派': 77, '大理段氏': 75, '青城派': 65, '蓬莱派': 23, '伏牛派': 8}
射雕英雄传 {'桃花岛': 289, '全真教': 99, '铁掌帮': 87, '仙霞派': 5}
白马啸西风 {'晋威镖局': 5}
碧血剑 {'仙都派': 51, '金龙帮': 47, '青竹帮': 45, '渤海派': 8, '永胜镖局': 6, '点苍派': 4, '飞虎寨': 4, '会友镖局': 2, '东支': 2, '千柳庄': 2}
神雕侠侣 {'绝情谷': 128, '古墓派': 87}
笑傲江湖 {'恒山派': 552, '华山派': 521, '嵩山派': 297, '五岳剑派': 281, '泰山派': 137, '衡山派': 102, '福威镖局': 102, '日月神教': 64, '武当派': 46, '金刀王家': 20}
连城诀 {'血刀门': 24}
雪山飞狐 {'平通镖局': 7, '饮马川山寨': 4, '青藏派': 2, '无极门': 2, '百会寺': 1}
飞狐外传 {'韦陀门': 49, '八卦门': 31, '天龙门': 24, '太极门': 22, '飞马镖局': 19, '五虎门': 16, '少林派': 15, '枫叶庄': 8, '镇远镖局': 2}
鸳鸯刀 {'威信镖局': 5}
鹿鼎记 {'天地会': 542, '神龙教': 161, '少林寺': 155, '清凉寺': 116, '王屋派': 38, '铁剑门': 12, '金顶门': 8, '武夷派': 3}可视化:
from pyecharts import options as opts
from pyecharts.charts import Tree
data = []
for novel in novel_bangs:
tmp = []
data.append({"name": novel, "children": tmp})
for name, count in find_main_bangs(novel, 5):
tmp.append({"name": name, "value": count})
c = (
TreeMap()
.add("", data, levels=[
opts.TreeMapLevelsOpts(),
opts.TreeMapLevelsOpts(
color_saturation=[0.3, 0.6],
treemap_itemstyle_opts=opts.TreeMapItemStyleOpts(
border_color_saturation=0.7, gap_width=5, border_width=10
),
upper_label_opts=opts.LabelOpts(
is_show=True, position='insideTopLeft', vertical_align='top'
)
),
])
.set_global_opts(title_opts=opts.TitleOpts(title="金庸高频门派"))
)
c.render_notebook()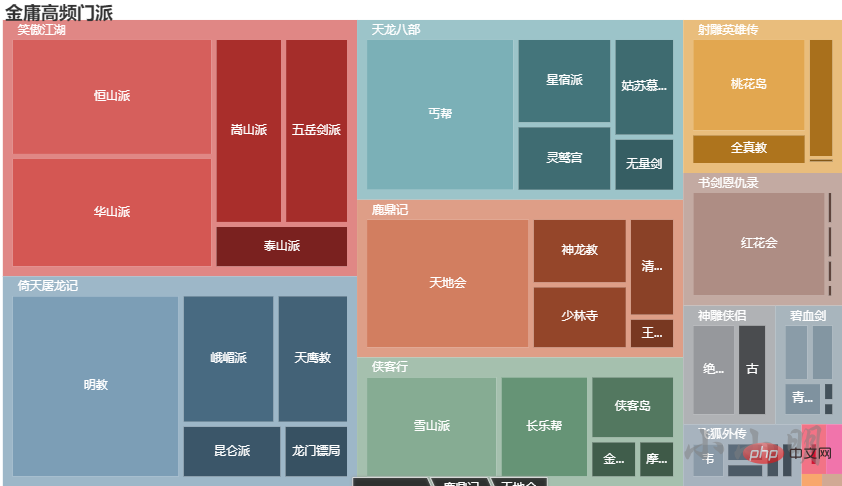
from pyecharts.charts import Tree
c = (
Tree()
.add("", [{"name": "门派", "children": data}], layout="radial")
)
c.render_notebook()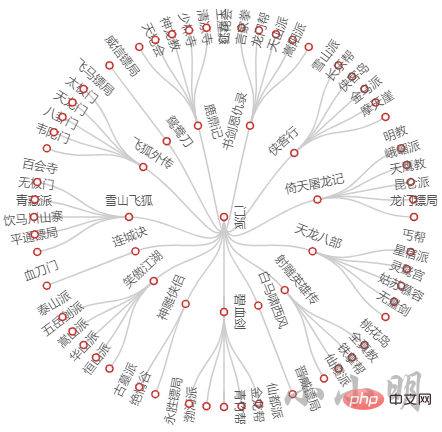
下面我们编写一个函数,输入一部小说名,可以输出其最高频的主角、武功和门派:
from pyecharts import options as opts
from pyecharts.charts import Bar
def show_top10(novel):
content = load_novel(novel)
charecters = find_main_charecters(novel, 10, content)[::-1]
k, v = map(list, zip(*charecters))
c = (
Bar(init_opts=opts.InitOpts("720px", "320px"))
.add_xaxis(k)
.add_yaxis("", v)
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(title_opts=opts.TitleOpts(title=f"{novel}主角"))
)
display(c.render_notebook())
kungfus = find_main_kungfus(novel, 10, content)[::-1]
k, v = map(list, zip(*kungfus))
c = (
Bar(init_opts=opts.InitOpts("720px", "320px"))
.add_xaxis(k)
.add_yaxis("", v)
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(title_opts=opts.TitleOpts(title=f"{novel}功夫"))
)
display(c.render_notebook())
bangs = find_main_bangs(novel, 10, content)[::-1]
k, v = map(list, zip(*bangs))
c = (
Bar(init_opts=opts.InitOpts("720px", "320px"))
.add_xaxis(k)
.add_yaxis("", v)
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(title_opts=opts.TitleOpts(title=f"{novel}门派"))
)
display(c.render_notebook())例如查看天龙八部:
show_top10("天龙八部")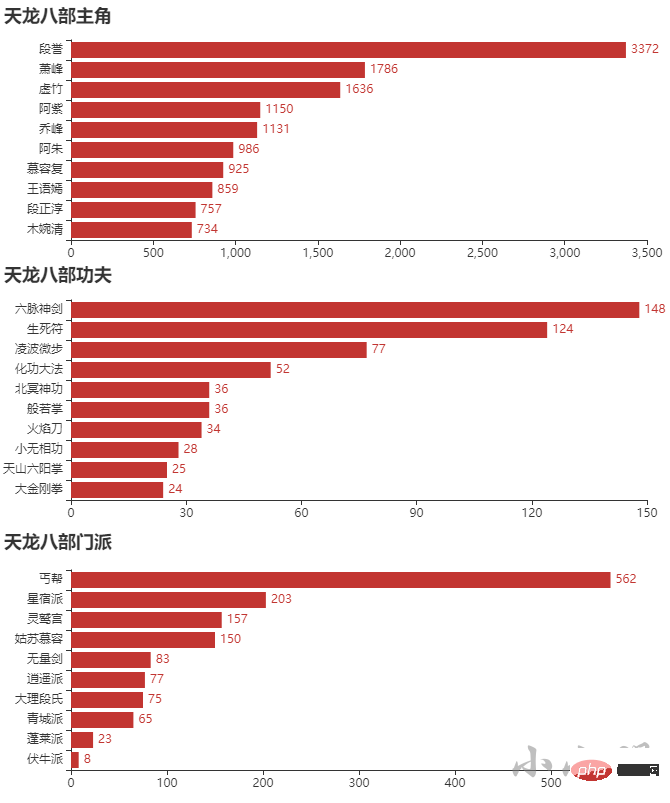
可以先添加所有的人物、武功和门派作为自定义词汇:
import jieba
for novel, names in novel_names.items():
for name in names:
jieba.add_word(name)
for novel, kungfus in novel_kungfus.items():
for kungfu in kungfus:
jieba.add_word(kungfu)
for novel, bangs in novel_bangs.items():
for bang in bangs:
jieba.add_word(bang)这里我们仅提取词长度不小于4的成语、俗语和短语进行分析,以天龙八部这部小说为例:
from IPython.display import Image
import stylecloud
import jieba
import re
# 去除非中文字符
text = re.sub("[^一-龟]+", " ", load_novel("天龙八部"))
words = [word for word in jieba.cut(text) if len(word) >= 4]
stylecloud.gen_stylecloud(" ".join(words),
collocations=False,
font_path=r'C:\Windows\Fonts\msyhbd.ttc',
icon_name='fas fa-square',
output_name='tmp.png')
Image(filename='tmp.png')


我们知道《神雕侠侣》这部小说最重要的主角是杨过和小龙女,我们可能会对于杨过和小龙女之间所发生的故事很感兴趣。如果通过程序快速了解呢?
我们考虑把《神雕侠侣》这部小说每一段中出现杨过及小龙女的段落进行jieba分词并制作词云。
同样我们只看4个字以上的词:
data = []
for line in load_novel("神雕侠侣").splitlines():
if "杨过" in line and "小龙女" in line:
line = re.sub("[^一-龟]+", " ", line)
data.extend(word for word in jieba.cut(line) if len(word) >= 4)
stylecloud.gen_stylecloud(" ".join(data),
collocations=False,
font_path=r'C:\Windows\Fonts\msyhbd.ttc',
icon_name='fas fa-square',
output_name='tmp.png')
Image(filename='tmp.png')
同样的思路看看郭靖和黄蓉:
data = []
for line in load_novel("射雕英雄传").splitlines():
if "郭靖" in line and "黄蓉" in line:
line = re.sub("[^一-龟]+", " ", line)
data.extend(word for word in jieba.cut(line) if len(word) >= 4)
stylecloud.gen_stylecloud(" ".join(data),
collocations=False,
font_path=r'C:\Windows\Fonts\msyhbd.ttc',
icon_name='fas fa-square',
output_name='tmp.png')
Image(filename='tmp.png')
data = []
for line in load_novel("天龙八部").splitlines():
if ("萧峰" in line or "乔峰" in line) and "段誉" in line and "虚竹" in line:
line = re.sub("[^一-龟]+", " ", line)
data.extend(word for word in jieba.cut(line) if len(word) >= 4)
stylecloud.gen_stylecloud(" ".join(data),
collocations=False,
font_path=r'C:\Windows\Fonts\msyhbd.ttc',
icon_name='fas fa-square',
output_name='tmp.png')
Image(filename='tmp.png')
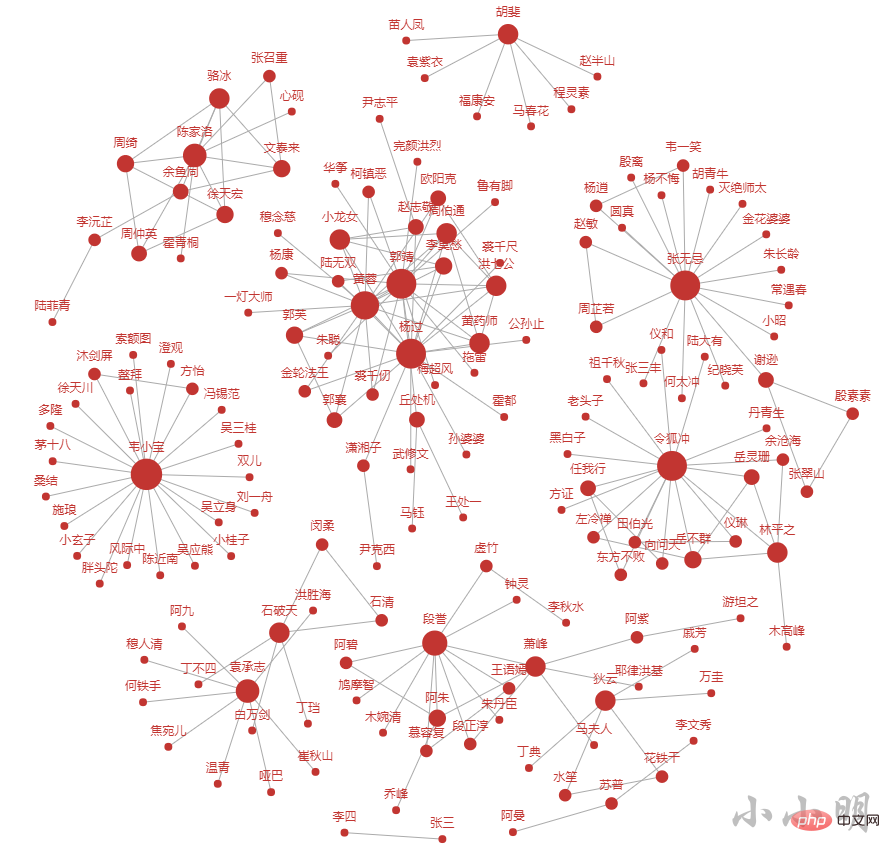
金庸小说15部小说中预计出现了1400个以上的角色,下面我们将遍历小说的每一段,在一段中出现的任意两个角色,都计数1。最终我们取出现频次最高的前200个关系对进行可视化。
完整代码如下:
from pyecharts import options as opts
from pyecharts.charts import Graph
import math
import itertools
count = Counter()
for novel in novel_names:
names = novel_names[novel]
re_rule = f"({'|'.join(names)})"
for line in load_novel(novel).splitlines():
names = list(set(re.findall(re_rule, line)))
if names and len(names) >= 2:
names.sort()
for s, t in itertools.combinations(names, 2):
count[(s, t)] += 1
count = count.most_common(200)
node_count, nodes, links = Counter(), [], []
for (n1, n2), v in count:
node_count[n1] += 1
node_count[n2] += 1
links.append({"source": n1, "target": n2})
for node, count in node_count.items():
nodes.append({"name": node, "symbolSize": int(math.log(count)*5)+5})
c = (
Graph(init_opts=opts.InitOpts("1280px","960px"))
.add("", nodes, links, repulsion=30)
)
c.render("tmp.html")这次我们生成了HTML文件是为了更方便的查看结果,前200个人物的关系情况如下:
按照相同的方法分析所有小说的门派关系:
from pyecharts import options as opts
from pyecharts.charts import Graph
import math
import itertools
count = Counter()
for novel in novel_bangs:
bangs = novel_bangs[novel]
re_rule = f"({'|'.join(bangs)})"
for line in load_novel(novel).splitlines():
names = list(set(re.findall(re_rule, line)))
if names and len(names) >= 2:
names.sort()
for s, t in itertools.combinations(names, 2):
count[(s, t)] += 1
count = count.most_common(200)
node_count, nodes, links = Counter(), [], []
for (n1, n2), v in count:
node_count[n1] += 1
node_count[n2] += 1
links.append({"source": n1, "target": n2})
for node, count in node_count.items():
nodes.append({"name": node, "symbolSize": int(math.log(count)*5)+5})
c = (
Graph(init_opts=opts.InitOpts("1280px","960px"))
.add("", nodes, links, repulsion=50)
)
c.render("tmp2.html")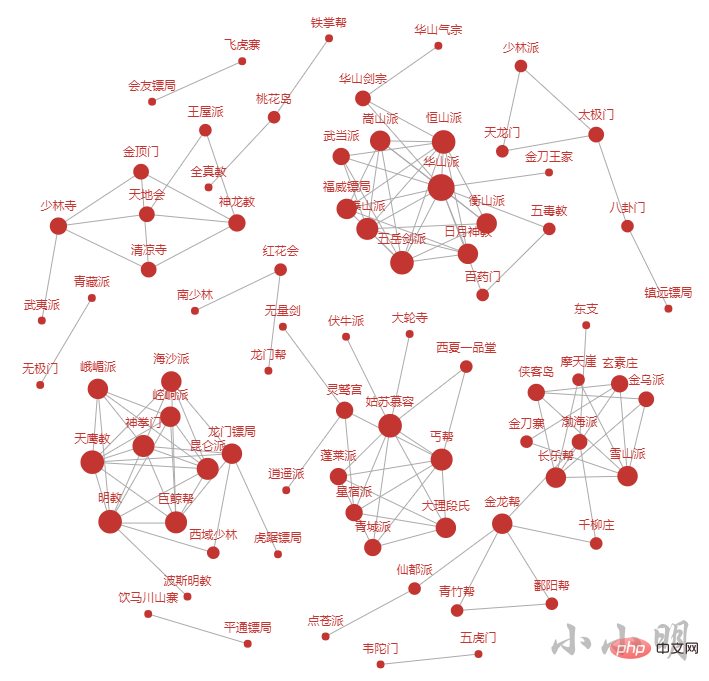
Word2Vec 是一款将词表征为实数值向量的高效工具,接下来,我们将使用它来处理这些小说。
gensim 包提供了一个 Python 版的实现。
之前我有使用gensim 包进行了相似文本的匹配,有兴趣可查阅:《批量模糊匹配的三种方法》
首先我要将所有小说的段落分词后添加到组织到一起(前面的程序可以重启):
import jieba
def load_novel(novel):
with open(f'novels/{novel}.txt', encoding="u8") as f:
return f.read()
with open('data/names.txt', encoding="utf-8") as f:
data = f.read().splitlines()
novels = data[::2]
names = []
for line in data[1::2]:
names.extend(line.split())
with open('data/kungfu.txt', encoding="utf-8") as f:
data = f.read().splitlines()
kungfus = []
for line in data[1::2]:
kungfus.extend(line.split())
with open('data/bangs.txt', encoding="utf-8") as f:
data = f.read().splitlines()
bangs = []
for line in data[1::2]:
bangs.extend(line.split())
for name in names:
jieba.add_word(name)
for kungfu in kungfus:
jieba.add_word(kungfu)
for bang in bangs:
jieba.add_word(bang)
# 去重
names = list(set(names))
kungfus = list(set(kungfus))
bangs = list(set(bangs))
sentences = []
for novel in novels:
print(f"处理:{novel}")
for line in load_novel(novel).splitlines():
sentences.append(jieba.lcut(line))处理:书剑恩仇录 处理:碧血剑 处理:射雕英雄传 处理:神雕侠侣 处理:雪山飞狐 处理:飞狐外传 处理:白马啸西风 处理:倚天屠龙记 处理:鸳鸯刀 处理:天龙八部 处理:连城诀 处理:侠客行 处理:笑傲江湖 处理:鹿鼎记 处理:越女剑
接下面我们使用Word2Vec训练模型:
import gensim model = gensim.models.Word2Vec(sentences)
我这边模型训练耗时15秒,若训练耗时较长可以把训练好的模型存到本地:
model.save("louis_cha.model")以后可以直接从本地磁盘读取模型:
model = gensim.models.Word2Vec.load("louis_cha.model")有了模型,我们可以进行一些简单而有趣的测试。
注意:每次生成的模型有一定随机性,后续结果根据生成的模型而变化,并非完全一致。
首先看与乔(萧)峰相似的角色:
model.wv.most_similar(positive=["乔峰", "萧峰"])
[('段正淳', 0.8006908893585205), ('张翠山', 0.8000873923301697), ('虚竹', 0.7957292795181274), ('赵敏', 0.7937390804290771), ('游坦之', 0.7803780436515808), ('石破天', 0.777414858341217), ('令狐冲', 0.7761642932891846), ('慕容复', 0.7629764676094055), ('贝海石', 0.7625609040260315), ('钟万仇', 0.7612598538398743)]
再看看与阿朱相似的角色:
model.wv.most_similar(positive=["阿朱", "蛛儿"])
[('殷素素', 0.8681862354278564), ('赵敏', 0.8558328747749329), ('木婉清', 0.8549383878707886), ('王语嫣', 0.8355365991592407), ('钟灵', 0.8338050842285156), ('小昭', 0.8316497206687927), ('阿紫', 0.8169034123420715), ('程灵素', 0.8153879642486572), ('周芷若', 0.8046135306358337), ('段誉', 0.8006759285926819)]
除了角色,我们还可以看看门派:
model.wv.most_similar(positive=["丐帮"])
[('恒山派', 0.8266139626502991), ('门人', 0.8158190846443176), ('天地会', 0.8078100085258484), ('雪山派', 0.8041207194328308), ('魔教', 0.7935695648193359), ('嵩山派', 0.7908961772918701), ('峨嵋派', 0.7845258116722107), ('红花会', 0.7830792665481567), ('星宿派', 0.7826651930809021), ('长乐帮', 0.7759961485862732)]
还可以看看与降龙十八掌相似的武功秘籍:
model.wv.most_similar(positive=["降龙十八掌"])
[('空明拳', 0.9040402770042419), ('打狗棒法', 0.9009960293769836), ('太极拳', 0.8992120623588562), ('八卦掌', 0.8909589648246765), ('一阳指', 0.8891675472259521), ('七十二路', 0.8713394999504089), ('绝招', 0.8693119287490845), ('胡家刀法', 0.8578060865402222), ('六脉神剑', 0.8568121194839478), ('七伤拳', 0.8560649156570435)]
在 Word2Vec 的模型里,有过“中国-北京=法国-巴黎”的例子,我们看看"段誉"和"段公子"类似于乔峰和什么的关系呢?
def find_relationship(a, b, c):
d, _ = model.wv.most_similar(positive=[b, c], negative=[a])[0]
print(f"{a}-{b} 犹如 {c}-{d}")
find_relationship("段誉", "段公子", "乔峰")段誉-段公子 犹如 乔峰-乔帮主
类似的还有:
# 情侣对
find_relationship("郭靖", "黄蓉", "杨过")
# 岳父女婿
find_relationship("令狐冲", "任我行", "郭靖")
# 非情侣
find_relationship("郭靖", "华筝", "杨过")郭靖-黄蓉 犹如 杨过-小龙女 令狐冲-任我行 犹如 郭靖-黄药师 郭靖-华筝 犹如 杨过-郭芙
查看韦小宝相关的关系:
# 韦小宝
find_relationship("杨过", "小龙女", "韦小宝")
find_relationship("令狐冲", "盈盈", "韦小宝")
find_relationship("张无忌", "赵敏", "韦小宝")
find_relationship("郭靖", "黄蓉", "韦小宝")杨过-小龙女 犹如 韦小宝-康熙 令狐冲-盈盈 犹如 韦小宝-方怡 张无忌-赵敏 犹如 韦小宝-阿紫 郭靖-黄蓉 犹如 韦小宝-丁珰
门派武功之间的关系:
find_relationship("郭靖", "降龙十八掌", "黄蓉")
find_relationship("武当", "张三丰", "少林")
find_relationship("任我行", "魔教", "令狐冲")郭靖-降龙十八掌 犹如 黄蓉-打狗棒法 武当-张三丰 犹如 少林-玄慈 任我行-魔教 犹如 令狐冲-恒山派
之前我们使用 Word2Vec 将每个词映射到了一个向量空间,因此,我们可以利用这个向量表示的空间,对这些词进行聚类分析。
首先取出所有角色对应的向量空间:
all_names = []
word_vectors = []
for name in names:
if name in model.wv:
all_names.append(name)
word_vectors.append(model.wv[name])
all_names = np.array(all_names)
word_vectors = np.vstack(word_vectors)聚类算法有很多,这里我们使用基本的Kmeans算法进行聚类,如果只分成3类,那么很明显地可以将众人分成主角,配角,跑龙套的三类:
from sklearn.cluster import KMeans
import pandas as pd
N = 3
labels = KMeans(N).fit(word_vectors).labels_
df = pd.DataFrame({"name": all_names, "label": labels})
for label, names in df.groupby("label").name:
print(f"类别{label}共{len(names)}个角色,前100个角色有:\n{','.join(names[:100])}\n")类别0共103个角色,前100个角色有: 李秋水,向问天,马钰,顾金标,丁不四,耶律齐,谢烟客,陈正德,殷天正,洪凌波,灵智上人,闵柔,公孙止,完颜萍,梅超风,鸠摩智,冲虚,冯锡范,尹克西,陆冠英,王剑英,左冷禅,商老太,尹志平,徐铮,灭绝师太,风波恶,袁紫衣,殷梨亭,宋青书,阿九,韩小莹,乌老大,杨康,何铁手,范遥,朱聪,郝大通,周仲英,风际中,何太冲,张召重,一灯大师,田归农,尼摩星,霍都,潇湘子,梅剑和,南希仁,玄难,纪晓芙,韩宝驹,邓百川,裘千尺,朱子柳,宋远桥,渡难,俞岱岩,武三通,云中鹤,余沧海,花铁干,杨逍,段延庆,巴天石,东方不败,归辛树,梁子翁,赵志敬,韦一笑,赵半山,丘处机,武修文,侯通海,鲁有脚,石清,彭连虎,胖头陀,达尔巴,裘千仞,金花婆婆,金轮法王,木高峰,苗人凤,任我行,王处一,柯镇恶,樊一翁,黄药师,欧阳克,张三丰,曹云奇,沙通天,文泰来,白万剑,鹿杖客,陆菲青,班淑娴,商宝震,全金发 类别1共6个角色,前100个角色有: 渔人,汉子,少妇,胖子,大汉,农夫 类别2共56个角色,前100个角色有: 张无忌,余鱼同,慕容复,木婉清,田伯光,郭襄,周伯通,陈家洛,乔峰,张翠山,丁珰,游坦之,岳不群,黄蓉,洪七公,岳灵珊,周芷若,马春花,杨过,阿紫,阿朱,赵敏,令狐冲,段正淳,水笙,石破天,徐天宏,程灵素,林平之,双儿,郭靖,袁承志,胡斐,陆无双,狄云,霍青桐,王语嫣,萧峰,李沅芷,骆冰,李莫愁,周绮,丁典,韦小宝,段誉,戚芳,小龙女,钟灵,殷素素,李文秀,谢逊,穆念慈,郭芙,方怡,仪琳,虚竹 类别3共236个角色,前100个角色有: 空智,章进,澄观,薛鹊,秃笔翁,曲非烟,田青文,郭啸天,陆大有,方证,阿碧,陶子安,吴三桂,钱老本,马行空,洪胜海,张勇,瑞大林,包不同,慕容景岳,康广陵,施琅,陆高轩,袁冠南,张康年,桃花仙,定逸,执法长老,范蠡,钟镇,陈达海,桃根仙,阿曼,李四,札木合,吴之荣,哈合台,传功长老,卓天雄,茅十八,风清扬,崔希敏,方生,王进宝,葛尔丹,常金鹏,秦红棉,薛慕华,侍剑,孙仲寿,范一飞,归二娘,孙不二,吴六奇,杨铁心,万震山,单正,玄寂,武敦儒,刘正风,西华子,樊纲,店伴,何足道,小昭,孙婆婆,苏普,谭婆,朱九真,耶律洪基,圆真,萧中慧,都大锦,司马林,叶二娘,安大娘,张三,杨成协,掌棒龙头,福康安,玉林,顾炎武,马超兴,殷离,莫声谷,郑萼,桃干仙,华筝,计无施,苏鲁克,费要多罗,苏荃,玄慈,卫璧,马光佐,常遇春,沐剑声,包惜弱,朱长龄,褚万里
我们可以根据每个类别的角色数量的相对大小,判断该类别的角色是属于主角,配角还是跑龙套。
下面我们过滤掉众龙套角色之后,重新聚合成四类:
c = pd.Series(labels).mode().iat[0]
remain_names = all_names[labels != c]
remain_vectors = word_vectors[labels != c]
remain_label = KMeans(4).fit(remain_vectors).labels_
df = pd.DataFrame({"name": remain_names, "label": remain_label})
for label, names in df.groupby("label").name:
print(f"类别{label}共{len(names)}个角色,前100个角色有:\n{','.join(names[:100])}\n")类别0共103个角色,前100个角色有: 李秋水,向问天,马钰,顾金标,丁不四,耶律齐,谢烟客,陈正德,殷天正,洪凌波,灵智上人,闵柔,公孙止,完颜萍,梅超风,鸠摩智,冲虚,冯锡范,尹克西,陆冠英,王剑英,左冷禅,商老太,尹志平,徐铮,灭绝师太,风波恶,袁紫衣,殷梨亭,宋青书,阿九,韩小莹,乌老大,杨康,何铁手,范遥,朱聪,郝大通,周仲英,风际中,何太冲,张召重,一灯大师,田归农,尼摩星,霍都,潇湘子,梅剑和,南希仁,玄难,纪晓芙,韩宝驹,邓百川,裘千尺,朱子柳,宋远桥,渡难,俞岱岩,武三通,云中鹤,余沧海,花铁干,杨逍,段延庆,巴天石,东方不败,归辛树,梁子翁,赵志敬,韦一笑,赵半山,丘处机,武修文,侯通海,鲁有脚,石清,彭连虎,胖头陀,达尔巴,裘千仞,金花婆婆,金轮法王,木高峰,苗人凤,任我行,王处一,柯镇恶,樊一翁,黄药师,欧阳克,张三丰,曹云奇,沙通天,文泰来,白万剑,鹿杖客,陆菲青,班淑娴,商宝震,全金发 类别1共6个角色,前100个角色有: 渔人,汉子,少妇,胖子,大汉,农夫 类别2共56个角色,前100个角色有: 张无忌,余鱼同,慕容复,木婉清,田伯光,郭襄,周伯通,陈家洛,乔峰,张翠山,丁珰,游坦之,岳不群,黄蓉,洪七公,岳灵珊,周芷若,马春花,杨过,阿紫,阿朱,赵敏,令狐冲,段正淳,水笙,石破天,徐天宏,程灵素,林平之,双儿,郭靖,袁承志,胡斐,陆无双,狄云,霍青桐,王语嫣,萧峰,李沅芷,骆冰,李莫愁,周绮,丁典,韦小宝,段誉,戚芳,小龙女,钟灵,殷素素,李文秀,谢逊,穆念慈,郭芙,方怡,仪琳,虚竹 类别3共236个角色,前100个角色有: 空智,章进,澄观,薛鹊,秃笔翁,曲非烟,田青文,郭啸天,陆大有,方证,阿碧,陶子安,吴三桂,钱老本,马行空,洪胜海,张勇,瑞大林,包不同,慕容景岳,康广陵,施琅,陆高轩,袁冠南,张康年,桃花仙,定逸,执法长老,范蠡,钟镇,陈达海,桃根仙,阿曼,李四,札木合,吴之荣,哈合台,传功长老,卓天雄,茅十八,风清扬,崔希敏,方生,王进宝,葛尔丹,常金鹏,秦红棉,薛慕华,侍剑,孙仲寿,范一飞,归二娘,孙不二,吴六奇,杨铁心,万震山,单正,玄寂,武敦儒,刘正风,西华子,樊纲,店伴,何足道,小昭,孙婆婆,苏普,谭婆,朱九真,耶律洪基,圆真,萧中慧,都大锦,司马林,叶二娘,安大娘,张三,杨成协,掌棒龙头,福康安,玉林,顾炎武,马超兴,殷离,莫声谷,郑萼,桃干仙,华筝,计无施,苏鲁克,费要多罗,苏荃,玄慈,卫璧,马光佐,常遇春,沐剑声,包惜弱,朱长龄,褚万里
每次运行结果都不一样,大家可以调整类别数量继续测试。从结果可以看到,反派更倾向于被聚合到一起,非正常姓名的人物更倾向于被聚合在一起,主角更倾向于被聚合在一起。
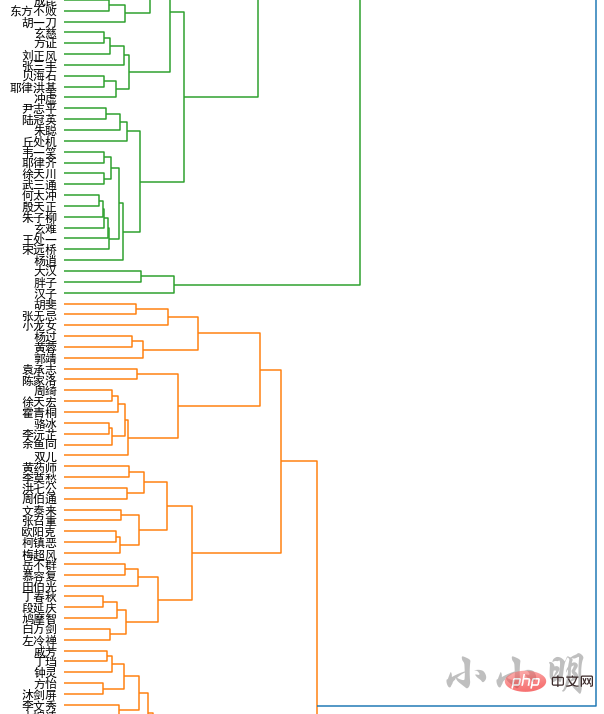
现在我们采用层级聚类的方式,查看人物间的层次关系,这里同样龙套角色不再参与聚类。
层级聚类调用 scipy.cluster.hierarchy 中层级聚类的包,在此之前先解决matplotlib中文乱码问题:
import matplotlib.pyplot as plt %matplotlib inline plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False
接下来调用代码为:
import scipy.cluster.hierarchy as sch
y = sch.linkage(remain_vectors, method="ward")
_, ax = plt.subplots(figsize=(10, 80))
z = sch.dendrogram(y, orientation='right')
idx = z['leaves']
ax.set_xticks([])
ax.set_yticklabels(remain_names[idx], fontdict={'fontsize': 12})
ax.set_frame_on(False)
plt.show()然后我们可以得到金庸小说宇宙的人物层次关系地图,结果较长仅展示一部分结果:
对各种武功作与人物层次聚类相同的操作:
all_names = []
word_vectors = []
for name in kungfus:
if name in model.wv:
all_names.append(name)
word_vectors.append(model.wv[name])
all_names = np.array(all_names)
word_vectors = np.vstack(word_vectors)
Y = sch.linkage(word_vectors, method="ward")
_, ax = plt.subplots(figsize=(10, 40))
Z = sch.dendrogram(Y, orientation='right')
idx = Z['leaves']
ax.set_xticks([])
ax.set_yticklabels(all_names[idx], fontdict={'fontsize': 12})
ax.set_frame_on(False)
plt.show()结果较长,仅展示部分结果:
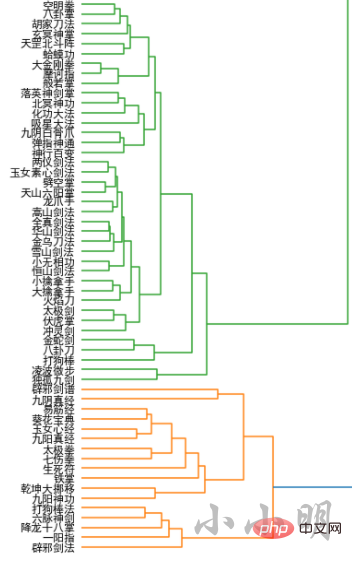
最后我们对门派进行层次聚类:
all_names = []
word_vectors = []
for name in bangs:
if name in model.wv:
all_names.append(name)
word_vectors.append(model.wv[name])
all_names = np.array(all_names)
word_vectors = np.vstack(word_vectors)
Y = sch.linkage(word_vectors, method="ward")
_, ax = plt.subplots(figsize=(10, 25))
Z = sch.dendrogram(Y, orientation='right')
idx = Z['leaves']
ax.set_xticks([])
ax.set_yticklabels(all_names[idx], fontdict={'fontsize': 12})
ax.set_frame_on(False)
plt.show()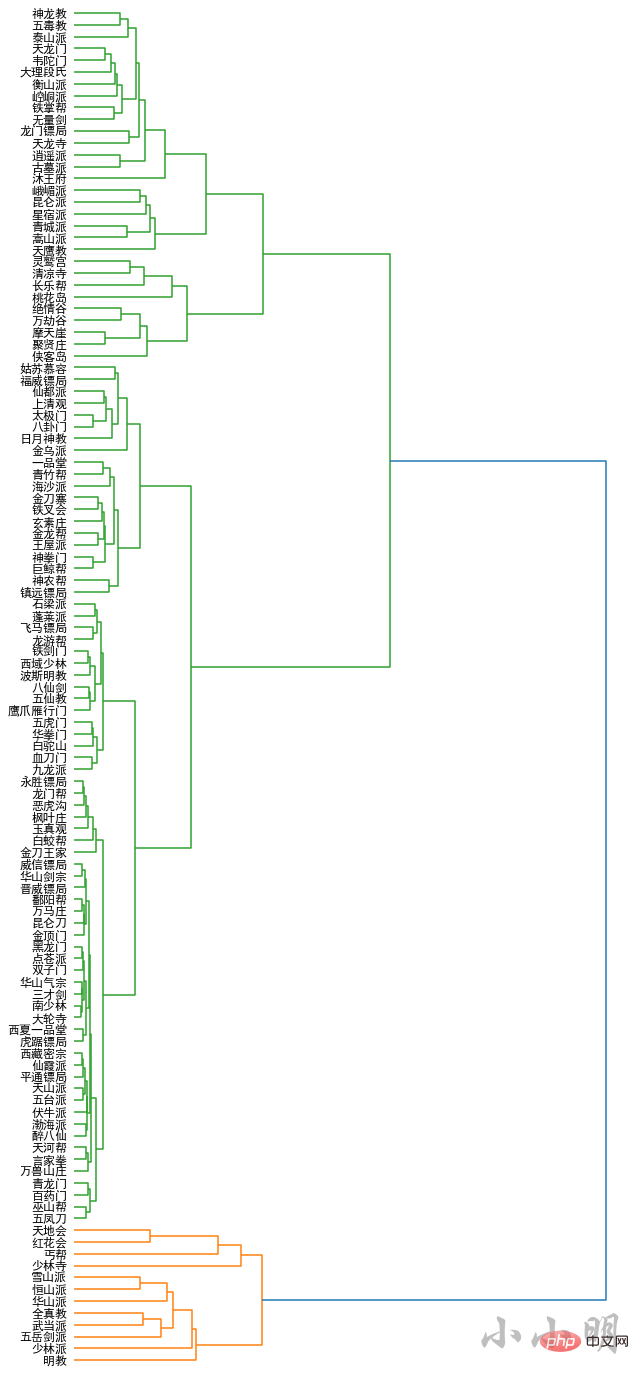
本文从金庸小说数据的采集,到普通的频次分析、剧情分析、关系分析,再到使用词向量空间分析相似关系,最后使用scipy进行所有小说的各种层次聚类。
위 내용은 고급 | Python을 사용하여 진용 소설의 세계를 탐구하는 20,000 단어의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



