

팁 | Python 크롤러 도구 Selenium 입문부터 고급까지

오늘은 에디터가 이야기selenium, 이 내용들을 이야기해보겠습니다
셀레늄소개 및 설치 selenium简介与安装页面元素的定位 浏览器的控制 鼠标的控制 键盘的控制 设置元素的等待 获取 cookies调用 JavaScript-
selenium🎜페이지 요소 위치 지정🎜🎜🎜🎜브라우저 컨트롤🎜🎜🎜🎜마우스 컨트롤🎜🎜🎜🎜키보드 컨트롤🎜🎜🎜🎜요소 대기 설정🎜🎜🎜🎜쿠키🎜🎜🎜🎜call
JavaScript🎜🎜🎜🎜셀레늄고급🎜🎜
셀레늄소개 및 설치selenium的简介与安装
selenium是最广泛使用的开源Web UI自动化测试套件之一,它所支持的语言包括C++、Java、Perl、PHP、Python和Ruby,在数据抓取方面也是一把利器,能够解决大部分网页的反爬措施,当然它也并非是万能的,一个比较明显的一点就在于是它速度比较慢,如果每天数据采集的量并不是很高,倒是可以使用这个框架。那么说到安装,可以直接使用pip
셀레늄 는 가장 널리 사용되는 오픈 소스 웹 UI 자동화 테스트 모음 중 하나입니다. 지원되는 언어에는 <code style="font-size: 14px;padding: 2px 4px;border-radius: 4px;margin-right" : rgba mono consolas monaco menlo monospace break-all rgb>C++, Java, Perl、<code style="font-size: 14px;padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px; background-color: rgba(27, 31, 35, 0.05 );font-family: " operator mono consolas monaco menlo monospace break-all rgb>PHP、Python 및 Ruby는 또한 데이터 캡처의 강력한 도구이며 대부분의 웹 크롤링 방지 문제를 해결할 수 있습니다. 물론 만병통치약은 아니지만, 상대적으로 느리다는 점은 매일 수집되는 데이터의 양이 그리 높지 않다면 이 프레임워크를 사용할 수 있습니다. 그러므로 설치 시 pip 설치 중
pip install selenium
<코드 스타일="글꼴 크기: 14px;패딩: 2px 4px;국경 반경: 4px;마진 오른쪽: 2px;마진 왼쪽: 2px;배경 색상: rgba(27, 31, 35, 0.05 );font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(150, 84, 181);">Firefox浏览器驱动: < 코드 스타일="글꼴 크기: 14px; 패딩: 2px 4px; 테두리 반경: 4px; 여백 오른쪽: 2px; 여백 왼쪽: 2px; 배경 색상: rgba(27, 31, 35, 0.05); 글꼴- 가족: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(150, 84, 181);">geckodriver Firefox浏览器驱动:geckodriverChrome浏览器驱动:chromedriver
selenium+chromedriver比较多,所以这里就以Chrome浏览器为示例,由于要涉及到chromedriver的版本需要和浏览器的版本一致,因此我们先来确认一下浏览器的版本是多少?看下图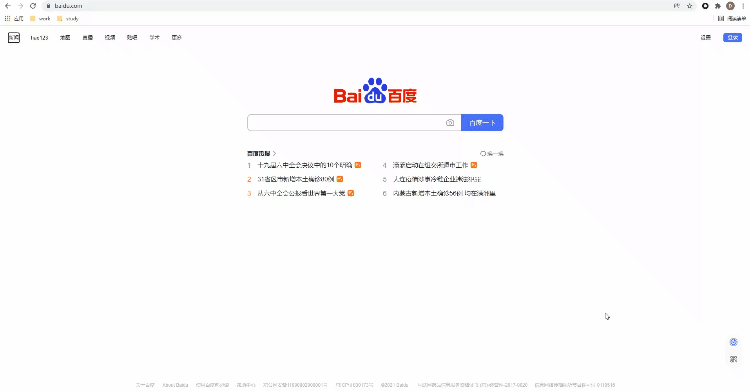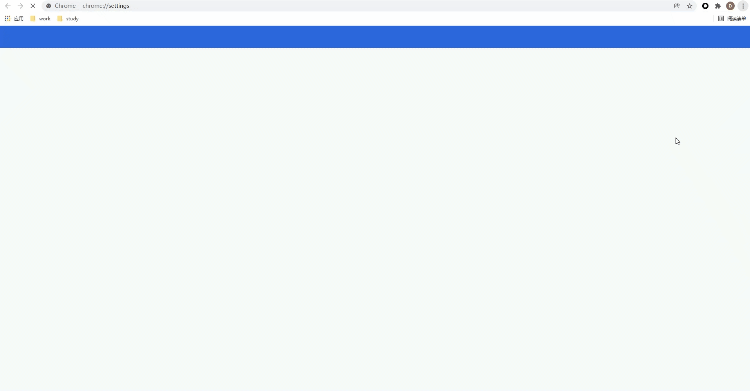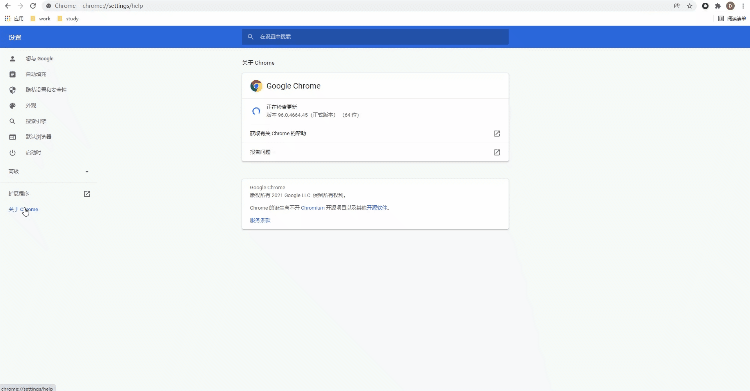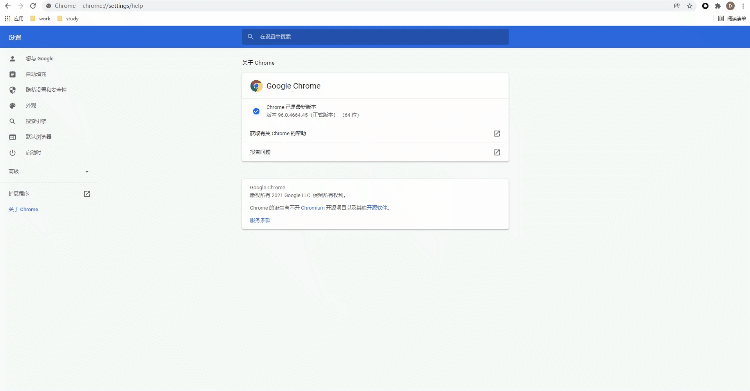
chromedriverChrome浏览器驱动: chromedriver셀레늄+chromedriver 더 많은 정보, 所以这里就以Chrome浏览器为示例,由于要涉及到chromedriver의 고유한 특별함과 浏览器的版本一致,因此我们先来确认一下浏览器版本是多少?看下图
🎜🎜🎜<섹션 스타일="글꼴 크기" : 16px;padding-top: 8px;padding-bottom: 8px;color: 검정;여백: 1em 4px;line-height: 2em;">저는 “关于Chrome”当中找到浏览器的版本,然后下载对应版本的chromedriver ,当然也要对应自己电脑的操作系统🎜🎜🎜🎜🎜🎜페이지 요소 위치 지정
페이지 요소 위치 지정에 대해 이야기할 때 편집자는 독자가 HTML,CSSetc.
ID标签的定位
HTML当中,ID属性是唯一标识一个元素的属性,因此在selenium当中,通过ID来进行元素的定位也作为首选,我们以百度首页为例,搜索框的HTML代码如下,其ID为“kw”,而“百度一下”这个按钮的ID为“su”,我们用Python脚本通过ID的标签来进行元素的定位driver.find_element_by_id("kw")
driver.find_element_by_id("su")NAME标签的定位
HTML当中,Name属性和ID属性的功能基本相同,只是Name属性并不是唯一的,如果遇到没有ID标签的时候,我们可以考虑通过Name标签来进行定位,代码如下driver.find_element_by_name("wd")Xpath定位
Xpath方式来定位几乎涵盖了页面上的任意元素,那什么是Xpath呢?Xpath是一种在XML和HTML文档中查找信息的语言,当然通过Xpath路径来定位元素的时候也是分绝对路径和相对路径。/来表示,相对路径是以//来表示,而涉及到Xpath路径的编写,小编这里偷个懒,直接选择复制/粘贴的方式,例如针对下面的HTML代码<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Test</title>
</head>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
<input name="continue" type="button" value="Clear" />
</form>
</body>
</html>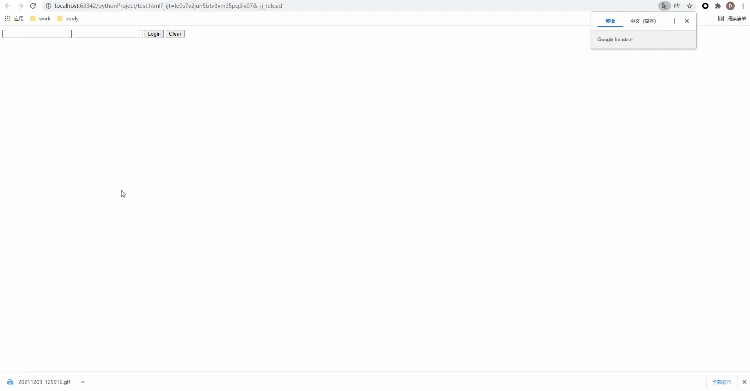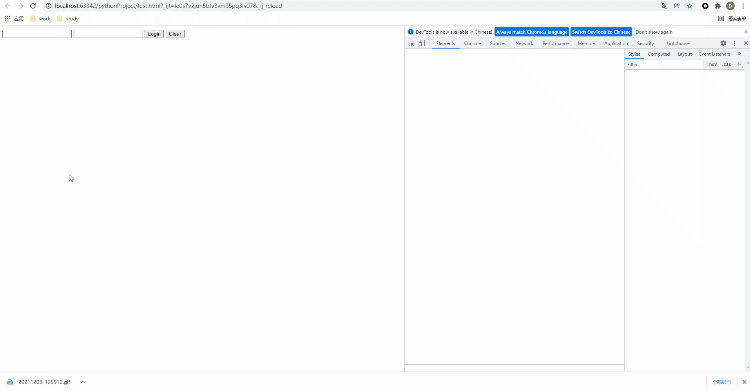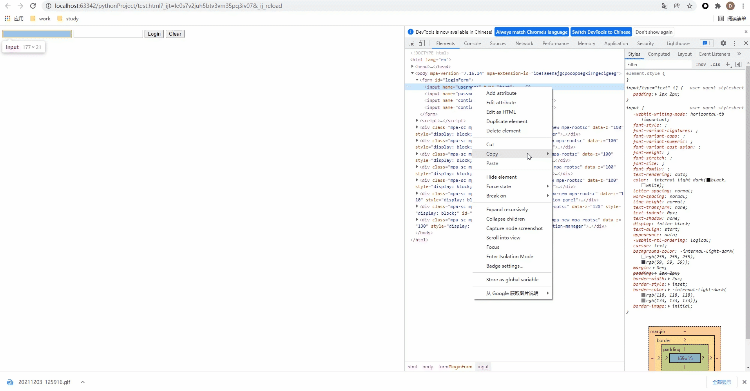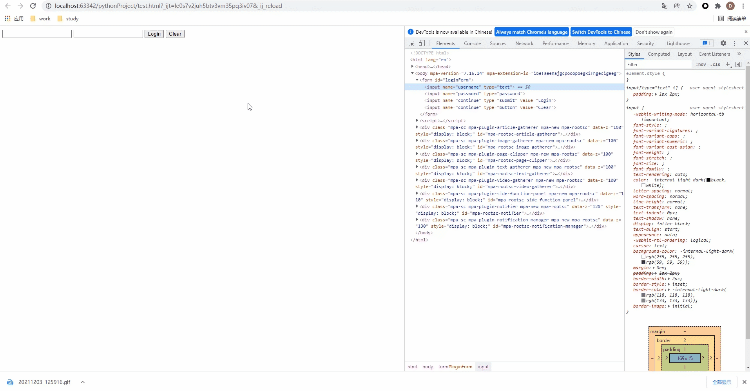
Xpath来进行页面元素的定位,代码如下driver.find_element_by_xpath('//*[@id="kw"]')
className标签定位
class属性来定位元素,尤其是当我们看到有多个并列的元素如list表单,class用的都是共用同一个,如:driver.find_element_by_class_name("classname")class属性来定位元素,该方法返回的是一个list列表,而当我们想要定位列表当中的第n个元素时,则可以这样来安排driver.find_elements_by_class_name("classname")[n]find_elements_by_class_name()方法而不是find_element_by_class_name()方法,这里我们还是通过百度首页的例子,通过className标签来定位搜索框这个元素driver.find_element_by_class_name('s_ipt')
CssSelector()方法定位
Selenium官网当中是更加推荐CssSelector()方法来进行页面元素的定位的,原因在于相比较于Xpath定位速度更快,Css定位分为四类:ID值、Class属性、TagName值等等,我们依次来看ID方式来定位
TagName的值,另外一种则是不加,代码如下driver.find_element_by_css_selector("#id_value") # 不添加前面的`TagName`值
driver.find_element_by_css_selector("tag_name.class_value") # 不添加前面的`TagName`值TagName的值非常的冗长,中间可能还有空格,那么这当中的空格就需要用点“.”来替换driver.find_element_by_css_selector("tag_name.class_value1.calss_value2.class_value3") # 不添加前面的`TagName`值我们仍然以百度首页的搜索框为例,它的HTML代码如下
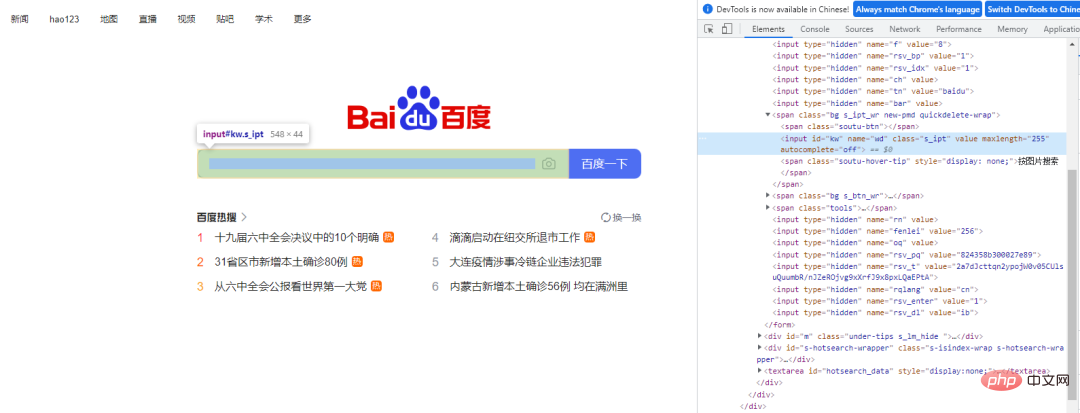
CssSelector的.class()方式来实现元素的定位的话,Python代码该这样来实现,和上面Xpath()的方法一样,可以稍微偷点懒,通过复制/粘贴的方式从开发者工具当中来获取元素的位置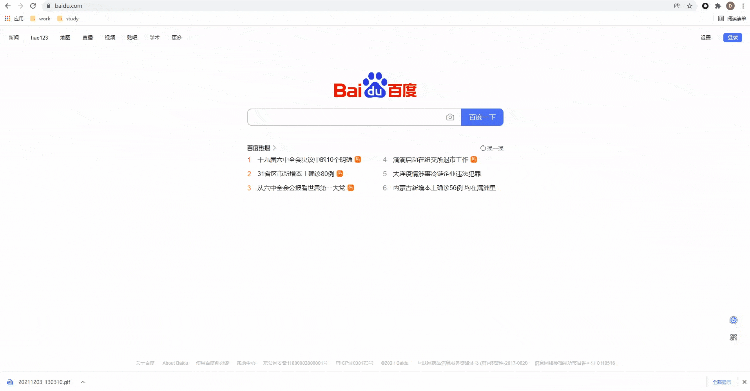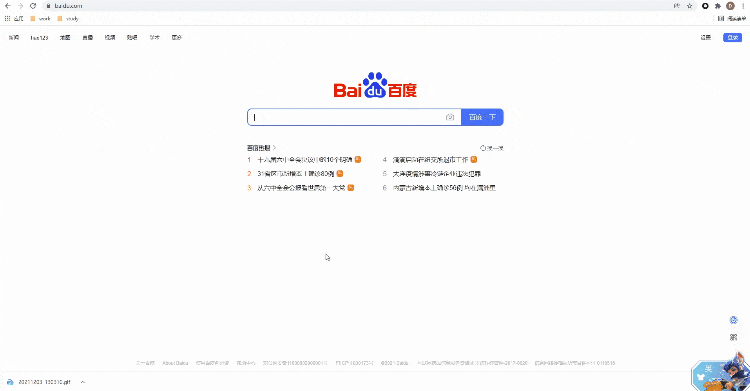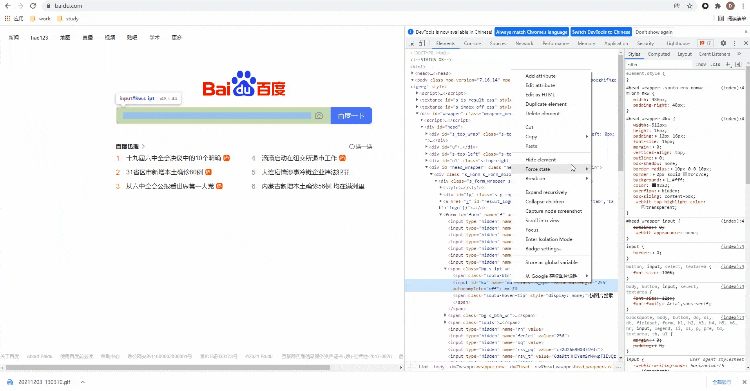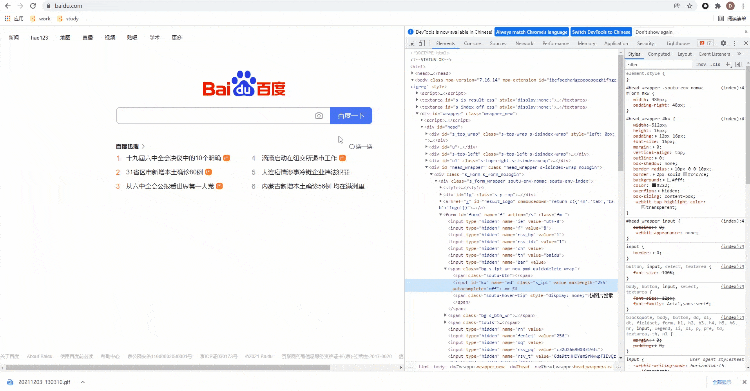
代码如下
driver.find_element_by_css_selector('#kw')
linkText()方式来定位
这个方法直接通过链接上面的文字来定位元素,案例如下
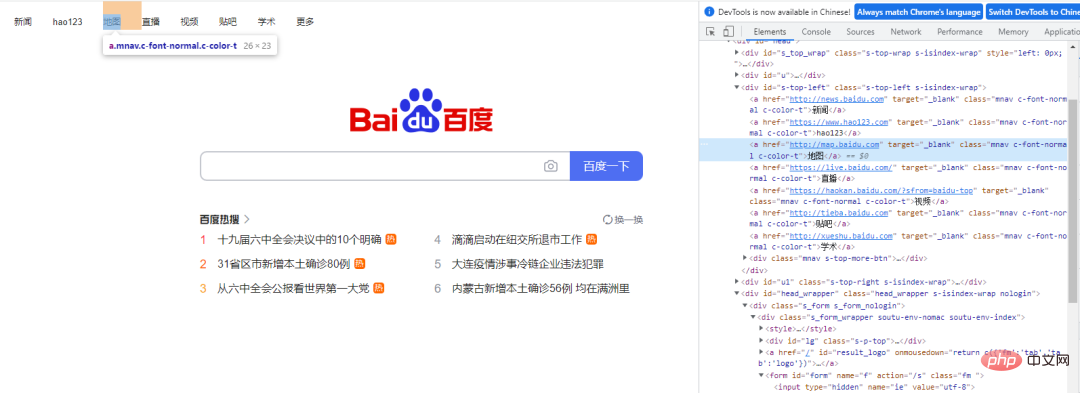
通过linkText()方法来定位“地图”这个元素,代码如下
driver.find_element_by_link_text("地图").click()浏览器的控制
修改浏览器窗口的大小
set_window_size()这个方法来修改浏览器窗口的大小,代码如下# 修改浏览器的大小 driver.set_window_size(500, 900)
同时还有maxmize_window()方法是用来实现浏览器全屏显示,代码如下
# 全屏显示 driver.maximize_window()
浏览器的前进与后退
前进与后退用到的方法分别是forward()和back(),代码如下
# 前进与后退 driver.forward() driver.back()
浏览器的刷新
刷新用到的方法是refresh(),代码如下
# 刷新页面 driver.refresh()
除了上面这些,webdriver的常见操作还有
关闭浏览器: get()清除文本: clear()单击元素: click()提交表单: submit()模拟输入内容: send_keys()
我们可以尝试着用上面提到的一些方法来写段程序
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome(executable_path="chromedriver.exe")
driver.get("https://www.baidu.com")
sleep(3)
driver.maximize_window()
sleep(1)
driver.find_element_by_xpath('//*[@id="s-top-loginbtn"]').click()
sleep(3)
driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_11__userName"]').send_keys('12121212')
sleep(1)
driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_11__password"]').send_keys('testtest')
sleep(2)
driver.refresh()
sleep(3)
driver.quit()output

鼠标的控制
鼠标的控制都是封装在ActionChains类当中,常见的有以下几种
引入action_chains类 from selenium.webdriver.common.action_chains import ActionChains # 右击 ActionChains(driver).context_click(element).perform() # 双击 ActionChains(driver).double_click(element).perform() # 拖放 ActionChains(driver).drag_and_drop(Start, End).perform() # 悬停 ActionChains(driver).move_to_element(Above).perform() # 按下 ActionChains(driver).click_and_hold(leftclick).perform() # 执行指定的操作
键盘的控制
webdriver中的Keys()类,提供了几乎所有按键的方法,常用的如下
# 删除键 driver.find_element_by_id('xxx').send_keys(Keys.BACK_SPACE) # 空格键 driver.find_element_by_id('xxx').send_keys(Keys.SPACE) # 回车键 driver.find_element_by_id('xxx').send_keys(Keys.ENTER) # Ctrl + A 全选内容 driver.find_element_by_id('xxx').send_keys(Keys.CONTROL, 'a') # Ctrl + C/V 复制/粘贴内容 driver.find_element_by_id('xxx').send_keys(Keys.CONTROL, 'c') driver.find_element_by_id('xxx').send_keys(Keys.CONTROL, 'v')
其他的一些键盘操作
向上箭头: Keys.ARROW_UP向下箭头: Keys.ARROW_DOWN向左/向右箭头: Keys.ARROW_LEFT/Keys.ARROW_RIGHTShift键: Keys.SHIFTF1键: Keys.F1
元素的等待
有显示等待和隐式等待两种
显示等待
TimeoutException),需要用到的是WebDriverWait()方法,同时配合until和not until方法WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
其中的参数:
timeout: 最长超时时间,默认以秒为单位 poll_frequency: 检测的时间间隔,默认是0.5s ignored_exceptions: 指定忽略的异常,默认忽略的有 NoSuchElementException这个异常
我们来看下面的案例
driver = webdriver.Chrome()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement")))
finally:
driver.quit()隐式等待
主要使用的是implicitly_wait()来实现
browser = webdriver.Chrome(path) # 隐式等待3秒 browser.implicitly_wait(3)
获取Cookie
Cookie是用来识别用户身份的关键,我们通常也是通过selenium先模拟登录网页获取Cookie,然后再通过requests携带Cookie来发送请求。webdriver提供了cookies的几种操作,我们挑选几个常用的来说明
get_cookies():以字典的形式返回当前会话中可见的cookie信息get_cookies(name): 返回cookie字典中指定的的cookie信息add_cookie(cookie_dict): 将cookie添加到当前会话中
下面看一个简单的示例代码
driver=webdriver.Chrome(executable_path="chromedriver.exe")
driver.get(url=url)
time.sleep(1)
cookie_list=driver.get_cookies()
cookies =";".join([item["name"] +"=" + item["value"] + "" for item in cookie_list])
session=requests.session()
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36',
'cookie': cookies
}
response=session.get(url=url,headers=headers)
soup=BeautifulSoup(response.text,'lxml')调用JavaScript
webdriver当中可以使用execut_script()方法来实现JavaScript的执行,下面我们来看一个简单的例子from selenium import webdriver
import time
bro=webdriver.Chrome(executable_path='./chromedriver')
bro.get("https://www.baidu.com")
# 执行js代码
bro.execute_script('alert(10)')
time.sleep(3)
bro.close()除此之外,我们还可以通过selenium执行JavaScript来实现屏幕上下滚动
from selenium import webdriver
bro=webdriver.Chrome(executable_path='./chromedriver')
bro.get("https://www.baidu.com")
# 执行js代码
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')selenium进阶
selenium启动的浏览器,会非常容易的被检测出来,通常可以通过window.navigator.webdriver的值来查看,如果是true则说明是使用了selenium模拟浏览器,如果是undefined则通常会被认为是正常的浏览器。window.navigator.webdriver最后返回的值driver.execute_script(
'Object.defineProperties(navigator,{webdriver:{get:()=>false}})'
)JavaScript程序已经通过读取window.navigator.webdriver知道你使用的是模拟浏览器了。所以我们有两种办法来解决这个缺陷。在Chrome当中添加实验性功能参数
代码如下
from selenium.webdriver import Chrome from selenium.webdriver import ChromeOptions option = ChromeOptions() option.add_experimental_option('excludeSwitches',['enable-automation']) driver=Chrome(options=option)
调用chrome当中的开发工具协议的命令
Chrome浏览器在打开页面,还没有运行网页自带的JavaScript代码时,先来执行我们给定的代码,通过execute_cdp_cmd()方法,driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})当然为了更好隐藏指纹特征,我们可以将上面两种方法想结合
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(options=options, executable_path='./chromedriver')
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
driver.get(url)stealth.min.js文件来实现隐藏selenium模拟浏览器的特征,这个文件之前是给puppeteer用的,使得其隐藏浏览器的指纹特征,而让Python使用时,需要先导入这份JS文件import time
from selenium.webdriver import Chrome
option = webdriver.ChromeOptions()
option.add_argument("--headless")
# 无头浏览器需要添加user-agent来隐藏特征
option.add_argument('user-agent=.....')
driver = Chrome(options=option)
driver.implicitly_wait(5)
with open('stealth.min.js') as f:
js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
driver.get(url)위 내용은 팁 | Python 크롤러 도구 Selenium 입문부터 고급까지의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7681
7681
 15
1393
52
1209
24
91
11
73
19
15
1393
52
1209
24
91
11
73
19

 PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.
 PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.
 Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
 Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
VS 코드는 파이썬을 작성하는 데 사용될 수 있으며 파이썬 애플리케이션을 개발하기에 이상적인 도구가되는 많은 기능을 제공합니다. 사용자는 다음을 수행 할 수 있습니다. Python 확장 기능을 설치하여 코드 완료, 구문 강조 및 디버깅과 같은 기능을 얻습니다. 디버거를 사용하여 코드를 단계별로 추적하고 오류를 찾아 수정하십시오. 버전 제어를 위해 git을 통합합니다. 코드 서식 도구를 사용하여 코드 일관성을 유지하십시오. 라인 도구를 사용하여 잠재적 인 문제를 미리 발견하십시오.
 VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VS 코드 확장은 악의적 인 코드 숨기기, 취약성 악용 및 합법적 인 확장으로 자위하는 등 악성 위험을 초래합니다. 악의적 인 확장을 식별하는 방법에는 게시자 확인, 주석 읽기, 코드 확인 및주의해서 설치가 포함됩니다. 보안 조치에는 보안 인식, 좋은 습관, 정기적 인 업데이트 및 바이러스 백신 소프트웨어도 포함됩니다.
 Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
VS 코드는 Windows 8에서 실행될 수 있지만 경험은 크지 않을 수 있습니다. 먼저 시스템이 최신 패치로 업데이트되었는지 확인한 다음 시스템 아키텍처와 일치하는 VS 코드 설치 패키지를 다운로드하여 프롬프트대로 설치하십시오. 설치 후 일부 확장은 Windows 8과 호환되지 않을 수 있으며 대체 확장을 찾거나 가상 시스템에서 새로운 Windows 시스템을 사용해야합니다. 필요한 연장을 설치하여 제대로 작동하는지 확인하십시오. Windows 8에서는 VS 코드가 가능하지만 더 나은 개발 경험과 보안을 위해 새로운 Windows 시스템으로 업그레이드하는 것이 좋습니다.
 PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP는 1994 년에 시작되었으며 Rasmuslerdorf에 의해 개발되었습니다. 원래 웹 사이트 방문자를 추적하는 데 사용되었으며 점차 서버 측 스크립팅 언어로 진화했으며 웹 개발에 널리 사용되었습니다. Python은 1980 년대 후반 Guidovan Rossum에 의해 개발되었으며 1991 년에 처음 출시되었습니다. 코드 가독성과 단순성을 강조하며 과학 컴퓨팅, 데이터 분석 및 기타 분야에 적합합니다.
 터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
vs 코드에서는 다음 단계를 통해 터미널에서 프로그램을 실행할 수 있습니다. 코드를 준비하고 통합 터미널을 열어 코드 디렉토리가 터미널 작업 디렉토리와 일치하는지 확인하십시오. 프로그래밍 언어 (예 : Python의 Python Your_file_name.py)에 따라 실행 명령을 선택하여 성공적으로 실행되는지 여부를 확인하고 오류를 해결하십시오. 디버거를 사용하여 디버깅 효율을 향상시킵니다.
