
최근 CVPR 2023에서 딥러닝 분야의 저명한 연구자이자 Lightning AI 수석 인공지능 교육자인 Sebastian Raschka가 "Scaling PyTorch Model Training With Minimal Code Changes"라는 기조연설을 했습니다.

연구 결과를 더 많은 사람들과 공유하기 위해 Sebastian Raschka는 연설문을 기사로 편집했습니다. 이 기사에서는 최소한의 코드 변경으로 PyTorch 모델 훈련을 확장하는 방법을 살펴보고 낮은 수준의 기계 최적화보다는 혼합 정밀도 방법과 다중 GPU 훈련 모드를 활용하는 데 중점을 두고 있음을 보여줍니다.
이 기사에서는 ViT(Visual Transformer)를 기본 모델로 사용했습니다. ViT 모델은 기본 데이터 세트에서 처음부터 시작되었으며 약 60분의 학습 후에 테스트 세트에서 62%의 정확도를 달성했습니다.
GitHub 주소: https://github.com/rasbt/cvpr2023
다음은 기사의 원본 텍스트입니다:
에 다음 섹션에서는 Sebastian이 광범위한 코드 리팩토링 없이 훈련 시간과 정확성을 향상시키는 방법을 살펴보겠습니다.
여기서는 모델과 데이터 세트의 세부 사항이 주요 초점이 아니라는 점에 유의하고 싶습니다(단지 독자가 너무 많은 것을 다운로드하고 설치하지 않고도 자신의 컴퓨터에서 재현할 수 있도록 가능한 한 간단하게 작성되었습니다). 종속성). 여기에 공유된 모든 예제는 독자가 전체 코드를 탐색하고 재사용할 수 있는 GitHub에서 찾을 수 있습니다.
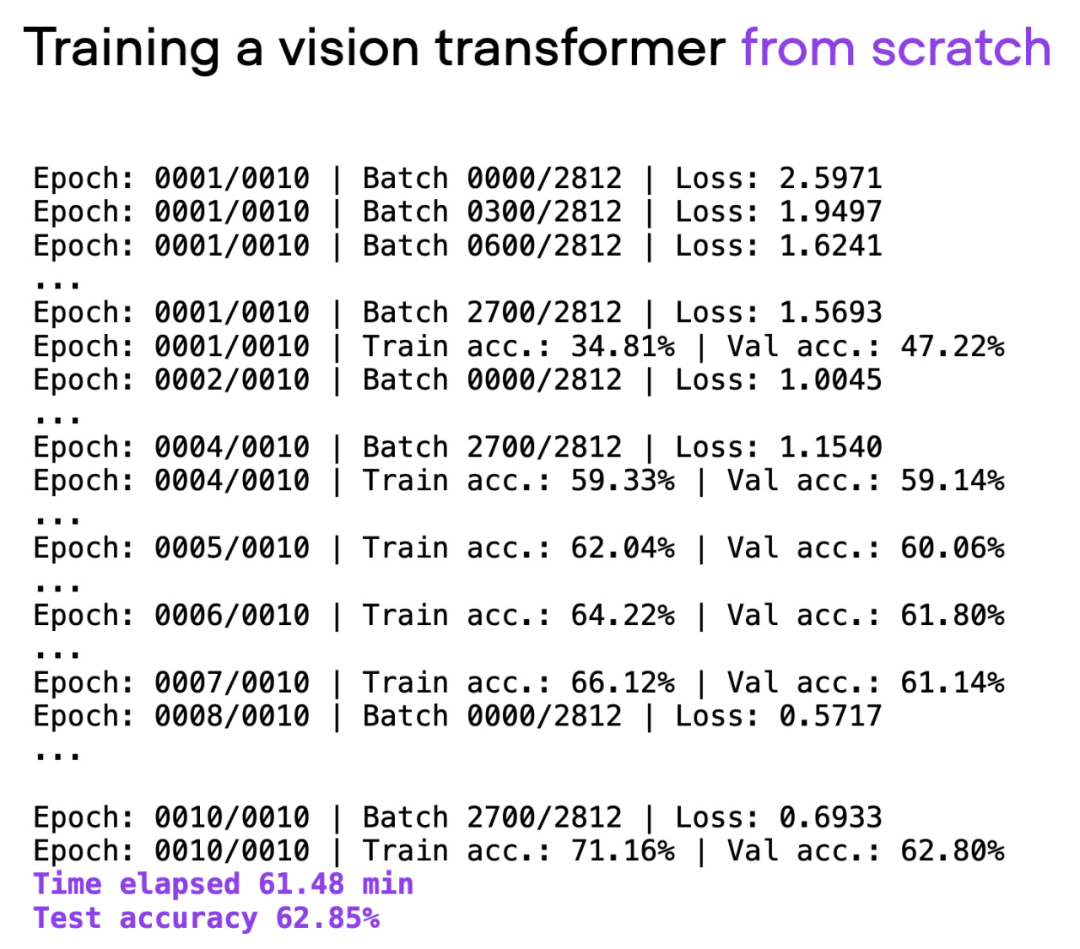
스크립트 00_pytorch-vit-random-init.py의 출력.
오늘날 텍스트나 이미지에 대한 딥 러닝 모델을 처음부터 훈련하는 것은 종종 비효율적입니다. 우리는 일반적으로 사전 훈련된 모델을 활용하고 모델을 미세 조정하여 시간과 컴퓨팅 리소스를 절약하는 동시에 더 나은 모델링 결과를 얻습니다.
위에 사용된 것과 동일한 ViT 아키텍처를 고려하고 다른 데이터 세트(ImageNet)에 대해 사전 훈련하고 미세 조정하면 20분이라는 짧은 시간에 더 나은 예측 성능을 얻을 수 있습니다(95%의 테스트 정확도는 3번의 훈련 기간 내에 달성됩니다.
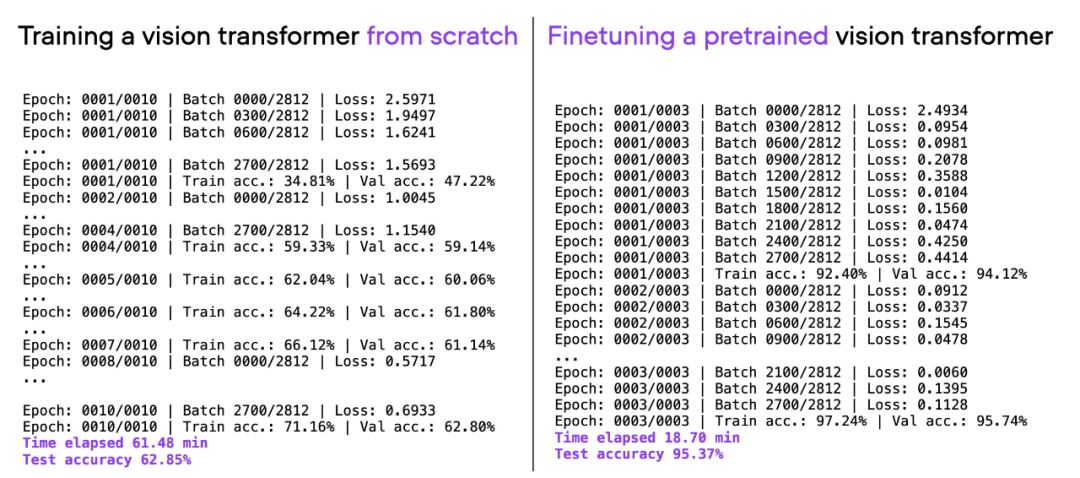
00_pytorch-vit-random-init.py와 01_pytorch-vit.py 비교.
미세 조정이 처음부터 훈련하는 것보다 모델 성능을 크게 향상시킬 수 있음을 알 수 있습니다. 아래 막대 차트는 이를 요약합니다.
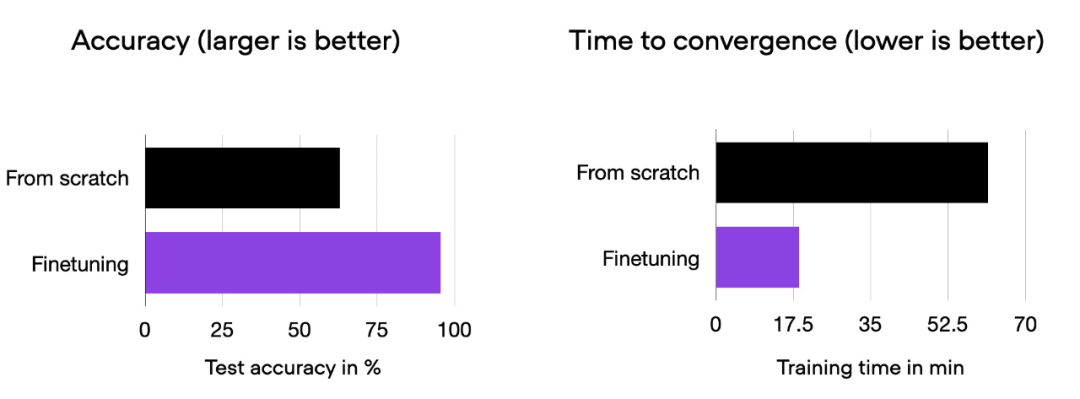
00_pytorch-vit-random-init.py와 01_pytorch-vit.py의 비교 히스토그램.
물론 모델 성능은 데이터 세트나 작업에 따라 달라질 수 있습니다. 그러나 많은 텍스트 및 이미지 작업의 경우 공통 공개 데이터 세트에서 사전 학습된 모델로 시작하는 것이 좋습니다.
다음 섹션에서는 예측 정확도를 저하시키지 않고 훈련 시간을 단축할 수 있는 다양한 기술을 살펴보겠습니다.
최소한의 코드 변경으로 PyTorch에서 교육을 효율적으로 확장하는 한 가지 방법은 PyTorch용 경량 래퍼 라이브러리/인터페이스로 볼 수 있는 오픈 소스 Fabric 라이브러리를 사용하는 것입니다. pip를 통해 설치합니다.
pip install lightning
아래에서 살펴보는 모든 기술은 순수 PyTorch에서도 구현할 수 있습니다. Fabric은 이 과정을 보다 편리하게 만드는 것을 목표로 합니다.
"코드 가속화를 위한 고급 기술"을 살펴보기 전에 먼저 Fabric을 PyTorch 코드에 통합하는 데 필요한 작은 변경 사항을 소개하겠습니다. 이렇게 변경하면 코드 한 줄만 변경하여 고급 PyTorch 기능을 쉽게 사용할 수 있습니다.
PyTorch 코드와 Fabric을 사용하도록 수정된 코드의 차이는 미묘하며 다음 코드에서 볼 수 있듯이 약간의 사소한 수정만 포함됩니다. 패브릭
总结一下上图,就可以得到普通的 PyTorch 代码转换为 PyTorch+Fabric 的三个步骤:

这些微小的改动提供了一种利用 PyTorch 高级特性的途径,而无需对现有代码进行进一步重构。
深入探讨下面的「高级特性」之前,要确保模型的训练运行时间、预测性能与之前相同。
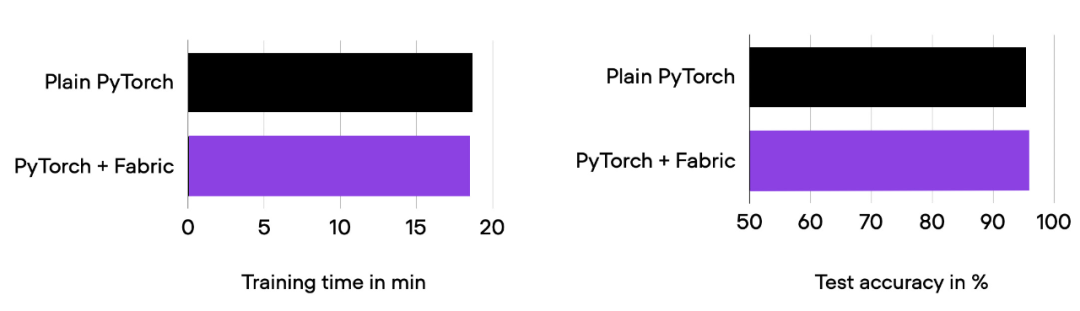
01_pytorch-vit.py 和 03_fabric-vit.py 的比较结果。
正如前面柱状图中所看到的,训练运行时间、准确率与之前完全相同,正如预期的那样。其中,任何波动都可以归因于随机性。
在前面的部分中,我们使用 Fabric 修改了 PyTorch 代码。为什么要费这么大的劲呢?接下来将尝试高级技术,比如混合精度和分布式训练,只需更改一行代码,把下面的代码
fabric = Fabric(accelerator="cuda")
改为
fabric = Fabric(accelerator="cuda", precisinotallow="bf16-mixed")
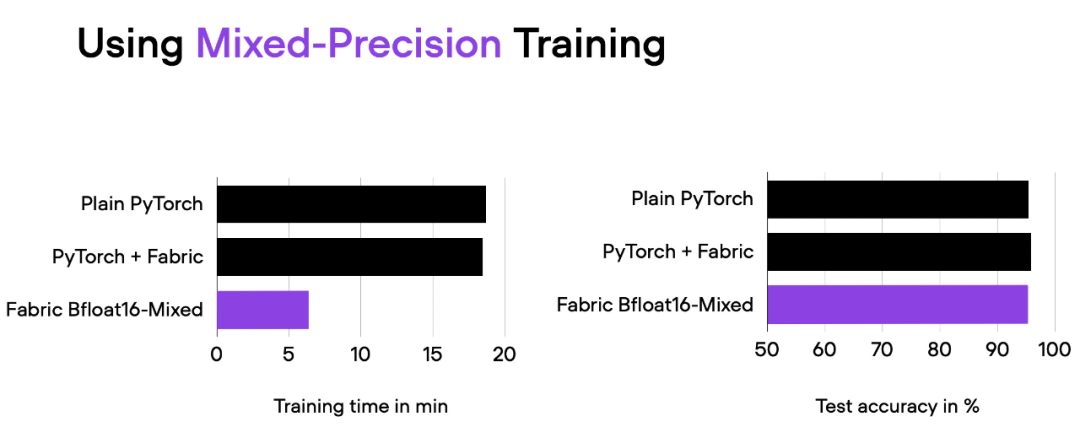
04_fabric-vit-mixed-precision.py 脚本的比较结果。脚本地址:https://github.com/rasbt/cvpr2023/blob/main/04_fabric-vit-mixed-precision.py
通过混合精度训练,我们将训练时间从 18 分钟左右缩短到 6 分钟,同时保持相同的预测性能。这种训练时间的缩短只需在实例化 Fabric 对象时添加参数「precisinotallow="bf16-mixed"」即可实现。
混合精度训练实质上使用了 16 位和 32 位精度,以确保不会损失准确性。16 位表示中的计算梯度比 32 位格式快得多,并且还节省了大量内存。这种策略在内存或计算受限的情况下非常有益。
之所以称为「混合」而不是「低」精度训练,是因为不是将所有参数和操作转换为 16 位浮点数。相反,在训练过程中 32 位和 16 位操作之间切换,因此称为「混合」精度。
如下图所示,混合精度训练涉及步骤如下:
这种方法在保持神经网络准确性和稳定性的同时,实现了高效的训练。
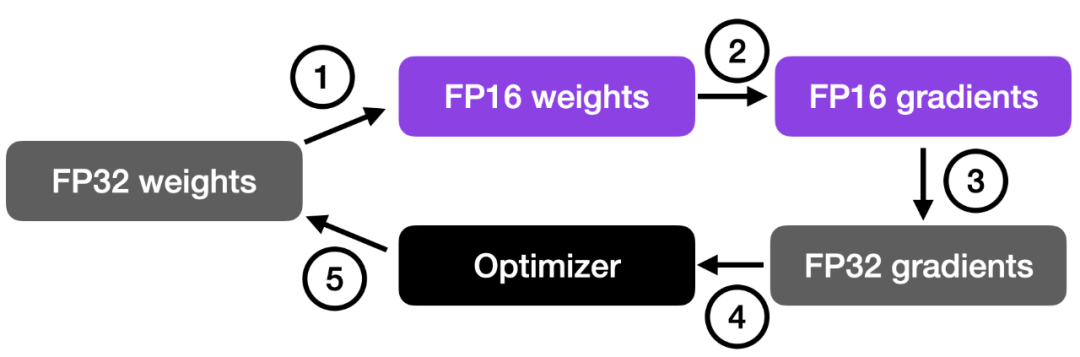
更详细的步骤如下:
步骤 4 中的乘积用于更新原始的 FP32 神经网络权重。学习率有助于控制优化过程的收敛性,对于实现良好的性能非常重要。
前面谈到了「float 16-bit」精度训练。需要注意的是,在之前的代码中,指定了 precisinotallow="bf16-mixed",而不是 precisinotallow="16-mixed"。这两个都是有效的选项。
在这里,"bf16-mixed" 中的「bf16」表示 Brain Floating Point(bfloat16)。谷歌开发了这种格式,用于机器学习和深度学习应用,尤其是在张量处理单元(TPU)中。Bfloat16 相比传统的 float16 格式扩展了动态范围,但牺牲了一定的精度。
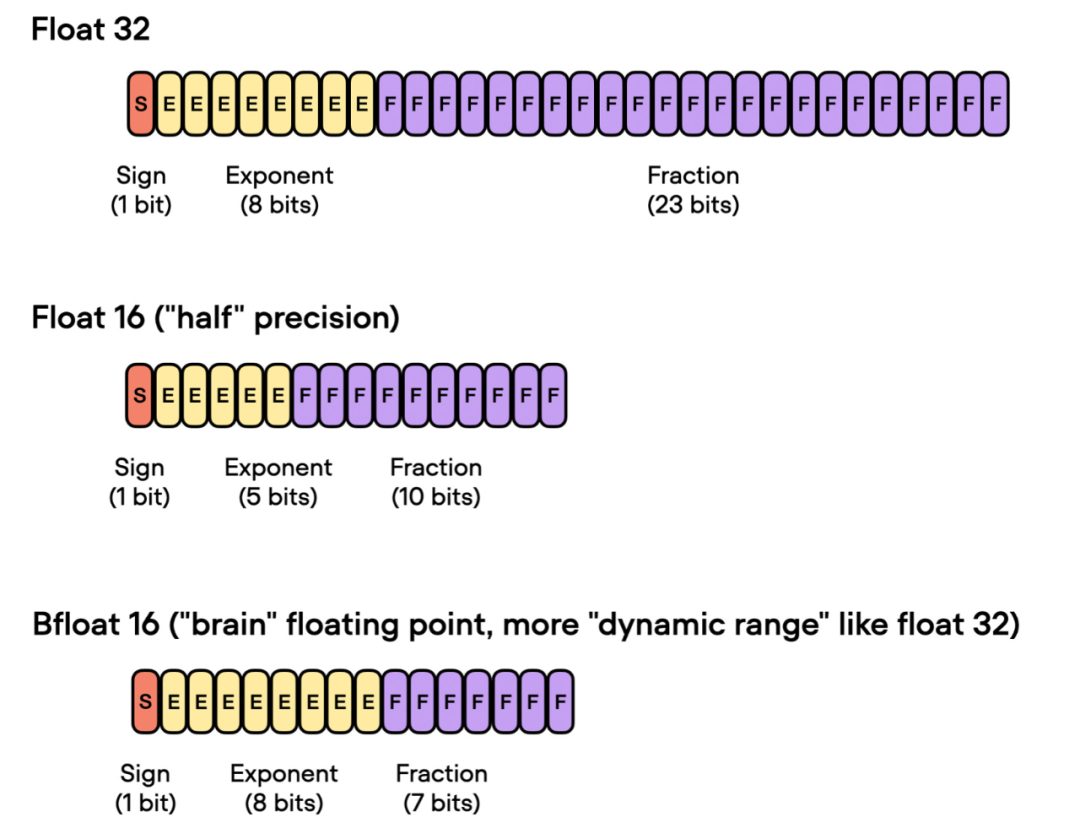
扩展的动态范围使得 bfloat16 能够表示非常大和非常小的数字,使其更适用于深度学习应用中可能遇到的数值范围。然而,较低的精度可能会影响某些计算的准确性,或在某些情况下导致舍入误差。但在大多数深度学习应用中,这种降低的精度对建模性能的影响很小。
虽然 bfloat16 最初是为 TPU 开发的,但从 NVIDIA Ampere 架构的 A100 Tensor Core GPU 开始,已经有几种 NVIDIA GPU 开始支持 bfloat16。
我们可以使用下面的代码检查 GPU 是否支持 bfloat16:
>>> torch.cuda.is_bf16_supported()True
如果你的 GPU 不支持 bfloat16,可以将 precisinotallow="bf16-mixed" 更改为 precisinotallow="16-mixed"。
接下来要尝试修改多 GPU 训练。如果我们有多个 GPU 可供使用,这会带来好处,因为它可以让我们的模型训练速度更快。
这里介绍一种更先进的技术 — 完全分片数据并行(Fully Sharded Data Parallelism (FSDP)),它同时利用了数据并行性和张量并行性。

在 Fabric 中,我们可以通过下面的方式利用 FSDP 添加设备数量和多 GPU 训练策略:
fabric = Fabric(accelerator="cuda", precisinotallow="bf16-mixed",devices=4, strategy="FSDP"# new!)
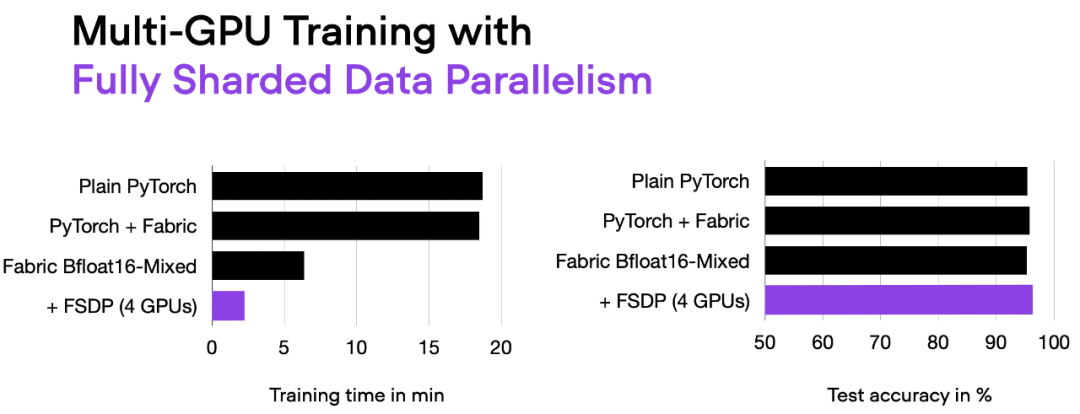
06_fabric-vit-mixed-fsdp.py 脚本的输出。
现在使用 4 个 GPU,我们的代码运行时间大约为 2 分钟,是之前仅使用混合精度训练时的近 3 倍。
在数据并行中,小批量数据被分割,并且每个 GPU 上都有模型的副本。这个过程通过多个 GPU 的并行工作来加速模型的训练速度。
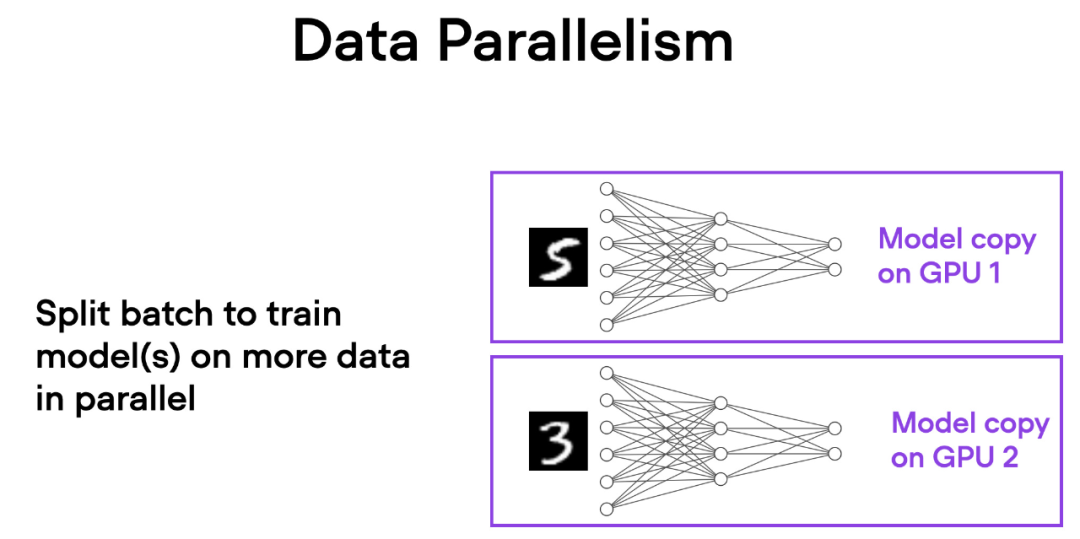
如下简要概述了数据并行的工作原理:
每个 GPU 都在并行地处理不同的数据子集,通过梯度的平均化和参数的更新,整个模型的训练过程得以加速。
这种方法的主要优势是速度。由于每个 GPU 同时处理不同的小批量数据,模型可以在更短的时间内处理更多的数据。这可以显著减少训练模型所需的时间,特别是在处理大型数据集时。
然而,数据并行也有一些限制。最重要的是,每个 GPU 必须具有完整的模型和参数副本。这限制了可以训练的模型大小,因为模型必须适应单个 GPU 的内存。这对于现代的 ViTs 或 LLMs 来说这是不可行的。
与数据并行不同,张量并行将模型本身划分到多个 GPU 上。并且在数据并行中,每个 GPU 都需要适 应整个模型,这在训练较大的模型时可能成为一个限制。而张量并行允许训练那些对单个 GPU 而言可能过大的模型,通过将模型分解并分布到多个设备上进行训练。
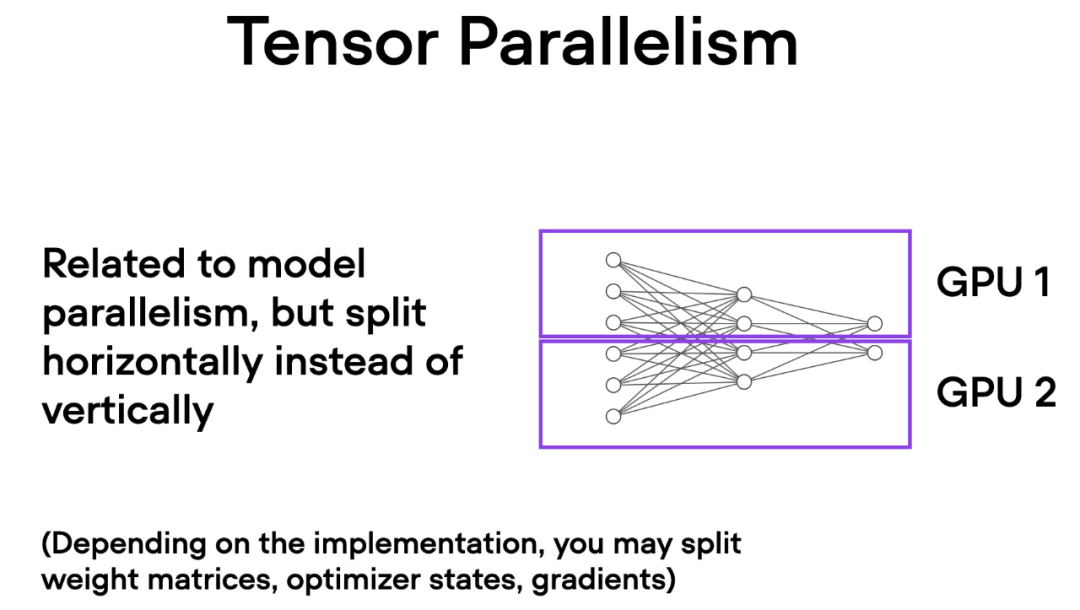
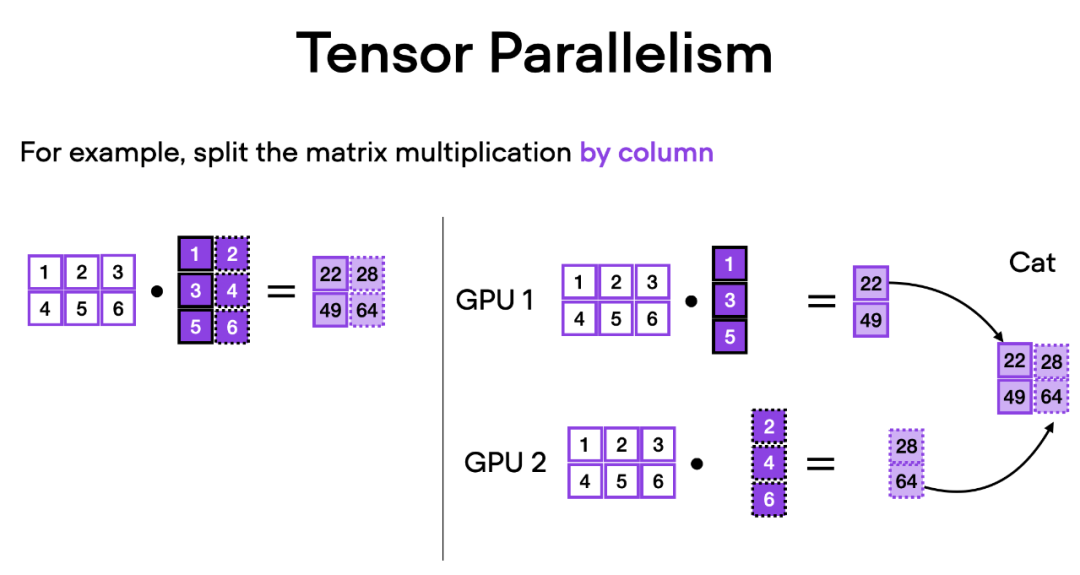
텐서 병렬 처리는 어떻게 작동하나요? 행렬 곱셈을 생각하면 분산 계산을 수행하는 방법에는 행 단위 또는 열 단위의 두 가지 방법이 있습니다. 단순화를 위해 열별 분포 계산을 고려하십시오. 예를 들어, 아래 그림과 같이 대규모 행렬 곱셈 연산을 여러 개의 독립적인 계산으로 분해할 수 있으며, 각 계산은 서로 다른 GPU에서 수행될 수 있습니다. 그런 다음 결과를 연결하여 결과를 얻으므로 계산 부하가 효과적으로 분산됩니다.
위 내용은 코드 한 줄만 바꾸면 PyTorch 학습 속도가 3배 빨라집니다. 이러한 '고급 기술'이 핵심입니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



