이 Python 크롤러를 사용하여 데이터를 수집할 때 매우 중요한 작업은 요청된 웹페이지에서 데이터를 추출하는 방법이며, 원하는 데이터를 올바르게 찾는 것이 첫 번째 단계입니다.
이 기사에서는 모든 사람이 배울 수 있도록 여러 Python 크롤러에서 웹 페이지 요소를 찾는 데 일반적으로 사용되는 방법을 비교합니다
“
TraditionalBeautifulSoup 작업 BeautifulSoup 操作
基于 BeautifulSoup 的 CSS 选择器(与 PyQuery 类似)
XPath
BeautifulSoup의 CSS 선택기(PyQuery 유사)
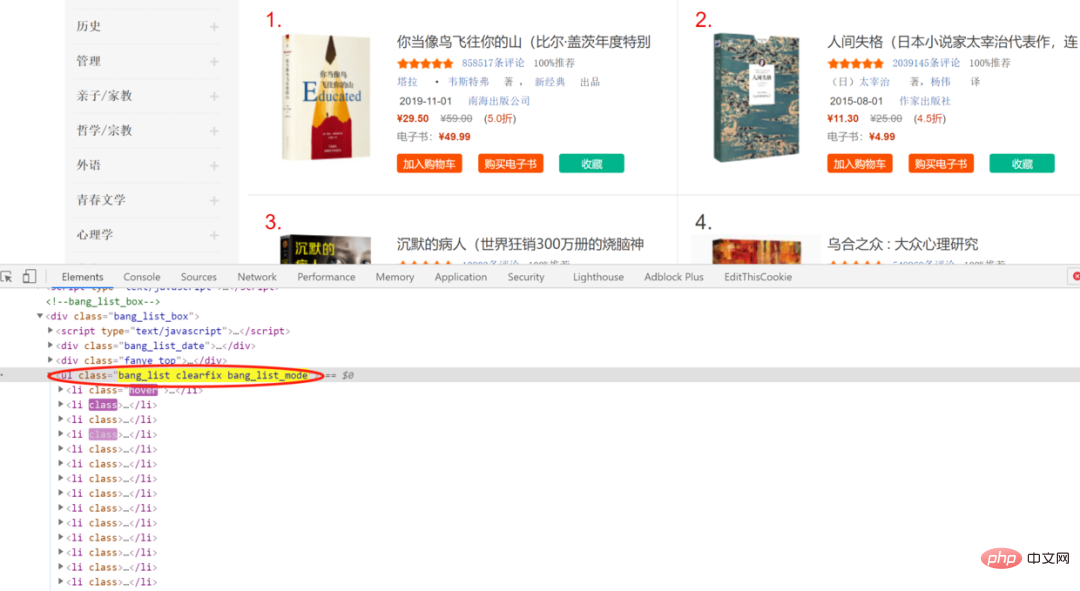
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'>http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1</pre><div class="contentsignin">로그인 후 복사</div></div><figure data-tool="mdnice编辑器" style="margin-top: 10px;margin-bottom: 10px;display: flex;flex-direction: column;justify-content: center;align-items: center;"><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/001/267/443/21d313e128464b6c1113677cb281678c-1.jpg" class="lazy"/ alt="Python 크롤러에 일반적으로 사용되는 네 가지 요소 찾기 방법을 비교했는데, 어떤 방법을 더 선호하시나요?" ></figure><p data-tool="mdnice编辑器" style="max-width:90%"> 처음 20권의 제목을 예로 들어보겠습니다. 먼저 웹사이트에 크롤링 방지 조치가 설정되어 있지 않은지, 분석할 콘텐츠를 직접 반환할 수 있는지 확인하세요. </p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'>import requests
url = &#39;http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1&#39;
response = requests.get(url).text
print(response)</pre><div class="contentsignin">로그인 후 복사</div></div><figure data-tool="mdnice编辑器" style="margin-top: 10px;margin-bottom: 10px;display: flex;flex-direction: column;justify-content: center;align-items: center;"><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/001/267/443/21d313e128464b6c1113677cb281678c-2.png" class="lazy"/ alt="Python 크롤러에 일반적으로 사용되는 네 가지 요소 찾기 방법을 비교했는데, 어떤 방법을 더 선호하시나요?" ></figure><p data-tool="mdnice编辑器" style="max-width:90%">신중하게 검사한 결과 반환된 항목에 필요한 데이터가 모두 포함되어 있는 것으로 확인되었습니다. 크롤링 방지 조치를 고려할 필요가 없음을 나타내는 콘텐츠 </p><p data-tool="mdnice编辑器" style="padding-top: 8px;padding-bottom: 8px;line-height: 26px;font-size: 16px;">웹 페이지 요소 검토 서지 정보는 <code style="padding: 2px 4px;border-radius: 4px;margin"에 포함되어 있음을 나중에 확인할 수 있습니다. -오른쪽: 2px;여백-왼쪽: 2px;배경색: rgba(27, 31, 35, 0.05); 글꼴 계열: "Operator Mono", Consolas, Monaco, Menlo, monospace;단어 나누기: 모두 중단 ;color: rgb(255, 100, 65);font-size: 13px;">li</code > in, <code style="padding: 2px 4px;border-radius: 4px;margin-right: 2px에 종속) ;여백-왼쪽: 2px;배경-색상: rgba(27, 31, 35, 0.05);글꼴- 계열: "Operator Mono", Consolas, Monaco, Menlo, monospace;단어 나누기: break-all;색상: rgb (255, 100, 65);글꼴 크기: 13px;">클래스는 bang_listclearfix bang_list_mode의ulli 中,从属于 class 为 bang_list clearfix bang_list_mode 的 ul 中
import requests
from bs4 import BeautifulSoup
from lxml import html
url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).text
def css_for_parse(response):
soup = BeautifulSoup(response, "lxml")
li_list = soup.select('ul.bang_list.clearfix.bang_list_mode > li')
for li in li_list:
title = li.select('div.name > a')[0]['title']
print(title)
if __name__ == '__main__':
css_for_parse(response)
로그인 후 복사
3. XPath
XPath 即为 XML 路径语言,它是一种用来确定 XML 文档中某部分位置的计算机语言,如果使用 Chrome 浏览器建议安装 XPath Helper 插件,会大大提高写 XPath 的效率。
之前的爬虫文章基本都是基于 XPath,大家相对比较熟悉因此代码直接给出:
import requests
from lxml import html
url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).text
def xpath_for_parse(response):
selector = html.fromstring(response)
books = selector.xpath("//ul[@class='bang_list clearfix bang_list_mode']/li")
for book in books:
title = book.xpath('div[@class="name"]/a/@title')[0]
print(title)
if __name__ == '__main__':
xpath_for_parse(response)
로그인 후 복사
4. 正则表达式
如果对 HTML 语言不熟悉,那么之前的几种解析方法都会比较吃力。这里也提供一种万能解析大法:正则表达式,只需要关注文本本身有什么特殊构造文法,即可用特定规则获取相应内容。依赖的模块是 re

클래식 BeautifulSoup 메서드는





 观察几个数目相信就有答案了:
观察几个数目相信就有答案了:














![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



