

Spring Boot는 MySQL 읽기-쓰기 분리 기술을 구현합니다.
읽기 및 쓰기 분리를 구현하는 방법은 Spring Boot 프로젝트이며 데이터베이스는 MySQL이고 지속성 레이어는 MyBatis를 사용합니다.
실제로 이를 구현하는 것은 매우 간단합니다. 먼저 질문에 대해 생각해 보세요.
고동시성 시나리오에서는 데이터베이스에 어떤 최적화 방법이 있습니까?
읽기-쓰기 분리, 캐싱, 마스터-슬레이브 아키텍처 클러스터, 하위 데이터베이스 및 하위 테이블 등의 구현 방법이 일반적으로 사용됩니다.
인터넷 애플리케이션에서는 대부분 독서를 많이 하고, 글쓰기를 적게 하고 있습니다. 메인 도서관과 독서 도서관, 두 개의 도서관이 마련되어 있습니다.
메인 라이브러리는 쓰기를 담당하고, 슬레이브 라이브러리는 읽기를 주로 담당합니다. 데이터 소스에서 읽기 및 쓰기 기능을 분리하여 읽기 및 쓰기 충돌을 줄이는 것이 목적입니다. , 데이터베이스 부하 완화 및 데이터베이스 보호를 달성할 수 있습니다. 실제 사용 시 쓰기와 관련된 모든 부분은 메인 라이브러리로 직접 전환되고, 읽기 부분은 읽기 라이브러리로 직접 전환되는 것이 전형적인 읽기-쓰기 분리 기술이다.
이 글에서는 읽기와 쓰기의 분리에 초점을 맞추고 이를 구현하는 방법을 살펴보겠습니다.
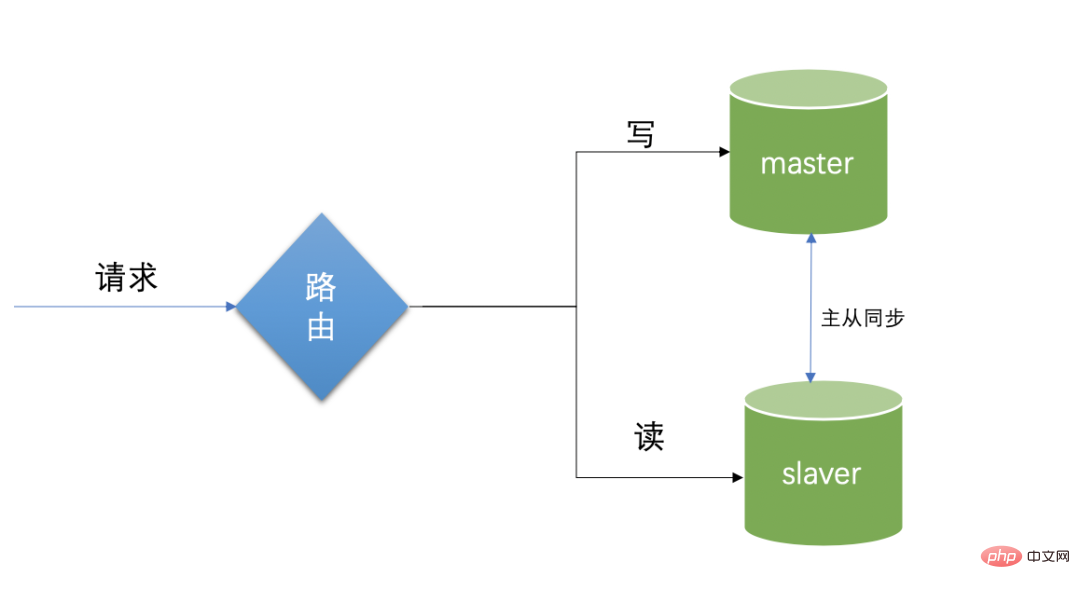
마스터-슬레이브 동기화의 한계: 마스터 데이터베이스와 슬레이브 데이터베이스로 나누어지며, 마스터 데이터베이스는 데이터 쓰기를 담당합니다. 데이터는 슬레이브 데이터베이스에 자동으로 동기화됩니다. 슬레이브 데이터베이스는 읽기 요청이 오면 읽기 데이터베이스에서 직접 데이터를 읽고, 마스터 데이터베이스는 자동으로 데이터를 슬레이브 데이터베이스에 복사합니다. 하지만 이 블로그에서는 운영 및 유지보수 작업에 더 중점을 두기 때문에 이 부분의 구성 지식을 소개하지 않습니다.
여기에 문제가 있습니다.
마스터-슬레이브 복제의 지연 문제. 메인 데이터베이스에 쓸 때 갑자기 읽기 요청이 오고 이때 데이터가 완전히 동기화되지 않아 읽기 요청이 나타납니다. 데이터를 읽을 수 없거나 읽은 데이터가 원래 값보다 작습니다. 가장 간단한 특정 솔루션은 읽기 요청을 일시적으로 메인 라이브러리로 지정하는 것이지만 동시에 마스터-슬레이브 분리 의미의 일부도 상실합니다. 즉, 데이터 일관성 시나리오의 엄격한 의미에서 읽기-쓰기 분리는 읽기-쓰기 분리 사용의 단점으로 인해 업데이트의 적시성에 주의해야 합니다.
좋습니다. 이 부분은 단지 이해를 돕기 위한 것입니다. 다음으로 Java 코드를 통해 읽기 및 쓰기 분리를 달성하는 방법을 살펴보겠습니다.
참고: 이 프로젝트에는 Spring Boot, spring-aop, spring-jdbc, aspectjweaver 등의 종속성을 도입해야 합니다.
프로그래머: 30일 밖에 안 남았는데 어떻게 준비해야 하나요?
1: 마스터-슬레이브 데이터 소스 구성
마스터-슬레이브 데이터베이스 구성은 일반적으로 구성 파일에 기록됩니다. @ConfigurationProperties 주석을 통해 구성 파일(일반적으로 이름: application.Properties)는 특정 클래스 속성에 매핑되어 작성된 값을 읽고 특정 코드 구성에 주입합니다. 습관이 관례보다 크다는 원칙에 따라 우리 모두는 메인 라이브러리에 다음과 같이 주석을 답니다. master, 슬레이브 라이브러리는 슬레이브로 표시됩니다. application.Properties)里的属性映射到具体的类属性上,从而读取到写入的值注入到具体的代码配置中,按照习惯大于约定的原则,主库我们都是注为 master,从库注为 slave。
本项目采用了阿里的 druid 数据库连接池,使用 build 建造者模式创建 DataSource 对象,DataSource 就是代码层面抽象出来的数据源,接着需要配置 sessionFactory、sqlTemplate、事务管理器等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
|
二: 数据源路由的配置
路由在主从分离是非常重要的,基本是读写切换的核心。Spring 提供了 AbstractRoutingDataSource 根据用户定义的规则选择当前的数据源,作用就是在执行查询之前,设置使用的数据源,实现动态路由的数据源,在每次数据库查询操作前执行它的抽象方法 determineCurrentLookupKey()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
AbstractRoutingDataSource 사용자 정의 규칙에 따라 현재 데이터 소스를 선택하는 기능은 쿼리를 실행하기 전에 사용되는 데이터 소스를 설정하고, 동적 라우팅의 데이터 소스를 구현하고, 각 데이터베이스 쿼리 작업 전에 해당 추상 메서드를 실행하는 것입니다.determineCurrentLookupKey() 사용할 데이터 소스를 결정합니다. 🎜🎜전역 데이터 소스 관리자를 갖기 위해서는 전역 변수로 이해되고 언제든지 액세스할 수 있는 데이터베이스 컨텍스트 관리자인 DataSourceContextHolder를 도입해야 합니다(아래 자세한 소개 참조). 현재 데이터를 저장합니다. 🎜1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
三:数据源上下文环境
数据源上下文保存器,便于程序中可以随时取到当前的数据源,它主要利用 ThreadLocal 封装,因为 ThreadLocal 是线程隔离的,天然具有线程安全的优势。这里暴露了 set 和 get、clear 方法,set 方法用于赋值当前的数据源名,get 方法用于获取当前的数据源名称,clear 方法用于清除 ThreadLocal 中的内容,因为 ThreadLocal 的 key 是 weakReference 是有内存泄漏风险的,通过 remove 方法防止内存泄漏。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
四:切换注解和 Aop 配置
首先我们来定义一个@DataSourceSwitcher 注解,拥有两个属性
① 当前的数据源② 是否清除当前的数据源,并且只能放在方法上,(不可以放在类上,也没必要放在类上,因为我们在进行数据源切换的时候肯定是方法操作),该注解的主要作用就是进行数据源的切换,在 dao 层进行操作数据库的时候,可以在方法上注明表示的是当前使用哪个数据源。
@DataSourceSwitcher 注解的定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
DataSourceAop配置:
为了赋予@DataSourceSwitcher 注解能够切换数据源的能力,我们需要使用 AOP,然后使用@Aroud 注解找到方法上有@DataSourceSwitcher.class 的方法,然后取注解上配置的数据源的值,设置到 DataSourceContextHolder 中,就实现了将当前方法上配置的数据源注入到全局作用域当中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
五:用法以及测试
在配置好了读写分离之后,就可以在代码中使用了,一般而言我们使用在 service 层或者 dao 层,在需要查询的方法上添加@DataSourceSwitcher(DataSourceEnum.SLAVE),它表示该方法下所有的操作都走的是读库。在需要 update 或者 insert 的时候使用@DataSourceSwitcher(DataSourceEnum.MASTER)表示接下来将会走写库。
其实还有一种更为自动的写法,可以根据方法的前缀来配置 AOP 自动切换数据源,比如 update、insert、fresh 等前缀的方法名一律自动设置为写库。select、get、query 等前缀的方法名一律配置为读库,这是一种更为自动的配置写法。缺点就是方法名需要按照 aop 配置的严格来定义,否则就会失效。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
|
六:总结
还是画张图来简单总结一下:
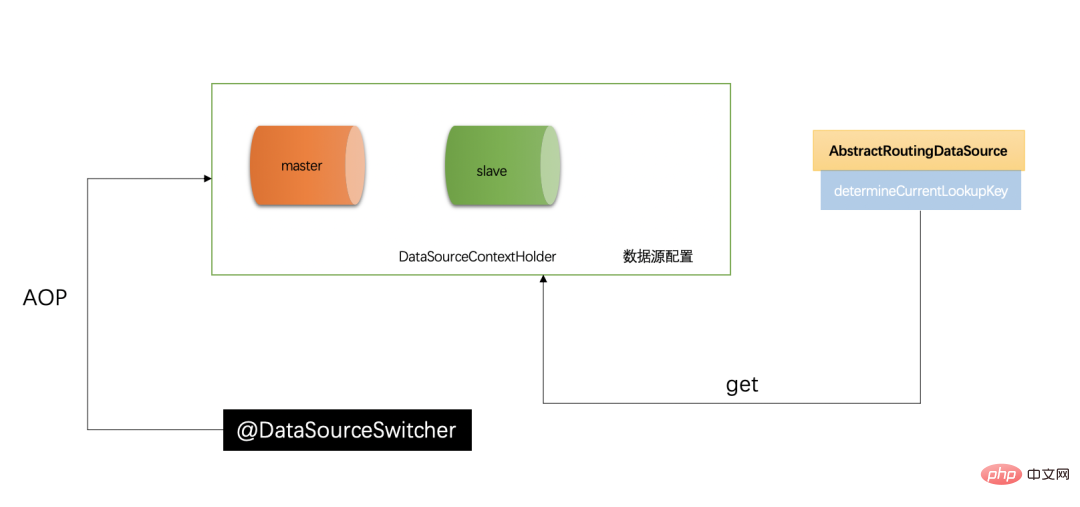
이 기사에서는 데이터베이스 읽기-쓰기 분리를 구현하는 방법을 소개합니다. 읽기-쓰기 분리의 핵심은 상속되어야 하는 데이터 라우팅이라는 점에 유의하세요. AbstractRoutingDataSource,复写它的 determineCurrentLookupKey ()方法。同时需要注意全局的上下文管理器 DataSourceContextHolder는 데이터 소스 컨텍스트를 저장하는 메인 클래스이기도 합니다. 라우팅 방법에서 찾은 데이터 소스 값입니다. 이는 데이터 소스의 전송 스테이션과 동일하며 jdbc-Template의 하위 계층과 결합되어 데이터 소스, 트랜잭션 등을 생성 및 관리하므로 데이터베이스 읽기 및 쓰기 분리가 완벽하게 실현됩니다.
위 내용은 Spring Boot는 MySQL 읽기-쓰기 분리 기술을 구현합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.
인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7542
7542
 15
1381
52
83
11
55
19
21
87
15
1381
52
83
11
55
19
21
87

 MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) 데이터베이스 및 테이블 작성 : CreateAbase 및 CreateTable 명령을 사용하십시오. 2) 기본 작업 : 삽입, 업데이트, 삭제 및 선택. 3) 고급 운영 : 가입, 하위 쿼리 및 거래 처리. 4) 디버깅 기술 : 확인, 데이터 유형 및 권한을 확인하십시오. 5) 최적화 제안 : 인덱스 사용, 선택을 피하고 거래를 사용하십시오.
 phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
다음 단계를 통해 phpmyadmin을 열 수 있습니다. 1. 웹 사이트 제어판에 로그인; 2. phpmyadmin 아이콘을 찾고 클릭하십시오. 3. MySQL 자격 증명을 입력하십시오. 4. "로그인"을 클릭하십시오.
 Navicat Premium을 만드는 방법
Apr 09, 2025 am 07:09 AM
Navicat Premium을 만드는 방법
Apr 09, 2025 am 07:09 AM
Navicat Premium을 사용하여 데이터베이스 생성 : 데이터베이스 서버에 연결하고 연결 매개 변수를 입력하십시오. 서버를 마우스 오른쪽 버튼으로 클릭하고 데이터베이스 생성을 선택하십시오. 새 데이터베이스의 이름과 지정된 문자 세트 및 Collation의 이름을 입력하십시오. 새 데이터베이스에 연결하고 객체 브라우저에서 테이블을 만듭니다. 테이블을 마우스 오른쪽 버튼으로 클릭하고 데이터 삽입을 선택하여 데이터를 삽입하십시오.
 MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템으로, 주로 데이터를 신속하고 안정적으로 저장하고 검색하는 데 사용됩니다. 작업 원칙에는 클라이언트 요청, 쿼리 해상도, 쿼리 실행 및 반환 결과가 포함됩니다. 사용의 예로는 테이블 작성, 데이터 삽입 및 쿼리 및 조인 작업과 같은 고급 기능이 포함됩니다. 일반적인 오류에는 SQL 구문, 데이터 유형 및 권한이 포함되며 최적화 제안에는 인덱스 사용, 최적화 된 쿼리 및 테이블 분할이 포함됩니다.
 MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL은 성능, 신뢰성, 사용 편의성 및 커뮤니티 지원을 위해 선택됩니다. 1.MYSQL은 효율적인 데이터 저장 및 검색 기능을 제공하여 여러 데이터 유형 및 고급 쿼리 작업을 지원합니다. 2. 고객-서버 아키텍처 및 다중 스토리지 엔진을 채택하여 트랜잭션 및 쿼리 최적화를 지원합니다. 3. 사용하기 쉽고 다양한 운영 체제 및 프로그래밍 언어를 지원합니다. 4. 강력한 지역 사회 지원을 받고 풍부한 자원과 솔루션을 제공합니다.
 Navicat에서 MySQL에 새로운 연결을 만드는 방법
Apr 09, 2025 am 07:21 AM
Navicat에서 MySQL에 새로운 연결을 만드는 방법
Apr 09, 2025 am 07:21 AM
응용 프로그램을 열고 새로운 연결 (Ctrl n)을 선택하여 Navicat에서 새로운 MySQL 연결을 만들 수 있습니다. "MySQL"을 연결 유형으로 선택하십시오. 호스트 이름/IP 주소, 포트, 사용자 이름 및 비밀번호를 입력하십시오. (선택 사항) 고급 옵션을 구성합니다. 연결을 저장하고 연결 이름을 입력하십시오.
 단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
Redis는 단일 스레드 아키텍처를 사용하여 고성능, 단순성 및 일관성을 제공합니다. 동시성을 향상시키기 위해 I/O 멀티플렉싱, 이벤트 루프, 비 블로킹 I/O 및 공유 메모리를 사용하지만 동시성 제한 제한, 단일 고장 지점 및 쓰기 집약적 인 워크로드에 부적합한 제한이 있습니다.
 MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL은 개발자에게 필수적인 기술입니다. 1.MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템이며 SQL은 데이터베이스를 관리하고 작동하는 데 사용되는 표준 언어입니다. 2.MYSQL은 효율적인 데이터 저장 및 검색 기능을 통해 여러 스토리지 엔진을 지원하며 SQL은 간단한 문을 통해 복잡한 데이터 작업을 완료합니다. 3. 사용의 예에는 기본 쿼리 및 조건 별 필터링 및 정렬과 같은 고급 쿼리가 포함됩니다. 4. 일반적인 오류에는 구문 오류 및 성능 문제가 포함되며 SQL 문을 확인하고 설명 명령을 사용하여 최적화 할 수 있습니다. 5. 성능 최적화 기술에는 인덱스 사용, 전체 테이블 스캔 피하기, 조인 작업 최적화 및 코드 가독성 향상이 포함됩니다.
