
면접에서 면접관은 MySQL의 ACID에 대해서만 질문하면 즉시 8부작 에세이를 암송할 수 있습니다(아직 답변하지 못하는 사람도 있을 수 있습니다). 더욱 역겨운 점은 일부 면접관이 루틴을 따르지 않고 계속 질문한다는 것입니다. MySQL은 ACID를 어떻게 구현합니까?
솔직히 이 질문은 95%의 사람들을 설득할 수 있습니다.
오늘 이 글에서는 주로 MySQL InnoDB 엔진 하의 ACID 구현 원리에 대해 논의합니다. 트랜잭션이 무엇인지, 격리 수준이 무엇인지와 같은 기본 지식에 대해서는 자세히 설명하지 않습니다.
관계형 데이터베이스로서 MySQL은 가장 일반적인 InnoDB 엔진 측면에서 ACID를 어떻게 보장합니까?
먼저 격리에 대해 이야기해 보겠습니다. 첫 번째는 4가지 격리 수준입니다.
격리 수준 제출 후 변경 사항은 다른 거래에서 볼 수 있습니다| 반복 읽기 | 트랜잭션에서 다른 트랜잭션이 데이터에 대해 작동하는지 여부와 트랜잭션이 커밋되는지 여부에 관계없이 동일한 데이터를 읽은 결과는 항상 동일합니다. InnoDB 기본 레벨. |
| 직렬화 | 트랜잭션은 순차적으로 실행됩니다. 각 읽기는 테이블 수준 공유 잠금을 획득해야 합니다. 읽기와 쓰기는 서로를 차단하며 시스템 동시성을 희생합니다. |
다양한 격리 수준은 다양한 문제를 해결하기 위한 것입니다. 즉, 더티 읽기(dirty read), 팬텀 읽기(phantom read), 반복 불가능 읽기가 해당됩니다.
| 隔离级别 | 脏读 | 不可重复读 | 幻读ㅋㅋㅋ | 반복읽기
|---|---|---|---|
| 출연 가능 | |||
| 직렬화 | 허용되지 않음 | 허용되지 않음 | 허용되지 않음 |
그렇다면 서로 다른 격리 수준은 어떻게 이루어지며, 서로 다른 것들이 서로 간섭하지 않는 이유는 무엇일까요? 대답은 Locks 및 MVCC입니다.
먼저 MySQL에는 몇 개의 잠금이 있는지 이야기해 보겠습니다.
세분성이란 테이블 잠금, 페이지 잠금, 행 잠금을 의미합니다. 테이블 잠금에는 의도적인 공유 잠금, 의도적인 배타적 잠금, 자체 증가 잠금 등이 포함됩니다. 행 잠금은 엔진 수준에서 각 엔진에 의해 구현됩니다. 그러나 모든 엔진이 행 잠금을 지원하는 것은 아닙니다. 예를 들어 MyISAM 엔진은 행 잠금을 지원하지 않습니다.
InnoDB 트랜잭션에서 행 잠금은 인덱스의 인덱스 항목을 잠그는 방식으로 구현됩니다. 즉, InnoDB는 인덱스 조건을 통해 데이터를 검색할 때만 행 수준 잠금을 사용하고, 그렇지 않으면 테이블 잠금을 사용합니다. 행 수준 잠금도 공유 잠금과 배타 잠금의 두 가지 유형으로 나뉘며, 잠금 전에 획득해야 하는 의도 공유 잠금과 의도 배타 잠금도 있습니다.
선택...공유 모드에서 잠금 잠금. select...lock in share mode 加锁。insert、update、delete、for update삽입, 업데이트, 삭제, 업데이트잠금. 행 잠금은 필요할 때
추가되지만 더 이상 필요하지 않을 때 즉시 해제되지 않고 거래가 끝날 때까지 해제되지 않습니다. 이는 2단계 잠금 프로토콜입니다. 🎜🎜단일 행 레코드에 대한 잠금은 항상 인덱스 레코드를 잠급니다.
Gap Lock, 팬텀 읽기의 이유를 생각해 보세요. 사실 행 잠금은 행만 잠글 수 있지만 새 레코드를 삽입할 때 업데이트해야 할 것은 레코드 사이의 "간격"입니다. 팬텀 리딩 문제를 해결하려면 간격 잠금 기능을 추가하세요.
Gap Lock + Record Lock, 열린 상태 및 닫힌 상태 유지.
하부 자물쇠에 대한 일반적인 소개를 보실 수 있습니다. 잠금을 사용하면 트랜잭션이 데이터를 쓸 때 다른 트랜잭션이 쓰기 잠금을 얻을 수 없고 데이터를 쓸 수 없습니다. 이렇게 하면 트랜잭션 간 격리가 어느 정도 보장됩니다. 그런데 앞서 언급한 것처럼 쓰기 잠금을 추가하면 왜 다른 트랜잭션도 데이터를 읽을 수 있는 걸까요? 읽기 잠금을 얻을 수 없는 것 아닌가요? 앞서 언급했듯이 잠금을 사용하면 현재 트랜잭션은 쓰기 잠금 없이 데이터를 수정할 수 없지만 읽을 때는 다른 트랜잭션에 의해 데이터 행이 수정되어 제출된 경우에도 여전히 읽을 수 있습니다. 동일한 행은 여전히 반복해서 읽을 수 있습니다. 이것이 바로 MVCC, 다중 버전 동시성 제어, 다중 버전 동시성 제어입니다. 몇 가지 추가 필드가 포함된 Innodb의 행 레코드 저장 형식: DATA_TRX_ID 및 DATA_ROLL_PTR. undo 로그: 데이터가 수정되기 전의 로그를 기록합니다. 자세한 내용은 나중에 설명하겠습니다. 은 각 SQL의 시작 부분에 생성되며 몇 가지 중요한 속성이 있습니다. 이제 쿼리를 시작하면 선택 항목이 나오고 데이터 행이 발견됩니다. DATA_TRX_ID DATA_TRX_ID >= low_limit_id: MVCC
버전 체인
undo log에 연결 목록 형식으로 구성됩니다. 
ReadView
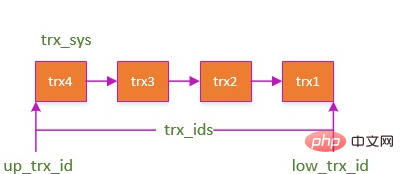
쿼리 시작
현재 읽기 뷰가 생성된 후 데이터가 생성되며, 해당 데이터가 표시되지 않음을 나타냅니다.
up_limit_id
잠금 및 MVCC를 사용하면 트랜잭션 격리가 해결됩니다. 여기에서 확장해 보겠습니다. 기본 RR 수준이 팬텀 판독을 해결합니까? 가상 읽기는 일반적으로 INSERT 및 반복 불가능한 대상 UPDATE를 대상으로 합니다.
| thing 1 | thing 2 |
|---|---|
| begin | begin |
| select * from dept | |
| - | 부서(이름) 값에 삽입("A") |
| - | commit |
| update dept set name="B" | |
| commit |
|
우리는
id name 1 A 2 B
id name 1 B 2 B
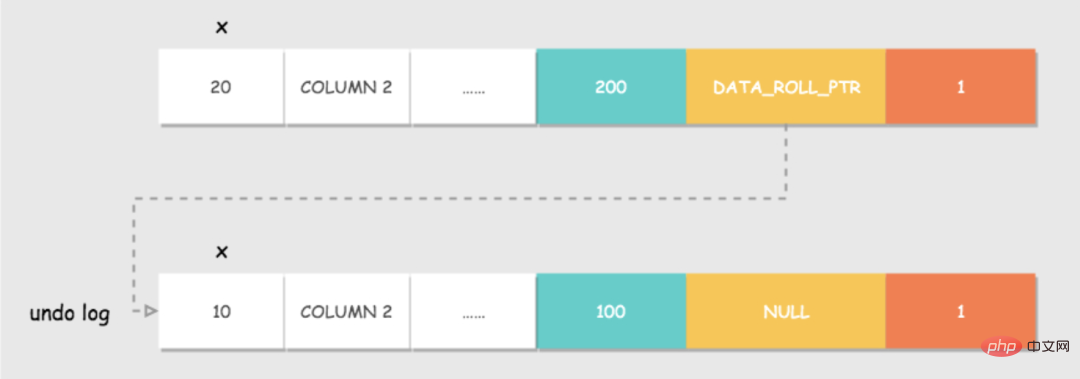
원자성에 대해 이야기해 봅시다. 앞서 언급했듯이 실행 취소 로그는 로그를 롤백합니다. 격리 MVCC는 원자성과 마찬가지로 실제로 이를 달성하기 위해 의존합니다. 원자성을 달성하는 핵심은 트랜잭션이 롤백될 때 성공적으로 실행된 모든 SQL 문을 실행 취소할 수 있는 것입니다.
트랜잭션이 데이터베이스를 수정하면 InnoDB는 해당 실행 취소 로그를 생성합니다. 트랜잭션 실행이 실패하거나 롤백이 호출되어 트랜잭션이 롤백되는 경우 실행 취소 로그의 정보를 사용하여 데이터를 롤백할 수 있습니다. 수정 전의 모습입니다. Undo 로그는 SQL 실행과 관련된 정보를 기록하는 논리적 로그이다. 롤백이 발생하면 InnoDB는 실행 취소 로그의 내용을 기반으로 이전 작업과 반대되는 작업을 수행합니다.
업데이트 작업을 예로 들어 보겠습니다. 트랜잭션이 업데이트를 실행할 때 생성된 실행 취소 로그에는 수정된 행의 기본 키(수정된 행을 알기 위해), 수정된 열, 및 수정 전과 후의 해당 열의 값을 롤백할 때 이 정보를 사용하여 업데이트 전 상태로 데이터를 복원할 수 있습니다.
Innnnodb에는 많은 로그가 있으며 지속성은 다시 실행 로그에 의존합니다.
지속성은 확실히 쓰기와 관련이 있습니다. MySQL에서 자주 언급되는 WAL 기술의 전체 이름은 Write-Ahead Logging입니다. 그 핵심은 로그를 먼저 작성한 다음 기록하는 것입니다. 디스크. 작은 가게에서 장사를 하는 것처럼 핑크색 판과 장부가 있어서 손님이 오면 먼저 핑크색 판에 글을 쓰고, 바쁘지 않을 때는 장부를 적는다.
redo 로그는 이 분홍색 보드입니다. 레코드를 업데이트해야 할 때 InnoDB 엔진은 먼저 해당 레코드를 리두 로그에 기록하고(그리고 메모리를 업데이트합니다) 업데이트가 완료됩니다. 적절한 시기에 이 작업 기록이 디스크에 업데이트되며, 이 업데이트는 가게 주인이 문을 닫은 후 하는 것과 마찬가지로 시스템이 상대적으로 유휴 상태일 때 수행되는 경우가 많습니다.
redo 로그에는 두 가지 기능이 있습니다:
리두 로그에는 커밋과 준비의 두 단계가 있습니다. "2단계 커밋"을 사용하지 않으면 데이터베이스 상태입니다. 로그에서 복구된 라이브러리의 상태가 일치하지 않습니다. 먼저 여기로 가서 다른 것을 살펴보겠습니다.
InnoDB는 캐시도 제공합니다. 버퍼 풀에는 데이터베이스 액세스를 위한 버퍼 역할을 하는 디스크의 일부 데이터 페이지 매핑이 포함되어 있습니다.
버퍼 풀을 사용하면 데이터 읽기 및 쓰기 효율성이 크게 향상되지만 새로운 문제도 발생합니다. MySQL이 다운되고 버퍼 풀의 수정된 데이터가 디스크에 플러시되지 않은 경우 데이터가 분실, 거래의 지속성이 보장되지 않습니다.
그래서 Redo Log에 가입하게 되었습니다. 데이터가 수정되면 버퍼 풀의 데이터가 수정되는 것 외에도 작업이 리두 로그에도 기록됩니다.
트랜잭션이 제출되면 fsync 인터페이스가 호출되어 리두 로그를 플러시합니다.
MySQL이 다운되면 redo 로그의 데이터를 읽고 재시작 시 데이터베이스를 복원할 수 있습니다.
redo 로그는 WAL(미리 쓰기 로깅, 미리 쓰기 로그)을 사용합니다. 모든 수정 사항은 먼저 로그에 기록된 다음 버퍼 풀에 업데이트되므로 MySQL 가동 중지 시간으로 인해 데이터가 손실되지 않으므로 내구성이 충족됩니다. 필요하다. 이렇게 하면 두 가지 이점이 있습니다.
이렇게 말하면 쓰기 작업에도 사용되며 데이터 복구에도 사용되는 bin 로그가 있다는 것이 궁금할 것입니다.
왜 Redo 로그를 먼저 작성하나요?
일관성은 트랜잭션이 추구하는 궁극적인 목표입니다. 이전 질문에서 언급한 원자성, 지속성 및 격리성은 실제로 데이터베이스 상태의 일관성을 보장하기 위한 것입니다. 물론 위의 내용은 모두 데이터베이스 수준에서 보장되는 것이며 일관성을 구현하려면 애플리케이션 수준에서도 보장이 필요합니다.
즉, 예를 들어 귀하의 비즈니스에서 구매 작업은 사용자의 잔고만 차감하고 재고를 줄이지 않는 상태를 유지하는 것은 절대 불가능합니다.
우리 모두는 MySQL에 익숙하고 ACID가 무엇인지도 알고 있습니다. 그런데 MySQL의 ACID는 어떻게 구현되나요?
때로는 Undo 로그와 Redo 로그가 있다는 것을 알지만 왜 그것이 있는지 모를 때도 있습니다. 디자인의 목적을 알면 더 명확해질 것입니다.
위 내용은 인터뷰어: MySQL은 ACID를 어떻게 구현합니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



