

Meituan 인터뷰: MySQL을 사용하면서 어떤 함정에 직면했습니까?
인터뷰어: 당신은 여전히 잠금에 대해 꽤 잘 이해하고 있습니다.
루키 나: (살짝 웃으며 대답함)
인터뷰어: 오랫동안 MySQL을 사용해오면서 결코 잊지 못할 함정이 무엇입니까?
루키 나 : 발라발라가 이야기를 시작했다. (이런 면접질문은 면접 전에 미리 준비해놨으니 물을 뿌린다.)
아래에는 실제 경험을 바탕으로 표준화된 데이터베이스 개발 사용법을 정리했다. 6 "피하십시오"로 요약합니다. 避免”来概括。
1、避免在数据库中做运算
有句话叫做“别让脚趾头想事情,那是脑瓜子的职责”,用在数据库开发中,说的就是避免让数据库做她不擅长的事情。MySQL
1. 데이터베이스에서 계산을 하지 마세요
"발끝으로 생각하지 마십시오. 그것은 두뇌의 책임입니다"는 데이터베이스 개발에 사용되며 데이터베이스가 그렇지 않은 일을 하도록 허용하지 않는다는 의미입니다. 잘한다. MySQL은 수학적 연산과 논리에 능숙하지 않습니다. 판단하므로 데이터베이스에서 계산을 하지 않도록 하세요. 복잡한 계산은 프로그램 측 CPU로 옮겨질 수 있습니다. 🎜🎜🎜2. 인덱스 열에 대한 작업을 피하세요🎜🎜 🎜🎜🎜한 번은 동료가 포그라운드에서 쿼리하는 것이 매우 빠르다며 SQL을 살펴보라고 요청했지만 SQL을 꺼내면 데이터베이스에서 실행했는데 10분 동안 실행해도 결과가 나오지 않았습니다. SQL을 살펴본 후 마침내 뷰에서 하위 쿼리를 찾았습니다. 이 하위 쿼리의 SQL 텍스트는 다음과 같습니다. 🎜## 以下SQL来源于网络
SELECT acinv_07.id_item ,
SUM(acinv_07.dec_endqty) dec_endqty
FROM acinv_07
WHERE acinv_07.fiscal_year * 100 + acinv_07.fiscal_period
= ( SELECT DISTINCT
ctlm1101.fiscal_year * 100 + ctlm1101.fiscal_period
FROM ctlm1101 WHERE flag_curr = 'Y'
AND id_oprcode = 'acinv'
AND acinv_07.id_wh = ctlm1101.id_table)
GROUP BY acinv_07.id_itemacinv_07 테이블의 회계_연도 열과 회계_기간 열이 인덱싱됩니다. 그러나 인덱스 열에 대해 작업을 수행하면 인덱스를 생성할 수 있었던 항목에 대해 인덱스를 사용할 수 없습니다. 그래서 다음 SQL로 다시 작성했습니다.
## 以下SQL来源于网络
SELECT id_item ,
SUM(dec_qty) dec_qty
FROM dpurreq_03
GROUP BY id_item
) a ,
( SELECT a.id_item ,
SUM(a.dec_endqty) dec_endqty
FROM acinv_07 a ,
( SELECT DISTINCT
ctlm1101.fiscal_year ,
ctlm1101.fiscal_period ,
id_table
FROM ctlm1101
WHERE flag_curr = 'Y'
AND id_oprcode = 'acinv'
) b
WHERE a.fiscal_year = b.fiscal_year
AND a.fiscal_period = b.fiscal_period
AND a.id_wh = b.id_table
GROUP BY a.id_item그런 다음 실행하면 약 4초 후에 결과가 나타납니다. 일반적으로 SQL을 작성할 때 꼭 필요한 경우가 아니면 인덱스 열에 대한 계산을 수행하지 마십시오.
3. count(*)를 피하세요
페이징 쿼리를 수행할 때 일부 사람들은 항상 총 레코드 수를 얻기 위해 select count()를 사용하는 데 익숙합니다. , 이전에 데이터를 한 번 쿼리한 적이 있기 때문에 select count()는 동일한 문을 두 번 쿼리하는 것과 동일하며 데이터베이스에 대한 오버헤드는 당연히 커집니다. 또는 시스템과 함께 제공되는 API를 사용해야 합니다. 작업을 완료하는 데 필요한 변수입니다.
4. NULL 필드 사용을 피하세요
모든 사람은 데이터베이스 테이블 필드를 디자인할 때 NOT NULL DEFAULT'를 추가해야 합니다. NULL 필드를 사용하면 쿼리를 최적화하기 어렵고, NULL 열에 인덱스를 추가하려면 추가 공간이 필요하며, NULL을 포함하는 복합 인덱스는 유효하지 않은 등 많은 나쁜 영향을 미칩니다.
다음 사례를 살펴보세요.
数据初始化:
create table table1 (
`id` INT (11) NOT NULL,
`name` varchar(20) NOT NULL
)
create table table2 (
`id` INT (11) NOT NULL,
`name` varchar(20)
)
insert into table1 values (4,"tianweichang"),(2,"zhangsan"),(3,"lisi")
insert into table2 values (1,"tianweichang"),(2, null)(1) NOT IN 하위 쿼리는 NULL 값이 있는 경우 항상 빈 결과를 반환하고 쿼리에 오류가 발생하기 쉽습니다
select name from table1 where name not in (select name from table2 where id!=1)
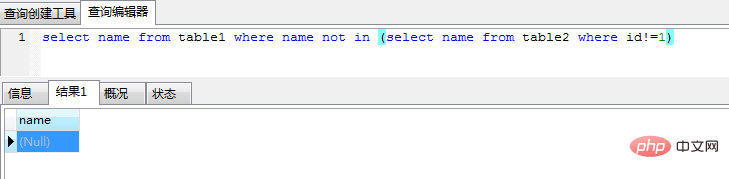
(2) 열 값 비어 있을 수 있으며 인덱스는 null 값을 저장하지 않으며 이러한 레코드는 결과 집합에 포함되지 않습니다.
select * from table2 where name != 'tianweichang'
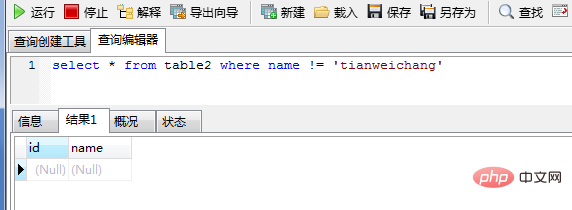
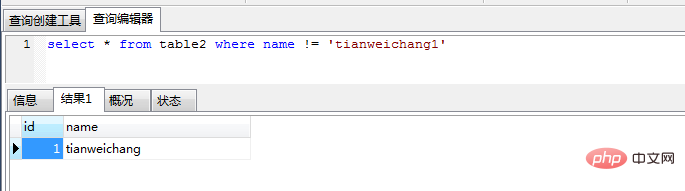
select * from table2 where name != 'zhaoyun1'
(3) concat 스플라이싱을 사용할 때 먼저 각 필드에 대해 null이 아닌 판단을 내려야 합니다. 그렇지 않으면 필드가 비어 있는 한, 접합 결과는 null입니다
select concat("1", null) from dual;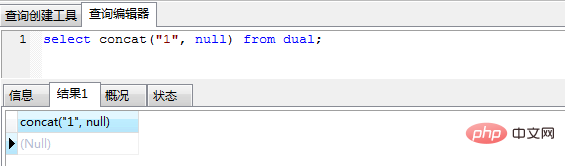
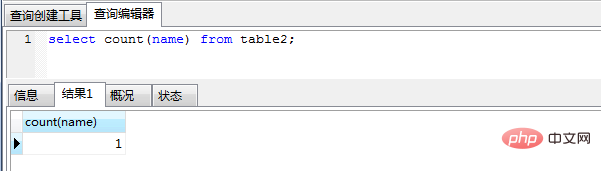
(4) 当计算count时候,name为null 的不会计入统计
select count(name) from table2;
5、避免select
使用 select *可能会返回不使用的列的数据。它在MySQL数据库服务器和应用程序之间产生不必要的I/O磁盘和网络流量。如果明确指定列,则结果集更可预测并且更易于管理。想象一下,当您使用 select *并且有人通过添加更多列来更改表格数据时,将会得到一个与预期不同的结果集。使用 select *可能会将敏感信息暴露给未经授权的用户。
6、避免在数据库里存图片
图片确实是可以存储到数据库里的,例如通过二进制流将图片存到数据库中。
但是,强烈不建议把图片存储到数据库中!!!!首先对数据库的读/写的速度永远都赶不上文件系统处理的速度,其次数据库备份变的巨大,越来越耗时间,最后对文件的访问需要穿越你的应用层和数据库层。
위 내용은 Meituan 인터뷰: MySQL을 사용하면서 어떤 함정에 직면했습니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7323
7323
 9
1625
14
1350
46
1262
25
1209
29
9
1625
14
1350
46
1262
25
1209
29

 PHP의 빅데이터 구조 처리 능력
May 08, 2024 am 10:24 AM
PHP의 빅데이터 구조 처리 능력
May 08, 2024 am 10:24 AM
빅 데이터 구조 처리 기술: 청킹(Chunking): 데이터 세트를 분할하고 청크로 처리하여 메모리 소비를 줄입니다. 생성기: 전체 데이터 세트를 로드하지 않고 데이터 항목을 하나씩 생성하므로 무제한 데이터 세트에 적합합니다. 스트리밍: 파일을 읽거나 결과를 한 줄씩 쿼리하므로 대용량 파일이나 원격 데이터에 적합합니다. 외부 저장소: 매우 큰 데이터 세트의 경우 데이터를 데이터베이스 또는 NoSQL에 저장합니다.
 PHP에서 MySQL 쿼리 성능을 최적화하는 방법은 무엇입니까?
Jun 03, 2024 pm 08:11 PM
PHP에서 MySQL 쿼리 성능을 최적화하는 방법은 무엇입니까?
Jun 03, 2024 pm 08:11 PM
선형 복잡성에서 로그 복잡성까지 조회 시간을 줄이는 인덱스를 구축하여 MySQL 쿼리 성능을 최적화할 수 있습니다. SQL 삽입을 방지하고 쿼리 성능을 향상하려면 PREPAREDStatements를 사용하세요. 쿼리 결과를 제한하고 서버에서 처리되는 데이터의 양을 줄입니다. 적절한 조인 유형 사용, 인덱스 생성, 하위 쿼리 사용 고려 등 조인 쿼리를 최적화합니다. 쿼리를 분석하여 병목 현상을 식별하고, 캐싱을 사용하여 데이터베이스 로드를 줄이고, 오버헤드를 최소화합니다.
 PHP에서 MySQL 백업 및 복원을 사용하는 방법은 무엇입니까?
Jun 03, 2024 pm 12:19 PM
PHP에서 MySQL 백업 및 복원을 사용하는 방법은 무엇입니까?
Jun 03, 2024 pm 12:19 PM
PHP에서 MySQL 데이터베이스를 백업하고 복원하는 작업은 다음 단계에 따라 수행할 수 있습니다. 데이터베이스 백업: mysqldump 명령을 사용하여 데이터베이스를 SQL 파일로 덤프합니다. 데이터베이스 복원: mysql 명령을 사용하여 SQL 파일에서 데이터베이스를 복원합니다.
 PHP를 사용하여 MySQL 테이블에 데이터를 삽입하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:26 PM
PHP를 사용하여 MySQL 테이블에 데이터를 삽입하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:26 PM
MySQL 테이블에 데이터를 삽입하는 방법은 무엇입니까? 데이터베이스에 연결: mysqli를 사용하여 데이터베이스에 대한 연결을 설정합니다. SQL 쿼리 준비: 삽입할 열과 값을 지정하는 INSERT 문을 작성합니다. 쿼리 실행: query() 메서드를 사용하여 삽입 쿼리를 실행하면 확인 메시지가 출력됩니다.
 MySQL 8.4에서 mysql_native_password가 로드되지 않음 오류를 수정하는 방법
Dec 09, 2024 am 11:42 AM
MySQL 8.4에서 mysql_native_password가 로드되지 않음 오류를 수정하는 방법
Dec 09, 2024 am 11:42 AM
MySQL 8.4(2024년 최신 LTS 릴리스)에 도입된 주요 변경 사항 중 하나는 "MySQL 기본 비밀번호" 플러그인이 더 이상 기본적으로 활성화되지 않는다는 것입니다. 또한 MySQL 9.0에서는 이 플러그인을 완전히 제거합니다. 이 변경 사항은 PHP 및 기타 앱에 영향을 미칩니다.
 PHP에서 MySQL 저장 프로시저를 사용하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:13 PM
PHP에서 MySQL 저장 프로시저를 사용하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:13 PM
PHP에서 MySQL 저장 프로시저를 사용하려면: PDO 또는 MySQLi 확장을 사용하여 MySQL 데이터베이스에 연결합니다. 저장 프로시저를 호출하는 문을 준비합니다. 저장 프로시저를 실행합니다. 결과 집합을 처리합니다(저장 프로시저가 결과를 반환하는 경우). 데이터베이스 연결을 닫습니다.
 PHP를 사용하여 MySQL 테이블을 만드는 방법은 무엇입니까?
Jun 04, 2024 pm 01:57 PM
PHP를 사용하여 MySQL 테이블을 만드는 방법은 무엇입니까?
Jun 04, 2024 pm 01:57 PM
PHP를 사용하여 MySQL 테이블을 생성하려면 다음 단계가 필요합니다. 데이터베이스에 연결합니다. 데이터베이스가 없으면 작성하십시오. 데이터베이스를 선택합니다. 테이블을 생성합니다. 쿼리를 실행합니다. 연결을 닫습니다.
 오라클 데이터베이스와 mysql의 차이점
May 10, 2024 am 01:54 AM
오라클 데이터베이스와 mysql의 차이점
May 10, 2024 am 01:54 AM
Oracle 데이터베이스와 MySQL은 모두 관계형 모델을 기반으로 하는 데이터베이스이지만 호환성, 확장성, 데이터 유형 및 보안 측면에서 Oracle이 우수하고, MySQL은 속도와 유연성에 중점을 두고 중소 규모 데이터 세트에 더 적합합니다. ① Oracle은 광범위한 데이터 유형을 제공하고, ② 고급 보안 기능을 제공하고, ③ 엔터프라이즈급 애플리케이션에 적합하고, ① MySQL은 NoSQL 데이터 유형을 지원하고, ② 보안 조치가 적고, ③ 중소 규모 애플리케이션에 적합합니다.
