

Python에서 요청 모듈 사용

Requests는 다양한 HTTP 요청을 보내는 데 사용할 수 있는 Python 모듈입니다. URL의 매개변수 전달부터 사용자 정의 헤더 전송 및 SSL 확인에 이르기까지 다양한 기능을 갖춘 사용하기 쉬운 라이브러리입니다. 이 튜토리얼에서는 이 라이브러리를 사용하여 Python에서 간단한 HTTP 요청을 보내는 방법을 배웁니다.
Python 버전 2.6~2.7 및 3.3~3.6에서 요청을 사용할 수 있습니다. 계속하기 전에 Requests가 외부 모듈이라는 점을 알아야 하므로 이 튜토리얼의 예제를 시도하기 전에 이를 설치해야 합니다. 터미널에서 다음 명령을 실행하여 설치할 수 있습니다.
으아아아모듈을 설치한 후 다음 명령을 사용하여 모듈을 가져와서 성공적으로 설치되었는지 확인할 수 있습니다.
으아아아설치가 성공하면 오류 메시지가 표시되지 않습니다.
GET 요청하기
요청을 사용하면 HTTP 요청을 보내는 것이 매우 쉽습니다. 먼저 모듈을 가져온 다음 요청합니다. 예는 다음과 같습니다.
으아아아요청에 대한 모든 정보는 이제 요청의 상태 코드를 가져오는 req 的响应对象中。例如,您可以使用 req.encoding 属性获取网页的编码。您还可以使用 req.status_code라는 속성에 저장됩니다.
응답 헤더의 req.cookies 访问服务器发回的 cookie。同样,您可以使用 req.headers 获取响应标头。 req.headers 属性返回响应标头的不区分大小写的字典。这意味着 req.headers['Content-Length']、req.headers['content-length'] 和 req。 headers['CONTENT-LENGTH'] 都会返回 'Content-Length' 값을 사용할 수 있습니다.
req.is_redirect 属性自动处理。它将根据响应返回 True 或 False 。您还可以使用 req.elapsed 속성을 사용하여 요청을 보낸 후 응답을 받는 데 소요된 시간을 가져오면 응답이 올바른 형식의 HTTP 리디렉션인지 확인할 수 있습니다.
처음에는 여러 가지 이유로(리디렉션 포함) get() 函数的 URL 可能与响应的最终 URL 不同。要查看最终的响应 URL,您可以使用 req.url 속성을 전달하고 있습니다.
방문 중인 웹 페이지에 대한 모든 정보를 알고 있다는 것은 좋지만 실제 콘텐츠에 액세스하고 싶을 가능성이 높습니다. 액세스하는 콘텐츠가 텍스트인 경우 req.text 属性来访问它。然后内容被解析为 unicode。您可以使用 req.encoding 속성을 사용하여 텍스트를 디코딩하는 데 사용되는 인코딩을 전달할 수 있습니다.
텍스트가 아닌 응답의 경우 req.content 以二进制形式访问它们。该模块将自动解码 gzip 和 deflate 传输编码。当您处理媒体文件时,这会很有帮助。同样,您可以使用 req.json()를 사용하여 json으로 인코딩된 응답 콘텐츠(있는 경우)에 액세스할 수 있습니다.
req.raw 从服务器获取原始响应。请记住,您必须在请求中传递 stream=True를 사용하여 원래 응답을 얻을 수도 있습니다.
요청 모듈을 사용하여 인터넷에서 다운로드하는 일부 파일은 용량이 클 수 있습니다. 이 경우 전체 응답이나 파일을 메모리에 즉시 로드하는 것은 현명하지 않습니다. iter_content(chunk_size = 1,decode_unicode=False) 방법을 사용하여 파일을 청크 또는 청크로 다운로드할 수 있습니다.
이 방법을 한 번 반복하면 chunk_size 字节数中的响应数据。当请求上设置了 stream=True 时,此方法将避免一次将整个文件读入内存以获得大量响应。 chunk_size 参数可以是整数,也可以是 None。当设置为整数值时,chunk_size 메모리로 읽어야 하는 바이트 수를 결정합니다.
chunk_size 设置为 None 且 stream 设置为 True 时,数据将被读取为无论收到的块大小如何,它都会到达。当 chunk_size 设置为 None 且 stream 设置为 False 이면 모든 데이터가 단일 청크로 반환됩니다.
요청 모듈을 사용하여 버섯 이미지를 다운로드해 보겠습니다. 실제 이미지는 다음과 같습니다.

필요한 코드는 다음과 같습니다.
import requests
req = requests.get('path/to/mushrooms.jpg', stream=True)
req.raise_for_status()
with open('mushrooms.jpg', 'wb') as fd:
for chunk in req.iter_content(chunk_size=50000):
print('Received a Chunk')
fd.write(chunk)
'path/to/mushrooms.jpg' 是实际的图像 URL。您可以将任何其他图像的 URL 放在这里来下载其他内容。给定的图像文件大小为 162kb,并且您已将 chunk_size 设置为 50,000 字节。这意味着“Received a Chunk”消息应在终端中打印四次。最后一个块的大小将仅为 32350 字节,因为前三次迭代后仍待接收的文件部分为 32350 字节。
您还可以用类似的方式下载视频。我们可以简单地将其值设置为 None,而不是指定固定的 chunk_size,然后视频将以提供的任何块大小下载。以下代码片段将从 Mixkit 下载高速公路的视频:
import requests
req = requests.get('path/to/highway/video.mp4', stream=True)
req.raise_for_status()
with open('highway.mp4', 'wb') as fd:
for chunk in req.iter_content(chunk_size=None):
print('Received a Chunk')
fd.write(chunk)
尝试运行代码,您将看到视频作为单个块下载。
如果您决定使用 stream 参数,则应记住以下几点。响应正文的下载会被推迟,直到您使用 content 属性实际访问其值。这样,如果某些标头值之一看起来不正确,您就可以避免下载文件。
另请记住,在将流的值设置为 True 时启动的任何连接都不会关闭,除非您消耗所有数据或使用 close() 方法。确保连接始终关闭的更好方法是在 with 语句中发出请求,即使您部分读取了响应,如下所示:
import requests
with requests.get('path/to/highway/video.mp4', stream=True) as rq:
with open('highway.mp4', 'wb') as fd:
for chunk in rq.iter_content(chunk_size=None):
print('Received a Chunk')
fd.write(chunk)
由于我们之前下载的图片文件比较小,您也可以使用以下代码一次性下载:
import requests
req = requests.get('path/to/mushrooms.jpg')
req.raise_for_status()
with open('mushrooms.jpg', 'wb') as fd:
fd.write(req.content)
我们跳过了设置 stream 参数的值,因此默认设置为 False。这意味着所有响应内容将立即下载。借助 content 属性,将响应内容捕获为二进制数据。
请求还允许您在 URL 中传递参数。当您在网页上搜索某些结果(例如特定图像或教程)时,这会很有帮助。您可以使用 GET 请求中的 params 关键字将这些查询字符串作为字符串字典提供。这是一个例子:
import requests
query = {'q': 'Forest', 'order': 'popular', 'min_width': '800', 'min_height': '600'}
req = requests.get('https://pixabay.com/en/photos/', params=query)
req.url
# returns 'https://pixabay.com/en/photos/?order=popular&min_height=600&q=Forest&min_width=800'
发出 POST 请求
发出 POST 请求与发出 GET 请求一样简单。您只需使用 post() 方法而不是 get() 即可。当您自动提交表单时,这会很有用。例如,以下代码将向 httpbin.org 域发送 post 请求,并将响应 JSON 作为文本输出。
import requests
req = requests.post('https://httpbin.org/post', data = {'username': 'monty', 'password': 'something_complicated'})
req.raise_for_status()
print(req.text)
'''
{
"args": {},
"data": "",
"files": {},
"form": {
"password": "something_complicated",
"username": "monty"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "45",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-63ad437e-67f5db6a161314861484f2eb"
},
"json": null,
"origin": "YOUR.IP.ADDRESS",
"url": "https://httpbin.org/post"
}
'''
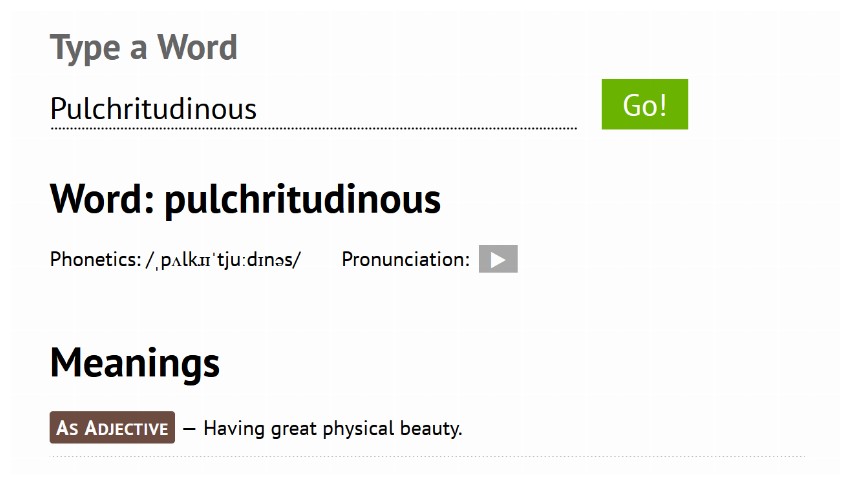
您可以将这些 POST 请求发送到任何可以处理它们的 URL。举个例子,我的一位朋友创建了一个网页,用户可以在其中输入单词并使用 API 获取其含义以及发音和其他信息。我们可以用我们查询的单词向URL发出POST请求,然后将结果保存为HTML页面,如下所示:
import requests
word = 'Pulchritudinous'
filename = word.lower() + '.html'
req = requests.post('https://tutorialio.com/tools/dictionary.php', data = {'query': word})
req.raise_for_status()
with open(filename, 'wb') as fd:
fd.write(req.content)
执行上面的代码,它会返回一个包含该单词信息的页面,如下图所示。
发送 Cookie 和标头
如前所述,您可以使用 req.cookies 和 req.headers 访问服务器发回给您的 cookie 和标头。请求还允许您通过请求发送您自己的自定义 cookie 和标头。当您想要为您的请求设置自定义用户代理时,这会很有帮助。
要将 HTTP 标头添加到请求中,您只需将它们通过 dict 传递到 headers 参数即可。同样,您还可以使用传递给 cookies 参数的 dict 将自己的 cookie 发送到服务器。
import requests
url = 'http://some-domain.com/set/cookies/headers'
headers = {'user-agent': 'your-own-user-agent/0.0.1'}
cookies = {'visit-month': 'February'}
req = requests.get(url, headers=headers, cookies=cookies)
Cookie 也可以在 Cookie Jar 中传递。它们提供了更完整的界面,允许您通过多个路径使用这些 cookie。这是一个例子:
import requests
jar = requests.cookies.RequestsCookieJar()
jar.set('first_cookie', 'first', domain='httpbin.org', path='/cookies')
jar.set('second_cookie', 'second', domain='httpbin.org', path='/extra')
jar.set('third_cookie', 'third', domain='httpbin.org', path='/cookies')
url = 'http://httpbin.org/cookies'
req = requests.get(url, cookies=jar)
req.text
# returns '{ "cookies": { "first_cookie": "first", "third_cookie": "third" }}'
会话对象
有时,在多个请求中保留某些参数很有用。 Session 对象正是这样做的。例如,它将在使用同一会话发出的所有请求中保留 cookie 数据。 Session 对象使用 urllib3 的连接池。这意味着底层 TCP 连接将被重复用于向同一主机发出的所有请求。这可以显着提高性能。您还可以将 Requests 对象的方法与 Session 对象一起使用。
以下是使用和不使用会话发送的多个请求的示例:
import requests
reqOne = requests.get('https://tutsplus.com/')
reqOne.cookies['_tuts_session']
#returns 'cc118d94a84f0ea37c64f14dd868a175'
reqTwo = requests.get('https://code.tutsplus.com/tutorials')
reqTwo.cookies['_tuts_session']
#returns '3775e1f1d7f3448e25881dfc35b8a69a'
ssnOne = requests.Session()
ssnOne.get('https://tutsplus.com/')
ssnOne.cookies['_tuts_session']
#returns '4c3dd2f41d2362108fbb191448eab3b4'
reqThree = ssnOne.get('https://code.tutsplus.com/tutorials')
reqThree.cookies['_tuts_session']
#returns '4c3dd2f41d2362108fbb191448eab3b4'
正如您所看到的,会话cookie在第一个和第二个请求中具有不同的值,但当我们使用Session对象时它具有相同的值。当您尝试此代码时,您将获得不同的值,但在您的情况下,使用会话对象发出的请求的 cookie 将具有相同的值。
当您想要在所有请求中发送相同的数据时,会话也很有用。例如,如果您决定将 cookie 或用户代理标头与所有请求一起发送到给定域,则可以使用 Session 对象。这是一个例子:
import requests
ssn = requests.Session()
ssn.cookies.update({'visit-month': 'February'})
reqOne = ssn.get('http://httpbin.org/cookies')
print(reqOne.text)
# prints information about "visit-month" cookie
reqTwo = ssn.get('http://httpbin.org/cookies', cookies={'visit-year': '2017'})
print(reqTwo.text)
# prints information about "visit-month" and "visit-year" cookie
reqThree = ssn.get('http://httpbin.org/cookies')
print(reqThree.text)
# prints information about "visit-month" cookie
如您所见,"visit-month" 会话 cookie 随所有三个请求一起发送。但是, "visit-year" cookie 仅在第二次请求期间发送。第三个请求中也没有提及 "vist-year" cookie。这证实了单个请求上设置的 cookie 或其他数据不会与其他会话请求一起发送。
结论
本教程中讨论的概念应该可以帮助您通过传递特定标头、cookie 或查询字符串来向服务器发出基本请求。当您尝试抓取网页以获取信息时,这将非常方便。现在,一旦您找出 URL 中的模式,您还应该能够自动从不同的网站下载音乐文件和壁纸。
学习 Python
无论您是刚刚入门还是希望学习新技能的经验丰富的程序员,都可以通过我们完整的 Python 教程指南学习 Python。
위 내용은 Python에서 요청 모듈 사용의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7487
7487
 15
1377
52
77
11
51
19
19
39
15
1377
52
77
11
51
19
19
39

 MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL에는 무료 커뮤니티 버전과 유료 엔터프라이즈 버전이 있습니다. 커뮤니티 버전은 무료로 사용 및 수정할 수 있지만 지원은 제한되어 있으며 안정성이 낮은 응용 프로그램에 적합하며 기술 기능이 강합니다. Enterprise Edition은 안정적이고 신뢰할 수있는 고성능 데이터베이스가 필요하고 지원 비용을 기꺼이 지불하는 응용 프로그램에 대한 포괄적 인 상업적 지원을 제공합니다. 버전을 선택할 때 고려 된 요소에는 응용 프로그램 중요도, 예산 책정 및 기술 기술이 포함됩니다. 완벽한 옵션은없고 가장 적합한 옵션 만 있으므로 특정 상황에 따라 신중하게 선택해야합니다.
 설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
이 기사는 MySQL 데이터베이스의 작동을 소개합니다. 먼저 MySQLworkBench 또는 명령 줄 클라이언트와 같은 MySQL 클라이언트를 설치해야합니다. 1. MySQL-Uroot-P 명령을 사용하여 서버에 연결하고 루트 계정 암호로 로그인하십시오. 2. CreateABase를 사용하여 데이터베이스를 작성하고 데이터베이스를 선택하십시오. 3. CreateTable을 사용하여 테이블을 만들고 필드 및 데이터 유형을 정의하십시오. 4. InsertInto를 사용하여 데이터를 삽입하고 데이터를 쿼리하고 업데이트를 통해 데이터를 업데이트하고 DELETE를 통해 데이터를 삭제하십시오. 이러한 단계를 마스터하고 일반적인 문제를 처리하는 법을 배우고 데이터베이스 성능을 최적화하면 MySQL을 효율적으로 사용할 수 있습니다.
 고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
MySQL 데이터베이스 성능 최적화 안내서 리소스 집약적 응용 프로그램에서 MySQL 데이터베이스는 중요한 역할을 수행하며 대규모 트랜잭션 관리를 담당합니다. 그러나 응용 프로그램 규모가 확장됨에 따라 데이터베이스 성능 병목 현상은 종종 제약이됩니다. 이 기사는 일련의 효과적인 MySQL 성능 최적화 전략을 탐색하여 응용 프로그램이 고 부하에서 효율적이고 반응이 유지되도록합니다. 실제 사례를 결합하여 인덱싱, 쿼리 최적화, 데이터베이스 설계 및 캐싱과 같은 심층적 인 주요 기술을 설명합니다. 1. 데이터베이스 아키텍처 설계 및 최적화 된 데이터베이스 아키텍처는 MySQL 성능 최적화의 초석입니다. 몇 가지 핵심 원칙은 다음과 같습니다. 올바른 데이터 유형을 선택하고 요구 사항을 충족하는 가장 작은 데이터 유형을 선택하면 저장 공간을 절약 할 수있을뿐만 아니라 데이터 처리 속도를 향상시킬 수 있습니다.
 hadidb : 파이썬의 가볍고 수평 확장 가능한 데이터베이스
Apr 08, 2025 pm 06:12 PM
hadidb : 파이썬의 가볍고 수평 확장 가능한 데이터베이스
Apr 08, 2025 pm 06:12 PM
HADIDB : 가볍고 높은 수준의 확장 가능한 Python 데이터베이스 HadIDB (HADIDB)는 파이썬으로 작성된 경량 데이터베이스이며 확장 수준이 높습니다. PIP 설치를 사용하여 HADIDB 설치 : PIPINSTALLHADIDB 사용자 관리 사용자 만들기 사용자 : createUser () 메소드를 작성하여 새 사용자를 만듭니다. Authentication () 메소드는 사용자의 신원을 인증합니다. Fromhadidb.operationimportuseruser_obj = user ( "admin", "admin") user_obj.
 MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 기본 데이터 저장 및 관리를위한 네트워크 연결없이 실행할 수 있습니다. 그러나 다른 시스템과의 상호 작용, 원격 액세스 또는 복제 및 클러스터링과 같은 고급 기능을 사용하려면 네트워크 연결이 필요합니다. 또한 보안 측정 (예 : 방화벽), 성능 최적화 (올바른 네트워크 연결 선택) 및 데이터 백업은 인터넷에 연결하는 데 중요합니다.
 MongoDB 데이터베이스 비밀번호를 보는 Navicat의 방법
Apr 08, 2025 pm 09:39 PM
MongoDB 데이터베이스 비밀번호를 보는 Navicat의 방법
Apr 08, 2025 pm 09:39 PM
해시 값으로 저장되기 때문에 MongoDB 비밀번호를 Navicat을 통해 직접 보는 것은 불가능합니다. 분실 된 비밀번호 검색 방법 : 1. 비밀번호 재설정; 2. 구성 파일 확인 (해시 값이 포함될 수 있음); 3. 코드를 점검하십시오 (암호 하드 코드 메일).
 MySQL Workbench가 Mariadb에 연결할 수 있습니다
Apr 08, 2025 pm 02:33 PM
MySQL Workbench가 Mariadb에 연결할 수 있습니다
Apr 08, 2025 pm 02:33 PM
MySQL Workbench는 구성이 올바른 경우 MariadB에 연결할 수 있습니다. 먼저 커넥터 유형으로 "mariadb"를 선택하십시오. 연결 구성에서 호스트, 포트, 사용자, 비밀번호 및 데이터베이스를 올바르게 설정하십시오. 연결을 테스트 할 때는 마리아드 브 서비스가 시작되었는지, 사용자 이름과 비밀번호가 올바른지, 포트 번호가 올바른지, 방화벽이 연결을 허용하는지 및 데이터베이스가 존재하는지 여부를 확인하십시오. 고급 사용에서 연결 풀링 기술을 사용하여 성능을 최적화하십시오. 일반적인 오류에는 불충분 한 권한, 네트워크 연결 문제 등이 포함됩니다. 오류를 디버깅 할 때 오류 정보를 신중하게 분석하고 디버깅 도구를 사용하십시오. 네트워크 구성을 최적화하면 성능이 향상 될 수 있습니다
 MySQL에는 서버가 필요합니까?
Apr 08, 2025 pm 02:12 PM
MySQL에는 서버가 필요합니까?
Apr 08, 2025 pm 02:12 PM
생산 환경의 경우 성능, 신뢰성, 보안 및 확장 성을 포함한 이유로 서버는 일반적으로 MySQL을 실행해야합니다. 서버에는 일반적으로보다 강력한 하드웨어, 중복 구성 및 엄격한 보안 조치가 있습니다. 소규모 저하 애플리케이션의 경우 MySQL이 로컬 컴퓨터에서 실행할 수 있지만 자원 소비, 보안 위험 및 유지 보수 비용은 신중하게 고려되어야합니다. 신뢰성과 보안을 높이려면 MySQL을 클라우드 또는 기타 서버에 배포해야합니다. 적절한 서버 구성을 선택하려면 응용 프로그램 부하 및 데이터 볼륨을 기반으로 평가가 필요합니다.
