
로케이터 xpath를 사용하여 검색 텍스트가 있는 요소를 식별할 수 있습니다
또는 공백이 있습니다. 먼저 웹 요소의 HTML 코드를 살펴보겠습니다. 후행 및 선행 공백. 아래 이미지에는 JAVA BASICS라는 텍스트가 있습니다. HTML 코드에 반영된 것처럼 Strong 태그 이름에는 공백이 포함되어 있습니다.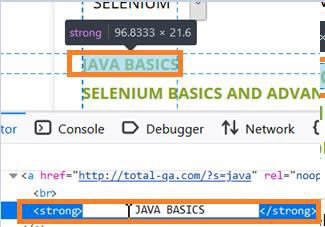
요소의 텍스트나 속성 값에 공백이 있는 경우 생성됩니다. 그러한 요소의 xpath에 대해서는 정규화된 공간 함수를 사용해야 합니다. 그것 문자열에서 모든 후행 및 선행 공백을 제거합니다. 또한 모든 것을 제거합니다. 새 레이블 또는 문자열의 기존 줄입니다.
//tagname[normalize-space(@attribute/ function) = 'value']
페이지에 나타나는 웹 요소 JAVA BASICS의 경우 xpath//를 생성해 보겠습니다. Strong[text()='JAVA BASICS'] (텍스트의 공백은 고려되지 않습니다). 만약 우리가 확인하려면 콘솔에서 $x("//strong[text()='JAVA' 표현식을 사용하세요. BASICS']"), 일치하는 요소(길이가 0으로 식별됨)가 없다는 것을 알게 됩니다.
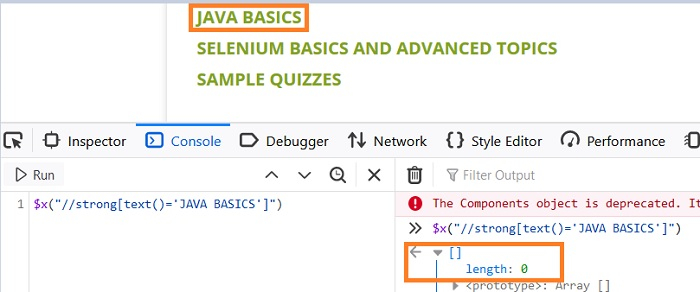
이제 Normalize-space 함수를 사용하여 xpath 표현식을 생성해 보겠습니다. xpath 표현식은 - //strong[normalize-space(text())='JAVA BASICS'].

콘솔에서 표현식을 사용하여 검증하는 경우 - $x("// Strong[standardized) 공간 ( text())='JAVA BASICS']"), 일치하는 항목을 찾습니다. 요소(길이 - 1로 식별됨)
얻은 결과 위로 마우스를 가져가면 JAVA BASICS가 가져오는 텍스트를 찾을 수 있습니다. 페이지를 강조 표시합니다.
위 내용은 XPATH를 사용하여 가 포함된 텍스트 검색의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



