
VLDB 2023 국제 컨퍼런스가 캐나다 밴쿠버에서 성공적으로 개최되었습니다. VLDB 컨퍼런스는 데이터베이스 분야에서 오랜 역사를 지닌 3대 컨퍼런스 중 하나로, 정식 명칭은 국제대규모데이터베이스컨퍼런스(International Large-Scale Database Conference)이다. 각 컨퍼런스는 데이터베이스 연구의 최신 방향과 업계 최신 기술, 다양한 국가의 R&D 수준을 전시하는 데 중점을 두고 있으며, 세계 최고의 연구 기관의 제출을 유치하고 있습니다.

이 컨퍼런스는 시스템 혁신에 중점을 두고, 완성도, 실험 설계 다른 측면에서도 요구 사항이 매우 높습니다. VLDB의 논문 승인률은 일반적으로 약 18%로 낮으며, 기여도가 큰 논문만 승인될 가능성이 높습니다. 올해 경쟁은 더욱 치열하다. 공식 자료에 따르면 올해 최우수 논문상을 받은 VLDB 논문은 스탠퍼드대학교, 카네기멜론대학교, 마이크로소프트 리서치, VM웨어 리서치, 메타 등 세계적으로 유명한 대학, 연구기관, 기술 대기업 등이다. 이들 중 4Paradigm과 칭화대학교, 싱가포르 국립대학교가 공동으로 완성한 논문 "FEBench: A Benchmark for Real-Time Relational Data Feature Extraction"이 최고의 산업 논문으로 Runner Up 상을 받았습니다.
 이 논문은 4Paradigm, Tsinghua University 및 National University of Singapore의 공동 작업입니다. 본 논문에서는 머신러닝 기반의 실시간 의사결정 시스템을 평가하는 데 사용되는 업계 실제 시나리오 축적을 기반으로 한 실시간 특징 계산 테스트 벤치마크를 제안합니다. 논문을 보려면 다음 링크를 클릭하세요. //github.com/decis -bench/febench/blob/main/report/febench.pdf
이 논문은 4Paradigm, Tsinghua University 및 National University of Singapore의 공동 작업입니다. 본 논문에서는 머신러닝 기반의 실시간 의사결정 시스템을 평가하는 데 사용되는 업계 실제 시나리오 축적을 기반으로 한 실시간 특징 계산 테스트 벤치마크를 제안합니다. 논문을 보려면 다음 링크를 클릭하세요. //github.com/decis -bench/febench/blob/main/report/febench.pdf
프로젝트 주소: https://github.com/decis-bench/febench
다시 작성해야 할 내용은 다음과 같습니다. 프로젝트 주소는 https://github.com/decis-bench/febench
프로젝트 배경
재작성된 콘텐츠: 그림 1. 사기 방지 애플리케이션에서 실시간 특징 계산 적용
일반적으로 실시간 특징 계산 플랫폼은 다음 두 가지 기본 요구 사항을 충족해야 합니다.
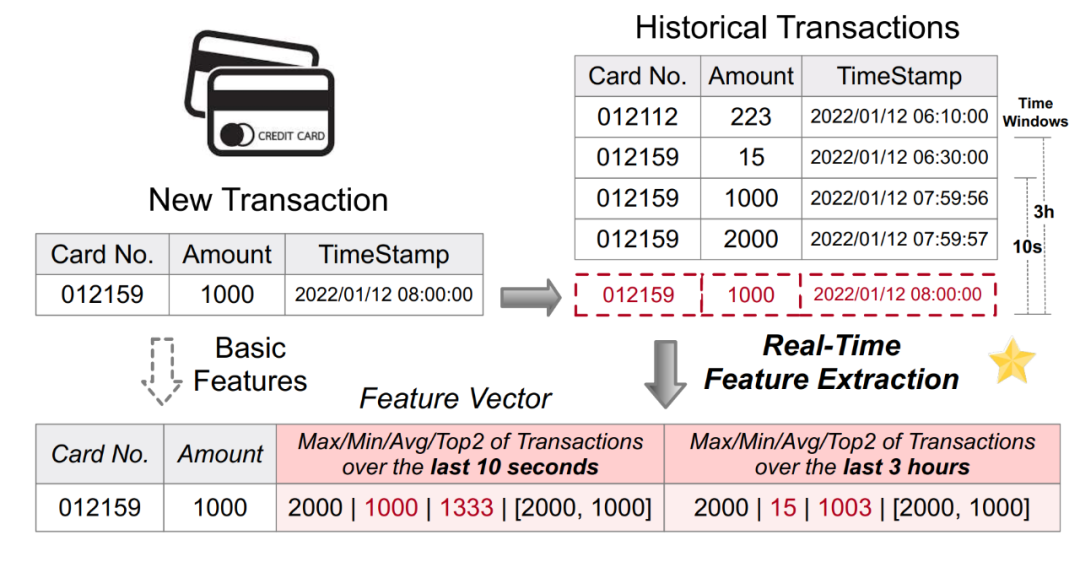
온라인 서비스의 효율성: 온라인 서비스는 실시간 데이터 및 계산을 목표로 하며 짧은 대기 시간, 높은 동시성 및 고가용성 요구 사항을 충족합니다.
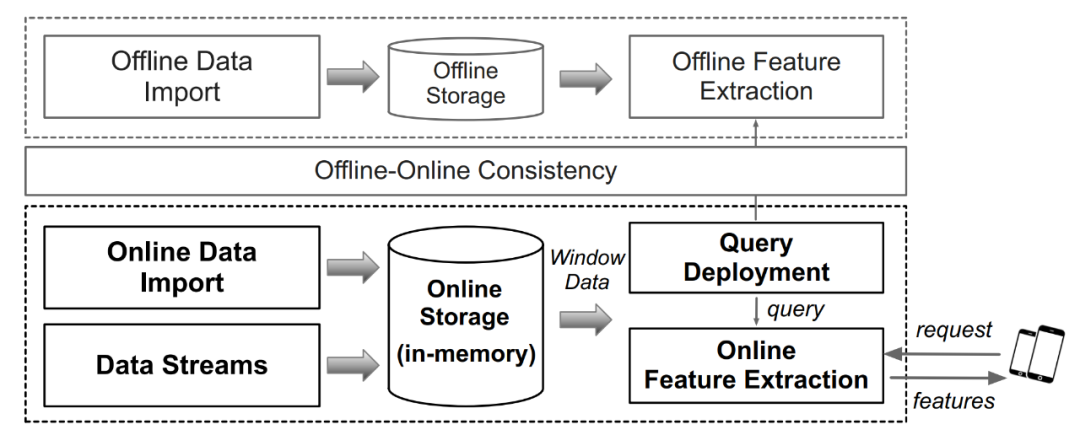 기술 원리
기술 원리
FEBench의 벤치마크 구성에는 주로 세 가지 작업 측면이 포함됩니다. 데이터 세트 수집, 쿼리 생성 콘텐츠를 다시 작성해야 하며, 콘텐츠를 다시 작성할 때 적절한 템플릿을 선택해야 합니다
데이터 세트 수집
연구팀은 실시간 특징 계산 시나리오에 사용할 수 있는 총 118개의 데이터 세트를 수집했습니다. 이러한 데이터 세트는 Kaggle, Tianchi, UCI ML, KiltHub 및 금융, 소매, 의료, 제조, 운송 및 기타 산업 시나리오와 같은 산업계의 일반적인 사용 시나리오를 다루는 네 번째 패러다임 내의 내부 공개 데이터입니다. 연구팀은 수집된 데이터 세트를 아래 그림 3과 같이 테이블 수와 데이터 세트 크기에 따라 더 분류했습니다.
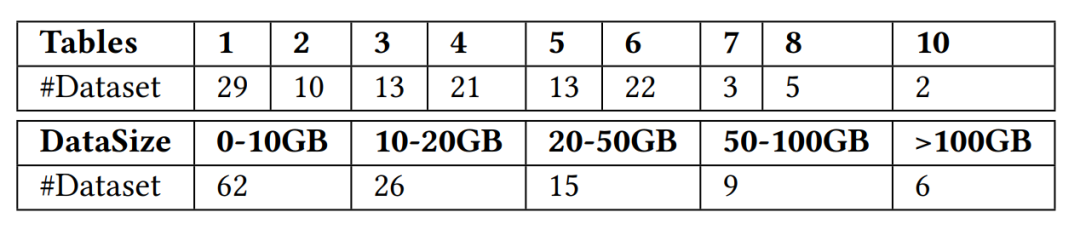
재작성된 내용: FEBench에서 설정한 테이블 수와 데이터 크기에 대한 차트는 다음과 같습니다.
쿼리로 생성된 내용을 재작성해야 합니다
용량이 크기 때문에 각 데이터에 대한 데이터 세트 수 수동으로 생성된 특징 추출의 계산 논리 작업량이 매우 크기 때문에 연구원들은 AutoCross와 같은 자동 기계 학습 기술을 사용했습니다(참고 논문: AutoCross: Automated Feature Crossing for Tabular Data in Real-World Application). 수집된 데이터를 Set으로 제공하면 자동으로 쿼리가 생성됩니다. FEBench의 기능 선택 및 쿼리 생성 콘텐츠를 다시 작성해야 합니다(아래 그림 4 참조).
기본 테이블(스트리밍 데이터 저장)과 보조 테이블(예: 정적 테이블)을 식별합니다. / 추가/스냅샷 테이블)을 초기화할 수 있습니다. 이어서, 1차 테이블과 2차 테이블에서 이름이 비슷하거나 키 관계가 유사한 컬럼을 분석하고, 컬럼 간의 일대일/일대다 관계를 열거하며, 이는 서로 다른 기능 작동 모드에 해당합니다.
열 관계를 특성 연산자에 매핑합니다.
모든 후보 특징을 추출한 후 Beam 검색 알고리즘을 사용하여 반복적으로 효과적인 특징 세트를 생성합니다.
선택한 기능은 의미상 동일한 SQL 쿼리로 변환됩니다.
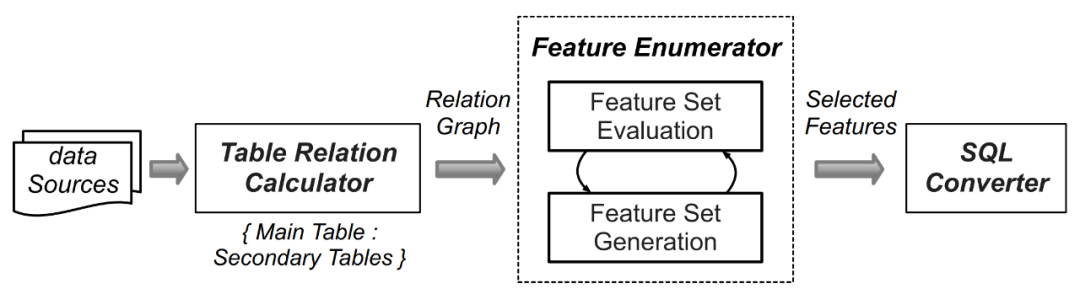
그림 4. FEBench의 쿼리 생성 프로세스
콘텐츠를 다시 작성할 때 적절한 템플릿을 선택해야 합니다.
각 데이터세트에 대한 쿼리를 생성한 후 연구원들은 클러스터링 알고리즘을 추가로 사용하여 다음을 수행했습니다. 유사한 작업에 대한 반복 테스트를 줄이기 위해 대표 쿼리를 쿼리 템플릿으로 선택합니다. 수집된 118개 데이터 세트 및 기능 쿼리에 대해 DBSCAN 알고리즘을 사용하여 이러한 쿼리를 클러스터링합니다. 구체적인 단계는 다음과 같습니다.
각 쿼리의 기능을 출력 열 수, 총 쿼리 수의 5개 부분으로 나눕니다. 쿼리 연산자, 복합 연산자의 발생 빈도, 중첩된 하위 쿼리 수준 수 및 시간 창의 최대 튜플 수입니다. 기능 엔지니어링 쿼리에는 일반적으로 기간이 포함되고 쿼리 복잡성은 배치 데이터 크기에 영향을 받지 않으므로 데이터 세트 크기는 클러스터링 기능 중 하나로 포함되지 않습니다.
로지스틱 회귀 모델을 사용하여 기능을 모델의 입력으로 사용하고 기능 쿼리의 실행 시간을 모델의 출력으로 사용하여 쿼리 기능과 쿼리 실행 특성 간의 관계를 평가합니다. 각 특성의 회귀 가중치를 클러스터링 가중치로 사용하여 클러스터링 결과에 대한 다양한 특성의 중요성을 고려합니다.
가중 쿼리 특성을 기반으로 DBSCAN 알고리즘을 사용하여 특성 쿼리를 여러 클러스터로 나눕니다.
다음 차트는 다양한 고려 사항 지표에 따라 118개 데이터 세트의 분포를 보여줍니다. 그림 (a)는 출력 열 수, 총 쿼리 연산자 수 및 중첩 하위 쿼리 수준 수를 포함하여 통계적 성격의 지표를 보여줍니다. 그림 (b)는 쿼리 실행 시간과 가장 높은 상관 관계를 갖는 지표를 보여줍니다. 집계 연산 수, 중첩된 하위 쿼리 수준 수 및 시간 창 수
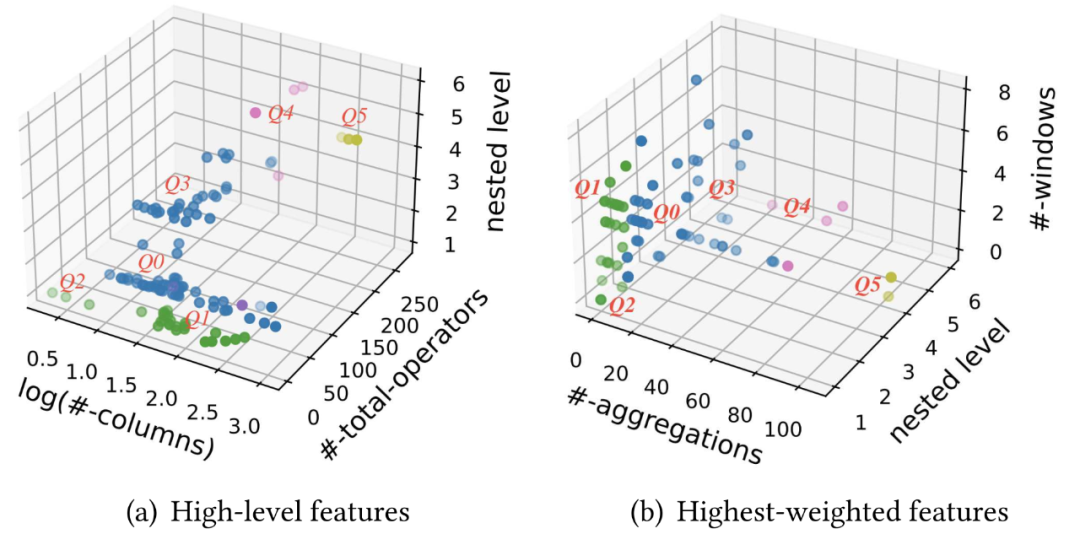
그림 5. 클러스터 분석을 통해 6개의 클러스터를 얻은 118개의 기능 쿼리 및 쿼리 템플릿(Q0-5)이 생성되었습니다
마지막으로 클러스터링 결과 118개의 특징 쿼리를 6개의 클러스터로 나누었습니다. 각 클러스터에 대해 중심 근처의 쿼리가 후보 템플릿으로 선택됩니다. 또한 다양한 애플리케이션 시나리오의 인공 지능 애플리케이션에는 다양한 기능 엔지니어링 요구 사항이 있을 수 있다는 점을 고려하여 다양한 기능 엔지니어링 시나리오를 더 잘 처리하기 위해 각 클러스터 중심 주변의 다양한 시나리오에서 쿼리를 선택해 보세요. 마지막으로 118개의 기능 쿼리 중에서 교통, 의료, 에너지, 판매, 금융 거래 등 다양한 시나리오에 적합한 6개의 쿼리 템플릿이 선택되었습니다. 이 6개의 쿼리 템플릿은 궁극적으로 실시간 피쳐 계산 플랫폼의 성능 테스트에 사용되는 FEBench의 핵심 데이터 세트 및 쿼리를 구성합니다.
다시 작성해야 할 사항은: 벤치마크 평가(OpenMLDB 및 Flink)
연구에서 연구원들은 FEBench를 사용하여 두 가지 일반적인 산업 시스템, 즉 Flink와 OpenMLDB를 테스트했습니다. Flink는 일반적인 배치 및 스트림 처리 일관된 컴퓨팅 플랫폼인 반면, OpenMLDB는 전용 실시간 기능 컴퓨팅 플랫폼입니다. 연구진은 테스트와 분석을 통해 각 시스템의 장단점과 그 이유를 발견했습니다. 실험 결과에 따르면 아키텍처 설계가 다르기 때문에 Flink와 OpenMLDB 간에 성능에 차이가 있는 것으로 나타났습니다. 동시에 이는 대상 시스템의 기능을 분석하는 데 있어 FEBench의 중요성을 보여줍니다. 요약하면, 연구의 주요 결론은 다음과 같습니다.
Flink는 대기 시간이 OpenMLDB보다 2배 정도 느립니다(그림 6). 연구원들은 두 시스템 아키텍처의 구현 방식이 다르기 때문이라고 연구진은 분석했다. OpenMLDB는 실시간 특징 계산 전용 시스템으로 메모리 기반의 이중 레이어 점프 테이블과 시간에 최적화된 기타 데이터 구조를 포함하고 있다. 궁극적으로 Flink와 비교하여 기능 계산 시나리오에서 확실한 성능 이점이 있습니다. 물론 Flink는 범용 시스템으로서 OpenMLDB보다 적용 가능한 시나리오 범위가 더 넓습니다.
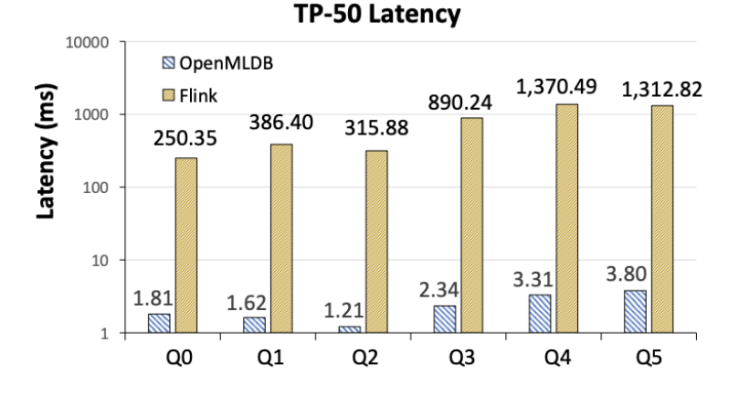
그림 6. OpenMLDB와 Flink의 TP-50 대기 시간 비교
OpenMLDB는 명백한 롱테일 대기 시간 문제를 보이는 반면, Flink의 테일 대기 시간은 더 안정적입니다(그림 7). 다음 숫자는 OpenMLDB 및 Flink의 각각 TP-50에 대해 표준화된 대기 시간 성능을 보여주며 절대적인 성능 비교를 나타내지는 않습니다. 다음과 같이 다시 작성: OpenMLDB는 꼬리 지연 시간에 명백한 문제가 있는 반면 Flink의 꼬리 지연 시간은 더 안정적입니다(그림 7 참조). 다음 숫자는 절대 성능 비교가 아닌 각각 TP-50에서 OpenMLDB 및 Flink의 성능에 대한 대기 시간 성능을 정규화한다는 점에 유의해야 합니다
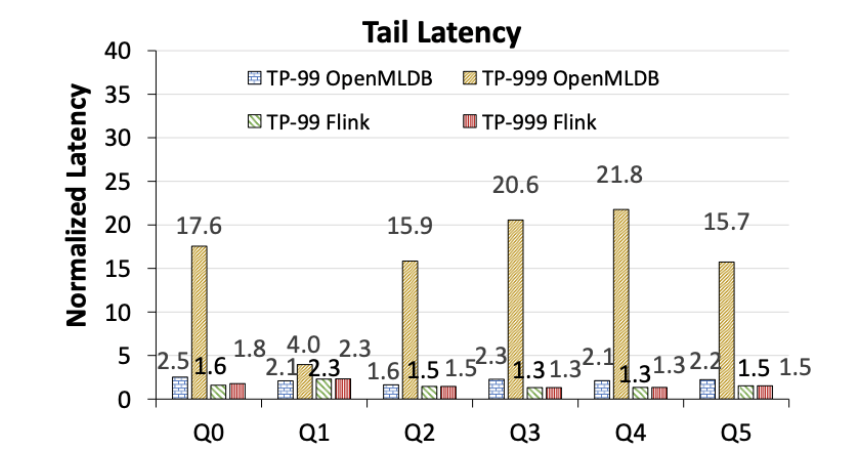
그림 7. OpenMLDB 및 Flink의 끝 지연 시간 비교(각각의 TP-50 지연 시간으로 정규화)
연구원들은 위의 성능 결과에 대해 심층 분석을 수행했습니다.
실행 시간을 기준으로 한 분해 분석, 마이크로 아키텍처 지표에는 명령 완료, 오류 분기 예측, 백이 포함됩니다. -엔드 종속성, 프런트엔드 종속성 등 쿼리 템플릿마다 미세 구조 수준에서 성능 병목 현상이 다릅니다. 그림 8에서 볼 수 있듯이 Q0-Q2의 성능 병목 현상은 주로 프런트 엔드에 의존하며 전체 실행 시간의 45% 이상을 차지합니다. 이 경우 수행되는 작업은 비교적 간단하며 대부분의 시간은 사용자 요청을 처리하고 특징 추출 명령 간을 전환하는 데 소요됩니다. 3~5분기에는 백엔드 종속성(예: 캐시 무효화) 및 명령어 실행(더 복잡한 명령어 포함)이 더 중요한 요소가 됩니다. OpenMLDB는 대상 최적화를 통해 성능을 더욱 향상시킵니다
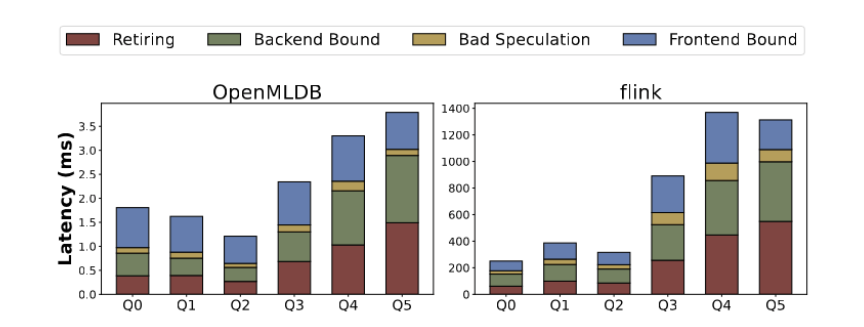
그림 8은 OpenMLDB 및 Flink의 마이크로 아키텍처 지표 분석을 보여줍니다
실행 계획 분석: Q0을 예로 들어 아래 그림 9를 비교합니다. Flink와 OpenMLDB 간의 실행 계획의 차이점. Flink의 계산 연산자는 가장 많은 시간을 소비하는 반면, OpenMLDB는 창을 최적화하고 사용자 지정 집계 함수와 같은 최적화 기술을 사용하여 실행 대기 시간을 줄입니다.
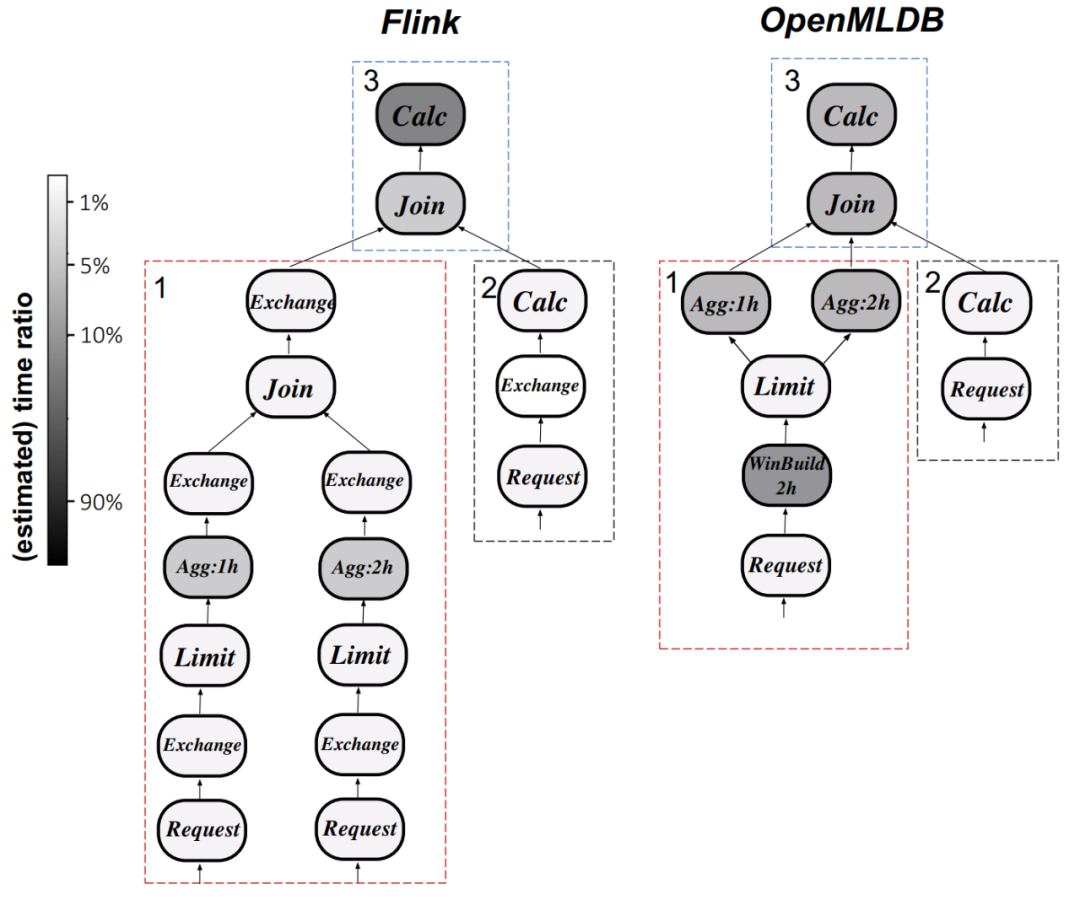
아홉 번째 그림은 실행 계획(Q0) 측면에서 OpenMLDB와 Flink의 비교를 보여줍니다.
사용자가 위의 실험 결과를 재현하거나 로컬 시스템에서 벤치마크 테스트를 수행할 것으로 기대하는 경우( 논문의 저자 또한 테스트 결과를 커뮤니티에 제출하고 공유하는 것이 좋습니다. 자세한 내용은 FEBench 프로젝트 홈페이지를 방문하세요.
FEBench 프로젝트: https://github.com/decis-bench/febench
Flink 프로젝트: https://github.com/apache/flink
OpenMLDB 프로젝트: https://github .com/4paradigm/OpenMLDB
위 내용은 VLDB 2023 시상식 발표, 칭화대학교, 4Paradigm, NUS 공동 논문이 최우수 산업 논문상 수상의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



