

주어진 두 문장에서 반복되지 않는 모든 단어를 인쇄합니다.


이 튜토리얼에서는 주어진 두 문장에서 반복되지 않는 모든 단어를 식별하고 인쇄합니다. 반복되지 않는 단어는 두 문장에서 한 번만 나타나는 단어, 즉 다른 문장에서는 반복해서 나타나지 않는 단어를 말합니다. 이 작업에는 입력 문장을 분석하고, 개별 단어를 식별하고, 두 문장을 비교하여 한 번만 나타나는 단어를 찾는 작업이 포함됩니다. 출력은 이러한 모든 단어의 목록이어야 합니다. 이 작업은 루프, 배열 또는 사전 사용과 같은 다양한 프로그래밍 방법을 통해 수행할 수 있습니다.
방법
다음은 주어진 두 문장에서 반복되지 않는 모든 단어를 인쇄하는 두 가지 방법입니다−
방법 1: 사전을 사용하세요
방법 2: 컬렉션 사용
방법 1: 사전을 사용하세요
사전을 사용하여 두 문구에 각 단어가 나타나는 횟수를 세어보세요. 그런 다음 사전을 찾아 한 번만 나타나는 모든 단어를 인쇄할 수 있습니다. C++의 사전 기능은 일반적으로 지정된 두 문장의 모든 고유 단어를 출력하는 데 사용됩니다. 이 방법에는 사전 또는 해시 테이블 데이터 구조를 사용하여 각 단어의 빈도를 두 문구에 저장하는 작업이 포함됩니다. 그런 다음 사전을 반복하여 한 번만 나타나는 용어를 인쇄할 수 있습니다.
문법
다음은 C++의 사전 메서드를 사용하여 주어진 두 문장에서 중복되지 않는 모든 단어를 인쇄하는 실제 코드가 없는 구문입니다. -
단어 빈도를 저장하는 사전을 선언하세요
두 문장을 문자열로 입력하세요
문장을 단어로 나누고 사전에 삽입하세요
사전을 반복하면서 고유한 단어를 인쇄하세요
알고리즘
C++에서는 사전 방법을 사용하여 지정된 두 문장의 모든 고유 항목을 단계별로 인쇄하는 트릭입니다. -
1단계 - 문장이 포함된 두 개의 문자열 s1과 s2를 만듭니다.
2단계 - 문장의 각 단어의 빈도를 기록하기 위해 순서가 지정되지 않은 빈 맵 문자열 int>를 선언합니다.
3단계 − C++의 문자열 스트림 클래스를 사용하여 두 구문을 구문 분석하여 단어를 추출합니다.
4단계 - 추출된 각 단어에 대해 사전에 나타나는지 확인합니다. 그렇다면 빈도를 1만큼 늘립니다. 그렇지 않으면 빈도 1로 사전에 추가하십시오.
5단계 - 두 문장을 모두 처리한 후 사전을 반복하고 빈도가 1인 모든 용어를 표시합니다. 두 문장에서 반복되지 않는 단어입니다.
6단계 − 이 방법의 시간 복잡도는 O(n)입니다.
예제 1
의 중국어 번역은 다음과 같습니다.예제 1
이 코드는 순서가 지정되지 않은 맵을 사용하여 결합된 구문에 있는 각 단어의 빈도를 저장합니다. 그런 다음 지도를 반복하면서 반복되지 않는 단어의 벡터에 한 번만 나타나는 각 단어를 추가합니다. 마지막으로, 중복되지 않은 단어를 공개합니다. 이 예는 두 문장이 사용자가 입력하는 것이 아니라 프로그램에 하드 코딩되어 있음을 의미합니다.
으아아아출력
으아아아방법 2: 컬렉션 사용
이 전략에는 집합을 사용하여 두 구문에서 한 번만 나타나는 용어를 찾는 것이 포함됩니다. 각 구문에 대한 용어 집합을 만든 다음 이러한 집합의 교차점을 식별할 수 있습니다. 마지막으로 교차점을 반복하여 한 번만 나타나는 모든 항목을 출력할 수 있습니다.
컬렉션은 다양한 요소를 정렬된 순서로 보관하는 연관 컨테이너입니다. 두 구문의 용어를 컬렉션에 삽입할 수 있으며 중복된 용어는 자동으로 제거됩니다.
문법
당연하죠! 다음은 주어진 두 문장에서 반복되지 않는 모든 단어를 인쇄하기 위해 Python에서 사용할 수 있는 구문입니다 −
두 문장을 문자열로 정의
각 문장을 단어 목록으로 분할하세요
이 두 단어 목록에서 세트를 만듭니다
세트의 교차를 통해 독특한 단어를 찾아보세요
고유한 단어를 인쇄하세요
알고리즘
C++의 집계 함수를 사용하여 주어진 두 문장에서 중복되지 않는 모든 단어를 출력하려면 아래 지침을 따르세요. -
1단계 - 두 문장을 저장할 문자열 변수 두 개를 만듭니다.
2단계 - 문자열 스트림 라이브러리를 사용하여 각 문장을 개별 단어로 분할하고 두 개의 개별 배열에 저장합니다.
3단계 - 각 문장마다 하나씩 두 개의 세트를 만들어 고유한 단어를 저장하세요.
4단계 - 각 단어 배열을 반복하고 각 단어를 올바른 세트에 삽입합니다.
5단계 - 각 세트를 반복하면서 중복되지 않는 단어를 인쇄하세요.
예 2
의 중국어 번역은 다음과 같습니다.예 2
이 코드에서는 문자열 스트림 라이브러리를 사용하여 각 문장을 별도의 단어로 분할합니다. 그런 다음 UniqueWords1 및 UniqueWords2라는 두 개의 컬렉션을 사용하여 각 문장의 고유한 단어를 저장합니다. 마지막으로 각 세트를 반복하여 중복되지 않은 단어를 인쇄합니다.
#include <iostream>
#include <string>
#include <sstream>
#include <set>
using namespace std;
int main() {
string sentence1 = "This is the first sentence.";
string sentence2 = "This is the second sentence.";
string word;
stringstream ss1(sentence1);
stringstream ss2(sentence2);
set<string> uniqueWords1;
set<string> uniqueWords2;
while (ss1 >> word) {
uniqueWords1.insert(word);
}
while (ss2 >> word) {
uniqueWords2.insert(word);
}
cout << "Non-repeating words in sentence 1:" << endl;
for (const auto& w : uniqueWords1) {
if (uniqueWords2.find(w) == uniqueWords2.end()) {
cout << w << " ";
}
}
cout << endl;
cout << "Non-repeating words in sentence 2:" << endl;
for (const auto& w : uniqueWords2) {
if (uniqueWords1.find(w) == uniqueWords1.end()) {
cout << w << " ";
}
}
cout << endl;
return 0;
}
输出
Non-repeating words in sentence 1: first Non-repeating words in sentence 2: second
结论
总之,从两个提供的句子中打印所有非重复单词的任务是通过使用各种编程方法来实现的,例如将句子分解为单个单词,利用字典来量化每个单词的频率,以及过滤掉非重复单词。生成的非重复单词集合可以报告给控制台或保存在列表或数组中以供进一步使用。这项工作对于基本的编程文本操作和数据结构操作很有帮助。위 내용은 주어진 두 문장에서 반복되지 않는 모든 단어를 인쇄합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 감성지능이 높은 틱톡 댓글에 어떻게 대응하나요? TikTok 댓글에 답할 문장은 무엇입니까?
Mar 23, 2024 pm 07:50 PM
감성지능이 높은 틱톡 댓글에 어떻게 대응하나요? TikTok 댓글에 답할 문장은 무엇입니까?
Mar 23, 2024 pm 07:50 PM
현대 사회에서는 많은 사람들이 Douyin 플랫폼에서 자신의 삶을 보여주고 개인적인 감정을 표현하는 것을 좋아하며 댓글 영역의 토론은 종종 열띤 토론을 촉발합니다. Douyin 댓글에 높은 EQ로 답변하는 방법은 많은 사람들의 관심의 초점이 되었습니다. 1. 감성지능이 높은 Douyin 댓글에 어떻게 대응하나요? 예의바르고 존중하는 태도는 인터넷 커뮤니케이션의 기본 원칙입니다. 동의하지 않더라도 정중하게 응답하세요. 감사를 표하고 기꺼이 의사소통을 함으로써 좋은 의사소통 분위기를 조성할 수 있습니다. 이해와 공감을 보여주는 것은 매우 중요합니다. 특히 리뷰어가 어려움이나 좌절을 겪고 있는 경우에는 더욱 그렇습니다. 공감과 이해를 표현하는 한 가지 방법은 다음과 같습니다. "나는 당신이 겪고 있는 어려움을 이해합니다. 당신이 문제를 해결할 방법을 찾을 수 있기를 바랍니다. 나는 당신이 그것을 극복할 수 있도록 최선을 다할 것입니다."
 몰입형 리더와 함께 Microsoft Reader Coach를 사용하는 방법
Mar 09, 2024 am 09:34 AM
몰입형 리더와 함께 Microsoft Reader Coach를 사용하는 방법
Mar 09, 2024 am 09:34 AM
이 기사에서는 Windows PC의 몰입형 리더에서 Microsoft Reading Coach를 사용하는 방법을 보여줍니다. 읽기 지도 기능은 학생이나 개인이 읽기를 연습하고 읽고 쓰는 능력을 개발하는 데 도움이 됩니다. 지원되는 애플리케이션에서 구절이나 문서를 읽는 것부터 시작하고, 이를 기반으로 Reading Coach 도구를 통해 읽기 보고서가 생성됩니다. 읽기 보고서에는 읽기 정확도, 읽는 데 걸린 시간, 분당 올바른 단어 수, 읽으면서 가장 어려웠던 단어가 표시됩니다. 또한 단어를 연습할 수 있어 전반적인 읽기 능력을 개발하는 데 도움이 됩니다. 현재 Office 또는 Microsoft365(웹용 OneNote 및 We용 Word 포함)만
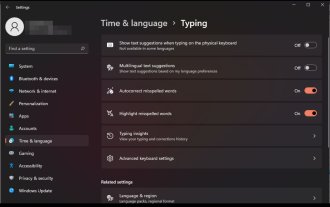 Windows 11에서 철자가 틀린 단어의 자동 수정을 활성화 또는 비활성화하는 방법
Sep 19, 2023 pm 10:53 PM
Windows 11에서 철자가 틀린 단어의 자동 수정을 활성화 또는 비활성화하는 방법
Sep 19, 2023 pm 10:53 PM
자동 수정은 일상 생활에서 많은 시간을 절약할 수 있는 매우 유용한 기능입니다. 완벽하지는 않지만 대부분의 경우 철자 실수와 쓰기 오류를 수정하는 데 사용할 수 있습니다. 그러나 때로는 제대로 작동하지 않을 때도 있습니다. 일부 단어를 인식하지 못하여 효율적으로 작업하기가 어렵다는 것을 알게 될 것입니다. 다른 경우에는 이를 비활성화하고 이전 방식으로 돌아가고 싶을 수도 있습니다. 하지만 자동 고침을 사용하면 어떤 이점이 있나요? 철자 오류를 수정하여 시간을 절약하세요. 올바른 철자를 표시하여 새로운 단어를 배우는 데 도움이 됩니다. 이메일과 기타 문서에서 당혹스러운 실수를 방지하는 데 도움이 됩니다. 더 빠르게 입력하고 실수를 줄일 수 있습니다. Windows 11에서 맞춤법 검사를 켜거나 끄는 방법은 무엇입니까? 1. 설정 앱을 사용해 키를 탭하세요.
 잉크로 암기하고 있는 단어를 어떻게 다시 암기할 수 있나요? 모모에서 단어를 외우고 단어를 다시 외우는 방법을 공유해보세요!
Mar 15, 2024 pm 03:28 PM
잉크로 암기하고 있는 단어를 어떻게 다시 암기할 수 있나요? 모모에서 단어를 외우고 단어를 다시 외우는 방법을 공유해보세요!
Mar 15, 2024 pm 03:28 PM
모모가 단어를 외우면 어떻게 다시 암기 시작하는지 궁금하시죠? Mo Mo Bei Vocabulary는 사용하기 매우 쉬운 영어 단어 학습 소프트웨어입니다. 사용자는 영어 수준과 학습 의도에 따라 영어 학습을 위한 영어 어휘 라이브러리를 선택할 수 있으며 예문, 니모닉 및 기타 방법을 사용하여 더 잘 이해할 수 있습니다. 단어를 암기하세요. 어떤 친구들은 단어 암기를 마치고 같은 단어장을 다시 암기하고 싶은데 어떻게 해야 할지 모르시나요? 오늘은 에디터가 여러분을 위해 단어암기와 재암기 방법을 정리해보았습니다! 도움이 되셨다면 다운받아보세요! 1. 단어 암기를 다시 시작하려면 어떻게 해야 하나요? 모모에서 단어를 외우고 단어를 다시 외우는 방법을 공유해보세요! 1. Mo Mo Bei Vocabulary 앱을 열고 리뷰 페이지에서 체크인 기능을 확인한 후 날짜를 선택하세요. 2. 클릭하여 들어가시면 세부정보를 볼 수 있는 옵션이 표시됩니다. 3. 해당 페이지로 이동한 후
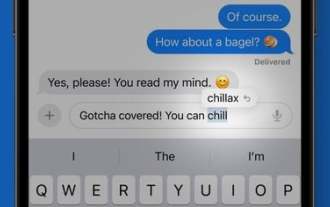 iOS 17에서 예측 자동 수정을 활용하는 방법
Sep 17, 2023 pm 03:37 PM
iOS 17에서 예측 자동 수정을 활용하는 방법
Sep 17, 2023 pm 03:37 PM
향상된 기계 학습 기술 덕분에 Apple의 iOS 17에서는 iPhone에서 텍스트를 입력할 때 자동 고침이 더욱 유용해졌습니다. Apple은 "모퍼 언어 모델"을 사용하여 개별 사용자를 위한 자동 고침을 더 잘 개인화하고 개인 선호도와 단어 선택을 학습하여 입력할 때 더 유용하게 만들 수 있다고 말합니다. 몇 주 동안 iOS 17을 사용한 후에는 자동 고침 제안이 말하고 싶은 내용을 예측하고 자동 완성을 위해 클릭할 단어를 표시하는 데 더 효과적이라는 것을 알게 될 것입니다. 자동 고침은 약어, 축약어, 속어 및 구어체를 사용할 때 자동 고침보다 덜 공격적이지만 실수로 인한 철자 오류를 수정할 수 있습니다. 자동 고침 수정 자동 고침이 단어를 변경하면 수정된 단어 아래에 파란색 선이 나타납니다. 당신은 할 수있다
 Hundred Words Chop에서 잘린 단어는 어디에 있나요? 수백 개의 단어를 제거하는 데 사용할 수 있는 단어 검색 튜토리얼!
Mar 15, 2024 pm 03:52 PM
Hundred Words Chop에서 잘린 단어는 어디에 있나요? 수백 개의 단어를 제거하는 데 사용할 수 있는 단어 검색 튜토리얼!
Mar 15, 2024 pm 03:52 PM
1. 백자컷에서 삭제된 단어는 어디에 있나요? 수백 개의 단어를 제거하는 데 사용할 수 있는 단어 검색 튜토리얼! 1. 홈페이지에 접속하여 단어목록을 클릭하세요. 2. 해당 페이지로 이동한 후 잘린 단어 옵션을 선택하세요. 3. 인터페이스에 들어가면 사용자가 잘린 단어를 볼 수 있습니다. 4. 잘린 단어를 복원하려면 편집 옵션을 클릭하세요. 5. 복원이 필요한 단어를 찾아 오른쪽의 잘라내기 아이콘을 클릭하면 해당 단어가 복원됩니다. 6. 학습된 단어 인터페이스로 돌아가면 방금 복구한 단어를 볼 수 있습니다.
 Python을 사용하여 문자열의 단어 길이 계산
Sep 13, 2023 am 11:29 AM
Python을 사용하여 문자열의 단어 길이 계산
Sep 13, 2023 am 11:29 AM
Python을 사용하여 주어진 입력 문자열에서 개별 단어의 길이를 찾는 것은 해결해야 할 문제입니다. 우리는 텍스트 입력에서 각 단어의 문자 수를 세고 그 결과를 목록과 같은 구조화된 스타일로 표시하려고 합니다. 이 작업을 수행하려면 입력 문자열을 나누고 각 단어를 분리해야 합니다. 그런 다음 각 단어의 문자 수를 기준으로 각 단어의 길이를 계산합니다. 기본 목표는 효율적으로 입력을 받고, 단어 길이를 결정하고, 적시에 결과를 출력할 수 있는 함수나 프로시저를 만드는 것입니다. 이 문제를 해결하는 것은 텍스트 처리, 자연어 처리, 데이터 분석 등 다양한 애플리케이션에서 매우 중요합니다. 여기서 단어 길이 통계는 통찰력 있는 정보를 제공하고 추가 분석을 가능하게 합니다. 사용된 방법 루프 및 분할() 함수 사용 len 및 분할()과 함께 map() 함수 사용
 iOS 17은 iPhone의 자동 수정 기능을 크게 향상시킵니다.
Jun 06, 2023 am 08:20 AM
iOS 17은 iPhone의 자동 수정 기능을 크게 향상시킵니다.
Jun 06, 2023 am 08:20 AM
Apple은 오늘 iPhone용 iOS 17을 미리 선보였으며, 업데이트가 제공하는 주요 새로운 기능 중 하나는 향상된 자동 수정 기능입니다. Apple은 iOS 17에 iPhone 자동 수정 기능을 크게 향상시킬 최첨단 단어 예측 언어 모델이 포함되어 있다고 밝혔습니다. 입력할 때마다 온디바이스 머신 러닝이 그 어느 때보다 더 정확하게 오류를 지능적으로 수정합니다. 또한 이제 입력할 때 인라인 예측 텍스트 제안을 받게 되므로 스페이스바를 눌러 단어를 추가하거나 문장을 완성할 수 있습니다. 자동 고침은 자동 고침되는 단어를 간략하게 강조하는 iOS 17의 디자인이 업데이트되었습니다. 밑줄 친 단어를 클릭하면 입력한 원래 단어가 표시되므로 변경 사항을 빠르게 되돌릴 수 있습니다. 시간이 지남에 따라 시스템은 사용자의 타이핑도 학습합니다.
